
В этой статье я расскажу о том, как настраивал непрерывную интеграцию в Amazon AWS для репозитория DevExtreme.
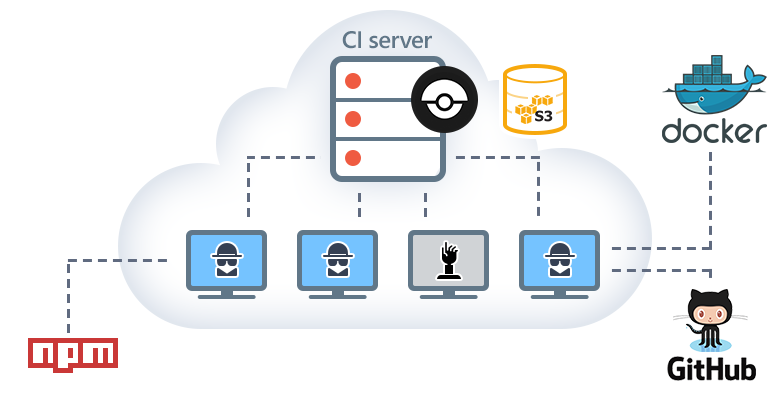
Уже несколько месяцев мы ведём разработку DevExtreme в открытом репозитории на GitHub. Непрерывная интеграция у нас с самого начала была построена на базе Docker, чтобы не зависеть от CI-платформы (будь то Travis, Shippable или что-то другое), но с момента публикации репозитория мы не выделялись и использовали для прогона тестов хорошо знакомый Travis CI. На GitHub у нас "бегает" только небольшая часть автоматических тестов, так сказать, первая линия, и возможностей Travis для техники Fork and Pull Request хватало.
Со временем коллеги начали сетовать на очередь из пулл-реквестов (но терпели). Мысль о том, что пора уже что-то предпринять, возникла в конце октября, когда на два дня Travis потерял связь с Docker Hub, а мы как раз готовились к beta-релизу DevExtreme 17.2.
Получив добро на эксперименты в корпоративном AWS-аккаунте, я решил дать второй шанс проекту Drone. Почему второй? Потому что мы его уже пробовали в процессе "обкатки выхода на GitHub". Тогда наш репозиторий был приватным, Drone был ещё более сырым, чем сегодня, и запускали мы его на временной наколеночной инфраструктуре, точнее на старых рабочих станциях, оставшихся после апгрейда рабочих мест (наш IT-отдел обещал их вот-вот забрать, но не торопился).
В итоге удалось поднять эластичную CI-инфраструктуру на спотовых инстансах, доступную по красивому адресу https://devextreme-ci.devexpress.com/DevExpress/DevExtreme:

Наработки я опубликовал и теперь хочу поделиться полученным в процессе опытом.
Два слова о Drone
Сам Drone неплохо описан на Хабре. Эта такая система непрерывной интеграции на Go, в которой Докер снизу, Докер сверху и Докер Докером погоняет. В 570-м выпуске Радио-Т Умпутун (известный любитель Докера) сказал про Drone: "Простой как железная дорога. Его простота — на грани, когда она хуже воровства."
Архитектура Drone типична для CI-платформы:
- Есть сервер. Он предоставляет web-интерфейс, слушает веб-хуки и управляет очередью задач.
- Можно запустить произвольное количество агентов, которые сами находят сервер, на которых происходит, собственно, интеграция.
- Docker везде. В этом есть и плюсы, и минусы. Например, если наступите на грабли на стыке Drone и Docker, то весёлое времяпрепровождение гарантировано.
Внутри AWS
Всё началось с небольшого инстанса t2.micro, на котором был запущен Drone-сервер.
А для агентов была заведена группа авто-масштабирования (далее буду называть её ASG). Хотелось держать агенты включенными только тогда, когда для них есть работа. Это особенно привлекательно в свете того, что с недавних пор в EC2 посекундная тарификация.
Scaler
Интересное началось, когда возник вопрос "как управлять ёмкостью ASG". Стандартные средства из разряда "добавь, если возросла нагрузка на процессор", не подходят. Нужно следить за очередью Drone, добавлять агентов, когда очередь растёт, и мягко их выключать, когда очередь рассасывается.
