
0. Об авторе
Всем привет, меня зовут Максим Логвинов и я студент Харьковского Национального университета радиоэлектроники.
Меня всегда интересовали звук и музыка. Я сам любил писать электронную танцевальную музыку и мне всегда было интересно, как человеку, который недостаточно хорошо разбирается в высоких материях математики, узнать, что же происходит со звуком в компьютере: как он пишется, сжимается, какие для этого существуют технологии и так далее. Ведь со школьной скамьи и физики я понимал, что звук — он «аналоговый»: его мало того что нужно преобразовать в цифровой (для чего необходимы такие устройства как АЦП), но его нужно как-то сохранить. А ещё лучше, чтобы эта музыка занимала поменьше дискового пространства, чтобы можно было поместить в скупую папку побольше музыки. И чтобы звучала хорошо, без всяких слышимых артефактов сжатия. Музыкант ведь. Натренированное ухо, не лишённое музыкального слуха, достаточно сложно обмануть методами, которые используются для компрессии звука с потерями — по крайней мере, на достаточно низких битрейтах. Ишь, какой привередливый.
А давайте посмотрим, что из себя представляет звук, как он кодируется и какие инструменты используются для этого самого кодирования. Более того, поэкспериментируем с битрейтами одного из самых продвинутых на сегодняшний день кодеков — Opus и оценим, что и с какими циферками можно закодировать, чтобы и рыбку съесть, и… Собственно, просто почему бы и нет? Почему бы не попытаться описать простым языком не только то, как хранится и кодируется аудио компьютером, но и протестировать один из лучших кодеков на сегодняшний день? Особенно, если речь идёт о сверхнизких битрейтах, где практически все существующие кодеки начинают творить невероятные вещи со звуком в попытках уложиться в малый размер файла. Если хочется отвлечься от рутины и узнать, какие выводы были получены при тестировании нового кодека — добро пожаловать под кат.
1. Кодирование звука
Звук имеет физическую природу. Любой звук — это колебания в пространстве (в данном случае — в воздухе), которые улавливаются нашим ухом. Колебания имеют непрерывный характер, который можно описать математическими моделями. Делать же этого мы, конечно же, не будем, но поставим перед собой вопрос: как колебания, имеющие непрерывную природу, записать в машину, которая оперирует лишь нулями и единицами?
1.1. Ни сжатия, ни потерь
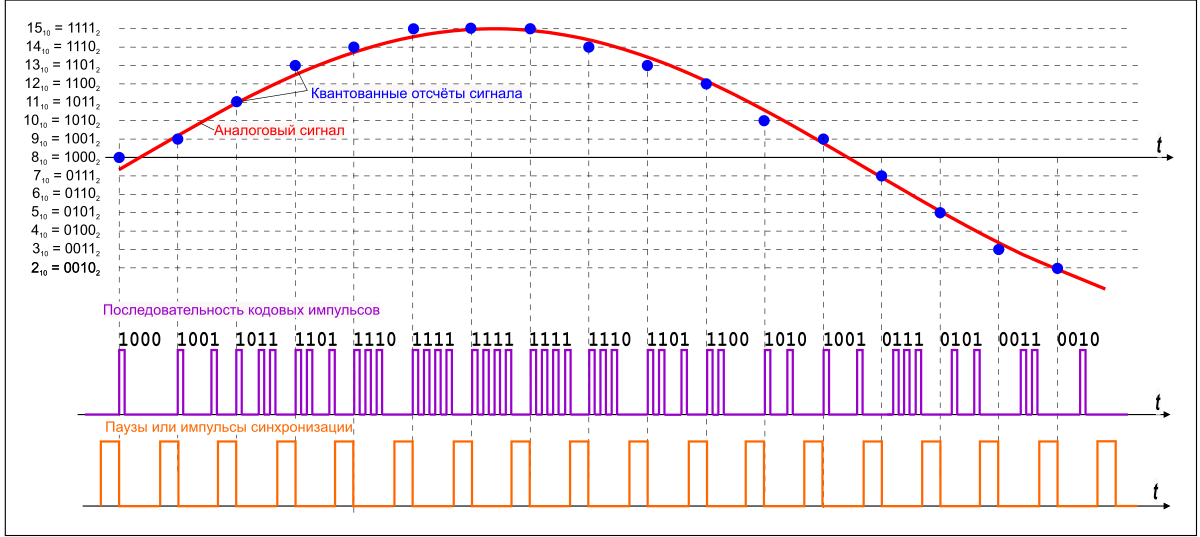
Рис. 1.1 — Графическое описание импульсно-кодовой модуляции
Формат WAV (WAVE) сохраняет аудио-дорожку в её истинном качестве, не проводя никаких манипуляций с самим аудио-файлом.
Для того, чтобы записать звук, нам необходимо преобразовать его в набор нулей и единиц. В случае с форматом WAV делается это наитупейшим образом: входящий звуковой поток разбивается на малейшие отрезки (кванты, отсюда термины «частота квантования», «частота выборки» или "частота дискретизации") и в каждый такой отрезок времени пишется текущее значение аналогового сигнала в двоичной форме. Файлы формата WAV могут быть записаны с частотой дискретизации, к примеру, от 8 кГц до 192 кГц, но, де-факто, стандартом считается частота выборки в 44.1 кГц.
Следует отметить, что WAV, как контейнер, поддерживает и другие способы хранения аудио-информации: к примеру, ADPCM, который способен, в зависимости от полосы пропускания, кодировать аудио-данные с переменной частотой дискретизации.
Частота 44.1 кГц произошла не случайно. Если допустить неточности в описании, то данная цифра произошла как утверждение теоремы Котельникова: для сохранения максимально правильной формы волны при частотах до 20 кГц (теоретический предел слышимости человеческого уха) необходима частота дискретизации вдвое выше — 40 кГц. Собственно, частота именно в 44.1 кГц обусловлена техническими аспектами, подробности которых можно прочитать здесь.
