

Всем привет! Меня зовут Лёха, и я работаю бэкенд-разработчиком в FunCorp. Сегодня мы поговорим про реактивное программирование, библиотеку Reactor и немного про веб.
Реактивное программирование часто «подвергается упоминанию», но если вы (как и автор статьи) всё ещё не знаете, что это такое — устраивайтесь поудобнее, попробуем разобраться вместе.
Что же такое реактивное программирование?
Реактивное программирование — это управление асинхронными потоками данных. Вот так просто. Мы люди нетерпеливые и не вникаем во все эти ваши манифесты с подробностями, а стоило бы.
Причём тут веб?
Ходят слухи, что если выстраивать свою систему реактивно, согласно всем канонам Reactive Manifesto, начиная с HTTP-сервера и заканчивая драйвером БД, можно вызвать второе пришествие. Ну, или хотя бы построить действительно качественный бэкенд.
Это, конечно, лёгкое лукавство. Но если ваш юзкейс — обработка множественных и не всегда быстрых запросов, а контейнер сервлетов перестаёт справляться — добро пожаловать в прекрасный мир реактивного!
If you have 128 continuous parallel requests, a servlet container is probably not the right tool for the job.
А на чём писать реактивно, если не на Netty? Стоит отметить, что написание бэкенда на голом Netty утомительно, и приятно иметь абстракции для работы.
Годных серверных абстракций для Netty много не бывает, поэтому ребята из Pivotal добавили в Spring Boot 2 его поддержку. 1 марта 2018 года всё это даже зарелизилось. Чтобы сделать нам совсем приятно, они создали модуль WebFlux, который является альтернативой Spring MVC и представляет собой реактивный подход для написания веб-сервисов.
WebFlux позиционирует себя как микрофреймворк (микрофреймворк и Spring, ха-ха), обещает вписаться в эти ваши (наши) модные микросервисы, представляет API в функциональном стиле и уже упоминался на Хабре. Более подробно (в т.ч. об отличиях от Spring MVC) можно почитать здесь. Но сегодня о другом. В основе WebFlux лежит библиотека Reactor. О ней и поговорим.
Reactor — это реактивная (внезапно!) open-source-платформа, разрабатываемая Pivotal. Я решился на вольный пересказ (с комментариями) введения в эту замечательную библиотеку.
Поехали.
Blocking code (для самых маленьких)
Программный код на языке Java обычно блокирующий. Например, вызовы по HTTP или запросы к БД вешают наш текущий поток до момента, пока нам не ответит сторонний сервис. Это нормальная практика, если сервис отвечает за приемлемое время. В противном случае это дело превращается в bottleneck. Мы вынуждены его распараллелить, запускать больше потоков, которые будут выполнять один и тот же блокирующий код. Попутно приходится решать возникающие проблемы с contention и конкурентностью.
Частое блокирование, особенно из-за I/O (а уж если у вас много мобильных клиентов, то совсем не быстрого I/O), заставляет наши многочисленные потоки просиживать штаны в ожидании данных, тратя драгоценные ресурсы на переключение контекста и всякое такое.
Параллелизация — это не волшебная палочка, решающая все проблемы. Это сложный инструмент, несущий свой оверхед.
Async && non-blocking
Эти термины легко найти, сложно понять и невозможно забыть. Но они часто фигурируют, когда речь идёт о реактивности, поэтому попробуем разобраться в них.
Из текста выше можно сделать вывод, что во всём виноват блокирующий код. Окей, давайте начнём писать неблокирующий. Что под этим подразумевается? Если мы ещё не готовы отдать результат, то вместо его ожидания мы отдаём какую-то ошибку, например, с просьбой повторить запрос позднее. Круто, конечно, но что нам с этой ошибкой делать? Так у нас появляется асинхронная обработка, чтобы позднее отреагировать на ответ: всё готово!