Для этого была написана утилита под кодовым именем scaler. На .NET Core (не могу удержаться от C#, когда есть такая возможность).
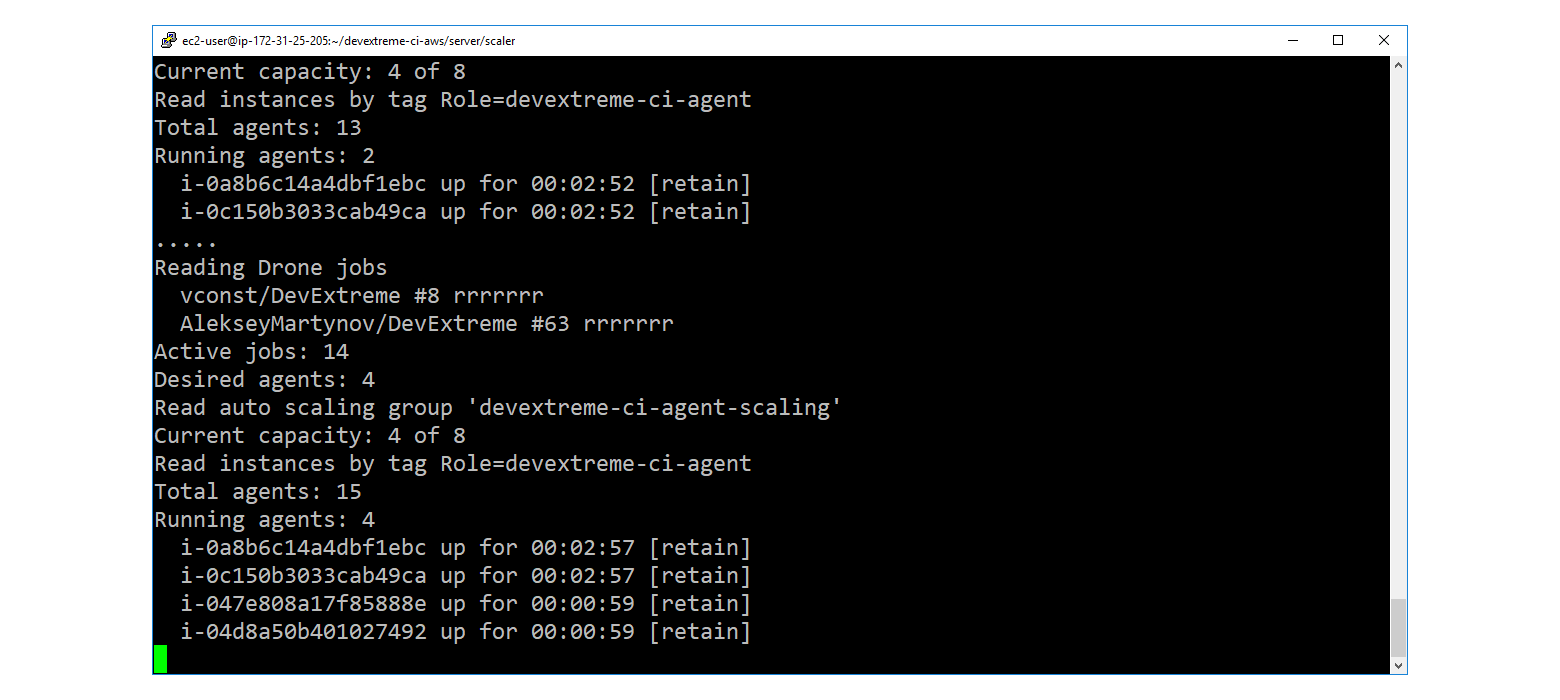
Scaler реализует следующий нехитрый цикл:
- Через Drone REST API читаем очередь.
- Если сумма running + pending превышает число запущенных агентов, помноженное на коэффициент плотности "jobs per agent", то через AWS REST API наращиваем ёмкость (до определенного предела).