В каждом таком отрезке в двоичной форме кодируется фактическое напряжение аналогового сигнала: наивысший уровень можно представить в виде «1111», наинизший — в виде «0000». И вот здесь вступает в игру второй параметр — глубина звучания, определяющая, насколько точно будет оцифровано значение волны в отрезок времени. Зачастую файлы формата WAV пишутся с разрядностью в 16 бит или 32 бит. Выше разрядность — точнее запись.
Кстати, о PCM. Что из себя представляет запись на обыкновенном компакт-диске, которые были так популярны после аудиокассет? Именно — поток несжатых нулей и единиц в формате PCM. Разрядность — 16 бит, частота выборки — 44.1 кГц. Какой тогда битрейт будет у такой записи?
- 44100 раз в секунду пишется 16-битное число. 44100 * 16 = 705600 бит/с для одного канала;
- для стерео-записи данное значение умножается на 2 — 1411200 бит/с или наши ~1411 кбит/с;
- для 32-разрядной записи это значение будет в два раза больше — ~2822 кбит/с.
Вывод: отсюда прожорливость данных файлов к свободному пространству на жёстком диске, но в качестве выигрыша — полное отсутствие потерь при записи и прослушивании аудио-файла.
1.2. Сжатие без потерь
О сжатии без потерь я не буду много писать. С этим термином можно ознакомиться здесь. Фактически, данный метод представляет собой, говоря грубо, архивацию аудиозаписи алгоритмами, заложенными в кодек, но данные при этом не теряются и сохраняется возможность восстановить аудио-запись с точностью бит-в-бит. При декодировании таких форматов мы получаем, фактически, тот же WAVE-формат, только он занимает меньше дискового пространства; сжатие — приблизительно двухкратное и зависит от характера кодируемой композиции. При прослушивании записи кодек производит «разархивирование» композиции и шлёт поток несжатых нулей и единиц на обработку звуковой карте.
Таких кодеков существует достаточно много: это FLAC (Free Lossless Audio Codec), разработанный организацией Xiph (она же и разработала Opus), ALAC (Apple Lossless) от одноимённой компании, APE (Monkey's audio), WV (WavPack) и прочие, менее известные форматы сжатия аудио без потерь.
1.3. Сжатие с потерями — обманываем свой слух
Учёные умы начали задумываться о том, что, в принципе, часто нет смысла сохранять полную информацию об аудиозаписи, так как наше ухо несовершенно. Оно может не слышать тихих звуков после громких, оно может не слышать слишком высокие и слишком низкие частоты и так далее. Эти феномены называются эффектом маскировки.
В итоге поняли: можно ведь выбросить здесь, подрезать там, а слушатель практически ничего не заметит — несовершенное ухо просто даст возможность слушателю обмануть себя. Следовательно, появляется возможность избавиться от психоакустической избыточности в файле.
Собственно, психоакустика существует как дисциплина и изучает психологические и физиологические особенности восприятия звуков человеком. Собственно, эти психоакустические модели и были заложены в основу работы программ сжатия с потерями и одним из первых таких форматов стал MPEG 1 Layer III или просто MP3. Здесь же оговорюсь, что маркетинг, оперирующий фактами практически без преувеличения, сделал своё дело: аудио-файл занимает в десять раз меньше места (с оговоркой: это при кодировании с битрейтом в 128 кбит/с, что позволяет получить «приемлемое для типичного слушателя качество» — вспоминаем 1411 кбит/с для WAVE), а, следовательно, на компакт-диск или на жёсткий диск поместится уже на порядок больше аудио-записей. Фурор! Популярность формата взорвала индустрию цифровой звукозаписи. В периоды не самых быстрых подключений к сети Интернет передавать подобные файлы стало как нельзя удобно. Удобно передавать, удобно хранить, удобно закинуть пачку композиций себе на плеер. Создано множество аппаратных декодеров формата MP3, в связи с чем файл проигрывался чуть ли не на
На момент написания данной статьи уже истекли сроки патентных ограничений и лицензионные сборы прекращены.
Что же касается сжатия с потерями и каким образом получается сжать аудио-файл на порядок без существенной потери для слушателя качества? Если вкратце, от одного кодека к другому нижеследующая последовательность мало отличается. Описание данного процесса упрощено до безобразия, но его течение приблизительно таково:
- входящий поток несжатых данных разбивается равные отрезки — на кадры (фреймы);
- для того, чтобы создать непрерывный участок спектра, для анализа, помимо уже выбранного кадра, берётся предыдущий и следующий кадр;
- сжатие №1: участок проходит через MDCT (модифицированное дискретное косинус-преобразование). Говоря грубо, это преобразование проводит спектральный анализ звукового сигнала — оно даёт возможность получить информацию о том, насколько велика энергия звука в каждом отрезке спектра.
В случае с Layer III производится второе MDCT-преобразование, которые повышает эффективность кодирования высоких частот на более низких битрейтах — это оказалось серебряной пулей для взрыва популярности данного кодека.Спасибо пользователю interrupt за поправку: MPEG 1 Layer III использует гибридный подход для преобразования аудио-данных: сначала спектр кодируемого аудио-файла разделяется на множество спектральных полос, как это происходит в SBC (Sub-band coding, англ.); каждая из этих полос преобразуется MDCT к частотному виду, который, собственно, уже даёт конкретную информацию о том, какие частоты и с какой энергией, присутствуют в кадре. - Результат анализа MDCT передаётся психоакустической модели, которая является чем-то вроде «виртуального уха». На данном этапе даются ответы на вопросы, что оставлять, а что можно выбросить из аудио-сигнала без существенного ущерба для восприятия.
- сжатие №2: кадр, который прошёл через такое преобразование, может быть сжат с использованием кодов Хаффмана; фактически, если опять говорить грубо, каждый кадр дополнительно архивируется, избавляясь от избыточности. Это похоже на что-то вроде упаковки длинных цепочек нулей и единиц в более короткий формат;
- кадры склеиваются; в каждый такой кадр добавляется необходимая информация для кодека:
- номер/размер кадра;
- версия формата (MPEG1/2/2.5);
- версия слоя (Layer I/II/III);
- частота дискретизации;
- режим стерео-базы (моно, стерео, совмещённое стерео).
