
Приветствую читатель,
сегодня мы посмотрим как можно использовать StackExchange API для того, чтобы получать данные с сайтов этого семейства, например таких, как StackOverflow. Также, мы рассмотрим, какие возможности существуют для продвижения приложений/сайтов, использующих данное API на StackExchange и, в завершение, покажем как выглядит интеграция с SO у нас на GrabDuck.
Заинтересовало? Просим под кат.
Для тех кто не знаком с тем, что такое GrabDuck, проведем краткий экскурс (более подробно можно посмотреть в предыдущей статье — GrabDuck: новый взгляд на закладки).
Итак, на GrabDuck пользователи хранят свои закладки и могут искать необходимые им документы с использованием полнотекстового поиска. Система в ответ вернет то, что было сохранено пользователем, а также покажет закладки других пользователей, если посчитает, что данные материалы также могут быть интересны.
Основная идея сервиса — выступать этаким центром, собирающим отложенное из разных источников страницы в одном месте и предоставлять универсальный механизм для поиска.
Почему StackExchange? Анализируя статистику по сохраненным документам, мы пришли к выводу, что у нас очень много закладок с ИТ-ориентированных сайтов, таких как Хабр или StackOverflow. Данные сайты позволяют пользователям формировать свое избранное из статей или вопросов. «Вот», — подумали мы: «еще один источник, который наши пользователи смогут настроить и получать периодические обновления своих закладок из данных сервисов на GrabDuck». Начать решили со StackOverflow — это популярный ресурс не только у нас, но и за рубежом, у него есть понятное и простое публичное API, а также большое комьюнити.
Итак, наша задача — сделать синхронизацию вопросов из избранного StackOverflow. Возмем более близкий нам сайт — StackOverflow на русском.
Как наверное все знают, StackExchange это не один, а целая группа сайтов (или в терминологии StackExchange — сообществ), объединенных одной идеей: вопросы-ответы. Самые популярные — так или иначе связанны с ИТ-тематикой, это StackOverflow, русская версия StackOverflow, AskUbuntu, ThinkDifferent, SuperUser и многие другие.
Начальная точка для изучения API — https://api.stackexchange.com/docs
Что удобно, не играет роли с каким сайтом необходимо коммуницировать — StackExchange предоставляет единое API для всех своих сайтов. То есть мы можем один и тот же запрос для всех сайтов генерировать и отправлять на api.stackexchange.com, а для того, чтобы определить какой из сайтов должет его отработать, нам необходимо задать специальный параметр (параметр site). В результате можем получать разные ответы от каждого сайта по отдельности.
Отправлять запросы можно двумя способами.
API открытое, что означает, его можно использовать без какой-либо предварительной регистрации, правда при этом количество запросов ограничивается 300 в день. Для того, чтобы иметь возможность отправлять больше запросов (до 10000 в день), лучше все таки зарегистрироваться и получить специальный ключ для своего приложения. В случае работы с API через форму на сайте количество вызовов API также ограничено 10000 в день.
Но довольно слов, перейдем к делу. Еще раз напомню, что наша задача — получить список избранного, сохраненного пользователем на русском StackOverflow (он же HashCode.ru в недавнем прошлом). Работать будем через форму на сайте.
Для начала нам необходимо понять, как задать, что мы хотим работать именно со stackoverflow.ru или иными словами, чему должен быть равен параметр site в нашем запросе. Посмотрим список всех сайтов, относящихся к StackExchange. Для этого идем в раздел документации Sites, запускаем запрос:
https://api.stackexchange.com/2.2/sites
и ищем в результатах необходимый нам StackOverflow на русском
Полученный объект содержит всю необходимую информацию о необходимом нам сайте. Например, как позиционируют аудиторию создатели (audience), Favicon и большое изображение для сайта (favicon_url и ison_url), цветовую гамму, которая может быть нам необходима для каких то целей (styling) и многое другое. Кроме того, видим необходимый нам параметр для API вызова (api_site_parameter), это ru.stackoverflow.
Теперь у нас есть все данные, чтобы сформировать запрос на список избранного определенного пользователя. Для примера выберем произвольного пользователя с id 16095 у которого есть вопросы в избранном.
