
Привет! Пока мы ждём субботу и Avito Data Science Meetup: Computer Vision, расскажу вам про моё участие в соревновании по машинному обучению KONICA MINOLTA Pathological Image Segmentation Challenge. Хотя я уделил этому всего несколько дней, мне повезло занять 2 место. Описание решения и детективная история под катом.

Описание задачи
Необходимо было разработать алгоритм сегментации областей на снимках из микроскопа. Судя по всему, это были некоторые очаги раковых клеток в эпителии. На картинке ниже — то, что было дано и как надо было сделать:
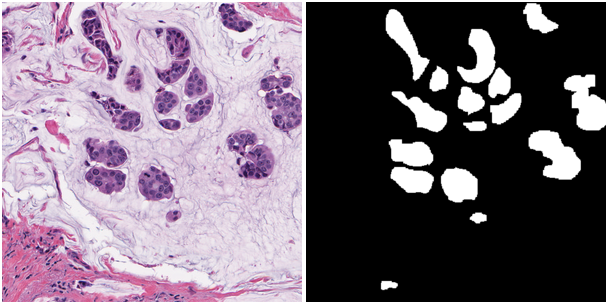
Обучающая и тестовые выборки состояли соответственно из 168 и 162 таких изображений размером 500x500 пикселей. Целевая метрика — арифметическое среднее F1-micro и instance-wise Dice x 1000000.
Лирическое отступление с впечатлениями о площадке
Конкурс проводился на сайте Topcoder. Возможно, читателю этот сайт больше напоминает об олимпиадном программировании, чем про машинное обучение и нейросети. Но, судя по всему, парни решили тоже быть в тренде. Получилось у них это сомнительно не только в плане подготовки данных (об этом ниже), но и в плане юзабилити. Чтобы отправить решение, необходимо:
- предсказать трейн (!) и тест;
- перегнать маски в txt, и не забыть при этом их транспонировать;
- запаковать маски в архив и закинуть его в свой gdrive/dropbox/etc;
- зайти в систему сабмитов соревнования и написать java-класс, который дергает по ссылке архив.
Сабмиты можно отправлять раз в 2 часа. Раз в 15 минут доступна проверка вашего трейна. Соответственно, если на каком-то пункте что-то шло не так — гуляем 2 часа. Закинул файлы в архиве в папку, а не в корень — очень жаль, мы не нашли маски, иди проверяй, у тебя 2 часа. Забыл докинуть маски трейна — через 2 часа будь повнимательней. Я не говорю о том, что с такой системой легко перепутать и отправить решение, которое уже посылал. Ну и очень классно, когда в час ночи ты наконец допилил очередной улучшайзер, собрал архив и ошибся — остается либо не спать, либо ждать до утра.
Также не было опции выбрать какой-то свой сабмит в качестве финального. Его нужно было просто отправить последним. И не ошибиться, конечно же. Забегая вперед надо сказать, что китайская платформа challenger.ai переплюнула в упоротости топкодер, но об этом в следующий раз.
Первая итерация
Надо сказать, что я долго не хотел участвовать, потому что это опять сегментация и площадка странная. Но Владимир Игловиков и Евгений Нижибицкий пушили меня присоединиться, за что им отдельное спасибо.
Как водится, я решил начать с бейзлайна. В качестве него я выбрал код ZFTurbo, который он причесал и выложил после kaggle’a со спутниками. Там уже были примеры моделей и код для их обучения. Я дополнил его разделением на пять фолдов. Их я сделал, отсортировав все маски трейна по площади и разделив так, чтобы в каждом фолде распределение площадей было одинаковым. Я надеялся так стратифицировать фолды, как же сильно я ошибался...
Из аугментаций я оставил стандартные повороты, кропы, ресайзы. В качестве оптимайзера выбрал Adam.