Следует отметить факт того, что формат MP3 не лишён существенных недостатков, при этом сам формат уже не позволяет должным образом расширять его возможности. Возьмём, к примеру, такое явление как pre-echo. Феномен данного артефакта сжатия кратко и достаточно неплохо описан здесь, но его суть заключается в искажении резко нарастающих относительно тишины звуков, например, инструмента Hi Hat. При кодировании такого инструмента в тишине, из-за особенностей работы MDCT, резкий переход будет создаваться с множеством колебаний. В исходной записи этих колебаний не существует, но при их наличии в результирующей записи они достаточно отчётливо улавливаются ухом. Современные кодеки, такие как AAC и OGG также не лишены этого недостатка, но стараются бороться с ними, применяя более точные и совершенные алгоритмы. А вот MusePack (о нём ниже), к примеру, данного недостатка лишён, так какне использует для повышения эффективности второе MDCT-преобразованиеиспользует SBC вкупе с очень качественной психоакустической моделью, чем и объясняется его качественное кодирование лишь начиная с битрейтов в 160 кбит/с. Редко, но метко: с таким битрейтом кодек кодирует аудио лучше, чем MP3 с аналогичным битрейтом.
Нельзя не отметить, что разработчики свободного кодека Lame всё же пытаются совершенствовать своё детище, улучшая психоакустические модели и алгоритмы кодирования с переменным битрейтом; релиз версии 3.100 представлен в декабре 2017 года.
Подробную информацию о том, как внутри устроен MP3 с точки зрения формата кадров, можно почитать здесь.
А вот потрясающую статью (а, точнее, её перевод) о том, как работает сжатие аудио кодеком MP3, можно прочитать здесь. Рекомендую!
1.4. Кодирование с потерями совершенствуется: краткое описание формата AAC
На момент написания статьи кодеку MP3 уже более 23 лет. Дабы не повторяться со статьёй (её более новая версия), где уже описаны кодеки OGG Vorbis (и снова привет организации Xiph — это также её разработка), MPC (Musepack), WMA (Windows Media Audio) и AAC, я опишу здесь вкратце формат AAC с точки зрения технологий, которые являлись до недавних пор передовыми в сфере кодирования с потерями.
По моему скромному мнению, AAC (Advanced Audio Codec) — один из самих продвинутых форматов в области кодирования данных. Опишу основные особенности данного формата, начиная с популярных профилей, которые можно представить матрёшкой (см. рис. ниже):
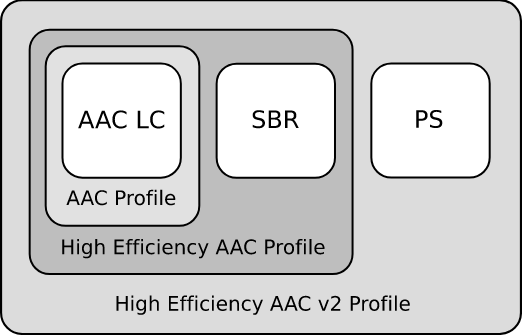
Рис. 1.2 — Иерархия профилей AAC, источник — Википедия
— Low Complexity Advanced Audio Coding (LC-AAC)
Низкая сложность декодирования отлично подходит для реализации аппаратного кодека; аппаратные требования к ЦПУ и ОЗУ также низки, что и снискало большую популярность к этому профилю. Достаточно эффективно кодирует сигнал с 96 кбит/с.
— High-Efficiency Advanced Audio Coding (HE-AAC).
Профиль HE-AAC является расширением LC-AAC и дополнен запатентованной технологией SBR (Spectral Band Replication, груб. — «спектральное повторение», статья на английском). Именно технология спектрального повторения позволяет «сохранить» высокие частоты при кодировании с низкими битрейтами.

Рис. 1.3 — Графическое изображение принципа восстановления высоких частот
Почему «сохранить» — в кавычках? Потому что царь — не настоящий: кодек отводит место для дополнительной информации, которая используется синтезатором кодека для восстановления высоких частот, но так как эти частоты синтезируются, то бишь воссоздаются кодеком, они, фактически, являются приблизительной копией высоких частот, которые существовали в исходном файле. На практике, сигнал, кодированный битрейтом 48 кбит/с будет звучать, например, аналогично формату mp3@98 кбит/с, если это поддерживается декодером; в противном случае такой файл будет проигрываться попросту без восстановления высоких частот и его битрейт будет соответствовать его качеству, аналогичному mp3.
— High-Efficiency Advanced Audio Coding Version 2 (HE-AACv2)
Данный профиль относительно молодой (описан в 2006 году), он создан для более эффективного кодирования аудио в условиях низкой пропускной способности.
Вторая версия профиля является расширением, собственно, первого профиля, изменения заключаются в добавлении технологии PS (Parametric Stereo). Принцип несколько похож на технологию SBR: кодек также отводит место под информацию для восстановления стерео-базы, жертвуя аккуратностью.

Рис. 1.4 — Графическое изображения кодирования параметрического стерео
Условия для работы данного профиля такие же, как и для вышеописанного HE-AAC; отсутствие поддержки профиля декодером приведёт к тому, что запись будет звучать в моно.
— AAC-LD (Advanced Audio Coding — Low Delay)
Профиль AAC-LD имеет усовершенствованные алгоритмы кодирования для уменьшения задержек (до 20 мс.);
— AAC-ELD (Advanced Audio Coding — Enhanced Low Delay)
Данный профиль, который наследует все возможности HE-AACv2 (используются аналоги технологий SBR и PS, но спроектированные для низких задержек);
— AAC Main Profile
Данный профиль был представлен как MPEG-2 AAC или HC-AAC (High Complexity Advanced Audio Coding). Не совместим с LC-AAC;
— AAC-LTP (Advanced Audio Coding — Long Term Prediction)
Этот профиль более сложный и ресурсоёмкий (но и более качественный), чем все остальные. Также не совместим с LC-AAC.
