
Недавно мне понадобилась библиотека для исправления опечаток. Большинство открытых спелл-чекеров (к примеру hunspell) не учитывают контекст, а без него сложно получить хорошую точность. Я взял за основу спеллчекер Питера Норвига, прикрутил к нему языковую модель (на базе N-грамм), ускорил его (используя подход SymSpell), поборол сильное потребление памяти (через bloom filter и perfect hash) а затем оформил всё это в виде библиотеки на C++ со swig биндингами для других языков.
Метрики качества
Прежде чем писать непосредственно спеллчекер нужно было придумать способ измерить его качество. Норвиг для этих целей использовал готовую коллекцию опечаток, в которой дан список слов с ошибками вместе с правильным вариантом. Но в нашем случае этот способ не подходит по причине отсутствия в нём контекста. Вместо этого первым делом был написан простой генератор опечаток.
Генератор опечаток на вход принимает слово, на выходе даёт слово с некоторым количеством ошибок. Ошибки бывают следующих типов: замена одной буквы на другую, вставка новой буквы, удаление существующей, а также перестановка двух букв местами. Вероятности каждого из типа ошибок настраиваются отдельно, так же настраивается общая вероятность совершить опечатку (в зависимости от длины слова) и вероятность совершить повторную опечатку.
Пока что все параметры выбраны интуитивно, вероятность ошибки составляет примерно 1 на 10 слов, вероятность самого простого типа ошибки (замена одной буквы на другую) в 7 раз выше чем других типов ошибок.
У данной модели много недостатков — она не основывается на реальной статистике опечаток, не учитывает раскладку клавиатуры а также не склеивает и не разделяет слова. Тем не менее, для начального варианта её хватит. А в следующих версиях библиотеки модель будет улучшена.
Теперь, имея генератор опечаток, можно прогнать через него любой текст и получить аналогичный текст с ошибками. В качестве метрики качества спеллчекера можно использовать процент ошибок оставшихся в тексте после прогона его через этот спеллчекер. В дополнение к этой метрике использовались следующие:
- процент исправленных слов (в отличие от метрики с процентом ошибок — считается только по словам с ошибками, а не по всему тексту)
- процент сломанных слов (это когда в слове не было ошибки, а спеллчекер решил, что она там есть, и исправил её)
- процент слов, для которых был предложен правильный вариант в списке из N кандидатов (спеллчекеры обычно предлагают несколько вариантов исправления)
Спеллчекер Питера Норвига
Питер Норвиг описал простой вариант спеллчекера. Для каждого слова генерируются все возможные варианты изменений (удаления + вставки + замены + перестановки), рекурсивно с глубиной <= 2. Получившиеся слова проверяются на наличие в словаре (хеш-таблица), среди множества подошедших вариантов выбирается тот, который встречается чаще всего. Подробней про этот спеллчекер можно почитать в оригинальной статье.
Основные недостатки данного спеллчекера — долгое время работы (особенно на длинных словах), отсутствие учёта контекста. Начнём с исправления последнего — добавим модель языка и вместо простой частоты встречаемости слов будем использовать оценку, возвращаемую языковой моделью.
Модель языка на основе N-грамм
| N-грамма — последовательность из n элементов. Например, последовательность звуков, слогов, слов или букв. |
Модель языка умеет отвечать на вопрос — с какой вероятностью данное предложение может встретится в языке. На сегодняшний день в основном используются два подхода: модели на основе N-грамм а также на основе нейросетей. Для первой версии библиотеки была выбрана N-граммная модель, так как она является более простой. Однако в будущем есть планы попробовать нейросетевую модель.
N-граммная модель работает следующим образом. По тексту, используемому для обучения модели проходим окном размером в N слов и подсчитываем количество раз которые встретилось каждое сочетание (n-грамма). При запросе к модели — аналогичным образом проходим окном по предложению и считаем произведение вероятностей всех n-грамм. Вероятность встретить n-грамму оцениваем по количеству таких n-грамм в обучающем тексте.