Вторая итерация
Пока модели обучались, я решил улучшить бейзлайн и начал с того, что внимательно посмотрел на снимки. Для начала я воспользовался математикой и понял, что количество снимков в трейне делится на 6, поэтому лучше делать 6 фолдов, а не 5. Мне показалось, что я не особо понимаю, где заканчиваются одни ткани и начинаются другие, поэтому я просто объединил каждую обучающую часть фолда в одну огромную маску. И дальше я дергал из нее случайные патчи в 1.5 раза больше, чем вход нейросети. К ним применял более агрессивные аугментации, используя библиотеку imgaug.
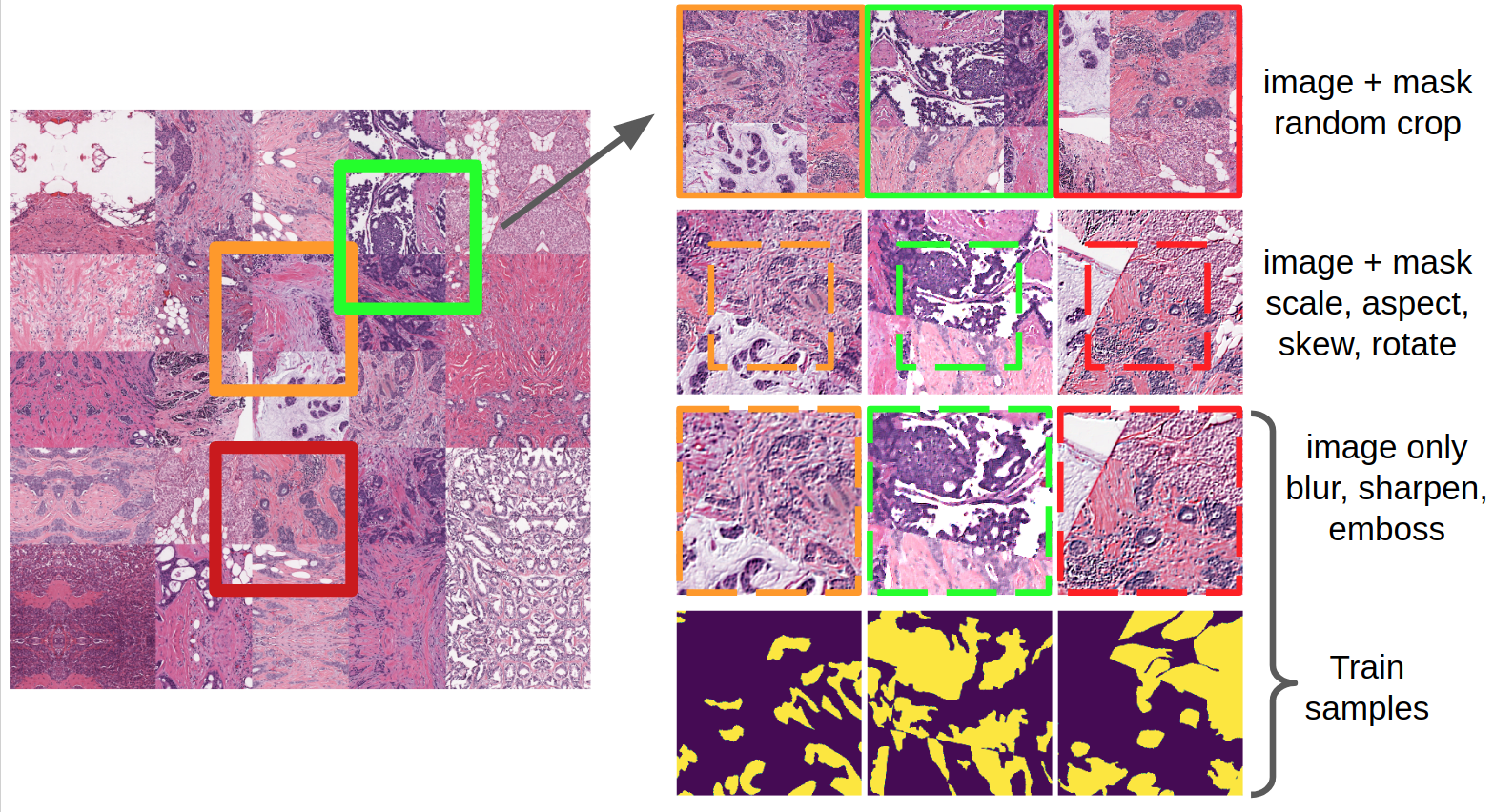
Стоит сказать, что imgaug использует skimage, который не отличается скоростью, поскольку написан на питоне. Чтобы побороть этот недостаток, я использовал dataloader из pytorch. Он офигенен: нужно написать по сути одну функцию get_sample, которая готовит x и y (в данном случае — картинку и маску), а итератор сам в несколько потоков с буфером собирает батч. Он настолько классный, что я использую его даже c keras и mxnet. Для этого нужно выдрать тензоры батча и перегнать в numpy.
