
От переводчика
В данном исследовании авторы раскрывают интересную технику эксплуатации переполнения памяти кучи. Разумеется, данная уязвимость давно исправлена, но сама представленная техника очень интересна, а процесс переполнения довольно детально расписан.
Если вам интересна информационная безопасность и вы хотели бы понять как происходят переполнения, которые то и дело мелькают в сводках новостей, исследование вам понравится.
Предисловие
В этой статье представлен новый метод эксплуатации переполнения кучи (heap
overflows) в интерпретаторах JavaScript. Вкратце, для получения heap
overflow можно использовать команды JavaScript для обеспечения надежного отображения указателя функции сразу после переполнения буфера. В данном учебном исследовании используется техника для Safari, которую авторы использовали для победы в конкурсе CanSecWest 2008 Pwn2Own.
Введение
Многие уязвимости, связанные с переполнением буфера и целого числа, позволяют записать несколько произвольных значений при относительном смещении к указателю на кучу. К сожалению для атакующего, часто данные, следующие за указателем, непредсказуемы, что делает эксплуатацию трудной и ненадежной. При идеальном выполнении heap overflows атакующий получает полный контроль над количеством и значениями переполненных байтов, и это часто практически невыполнимо, если ничего интересного и предсказуемого не ждет перезапись.
Благодаря защите безопасного освобождения структуры метаданных, кучи все чаще не являются интересной целью для переполнения. В настоящее время в качестве цели переполнения необходимы такие данные, для которых нормальное исполнение программы приводит к вызову указателя функции, который был перезаписан с указателем на код атакующего. Однако такие эксплуатации никоим образом не гарантируют надежность. Для успешного переполнения, указатели, которые еще не доступны, должны находиться в куче после переполненного буфера, и между ними не должно быть других критических данных или немаркированной памяти, разрушение которых приведет к преждевременному сбою. Такие идеальные условия, безусловно, это редкость для любого приложения.
Однако, учитывая доступ к скриптовому языку на стороне клиента, например JavaScript, злоумышленник может создать эти идеальные условия для уязвимостей в таких приложениях, как веб-браузеры. В статье (Sotirov, A. Heap Feng Shui in JavaScript. Blackhat Europe 2007) Sotirov описывает, как использовать распределения JavaScript в Internet Explorer, чтобы позволить атакующему контролировать целевую кучу. В этой статье мы описываем новую технику, вдохновленную его кучей фэн-шуй (Heap Feng Shui), которую можно использовать для надежного позиционирования.
2 Техника
2.1 Контекст
В широком смысле этот метод можно использовать для разработки клиентских эксплойтов против веб-браузеров, которые используют JavaScript. В этом контексте злоумышленник создает веб-страницу, содержащую (среди прочего) команды JavaScript, и побуждает жертву загрузить страницу в браузере. Используя определенные команды JavaScript, злоумышленник влияет на состояние кучи в процессе браузера жертвы, чтобы организовать успешную атаку.
В дальнейшем, мы будем иметь в виду, что буфер, который переполнен — это уязвимый буфер. Для достижения heap overflow, размещение и переполнение уязвимого буфера должны запускаться в интерпретаторе JavaScript. В частности, этот метод не будет применяться в ситуациях, когда уязвимый буфер уже был выделен до того, как интерпретатор JavaScript был создан.
Мы также предполагаем, что шеллкод доступен, и механизм его загрузки в память уже найден. Это тривиально с JavaScript — просто загрузите его в большую строку.
2.2 Обзор
Имейте в виду, что целью является управление буфером в куче сразу после уязвимого буфера. Мы достигнем этого, организовав кучу, в которой все дыры достаточно велики для хранения уязвимого буфера, и окружены буферами, которыми мы управляем.
Техника состоит из пяти этапов.
1. Дефрагментация кучи.
2. Создание отверстия в куче.
3. Подготовление блоков вокруг отверстий.
4. Выделение и переполнение триггера.
5. Запуск перехода к шеллкоду.
Эти шаги описаны более подробно в остальных частях этого раздела.
