

В результате я натолкнулся на один очень любопытный материал, который впечатлил меня настолько, что мое желание поделиться им с как можно более широкой аудиторией пересилило
Что мне понравилось в этой статье? В первую очередь — разнообразие предложенных вариантов. Никаких «делайте только так, и будет вам счастье», что частенько можно услышать от евангелистов и консультантов. Здесь — 9 «правильных» и 7 «неправильных» вариантов, которые можно примерить к своей организации, по-разному cкомбинировать и получить если не что-то работоспособное, то по меньшей мере пару идей «на попробовать». Во-вторых, эти истории явно взяты из реального мира «кровавого энтерпрайза» — большинство из них предлагают DevOps-модели не для стартапа из пяти человек, с самого начала делающего всё правильно, а для большой конторы со своим legacy, сложной оргструктурой и запутанными человеческими взаимоотношениями. Ведь как мы знаем из недавнего хита Хабра, даже самые передовые организации становятся похожи друг на друга по достижении определенного размера.
Итак, Matthew Skelton и Manuel Pais, статья Какая структура команд лучше подходит для развития DevOps?. Первая версия появилась еще в 2013 году, с тех пор авторы многое дополнили и переработали.
Анти-типы DevOps-топологий
Всегда полезно иметь представление о плохих практиках, которые мы можем называть «Анти-типами» (а не вездесущим термином «анти-паттерн»)
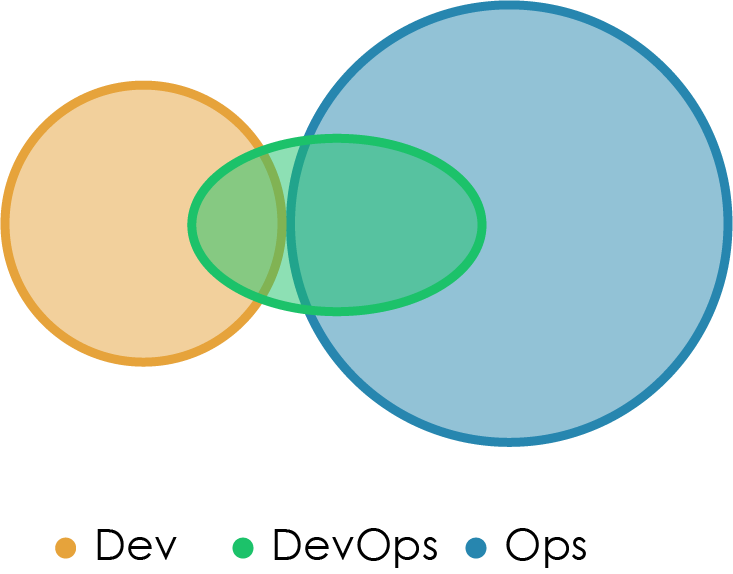
Анти-тип A: Делянки Dev и Ops
Это классическая схема разделения Dev и Ops по принципу «перекинь софт через стенку». На практике для Dev это означает более раннее признание выполнения задач («готово» означает «сделали фичу», а не «работает в бою»), но работоспособность софта страдает из-за того, что Dev не знают, что в реальности происходит в промышленной среде, а Ops не имеют возможности или времени вовлечь Dev в решение проблем, пока новая версия приложения не вышла для пользователей.
Все мы уже слышали, что эта топология — не лучшая, но лично я считаю, что есть варианты еще хуже.

Анти-тип B: Делянка DevOps-команды
Как правило, этот анти-тип возникает, когда некий высокопоставленный менеджер решает, что «нам нужно немного этого DevOps-а» и дает указание создать «DevOps-команду» (возможно даже состоящую из «DevOps-людей»). Такая команда очень быстро выгородит себе отдельную делянку, отодвигая Dev и Ops подальше друг от друга, чтобы каждый из них мог защищать свой угол, навыки и инструменты от этих «криворуких девелоперов» или «тупых админов».
Единственная ситуация, в которой эта модель имеет практический смысл — когда отдельная DevOps-команда создается на ограниченный период времени, максимум на (к примеру) 12-18 месяцев, с изначальной целью сблизить Dev и Ops и с четкой установкой о ликвидации DevOps-команды по истечении этого времени. В этом случае реализуется DevOps-модель, которую я называю Тип 5.