- Если наоборот, то отправляем самым старым агентам запрос на мягкое завершение.
Основной нюанс заключается в том, что нельзя просто так взять и уменьшить ёмкость. Если это сделать, то инстансы агентов могут быть погашены, пока те ещё заняты, и это приведёт к негативным последствиям вплоть до образования так называемых zombie builds.
В связи с этим, ASG запускает инстансы с защитой от выключения (Protect From Scale In), и ёмкость никогда явно не уменьшается. Как только агент становится кандидатом на выбывание, scaler исключает его из группы (detach) и отправляет через SSM вот такую последовательность команд. Сигнал SIGINT даёт агенту понять, что не следует брать новых задач, следует дождаться завершения уже имеющихся, а после этого выйти. Таким образом, агент уходит в сторонку, мирно доделывает свои дела и выключается. Исключение из группы делается с выставленным флагом уменьшения ёмкости, благодаря этому ASG сразу готова к добавлению новых агентов, если очередь начнет наполняться.
Кроме управления ёмкостью ASG, scaler обвешан дополнительными проверками и костылями:
- Посылает Terminate агентам, находящимся в состоянии Stopped.
- Гасит агентов, которые по каким-то причинам живут подозрительно долго.
- Гасит агентов, у которых давно не проходит reachability check.
- Следит за образованием зомби на стороне Drone и убивает их (самое весёлое место!)
- Даёт агентам поработать хотя бы несколько минут. Это нужно для того, чтобы соответствующие Spot Requests успели перейти в состояние "fulfilled". В результате обкатки выяснилось, что иногда ASG пытается отменить Spot Request, для которого инстанс уже запущен, но статус ещё не обновлён.
Инстансы: On-Demand vs. Spot
Сначала для агентов использовались обычные (on-demand) инстансы c4.xlarge. На каждом до 4 агентов (из расчёта 1 агент на 1 ядро).
Как только система более-менее зашевелилась, я попробовал в качестве эксперимента конфигурацию с включенной галочкой "Request Spot Instances". Оказалось, что это хорошо работает. Спотовые инстансы всегда есть, и ещё ни разу я не видел, чтобы инстанс "отобрали" (при Spot Price = On-Demand Price).
За их поведением надо будет ещё понаблюдать и, может быть, прикрутить автоматическое переключение между ASG на спотах и ASG на on-demand.
Кэши
Непрерывная интеграция сопряжена с повторяющимся скачиванием одних и тех же Docker-образов и NPM/NuGet-пакетов. Чтобы уменьшить внешний трафик и смягчить периоды недоступности реестров образов и пакетов, я реализовал кэширование в S3.
Для Drone есть готовый плагин drone-s3-cache, но я не стал его использовать, так как не хватило каких-то настроек. Для загрузки/восстановления директорий node_modules и dotnet_packages у нас используется нехитрый скрипт drone-cache.sh.
S3 bucket "devextreme-ci-cache" настроен так, что в него можно анонимно писать изнутри VPC. Это удобно, потому что не нужна возня с секретными ключами. Однако при такой конфигурации архивы оказываются доступны на анонимное чтение. Для кэша пакетов это не страшно, но я не осилил настроить policy так, чтобы чтение было ограничено VPC, и при этом не отобрать права у авторизованных пользователей. Похожие ситуации обсуждаются на StackOverflow здесь и здесь. Если у вас есть идеи/опыт подобной настройки, дайте знать в комментариях!
Архивы в кэше дифференцируется по форку-ветке. Просроченные объекты автоматически удаляются с S3, благодаря настроенному Expiration Lifecycle Rule.
Для кэширования Docker-образов рядом с Drone-сервером работает реестр в режиме pull-through cache с хранением блобов в S3 (конфигурация). Реестр доступен только внутри security-группы для агентов, а сами агенты настроены на использование этого зеркала. Неактивные образы/слои автоматически удаляются из кэша через 7 дней.
HTTPS
Когда стало понятно, что система жизнеспособна, Drone-сервер был спрятан за nginx. Website team любезно выделил нам поддомен "devextreme-ci.devexpress.com", к которому привязали Elastic IP Drone-сервера. Для поддомена я настроил HTTPS через Let's Encrypt с автоматическим продлением.
