

Трудно отслеживать всё новое, что появляется в JavaScript (ECMAScript). И ещё труднее находить полезные примеры кода. В этой статье я собрал 18 фич, перечисленных в списке выполненных предложений TC39, которые были добавлены в ES2016, ES2017 и ES2018 (финальный драфт), и по каждой из фич привёл полезные примеры. Статья длинная, но не трудная.

1. Array.prototype.includes
Includes — это простой метод экземпляра класса в массиве. Он позволяет легко определять, находится ли в массиве элемент (включая NaN, в отличие от indexOf).
ECMAScript 2016 или ES7?—?Array.prototype.includes()
Любопытный факт: авторы спецификации JavaScript хотели назвать метод contains, но это имя уже застолбила Mootools, поэтому назвали includes.
2. Инфиксный оператор возведения в степень
Для математических операций сложения и вычитания есть инфиксные операторы
+ и -. А для возведения в степень часто используется оператор **. В ECMAScript 2016 ** был введён вместо Math.pow.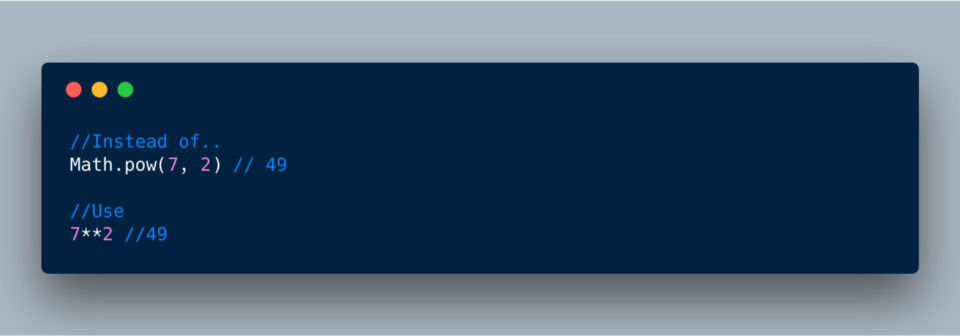
ECMAScript 2016 or ES7?— Инфиксный оператор возведения в степень?**

1. Object.values()
Object.values() — новая функция, аналогичная Object.keys(), только она возвращает все значения собственных свойств объекта, за исключением свойств из прототипной цепочки.
ECMAScript 2017 (ES8)— Object.values()
2. Object.entries()
Object.entries() относится к Object.keys, но возвращает не одни лишь ключи, а ключи и значения в виде массива. С помощью этой функции можно очень легко использовать объекты в циклах или преобразовывать объекты в Map.Пример 1:
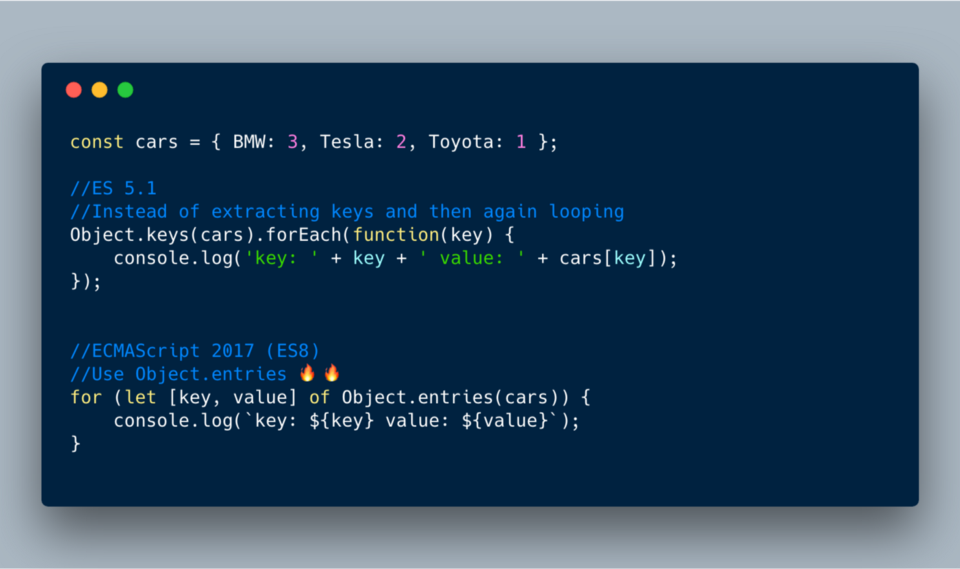
ECMAScript 2017 (ES8)?—?Использование Object.entries() в циклах
Пример 2:

ECMAScript 2017 (ES8)?—?Использование Object.entries() для преобразования объекта в Map
3. Паддинг строк
Для строковых значений было добавлено два метода экземпляров классов —?
