
19 октября 2017 года команда Deepmind опубликовала в Nature статью, краткая суть которой сводится к тому, что их новая модель AlphaGo Zero не только разгромно обыгрывает прошлые версии сети, но ещё и не требует никакого человеческого участия в процессе тренировки. Естественно, это заявление произвело в AI-коммьюнити эффект разорвавшейся бомбы, и всем тут же стало интересно, за счёт чего удалось добиться такого успеха.
По мотивам материалов, находящихся в открытом доступе, Семён sim0nsays записал отличный стрим:
А для тех, кому проще два раза прочитать, чем один раз увидеть, я сейчас попробую объяснить всё это буквами.
Сразу хочу отметить, что стрим и статья собирались в значительной степени по мотивам дискуссий на closedcircles.com, отсюда и спектр рассмотренных вопросов, и специфическая манера повествования.
Ну, поехали.
Что такое го?
Го — это древняя (по разным оценкам, ей от 2 до 5 тысяч лет) настольная стратегическая игра. Есть поле, расчерченное перпендикулярными линиями. Есть два игрока, у одного в мешочке белые камни, у другого — чёрные. Игроки по очереди выставляют камни на пересечение линий. Камни одного цвета, окружённые по четырём направлениям камнями другого цвета, снимаются с доски:
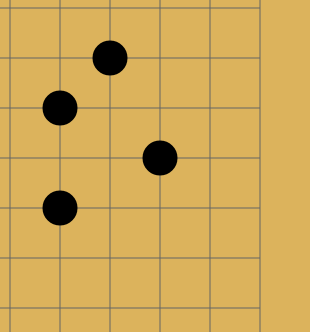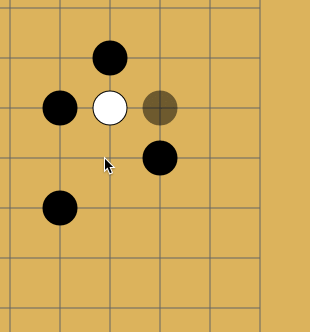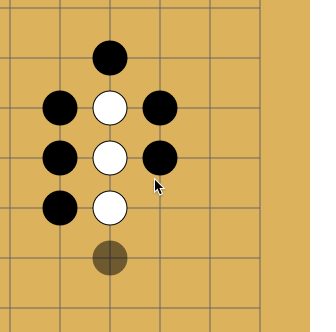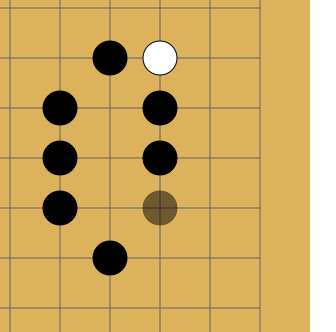
Выигрывает тот, кто к концу партии «окружит» большую по площади территорию. Там есть ещё несколько тонкостей, но базово это всё — человеку, который видит го первый раз в жизни, вполне реально объяснить правила за пять минут.
И почему это считается сложным?
Окей, давай попробуем сравнить несколько настольных игр.
Начнём с шашек. В шашках у игрока есть примерно 10 вариантов того, какой сделать ход. В 1994 году чемпион мира по шашкам был обыгран программой, написанной исследователями из университета Альберты.
Дальше шахматы. В шахматах игрок выбирает в среднем из 20 допустимых ходов и делает такой выбор приблизительно 50 раз за игру. В 1997 году Deep Blue, созданная командой IBM программа, обыграла чемпиона мира по шахматам Гарри Каспарова.
Теперь го. Профессионалы играют в го на поле размера 19х19, что даёт 361 вариант того, куда можно поставить камень. Отсекая откровенно проигрышные ходы и точки, занятые другими камнями, мы всё равно получаем выбор из более чем 200 опций, который требуется совершить в среднем 50-70 раз за партию. Ситуация осложняется тем, что камни взаимодействуют между собой, образуя построения, и в результате камень, поставленный на 35 ходу, может принести пользу только на 115. А может не принести. А чаще всего вообще трудно понять, помог нам этот ход или помешал. Тем не менее, в 2016 году программа AlphaGo обыграла сильнейшего (по меньшей мере, одного из сильнейших) игрока в мире Ли Седоля в серии из пяти игр со счётом 4:1.
Почему на победу в го потребовалось столько времени? Там так много вариантов?
Грубо говоря, да. И в шашках, и в шахматах, и в го общий принцип, по которому работают алгоритмы, один и тот же. Все эти игры попадают в категорию игр с полной информацией, значит, мы можем построить дерево всех возможных состояний игры. Поэтому мы банально строим такое дерево, а дальше просто идём по ветке, которая приводит к победе. Тонкость в том, что для го дерево получается ну очень большим из-за лютого фактора ветвления и впечатляющей глубины, и ни построить, ни обойти его за адекватное время не представлялось возможным. Именно эту проблему смогли решить ребята из DeepMind.
И как они победили?
Тут начинается интересное.
Сначала давай поговорим о том, как работали алгоритмы игры в го до AlphaGo. Все они показывали не самые впечатляющие результаты и успешно играли примерно на уровне среднего любителя, и все опирались на метод под названием Monte Carlo Tree Search — MCTS. Идея в чём (с этим важно разобраться).
У тебя есть дерево состояний — ходов. Из данной конкретной ситуации ты идёшь по какой-то из веток этого дерева, пока она не закончится. Когда ветка заканчивается, добавляешь в неё новый узел (ноду), тем самым инкрементально это дерево достраивая. А потом добавленную ноду оцениваешь, чтобы в дальнейшем определять, стоит ходить по данной ветке или не стоит, не раскрывая само дерево.
Чуть детальнее, это работает следующим образом:
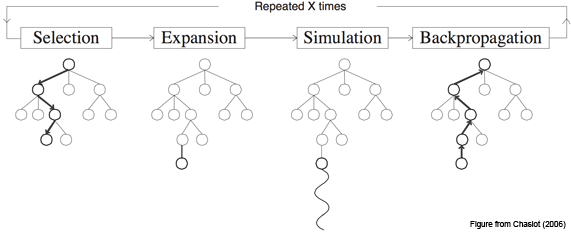
Шаг первый, Selection: у нас есть дерево позиций, и мы каждый раз совершаем ход, выбирая наилучший дочерний узел для текущей позиции.
Шаг второй, Expansion: допустим, мы дошли до конца дерева, но это ещё не конец игры. Просто создаём новую дочернюю ноду и идём в неё.
Шаг третий, Simulation: хорошо, появилась новая нода, фактически, игровая ситуация, в которой мы оказались впервые. Теперь надо её оценить, то есть понять, в хорошей мы оказались ситуации или не очень. Как это сделать? В базовой концепции — используя так называемый rollout: просто сыграть партию (или много партий) из текущей позиции и посмотреть, выиграли мы или проиграли. Получившийся результат и считаем оценкой узла.
Шаг четвёртый, Backpropagation: идём вверх по дереву и увеличиваем или уменьшаем веса всех родительских нод в зависимости от того, хороша новая нода или плоха. Пока важно понять общий принцип, мы ещё успеем рассмотреть данный этап в деталях.
В каждой ноде сохраняем два значения: оценку (value) текущей ноды и количество раз, которое мы по ней пробегали. И повторяем цикл из этих четырёх шагов много-много раз.
Как мы выбираем дочернюю ноду на первом шаге?
