
В 2016 год Google Brain Group выпустил проект Magenta в открытый доступ. Magenta позиционируется как проект, который задает и отвечает на вопросы:«Можем ли мы использовать машинное обучение для создания музыки и искусства достойных внимания? Если да, то как? Если нет, то почему нет?». Вторая цель проекта — это построить сообщество художников, музыкантов и исследователей в области машинного обучения.
Почему бы и нет, действительно. Появился и повод: сделать небольшой перфоманс на открытии конференции TopConf.
Привет, меня зовут Александр Тавген. Я Архитектор в компании Playtech, и мне нравится по прежнему играть в конструктор. Правда конструктор немного усложнился.
Я предложил попробовать связать музыку и машину Александру Жеделёву aka Faershtein, композитору и музыкальному продюсеру Русского Tеатра Эстонии. Вернее, проекту MODULSHTEIN (Александр Жеделёв, Мартен Альтров и Алексей Семинихин). У меня давно уже подспудно витали мысли попробовать обьединить MIDI и char-based модели. Нас очень здорово поддержала компания Playtech, за что ей огромная благодарность. У нас было порядка двух месяцев, чтобы реализовать нашу попытку. И это очень мало, учитывая, что мы живем в разных городах и работаем по основным родам деятельности.
В этом плане, известная статья Andrej Karpathy — это отличное введение в принципы, стоящие за рекуррентными нейронными сетями, и там отличные примеры. Чего стоит одна только сеть, натренированная на исходном коде Linux. Или модель, натренированная на речах Дональда Трампа, о чем я писал весной.
Если взять в общем, то рекуррентные нейронные сети показывают вполне удовлетворительные результаты для временных данных с некой структурой.
Возьмем язык. Структура языка имеет несколько измерений. Одно из них семантическое, к которому машины только подбираются. К примеру, аргумент «Китайской комнаты» Сёрла уже не выглядит таким убедительным по отношению к Мультимодальному Обучению.
Другое измерение, синтаксическое, уже вполне по силам. Рекуррентные нейронные сети учитывают предыдущий контекст и могут хранить состояние. И это было забавно наблюдать на практике, но об этом ниже. Мы можем скормить модели большое количество текста и попросить предсказать вероятность получения следующих букв. К примеру, после букв 'I lov', с очень большой вероятностью будет идти 'е', но после букв 'I love ', уже не очевидно — может быть и 'y', 'h' или иная.
Музыка, как правило, имеет некую структуру. Это ритм, интервалы, динамика. Если моделировать музыкальную последовательность как набор неких символов, то рекуррентные нейронные сети подходят для этого отлично. MIDI формат файлов подходит для этого идеально. Пока я думал как это можно сделать, и присматривался к MIDI библиотекам на Питоне, я наткнулся на проект Magenta.
По сути, Magenta предоставляет MIDI интерфейс для моделей TensorFlow. Создаются виртуальные MIDI порты для call-response, грубо говоря — входа и выхода. Можно запускать несколько параллельных портов. К каждой паре портов можно подсоединить модель TensorFlow. Так называемый bundle файл — это checkpoint тренинга и метаданные графа из TensorFlow. Кратко процесс взаимодействия можно описать так.