String.prototype.padStart и String.prototype.padEnd. Они позволяют добавлять в начало или конец строкового значения любое другое строковое, в том числе пустое.'someString'.padStart(numberOfCharcters [,stringForPadding]);
'5'.padStart(10) // ' 5'
'5'.padStart(10, '=*') //'=*=*=*=*=5'
'5'.padEnd(10) // '5 '
'5'.padEnd(10, '=*') //'5=*=*=*=*='Это удобно, когда нужно выравнивать данные при выводе на экран или в терминале.
3.1 Пример с padStart:
Допустим, у нас есть список чисел разной длины. В начале каждого из них нужно добавить “0”, чтобы все элементы стали состоять из 10 цифр. Это можно сделать с помощью
padStart(10, '0').
ECMAScript 2017?—?пример с padStart
3.2 Пример с padEnd:
padEnd очень удобен, когда мы выводим на экран много элементов разной длины и хотим выровнять их по правой стороне.Ниже приведён хороший пример одновременного использования
padEnd, padStart и Object.entries для красивого вывода данных на экран.
ECMAScript 2017?—?padEnd, padStart и Object.Entries
3.3  Использование padStart и padEnd с эмодзи и другими двухбайтными символами
Использование padStart и padEnd с эмодзи и другими двухбайтными символами
Эмодзи и другие двухбайтные символы представляются с помощью нескольких байтов Unocode. Поэтому padStart и padEnd могут работать не так, как вы ожидаете!
Допустим, нам нужно добавить к строковому значению heart несколько эмодзи
//Notice that instead of 5 hearts, there are only 2 hearts and 1 heart that looks odd!
'heart'.padStart(10, " "); // prints.. 'heart'
"); // prints.. 'heart'Дело в том, что
'\u2764\uFE0F'). Слово heart состоит из 5 символов, так что нужно добавить пять сердечек. Но с помощью '\u2764\ JavaScript добавляет только два \u2764, в результате получается ещё одно P.S.: Можете с помощью этой ссылки проверить преобразование Unicode-символов.
4. Object.getOwnPropertyDescriptors
Это метод возвращает всё, что связано со свойствами заданного объекта (включая методы
get и set). Добавлен он, главным образом, для того, чтобы можно было выполнять теневое копирование/клонирование объекта в другой объект, при котором, в отличие от Object.assign, копируются также геттеры и сеттеры.Object.assign теневым способом копирует всё, за исключением геттеров и сеттеров исходного объекта.
