
Если пять лет назад нейронная сеть считалась «тяжеловесным» алгоритмом, требующим железа, специально предназначенного для высоконагруженных вычислений, то сегодня уже никого не удивить глубокими сетями, работающими прямо на мобильном телефоне.

В наши дни сети распознают ваше лицо, чтобы разблокировать телефон, стилизуют фотографии под известных художников и определяют, есть ли в кадре хот-дог.
В этой статье мы поговорим о MobileNet, передовой архитектуре сверточной сети, позволяющей делать всё это и намного больше.
Статья будет состоять из трёх частей. В первой мы посмотрим на строение сети, а также на трюки, которые авторы оригинальной научной работы предложили для оптимизации скорости работы алгоритма. Во второй части мы поговорим о следующей версии MobileNetV2, статью о которой исследователи из Google опубликовали буквально пару месяцев назад. В конце мы обсудим практические результаты, достижимые с помощью этой архитектуры.
В прошлом посте мы рассмотрели Xception-архитектуру, которая позволяла существенно уменьшить количество параметров в сверточной сети с Inception-подобной архитектурой за счёт замены обычных свёрток так называемыми depthwise separable convolutions. Вкратце напомню, что это такое.
Обычная свертка представляет из себя фильтр , где — это размер ядра свёртки, а — количество каналов на входе. Общая вычислительная сложность сверточного слоя составляет , где — это высота и ширина слоя (мы считаем, что пространственные размеры входного и выходного тензоров совпадают), а — число каналов на выходе.
Идея depthwise separable convolution состоит в том, чтобы разложить подобный слой на depthwise-свертку, которая представляет из себя поканальный фильтр, и 1x1-свёртку (также называемую pointwise convolution). Суммарное количество операций для применения такого слоя равно .
По большому счёту, это и всё, что нужно знать, чтобы успешно построить MobileNet.
Слева нарисован блок обычной сверточной сети, а справа — базовый блок MobileNet.
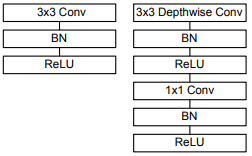
Сверточная часть интересующей нас сети состоит из одного обычного свёрточного слоя с 3х3 свёрткой в начале и тринадцати блоков, изображенных справа на рисунке, с постепенно увеличивающимся числом фильтров и понижающейся пространственной размерностью тензора.
Особенностью данной архитектуры является отсутствие max pooling-слоёв. Вместо них для снижения пространственной размерности используется свёртка с параметром stride, равным 2.
Двумя гиперпараметрами архитектуры MobileNet являются (множитель ширины) и (множитель глубины или множитель разрешения).
Множитель ширины отвечает за количество каналов в каждом слое. Например, даёт нам архитектуру, описанную в статье, а — архитектуру с уменьшенным в четыре раза числом каналов на выходе каждого блока.
Множитель разрешения отвечает за пространственные размеры входных тензоров. Например, означает, что высота и ширина feature map, подаваемой на вход каждому слою будет уменьшена вдвое.
Оба параметра позволяют варьировать размеры сети: уменьшая и , мы снижаем точность распознавания, но в то же время увеличиваем скорость работы и уменьшаем потребляемую память.
Появление MobileNet уже само по себе сделало революцию в компьютерном зрении на мобильных платформах, однако несколько дней назад Google выложил в открытый доступ MobileNetV2 — следующее поколение нейросетей этого семейства, которое позволяет достигать примерно такой же точности распознавания при ещё большей скорости работы.
Основной строительный блок этой сети в целом похож на предыдущее поколение, но имеет ряд ключевых особенностей.
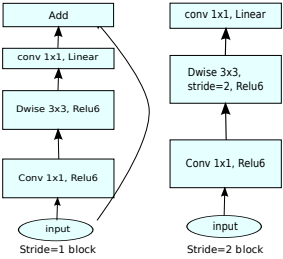
Как и в MobileNetV1, здесь есть сверточные блоки с шагом 1 (на рисунке слева) и с шагом 2 (на рисунке справа). Блоки с шагом 2 предназначены для снижения пространственной размерности тензора и, в отличие от блока с шагом 1, не имеют residual connections.
Блок MobileNet, называемый авторами расширяющим сверточным блоком (в оригинале expansion convolution block или bottleneck convolution block with expansion layer), состоит из трёх слоёв:
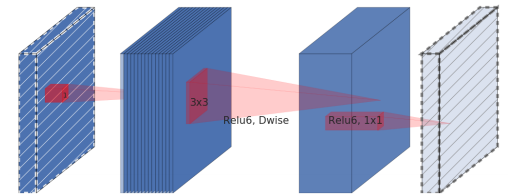
Фактически, именно третий слой в этом блоке, называемый bottleneck layer, и является основным отличием второго поколения MobileNet от первого.