Вот и всё, что я хотел написать об этом кодеке. Основной акцент я сделал на технологии, которые используются в различных профилях AAC (которые, кстати, порождают множество аббревиатур: AAC, LC-AAC, eAAC+, aacPlus, HE-AAC и т.д.), так как буду сравнивать их с таковыми в Opus, но кодек делает своё дело: он широко используется в интернет-радио, а также в технологиях цифрового радио-вещания: DRM (Digital Radio Mondiale) и DAB (Digital Audio Broadcasting) (ознакомиться с этими технологиями можно здесь), YouTube, как аудио-дорожка к множеству роликов в контейнерах mp4, mkv и пр.
2. Введение в Opus: описание формата

Рис. 2.1 — Логотип Opus
21 декабря 2017 года организация Xiph представила бета-версию аудиокодека Opus версии 1.3. Я не буду вдаваться в высокие материи при описании данного кодека, так как подобная информация находится в свободном доступе (например, здесь, здесь, а для знающих английский — здесь и здесь.)). Информацию о релизе этой бета-версии можно найти здесь. Здесь я отмечу, что данный кодек является замечательным кандидатом на замену остальных кодеков. У него немало достоинств:
- битрейт от 6 до 510 Kbit/s;
- частота дискретизации от 8 до 48KHz;
- поддержка постоянного (CBR) и переменного (VBR) битрейтов;
- поддержка узкополосного и широкополосного звука;
- поддержка голоса и музыки;
- поддержка стерео и моно;
- поддержка переменного битрейта (VBR);
- возможность восстановления звукового потока в случае потери кадров (PLC);
- поддержка до 255 каналов;
- доступность реализаций с использованием арифметики с плавающей и фиксированной запятой.
Кодек распространяется под лицензией BSD и полностью избавлен от всех патентных преследований, а также утверждён в качестве интернет-стандарта. Opus можно использовать в любых своих проектах, включая коммерческие, без необходимости открытия исходных текстов. На данный момент кодек используется в мессенджере Telegram для реализации VoIP, в проекте WebRTC, для кодирования аудио-дорожки в видео YouTube и т.д. Перспективы данного кодека не стоит недооценивать.
Может возникнуть резонный вопрос: что такого особенного в вышеописанных тезисах? Всё это есть практически в любом более-менее современном кодеке. Ответы последуют далее в статье.
Одна из ключевых особенностей данного кодека — чрезвычайно низкие задержки кодирования: от 2.5 мс. (!) до 60 мс, что просто необходимо, как воздух, приложениям, позволяющим пользователям общаться голосом в сети Интернет. Такие низкие задержки также позволяют строить интерактивные приложения, например, цифровую звуковую студию для совместного написания музыки или что-то в этом роде. Стоит отметить, что по этому параметру кодек конкурирует с относительно новым профилем AAC-ELD, описанному выше; тем не менее, минимальная задержка алгоритмов кодирования составляет прибл. 20 мс., что ни чуть не является проблемой для свободного, открытого и бесплатного кодека Opus.
Я не буду рассматривать все тонкости, связанные с кодированием аудио этим кодеком, но ниже опишу режимы, которые меняются кодеком в зависимости от смены битрейта.
2.1. Opus: режимы кодирования
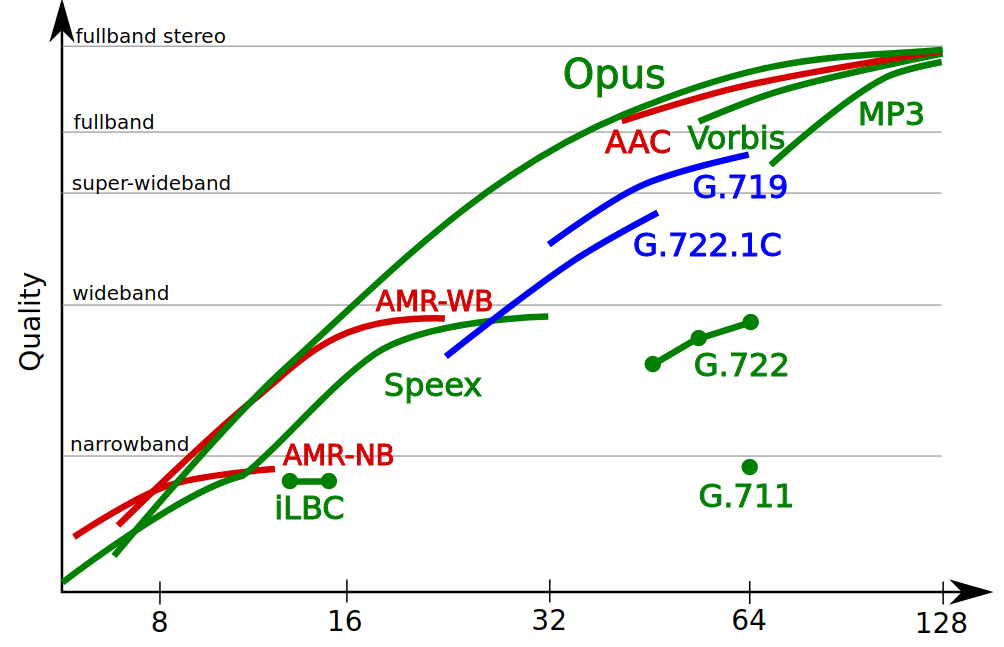
Рис. 2.2 — Сравнение качества кодирования различными кодеками — официальный график с сайта opus-codec.org
После выхода данной бета-версии мне стало интересно, как меняются режимы кодирования в зависимости от битрейта, поэтому я и решил провести эксперименты, начиная с самых низких битрейтов, но только с ними. Проводить эксперименты с более высокими битрейтами я не вижу смысла — это отлично описано в статьях (например, здесь).