Получается, нужно писать код асинхронный и неблокирующий, и всё у нас станет хорошо? Нет, не станет. Но облегчить жизнь может. Для этого добрые и умные люди напридумывали всяких спецификаций (в т.ч. реактивных) и напилили библиотек, которые эти спецификации уважают.
Так вот, Reactor. Если очень коротко
По факту, Reactor (по-крайней мере его core-часть) — это имплементация спецификации Reactive Streams и части ReactiveX-операторов. Но об этом чуть позже.
Если вы знакомы или наслышаны о RxJava, то Reactor разделяет подход и философию RxJavа, но имеет ряд семантических отличий (которые растут из-за backward compatibility со стороны RxJava и особенностей Android-разработки).
Что же такое Reactive Streams в Java?
Если грубо, то это 4 интерфейса, которые представлены в библиотеке reactive-streams-jvm:
- Publisher;
- Subscriber;
- Subscription;
- Processor.
Их точные копии присутствуют в классе Flow из девятки.
Если ещё более грубо, то к ним всем выдвигаются примерно следующие требования:
- ASYNC — асинхронность;
- NIO — «неблокируемость» ввода/вывода;
- RESPECT BACKPRESSURE — умение обрабатывать ситуации, когда данные появляются быстрее, чем потребляются (в синхронном, императивном коде подобная ситуация не возникает, но в реактивных системах такое часто встречается).
Давайте взглянем на код класса Flow из JDK 9 (Javadoc-комментарии убраны для лаконичности):
public final class Flow {
public static interface Publisher<T> {
public void subscribe(Subscriber<? super T> subscriber);
}
public static interface Subscriber<T> {
public void onSubscribe(Subscription subscription);
public void onNext(T item);
public void onError(Throwable throwable);
public void onComplete();
}
public static interface Subscription {
public void request(long n);
public void cancel();
}
public static interface Processor<T,R> extends Subscriber<T>, Publisher<R> {
}
}Пока что это вся поддержка реактивности на уровне JDK. Где-то в модуле инкубатора зреет HTTP/2-клиент, в котором Flow активно используется. Других использований внутри JDK 9 я не обнаружил.
Интеграции
Reactor интегрирован в наши любимые приблуды Java 8, среди которых CompletableFuture, Stream, Duration. Поддерживает IPC-модули. У него есть адаптеры для Akka и RxJava, модули test (очевидно, для написания тестов) и extra (utility классы).
Для любителей Redis у клиентов lettuce/redisson есть реактивный API с поддержкой Reactor.
Для любителей MongoDB есть официальный реактивный драйвер, который имплементирует Reactive Streams, в связи с чем его легко подхватывает Reactor.
Отлично, а как всё это запустить?
Всё это можно запустить на JDK8 и выше. Однако, если вы используете Android и ваш (minSdk < 26), то лучше обратите свой взор на RxJava 2.
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-bom</artifactId>
<version>Bismuth-RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-core</artifactId>
</dependency>
</dependencies>plugins {
id "io.spring.dependency-management" version "1.0.1.RELEASE"
}
dependencyManagement {
imports {
mavenBom "io.projectreactor:reactor-bom:Bismuth-RELEASE"
}
}
dependencies {
compile 'io.projectreactor:reactor-core'
}BOM служит для обеспечения лучшей совместимости различных кусков Reactor. В Gradle нет нативной поддержки BOM, поэтому нужен плагин.
Примерчики
Так вот, нам нужно написать асинхронный и неблокирующий код. Другими словами, дать возможность текущему потоку выполнения не блокироваться и ждать, а переключиться на что-нибудь полезное, вернувшись к текущему процессу, когда асинхронная обработка будет завершена.
На солнечном острове под названием Java для это есть два основных способа:
Callbacks. В случае с колбэками у метода нет возвращаемого значения (void), но он принимает дополнительный параметр (лямбду, анонимный класс и т.п.), который вызывается после определённого события. В качестве примера можно привести EventListener из библиотеки Swing.