Теперь, когда мы знаем, как MobileNet устроен внутри, давайте посмотрим, насколько хорошо он работает.
Сравним между собой несколько архитектур сетей. Возьмем для примера Xception, о котором был прошлый пост, глубокую и старую VGG16, а также несколько вариаций MobileNet.
Самым большим достижением из этих экспериментов мне кажется то, что сейчас сети, способные работать на мобильных устройствах, показывают accuracy выше, чем у VGG16.
Также, в статье про MobileNetV2 показываются весьма интересные результаты на других задачах. В частности, авторы демонстрируют, что SSDLite-архитектура для задачи object detection, использующая MobileNetV2 в свёрточной части, превосходит известный детектор реального времени YOLOv2 по точности на датасете MS COCO, при этом показывая в 20 раз большую скорость и в 10 раз меньший размер (в частности, на смартфоне Google Pixel сеть MobileNetV2 позволяет делать object detection с 5 FPS).

С MobileNetV2 мобильные разработчики получили почти неограниченный инструментарий в области компьютерного зрения — помимо относительно простых моделей для классификации изображений, теперь мы можем использовать прямо на мобильном устройстве алгоритмы детектирования объектов и семантической сегментации.
При этом использовать MobileNet с помощью Keras и TensorFlow настолько просто, что в принципе разработчики могут делать это, даже не углубляясь во внутреннее устройство алгоритмов, как завещает известный комикс.
В наши дни сети распознают ваше лицо, чтобы разблокировать телефон, стилизуют фотографии под известных художников и определяют, есть ли в кадре хот-дог.
В этой статье мы поговорим о MobileNet, передовой архитектуре сверточной сети, позволяющей делать всё это и намного больше.
Статья будет состоять из трёх частей. В первой мы посмотрим на строение сети, а также на трюки, которые авторы оригинальной научной работы предложили для оптимизации скорости работы алгоритма. Во второй части мы поговорим о следующей версии MobileNetV2, статью о которой исследователи из Google опубликовали буквально пару месяцев назад. В конце мы обсудим практические результаты, достижимые с помощью этой архитектуры.
В предыдущих сериях
В прошлом посте мы рассмотрели Xception-архитектуру, которая позволяла существенно уменьшить количество параметров в сверточной сети с Inception-подобной архитектурой за счёт замены обычных свёрток так называемыми depthwise separable convolutions. Вкратце напомню, что это такое.
Обычная свертка представляет из себя фильтр , где — это размер ядра свёртки, а — количество каналов на входе. Общая вычислительная сложность сверточного слоя составляет , где — это высота и ширина слоя (мы считаем, что пространственные размеры входного и выходного тензоров совпадают), а — число каналов на выходе.
Идея depthwise separable convolution состоит в том, чтобы разложить подобный слой на depthwise-свертку, которая представляет из себя поканальный фильтр, и 1x1-свёртку (также называемую pointwise convolution). Суммарное количество операций для применения такого слоя равно .
По большому счёту, это и всё, что нужно знать, чтобы успешно построить MobileNet.
Структура MobileNet
Слева нарисован блок обычной сверточной сети, а справа — базовый блок MobileNet.
Сверточная часть интересующей нас сети состоит из одного обычного свёрточного слоя с 3х3 свёрткой в начале и тринадцати блоков, изображенных справа на рисунке, с постепенно увеличивающимся числом фильтров и понижающейся пространственной размерностью тензора.
Особенностью данной архитектуры является отсутствие max pooling-слоёв. Вместо них для снижения пространственной размерности используется свёртка с параметром stride, равным 2.
Двумя гиперпараметрами архитектуры MobileNet являются (множитель ширины) и (множитель глубины или множитель разрешения).
Множитель ширины отвечает за количество каналов в каждом слое. Например, даёт нам архитектуру, описанную в статье, а — архитектуру с уменьшенным в четыре раза числом каналов на выходе каждого блока.
Множитель разрешения отвечает за пространственные размеры входных тензоров. Например, означает, что высота и ширина feature map, подаваемой на вход каждому слою будет уменьшена вдвое.
Оба параметра позволяют варьировать размеры сети: уменьшая и , мы снижаем точность распознавания, но в то же время увеличиваем скорость работы и уменьшаем потребляемую память.
MobileNetV2
Появление MobileNet уже само по себе сделало революцию в компьютерном зрении на мобильных платформах, однако несколько дней назад Google выложил в открытый доступ MobileNetV2 — следующее поколение нейросетей этого семейства, которое позволяет достигать примерно такой же точности распознавания при ещё большей скорости работы.
Как выглядит MobileNetV2?
Основной строительный блок этой сети в целом похож на предыдущее поколение, но имеет ряд ключевых особенностей.