Сейчас же перечислим те режимы, которыми оперирует кодек:
- Режим кодирования сигнала — LP, hybrid, MDCT:
- LPC или LP (кодирование с линейным предсказанием, статья на английском) используется в кодеках сжатия голоса и позволяет кодировать голос с достаточным для восприятия качеством, используя при этом очень низкие битрейты. Используется в кодеках GSM, AMR, SILK (также используемый в Skype), Speex (и снова привет Xiph; правда, она объявила кодек как «deprecated» и рекомендует использовать Opus). В кодеке Opus для кодирования голоса на низких битрейтах используется модифицированный кодек SILK, который не является обратно совместимым с таковым в Skype;
- MDCT (модифицированное дискретное косинус-преобразование) — разновидность преобразования Фурье (о нём можно почитать здесь), используется практически во всех кодеках для сжатия музыки с потерями (lossy compression): MP3, AAC, OGG Vorbis и т.д. В кодеке Opus используется кодек CELT (статья на английском);
- Hybrid mode (гибридный режим кодирования) является разработкой организации Xiph и заключается в том, что для кодирования нижней части спектра сигнала (до 8 кГц) используется LP, а для верхнего (от 8 кГц и выше) — MDCT, а на выходе получаем компромиссное качество звука при сохранении достаточно низкого битрейта.
- Стерео-база:
- кодирование в режиме моно;
- кодирование в режиме стерео;
- кодирование в режиме совмещённого стерео (Joint Stereo).
- Исходя из вышеперечисленного — изменение ширины спектра в зависимости от битрейта:
- Narrowband (узкополосное кодирование) — кодирование сигнала с шириной спектра до 6 кГц, соответствует качеству кодирования кодеками GSM и AMR-NB;
- Wideband (широкополосное кодирование) — кодирование сигнала с шириной полосы от 6 кГц до 14 кГц, соответствует качеству кодирования кодеком AMR-WB (или так называемый операторами "HD Voice"), который используется ныне в сетях третьего поколения (3G);
- Fullband (полное кодирование полосы) — сохранение всей слышимой человеческим ухом полосы (от 20 Гц до 20 кГц), моно-сигнал;
- Fullband stereo — см. выше, но стерео-сигнал.
2.2. Низкие битрейты — высокие частоты. Как достигнуты такие результаты?
В начале данной статьи я не зря рассматривал кодек AAC и его навороченные профили, которые, фактически, строят стерео-базу и восстановление высоких частот, что называется, «из воздуха». Утрирую, конечно, но выражение недалеко от истины. Но вот беда: кодек покрыт патентами и является проприетарной разработкой альянса из компаний Bell Labs, Института интегральных схем общества Фраунгофера (который, кстати, и является ключевым создателем формата MP3), Dolby Laboratories и т.д. Следовательно, использование данных технологий потребует лицензионных отчислений, что недопустимо для полностью открытого и свободного кодека. Поэтому разработчики Opus пошли иным путём: они реализовали собственные алгоритмы воспроизведения высоких частот — Band Folding (Spectral Folding, Hybrid Folding). Об этом подходе кодирования высоких частот можно ознакомиться, соответственно, здесь (там даже интерактивные картинки есть), здесь (см. 4.4.1) и здесь. Кодек не синтезирует высокие частоты из дополнительных данных, как это делает HE-AACv2, он берёт за основу сам сигнал, исходя из энергии в области высоких частот, закодированной в оригинальном сигнале. Слепое тестирование со стороны энтузиастов показывает, что данный метод очень эффективен, не говоря уже о том, что подобный метод такого воспроизведения высоких частот, по заверениям разработчиков, более прост в исполнении, нежели SBR или его аналог и реализуем с меньшими алгоритмическими задержками.
К слову: результаты слепого тестирования можно посмотреть на графиках по следующей ссылке.
Давайте же испытаем это последнее слово в области сжатии звука с потерями.
2.3. Opus: инструменты для кодирования и тестирования
Данное тестирование проводилось на коротком отрывке из аудиокниги Вадима Зеланда — Трансерфинг реальности. Книга была озвучена российским актёром и радиоведущим Михаилом Черняком, который обладает приятным тембром голоса.
Как был получен отрывок?
- Утилитой «youtube-dl» был скачан фрагмент файла формата WebM — контейнер, в котором присутствует только аудио-дорожка:
youtube-dl "https://www.youtube.com/watch?v=_-OUXW3a0Yw" -f 250
- Фрагмент был перекодирован в формат WAV для скармливания его кодеку opusenc (исходный файл был переименован для удобства):
ffmpeg -i tr1_original.webm -acodec pcm_s16le tr1.wav - Чтобы не заморачиваться с кодированием множества файлов с разными битрейтами, я воспользовался простой однострочной программой на языке Bash и получил на выходе множество необходимых мне файлов:
for i in `seq 8 21`; do opusenc --bitrate $i tr1.wav tr-enc-${i}.opus ; done - все эти файлы были импортированы в Audacity и в проигрыватель Qmmp, чтобы оценивать качество звучания на слух и визуально оценивать соответствующую дорожку.
Рис. 2.3 — Результат выполнения скрипта — скриншот программы Dolphin
Дальше пойдёт описание практически каждой из них — с приложением скриншотов и субъективного описания звучания, после чего последуют небольшие выводы.
3. Оценка звучания кодированных дорожек
По-хорошему, оценка звучания должна быть объективной и проводиться, к примеру, с использованием метода слепого ABX-тестирования (статья на английском). Тестирование проводится для того, чтобы исключить эффект пустышки (плацебо).
Если вкратце, суть метода заключается в прослушивании при помощи вспомогательного ПО (Foobar или аналогичное веб-приложение, см. прим. на рис. 3.1) двух семплов: референсного и сжатого — кнопки А и В соответственно. Слушатель заранее не знает, какой из них является сжатым, а какой — референсным.