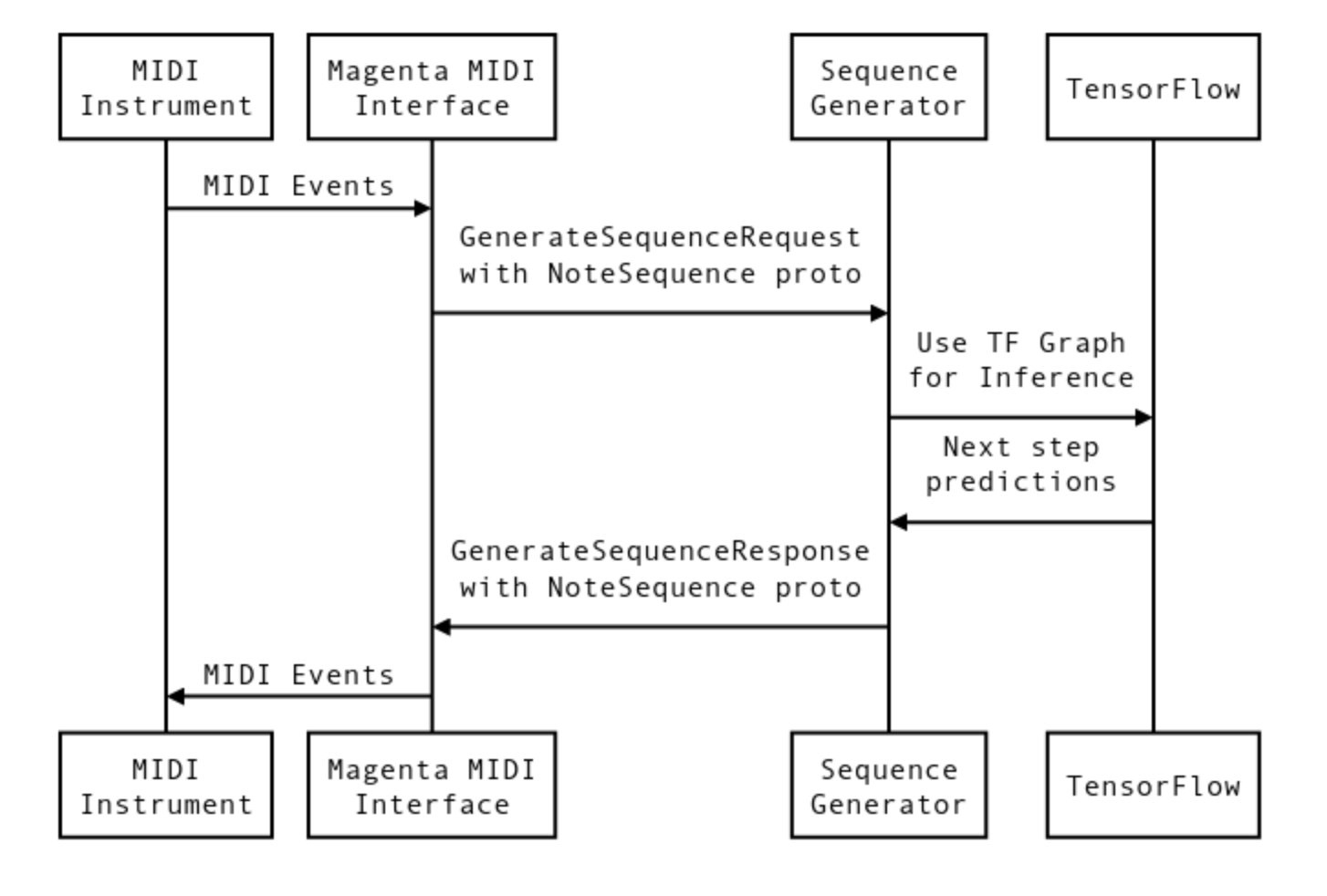
Сигналы проходят через MIDI интерфейс, и преобразуются в формат NoteSequence. Это protocol buffers формат для обмена данными с моделями. Данные для тренинга можно скачать отсюда, или взять pretrained модель, и продолжить обучение с нее.
Поначалу я думал вести тренинг с нуля, но во-первых были проблемы с объемом данных для тренинга, а во-вторых, когда я пробовал запустить Magenta на Амазоне, на instance с GPU, там возникли проблемы с зависанием на разных этапах тренинга. Проблемы были с объемом данных для тренинга с нуля, а тренировать на том же dataset, на каком натренированы модели в репозитории Magenta не имеет смысла. Поэтому я продолжил с их checkpointa. Я накачал кучу музыки с ломанными ритмами. От Prodigy — Outer of Space и Goldie — Inner City Life до Massive Attack.
На Magenta Project Github, уже есть инструменты для извлечения разных секций, таких как ударных и мелодий из подготовленных последовательностей нот. LSTM рекуррентная сеть была использована, 2 слоя по 128 элементов, 2 последних бара принимались в расчет. Время тренинга порядка 4 дней на лаптопе. Впрочем градиент спускался очень медленно, и я не могу сказать, был ли это в конце спуск, или осцилляция вокруг локального минимума.