В самом простом варианте — берём ноду, у которой будет наивысший показатель Upper Confidence Bounds (UCB):
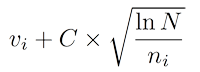
Здесь v — это value нашей ноды, n — сколько раз мы в этой ноде были, N — сколько раз были в родительской ноде, а C — просто некоторый коэффициент.
В не самом простом варианте можно усложнять формулу, чтобы получить более точные результаты, или вообще использовать какую-то другую эвристику, например, нейросеть. Об этом подходе мы тоже ещё поговорим.
Если смотреть чуть шире, перед нами классическая multi-armed bandit problem. Задача — найти такую функцию выбора узла, которая обеспечит оптимальный баланс между использованием лучших из имеющихся вариантов и исследованием новых возможностей.
Почему это работает?
Потому что с MCTS дерево решений растёт асимметрично: более интересные ноды посещаются чаще, менее интересные — реже, а оценить отдельно взятую ноду становится возможным без раскрытия всего дерева.

Это имеет какое-то отношение к AlphaGo?
В общем и целом, AlphaGo опирается на те же самые принципы. Ключевое отличие — когда на втором этапе мы добавляем новую ноду, для того, чтобы определить, насколько она хорошая, вместо rollout'ов используем нейросеть. Как мы это делаем.
(Я совсем в двух словах расскажу про прошлую версию AlphaGo, хотя на самом деле в ней хватает интересных нюансов; кто хочет подробностей — вэлком в видео в начале, там они хорошо объясняются, или в соответствующий пост на хабре, там они хорошо расписаны).
Во-первых, тренируем две сети, каждая из которых получает на вход состояние доски и говорит, какой бы ход в этой ситуации сделал человек. Почему две? Потому что одна — медленная, но работает хорошо (57% верных предсказаний, и каждый дополнительный процент даёт очень солидный бонус к итоговому результату), а вторая обладает намного меньшей точностью, зато быстрая.
Обе эти сети, медленную и быструю, мы тренируем на человеческих ходах — банально идём на сервер го, забираем партии игроков хорошего уровня, парсим и скармливаем для обучения.
Во-вторых, берём две эти натренированные «на людях» сети и начинаем играть ими сами с собой, чтобы их прокачать.

Примерно так.
В-третьих, тренируем value-сеть, которая получает на вход текущее состояние доски, а в ответ отдаёт число от -1 до 1 — вероятность выиграть, оказавшись в этой позиции в какой-то момент партии.
В итоге, у нас есть одна функция, которая говорит, куда надо ходить (из шага 2), и другая функция, которая, глядя на доску, говорит, проиграешь ты или выиграешь, если окажешься вот в такой ситуации (из шага 3). Всё, с этими двумя функциями мы играем по MCTS и используем первую, чтобы посмотреть, в какие ноды следует соваться из текущей, а вторую — чтобы без rollout'а оценить, насколько хороша нода, в которую мы сунулись. В результате первая функция очень сильно урезает фактор ветвления, а вторая позволяет для оценки узла не лезть вниз по дереву.
И это работает прям сильно лучше, чем вариант без нейросетей?
Да, внезапно этого оказывается достаточно.
В октябре 2015 AlphaGo играет с трёхкратным чемпионом Европы Fan Hui и обыгрывает его со счётом 5:0. Событие, с одной стороны, большое, потому что впервые компьютер выигрывает у профессионала в равных условиях, а с другой — не очень, потому что в мире го чемпион Европы — это примерно чемпион водокачки, и тот же Fan Hui обладает всего лишь вторым профессиональным даном (из девяти возможных). Версия AlphaGo, которая играла в этом матче, получила внутреннее название AlphaGo Fan.
А вот в марте 2016 новая версия AlphaGo играет пять партий уже с одним из лучших игроков мира Lee Sedol и выигрывает со счётом 4:1. Забавно, но сразу после игр в медиа к Ли Седолю стали относиться как к первому топ-игроку, проигравшему ИИ, хотя время расставило всё по местам и на сегодня Седоль остаётся (и, вероятно, останется навсегда) последним человеком, обыгравшим компьютер. Но я забегаю вперёд. Эта версия AlphaGo в дальнейшем стала обозначаться AlphaGo Lee.

Хорошая попытка, Ли, но нет.
После этого, в конце 2016 и начале 2017, уже следующая версия AlphaGo (AlphaGo Master) играет 60 матчей в онлайне с игроками из топовых позиций мирового рейтинга и выигрывает с общим счётом 60:0. В мае AlphaGo Master играет с топ-1 мирового рейтинга Ke Jie и обыгрывает его со счётом 3:0. Собственно, всё, противостояние человека и компьютера в го завершено.
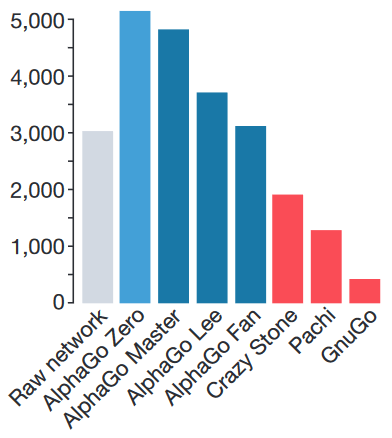
Рейтинг ELO. GnuGo, Pachi и CrazyStone — боты, написанные без использования нейросетей.
Но раз они и так всех обыграли, зачем понадобилась ещё одна сеть?
Если коротко — для красоты. У сообщества были три относительно большие претензии к AlphaGo:
1) Для стартового обучения используются игры людей. Получается, что без человеческого интеллекта искусственный интеллект не работает.
2) Много заинженеренных фич. Я опустил этот момент в своём пересказе, но в видео и в посте про AlphaGo Lee ему уделяется достаточно внимания, — обе используемые сети получают на вход значительное количество фич, придуманных людьми. Сами по себе эти фичи никакой новой информации не несут и могут быть вычислены, исходя из положения камней на доске, но вот без них сети не справляются. Например, сеть, которая определяет следующий ход, помимо непосредственно стейта получает следующее:
- сколько ходов назад был поставлен тот или иной камень;
- сколько свободных точек вокруг данного камня;
- сколько своих камней ты пожертвуешь, если сходишь в данную точку;
- легален ли вообще данный ход, то есть позволяется ли он правилами го;
- поучаствует ли камень, поставленный в эту точку, в так называемом “лестничном” построении;
и так далее — в общей сложности 48 слоёв с информацией. А “быстрой” сети, которая предсказывает вероятность победы, и вовсе отдают на вход сто с лишним тысяч заготовленных параметров. Получается, модель учится не играть в го per se, а показывать результаты в некотором заранее очень хорошо подготовленном окружении с большим количеством свойств, о которых ей рассказывает опять же человек.
3) Нужен здоровый кластер, чтобы всё это запустить.
И вот буквально месяц назад Deepmind представили новую версию алгоритма, AlphaGo Zero, в котором все эти проблемы устранены — модель учится с нуля, играя исключительно сама с собой и используя случайные веса нейросети в качестве стартовых; использует только положение камней на доске, чтобы принять решение; и сильно проще по требованиям к железу. Приятным бонусом она обыгрывает AlphaGo Lee в противостоянии из ста партий с общим счётом 100:0.
Так, и что для этого пришлось сделать?
Две большие штуки.
Во-первых, объединить две сети из прошлых версий AlphaGo в одну. Она получает состояние доски с небольшим количеством фич (я расскажу о них чуть позже), прогоняет всё это добро через свои слои, и в конце два её выхода выдают два результата: policy-выход выдаёт массив 19х19, который показывает, насколько вероятен каждый из ходов из данной позиции, а value выдаёт одно число — вероятность выиграть партию, опять же из данной позиции.