Ниже на примере копирования исходного объекта
Car в новый объект ElectricCar показано, чем Object.assign и Object.getOwnPropertyDescriptors отличаются от Object.defineProperties. При использовании Object.getOwnPropertyDescriptors в целевой объект копируются также геттер и сеттер discount.Было:
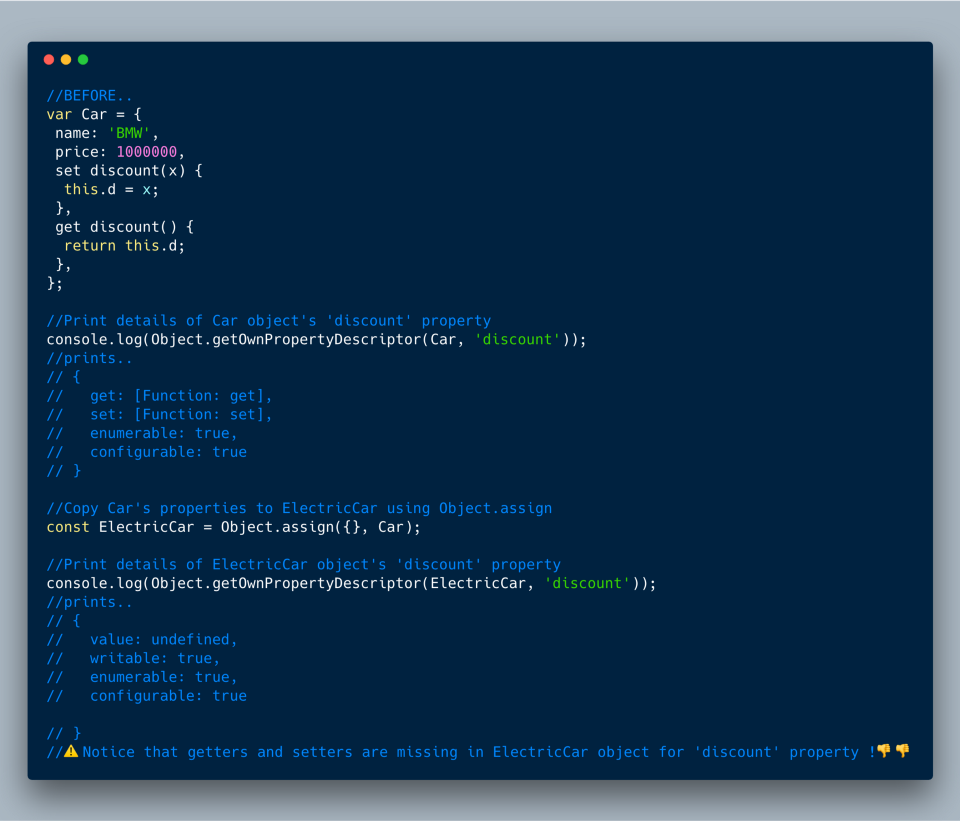
Object.assign
Стало:
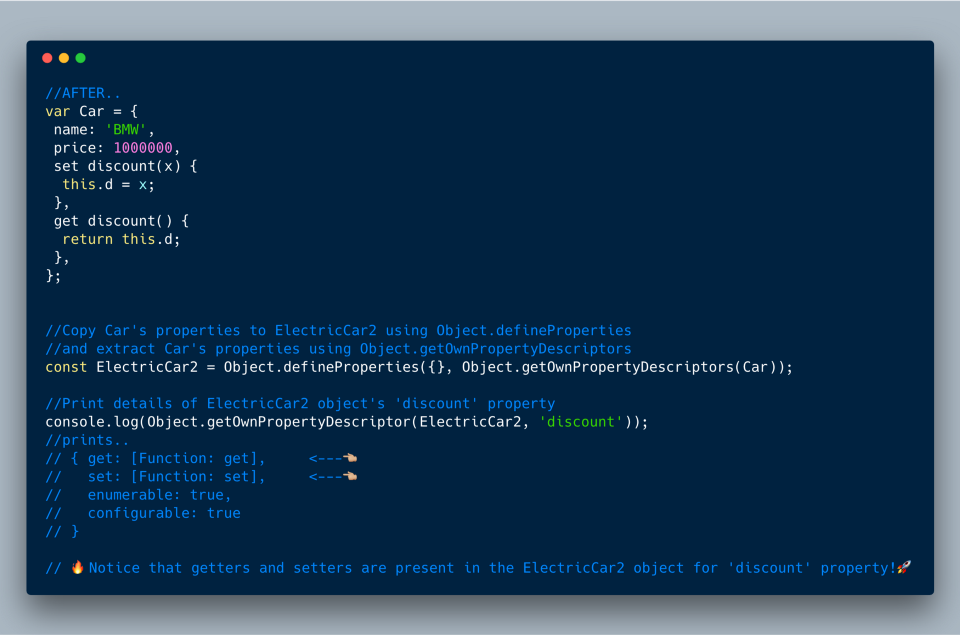
ECMAScript 2017 (ES8)?—?Object.getOwnPropertyDescriptors
var Car = {
name: 'BMW',
price: 1000000,
set discount(x) {
this.d = x;
},
get discount() {
return this.d;
},
};
//Print details of Car object's 'discount' property
console.log(Object.getOwnPropertyDescriptor(Car, 'discount'));
//prints..
// {
// get: [Function: get],
// set: [Function: set],
// enumerable: true,
// configurable: true
// }
//Copy Car's properties to ElectricCar using Object.assign
const ElectricCar = Object.assign({}, Car);
//Print details of ElectricCar object's 'discount' property
console.log(Object.getOwnPropertyDescriptor(ElectricCar, 'discount'));
//prints..
// {
// value: undefined,
// writable: true,
// enumerable: true,
// configurable: true
// }
// Notice that getters and setters are missing in ElectricCar object for 'discount' property !
//Copy Car's properties to ElectricCar2 using Object.defineProperties
//and extract Car's properties using Object.getOwnPropertyDescriptors
const ElectricCar2 = Object.defineProperties({}, Object.getOwnPropertyDescriptors(Car));
//Print details of ElectricCar2 object's 'discount' property
console.log(Object.getOwnPropertyDescriptor(ElectricCar2, 'discount'));
//prints..
// { get: [Function: get],
// set: [Function: set],
// enumerable: true,
// configurable: true
// }
// Notice that getters and setters are present in the ElectricCar2 object for 'discount' property!5. Висячая пунктуация в параметрах функций
Это небольшое нововведение позволяет использовать висячие запятые в конце последнего параметра функции. Зачем? Чтобы с помощью инструментов вроде git blame было видно только новых разработчиков.
Ниже приведён пример проблемы и её решения.