Как и в MobileNetV1, здесь есть сверточные блоки с шагом 1 (на рисунке слева) и с шагом 2 (на рисунке справа). Блоки с шагом 2 предназначены для снижения пространственной размерности тензора и, в отличие от блока с шагом 1, не имеют residual connections.
Блок MobileNet, называемый авторами расширяющим сверточным блоком (в оригинале expansion convolution block или bottleneck convolution block with expansion layer), состоит из трёх слоёв:
- Сначала идёт pointwise convolution с большим количеством каналов, называемый expansion layer.
На входе этот слой принимает тензор размерности , а на выходе выдает тензор , где — новый гиперпараметр, названный уровнем расширения (в оригинале expansion factor). Авторы рекомендуют задавать этому гиперпараметру значение от 5 до 10, где меньшие значения лучше работают для более маленьких сетей, а большие — для более крупных (в самой статье во всех экспериментах принимается ).
Этот слой создает отображение входного тензора в пространстве большой размерности. Авторы называют такое отображение «целевым многообразием» (в оригинале «manifold of interest») - Затем идёт depthwise convolution с ReLU6-активацией. Этот слой вместе с предыдущим по сути образует уже знакомый нам строительный блок MobileNetV1.
На входе этот слой принимает тензор размерности , а на выходе выдает тензор , где — шаг свертки (stride), ведь как мы помним, depthwise convolution не меняет число каналов. - В конце идёт 1х1-свертка с линейной функцией активации, понижающая число каналов. Авторы статьи выдвигают гипотезу, что «целевое многообразие» высокой размерности, полученное после предыдущих шагов, можно «уложить» в подпространство меньшей размерности без потери полезной информации, что, собственно и делается на этом шаге (как можно увидеть по экспериментальным результатам, эта гипотеза полностью оправдывается).
На входе такой слой принимает тензор размерности , а на выходе выдает тензор , где — количество каналов на выходе блока.
Фактически, именно третий слой в этом блоке, называемый bottleneck layer, и является основным отличием второго поколения MobileNet от первого.
Теперь, когда мы знаем, как MobileNet устроен внутри, давайте посмотрим, насколько хорошо он работает.
Практические результаты
Сравним между собой несколько архитектур сетей. Возьмем для примера Xception, о котором был прошлый пост, глубокую и старую VGG16, а также несколько вариаций MobileNet.
| Архитектура сети | Количество параметров | Top-1 accuracy | Top-5 accuracy |
|---|---|---|---|
| Xception | 22.91M | 0.790 | 0.945 |
| VGG16 | 138.35M | 0.715 | 0.901 |
| MobileNetV1 (alpha=1, rho=1) | 4.20M | 0.709 | 0.899 |
| MobileNetV1 (alpha=0.75, rho=0.85) | 2.59M | 0.672 | 0.873 |
| MobileNetV1 (alpha=0.25, rho=0.57) | 0.47M | 0.415 | 0.663 |
| MobileNetV2 (alpha=1.4, rho=1) | 6.06M | 0.750 | 0.925 |
| MobileNetV2 (alpha=1, rho=1) | 3.47M | 0.718 | 0.910 |
| MobileNetV2 (alpha=0.35, rho=0.43) | 1.66M | 0.455 | 0.704 |
Самым большим достижением из этих экспериментов мне кажется то, что сейчас сети, способные работать на мобильных устройствах, показывают accuracy выше, чем у VGG16.
Также, в статье про MobileNetV2 показываются весьма интересные результаты на других задачах. В частности, авторы демонстрируют, что SSDLite-архитектура для задачи object detection, использующая MobileNetV2 в свёрточной части, превосходит известный детектор реального времени YOLOv2 по точности на датасете MS COCO, при этом показывая в 20 раз большую скорость и в 10 раз меньший размер (в частности, на смартфоне Google Pixel сеть MobileNetV2 позволяет делать object detection с 5 FPS).
Что дальше?
С MobileNetV2 мобильные разработчики получили почти неограниченный инструментарий в области компьютерного зрения — помимо относительно простых моделей для классификации изображений, теперь мы можем использовать прямо на мобильном устройстве алгоритмы детектирования объектов и семантической сегментации.
При этом использовать MobileNet с помощью Keras и TensorFlow настолько просто, что в принципе разработчики могут делать это, даже не углубляясь во внутреннее устройство алгоритмов, как завещает известный комикс.
Ruslan564
Он быстрее и точнее yolo?
roryorangepants Автор
Да, на COCO test-dev2015 SSDLite+MobileNetV2 показывает 22.1 mAP, тогда как у YOLOv2 всего 21.6. По скорости Google репортят х20 выигрыш по количеству multiply-adds, но конкретные бенчмарковые значения приводят только для SSDLite+MobileNet (270 ms на кадр с MobileNetV1 и 200 ms на кадр с MobileNetV2 на телефоне Pixel One).