Во-вторых, поменять сам RL-алгоритм. Если раньше непосредственно MCTS использовался только во время игры, то теперь он используется сразу при тренировке. Как это работает.
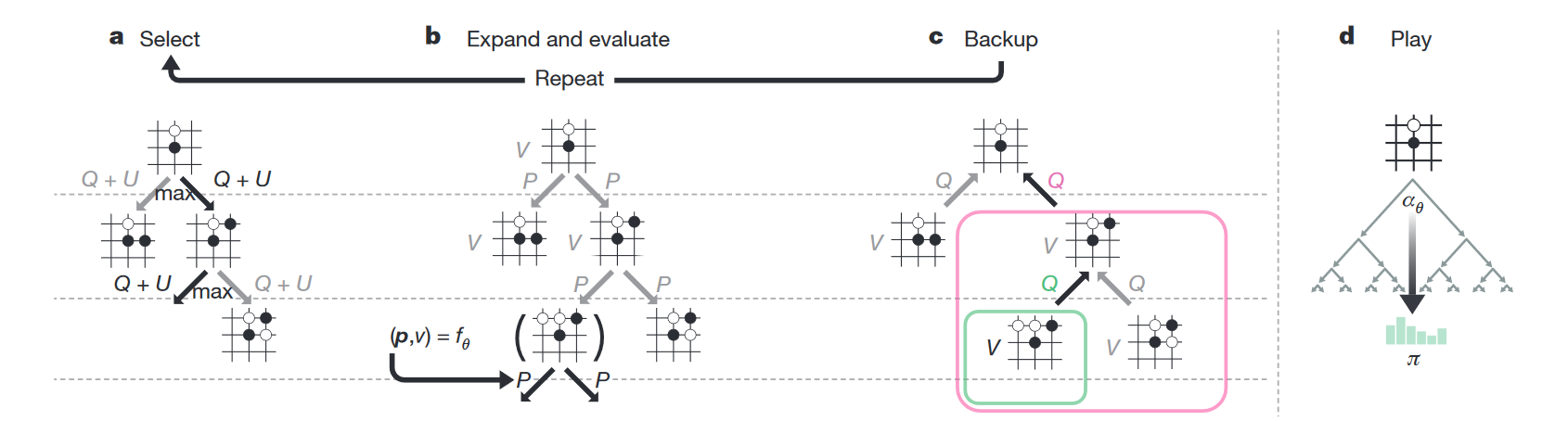
В каждой ноде дерева состояний хранится четыре значения — N (сколько раз мы ходили по этой ноде), V (value этой ноды), Q (усреднённое value всех дочерних нод этой ноды) и P (вероятность, что из всех допустимых на данном ходу нод мы выберем именно эту). Когда сеть играет сама с собой, во время каждого хода она производит следующие симуляции:
- Берёт дерево, корнем которого является текущая нода.
- Идёт в ту дочернюю ноду, где больше Q + U (U — добавка, стимулирующая поиск новых путей; она больше в начале тренировки и меньше — в дальнейшем).
- Таким нехитрым образом доходит до конца дерева — состояния, когда дочерних узлов нет, а игра ещё не закончена.
- Отдаёт это состояние на вход нейросети, в ответ получает v (value текущей ноды) и p (вероятности следующих ходов).
- Записывает v в ноду.
- Создаёт дочерние ноды с P согласно p и нулевыми N, V и Q.
- Обновляет все ноды выше текущей, которые были выбраны во время симуляции, следующим образом: N := N + 1; V := V + v; Q := V / N.
- Повторяет цикл 1-7 1600 раз.
Практика показывает, что такая симуляция выдаёт намного более сильные предсказания, нежели базовая нейросеть.
А дальше ход, который сеть действительно сделает, выбирается одним из двух способов:
— Если это реальная игра, идём туда, где больше N (выяснилось, что такая метрика оказывается самой надёжной);
— Если просто тренировка, выбираем ход из распределения Pi ~ N ^ (1/T), где T — просто некоторая температура для контроля баланса между исследованием и эффективностью.
То, что и policy, и value предсказываются одной общей сетью, даёт возможность крайне эффективно всё это запускать. Мы один раз оказались в какой-то ноде, отдали эту ноду в нашу сеть, получили некоторый результат V, все P запомнили, как изначальные веса на дочерних нодах, и всё, больше для этой ноды сеть не задействуем, сколько бы раз через неё ни ходили, а rollout'ов не запускаем вообще, считая, что предсказанный результат и так достаточно точен. Красота.
Как тренировать сеть, которая должна предсказывать и policy, и value?
Тренируется всё это дело, используя вот такой лосс:
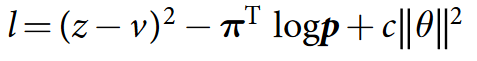
Что это, Бэрримор?
Формула состоит из трёх частей.
В первой части мы говорим, что сеть должна уметь предсказать результат, то есть z (то, с каким результатом закончилась партия) не должно отличаться от v (того value, которое она предсказала).
Во второй части в качестве лейблов для policy используем наши улучшенные вероятности. Это как reward в supervised learning'е — мы хотим как можно точнее предсказать те вероятности, которые получим, пробегаясь по дереву; очень похоже на cross-entropy loss.
Третья часть, c в конце формулы — просто регуляризатор.
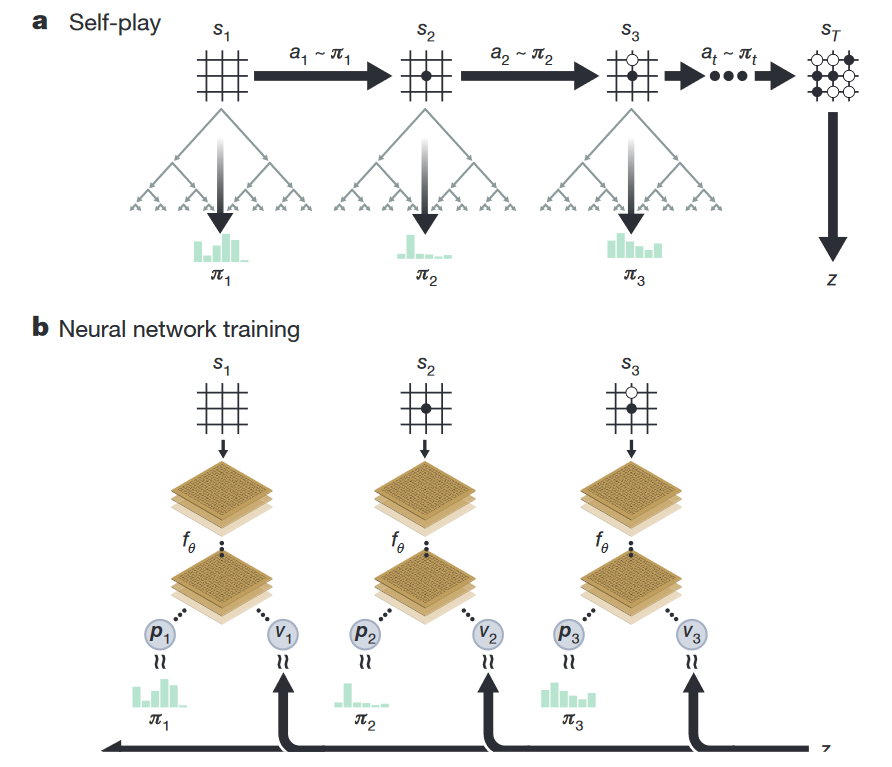
Более глобально, у нас есть некоторая «наилучшая» сеть с весами А. Эта сеть A играет сама с собой 25 000 раз (используя MCTS со своими весами для оценки новых нод), и для каждого хода мы сохраняем сам стейт, распределение Pi и то, чем закончилась игра (+1 за победу и -1 за поражение). Дальше готовим батчи из 2048 случайных позиций из последних 500 000 игр, отдаём 1000 таких батчей на тренировку и получаем некоторую новую сеть с весами B, после чего сеть A играет 400 игр с сетью B — при этом обе сети используют MCTS для выбора хода, только при оценке новой ноды A, очевидно, использует свои веса, а B — свои. Если B побеждает более, чем в 55% случаев, она становится лучшей сетью, если нет — чемпион остаётся прежним. Повторять до готовности.