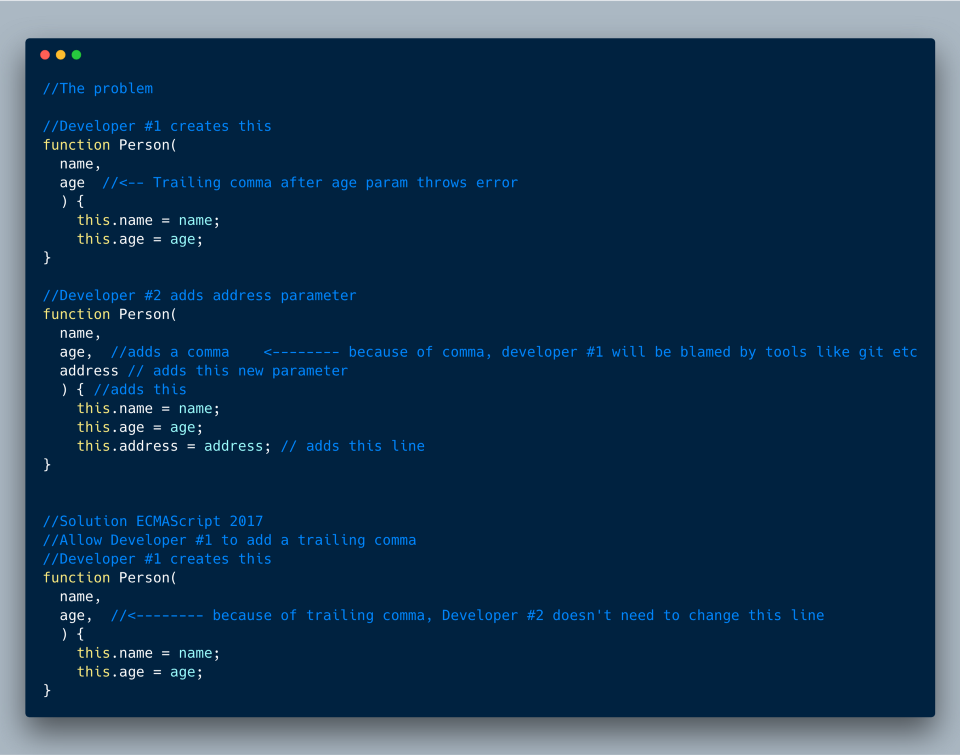
ECMAScript 2017 (ES 8)?—?Висячая запятая в параметре функции
Примечание: Вы также можете вызывать функции с висячими запятыми!
6. Async/Await
На мой взгляд, это самая важная и полезная фича. Функции
async позволяют избежать callback hell и в целом упросить код.Благодаря ключевому слову
async JavaScript-компилятор понимает, что с функцией нужно обращаться иначе. Когда он доходит до слова await, то встаёт на паузу. Компилятор предполагает, что выражение после await возвращает промис, и ждёт, пока промис не будет разрешён или отклонён, после чего продолжает работу.В этом примере функция
getAmount вызывает асинхронные функции getUser и getBankBalance. Можно сделать это в промисе, но использование async/await — более элегантный и простой способ.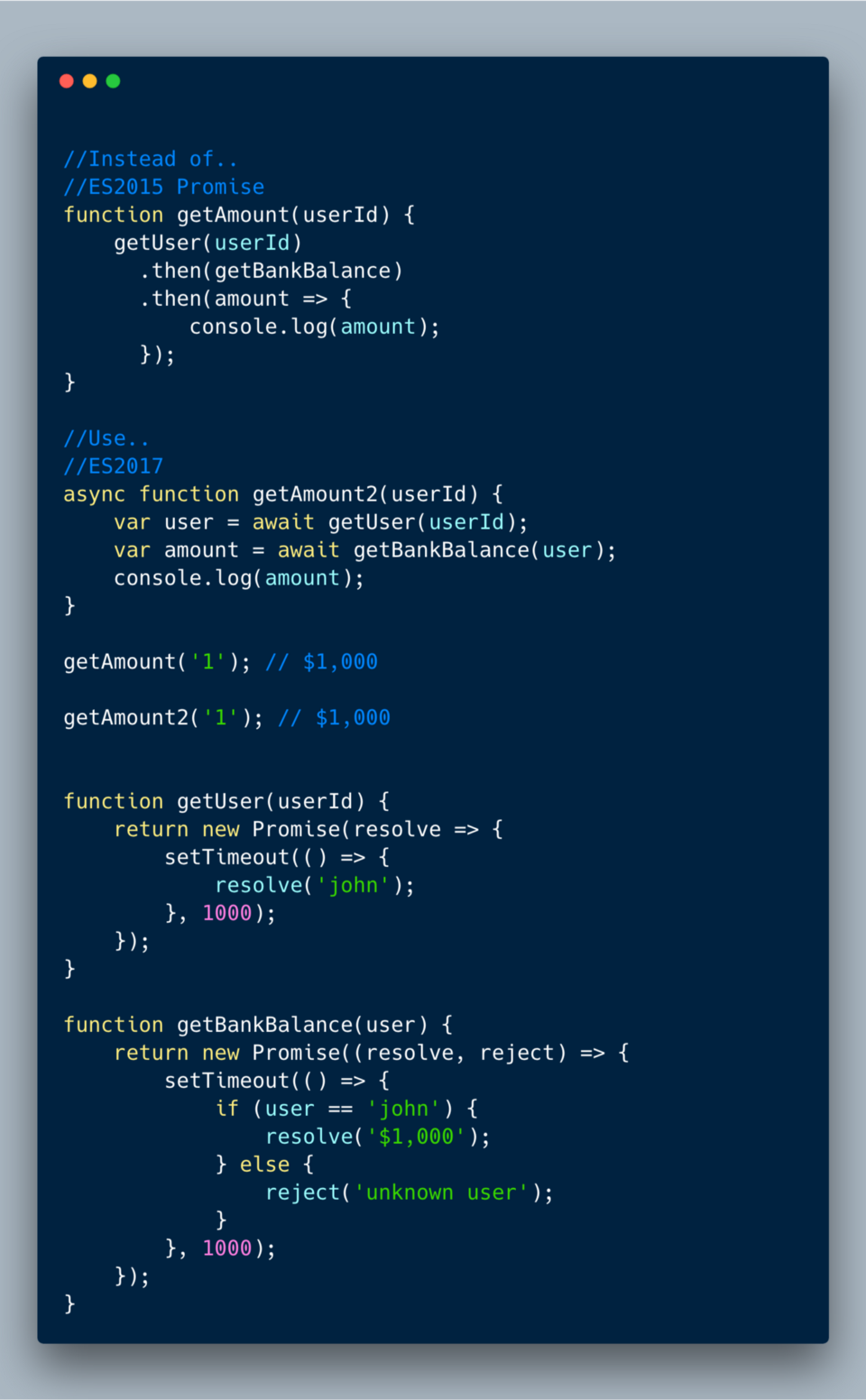
ECMAScript 2017 (ES 8)?—?Базовый пример использования async/await
6.1 Функции Async возвращают промис
Если вы ждёте результат исполнения функции