переходим на страницу Пользователи — Избранное (также доступна из раздела документации)
Корректируем запрос на нужные нам параметры и запускаем:
https://api.stackexchange.com/2.2/users/16095/favorites?order=desc&sort=activity&site=ru.stackoverflow
в результате получаем то что и было нам нужно — список «фаворитов» конкретного пользователя:
Задача решена. Все просто, не правда ли?
Итак, наше приложение готово, что дальше? Необходимо как-то рассказать о нем людям. И тут StackExchange снова нам в помощь.
Дело в том, что существует официальный способ дать описание на свое приложение на самом SE. Подробное описание, как это сделать (правда только на английском) можно найти на самом stackapps.com
В качестве примера, как выглядит размещенное объявление, приведем описание GrabDuck на StackApps.com.
Надеюсь приведенная информация будет полезна тем, у кого есть идеи, что можно сделать на основе сайтов StackExchange.
Посмотрим теперь выглядит синхронизация у нас. Работать будем под тем же пользователем с ID 16095
Итак после регистрации, заходим в личный кабинет и выбираем пункт «Синхронизация».
На настоящий момент пользователю доступно 3 слота для синхронизации. Выбираем необходимый нам сервис (это StackOverflow на русском) и нажимаем на кнопку «Добавить новый сервис».
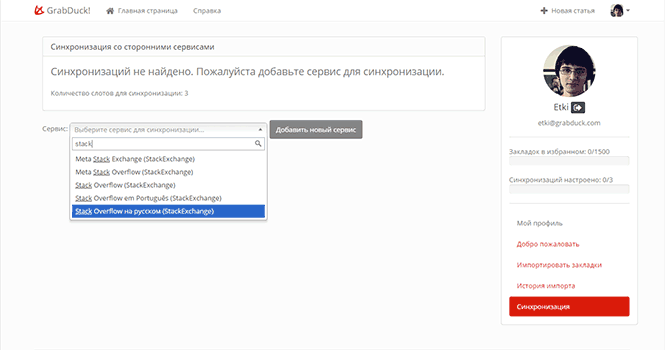
Вводим ID пользователя. Нажав на кнопку «Проверить», можно убедиться, что ID ввели правильно. Сохраняем. Все, синхронизация настроена.
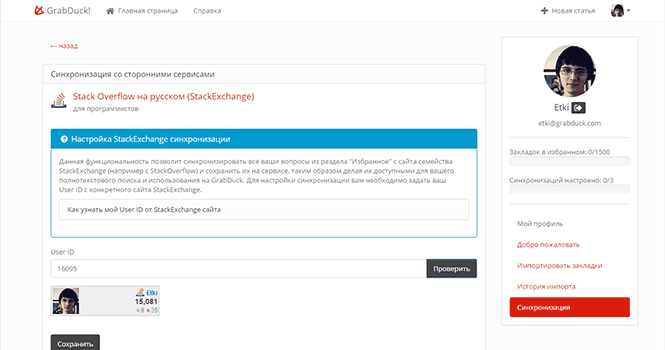
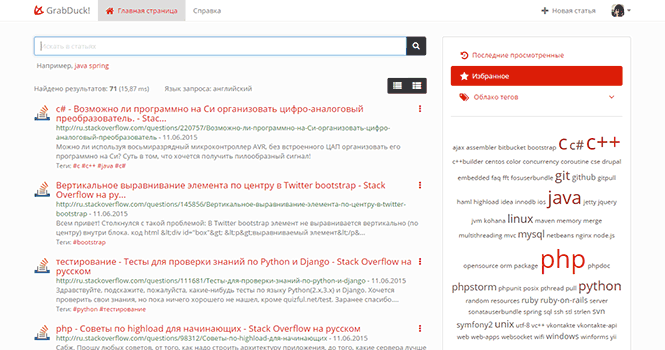
Текущий статус синхронизации всегда можно посмотреть в личном кабинете. А добавляемые на StackOverflow вопросы доступны вместе с тегами для поиска на GrabDuck.