И ты ещё обещал рассказать про фичи, которые подаются на вход.
Ага, было такое. Итак, на вход подаётся поле 19х19, каждый пиксель которого имеет 17 каналов, итого получаем 19х19х17. 17 слоёв нужны для следующего.
Первый говорит, находится ли в данной точке твой камень или нет (1 — стоит, 0 — отсутствует), а дальнейшие семь — находился ли он тут в какой-то из предыдущих семи ходов.
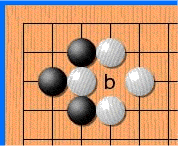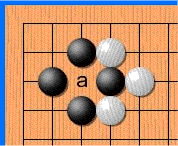
Не знаю, почему, но хабр иногда отказывается проигрывать эту гифку. Если так и произошло и ты не видишь анимации — просто кликни на неё.
Белые делают ход в точку a и забирают камень чёрных. Чёрные делают ход в точку b и забирают камень белых. Без запрета повторений оппоненты могли бы сидеть и играть последовательность a-b до бесконечности. В реальности же белые не могут сразу повторно сходить в позицию a и должны выбрать другой ход (а вот уже после какого-то иного хода сходить в позицию a разрешено). Именно для того, чтобы сеть могла научиться этому правилу, ей и передают историю. Вторая причина — в АМА на реддите разработчики рассказывали, что когда сеть видит, где в последнее время была активность, она лучше учится. По мысли это чем-то похоже на attention.
Следующие восемь слоёв — то же самое, но для камней оппонента.
Последний, семнадцатый, слой забит единицами, если ты играешь чёрными, и нулями, если играешь белыми. Это нужно, потому что при финальном подсчёте очков белые получают небольшой бонус за то, что ходят вторыми.
Вот и всё, по факту сеть действительно видит только состояние доски, но с информацией о том, камнями какого цвета она играет, и историей на восемь ходов.
А что с архитектурой?
Convolutional layer, потом 40 residual layer'ов, в конце два выхода — value head и policy head. Я не хочу останавливаться на этом подробно, кому важно — посмотрит сам, а всем остальным конкретные слои вряд ли интересны. Если резюмировать, по сравнению с версией Lee сеть стала больше, добавили batch normalization и появились residual connection. Нововведения очень стандартные, очень мейнстримовые, какого-то отдельного rocket science здесь нет.
И всё это чтобы что?
И всё это привело вот к таким результатам.
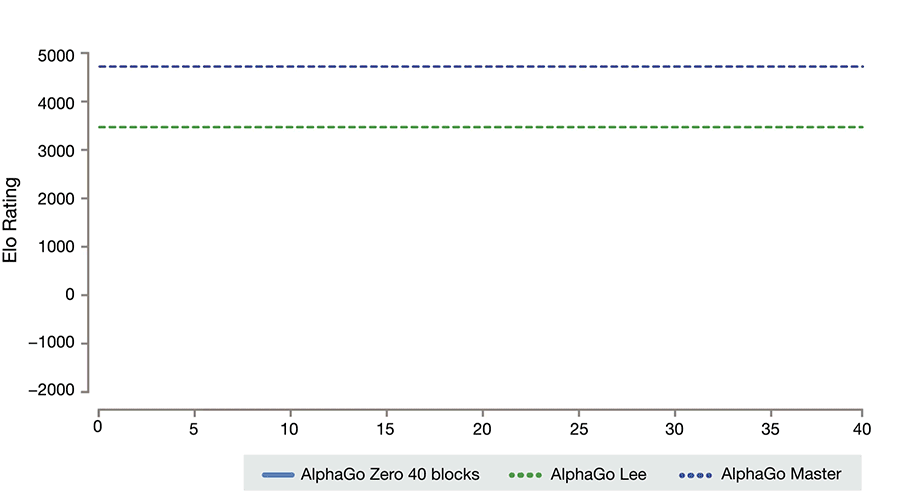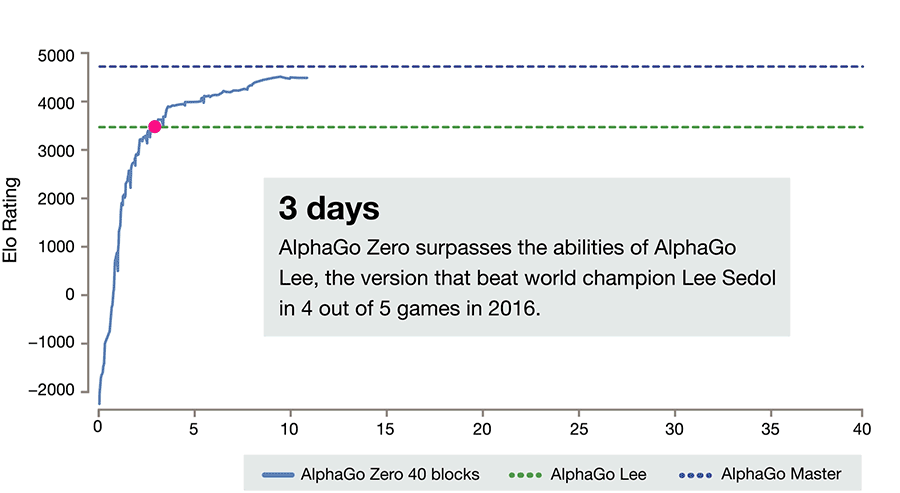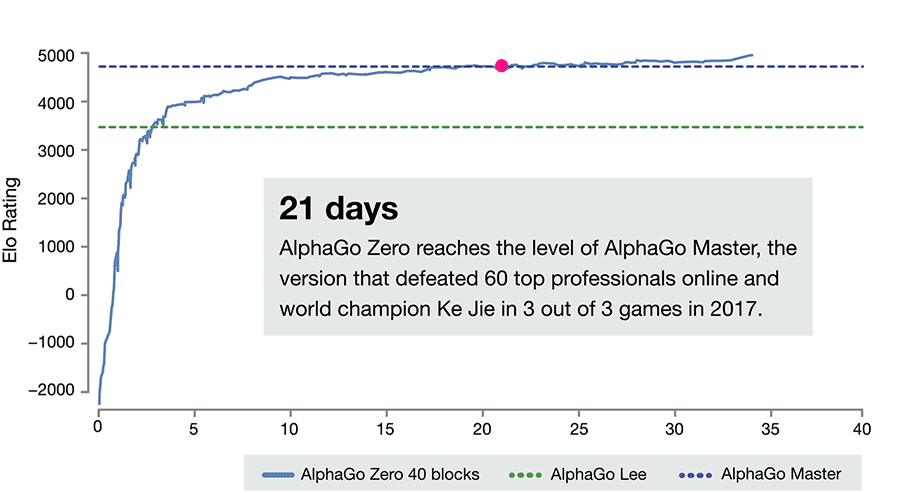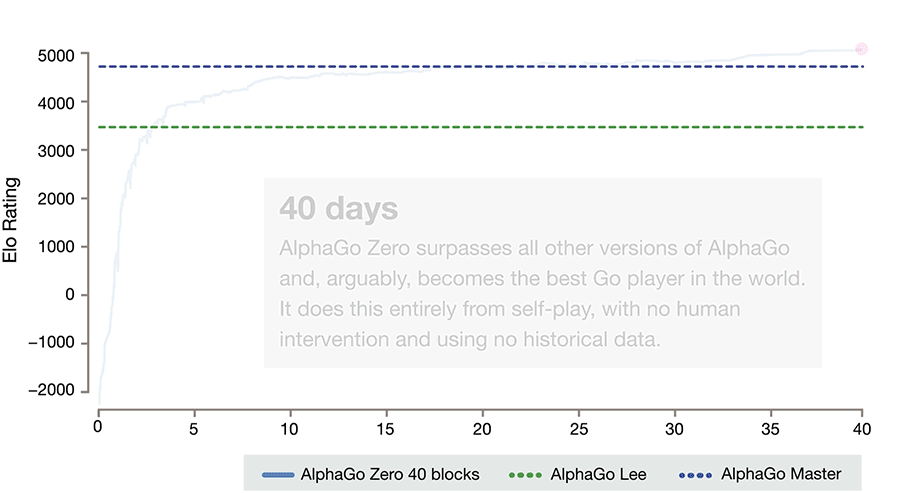
За три дня AlphaGo Zero учится обыгрывать версию Lee, за 21 — Master, а дальше отправляется в космос. После 40 дней тренировки она обыгрывает версию Lee со счётом 100:0 и версию Master со счётом 89:11. В этом свете интересно отметить, что у Master и Zero идентичный алгоритм тренировки, идентичная архитектура, а все отличия заключаются в фичах, подаваемых на вход, и том, что Zero не тренируется на играх людей. И выигрывает.
То есть всё, компьютер умнее, у человечества шансов нет?
В го — похоже, что да, мы официально в хурме. В общем случае, нет. У го есть несколько особенностей, крайне важных для текущих методов обучения:
- Всегда точно определённая среда, для которой есть идеальный и простой симулятор; никаких случайностей, никаких внешних вмешательств.
- Го — игра с полной информацией. Немножко похоже на предыдущий пункт, но тем не менее — нам известно абсолютно всё, что происходит.
В среде, жёстко ограниченной этими рамками, мы научились строить системы, эффективность которых значительно превышает человеческую. Стоит за рамки немножко выйти, и всё становится сильно сложнее. Поподробнее можно почитать в посте Andrej Karpathy.
А следующий бастион какой?
В играх — Starcraft и DotA. В обоих направлениях ведётся активная работа, но пока без прорывов сравнимого масштаба. Ждём.
Ух! Кажется, немножко понятно. Что ещё можно посмотреть по теме?