Промежуточные итоги
Drone в AWS-облаке для репозитория DevExtreme на GitHub работает уже четвёртую неделю. Команда довольна. На вопрос "Ну как вам Дрон?" в основном отвечают "Огонь! Быстрый, не то что усатый" (прим. усатый = Travis). Конечно, ресурсы AWS, в отличие от Travis CI, не бесплатны, и ещё предстоит узнать, во сколько обходится наш новый CI, но [TODO придумать что написать в оправдание всей этой развлекушки].
Если серьёзно, то правда стало приятнее работать. Когда нас прёт и пулл-реквесты льются рекой, мы больше не сидим и не тупим (вы уж поверьте) в ожидании очереди CI. В то же время, стоимость ресурсов AWS напрямую зависит от интенсивности использования. В периоды простоя (например, на новогодних каникулах) работает только один инстанс t2.micro, а агенты выключаются и кэши очищаются. Словом, хочется верить, что мы используем облачные технологии себе во благо.
Пробовали ли вы Drone? Какие впечатления? Разворачивали ли его или другие платформы для непрерывной интеграции в облаках? Расскажите в комментариях!
Комментарии (11)

gred
21.11.2017 17:38я слегка поясню свою мысль.
мы сейчас используем Jenkins, в принципе он всем устраивает, но надоело его конфигурить через вебинтерфейс. очень нравится конфигурирование в стиле Travis/Drone, но Travis — исключительно Github, а Drone — слишком сильно завязан на Docker, что тоже является проблемой для тех проектов, с которыми мы работаем

malinoff
21.11.2017 18:45+1Начиная с некоторой версии Jenkins 1.x (в 2.x установлен по умолчанию) можно (и нужно!) использовать jenkins.io/doc/book/pipeline. Конфигурация абсолютно всех джоб уезжает в git (хотя админить сам Jenkins, к сожалению, не получится таким образом).
gred
21.11.2017 18:56про pipeline — знаю, но тоже не панацея. джобы-то создавать все-равно надо руками
Tonkonozhenko
22.11.2017 01:22Мы создаём джобы через jobdsl plugin, все хранится в гите, разве что иногда надо запускать seed job, которая создаёт другие джобы.

acmnu
22.11.2017 10:44и нужно!
Ой, не факт. Идея то прекрасная, но реализация…
Список притензий:
- Документация бедная. Вот здесь и половина не описана. Надо смотреть код, а если вы не знакомы с java будет тяжело.
- Нет SDK — отлаживать можно только в Jenkins.
- Groovy Sandbox не документирована. Никто не знает, что там конкретно ограничено. Советы, типа отключи security, работают не до конца, ибо есть скрытые ограничения. Опять таки надо смотреть код.
- Поддержка в интерфейсе слабая. Невозможен рестарт с точки падения (но возможна пауза, а это немного другая история).
acmnu
22.11.2017 10:35но надоело его конфигурить через вебинтерфейс
Есть jenkins-job-builder, Job DSL и, как выше сказали, Pipeline.

eugene08
22.11.2017 12:40Нужно следить за очередью Drone, добавлять агентов, когда очередь растёт, и мягко их выключать, когда очередь рассасывается.
Это похоже на оверинжиниринг. Есть смысл собирать свои метрики (например через cloudwatch agent) и настраивать скейлинг полиси на их основе. Для scale-in можно (и нужно) использовать lifecycle hooks.
Для этого была написана утилита под кодовым именем scaler. На .NET Core (не могу удержаться от C#, когда есть такая возможность).
amartynov Автор
22.11.2017 12:48Это похоже на оверинжиниринг.
Зато легко отлаживать. Вначале я запускал этот тул на локальной машине, долго гонял и наблюдал, а потом уже пересадил в облако. Легко добавлять любые дополнительные условия и костыли.
Alex_JK
Мне кажется, что лучше испльзовать instance profile:
EC2 instance < — Instance profile < — IAM role < — IAM policy < — Allow read/write from/to S3 bucket