Пытливый читатель здесь может спросить — а зачем вообще это нужно? Я и так могу зайти на StackOverflow и найти что мне нужно там.
Да это правда, но что дополнительно предлагаем мы на GD. Поиск происходит не только по избранному с SO, но и по другим закладкам пользователя, которые тоже могут содержать необходимую информацию. Или пользователь может настроить дополнительные сервисы для синхронизации и искать по документам с других сайтов одновременно (а у нас в планах синхронизироваться с хабром, rss, delicious и многими другими популярными сервисами). И все это заметьте без какого либо активного участия пользователя — все синхронизации однажды настроенные автоматически подгружают отложенные материалы на GD.
И в завершение статьи, для тех, кто следит за нами — небольшой обзор о том, что у нас нового с прошлого раза
Со времени прошлой статьи прошло чуть больше месяца. Что изменилось за это время у нас.
У нас появилось расширение для «Лисы». Из личных впечатлений — для хрома как-то все выглядит гораздо проще и логичней. Первоначально, просто хотели перенести код из Chrome без каких-либо переделок на FF. Поэтому, когда делали расширение для Chrome, старались использовать только HTML+CSS+JavaScript, чтобы можно было в будущем перенести без каких-либо доработок на другие браузеры. Не тут-то было. В FF, практически все, можно сделать только с использованием своего специфического API. Банальный, казалось бы пример, отправить запрос на сервер, тут просто не будет работать — необходимо использовать специальную функцию от FireFox Addon API. Поэтому пришлось практически все переделывать заново. С подтверждением расширений та же песня. Если для Хрома все прошло относительно легко и гладко, то в FF обещают завершить процедуру одобрения за 3-5 дней, но на практике помещают в очередь, которая практически не двигается. Изначально мы были там на 136 месте, за месяц с небольшим передвинулись на 106. Так что видимо к зиме наше расширение все таки будет рассмотрено. Вообщем, как у них вообще что-то работает не понятно, но зато становиться ясно, почему Хром отнимает у FF рынок (как бы это не было грустно).
Стало возможно при добавлении закладок сразу задавать теги. Это доступно, как при добавлении через сайт, так и из всех расширений. Нам по прежнему не нравиться этот способ, и мы верим, что со временем сможем предложить пользователям, чтобы теги назначались автоматически. Но после первой статьи было много просьб добавить эту функциональность, поэтому пока решили пойти навстречу и сделать.
При парсинге сайтов мы стараемся подобрать отображаемое изображение со страницы. Иногда это не удается, иногда изображения просто нет, а иногда с сайта можно снять только небольшие изображения, которые при растягивании выглядять не очень красиво. Поэтому мы начали делать скриншоты сайтов. К сожалению количество закладок огромно и сгенерировать за один подход изображения для всего физически не возможно. Поэтому поправили алгоритм парсинга и пока стараемся снимать скриншоты только там, где это действительно необходимо. Для любопытствующих — мы используем Page2Images. На «попробовать», есть бесплатный аккаунт с ограничением в 100 url в сутки и большим временем обработки каждого url. Если существуют какие-то лучшие альтернативы, прошу оставлять в комментариях.
Нет, мы не перерисовывали на сайте кнопочки и не меняли цвета, но постепенно пришли к выводу, что неудобно прыгать со страницы на страницу между закладками, тегами и последними документами и решили объединить все на одном экране. Теперь пользователь может сразу окинуть взглядом все что у него есть и решить каким путем найти, то что ему нужно. «Редизайн» пока не завершен, мы хотим переделать саму логику доступа к документам, сделать ее более простой и понятной. Но первый шаг в этом направлении уже сделан.
Собственно об этом вся данная статься. Кроме самой синхронизации, GrabDuck также научился правильно расставлять теги со всех вопросов StackExchange сообществ, а также со всех Хабра-сайтов. Будем дальше прорабатывать эту идею, и в будущем планируем добавлять синхронизации с другими полезными сайтами и учиться заполнять за пользователей мета информацию.