Анти-тип C: Dev-у Ops не нужен
Эта модель возникает из комбинации наивности и самонадеянности разработчиков и их менеджеров, особенно часто — при запуске новых проектов или систем. Предполагая, что IT Ops — это образ из прошлого («у нас же теперь кругом облака, правильно?»), разработчики часто недооценивают сложность и важность операционных навыков и активностей, и начинают верить, что могут существовать без них, либо же выполнять их в «свободное» время.
Анти-тип C с большой вероятностью превратится в Тип 3 (Ops как IaaS) или Тип 4 (DevOps как внешний сервис), когда выпускаемое ПО начнет создавать реальную операционную нагрузку и поглощать время, отведенное на разработку. Только если эта команда осознает важность IT Operations как дисциплины, она сможет избежать болей и необязательных операционных ошибок.

Анти-тип D: DevOps как команда инструменталистов
Чтобы «стать DevOps» без ущерба для текущей производительности разработчиков (т.е. реализации функциональных фич), внутри Dev создается DevOps-команда для обеспечения Dev всем набором инструментов — конвейером разработки, системой управления конфигурациями, подходом к управлению средами и так далее. При этом Ops продолжают работать изолированно, а Dev — «перекидывать ПО через стенку».
Несмотря на то, что DevOps-команда в такой схеме может принести реальную пользу через внедрение инструментов, итоговый эффект будет ограниченным. Остается нерешенной фундаментальная проблема: отсутствие раннего вовлечения Ops и взаимодействия функций в течение всего жизненного цикла софта.

Анти-тип E: Перебрендированные сисадмины
Этот анти-тип характерен для организаций с низкой инженерной зрелостью. Они хотят улучшать практики и снижать затраты, но не способны увидеть в ИТ ключевой фактор успеха для бизнеса. Так как польза DevOps для индустрии (уже) считается очевидной, они тоже хотят «делать DevOps». Увы, вместо того, чтобы решать реальные проблемы в структуре или взаимоотношениях команд, они выбирают ложный путь, нанимая «инженеров DevOps» в Ops-команду.
Термин «DevOps» используется для ребрендинга роли сисадминов, реальных изменений в культуре или организации процессов не происходит. Этот анти-тип становится всё популярнее по мере того, как неразборчивые рекрутеры присоединяются к поискам людей, имеющих навыки автоматизации и работы с инструментами DevOps. В реальности, именно коммуникационные навыки людей позволяют DevOps работать.

Анти-тип F: Ops внутри Dev
Эта организация не хочет иметь отдельной Ops-команды, поэтому Dev-команда несет ответственность за инфраструктуру, управление средами, мониторинг и так далее. При таком подходе в проектах или продуктовых командах операционные задачи становятся жертвами ресурсных ограничений или низких приоритетов, что, в свою очередь, приводит к некачественным, сырым продуктам.
Этот анти-тип демонстрирует недооценку важности роли и навыков эффективных IT Operations.