2.3 Дефрагментация
Состояние кучи процесса зависит от истории распределения и освобождения памяти, которые произошли во время жизни процесса. Следовательно, состояние кучи для продолжительного многопоточного процесса (например, веб-браузера) непредсказуемо. Как правило, такая куча фрагментирована тем, что в ней много отверстий свободной памяти. Наличие отверстий различной величины свободной памяти означает, что адреса последовательных распределений буферов одинакового размера вряд ли будут иметь надежные отношения. На рисунке 1 показано, как может выглядеть распределение в фрагментированной куче:

Рисунок 1. Фрагментированная куча.
Поскольку невозможно предсказать, где эти дыры могут возникать в куче, которая использовалась в течение некоторого времени, невозможно предсказать, где произойдет следующее распределение.
Однако, если у нас есть некоторый контроль над целевым приложением, мы можем заставить приложение сделать много распределений любого заданного размера. В частности, мы можем сделать много распределений, которые по существу заполнят все дыры. Как только отверстия заполняются, то есть куча дефрагментирована, распределения аналогичного размера будут, как правило, предсказуемо близкими друг к другу, как на рисунке 2:

Рисунок 2. Дефрагментированная куча. Будущие ассигнования оказываются смежными.
Мы подчеркиваем, что дефрагментация всегда относится к определенному размеру буфера. При подготовке к эксплуатации уязвимости мы должны дефрагментировать кучу в отношении размера уязвимого буфера. Размер этого буфера будет отличаться, но он должен быть известен. Как показано на рисунке 2, настройка для дефрагментации очень проста в JavaScript.
Например:
var bigdummy = new Array(1000);
for(i=0; i<1000; i++){
bigdummy[i] = new Array(size);
}
В приведенном выше фрагменте кода каждый вызов new Array(size) приводит к распределению 4*size+8 байтов в куче. Это распределение соответствует объекту ArrayStorage, состоящему из восьмибайтового заголовка, за которым следует массив указателей size. Изначально все распределения обнуляются. Значение size должно быть выбрано так, чтобы результирующие распределения были как можно ближе к size и не меньше, чем размер уязвимого буфера. Значение 1000, указанное выше, было определено эмпирически.
2.4 Сделать отверстия
Помните, что наша цель — достигнуть контроля над буфером, который следует за уязвимым буфером. Предполагая, что дефрагментация сработала, у нас должно быть несколько смежных буферов в конце кучи, примерно того же размера, что и уязвимый буфер (еще не выделенный) (рис. 3):

Рис 3. Дефрагментированная куча с множеством распределений. Мы видим длинную строку буферов одинакового размера, которые мы контролируем.
Следующий шаг — освободить все остальные из этих смежных буферов, оставив чередующиеся буферы и отверстия, которые соответствуют размеру уязвимого буфера.
Первым шагом в достижении этого является следующий код:
for (i=900; i<1000; i+=2){
delete(bigdummy[i]);
}
Нижний предел в цикле for основан на предположении, что после 900 распределений на этапе дефрагментации мы достигли точки, где все последующие распределения происходят смежно в конце кучи.
К сожалению, на данном этапе у нас есть проблема. Простое удаление объекта в JavaScript не сразу приводит к тому, что пространство объекта в куче будет освобождено. Пространство в куче не очищается, пока не произойдет сбор мусора. Internet Explorer предоставляет метод CollectGarbage (), который сразу же запускает сборку мусора, но другие реализации браузеров этого не делают. В частности, WebKit этого не делает. Поэтому, мы отвлечемся на обсуждения сборки мусора в WebKit.
Наша проверка исходного кода WebKit показала что есть три основных события, которые могут инициировать сбор мусора. Чтобы понять эти события, нужно быть знакомым с тем, как JavaScript-код в WebKit управляет объектами.