- Futures. Это такой объект, который обещает что-то вернуть в будущем. Во Future лежит ссылка на объект<T>, значение которого будет вычислено позже (асинхронно). Future умеет блокироваться, чтобы дождаться результата. Допустим, ExecutorService на submit() возвращает вам Future<T> из Callable<T>.
Это хорошо известные инструменты, но в какой-то момент их становится недостаточно.
Проблемы с колбэками
Колбэки плохо поддаются композиции и быстро превращаются в мешанину под названием "callback hell".
Разберём на примере
Нужно показать пользователю 5 топовых мемов, а если их нет, то сходить в сервис предложений и взять 5 мемов оттуда.
Итого задействовано 3 сервиса: первый отдаёт ID любимых мемов пользователя, второй фетчит сами мемы, а третий отдаёт предложения, если любимых мемов не имеется.
//список любимых мемов пользователя
userService.getFavoriteMemes(userId, new Callback<>() {
//получили данные
public void onSuccess(List<String> userFavoriteMemes) {
if (userFavoriteMemes.isEmpty()) {
//если любимых записей нет, предлагаем ему контент
suggestionService.getSuggestedMemes(new Callback<>() {
public void onSuccess(List<Meme> suggestedMemes) {
uiUtils.submitOnUiThread(() -> {
suggestedMemes.stream().limit(5).forEach(meme -> {
//рендеринг данных в UI
}));
}
}
public void onError(Throwable error) {
uiUtils.errorPopup(error); //рендеринг ошибки в UI
}
});
} else {
//если нашли записи
userFavoriteMemes.stream()
.limit(5) //ограничиваем выдачу 5 элементами
.forEach(favId -> memeService.getMemes(favId,
new Callback<Favorite>() {
//фетчим мемы
public void onSuccess(Meme loadedMeme) {
uiUtils.submitOnUiThread(() -> {
//рендеринг данных в UI
});
}
public void onError(Throwable error) {
uiUtils.errorPopup(error);
}
}));
}
}
public void onError(Throwable error) {
uiUtils.errorPopup(error);
}
});Выглядит как-то не круто.
Теперь посмотрим, как мы бы сделали это с Reactor
//получаем последовательность идентификаторов
userService.getFavoriteMemes(userId)
.flatMap(memeService.getMemes) //закачиваем мемы по ID
//если пусто, берём мемы из сервиса предложений
.switchIfEmpty(suggestionService.getSuggestedMemes())
.take(5) // нам нужно не больше 5 элементов
.publishOn(UiUtils.uiThreadScheduler()) //отдаём данные в UI-поток
.subscribe(favorites -> {
uiList.show(favorites); //вызывается в UI-потоке
}, UiUtils::errorPopup); //колбэк на случай ошибки
А что если мы вдруг захотели отваливаться по тайм-ауту в 800 мс и загружать кэшированные данные?
userService.getFavoriteMemes(userId)
.timeout(Duration.ofMillis(800)) //длительность тайм-аута
//альтернативный источник данных
.onErrorResume(cacheService.cachedFavoritesFor(userId))
.flatMap(memeService.getMemes) //закачиваем мемы по ID
.switchIfEmpty(suggestionService.getSuggestedMemes())
.take(5) // берем первые 5 элементов
.publishOn(UiUtils.uiThreadScheduler())
.subscribe(favorites -> {
uiList.show(favorites);
}, UiUtils::errorPopup);В Reactor мы просто добавляем в цепочку вызовов оператор timeout. Timeout выбрасывает исключение. Оператором onErrorResume мы указываем альтернативный (fallback) источник, из которого нужно взять данные в случае ошибки.
Колбэки в 20!8, у нас же есть CompletableFuture
У нас есть список ID, по которым мы хотим запросить имя и статистику, а затем скомбинировать в виде пар «ключ-значение», и всё это асинхронно.