Также во второй итерации я поменял стратегию по обучению. Сначала я обучал Adam с понижением Learning rate, затем переключался на SGD и в конце обучал с SGD без аугментаций изображений, связанных с блюрами и шарпами.
Кроме того, параллельно я запустил три обучения с разными функциями потерь: Binary Cross Entropy (BCE), BCE — log(Jaccard), BCE — log(Dice).

Третья итерация
В третий заход я решил, что настало время слезть с иглы архитектуры U-net, полюбить другие нейросети и начать жить. Я внимательно изучил картинки в обзоре и выбрал Global Convolutional Network. Большие ядра, факторизованные свертки, уточняющие границу блоки, гусь на картинках… “Easygold!”, — подумал я. Но за пару вечеров так и не получил на этой архитектуре приличный результат, время закончилось и все эксперименты переехали в kaggle Carvana.
Финальный ансамбль
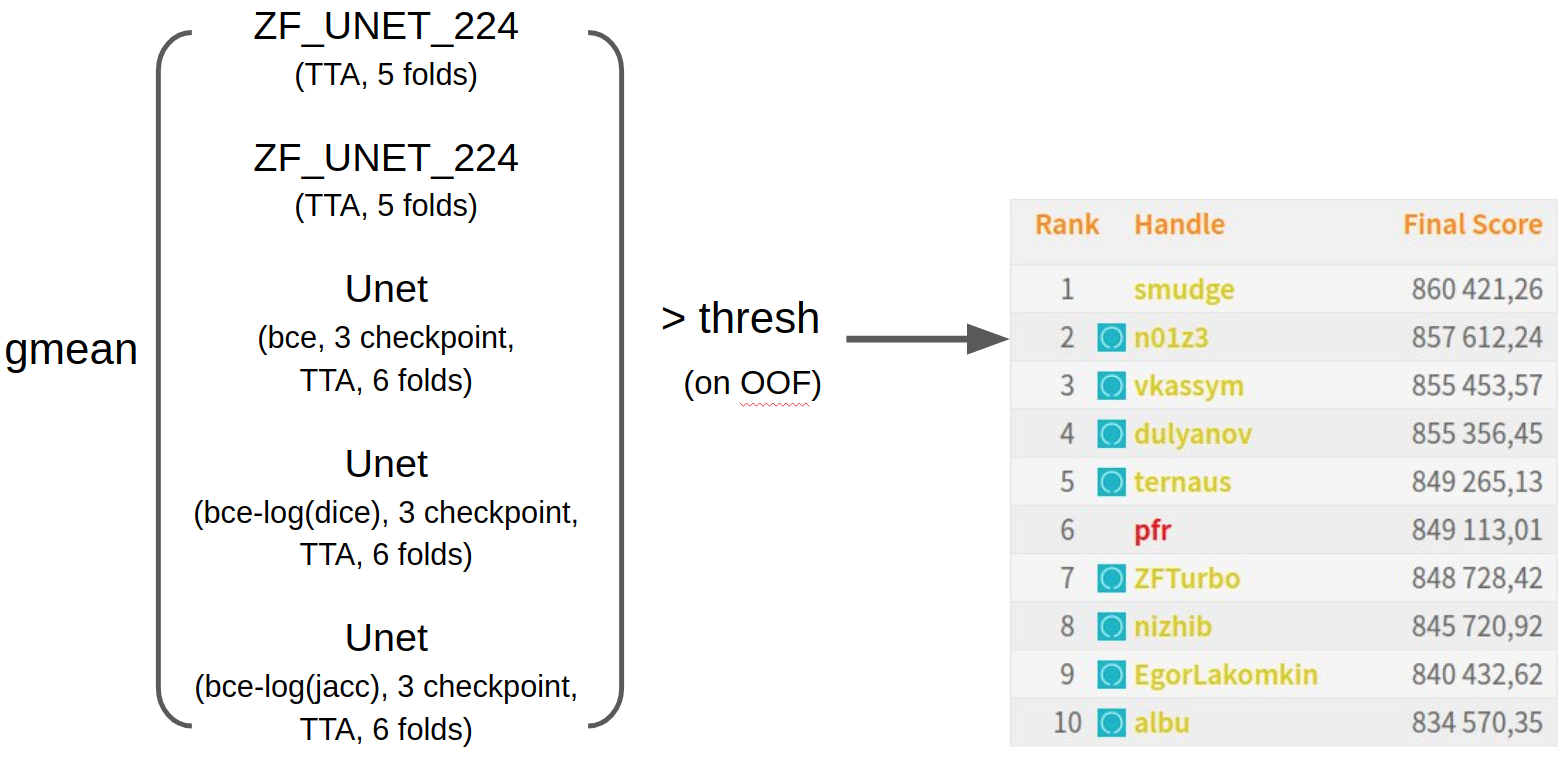
В итоге я просто смешал все обученные к тому моменту нейросети геометрическим средним. Подобрал пороги на OOF предсказаниях и отправил за несколько часов до дедлайна. Я был крайне удивлен, оказавшись на втором месте, поскольку на public части был 11-м. На мой