Рис. 3.1 — Пример внешнего вида одной из программ слепого ABX-тестирования
Далее слушатель прослушивает аудиозапись, подставленную программой под кнопку Х и пытается определить: к какому из двух семплов (А или В) относится семпл на кнопке Х. После выбора ответа слушателем цикл повторяется определённое количество раз, после чего программой выводится результат, где показано, с какой вероятностью слушатель нажимал кнопки случайно.
Стоит оговориться, что существуют люди, которые не воспринимают эффекты психоакустической компрессии и, фактически, не могут отличить, например, запись mp3@128 кбит/с от FLAC — для них оба файла звучат «замечательно». Таких людей немало и для них 128 кбит/с — полностью прозрачное звучание, так как они не задумываются над тем, какие там артефакты и как они звучат. Музыка есть? Инструменты слышны? Отлично. Это ещё одна из причин высокой популярности формата MP3.
Я принципиально не проводил слепое ABX-тестирование, но пожелал описать субъективное восприятие звука с приведением скриншотов спектрограммы каждого семпла в надежде, что читателям данной статьи это будет интересно.
Поехали.
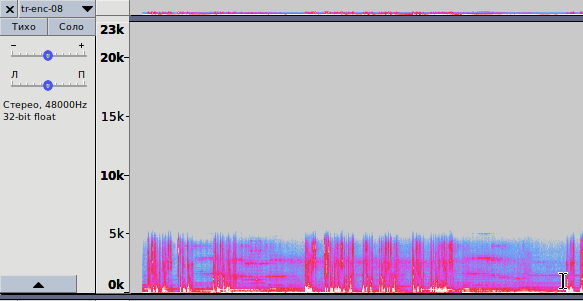
Рис. 3.2 — Спектрограмма записи, кодированной с битрейтом 8 кбит/с
opus-enc-8.opus
1. На рис. 3.2 показана спектрограмма для кодирования практически с самым низким битрейтом. Аудио-файл кодируется методом LP, кодек отводит спектр частот в 6 кГц; всё, что выше — обрезается. В итоге размер файла чрезвычайно мал, качество звучания соответствует таковому с кодеком AMR-NB (Narrowband). Классика жанра в сетях сотовой связи второго поколения (GSM). Поведение кодека Opus соответствует вышеописанному в диапазоне битрейтов от 6 до 9 кбит/с.
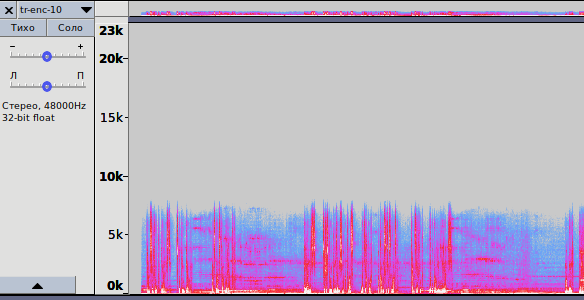
Рис. 3.3 — Спектрограмма записи, кодированной с битрейтом 10 кбит/с
opus-enc-10.opus
2. На рис. 3.3 показана спектрограмма для кодирования с битрейтом в 10 кбит/с. Та же ситуация: кодирование методом LP, но спектр частот уже шире — до 8 кГц. По звучанию — среднее между AMR-NB и AMR-WB.

Рис. 3.4 — Спектрограмма записей, кодированных с битрейтами 12 и 13 кбит/с
opus-enc-12.opus
opus-enc-13.opus
3. На рис. 3.4 показано две спектрограммы: для битрейтов 12 и 13 кбит/с соответственно. Здесь ситуация интереснее: при 12 кбит/с используется всё то же LP, но ширина спектра расширена ещё больше: до 10 кГц и звучание практически идентично таковому в AMR-WB.
Начиная с битрейта 13 кбит/с кодек переключается в гибридный режим и начинает использовать сразу три метода: LP, MDCT и Band Folding. Всё, что лежит в диапазоне от 0 до 8 кГц, кодируется LP, от 8 до 10 кГц — MDCT; именно этот отрезок спектра в 2 кГц используется как исходная информация для использования Band Folding — отсюда получаем фактически восстановленные высокие частоты, вплоть до 20 кГц.
Отчётливо видны «мазки» вдоль записи, начинающиеся с 10 кГц; видна попытка кодека сохранить максимум информации о высоких частотах. Интересно, что уже при 13 кбит/с. кодек в гибридном режиме, с использованием Hybrid Folding, пытается работать в режиме Fullband, восстанавливая спектр вплоть до 20 кГц.
Что же по поводу звучания? Звучание голоса просто Фантастическое — с большой буквы Ф. На такой результат не способен даже HE-AAC с его SBR — даже близко не способен. Высокие частоты, в области которых находятся шипящие, свистящие, цокающие (Ш, Щ, С, Ц) звуки воспроизводятся потрясающе, слушать человеческую речь — приятно. Не забываем про цифру «13 кбит/с», а ведь с таким битрейтом раньше работали кодеки GSM (AMR-NB), где толком и не разобрать, где «Ш», а где «С»…
Тем не менее, не стоит забывать, что для кодирования музыки такой режим всё ещё плохо подходит: из-за кодирования нижней части спектра методом LP в области нижних частот присутствуют существенные искажения, особенно, в области перехода, где голоса нет, но слышен соответствующий данной области FX-эффект «атмосферного ржавого скрипа».

Рис. 3.5 — Спектрограмма записей, кодированных с битрейтами 14 и 15 кбит/с
opus-enc-14.opus
opus-enc-15.opus

Рис. 3.6 — Обратите внимание на выделенную область FX-эффекта
4. На рис 3.5 видно, как меняется способ кодирования сигнала от перехода к более высокому битрейту — с 14 до 15 кбит/с. Пока спектрограмма записи для битрейта в 14 кбит/с похожа на вышеописанную с 13 кбит/с, то начиная с битрейта в 15 кбит/с использование гибридного режима прекращается и кодек полностью полагается на MDCT и Band Folding.