CompletableFuture<List<String>> ids = ifhIds(); //наш список идентификаторов
CompletableFuture<List<String>> result = ids.thenComposeAsync(l -> {
Stream<CompletableFuture<String>> zip = l.stream().map(i -> {
//получаем имя (асинхронно)
CompletableFuture<String> nameTask = ifhName(i);
//получаем статистику (асинхронно)
CompletableFuture<Integer> statTask = ifhStat(i);
//комбинируем результаты
return nameTask.thenCombineAsync(statTask,
(name, stat) -> "Name " + name + " has stats " + stat);
});
//Собираем массив CompletableFuture
List<CompletableFuture<String>> combinationList = zip.collect(Collectors.toList());
CompletableFuture<String>[] combinationArray = combinationList.toArray(
new CompletableFuture[combinationList.size()]);
//дожидаемся выполнения всех Feature с помощью allOf
CompletableFuture<Void> allDone = CompletableFuture.allOf(combinationArray);
// тут хак, связанный с тем, что allOf возвращает Feauture<Void>
return allDone.thenApply(v -> combinationList.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList()));
});
List<String> results = result.join();
assertThat(results).contains(
"Name NameJoe has stats 103",
"Name NameBart has stats 104",
"Name NameHenry has stats 105",
"Name NameNicole has stats 106",
"Name NameABSLAJNFOAJNFOANFANSF has stats 121"
);Как мы можем сделать это с Reactor?
Flux<String> ids = ifhrIds();
Flux<String> combinations = ids.flatMap(id -> {
Mono<String> nameTask = ifhrName(id);
Mono<Integer> statTask = ifhrStat(id);
//zipWith-оператор для комбинации
return nameTask.zipWith(
statTask, (name, stat) -> "Name " + name + " has stats " + stat
);
});
Mono<List<String>> result = combinations.collectList();
List<String> results = result.block(); // т.к. мы в тесте, то просто блокируемся
assertThat(results).containsExactly(
"Name NameJoe has stats 103",
"Name NameBart has stats 104",
"Name NameHenry has stats 105",
"Name NameNicole has stats 106",
"Name NameABSLAJNFOAJNFOANFANSF has stats 121"
);В итоге нам предоставляется высокоуровневый API, композируемый и читабельный (на самом деле изначально мы использовали Reactor именно для этого, т.к. нужен был способ писать асинхронный код в едином стиле), и прочие вкусности: ленивое выполнение, управление BackPressure, различные планировщики (Schedulers) и интеграции.
Окей, какие ещё Flux и Mono?
Flux и Mono — это две основные структуры данных Reactor.
Flux
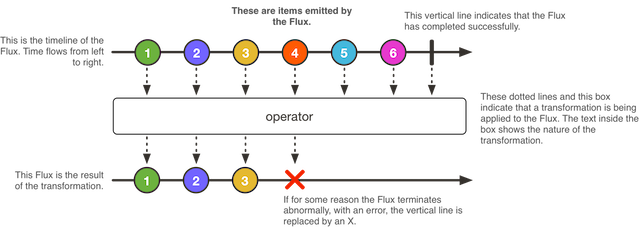
Flux — это имплементация интерфейса Publisher, представляет из себя последовательность из 0..N элементов, которая может (но не обязательно) завершаться (в т.ч. и с ошибкой).
У последовательности Flux есть 3 допустимых значения: объект последовательности, сигнал завершения или сигнал ошибки (вызовы методов onNext, onComplete и onError соответственно).
Каждое из 3 значений опционально. К примеру, Flux может представлять из себя бесконечную пустую последовательность (ни один метод не вызывается). Или конечную пустую последовательность (вызывается только onComplete). Или бесконечную последовательность значений (вызывается только onNext). И т.д.
Например, Flux.interval() отдаёт бесконечную последовательность тиков типа Flux<Long>.