Реализация поддерживает две структуры: primaryHeap и numberHeap, каждая из которых представляет собой массив указателей на объекты CollectorBlock. CollectorBlock — это массив ячеек фиксированных размеров, и каждая ячейка может содержать объект JSCell (или производную). Каждый объект JavaScript занимает ячейку в одной из этих куч. Большие объекты (такие как массивы и строки) занимают дополнительную память в системной куче. Мы ссылаемся на эту дополнительную память системы как на связанное хранилище.
Каждый CollectorBlock поддерживает связанный список свободных ячеек. Когда запрашивается выделение и нет свободных ячеек в любых существующих CollectorBlocks, выделяется новый CollectorBlock.
Все объекты JavaScript, полученные из JSObject, выделяются в primaryHeap. numberHeap зарезервировано для объектов NumberImp. Обратите внимание, что последние не соответствуют объектам JavaScript Number, но, как правило, представляют собой объекты с коротким замыканием, соответствующие промежуточным арифметическим вычислениям.
Когда запускается сбор мусора, обе кучи проверяются на объекты с нулевым количеством ссылок, и такие объекты (и связанное с ними хранилище, если они есть) освобождаются.
Теперь мы возвращаемся к трем найденным событиям, которые запускают сборку мусора:
1. Истечение выделенного таймера сбора мусора.
2. Запрос на распределение, который возникает, когда все отдельные блоки CollectorBlocks кучи заполнены.
3. Выделение объекта с достаточно большим связанным хранилищем (или нескольких таких объектов).
Первое из этих событий не очень полезно, т.к. JavaScript не имеет режима ожидания, и любая заметная задержка в скрипте может привести к появлению диалогового окна «Медленный сценарий».
Последнее из этих событий зависит от количества объектов в primaryHeap и размера их связанного хранилища. Эксперименты показывают, что состояние primaryHeap сильно варьируется в зависимости от количества открытых в браузере веб-страниц и степени, в которой эти страницы используют JavaScript. Следовательно, надежный запуск сборки мусора с этим событием затруднен.
С другой стороны, numberHeap, по-видимому, относительно нечувствителен к этим изменениям. Как показывают исследования, numberHeap поддерживает только один выделенный CollectorBlock, даже при значительном просмотре страниц с JavaScript. Поскольку numberHeap CollectorBlock имеет 4062 Ячейки, JavaScript-код, который создает много NumberImps (выполняет много арифметических операций с промежуточными вычислениями), должен инициировать сбор мусора. В качестве примера, манипулирование числами двойной точности (doubles) — это та операция, которая приводит к присвоению NumberImp из numberHeap, поэтому следующий JavaScript код может использоваться для запуска сбора мусора:
for (i=0; i<4100; i++) {
a = .5;
}
После завершения этого кода куча должна выглядеть так, как на рисунке 4, и мы готовы к следующему шагу:
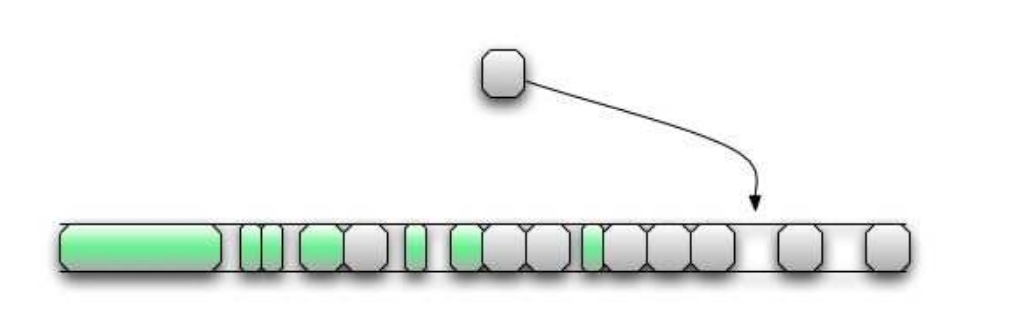
Рис 4. Управляемая куча со всеми освобожденными буферами. Выделение уязвимого буфера заканчивается в одном из отверстий.
2.5 Подготовка блоков.