Реализовали историю просмоторов. Что это такое? Самое простое объяснение — сделано как на YouTube — когда есть список «посмотреть позже» / избранное и список всего просмотренного. Для нас, на практике, это означает, что теперь есть два списка — закладки пользователя, отсортированные по дате добавления (так называемое избранное) и история просмотров, отсортированная по дате прочтения, где находиться все что пользователь использовал, включая документы из рекомендаций.
Исправили кучу ошибок и доработали механизм парсинга, распознавания страниц и поиска дубликатов. Честно сказать, даже не предполагали, со сколькими нарушениями всего и вся могут быть сделаны веб-сайты. Самый «страшный» пример, который так и не придумали как обрабатывать — страница есть и возвращается с актуальным контентом, но с 500 (ошибка на сервере) ответом от сервера. Для браузера это не играет роли, он просто отображает, что пришло, а для нас это означает, что страница не валидна.
На этом на сегодня все. Приглашаем всех пробовать как работает новая функциональность и делиться впечатлениями.
Подписывайтесь на наш твиттер, чтобы быть в курсе всех обновлений.
До встречи на GrabDuck!
сегодня мы посмотрим как можно использовать StackExchange API для того, чтобы получать данные с сайтов этого семейства, например таких, как StackOverflow. Также, мы рассмотрим, какие возможности существуют для продвижения приложений/сайтов, использующих данное API на StackExchange и, в завершение, покажем как выглядит интеграция с SO у нас на GrabDuck.
Заинтересовало? Просим под кат.
Вступление, или почему StackExchange
Для тех кто не знаком с тем, что такое GrabDuck, проведем краткий экскурс (более подробно можно посмотреть в предыдущей статье — GrabDuck: новый взгляд на закладки).
Итак, на GrabDuck пользователи хранят свои закладки и могут искать необходимые им документы с использованием полнотекстового поиска. Система в ответ вернет то, что было сохранено пользователем, а также покажет закладки других пользователей, если посчитает, что данные материалы также могут быть интересны.
Основная идея сервиса — выступать этаким центром, собирающим отложенное из разных источников страницы в одном месте и предоставлять универсальный механизм для поиска.
Почему StackExchange? Анализируя статистику по сохраненным документам, мы пришли к выводу, что у нас очень много закладок с ИТ-ориентированных сайтов, таких как Хабр или StackOverflow. Данные сайты позволяют пользователям формировать свое избранное из статей или вопросов. «Вот», — подумали мы: «еще один источник, который наши пользователи смогут настроить и получать периодические обновления своих закладок из данных сервисов на GrabDuck». Начать решили со StackOverflow — это популярный ресурс не только у нас, но и за рубежом, у него есть понятное и простое публичное API, а также большое комьюнити.
Итак, наша задача — сделать синхронизацию вопросов из избранного StackOverflow. Возмем более близкий нам сайт — StackOverflow на русском.
StackExchange API
Как наверное все знают, StackExchange это не один, а целая группа сайтов (или в терминологии StackExchange — сообществ), объединенных одной идеей: вопросы-ответы. Самые популярные — так или иначе связанны с ИТ-тематикой, это StackOverflow, русская версия StackOverflow, AskUbuntu, ThinkDifferent, SuperUser и многие другие.
Начальная точка для изучения API — https://api.stackexchange.com/docs
Что удобно, не играет роли с каким сайтом необходимо коммуницировать — StackExchange предоставляет единое API для всех своих сайтов. То есть мы можем один и тот же запрос для всех сайтов генерировать и отправлять на api.stackexchange.com, а для того, чтобы определить какой из сайтов должет его отработать, нам необходимо задать специальный параметр (параметр site). В результате можем получать разные ответы от каждого сайта по отдельности.
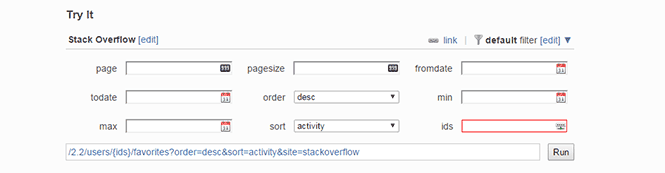
Отправлять запросы можно двумя способами.