Конструкция вида :
Flux
.interval(Duration.ofSeconds(1))
.doOnEach(signal -> logger.info("{}", signal.get()))
.blockLast();Выведет следующий текст:
12:24:42.698 [parallel-1] INFO - 0
12:24:43.697 [parallel-1] INFO - 1
12:24:44.698 [parallel-1] INFO - 2
12:24:45.698 [parallel-1] INFO - 3
12:24:46.698 [parallel-1] INFO - 4
12:24:47.699 [parallel-1] INFO - 5
12:24:48.696 [parallel-1] INFO - 6
12:24:49.696 [parallel-1] INFO - 7
12:24:50.698 [parallel-1] INFO - 8
12:24:51.699 [parallel-1] INFO - 9
12:24:52.699 [parallel-1] INFO - 10Метод doOnEach(Consumer<T>) применяет сайд-эффект к каждому элементу в последовательности, что удобно для логирования.
Обратите внимание на blockLast(): т.к. последовательность бесконечная, поток, в котором происходит вызов, будет бесконечно ждать окончания.
Если вы знакомы с RxJava, то Flux очень похож на Observable
Mono
Mono — это имплементация интерфейса Publisher, представляет из себя какой-то асинхронный элемент или его отсутствие Mono.empty().
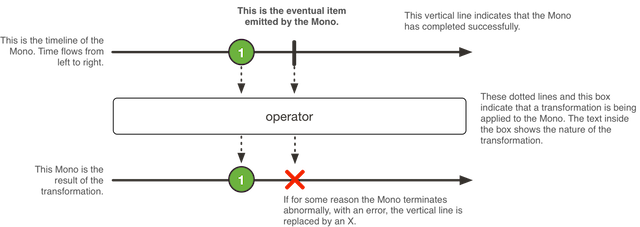
В отличии от Flux, Mono может вернуть не более 1 элемента. Вызовы onComplete() и onError(), как и в случае с Flux, опциональны.
Mono также может использоваться как какая-то асинхронная задача в стиле «выполнил и забыл», без возвращаемого результата (похоже на Runnable). Для этого можно объявить его как Mono<Void> и использовать оператор empty.
Mono<Void> asyncCall = Mono.fromRunnable(() -> {
//тут какая-то логика
//возвращаем Mono.empty() после выполнения
});
asyncCall.subscribe();Если вы знакомы с RxJava, воспринимайте Mono как коктейль из Single + Maybe
К чему это разделение?
Разделение на Flux и Mono помогает улучшить семантику реактивного API, делая его достаточно выразительным, но не избыточным.
В идеале, просто посмотрев на возвращаемое значение, мы можем понять, что делает метод: какой-то вызов (Mono<Void>), запрос-ответ (Mono<T>) или возвращает нам поток данных (Flux<T>).
Flux и Mono пользуются своей семантикой и перетекают друг в друга. У Flux есть метод single(), который возвращает Mono<T>, а у Mono есть метод concatWith(Mono<T>), который возвращает уже Flux<T>.
Также у них есть уникальные операторы. Некоторые имеют смысл только при N элементах в последовательности (Flux) или, наоборот, актуальны только для одного значения. Например, у Mono есть or(Mono<T>), а у Flux есть операторы limit/take.
Ещё примерчики
Самый простой способ создать Flux/Mono — воспользоваться одним из массы фабричных методов, которые представлены в этих классах.
Flux<String> sequence = Flux.just("foo", "bar", "foobar");List<String> iterable = Arrays.asList("foo", "bar", "foobar");
Flux<String> sequence = Flux.fromIterable(iterable);Publisher<String> publisher = redisson.getKeys().getKeys();
Flux<String> from = Flux.from(publisher);Mono<String> noData = Mono.empty(); //пустой Mono
Mono<String> data = Mono.just("foo"); //строка "foo"
// последовательность //чисел - 5,б,7
Flux<Integer> numbersFromFiveToSeven = Flux.range(5, 3); Flux и Mono ленивые. Для того чтобы запустить какую-то обработку и воспользоваться данными, лежащими в наших Mono и Flux, нужно на них подписаться с помощью .subscribe().