Во-первых, посмотри видео в начале этого поста, оно крутое и охватывает многие вопросы, которые я скипнул.
Во-вторых, почитай пост Семёна про AlphaGo Lee.
В-третьих, приходи в канал #data на closedcircles.com, мы там активно всё это обсуждаем.
В-четвёртых, всё, что я сейчас рассказал про AGZ, есть на одной картинке.
И давай финалочку.
Я закончу этот пост последним параграфом оригинального пейпера:
Humankind has accumulated Go knowledge from millions of games played over thousands of years, collectively distilled into patterns, proverbs and books. In the space of a few days, starting tabula rasa, AlphaGo Zero was able to rediscover much of this Go knowledge, as well as novel strategies that provide new insights into the oldest of games.
Просто подумай об этом.
Спасибо всем, у кого хватило терпения доскроллить до этого места. Отдельная благодарность пользователям sim0nsays за контент и комментарии и buriy за помощь в вычитке.
Комментарии (45)

f0rk
04.12.2017 15:37Я правильно понимаю, что из-за отсутствия MCTS в процессе игры, Zero в одной и той же позиции всегда будет выбирать один и тот же ход? А в версии master MCTS вносит некоторую случайность в игру?

JustRoo Автор
04.12.2017 16:46Мастер и Зеро играют по одному и тому же алгоритму. По поводу одного и того же хода трудно сказать — по идее, в реальной игре это должно быть так, но если в игре MCTS выдаст новое распределение, ход может поменяться. Во время тренировки, если я правильно помню, сеть в первые 30 прогонов MCTS обязательно ходит по 30 разным веткам, а потом уже использует связку лучший ход + случайность.
Время на обдумывание у Fan, Lee, Master и Zero одинаковое — 5 секунд на ход. Учитывая, что правила состязаний ограничивают время на партию, а не время на ход, думаю, они просто взяли с запасом.f0rk
04.12.2017 17:03+1Посмотрел сейчас внимательнее партии где zero играл белыми, master чаще делает новые ходы:
http://www.alphago-games.com/view/eventname/agzero_vs_agmaster/game/0/move/17
http://www.alphago-games.com/view/eventname/agzero_vs_agmaster/game/4/move/23
http://www.alphago-games.com/view/eventname/agzero_vs_agmaster/game/8/move/21
А вот тут zero разные ходы сыграл:
http://www.alphago-games.com/view/eventname/agzero_vs_agmaster/game/10/move/24
http://www.alphago-games.com/view/eventname/agzero_vs_agmaster/game/2/move/24
Получается во всех версиях есть какой-то случайный фактор при выборе хода.

dom1n1k
04.12.2017 18:28+1Почему на победу в го потребовалось столько времени? Там так много вариантов?
Количество вариантов — проблема важная, но не главная.
Грубо говоря, да.
Самая главная трудность там в функции оценки позиции. Ходы мало перебрать — нужно ещё понять, насколько они хороши. В шахматах позиция оценивается по относительно понятному набору критериев, которые более-менее можно формализовать. А в го оценка позиции поддается формальному описанию гораздо сложнее, она более комплексная и «человеческая».
JustRoo Автор
04.12.2017 18:34Об этом я тоже упоминаю, но на 100% согласиться не могу. Для оценки позиции придумали rollout, только вот на дереве таких размеров он всё равно не спасает.
Rom77
04.12.2017 21:13Самое интересное, что когда Гугл опубликовал свою прошлую статью об АльфаГо, и другие ведущие программы тоже перешли на использование policy (но пока без value), то структура Го-программ стала несколько парадоксальной. За оценку позиции в них отвечал перебор (rollout'ы), в то время как ходы рекомендовала оценка (policy). Хотя, казалось бы, логичнее наоборот. Например, как в шахматных программах — отбор перспективных вариантов реализуется средствами поиска, то есть направленного перебора, а оценкой позиции занимается оценочная функция.
erwins22
04.12.2017 21:14Напоминает Точки.