Почему я так решил? Потому что при прослушивании записи в области FX-эффектов все искажения, которые присущи LP, пропадают. Да и если присмотреться на спектрограмму обеих записей (см. также рис. 3.6), то можно увидеть, что точность воспроизведения спектра увеличена. Однако, характерный «мазок», разделяющий спектр пополам, в области 10 кГц, можно увидеть в обоих случаях.
Это как раз тот случай, когда качество здесь сопоставимо с таковым у mp3@80 кбит/с, если не выше. Опять-таки, не имею права ставить свои суждения истиной в последней инстанции, так как не проводил слепое ABX-тестирование.
5. Начиная с битрейта в 18 кбит/с (opus-enc-18.opus), последнего становится достаточно для того, чтобы переключиться в режим Fullband Stereo, а это означает, что на данном битрейте можно получить «приемлемое» качество записи в условиях очень малой пропускной способности сети. Нет, это не фиаско, братан, это победа!
Далее всё достаточно просто: пропорционально, с увеличением битрейта, кодек всё реже использует Band Folding, так как, собственно, битрейт становится достаточным для того, чтобы закодировать более высокие частоты без надобности в их искусственном восстановлении. Чем выше битрейт — тем более широкий спектр будет закодирован без применения Band Folding.
4. Вместо заключения
Что же касается меня, то тот «порог прозрачности» (или «Transparency», как это называют носители английского языка), который выражается в моей неспособности отличить оригинал от сжатого аналога — прибл. 170 кбит/с. Для mp3 этот параметр лежит в пределах 224-256 кбит/с, в зависимости от характера музыки.
Что же тут сказать. Технологии стремительно развиваются. И не только технологии сжатия аудио-данных — все технологии, не побоюсь обобщить. Особенно приятно, что такие качественные технологии, которые позволяют так качественно обмануть человеческое ухо и позволяющие быть настолько универсальными, также развиваются и остаются свободными и открытыми. Спасибо разработчикам и тем потрясающим людям, которые творят и двигают прогресс. А также спасибо всем за внимание и всем, кто осилил статью до конца.
P.S.: В статью будут вноситься правки при обнаружении существенных неточностей; будут исправляться синтаксические и семантические ошибки.
P.P.S.: Ссылка на мою собственную статью, написанную с использованием сервиса telegra.ph. Она нигде не публиковалась, является моей авторской работой (автора можно проверить) и является более старой версией текущей статьи.
Комментарии (21)

interrupt
12.01.2018 19:12+2Ох, опять эта копипаста про «второй MDCT» (( Попробую расписать кратко.
В неком приближении, кодеки можно разделить на Subband, Transform, Hybrid
Subband — в них исходных PCM сигнал разбивается по частотам на набор PCM сигналов. При этом так же происходит децимация — поэтому возможен алиасинг. Как правило используется PQMF filterbank. Еще раз, важно, после разбиения мы так и остаемся во временной области, просто имея несколько PCM сигналов. Дальше каждый такой сигнал можно квантовать с разной точностью, так чтоб шумы квантования были ниже порога маскировки, определяемого психоакустикой. Можно дополнительно применить ADPCM сжатие к тем диапазонам где это эффективно (так DTS делает), и т.д. К subband кодекам относятся MPEG1 Layer1, Layer2, Musepack, DTS, apt-x.
Transform — Тут, как и написано, в основе MDCT преобразование, которое преобразует сигнал в частотную область. Почему MDCT, а не скажем FFT? Основная причина — MDCT позволяет эффективно бороться с согласованием на границе блоков. Плюс, не надо отдельно что то делать с комплексной частью (в результате MDCT для N входных чисел получается N/2 выходных). Далее полученные после mdct, коэффициенты можно квантовать (в самом простом случае) или попробовать дополнительно обработать. Важно — основная работа тут происходит в частотной области. К таким кодекам относятся AC3, Vorbis, AAC (большенство профилей), CELT.
Hybrid (не тот который в opus) — гибрид этих подходов — вначале разбиваем на поддиапазоны (PQMF или QMF), а затем каждый отдельно преобразуем в частотное представление (MDCT). В принципе, это позволяет иметь лучшую локализацию частоты в результирующем спектре, так же это могдо бы позволить иметь разные размеры окна MDCT преобразования в разных поддиапазонах (ATRAC так делает), ну и т.д. Но в моем понимании, проблемы с из за алиасинга превосходят возможный профит, cейчас такой подход считается не удачным. К таким кодекам относятся Mpeg1 Layer3, ATRAC, AAC-SSR профиль.
Как видим, нет «Второго MDCT».Zeben Автор
13.01.2018 21:12Я не разобрался в подобных тонкостях и рад, что Вы указали на это. Я помню, что вещи, которые происходят в таких кодеках как MPEG Layer I/II и Musepack, происходят также и в SBC, используемый по умолчанию в Bluetooth-профиле A2DP, верно? Также я понял, что MDCT в большинстве случаев используется только потому, что с результатами преобразования данным подходом проще работать с точки зрения реализации алгоритмов.
Я поправлю в статье нюанс со вторым MDCT, чтобы не вводить читателей в заблуждение.
Спасибо, очень подробно и доходчиво описано.interrupt
15.01.2018 15:16SBC детально не смотрел, судя по описанию в википедии да. А вот Apt-x на днях в ffmpeg залили — можно поизучать код.
Работать с MDCT не то что проще (кстати часто наоборот, например MDCT спектр синусоиды зависит от фазы, собственно часто психоакустика работает с FFT спектром), MDCT решает проблему артефактов на границе блоков. Про MDCT есть приличное видео с примерами www.youtube.com/watch?v=xLzkLc33S_U.Zeben Автор
15.01.2018 16:05Посмотрел видео. Спасибо, очень интересный материал. И в публикацию, кстати, внёс поправки.
У меня есть вопросы к Вам (да и ко всем, кто ознакомился с материалом).