Вероятность P(w1,..., wm) встретить предложение (w1,..., wm) из m слов примерно равна произведению всех n-грамм размера n, из которых состоит это предложение:
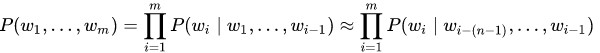
Вероятность каждой из n-граммы определяется через количество раз, которое встретилась эта n-грамма по отношению к количеству раз, которое встретилась такая же n-грамма но без последнего слова:
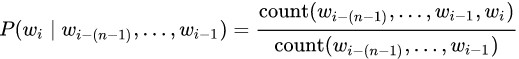
На практике в чистом виде такую модель не используют, так как у неё есть следующая проблема. Если какая-то n-грамма не встречалась в обучающем тексте — всё предложение сразу же получит нулевую вероятность. Для решения этой проблемы используют один из вариантов сглаживания (smoothing). В простом виде это добавление единицы к частоте встречаемости всех n-грамм, в более сложном — использование n-грамм более низкого порядка при отсутствии n-граммы высокого порядка.
Самая популярная техника сглаживания — Kneser–Ney smoothing. Однако она требует для каждой n-граммы хранить дополнительную информацию, а выигрыш по сравнению с более простым сглаживанием получился не сильный (по крайней мере в экспериментах с небольшими моделями, до 50 миллионов n-грамм). Для простоты в качестве сглаживания будем считать вероятность каждой n-граммы как произведение n-грамм всех порядков, например для триграмм:
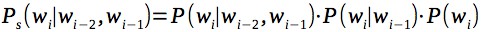
Теперь, имея модель языка, будем выбирать среди кандидатов на исправление опечаток того, для которого модель языка с учетом контекста будет выдавать наилучшую оценку. Кроме того, добавим к оценке небольшой штраф за изменение исходного слова, чтобы избежать большого числа ложных срабатываний. Изменение данного штрафа позволяет регулировать процент ложных срабатываний: например, в текстовом редакторе можно оставить процент ложных срабатываний выше, а для автоматического исправления текстов — ниже.
SymSpell
Следующая проблема спеллчекера Норвига — низкая скорость работы для случаев, когда кандидатов не нашлось. Так, на слове из 15 букв алгоритм работает около секунды, такой производительности вряд ли хватит для практического использования. Один из вариантов ускорения производительности — алгоритм SymSpell, который, по заверению авторов, работает в миллион раз быстрее. SymSpell работает по следующему принципу: для каждого слова из словаря в отдельный индекс добавляются удаления, а точнее — все слова, получившиеся из исходного путём удаления одной или нескольких букв (обычно 1 и 2), со ссылкой на оригинальное слово. В момент поиска кандидатов для слова делаются аналогичные удаления и проверяется их наличие в индексе. Такой алгоритм корректно обрабатывает все случаи ошибок — замены букв, перестановки, добавления и удаления.
Для примера рассмотрим замену (в примере будем учитывать только расстояние 1). Пусть в оригинальном словаре содержится слово "тест". А мы набрали слово “темт”. В индексе будут находится все удаления слова “тест”, а именно: ест, тст, тет, тес. Для слова “темт” удаления будут: емт, тмт, тет, емт. Удаление “тет” содержится в индексе, значит слову с опечаткой “темт” соответствует слово “тест”.
Perfect Hash
Следующая проблема — потребление памяти. Модель, обученная на тексте из двух миллионов предложений (миллион из википедии + миллион из новостных текстов) занимала 7 Гб оперативки. Примерно половину этого объёма использовала языковая модель (n-граммы с частотой встречаемости) а другую половину — индекс для SymSpell. С таким потреблением памяти прикладное использование становилось не очень практичным.