- Как обычно, посылая HTTP запросы на api.stackexchange.com и получая JSON ответ или
- используя специальную форму на самом stackexchange.com, которую можно использовать для того, чтобы предварительно посмотреть, как работает та или иная функциональность, или же тут можно легко набить запрос и потом просто перенести его в свое приложение.
API открытое, что означает, его можно использовать без какой-либо предварительной регистрации, правда при этом количество запросов ограничивается 300 в день. Для того, чтобы иметь возможность отправлять больше запросов (до 10000 в день), лучше все таки зарегистрироваться и получить специальный ключ для своего приложения. В случае работы с API через форму на сайте количество вызовов API также ограничено 10000 в день.
Но довольно слов, перейдем к делу. Еще раз напомню, что наша задача — получить список избранного, сохраненного пользователем на русском StackOverflow (он же HashCode.ru в недавнем прошлом). Работать будем через форму на сайте.
Для начала нам необходимо понять, как задать, что мы хотим работать именно со stackoverflow.ru или иными словами, чему должен быть равен параметр site в нашем запросе. Посмотрим список всех сайтов, относящихся к StackExchange. Для этого идем в раздел документации Sites, запускаем запрос:
https://api.stackexchange.com/2.2/sites
и ищем в результатах необходимый нам StackOverflow на русском
...,
{
"styling": {
"tag_background_color": "#FFF",
"tag_foreground_color": "#000",
"link_color": "#0077CC"
},
"related_sites": [
{
"relation": "meta",
"api_site_parameter": "meta.ru.stackoverflow",
"site_url": "http://meta.ru.stackoverflow.com",
"name": "Stack Overflow на русском Meta"
},
{
"relation": "chat",
"site_url": "http://chat.stackexchange.com?tab=site&host=ru.stackoverflow.com",
"name": "Chat Stack Exchange"
}
],
"aliases": [
"http://hashcode.ru",
"http://stackoverflow.ru"
],
"markdown_extensions": [
"Prettify"
],
"open_beta_date": 1427414400,
"closed_beta_date": 1427414400,
"site_state": "open_beta",
"favicon_url": "http://cdn.sstatic.net/ru/img/favicon.ico",
"icon_url": "http://cdn.sstatic.net/ru/img/apple-touch-icon.png",
"audience": "программистов",
"site_url": "http://ru.stackoverflow.com",
"api_site_parameter": "ru.stackoverflow",
"logo_url": "http://cdn.sstatic.net/ru/img/logo.png",
"name": "Stack Overflow на русском",
"site_type": "main_site"
},...
Полученный объект содержит всю необходимую информацию о необходимом нам сайте. Например, как позиционируют аудиторию создатели (audience), Favicon и большое изображение для сайта (favicon_url и ison_url), цветовую гамму, которая может быть нам необходима для каких то целей (styling) и многое другое. Кроме того, видим необходимый нам параметр для API вызова (api_site_parameter), это ru.stackoverflow.
Теперь у нас есть все данные, чтобы сформировать запрос на список избранного определенного пользователя. Для примера выберем произвольного пользователя с id 16095 у которого есть вопросы в избранном.