Публикация затрагивает только кодирование голоса. При кодировании музыки я получил не менее интересные результаты. Стоит ли расширить публикацию нюансами кодирования музыки? Стоит ли дополнить её семплами, закодированными при помощи, к примеру, того же neroAacEnc, а может даже дополнить её спектрограммами? Стоит ли добавить картинку и кратко дополнить применение MDCT, чтобы у читателя имелось представление, для чего это необходимо (переход из амплитудной плоскости в частотную)?
Впрочем, есть подозрение, что эти дополнения будут уже не так интересны читателям.
Голосовалку решил не ставить.interrupt
15.01.2018 17:38Зависит от задачи которую вы преследуете. Если по мне, то не стоит смешивать теоретические основы и примеры кодирования продвинутыми (а opus действительно крут) кодеками в одной статье. Может сложится ложное представление, что MDCT решает все проблемы. Если Вы пишите про основы (а MDCT, QMF, психоакустика на уровне определения порога маскировки — это только основы), то уместнее приводить работу более простых кодеков, например, можно обратить внимание на артефакты вызванные теми или иными преобразованиями (например послушать результат работы mdct кодека при занулении части коэффициентов). Opus и AAC достаточно много всего делают помимо MDCT чтоб достичь своих результатов. Но это все IMHO.
Zeben Автор
15.01.2018 18:51На самом деле дельный совет.
Конкретную задачу, честно говоря, я не преследовал, только экспериментирование и сравнение кодеков. Судя по всему, в текущем виде публикация готова и стоит подумать, о чём ещё интересном стоит написать. В любом случае, пока писал и пока читал комментарии — узнал много нового; оно того стоило. :)
И снова спасибо.

SADKO
12.01.2018 22:27Яростно плюсую, ибо эта «копипаста» уже, блин традиция!
PS. Однако замечу, что первый ATRAC был очень даже subband причём весьма остроумный и хитроделанный, у него была очень простая и красивая аппаратная реализация, и никакого альясинга, дьявол в деталях…interrupt
12.01.2018 23:58Спасибо.
Декодер ATRAC реализован в ffmpeg, на гитхабе есть экспериментальная реализация кодера (atracdenc), так что там все более менее понятно. В первом ATRAC стекирование из 2х QMF, вначале разбиваем на HF и LF, затем еще раз LF. В HF компенсируем задержку. Получаем 3 бенда. Потом каждый бенд подаем на MDCT, в каждом бенде можно независимо переключаться между коротким и длинным окном. Тонкость — длинное окно там с меньшим чем 50% перекрытием. Полученные после MDCT коэффициенты группируются, квантуются. Хафмана или какого либо иного VLC кодирования нет. Так что, вполне себе гибрид.
dmitry_dvm
12.01.2018 22:36Большая работа проделана, спасибо за хорошую статью. Раньше заморачивался с кодеками, в итоге пришел к лосслесс. Кодирую флак/ape/alac в wma lossless, чтобы слушать из облака через Groove. Хоть и место жрет, но на больших колонках отчетливо слышно разницу между мп3-320 и лосслесс. И чем больше колонки, тем сильнее слышно.
Кстати, может кто знает — чем еще можно слушать напрямую из облака (в частности OneDrive)? Для aimp попробовал плагин, но что-то он нестабильный и перематывать нельзя.
VEG
13.01.2018 12:36Хоть и место жрет, но на больших колонках отчетливо слышно разницу между мп3-320 и лосслесс. И чем больше колонки, тем сильнее слышно.
Исключая наличие у вас экстрасенсорных способностей, напрашивается предположение, что вы неправильно провели тест. MP3 320kbps (при верном кодировании) должно быть прозрачным, то есть неотличимым от оригинала на слух. Тест должен проводиться «в слепую», то есть вы не должны знать, в каком именно формате записано то, что вы слышите. При этом MP3 320kbps должен быть получен (при помощи LAME) из того же исходного файла, с которым потом будет производиться сравнение, чтобы гарантировать что используется одна и та же аранжировка, и что этот MP3 320kbps получен не из какого-нибудь MP3 128kbps, что встречается повсеместно в сети.dmitry_dvm
13.01.2018 20:25Мне не нужны экстрасенсорные способности, чтобы слышать разницу. Вы слушали мп3 на больших колонках? Под большими я имею в виду какие-нибудь клубные Turbosound. Слушали и не услышали разницу? Поздравляю. А я слышу. Звук тупо глухой.
iDm1
16.01.2018 11:52Это может быть связано с ошибками при кодировании mp3 или же при его декодировании на устройстве воспроизведения. Если все будет работать корректно, то разницу в слепом прослушивании вы не услышите ни на каком оборудовании.
Rsolars
15.01.2018 12:06-1Сама логика «слепых тестов» ущербна. Музыка — не поток информации, сообщаемой вам. Сравнивать нужно по воздействию на человека, а не путём слухового анализа каких-то составляющих звука. Послушайте пару недель только mp3 а потом только lossless. Вот тут то и будет разница.
Rsolars
12.01.2018 23:26Отличная статья, написана очень хорошим языком, понятным и не занудным. Спасибо автору!
RomanKharin
13.01.2018 20:58А существет ли подобный и подробный анализ codec2?
Zeben Автор
13.01.2018 21:00Не уверен, если честно. Я находил статьи на Хабре на эту тему, но конкретные эксперименты мне на глаза не попадались. Я бы с радостью это провёл, но с описанием физики процесса кодирования сигнала codec2 у меня будут большие проблемы — я не математик.
mistergrim
> Файлы формата WAVE
Если вы имели в виду файлы WAV, то вы спутали формат и контейнер. В WAV можно запихать много чего, кроме несжатого звука.
rub_ak
PCM упаковывается в wav или, что вы имели в виду под несжатым звуком?
mistergrim
PCM упаковывается не только в WAV.
В WAV упаковывается не только PCM.
Zeben Автор
Да, я в этом постоянно путаюсь. Да, я имел в виду обычный WAV, без всякого сжатия и нюансов вроде ADPCM. Могу поправить статью, спасибо.