Подписка — это способ обеспечить ленивое поведение и заодно указать, что нужно делать с нашими данными. Методы subscribe используют «лямбда-выражения» из Java 8 в качестве параметров.
subscribe(); //запустить исполнение..
// .. и сделать что-то с каждым полученным значением
subscribe(Consumer<? super T> consumer);
// .. и сделать что-то в случае исключения
subscribe(Consumer<? super T> consumer, Consumer<? super Throwable> errorConsumer);
// .. и сделать что-то по завершению
subscribe(
Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer,
Runnable completeConsumer
);Flux<Integer> ints = Flux.range(1, 3);
ints.subscribe(i -> System.out.println(i));выведет следующее:
1
2
3Flux<Integer> ints = Flux.range(1, 4)
.map(i -> {
if (i <= 3) {
return i;
}
throw new RuntimeException("Got to 4");
});
ints.subscribe(
i -> System.out.println(i), error -> System.err.println("Error: " + error)
);выведет следующее:
1
2
3
Error: java.lang.RuntimeException: Got to 4Flux<Integer> ints = Flux.range(1, 4);
ints.subscribe(i -> System.out.println(i),
error -> System.err.println("Error " + error),
() -> {System.out.println("Done");
});выведет следующее:
1
2
3
4
DoneПо умолчанию всё это будет отрабатывать в текущем потоке. Поток исполнения можно изменить, к примеру, с помощью оператора .publishOn(), передав туда интересующий нас Scheduler (Scheduler — это такой наворот над ExecutorService).
Flux<Integer> sequence = Flux.range(0, 100).publishOn(Schedulers.single());
//вызовы onNext, onComplete и onError будут происходить в шедулере single.
sequence.subscribe(n -> {
System.out.println("n = " + n);
System.out.println("Thread.currentThread() = " + Thread.currentThread());
});
sequence.blockLast();выведет следующее (100 раз):
n = 0
Thread.currentThread() = Thread[single-1,5,main]Какие выводы можно сделать?
- При всем уважении к CompletableFuture, их API, композируемость и читабельность оставляет желать лучшего.
- С использованием Reactor мы получаем способ манипулировать асинхронными потоками данных без блокировок и страданий.
- Со стороны бэкенда, к сожалению, есть ряд причин, которые пока мешают строить полностью реактивные системы (например, блокирующие драйвера).
- Реактивность не делает ваш код производительнее, однако улучшает масштабируемость.
- Для управления данными внутри приложения Reactor можно использовать прямо сейчас.
Вот такой занимательный обзор получился (нет). Если вам было интересно — пишите, и мы углубимся в происходящее. И не стесняйтесь комментировать!
Спасибо за внимание!
По мотивам документации Reactor
Copies of this document may be made for your own use and for distribution to others, provided that you do not charge any fee for such copies and further provided that each copy contains this Copyright Notice, whether distributed in print or electronically.
Меня тут нет, но есть более достойные мужи, в т.ч. и контрибьюторы / мейнтейнеры.
Комментарии (13)

gkislin
13.03.2018 13:36Спасибо, продолжение будет интересно.
numbersFromFiveToSeven = Flux.range(5, 3) поправить на (5,7) :)
Еще заметил, что с Reactor реализацией 5 мемов проверка на empty происходит не до, а после обращения к
memeService. Издержки реализации или можно сделать логику идентично?