async, то для его получения придётся воспользоваться синтаксисом промиса then.Допустим, нам нужно журналировать результат в
console.log, но не внутри doubleAndAdd. Подождём результата и для его передачи в console.log используем синтаксис then.
ECMAScript 2017 (ES 8)?—?Функции async/await возвращают промис
6.2 Параллельный вызов async/await
В предыдущем примере мы дважды вызывали
await, но каждый раз ждали по одно секунде (всего две секунды). Можно это распараллелить, потому что a и b не зависят друг от друга при использовании Promise.all.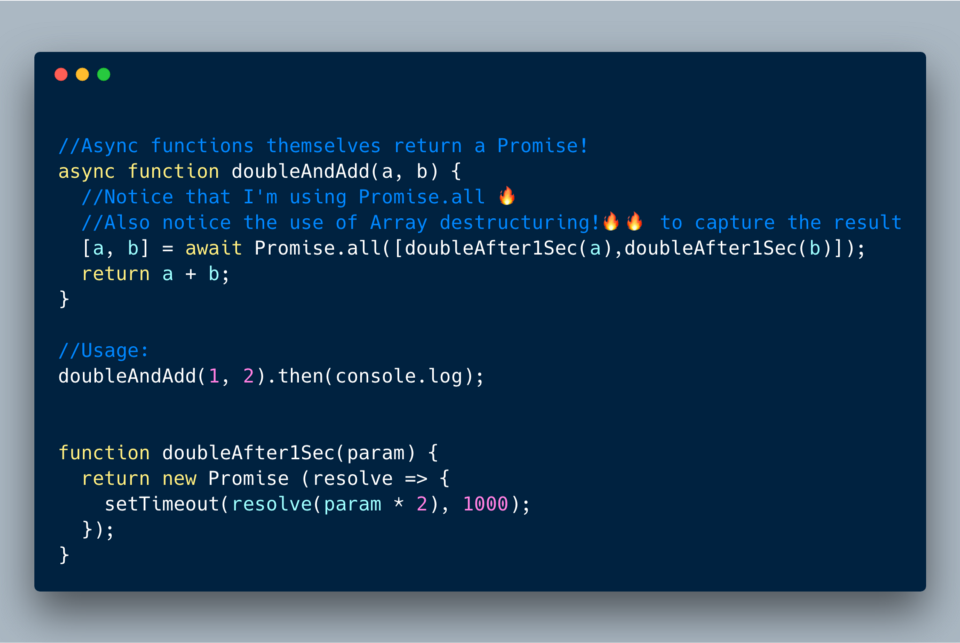
ECMAScript 2017 (ES 8)?—?Использование Promise.all для распараллеливания async/await
6.3 Обработка ошибок с помощью async/await
Есть разные способы обработки ошибок с помощью
async/await.Способ 1 ?—? Использование try catch в функции
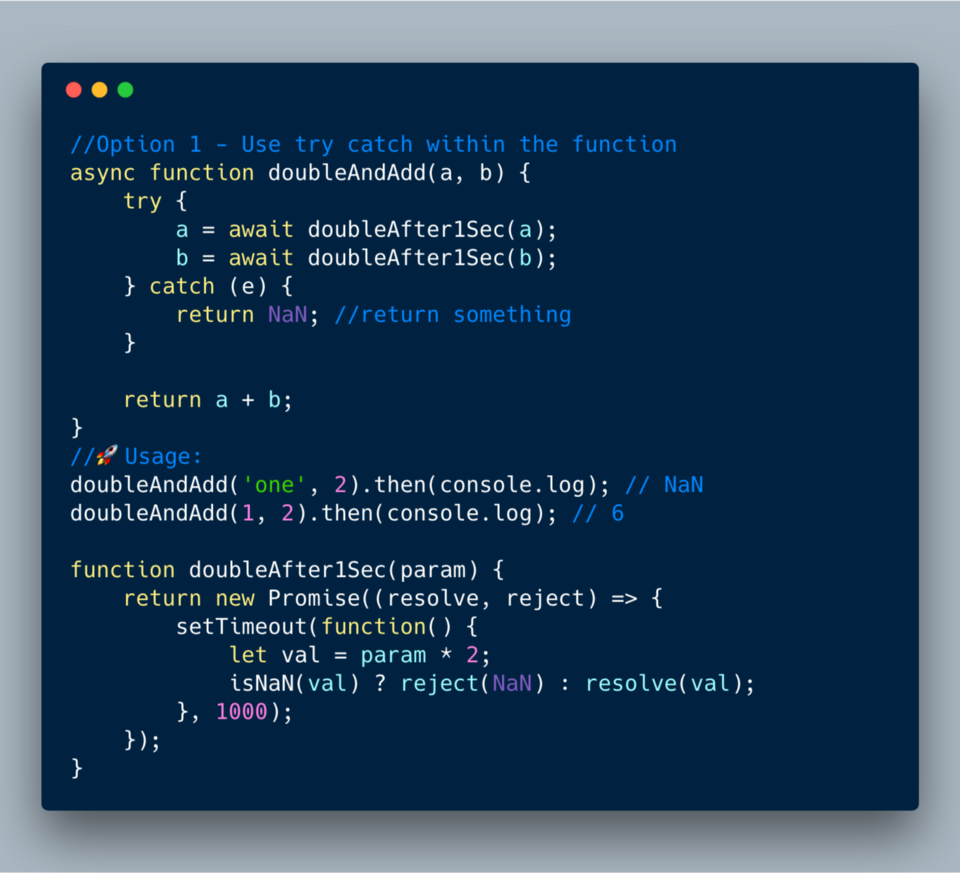
ECMAScript 2017?—?Использование try catch в функции async/await
//Option 1 - Use try catch within the function
async function doubleAndAdd(a, b) {
try {
a = await doubleAfter1Sec(a);
b = await doubleAfter1Sec(b);