Но в точки я думаю выиграю железную башку. (самообман)
a1111exe
05.12.2017 23:07Lol, да, точки… :) Когда по школе прошла эпидемия этой игры, образовалось несколько сильных игроков, выиграть у которых было очень трудно. И я стал по вечерам после (а иногда, каюсь, вместо) домашнего задания играть сам с собой двумя шариковыми ручками разного цвета. Через где-то месяц-два стал стабильно выигрывать у всех доступных рекодсменов. Стал, так сказать, Альфа-Точкой. ) Через неделю-две после этого со мной перестали играть от слова вообще. Интересно, что через года три, уже в армии, встретил такого же, как оказалось, Альфа-Точку: после пары часов напряжённой работы наших естественных нейросетей он-таки выиграл! И отказался играть со мной от слова вообще (а я был реально в шоке, слёзно просил дать возможность отыграться...). Эхх, детство...

{kind=link}
Rom77
04.12.2017 21:29В этом свете интересно отметить, что у Master и Zero идентичный алгоритм тренировки, идентичная архитектура, а все отличия заключаются в фичах, подаваемых на вход, и том, что Zero не тренируется на играх людей. И выигрывает.
Присутствует ещё одно отличие. Точнее важный нюанс. У Мастера по-видимому было 20 блоков, а значит и сравнивать его нужно с 20-блочным Зеро. Источники:
bestchinanews.com
sports.sina.com.cn
Но тогда выходит, что Мастер сильнее Зеро при равной глубине сети. Отсюда, rollout'ы со встроенными фичами всё же видимо приносят пользу. В принципе их использование выглядит вполне логично — «интуиция» нейросети, это конечно хорошо, но конкретный перебор rollout'ов должен бы удачно её дополнять.
Ещё один важный момент. При тренировке, а если конкретно — самоигре, использовалось 2000 TPU (источник см. выше). То есть ресурс для тренировки требуется всё же очень и очень приличный. Но, конечно, если высококачественные партии уже есть (например человеческие), то для оптимизации параметров много ресурсов не надо.JustRoo Автор
04.12.2017 23:44Это, мягко говоря, не совсем так, да и 2000 TPU выглядит как «редактор не дал написать дохреналион». Не знаю, откуда берут пруфы вышеупомянутые источники, но в пейпере прямым текстом сказано: We also played games against the strongest existing program, AlphaGo Master — a program based on the algorithm and architecture presented in this paper but using human data and features — which defeated the strongest human professional players 60–0 in online games in January 2017. In our evaluation, all programs were allowed 5s of thinking time per move; AlphaGo Zero and AlphaGo Master each played on a single machine with 4 TPUs. То есть, одинаковая архитектура, одинаковое железо, одинаковые условия. Apples to apples.
khim
05.12.2017 03:16Это, мягко говоря, не совсем так, да и 2000 TPU выглядит как «редактор не дал написать дохреналион».
Это число, которое легко вычисляется из доступных данных. 5 миллионов игр, 0.4s на каждый ход — это 6000 дней. В реальности это, как они утверждают, заняло 3 дня. То есть в кластере должно быть 2000 машин, минимум с одним TPU каждая. То есть TPU могло быть и больше — но 2000 там были точно.
Rom77
05.12.2017 08:23Вышеупомянутые источники (в основном второй), это информация непосредственно от авторов АльфаГо. По второй ссылке — выступление Айя Хуанга на недавней конференции на Тайване. Снимки с его слайдов. Информация самая свежая, в то время как публикация в Nature реально написана в марте-апреле. В публикации Nature вы не найдёте информации о количестве блоков у Мастера и число TPU для формирования тренировочного набора позиций Зеро. В вашей цитате приведено число TPU для контрольных игр, а не для тренировки. Информация о количестве блоков в Зеро (20 или 40), тоже опущена. Так и получается, что 20-блочный Мастер сравнивается с 40-блочным Зеро, тогда как Мастера надо сравнивать с графиком на рисунке 3а публикации, а не на рисунке 6.
Выше уже указали как можно оценить число TPU для тренировки. Сам я тоже недавно писал, что статья в Nature содержит немало «замыленных» мест:
kasparovchess.crestbook.com
FoxProlog
05.12.2017 09:12-1Я правильно понимаю, что если Alpha Go Zero на вход подать шахматы, то за 40 дней он обыграет Komodo?
Rom77
05.12.2017 09:49Совсем не факт. По крайней мере не так-то просто этого добиться.
Хотя у новой технологии не просматривается каких-то принципиальных ограничений сверху, тем не менее современные шахматные программы очень высоко подняли планку уровня игры, которую не так-то просто преодолеть. В первую очередь, обратите внимание на то, что шахматные программы, пользуясь специальными правилами, в среднем рассматривают всего 1,5 вариантов на позицию, из 30-40 возможных. Можно ли превзойти такую высокую эффективность, используя policy? Не факт. Во вторых, value оценивает позицию в тысячи раз медленнее, чем линейная оценочная функция шахматных программ. Миллисекунды вместо долей микросекунд. И хотя value по-видимому будет оценивать качественнее, но зато и пропорционально медленнее. Так что, выигрыш у Стокфиша или Комодо, всё ещё большой вопрос. Хотя, конечно, очень интересно было бы понаблюдать за такими попытками.
Rom77
06.12.2017 11:56+2А вот и для шахмат свежие результаты подоспели — arxiv.org/pdf/1712.01815.pdf
Альфа Зеро против прошлогоднего Стокфиш 8 — 28 побед, 72 ничьи, 0 поражений. Играли по минутке на ход. Железо — 4 TPU против 64-х ядер (хэш 1 Гб).Rom77
06.12.2017 12:02+1Для сравнения, результаты последней версии Стокфиша против Стокфиша 8, контроль примерно 5 минут на партию:
tests.stockfishchess.orgJustRoo Автор
06.12.2017 14:17+2Собственно, вот он, двадцать первый век — люди-аутсайдеры смотрят со стороны, как роботы разбираются между собой, кто из них лучше. Пока что только в играх, но мы-то знаем.
khim
06.12.2017 17:20Ну в 20м веке лошади грустно смотрели на то, как автомобили разбирались кто из них быстрее. В 21 веке — настала очередь шахмат и Го.
Очень забавная картинка есть в книжке у Курцвейла: там чувак сидит за столом и ошалело выписывает таблички со словами «only human could ...». На полу их, выкинутых в мусор — гораздо больше, чем на стене, признанных правдивыми, причём половину из тех, которые были [оправданно] на стене в момент выхода книги… сейчас пора бы снять. Вот тут есть.
Доживём ли мы до времени, когда стена окажется девственно пуста? Кто знает…
elamaunt
05.12.2017 09:12+1Люди добрые, может кто-нибудь объяснить мне вот эти моменты? Очень хочу понять весь алгоритм, но для меня он пока сложноват (хоть и совсем на пальцах). Буду очень признателен =)
U — добавка, стимулирующая поиск новых путей; она больше в начале тренировки и меньше — в дальнейшем
Каким образом она меняется? Как захочется разработчику?
очень похоже на cross-entropy loss...
В статье очень мало об этом. Что такое кросс-этропия? Зачем она здесь? Прошу прощения, если я выгляжу невежественно, никогда не встречал это.
Создаёт дочерние ноды с P согласно p
Создает до конца дерева? По одному ноду за проход? Как это связано с P?
Некоторые фразы туманно воспринимаются. Мой уровень очень далек от авторского, чтобы сразу понять, что он имеет в виду.JustRoo Автор
05.12.2017 09:34Ок, давай по очереди.
1) В общем и целом, да, как захочется разработчику. Какой-то идеальной эвристики здесь не существует, ты всегда ищешь устраивающий конкретно тебя баланс между использованием хороших вариантов и поиском новых, тут очень много влияющих факторов. Если нужен конкретный пример, перечитай часть про Upper Confidence Bounds — это ровно то же самое Q + U, где Q = v, а правая часть — как раз U.