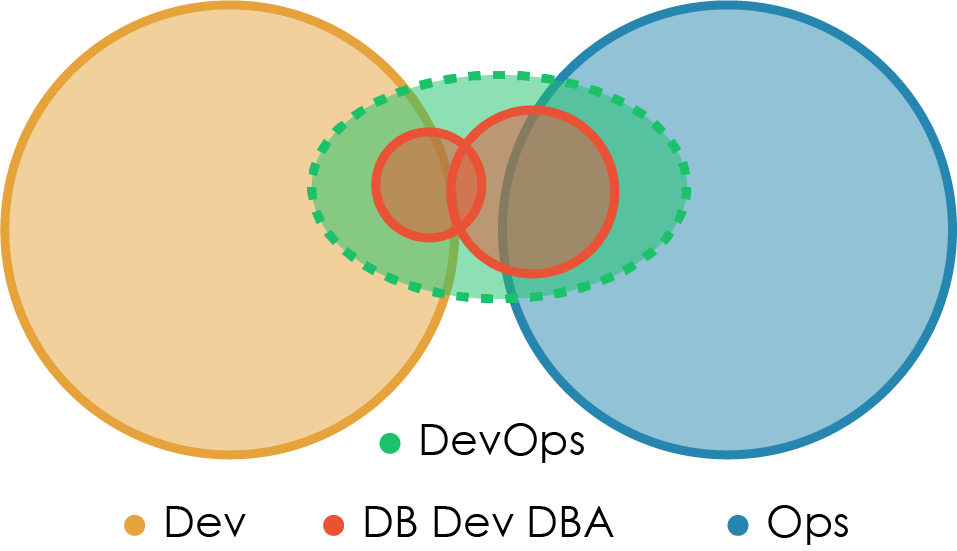
Анти-тип G: Делянки Dev и DBA
Это одна из разновидностей Анти-типа А, которая очень распространена в средних и больших компаниях с многочисленными старыми системами, завязанными на централизованные базы данных. Поскольку эти базы данных критичны для бизнеса, отдельная DBA-команда, обычно в рамках структуры Ops, отвечает за их администрирование, настройку и восстановление при сбоях. Такая схема логична. Но если при этом команда DBA становится стражем границы и тормозит все возможные изменения в базе данных, это становится дополнительным препятствием для регулярных обновлений ПО (ускорение которых является главной целью DevOps).
Более того, если команда DBA не вовлекается в разработку ПО на раннем этапе, все проблемы с миграциями данных, производительностью БД и так далее, обнаруживаются только на поздних стадиях жизненного цикла, что вкупе с большой нагрузкой на администраторов ведет к постоянным пожарам в бою и к усилению давления на DBA.

Типы DevOps-топологий
Поговорив о неудачных вариантах, посмотрим на те модели, которые помогают DevOps работать.
Тип 1: Сотрудничество Dev и Ops
Это та самая «земля обетованная» DevOps: «гладкое» взаимодействие Dev- и Ops-команд, где нужно — применяется специализация, где нужно — команды работают вместе. В этом варианте может быть несколько отдельных Dev-команд, каждая из которых работает над частично независимым продуктом.
По моему мнению, для реализации Типа 1 требуется существенные организационные изменения и высокий уровень компетенции в руководстве ИТ-организации. Dev и Ops должны иметь четко артикулированную, наглядную и понятную общую цель (например, «Поставлять надежные и частые изменения ПО»). Люди из Ops должны чувствовать себя комфортно, работая в паре с разработчиками над вопросами, специфичными для разработки, например разработкой через тестирование (TDD) или версионным контролем. С другой стороны, Dev должны всерьез вовлекаться в операционные проблемы, а также стремиться получать вводные от Ops, разрабатывая новые решения. Всё это требует существенных культурных сдвигов по сравнению с традиционными подходами прошлого.

Применимость Типа 1: организации с сильной технологической составляющей
Потенциальная эффективность: высокая
Тип 2: Полностью совмещенные команды
Когда люди из Ops полностью интегрируются в команды, развивающие продукты, мы получаем топологию Типа 2. В этом случае разница между Dev и Ops настолько минимальна, что все сотрудники полностью сфокусированы на общей цели. В принципе, это одна из разновидностей Типа 1, но со своими особенностями.
Компании типа Netflix или Facebook, которые предоставляют клиентам единственный чисто цифровой продукт, используют топологию Типа 2, но я думаю, что этот подход имеет ограниченную применимость в условиях, когда организация предоставляет клиентам больше одного продукта. Бюджетные ограничения и необходимость переключения контекста, обычно присутствующие в организациях, производящих множественные продукты, может заставить увеличить дистанцию между Dev и Ops (использовать топологию Типа 1).
Тип 2 также может быть назван «NoOps», потому что в этой модели нет отдельной или видимой Ops-команды (хотя модель NoOps в Netflix также похожа на Тип 3 (Ops как IaaS)).