Этот шаг прост. Мы используем следующий JavaScript:
for (i=901; i<1000; i+=2) {
bigdummy[i][0] = new Number(i);
}
Код bigdummy [i] [0] = new Number (i) создает новый объект NumberInstance и сохраняет указатель на этот объект в объекте ArrayStorage, соответствующем bigdummy [i]. На рисунке 5 изображена часть кучи после запуска JavaScript:
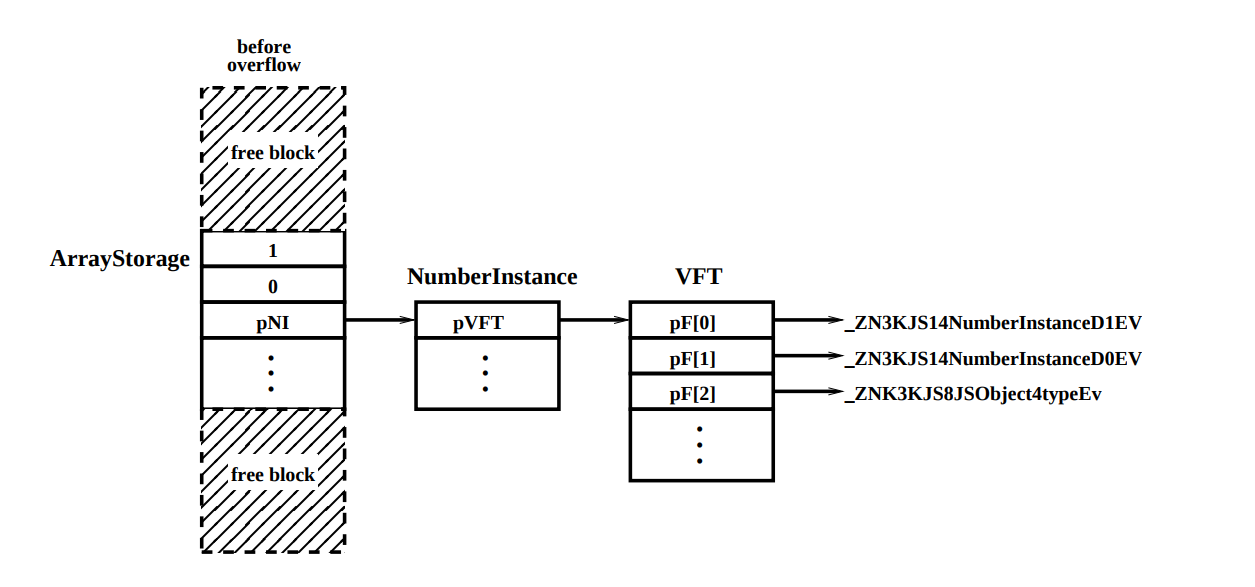
Рис 5. Подробная информация о блоке, который контролирует атакующий, непосредственно перед запуском переполнения.
2.6. Запуск перераспределения и переполнения.