zealot_and_frenzy Автор
13.03.2018 14:09+1Это из-за особенности устройства Flux (и работы оператора flatMap()). Flux.empty() будет передан дальше по цепочке вызовов, а потом подхватится оператором switchIfEmpty(). Вместо тысячи слов:
Flux<String> emptyFlux = Flux.empty(); String lastValue = emptyFlux .flatMap((Function<String, Publisher<String>>) someValue -> { System.out.println("flatMap call"); return Flux.just(someValue + "(is modified)"); }) .<String>switchIfEmpty(Flux.just(":(")) .blockLast(); System.out.println("lastValue = " + lastValue);
Выведет грустный смайлик
gkislin
13.03.2018 13:45Еще хорошая ссылка по теме: https://spring.io/blog/2016/03/11/reactor-core-3-0-becomes-a-unified-reactive-foundation-on-java-8
zealot_and_frenzy Автор
13.03.2018 14:37По поводу Flux.range. Там нет ошибки, просто так устроен оператор:
/** * @param start the first integer to be emit * @param count the total number of incrementing values to emit, including the first value * @return a ranged {@link Flux} */ public static Flux<Integer> range(int start, int count) {}
Он выводит значения начиная со start и по count-1.
alatushkin
13.03.2018 17:01Маленький шаг для человека, огромный шаг для spring.
Сложность с rx -стилем в коде только в том, что без контроля очень легко получить "мама-смотри-какой-я-умный" лапшу в коде, причем даже на небольшом количестве строк.
И с этой точки зрения корутины котлина с синтаксическим сахаром кажутся весьма хорошим решением вместе с project reactor и spring

IL_Agent
13.03.2018 22:38Выглядит, как «ещё один rx». Имеются ли преимущества перед RxJava?
zealot_and_frenzy Автор
14.03.2018 00:13Перед RxJava 1? Очевидно есть. Перед RxJava 2? Отсутствие поддержки Java 6 + Android 2.3 + наследия RxJava 1, в связи с чем более "чистая" семантика. Лучшая поддержка фишек Java 8. Spring Boot 2, по умолчанию, предлагает использовать Reactor для реактивности, хотя это же Spring, поэтому можно подключить альтернативное решение.
Еще есть вот такой забавный твит, от "project lead of RxJava".

leventov
13.03.2018 23:54Отличная статья. "Повергается упоминанию" — замечательное выражение)
Вывод "Реактивность не делает ваш код производительнее, однако улучшает масштабируемость." вроде бы не следует из самой статьи, однако он следует из этой замечательной статьи: https://medium.com/netflix-techblog/zuul-2-the-netflix-journey-to-asynchronous-non-blocking-systems-45947377fb5c было бы неплохо добавить на нее ссылку с комментарием, где-то ближе к началу статьи.
darkit
14.03.2018 00:26RxJava и Reactor отличные штуки, но вот как только натыкаешься на JDBC и транзакцию, которая на несколько операций, то приехали :(
zealot_and_frenzy Автор
15.03.2018 13:15Да, в плане работы с JDBC — все очень плохо.
Но в случае чего, для работы с блокирующим источником, документация предлагает следующую конструкцию:
Mono blockingWrapper = Mono.fromCallable(() -> { return /* make a remote synchronous call */ }); blockingWrapper = blockingWrapper.subscribeOn(Schedulers.elastic());
У нас в одном из сервисов есть вот такой метод:
public Mono<Boolean> createUserRelation(UserId objectId, UserId subjectId) { return Mono.fromSupplier(() -> { try { relationRepo.create(new UserRelationResource(objectId, subjectId)); return true; } catch (Exception e) { logger.error(e.getMessage(), e); return false; } }).publishOn(elastic); }
Оба варианта: publishOn() и subscribeOn() позволяют изменять поток выполнения. В случае с Schedulers.elastic(), можно сказать что он похож на стандартный ExecutorService newCachedThreadPool().
darkit
16.03.2018 01:24Проблема в том, что одно дело когда один блокирующий метод, а другое их несколько и они вызываются как угодно в зависимости от логики и надо иметь одну общую транзакцию :(
Nibilung
Спасибо за статью! Все выглядит очень здорово, когда вы работаете с какой-нибудь Монгой, где драйвер неблокирующий либо у вас несколько источников данных, дергающих другие сервисы. Максим Гореликов на прошлом Joker-e очень хорошо показал, как этой штукой пользоваться.