Применимость Типа 2: Организации, предоставляющие один, полностью цифровой продукт
Потенциальная эффективность: высокая
Тип 3: Ops как IaaS (инфраструктура как сервис)
Для организаций с более традиционным подразделением IT Ops, которое не может или не будет быстро меняться, а также для организаций, которые используют для всех своих приложений публичные облака типа Amazon EC2, Azure и тому подобные, может быть полезно относиться к Ops как к команде, которая предоставляет эластичную инфраструктуру, на которой устанавливаются и работают приложения. В этой модели Ops-команда аналогична Amazon EC2, то есть подходу IaaS (инфраструктура как сервис).
При такой схеме внутри Dev работает отдельная команда (возможно, виртуальная), выступающая в роли центра экспертизы по операционным фичам, метрикам, мониторингу, развертыванию серверов и так далее. Она также может брать на себя все коммуникации c IaaS-командой. Эта команда по своей натуре всё же Dev, и она использует стандартный набор практик типа TDD, CI, итеративной разработки и прочего.
Топология IaaS для упрощения внедрения имеет ограниченную эффективность (из-за потери сотрудничества с Ops-командой), но дает возможность получить результат быстрее, чем при попытке прямого внедрения Типа 1 (который может стать следующим шагом в развитии).

Применимость Типа 3: организации с несколькими разными продуктами и сервисами, с традиционным подразделением IT Ops; организации, чьи приложения полностью работают в публичном облаке
Потенциальная эффективность: средняя
Тип 4: DevOps как внешний сервис
Некоторые организации, особенно небольшие, могут не обладать финансовыми ресурсами, опытом или квалифицированным персоналом для того, чтобы самостоятельно успешно справляться с операционными задачами в отношении своего ПО. В этом случае Dev-команда может найти внешнего сервис-провайдера типа Rackspace, чтобы тот помог построить систему тестовых сред, автоматизировать инфраструктуру и выстроить мониторинг, а также давал советы по нефункциональным требованиям, которые необходимо реализовать в ходе разработки.
Такой вариант может быть полезен для небольших организаций или для команд, которые хотят на практике узнать о современных подходах к автоматизации, мониторингу или управлению конфигурациями. В дальнейшем, по мере роста организации и появления в ней людей с выраженным фокусом на операционную деятельность, организация сможет двигаться к модели Типа 3 или даже Типа 1.
Применимость Типа 4: небольшие команды и организации с ограниченным опытом в области IT Operations
Потенциальная эффективность: средняя
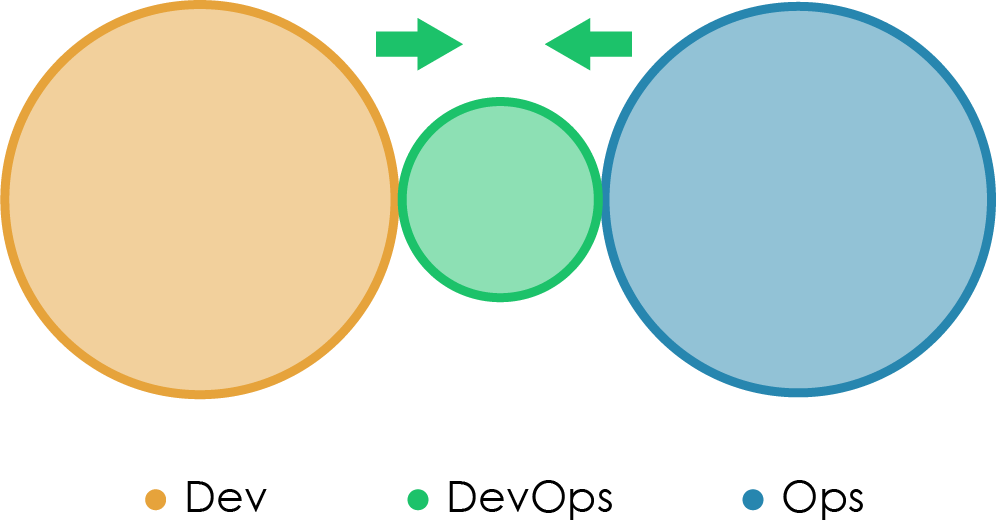
Тип 5: DevOps-команда с ограниченным сроком существования
Эта модель выглядит так же, как и Анти-тип B («Делянка» DevOps), но в ней задачи и жизненный срок DevOps-команды принципиально другие. Временная команда DevOps создается с миссией сблизить Dev и Ops, в идеале — привести их к Типу 1 или Типу 2, и после этого самоустраниться вследствие ненужности.
Члены временной команды вначале работают «переводчиками» между Dev и Ops, предлагая, с одной стороны, сумасшедшие идеи типа стэнд-апов и Канбан-досок для Ops-команд, а с другой — вместе с командой разрабочиков думая о низкоуровневой «кухне» типа настройки балансеров, SSL-разгрузки или управления сетевыми контроллерами. Если достаточное количество людей начинает видеть ценность в сближении Dev и Ops, то DevOps-команда получает реальный шанс достичь своих целей. Важно: долгосрочная ответственность за внедрения или работоспособность приложения не должна быть «повешена» на временную команду, в противном случае эта схема быстро превратится в Анти-тип B.
Применимость Типа 5: Это предшественник Типа 1, но есть риск превращения в Анти-тип B.
Потенциальная эффективность: от низкой до высокой
Тип 6: Команда евангелистов DevOps
Внутри организаций с большим разрывом между Dev и Ops (или с тенденцией к увеличению этого разрыва) может быть полезным создание DevOps-команды, которая будет поддерживать общение между Dev и Ops. Это версия на базе Типа 5, в которой DevOps-команда существует в постоянном режиме, но ее задача — способствовать общению и взаимодействию между Dev- и Ops-командами. Членов этой DevOps-команды часто называют евангелистами, потому что они распространяют знание о DevOps-практиках.