Уменьшать размер словаря не хотелось, так как начинало заметно проседать качество. Как оказалось — это не новая проблема. В научных статьях предлагаются разные пути решения проблемы потребления памяти языковой моделью. Один из интересных подходов (описанный в статье Efficient Minimal Perfect Hash Language Models) — использовать perfect hash (а точнее, алгоритм CHD) для хранения информации об n-граммах. Perfect hash — это такой хеш, который не даёт коллизий на фиксированном наборе данных. При отсутствии коллизий пропадает необходимость в хранении ключей, так как нет нужды их сравнивать. В результате, можно держать в памяти массив, равный количеству n-грамм, в котором хранить их частоту встречаемости. Это даёт очень сильную экономию памяти, так как сами n-грамм-ы занимают сильно больше места чем их частоты встречаемости.
Но есть одна проблема. При использовании модели в неё будут приходить n-граммы, которые ни разу не встречались в обучающем тексте. Как следствие, perfect hash будет возвращать хеш какой-то другой, существующей n-граммы. Чтобы решить эту проблему, авторы статьи для каждой n-граммы предлагают дополнительно хранить другой хеш, по которому можно будет сравнить совпадают ли n-граммы или нет. В случае если хеш различается — данной n-граммы не существует и следует считать частоту встречаемости нулевой.
Например, у нас есть три n-граммы: n1, n2, n3, которые встретились 10, 15 и 3 раза, а также n-грамма n4 которая не встречалась в исходном тексте:
| n1 | n2 | n3 | n4 | |
| Perfect Hash | 1 | 0 | 2 | 1 |
| Second Hash | 42 | 13 | 24 | 18 |
| Частота | 10 | 15 | 3 | 0 |
Мы завели массив, в котором храним частоты встречаемости, а также дополнительный хеш. Используем значение perfect-hash-а в качестве индекса массива:
| 15, 13 | 10, 42 | 3, 24 |
Предположим, нам встретилась n-грамма n1. Её perfect-hash равен 1, а second-hash 42. Мы идём в массив по индексу 1, и сверяем хеш который там лежит. Он совпадает, значит частота n-граммы 10. Теперь рассмотрим n-грамму n4. Её perfect-hash также равен 1, но second-hash равен 18. Это отличается от хеша который лежит по индексу 1, значит частота встречаемости 0.
На практике в качестве хеша был использован CityHash, размером в 16 бит. Конечно же хеш не исключает ложных срабатываний полностью, но сводит их частоту к такой, что на итоговых метриках качества это никак не отражается.
Сама частота встречаемости так же была закодирована более компактно, из 32-битных чисел в 16-битные, путём нелинейного квантования. Мелкие числа соответствовали как 1 к 1, более крупные как 1 к 2, 1 к 4, и т. д. На итоговых метриках квантование опять же никак не сказалось.
Скорее всего, можно запаковать и хеш, и частоты встречаемости ещё сильней — но это уже в следующих версиях. В текущем варианте модель ужалась до 260 Мб — более чем в 10 раз, без какой либо просадки качества.
Bloom Filter
Кроме модели языка оставался ещё индекс от алгоритма SymSpell, который также занимал кучу места. Над ним пришлось подумать немного дольше, так как готовых решений под это не существовало. В научных статьях про компактное представление языковой модели часто использовался bloom-фильтр. Казалось, что и в этой задаче он может помочь. Применить bloom-фильтр в лоб не удавалось — для каждого слова из индекса с удалениями нам нужны были ссылки на оригинальное слово, а bloom фильтр не позволяет хранить значения, только проверять факт наличия. С другой стороны — если bloom фильтр скажет что такое удаление есть в индексе — мы можем восстановить для него оригинальное слово выполняя вставки и проверяя их в индексе. Итоговая адаптация алгоритма SymSpell получилась следующей:
Будем хранить все удаления слов из оригинального словаря в bloom-фильтре. При поиске кандидатов будем вначале делать удаления от исходного слова на нужную глубину (аналогично SymSpell). Но, в отличии от SymSpell, следующим шагом для каждого удаления будем делать вставки, и проверять получившееся слово в оригинальном словаре. А индекс с удалениями, хранящийся в bloom-фильтре, будем использовать чтобы пропускать вставки для тех удалений, которые в нём отсутствуют. В этом случае ложные срабатывания нам не страшны — мы просто выполним немного лишней работы.