Теперь пришло время выделить уязвимый буфер. Если предыдущие шаги прошли, как и ожидалось, распределение для уязвимого буфера окажется в одном из отверстий, которые мы создали, и мы готовы к переполнению. Объектом переполнения является перезапись указателя pNI в объекте ArrayStorage, который следует за уязвимым буфером. Новое значение должно быть адресом в sled для шеллкода. Подробности о sled будут обсуждаться ниже, но пока обратите внимание, что типичные sled NOP (https://en.wikipedia.org/wiki/NOP_slide) здесь не подходят. После выделения и переполнения, куча должна выглядеть так, как показано на рисунке 6:
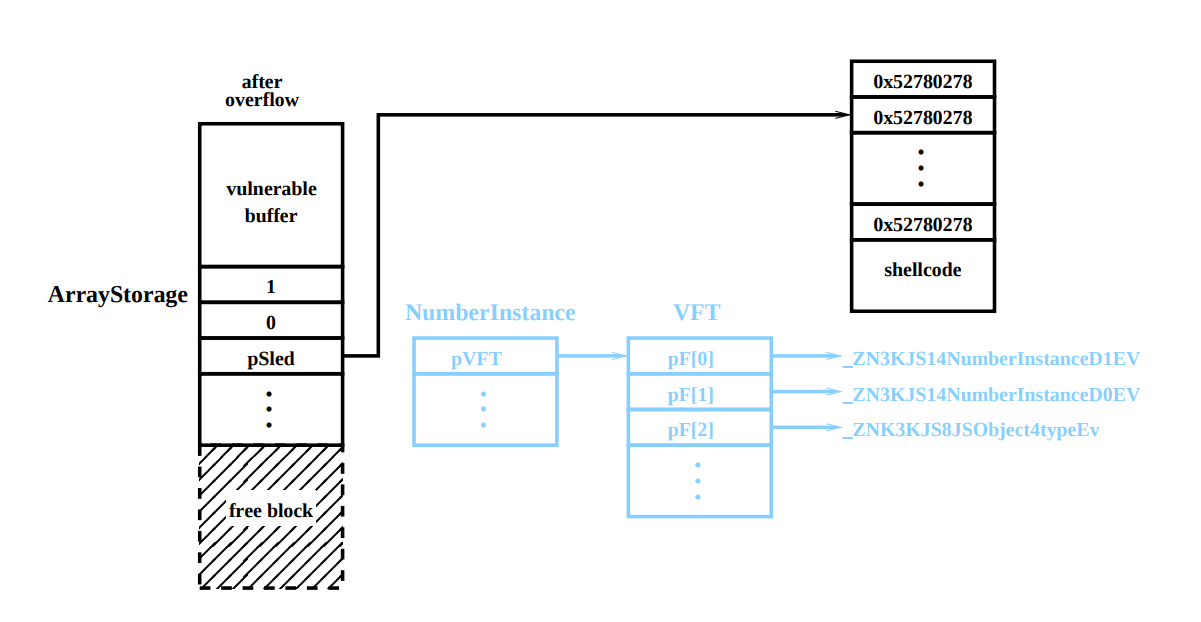
Рис 6. Информация о блоке, контролируемом атакующим сразу после запуска переполнения.
2.7 Запуск перехода к шеллкоду
Переход к шеллкоду выполняется простым взаимодействием с объектами Number, созданными при подготовке блоков выше. А конкретнее, нам нужно принудительно вызвать виртуальный метод базового объекта NumberInstance в реализации JavaScript. Для блоков, которые не были перезаписаны, выполнение переносится в * ((* pNI) + 4 * k), где k — это индекс метода в таблице виртуальных функций, которая вызывается. Для блока, который сразу следует за уязвимым буфером, выполнение переносится на * ((* pSled) + 4 * k). Это двойное разыменование pSled немного раздражает, но приведенное ниже тематическое исследование показывает простой способ борьбы с ним.
Следующий JavaScript производит вызов виртуальной функции для каждого объекта NumberInstance и тем самым запускает выполнение shellcode.
for (i=901; i<1000; i+=2) {
document.write(bigdummy[i][0] + "<br />");
}
3. Пример из практики
Наши исследования в области надежной работы с кучей JavaScript были мотивированы уязвимостью, которую мы обнаружили в анализе PCRE (Perl-Compatible Regular Expression) WebKit. Это было переполнение целого числа, которое допускало произвольный размер переполнения за буфером, содержащим скомпилированное регулярное выражение, которое может быть любого размера вплоть до 65535 байт. Однако переполнение произошло очень скоро после выделения буфера, так что мы часто сталкивались с нераспределенной памятью во время переполнения. В других случаях мы переписывали важные данные, но казалось совершенно непредсказуемым, какие данные там были изменены между прогонами. Техника, описанная в разделе 2, решила эти проблемы для нас и позволила обеспечить надежную эксплуатацию.