Применимость Типа 6: Организации с тенденцией на отдаление Dev и Ops. Опасность — сползание к Анти-типу B.
Потенциальная эффективность: от средней до высокой
Тип 7: Команда SRE (Модель Google)
DevOps обычно рекомендует привлекать сотрудников Dev-команд к дежурствам на телефоне, но это не обязательно. На самом деле, некоторые организации (в том числе в Google) используют другую модель, с явным ритуалом передачи ПО от команды разработки команде, которая отвечает за эксплуатацию — SRE (Site Reliability Engineering). В этой модели Dev-команды должны представить SRE-команде свидетельства (логи, метрики и так далее), явно демонстрирующие, что передаваемое приложение достаточно надежно для поддержки силами SRE.
Что важно — SRE-команда может не взять в поддержку приложение, которое не соответствует стандартам SRE, попросив разработчиков переделать определенные «особенности» до того, как приложение перейдет в режим промышленной эксплуатации. Взаимодействие между командами Dev и SRE крутится вокруг операционных показателей, но как только SRE-команда довольна качеством приложения (именно она, а не Dev-команда), SRE начинают этот софт поддерживать.

Применимость Типа 7: Тип 7 применим только в организациях с высокой культурой инженерии и организационной зрелостью. В противном случае есть риск получить Анти-тип A, в которой SRE/Ops-команды просто получают и выполняют инструкции по установке ПО
Потенциальная эффективность: от низкой до высокой
Тип 8: Сотрудничество на базе контейнеров
Помещение среды исполнения приложения в контейнер исключает реальную потребность в сотрудничестве Dev и Ops. В этом случае контейнер служит разграничителем зон ответственности Dev и Ops. При высоком уровне инженерной зрелости эта модель работает хорошо, но если Dev начинают игнорировать операционные вопросы, то и этот вариант может превратиться в классическое противостояние «мы против них».

Применимость Типа 8: Контейнеры могут работать отлично, но этот вариант может мутировать в Анти-тип A, если от команды Ops ожидают, что она будет поддерживать всё, что ей вбросит Dev-команда
Потенциальная эффективность: от средней до высокой
Тип 9: Сотрудничество Dev и DBA
Этот вариант является ответом на ситуацию, описанную в Анти-типе G. Для закрытия пропасти между Dev и DBA некоторые организации сближают команду DBA с отдельной командой Dev, специализирующейся на доработке центральной БД. Это помогает в общении между людьми, привыкшими смотреть на БД как на объект разработки, в котором складируют данные приложения, и теми, кто воспринимает эту же базу как колоссальный объем сложной бизнес-информации.
Применимость Типа 9: Подходит для организаций, в которых множественные приложения работают с одной или несколькими централизованным базами данных
Потенциальная эффективность: средняя
P.S. Сами мы (Райффайзенбанк) этим летом договорились считать целевыми Тип 1 (как базовый вариант для всех) и Тип 2 (как более «продвинутый» там, где получается его сделать). Жизнь покажет, насколько этот выбор был правильным.
P.P.S. А как у вас? Какие типы DevOps есть в ваших организациях?
Комментарии (8)