2) У тебя есть распределение, которое предсказала нейросеть, и есть распределение, которое ты получил через MCTS. Твоя задача — дать сети такой фидбек, чтобы в следующий раз её предсказание как можно точнее соответствовало тому, что ты получил через симуляции. Почитай вот тут, думаю, поможет, плюс в видео Семён обсуждает этот момент чуть подробнее, чем я. Увы, я не мог уместить весь machine learning в один пост =)
3) Смотри. Вернись к описанию оригинального MCTS, первые два шага. Мы прошли по дереву, дошли до конечной ноды, и создали дочернюю ноду для этой конечной. Всё, больше мы в этот проход ничего не создаём. В АГЗ то же самое, только мы создаём не одну дочернюю ноду, а все возможные дочерние ноды, и у каждой из них P (вероятность, что из всех дочерних нод мы выберем именно эту) будет равна соответствующему элементу p (выданного нейросетью вектора, который говорит, какая вероятность у какого хода из данной позиции). Совсем понятийно — мы скормили нейросети текущую позицию, она нам выдала массив 19х19, в котором говорит: вероятность сходить в точку с координатами [1;1] — 0.01825, в точку с координатами [1;2] — 0.0097 и так далее для каждого легального хода вплоть до точки с координатами [19;19]. Всё, мы для каждого из этих ходов создаём ноду, и в P записываем вот эту вот вероятность. Так чуть понятнее?elamaunt
05.12.2017 17:36Спасибо, стало понятнее. Я правильно понял, что без MCTS нейронная сеть не смогла бы научиться так играть? Возможно ли обучение сети без MCTS на сырых поначалу случайных ходах и без построения дерева?
JustRoo Автор
05.12.2017 18:08MCTS — это подход к «решению» игр с полной информацией; изначально, насколько я понимаю, в рамках теории игр был придуман minimax, потом — ММК, а потом эти две хурмы объединили и получили MCTS, ну мне это представляется в таком свете, во всяком случае. MCTS — просто самый эффективный подход из существующих, давай так пока это сформулируем. Пройдёт время, и вместо вероятностного поиска по дереву кто-нибудь придумает что-то покруче (или уже придумал, но мы ещё об этом не знаем). А нейросеть — просто добавка, которая усиливает два самых неэффективных места в этом подходе: выбор ноды для достраивания и оценку новой ноды. Это довольно независимые друг от друга штуки; в теории, ты можешь придумать более совершенные и быстрые эвристики для двух описанных выше действий, прикрутить свои эвристики к MCTS и победить АльфаГо вообще без нейросетей. Или наоборот — выкинуть вероятностный поиск по дереву, взять какой-то другой подход, «усилить» его неэффективные части точно такой же нейросетью, как в посте, и опять же победить АльфаГо.

i360u
05.12.2017 10:33Всегда точно определённая среда, для которой есть идеальный и простой симулятор; никаких случайностей, никаких внешних вмешательств.
Го — игра с полной информацией. Немножко похоже на предыдущий пункт, но тем не менее — нам известно абсолютно всё, что происходит.При этом, нейросеть — отличный инструмент для моделирования детерминированной среды (пусть даже синтетической, у человека происходит так-же с его категориальным мышлением) на основе хаотичных данных. Так что уже скоро человеки познакомятся лично с Богом-Машиной. Ведите себя хорошо.

ral
05.12.2017 14:11ну в DotA 2 OpenAI тоже уже обыгрывает «профи» еще в августе: www.theverge.com/2017/8/14/16143392/dota-ai-openai-bot-win-elon-musk
JustRoo Автор
05.12.2017 14:16Там миллион ограничений. Если я правильно помню, только один герой, только мид, без фарминга, без закупки предметов и так далее. То есть, до непосредственно игры в доту ещё далеко, они только микро натренировали. В старкрафте тоже есть отдельные достижения в микро и в макро, только вот полноценно играть вроде как ещё никто не умеет.
ral
05.12.2017 18:04блин, «китайская грамота» :) «мид, фарминг, микро» ))) ну ОК, не умеет, то не умеет.
JustRoo Автор
05.12.2017 18:13+1А, прости, я думал, ты в теме! В общем, они научились играть только одним персонажем из сотни или сколько их там возможных, и этот единственный персонаж стоит строго в одной небольшой области карты и делает несколько очень базовых действий, которых недостаточно для того, чтобы провести партию от начала до конца. Очень грубая аналогия — как если бы в шахматах научились делать очень хорошие ходы, но только чёрным конём и только в левой нижней четверти поля.

edge790
05.12.2017 18:41+1ral если ты читал про SC2, то по аналогии с StarCraft 2, это тоже самое что управлять всего одним юнитом в стратегии, не задумываясь о ресурсах и создании новых.
Dota 2 — одна из самых командных игр потому что способности одних персонажей, хорошо сочетаются с другими. И в добавок к этому у игроков много разных вещей о которых нужно думать:
- Выбор героев. Одни герои лучше сочетаются с другими, другие лучше противостоят определенным героям противника. Выбор из более чем 110 героев 5 героев на команду, команд две. За каждого отдельного персонажа стратегия игры отличается и может ещё изменятся в зависимости от героев противника/их "материального состояния" = В матче с OpenAI герой всегда один и тот же и матч "зеркальный"
- Покупка предметов — более 100 разных предметов. У каждого персонажа в игре есть инвентарь на 6 предметов. Как одноразовых "расходников" которые тратятся, так и пассивных(работают постоянно, пока лежат в инвентаре) и активных(которые нужно применять в определенные моменты). Некоторые предметы можно брать на 1-2 героев на команду, т.к. при правильном использовании они дают выгоду всей команде. = В матче OpenAI герои были 1х1 что уже урезает число возможных вариантов с 6 * 5 до 5. Некоторые предметы дорогие, а игра 1х1 часто заканчивается достаточно быстро, поэтому бОльшая часть из предметов недоступна. Вдобавок к этому, OpenAI "искуственно" запретили некоторые предметы. (о причине мне не ведомо)
- Принятие решений. В игре персонаж становится гораздо сильнее с дорогими предметами, поэтому часто персонажей делят на роли Core(Основа, которая в будущем должна выиграть игру), которая занимается фармом(процессом убивания вражеских/нейтральных юнитов, для получения денег) и саппортов(помощники, которые делают всё, чтобы их "Основа" чувствовала себя чудесно и мешают "Основе" противника. И тут как раз игра в полной мере раскрывает стратегический потенциал.
Core-игрок должен понимать, когда ему лучше выходить на бой с противником, а когда лучше заниматься добычей денег, должен "чувствовать" игру, чтобы понимать, когда на него могут делать вылазку противники.
Support-игрок должен правильно распределять ресурсы — у него не так много денег, поэтому он должен стараться использовать их максимально эффективно, помогать союзникам и нападать на героев оппонента.
По последнему пункту в OpenAI было ничего общего с командной Dota.
Да, он понимал что ему нужно наносить герой оппоненту и убивать его по возможности, а в свободное время "фармить", но это всего одна линия, с которой, по сути, выходить было нельзя. Распределения ролей тоже не было. Командного взаимодействия тоже не было.