Теперь перейдем к тому, как это все было связано дальше. Checkpoints были связаны в bundle файл, и две модели загружались на старте, каждая из которых — со своей парой виртуальных портов. Назовем их magenta_in/out 1 и 2. Теперь надо все это связать с живыми музыкантами. Александр Жедёлев использовал Ableton как универсальный клей.
На сайте проекте Magenta есть пример, как связывать Ableton с помощью MaxMSP, но этот вариант отпал, так как MaxMSP аварийно завершал работу и вылетал. Если что-то можно выкинуть из системы без помехи для работы, то смело выкидывайте.
Александр Жеделёв колдовал с Ableton. У нас были небольшие проблемы с общей синхронизацией Magenta and Ableton через midi_clock. В конце концов у нас получилась такая конфигурация.
Модели было две. Первая прослушивает человека и выдает ответ, после чего вторая начинает слушать ответ первой и выдает свою партию. Забавный момент был, когда мы их связали в луп(первая слушает вторую и так по кругу). Мы ушли на обед, и вернулись где-то через час, и они уже вовсю вошли в раж друг с другом, если можно так сказать. Полу-транс, полу-нечто, но местами интересно и забавно.
Человек наигрывает на drum-pad (Ableton Push2) пример ритма, модель, все это время принимает MIDI сигналы на вход и затем, после окончания примера, через какое то время выдает ответ. Причем мы заметили, что чем дольше наигрываешь и выставляешь длину прослушиваемых участков, тем более осмысленным является ответ. Видимо это связанно с тем самым внутренним состоянием. Я не могу пока полностью обьяснить и себе тоже, почему в начале сеть выдает варианты с log-likelihood -70, но со временем это значение падает до -150, -400, даже -750. Чем это значение ниже, тем выше максимальное правдоподобие результата. То есть минимизация log-likelihood, это тоже самое что максимизация функции максимального правдоподобия. На слух это выражается, что модель, как будто бы сыгрывается, и входит в раж. То есть понятно, что у модели есть внутреннее состояние, которое зависит от предыдущего контекста, но со временем оно сходится к лучшим генерированным последовательностям.
В процессе.

Начало выглядело примерно так.
Это самые первые шаги и тестирование различных вариантов связывания моделей.
Но первая реальная репетиция с живыми людьми была в момент, когда мы решили все запечатлеть на видео. Компания Playtech предоставила нам для этого офисные помещения, и в этом было что-то. За окном — аэропорт с взлетающими самолетами, 10 этаж, вечер, пустой офис, звук басов пробирающий до костей. Огромное спасибо Николаю Алхазову за его помощь и работу, без него это видео бы не получилось. Сложность была в том, что поскольку со стороны моделей это была каждый раз импровизация, то каждый дубль был не похож на предыдущие, и это добавляло интриги. И да, хороший какао спасал жизнь.

Ритм секция выдается нейронными сетями. В разные моменты Александр наигрывает затравку ритмов, и далее уже разворачивается цепочка импровизаций.
Поскольку для Александра было важно, что происходит в моделях в каждый конкретный момент, то очень удачно пригодился Magenta web интерфейс, который позволяет через браузер видеть и менять параметры сети. В видео он бежит сбоку, как тетрис.
С каждым разом результаты все лучше и лучше. Если взять видео, управляемое MIDI сигналами, то можно теоретически связывать сети с видео и музыкой, и синхронизировать их между собой. Пространство для дальнейших поисков достаточно велико, как и вариантов использования. Можно связывать модели друг с другом, создавать петли, и получать неожиданные и подчас интересные варианты.
А, тут, сегодняшнее интервью на местном телевидении.
Это был очень интересный и необычный опыт. И есть мысли для дальнейшего направления.
Я хотел бы поблагодарить всех людей участвовавших в проекте.
Почему бы и нет, действительно. Появился и повод: сделать небольшой перфоманс на открытии конференции TopConf.