переходим на страницу Пользователи — Избранное (также доступна из раздела документации)
Корректируем запрос на нужные нам параметры и запускаем:
https://api.stackexchange.com/2.2/users/16095/favorites?order=desc&sort=activity&site=ru.stackoverflow
в результате получаем то что и было нам нужно — список «фаворитов» конкретного пользователя:
{
"items": [
{
"tags": ["maven","java","idea","resources"],
"owner": {
"reputation": 11,
"user_id": 25194,
"user_type": "registered",
"profile_image": "https://www.gravatar.com/avatar/7b745015819bd1d9dbc17ac3f64a40f1?s=128&d=identicon&r=PG",
"display_name": "Slayfi",
"link": "http://ru.stackoverflow.com/users/25194/slayfi"
},
"is_answered": false,
"view_count": 162,
"answer_count": 0,
"score": 2,
"last_activity_date": 1433402068,
"creation_date": 1416248008,
"last_edit_date": 1433402068,
"question_id": 376200,
"link": "http://ru.stackoverflow.com/questions/376200/class-path-resourse-applicationcontext-xml-cannot-be-opened-because-it-does-no",
"title": "Class path resourse [ApplicationContext.xml] cannot be opened because it does not exist"
},{
"tags": ["php","websocket"],
"owner": {
"reputation": 300,
"user_id": 19768,
"user_type": "registered",
"accept_rate": 93,
"profile_image": "https://www.gravatar.com/avatar/fa8fae6547dd2415a143680d337b1758?s=128&d=identicon&r=PG",
"display_name": "duhon",
"link": "http://ru.stackoverflow.com/users/19768/duhon"
},
"is_answered": false,
"view_count": 197,
"answer_count": 0,
"score": 4,
"last_activity_date": 1432902435,
"creation_date": 1414136622,
"last_edit_date": 1432902435,
"question_id": 370273,
"link": "http://ru.stackoverflow.com/questions/370273/%d0%9f%d1%80%d0%b0%d0%b2%d0%b8%d0%bb%d1%8c%d0%bd%d0%b0%d1%8f-%d0%b0%d1%80%d1%85%d0%b8%d1%82%d0%b5%d0%ba%d1%82%d1%83%d1%80%d0%b0-%d0%b4%d0%bb%d1%8f-wamp-%d1%87%d0%b0%d1%82%d0%b0",
"title": "Правильная архитектура для wamp чата"
},...
Задача решена. Все просто, не правда ли?
Возможности по продвижению
Итак, наше приложение готово, что дальше? Необходимо как-то рассказать о нем людям. И тут StackExchange снова нам в помощь.
Дело в том, что существует официальный способ дать описание на свое приложение на самом SE. Подробное описание, как это сделать (правда только на английском) можно найти на самом stackapps.com
В качестве примера, как выглядит размещенное объявление, приведем описание GrabDuck на StackApps.com.
Надеюсь приведенная информация будет полезна тем, у кого есть идеи, что можно сделать на основе сайтов StackExchange.
Как сделали синхронизацию с StackOverflow мы на GrabDuck
Посмотрим теперь выглядит синхронизация у нас. Работать будем под тем же пользователем с ID 16095
Итак после регистрации, заходим в личный кабинет и выбираем пункт «Синхронизация».
На настоящий момент пользователю доступно 3 слота для синхронизации. Выбираем необходимый нам сервис (это StackOverflow на русском) и нажимаем на кнопку «Добавить новый сервис».
Вводим ID пользователя. Нажав на кнопку «Проверить», можно убедиться, что ID ввели правильно. Сохраняем. Все, синхронизация настроена.
Текущий статус синхронизации всегда можно посмотреть в личном кабинете. А добавляемые на StackOverflow вопросы доступны вместе с тегами для поиска на GrabDuck.
Преимущества такого подхода или зачем синхронизировать избранное с SO на GD
Пытливый читатель здесь может спросить — а зачем вообще это нужно? Я и так могу зайти на StackOverflow и найти что мне нужно там.
Да это правда, но что дополнительно предлагаем мы на GD. Поиск происходит не только по избранному с SO, но и по другим закладкам пользователя, которые тоже могут содержать необходимую информацию. Или пользователь может настроить дополнительные сервисы для синхронизации и искать по документам с других сайтов одновременно (а у нас в планах синхронизироваться с хабром, rss, delicious и многими другими популярными сервисами). И все это заметьте без какого либо активного участия пользователя — все синхронизации однажды настроенные автоматически подгружают отложенные материалы на GD.
И в завершение статьи, для тех, кто следит за нами — небольшой обзор о том, что у нас нового с прошлого раза
GrabDuck Update Log
Со времени прошлой статьи прошло чуть больше месяца. Что изменилось за это время у нас.