xxfatumxx
29.11.2017 07:27Может вопрос покажется глупым, но все же:
В чем разница между анти-типом F и типом 2, особенно учитывая контекст про «NoOps»? Ведь в обоих случаях Ops Team нет как таковой, но в случае с F акцентируется внимание на том, что команда разработчиков выполняет Ops-функции. А кто их выполняет для типа 2?shador_t Автор
29.11.2017 09:32Отличный вопрос! Грань между Анти-типом F (Dev внутри Ops) и Типом 2 (Полностью совмещенные команды) на самом деле довольно тонкая.
В классическом варианте Типа 2 предполагается, что люди внутри команды представляют разные функции, а при наличии в организации «честной» матрицы еще и относятся к разным профессиональным линейкам (и, возможно, разным структурным подразделениям). За счет T-shape грань между профессиями может несколько размываться, но все равно одни остаются «чуть больше Dev», а другие «чуть больше Ops». При этом достигается определенный баланс целей и задач Dev и Ops, без хронического перекоса в ту или другую сторону.
В случае чистого Анти-типа F Ops является выделенной, но подчиненной командой внутри Dev, и с одной стороны цели и задачи Dev имеют существенно больший вес, а с другой — Ops существует как отдельная команда, что может привести к любому из классических анти-паттернов общения между функциями («перекинь через стенку» или «мы тут накреативили, возьмите на поддержку»)
skandyla
30.11.2017 23:00Позвольте узнать, а где вы откопали такое определение SRE?
Мне кажется идея Site Reliability Engineering дефакто соотвествует "Типу 2", описанному в статье.
И да, в терминологии DevOps явно забыли Qa. Видимо, название DevOpsQa не очень благозвучно.
shador_t Автор
01.12.2017 08:21Такое определение SRE я откопал в оригинале статьи, а авторы статьи — в том же источнике, что и Вы, и в других материалах от Гугла. Мне кажется, что на Тип 2 это не очень похоже — в Google команда SRE существует отдельно от Dev-команды, между ними есть очень четкое разграничение и процессы взаимодействия, иногда (ИМХО) очень жесткие в отношении Dev.
И да, в название можно было бы добавить некоторое кол-во букв — QA, Biz, Sec и т.д.
skandyla
01.12.2017 20:36+1Простите, не заметил что перевод.
В целом с вами согласен. Но лично я понимаю SRE как среднее между "Тип 1" и "Тип 2".
Подробнее об описании зоны ответственности SRE написано здесь:
https://landing.google.com/sre/interview/ben-treynor.html
https://landing.google.com/sre/book/chapters/introduction.html
https://landing.google.com/sre/book/chapters/evolving-sre-engagement-model.htmlshador_t Автор
01.12.2017 21:06А для тех, кого заинтересовал этот загадочный термин, я позволю себе добавить ссылку на видео классической презентации про SRE от того же Бена Трейнора из Google:
www.usenix.org/conference/srecon14/technical-sessions/presentation/keys-sre
Wolverine
Расскажите, пожалуйста, что в вашем понимании есть команда (разработка определенного продукта)? Сколько у вас таких команд, сколько в каждой команде людей, шарятся ли люди между командами?
А также очень интересно, что происходит потом с командами, когда продукт перестает активно разрабатываться, но при этом остается необходимость его сопровождать. Фактически остается только Ops часть + багфиксинг. Из ниоткуда появляется старорежимная команда сисадминов, которая готова присматривать за еще одним проектом?
shador_t Автор
Если вкратце: команд разработки несколько десятков. Размер может быть разным — от 5-6 человек до 30+ (в этом случае есть внутреннее деление). Классический состав команды — разрабочики, аналитики, тестировщики, софтверные архитекторы (обычно совмещающие это с разработкой), в ряде команд — дизайнеры, OPS и некоторые другие специальности. Люди между командами в подавляющем большинстве случаев не шарятся.
Если продукт перестает активно развиваться (это бывает редко), большая часть ресурсов команды развития переходит на другие продукты. Ops как поддерживал продукт, так и продолжает поддерживать — за счет того, что команды Ops в большинстве случаев закрывают большИе куски ландшафта, там маневр ресурсами выполнить проще.