Привет, меня зовут Александр Тавген. Я Архитектор в компании Playtech, и мне нравится по прежнему играть в конструктор. Правда конструктор немного усложнился.
Я предложил попробовать связать музыку и машину Александру Жеделёву aka Faershtein, композитору и музыкальному продюсеру Русского Tеатра Эстонии. Вернее, проекту MODULSHTEIN (Александр Жеделёв, Мартен Альтров и Алексей Семинихин). У меня давно уже подспудно витали мысли попробовать обьединить MIDI и char-based модели. Нас очень здорово поддержала компания Playtech, за что ей огромная благодарность. У нас было порядка двух месяцев, чтобы реализовать нашу попытку. И это очень мало, учитывая, что мы живем в разных городах и работаем по основным родам деятельности.
В этом плане, известная статья Andrej Karpathy — это отличное введение в принципы, стоящие за рекуррентными нейронными сетями, и там отличные примеры. Чего стоит одна только сеть, натренированная на исходном коде Linux. Или модель, натренированная на речах Дональда Трампа, о чем я писал весной.
Если взять в общем, то рекуррентные нейронные сети показывают вполне удовлетворительные результаты для временных данных с некой структурой.
Возьмем язык. Структура языка имеет несколько измерений. Одно из них семантическое, к которому машины только подбираются. К примеру, аргумент «Китайской комнаты» Сёрла уже не выглядит таким убедительным по отношению к Мультимодальному Обучению.
Другое измерение, синтаксическое, уже вполне по силам. Рекуррентные нейронные сети учитывают предыдущий контекст и могут хранить состояние. И это было забавно наблюдать на практике, но об этом ниже. Мы можем скормить модели большое количество текста и попросить предсказать вероятность получения следующих букв. К примеру, после букв 'I lov', с очень большой вероятностью будет идти 'е', но после букв 'I love ', уже не очевидно — может быть и 'y', 'h' или иная.
Музыка, как правило, имеет некую структуру. Это ритм, интервалы, динамика. Если моделировать музыкальную последовательность как набор неких символов, то рекуррентные нейронные сети подходят для этого отлично. MIDI формат файлов подходит для этого идеально. Пока я думал как это можно сделать, и присматривался к MIDI библиотекам на Питоне, я наткнулся на проект Magenta.
По сути, Magenta предоставляет MIDI интерфейс для моделей TensorFlow. Создаются виртуальные MIDI порты для call-response, грубо говоря — входа и выхода. Можно запускать несколько параллельных портов. К каждой паре портов можно подсоединить модель TensorFlow. Так называемый bundle файл — это checkpoint тренинга и метаданные графа из TensorFlow. Кратко процесс взаимодействия можно описать так.
Сигналы проходят через MIDI интерфейс, и преобразуются в формат NoteSequence. Это protocol buffers формат для обмена данными с моделями. Данные для тренинга можно скачать отсюда, или взять pretrained модель, и продолжить обучение с нее.
Поначалу я думал вести тренинг с нуля, но во-первых были проблемы с объемом данных для тренинга, а во-вторых, когда я пробовал запустить Magenta на Амазоне, на instance с GPU, там возникли проблемы с зависанием на разных этапах тренинга. Проблемы были с объемом данных для тренинга с нуля, а тренировать на том же dataset, на каком натренированы модели в репозитории Magenta не имеет смысла. Поэтому я продолжил с их checkpointa. Я накачал кучу музыки с ломанными ритмами. От Prodigy — Outer of Space и Goldie — Inner City Life до Massive Attack.
На Magenta Project Github, уже есть инструменты для извлечения разных секций, таких как ударных и мелодий из подготовленных последовательностей нот. LSTM рекуррентная сеть была использована, 2 слоя по 128 элементов, 2 последних бара принимались в расчет. Время тренинга порядка 4 дней на лаптопе. Впрочем градиент спускался очень медленно, и я не могу сказать, был ли это в конце спуск, или осцилляция вокруг локального минимума.