Расширение для FireFox
У нас появилось расширение для «Лисы». Из личных впечатлений — для хрома как-то все выглядит гораздо проще и логичней. Первоначально, просто хотели перенести код из Chrome без каких-либо переделок на FF. Поэтому, когда делали расширение для Chrome, старались использовать только HTML+CSS+JavaScript, чтобы можно было в будущем перенести без каких-либо доработок на другие браузеры. Не тут-то было. В FF, практически все, можно сделать только с использованием своего специфического API. Банальный, казалось бы пример, отправить запрос на сервер, тут просто не будет работать — необходимо использовать специальную функцию от FireFox Addon API. Поэтому пришлось практически все переделывать заново. С подтверждением расширений та же песня. Если для Хрома все прошло относительно легко и гладко, то в FF обещают завершить процедуру одобрения за 3-5 дней, но на практике помещают в очередь, которая практически не двигается. Изначально мы были там на 136 месте, за месяц с небольшим передвинулись на 106. Так что видимо к зиме наше расширение все таки будет рассмотрено. Вообщем, как у них вообще что-то работает не понятно, но зато становиться ясно, почему Хром отнимает у FF рынок (как бы это не было грустно).
Теги при добавлении закладок
Стало возможно при добавлении закладок сразу задавать теги. Это доступно, как при добавлении через сайт, так и из всех расширений. Нам по прежнему не нравиться этот способ, и мы верим, что со временем сможем предложить пользователям, чтобы теги назначались автоматически. Но после первой статьи было много просьб добавить эту функциональность, поэтому пока решили пойти навстречу и сделать.
Скриншоты сайтов
При парсинге сайтов мы стараемся подобрать отображаемое изображение со страницы. Иногда это не удается, иногда изображения просто нет, а иногда с сайта можно снять только небольшие изображения, которые при растягивании выглядять не очень красиво. Поэтому мы начали делать скриншоты сайтов. К сожалению количество закладок огромно и сгенерировать за один подход изображения для всего физически не возможно. Поэтому поправили алгоритм парсинга и пока стараемся снимать скриншоты только там, где это действительно необходимо. Для любопытствующих — мы используем Page2Images. На «попробовать», есть бесплатный аккаунт с ограничением в 100 url в сутки и большим временем обработки каждого url. Если существуют какие-то лучшие альтернативы, прошу оставлять в комментариях.
Новый дизайн
Нет, мы не перерисовывали на сайте кнопочки и не меняли цвета, но постепенно пришли к выводу, что неудобно прыгать со страницы на страницу между закладками, тегами и последними документами и решили объединить все на одном экране. Теперь пользователь может сразу окинуть взглядом все что у него есть и решить каким путем найти, то что ему нужно. «Редизайн» пока не завершен, мы хотим переделать саму логику доступа к документам, сделать ее более простой и понятной. Но первый шаг в этом направлении уже сделан.
Синхронизация со StackExchange
Собственно об этом вся данная статься. Кроме самой синхронизации, GrabDuck также научился правильно расставлять теги со всех вопросов StackExchange сообществ, а также со всех Хабра-сайтов. Будем дальше прорабатывать эту идею, и в будущем планируем добавлять синхронизации с другими полезными сайтами и учиться заполнять за пользователей мета информацию.
История просмотров
Реализовали историю просмоторов. Что это такое? Самое простое объяснение — сделано как на YouTube — когда есть список «посмотреть позже» / избранное и список всего просмотренного. Для нас, на практике, это означает, что теперь есть два списка — закладки пользователя, отсортированные по дате добавления (так называемое избранное) и история просмотров, отсортированная по дате прочтения, где находиться все что пользователь использовал, включая документы из рекомендаций.
Мелкие доработки и баги
Исправили кучу ошибок и доработали механизм парсинга, распознавания страниц и поиска дубликатов. Честно сказать, даже не предполагали, со сколькими нарушениями всего и вся могут быть сделаны веб-сайты. Самый «страшный» пример, который так и не придумали как обрабатывать — страница есть и возвращается с актуальным контентом, но с 500 (ошибка на сервере) ответом от сервера. Для браузера это не играет роли, он просто отображает, что пришло, а для нас это означает, что страница не валидна.
На этом на сегодня все. Приглашаем всех пробовать как работает новая функциональность и делиться впечатлениями.
Подписывайтесь на наш твиттер, чтобы быть в курсе всех обновлений.
До встречи на GrabDuck!