Производительность получившегося решения практически не замедлилась, а используемая память сократилась очень существенно — до 140 Мб (примерно в 25 раз). В итоге общий размер памяти сократился с 7 Гб до 400 Мб.
Результаты
В таблице ниже приведены результаты для английского текста. Для обучения использовались 300К предложений из википедии и 300К предложений из новостных текстов (тексты взяты здесь). Исходная выборка была разбита на 2 части, 95% использовалось для обучения, 5% для оценки. Результаты:
| Errors | Top 7 Errors | Fix Rate | Top 7 Fix Rate | Broken | Speed (words per second) |
|
| JamSpell | 3.25% | 1.27% | 79.53% | 84.10% | 0.64% | 1833 |
| Norvig | 7.62% | 5.00% | 46.58% | 66.51% | 0.69% | 395 |
| Hunspell | 13.10% | 10.33% | 47.52% | 68.56% | 7.14% | 163 |
| Dummy | 13.14% | 13.14% | 0.00% | 0.00% | 0.00% | - |
JamSpell — получившийся в итоге спелл-чекер. Dummy — корректор который ничего не делает, приведён для того чтобы было понятно какой процент ошибок в исходном тексте. Norvig — спелл-чекер Питера Норвига. Hunspell — один из самых популярных open-source спелл-чекеров. Для чистоты эксперимента — так же была проведена проверка на художественном тексте. Метрики по тексту "Приключения Шерлока Холмса":
| Errors | Top 7 Errors | Fix Rate | Top 7 Fix Rate | Broken | Speed (words per second) |
|
| JamSpell | 3.56% | 1.27% | 72.03% | 79.73% | 0.50% | 1764 |
| Norvig | 7.60% | 5.30% | 35.43% | 56.06% | 0.45% | 647 |
| Hunspell | 9.36% | 6.44% | 39.61% | 65.77% | 2.95% | 284 |
| Dummy | 11.16% | 11.16% | 0.00% | 0.00% | 0.00% | - |
JamSpell показал лучшее качество и производительность по сравнению со спеллчекерами Hunspell и Норвига в обоих тестах, как в кейсе с одним кандидатом, так и в кейсе с лучшими 7 кандидатами.
В следующей таблице приведены метрики для разных языков и для обучающей выборки разных размеров:
| Errors | Top 7 Errors | Fix Rate | Top 7 Fix Rate | Broken | Speed | Memory | |
| English (300k wikipedia + 300k news) |
3.25% | 1.27% | 79.53% | 84.10% | 0.64% | 1833 | 86.2 Мб |
| Russian (300k wikipedia + 300k news) |
4.69% | 1.57% | 76.77% | 82.13% | 1.07% | 1482 | 138.7 Мб |
| Russian (1M wikipedia + 1M news) |
3.76% | 1.22% | 80.56% | 85.47% | 0.71% | 1375 | 341.4 Мб |
| German (300k wikipedia + 300k news) |
5.50% | 2.02% | 70.76% | 75.33% | 1.08% | 1559 | 189.2 Мб |
| French (300k wikipedia + 300k news) |
3.32% | 1.26% | 76.56% | 81.25% | 0.76% | 1543 | 83.9 Мб |
Итоги
В результате получился качественный и быстрый спелл-чекер, который превосходит аналогичные открытые решения. Примеры использования — текстовые редакторы, мессенджеры, предобработка грязного текста в задачах машинного обучения и т. п.