Теперь перейдем к тому, как это все было связано дальше. Checkpoints были связаны в bundle файл, и две модели загружались на старте, каждая из которых — со своей парой виртуальных портов. Назовем их magenta_in/out 1 и 2. Теперь надо все это связать с живыми музыкантами. Александр Жедёлев использовал Ableton как универсальный клей.
На сайте проекте Magenta есть пример, как связывать Ableton с помощью MaxMSP, но этот вариант отпал, так как MaxMSP аварийно завершал работу и вылетал. Если что-то можно выкинуть из системы без помехи для работы, то смело выкидывайте.
Александр Жеделёв колдовал с Ableton. У нас были небольшие проблемы с общей синхронизацией Magenta and Ableton через midi_clock. В конце концов у нас получилась такая конфигурация.
Модели было две. Первая прослушивает человека и выдает ответ, после чего вторая начинает слушать ответ первой и выдает свою партию. Забавный момент был, когда мы их связали в луп(первая слушает вторую и так по кругу). Мы ушли на обед, и вернулись где-то через час, и они уже вовсю вошли в раж друг с другом, если можно так сказать. Полу-транс, полу-нечто, но местами интересно и забавно.
Человек наигрывает на drum-pad (Ableton Push2) пример ритма, модель, все это время принимает MIDI сигналы на вход и затем, после окончания примера, через какое то время выдает ответ. Причем мы заметили, что чем дольше наигрываешь и выставляешь длину прослушиваемых участков, тем более осмысленным является ответ. Видимо это связанно с тем самым внутренним состоянием. Я не могу пока полностью обьяснить и себе тоже, почему в начале сеть выдает варианты с log-likelihood -70, но со временем это значение падает до -150, -400, даже -750. Чем это значение ниже, тем выше максимальное правдоподобие результата. То есть минимизация log-likelihood, это тоже самое что максимизация функции максимального правдоподобия. На слух это выражается, что модель, как будто бы сыгрывается, и входит в раж. То есть понятно, что у модели есть внутреннее состояние, которое зависит от предыдущего контекста, но со временем оно сходится к лучшим генерированным последовательностям.
В процессе.
Начало выглядело примерно так.
Это самые первые шаги и тестирование различных вариантов связывания моделей.
Но первая реальная репетиция с живыми людьми была в момент, когда мы решили все запечатлеть на видео. Компания Playtech предоставила нам для этого офисные помещения, и в этом было что-то. За окном — аэропорт с взлетающими самолетами, 10 этаж, вечер, пустой офис, звук басов пробирающий до костей. Огромное спасибо Николаю Алхазову за его помощь и работу, без него это видео бы не получилось. Сложность была в том, что поскольку со стороны моделей это была каждый раз импровизация, то каждый дубль был не похож на предыдущие, и это добавляло интриги. И да, хороший какао спасал жизнь.
Ритм секция выдается нейронными сетями. В разные моменты Александр наигрывает затравку ритмов, и далее уже разворачивается цепочка импровизаций.
Поскольку для Александра было важно, что происходит в моделях в каждый конкретный момент, то очень удачно пригодился Magenta web интерфейс, который позволяет через браузер видеть и менять параметры сети. В видео он бежит сбоку, как тетрис.
С каждым разом результаты все лучше и лучше. Если взять видео, управляемое MIDI сигналами, то можно теоретически связывать сети с видео и музыкой, и синхронизировать их между собой. Пространство для дальнейших поисков достаточно велико, как и вариантов использования. Можно связывать модели друг с другом, создавать петли, и получать неожиданные и подчас интересные варианты.
А, тут, сегодняшнее интервью на местном телевидении.
Это был очень интересный и необычный опыт. И есть мысли для дальнейшего направления.
Я хотел бы поблагодарить всех людей участвовавших в проекте.
- Aleksandr Zedeljov aka Faershtein
- Marten Altrov — MODULSHTEIN
- Aleksej Semenihhin — MODULSHTEIN
- Nikolay Alhazov, for making this videos real
- Katrin Kvade, sound engineering
- Playtech company
- Marianne Voime and Ergo Joepere personally for their support and help