} catch (e) {
return NaN; //return something
}
return a + b;
}
//Usage:
doubleAndAdd('one', 2).then(console.log); // NaN
doubleAndAdd(1, 2).then(console.log); // 6
function doubleAfter1Sec(param) {
return new Promise((resolve, reject) => {
setTimeout(function() {
let val = param * 2;
isNaN(val) ? reject(NaN) : resolve(val);
}, 1000);
});
}Способ 2 — Ловля каждого выражения await
Каждое выражение
await возвращает промис, поэтому можете ловить ошибки в каждой строке.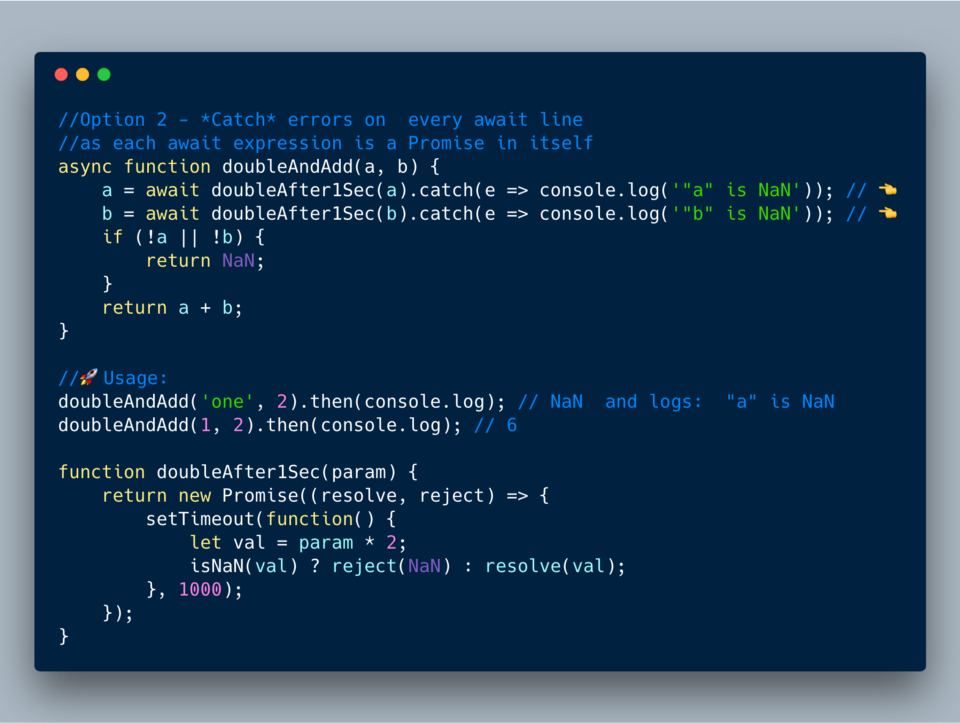
ECMAScript 2017?—?Использование try catch в каждом выражении await
//Option 2 - *Catch* errors on every await line
//as each await expression is a Promise in itself
async function doubleAndAdd(a, b) {
a = await doubleAfter1Sec(a).catch(e => console.log('"a" is NaN')); //
b = await doubleAfter1Sec(b).catch(e => console.log('"b" is NaN')); //
if (!a || !b) {
return NaN;
}
return a + b;
}
//Usage:
doubleAndAdd('one', 2).then(console.log); // NaN and logs: "a" is NaN
doubleAndAdd(1, 2).then(console.log); // 6