Сначала нам нужно было дефрагментировать кучу для целевого размера около 4000 байт. Следующий вывод отладчика показывает, как нужно использовать первые несколько распределений для дефрагментации кучи (обратите внимание на прыжок вокруг адресов распределения):
Breakpoint 3, 0x95850389 in KJS::ArrayInstance::ArrayInstance () array buffer at$1 = 0x16278c78
Breakpoint 3, 0x95850389 in KJS::ArrayInstance::ArrayInstance () array buffer at$2 = 0x50d000
Breakpoint 3, 0x95850389 in KJS::ArrayInstance::ArrayInstance () array buffer at$3 = 0x510000
Breakpoint 3, 0x95850389 in KJS::ArrayInstance::ArrayInstance () array buffer at$4 = 0x16155000
Breakpoint 3, 0x95850389 in KJS::ArrayInstance::ArrayInstance () array buffer at$5 = 0x1647b000
Breakpoint 3, 0x95850389 in KJS::ArrayInstance::ArrayInstance () array buffer at$6 = 0x1650f000
Breakpoint 3, 0x95850389 in KJS::ArrayInstance::ArrayInstance () array buffer at$7 = 0x5ac000
К тому времени, когда мы выполнили почти 1000 распределений, куча начинает выглядеть вполне предсказуемой, и все распределения в конечном итоге смежны
Breakpoint 3, 0x95850389 in KJS::ArrayInstance::ArrayInstance () array buffer at$997 = 0x17164000
Breakpoint 3, 0x95850389 in KJS::ArrayInstance::ArrayInstance () array buffer at$998 = 0x17165000
Breakpoint 3, 0x95850389 in KJS::ArrayInstance::ArrayInstance () array buffer at$999 = 0x17166000
Breakpoint 3, 0x95850389 in KJS::ArrayInstance::ArrayInstance () array buffer at$1000 = 0x17167000
Breakpoint 3, 0x95850389 in KJS::ArrayInstance::ArrayInstance () array buffer at$1001 = 0x17168000
Breakpoint 3, 0x95850389 in KJS::ArrayInstance::ArrayInstance () array buffer at$1002 = 0x17169000
Освободив кучу отверстий в конце, используя технику сбора мусора, описанную в Разделе 2.4, мы видим, что уязвимый буфер высаживается в последнем отверстии на 0x17168000, прямо перед данными, которые мы контролируем на 0x17169000.
Breakpoint 2, 0x95846748 in jsRegExpCompile () regex buffer at$1004 = 0x17168000
Поэтому мы переполним наш буфер регулярных выражений в данные ArrayStorage. Байты переполнения должны быть скомпилированы в байт регулярного выражения. К счастью, конструкция класса символов регулярного выражения допускает практически произвольные байты в скомпилированной форме, поскольку она компилируется в 33 байта, последние 32 из которых составляют массив с 256-битным битом, где бит, установленный в один, означает, что этот символ находится в классе. Таким образом, мы используем класс символов [\ x00 \ x59 \ x5c \ x5e] и устраиваем их в начале данных ArrayStorage, так как первые 3 слова его скомпилированного битового класса являются ненулевым dword, zero dword, и адресом в нашей куче, а именно:
0x00000001 0x00000000 0x52000000Наконец, мы используем специально созданный адрес в куче, используя большую строку dword 0x52780278, за которой следует шеллкод. Мы организуем распределение распыления, чтобы этот адрес находился в рамках необходимого нам. Затем, когда это интерпретируется как инструкция после начала выполнения, она становится условными переходами:
78 02: js +0x2
78 52: js +0x52
которые являются эффективным NOP независимо от значения условия перехода: если условие истинно, скачок из двух берется в начало следующей команды, а если условие ложно, это также неверно для скачка 0x52. Это означает самый значительный байт, когда определение адреса распыления кучи полностью не используется в sled, а также выравнивается по 4 байт.
4. Выводы
Методика, описанная в этой статье, позволила обеспечить надежную эксплуатацию переполнения буфера, которая изначально не имела предсказуемых и интересных данных для перезаписи. Пока атакующему необходим некоторый контроль над системой, такой как размер распределения, размер переполнения и данные переполнения, этот метод должен применяться к другим уязвимостям браузера, когда атакующий имеет доступ к JavaScript. Мы подозреваем, что подобные методы могут быть применимы при работе с другими клиентским скриптовым языками.