Исходники доступны на github, под MIT лицензией. Библиотека написана на C++, биндинги для других языков доступны через swig. Пример использования в python:
import jamspell
corrector = jamspell.TSpellCorrector()
corrector.LoadLangModel('model_en.bin')
corrector.FixFragment('I am the begt spell cherken!')
# u'I am the best spell checker!'
corrector.GetCandidates(['i', 'am', 'the', 'begt', 'spell', 'cherken'], 3)
# (u'best', u'beat', u'belt', u'bet', u'bent', ... )
corrector.GetCandidates(['i', 'am', 'the', 'begt', 'spell', 'cherken'], 5)
# (u'checker', u'chicken', u'checked', u'wherein', u'coherent', ...)</td>Дальнейшие доработки — улучшение качества языковой модели, уменьшение потребления памяти, добавление возможности обрабатывать склеивания и разделения слов, поддержка особенностей разных языков. Если кто-то захочет поучаствовать в улучшении библиотеки — буду рад вашим pull-реквестам.
Ссылки
- Исходники JamSpell: github.com/bakwc/JamSpell
- How to Write a Spelling Corrector, Peter Norvig: norvig.com/spell-correct.html
- Hunspell: github.com/hunspell/hunspell
- Language Modeling with N-grams, Daniel Jurafsky & James H. Martin: web.stanford.edu/~jurafsky/slp3/4.pdf
- Understanding LSTM Networks, Christopher Olah: colah.github.io/posts/2015-08-Understanding-LSTMs/
- N-GRAM LANGUAGE MODELING USING RECURRENT NEURAL NETWORK ESTIMATION, Google Tech Report, Ciprian Chelba, Mohammad Norouzi, Samy Bengio: static.googleusercontent.com/media/research.google.com/ru//pubs/archive/46183.pdf
- An empirical study of smoothing techniques for language modeling, Stanley F. Chen and Joshua Goodman: u.cs.biu.ac.il/~yogo/courses/mt2013/papers/chen-goodman-99.pdf
- 1000x Faster Spelling Correction algorithm, Wolf Garbe: blog.faroo.com/2012/06/07/improved-edit-distance-based-spelling-correction/
- Efficient Minimal Perfect Hash Language Models, David Guthrie, Mark Hepple, Wei Liu: www.lrec-conf.org/proceedings/lrec2010/pdf/860_Paper.pdf
- Perfect hash function, wikipedia: en.wikipedia.org/wiki/Perfect_hash_function
- Hash, displace, and compress. Djamal Belazzougui1, Fabiano C. Botelho, Martin Dietzfelbinger: cmph.sourceforge.net/papers/esa09.pdf
- Фильтр Блума, habrahabr: habrahabr.ru/post/112069/
- Leipzig Corpora Collection: wortschatz.uni-leipzig.de/en/download/
Комментарии (2)

tessob
25.01.2018 18:04Занимался подобной задачей некоторое время назад. Алгоритм Норвига удалось ускорить без потери качества оперевшись на предположении, что люди чаще совершают опечатки нажимая на соседние клавиши.
elingur
Спасибо, интересная статья. Пару раз я делал подобные сервисы, причем не только исправления орфографии, но пунктуации и стилистики. Идея была немного другая. Сначала работал Hanspell с хорошо переработанными словарями. Но Hanspell выдает несколько вариантов на слово. А вот вариант выбирается языковой моделью. В пунктуации работал алгоритм, похожий на Symspell. До «продакшн» сервисы не дошли. Проблемы: во-первых, слишком неповоротливы (perfect hash я тогда еще не знал, лет 7 назад это было). Во вторых, проблема неизвестных слов. Если слова нарицательные можно учесть почти все, то имена собственные — открытое множество, растущее почти линейно. А система все рано пытается заменить неизвестное слово на ближайшее. Моделями, даже с хорошим сглаживанием, можно убрать наиболее частотные ошибки, но всех комбинаций модель учесть не может. А точность, которую желает видеть потребитель, должна быть не менее 95%.