function doubleAfter1Sec(param) {
return new Promise((resolve, reject) => {
setTimeout(function() {
let val = param * 2;
isNaN(val) ? reject(NaN) : resolve(val);
}, 1000);
});
}Способ 3 ?— ?Ловля всей функции async/await
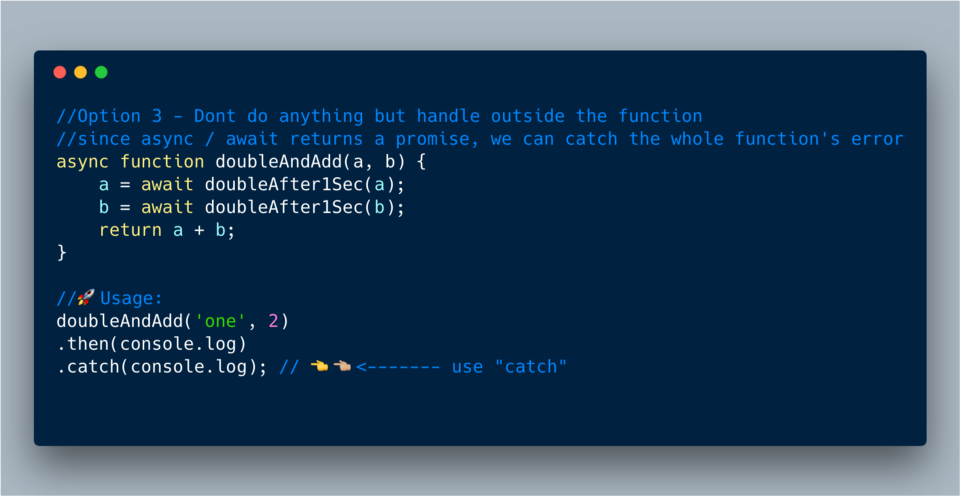
ECMAScript 2017?—?Ловля в конце всей функции async/await
//Option 3 - Dont do anything but handle outside the function
//since async / await returns a promise, we can catch the whole function's error
async function doubleAndAdd(a, b) {
a = await doubleAfter1Sec(a);
b = await doubleAfter1Sec(b);
return a + b;
}
//Usage:
doubleAndAdd('one', 2)
.then(console.log)
.catch(console.log); // <------- use "catch"
function doubleAfter1Sec(param) {
return new Promise((resolve, reject) => {
setTimeout(function() {
let val = param * 2;
isNaN(val) ? reject(NaN) : resolve(val);
}, 1000);
});
}ECMAScript сейчас в находится в стадии финального драфта и выйдет в июне/июле 2018-го. Все описанные ниже фичи включены в Stage-4 и будут частью ECMAScript 2018.