Я уверен, что до 2020 года не будет ничего, что сможет сравниться с людьми по навыку игры Dota 2 и похожие игры, потому что, имхо, это решение требует совершенно нового подхода, которое должно быть на порядок лучше(как минимум, для этой задачи)

Athari
05.12.2017 22:09Э… я бы поосторожнее умножал варианты. :) Комбинаций героев, предметов и прочего много, но очень многие из них заведомо неэффективные. Скажем, в шахматах можно всё начало игры разваливать ряд пешек миллионами способов, но ни один ИИ углубляться в разбор этих ходов не будет, поэтому что это заведомо провальная стратегия.
У командного ИИ будет очевидное преимущество преимущество — идеальное микро в любом бою и идеальное взаимодействие между юнитами: способности будут использоваться в идеальной последовательности с выравниванием до миллисекунды, реакция на действия противников будет моментальная. Не знаю, как там в доте, а в хотсе "элитный ИИ" собирается в очень недурной шарик смерти, который без АоЕ-шных способностей разобрать не так-то просто. Элитный ИИ обыгрывают не в бою, а с помощью дыр в логике ИИ — ИИ по сути умеет только точно целиться и собираться в шарик смерти, всё остальное практически по нулям.
Что требуется от OpenAI для победы в 5v5 — это довести макро до уровня, когда оно не будет помножать на ноль божественный микро. Это мне кажется реалистичным, особенно учитывая, что разрабы не брезгуют добавлять костыли к самообучению.
edge790
05.12.2017 23:25Речь о нейронках и самообучении.
Да, некоторые комбинации герой-предмет заведомо слабые, но суть RL(Reinforcement Learning) в том, что он может найти удачные моменты даже в случае если для этого придётся чем-то пожертвовать (аналог гамбита). Так что ему в любом случае нужно будет попробовать все вариации предметов, причём не один раз.
По поводу шахмат при обучении ИИ как раз и поиграется со всеми фигурами. Но достаточно быстро(относительно) сделает выводы о выгоде от фигур.
В то же время в Dota 2 где матчи длятся очень долго(особенно для AI с не обученным RL) 115 героев, по 6 слотов у каждого, где может быть один из ~130 предметов, с учётом команды...
Идеально микро появится совсем не скоро… Того же OpenAI обыграли в 1х1 на равных условиях и это с учётом того что учили его одного, только для этого типа игры.
Какие мощности понадобятся для того, чтобы сделать что-то что может конкурировать с командой "любительского уровня" страшно представить.
Про ботов в HotS'е: в доте такое сложно будет провернуть из-за специфики игры. Некоторые способности направлены на длительные дизейблы по врагам стоящим рядом друг с другом, в то время как другие позволяют расправляться с теми, что разрознены. Я понятия не имею, как с этим будут бороться. Поживём — увидим.
2020 год — это мой самый "позитивный" прогноз. Так делаю ставку на 2025-2035.
khim
05.12.2017 23:51Судя описанию сложностей задачи — это как AlphaGo Fan vs AlphaGo Master. Звучит как космическая разница, а на деле — вопрос техники, пара лет, не более.
Я думаю все ограничения, которые ввели были сделаны, чтобы не мучить разработчиков попытками формально описать правила для сетей.
Я уверен, что до 2020 года не будет ничего, что сможет сравниться с людьми по навыку игры Dota 2 и похожие игры, потому что, имхо, это решение требует совершенно нового подхода, которое должно быть на порядок лучше(как минимум, для этой задачи)
А. До 2020го. То есть два года всего? Ну тогда, скорее всего, соглашусь.
Ничего «совершенно нового» тут не нужно, нужно просто время чтобы уже существующие схемы «довести до ума» и дать сети полное описание всей игры.
Это всё равно как утверждать, что между русскими и 100-клеточными шашками — море разницы. Для человека, наверное, да, а для робота — разница чисто количественная и очень небольшая.
edge790
05.12.2017 16:08+1Как и сказал JustRoo в доте было много ограничений. Добавлю, что на некоторые моменты модель натренировали специально (например блокинг крипов был "захардкожен", а не бот сам до него "додумался").
Про SC2 лучше процитировать ребят из DeepMind
Our initial investigations show that our agents perform well on these mini-games. But when it comes to the full game, even strong baseline agents, such as A3C, cannot win a single game against even the easiest built-in AI. For instance, the following video shows an early-stage training agent (left) which fails to keep its workers mining, a task that humans find trivial. After training (right), the agents perform more meaningful actions, but if they are to be competitive, we will need further breakthroughs in deep RL and related areas.
f0rk
Я посмотрел несколько партий сыгранных AlphaGo Zero и больше всего меня впечатляет тот факт, что во многих позициях он играет варианты понятные человеку чисто интуитивно. Когда я смотрел игры master — это можно было объяснить тем что master и предыдущие версии учились на играх людей. Но то что ИИ сам, без участия человека пришел к "пониманию" игры, которое похоже на человеческое, на мой взгляд, говорит о том, что мы люди — не такие уж и тупые :)
JustRoo Автор
С одной стороны, да. С другой стороны, принцип обучения один и тот же («сыграй много-много партий, посмотри, что сработало, и делай так почаще»), только у людей это заняло 5 000 лет, а у компьютера — 40 дней. Мы, может, и не тупые, но мееееееедленные.
f0rk
Я совсем не специалист в ML, но мне кажется что принципы похожи, только если издалека смотреть. Человека (кроме умения перебором просчитывать позиции) учат каким-то принципам, которые просто сформулированы словами, например говорят, что в начале партии нужно занимать углы, что от стенки нужно прыгать на N+1 камень и тд. Учат какой-то своеобразной эстетике, говорят что кейма — хорошая форма, а пустой треугольник — плохая. То есть знания передаются в достаточно общем виде, и нет отбора более эффективного игрока. Я, если честно, ожидал, что манера игры Zero будет сильнее отличаться от человеческой.
JustRoo Автор
С высоты моих 6 кю сказать трудно, но вот здесь товарищ как раз заявляет обратное — мол, у АльфаГо совсем другая парадигма игры, поэтому мы и проигрываем. Плюс опять же, что такое эстетика, что такое хорошая форма и плохая форма? Форма, которая максимизирует твоё вэлью, очевидно будет считаться хорошей, а форма, которая делает тебя уязвимым и ведёт к поражению, будет считаться плохой, разве нет? Сомневаюсь, что в го эстетика добавляется в ущерб результативности.
f0rk
Спасибо, я гляну ролик. Мне с высоты моего (тоже не сказать что высокого) 2 дана показалось, что я вижу параллели между игрой сильнейших про и zero. Конечно вполне возможно что мне просто показалось :)
Что касается формы, я не берусь определять что такое хорошая, а что такое плохая форма. Моя мысль в том, что у людей такое понятие существует, а вот у AlphaGo — вряд ли. Но при этом, создается ощущение, что AlphaGo соглашается с нашим интуитивным пониманием того, что такое хорошая форма.
Proteck
при этом также есть чисто «компьютерные», нечеловеческие ходы, которые нам пока непонятны
edge790
"Принципы" которым учат — это знания людей выраженные в более простой форме.
На хабре была хорошая статья, где автор ML научил играть в шахматы а потом регрессионным анализом достал "стоимость" каждый из фигур, которые были приблизительно равны тем, что "написаны в учебнике".
(хотя для некоторых профессиональных игроков они отличались. я склоняюсь к тому, что это зависит от стиля игры. Например играя против одного игрока ты "боишься" его слонов, против другого лучше "бояться" коня.)
Вот, кстати, эта статья: https://habrahabr.ru/post/254753/