взгляд, мне дико повезло, поскольку в данных был один глобальный косяк, о котором ниже. Синими значками отмечены участники из сообщества ODS.ai. Видно, что набег удался. Чтобы следить за успехами нашего чатика, можно подписаться на твиттер
Детективное CV-расследование Евгения Нижибицкого
В подавляющем большинстве соревнований локальная валидация и лидерборд перестают совпадать начиная с некоторого качества моделей. И этот компетишн — не исключение. Однако причина оказалась куда интересней, чем просто неоднородное разбиение.
В этом конкурсе по аналогии с соревнованием Kaggle Amazon from Space Евгений Нижибицкий решил собрать исходную мозаику, из которой были нарезаны снимки.
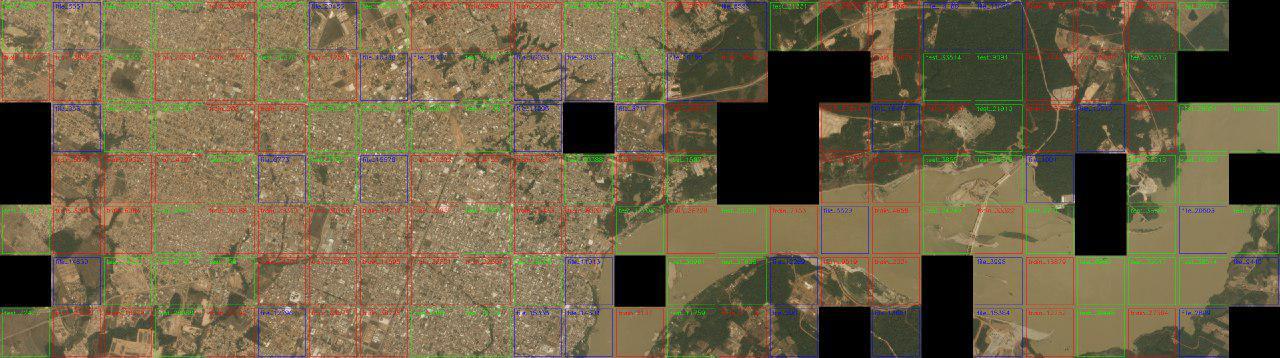
Поиск соседей осуществлялся на основе L2-расстояния между парами границ для всех возможных изображений. На основе сравнения с порогом создавалась таблица, в которой для каждого изображения были указаны его соседи и расстояние до них. Каждый раз найденные пары валидировались глазами, при этом запоминались отдельно как корректные, так и некорректные. После этого порог немного повышался и поиск производился еще раз.
Итогом составления мозаики стало понимание структуры данных — обучающая выборка состоит из 42 квадратов 1000x1000, каждый из которых нарезан на 4 меньших. Тестовая выборка на квадраты «распалась» не вся, но 120 из 162 изображений теста так же объединяются в 30 квадратов 2x2.
Из этого эксперимента можно сделать неутешительный вывод — кросс-валидация со случайными разбиениями сплитов нерепрезентативна, потому что при 6 фолдах для каждого фиксированного квадрата 2x2 его части с вероятностью около 50% попадают и в трейн, и в валидацию.
Но не угасало любопытство, почему же в мозаику никак не объединяются 42 тайла из теста. Во время одного из процессов отсеивания неправильно сматченных соседних тайлов обнаружилось, что ошибочно склеенные тайлы теста и трейна на самом деле не соединяются по границе, но после поворота они матчатся целыми подрегионами!
Небольшой proof-of-concept с матчингом на SURF-признаках позволил выяснить, что некоторые тестовые картинки действительно просто вырезаны из исходных больших картинок трейна:

После попыток подбора по всем картинкам теста оказалось, что не объединяющиеся в мозаики 42 картинки из теста есть не что иное, как участки трейна. То есть орги сделали следующее.
- Взяли 42 оригинальные (размером 1000х1000) картинки трейна и 30 картинок теста.
- Нарезали из них картинки размером 500х500.
- Решили, что в тесте маловато картинок (120).
- Докинули в тест рандомно повернутые патчи из трейна.
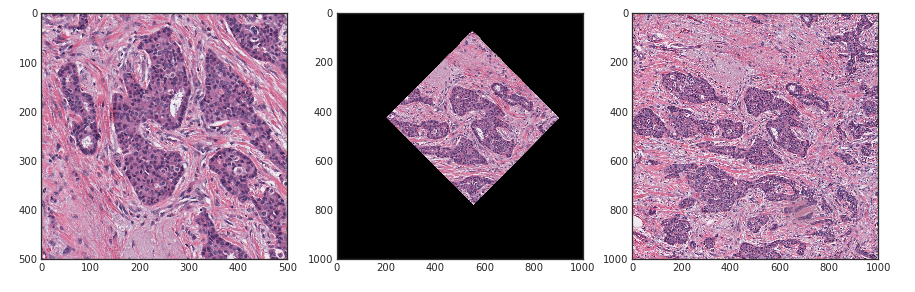
На картинке слева направо: одна картинка из теста, она же повернутая для соответствия трейну, исходный квадрат 2х2 трейна.
В итоге все участники, кто не чистил таким образом данные и кто не делал сплиты по пациентам (то есть все участники ODS.ai) оверфитились. При этом улучшение на лидерборде могло происходить по двум причинам: улучшение качества работы модели на неизвестных данных и переобучение на повернутых кусках теста в трейне. А поскольку сплиты были неинформативны, то корреляции с локальной валидацией и лидербордом не было и в помине. Ведь невозможно было даже локально понять: модель действительно научилась обобщать или оверфитнулась на трейне и за счет этого улучшилась валидация.
Про этот компетишн я рассказывал на ML-тренировке в Яндексе, можно посмотреть видео. Бонусом можно посмотреть слайды Владимира с митапа в H20. Так же о куда более продвинутом подходе к сегментации Евгений Нижибицкий расскажет в конце этой неделе на meetup’e в Avito. Регистрация уже закрыта, но можно будет присоединиться к онлайн-трансляции на youtube-канале AvitoTech в день мероприятия начиная с 12:30.
ser-mk
А есть какой-нибудь глоссарий для новичков? Что бы понять хотя бы половину русских транслитераций…
N01Z3 Автор
Увы, нет. Но это повод заглянуть в ODS slack и даже поучаствовать в соревнованиях.