1. Общая память и атомики
Это огромная, очень продвинутая фича, являющаяся ключевым расширением движка JS.
Суть в том, чтобы привнести в JavaScript возможности многопоточности, чтобы в будущем разработчики могли писать высокопроизводительные, параллельно выполняемые приложения, самостоятельно управляя памятью, а не отдавая это на откуп движку.
Достигается это с помощью нового типа глобальных объектов, который называется SharedArrayBuffer. Он хранит данные в общей области памяти, поэтому они могут использоваться и основным потоком выполнения JS, и потоками веб-воркеров.
Раньше, если нам нужно было поделиться данными между основным потоком и потоками веб-воркеров, приходилось копировать информацию и отправлять в другой поток с помощью
postMessage. Теперь это не нужно!Просто используйте
SharedArrayBuffer, и данные мгновенно станут доступны всем упомянутым потокам.Но применение общей памяти может привести к состоянию гонки. Чтобы этого избежать, внедрили глобальные объекты «атомики». Они предоставляют разные методы для блокирования общей памяти, когда какой-то поток выполнения использует данные. Также атомики предоставляют методы для безопасного обновления данных в общей памяти.
Рекомендуется использовать эту фичу через какую-нибудь библиотеку, но пока что таких библиотек не существует.
Дополнительно можете почитать:
- From Workers to Shared Memory?—?lucasfcosta
- A cartoon intro to SharedArrayBuffers?—?Lin Clark
- Shared memory and atomics?—?Dr. Axel Rauschmayer
2. Убрано ограничение Tagged Template literal
Для начала давайте определимся с понятием “Tagged Template literal” (тегированные шаблонные строки), чтобы лучше разобраться в этой фиче.
Тегированные шаблонные строки появились в ES2015+ и позволяют разработчикам настраивать характер интерполирования строковых значений. Обычно они интерполируются так:
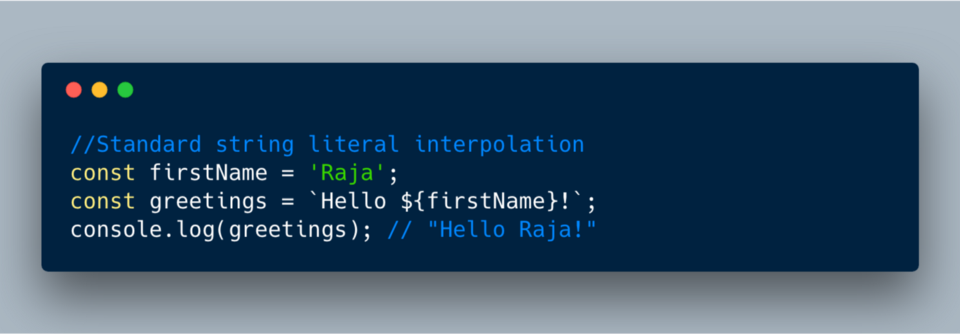
В тегированной строке можно написать функцию для получения прописанных в коде частей строкового литерала, например,
[ ‘Hello ‘, ‘!’ ], и заменяющих переменных, например, [ 'Raja'], в виде параметров кастомной функции (например, greet), и вернуть из неё что угодно.Ниже показано, как кастомная «тегирующая» функция
greet в зависимости от текущего времени присоединяет к строковому литералу выражение “Good Morning!”, “Good afternoon” или “Good evening”, а затем возвращает кастомную строку.//A "Tag" function returns a custom string literal.
//In this example, greet calls timeGreet() to append Good //Morning/Afternoon/Evening depending on the time of the day.
function greet(hardCodedPartsArray, ...replacementPartsArray) {
console.log(hardCodedPartsArray); //[ 'Hello ', '!' ]
console.log(replacementPartsArray); //[ 'Raja' ]
let str = '';
hardCodedPartsArray.forEach((string, i) => {
if (i < replacementPartsArray.length) {
str += `${string} ${replacementPartsArray[i] || ''}`;
} else {
str += `${string} ${timeGreet()}`; //<-- append Good morning/afternoon/evening here
}
});
return str;
}
//Usage:
const firstName = 'Raja';
const greetings = greet`Hello ${firstName}!`; //<-- Tagged literal
console.log(greetings); //'Hello Raja! Good Morning!'
function timeGreet() {
const hr = new Date().getHours();
return hr < 12
? 'Good Morning!'
: hr < 18 ? 'Good Afternoon!' : 'Good Evening!';
}Вероятно, многие теперь захотят использовать «тегированные» функции в разных ситуациях, например, в командах терминала, в HTTP-запросах для компоновки URI, и т.п.
? Проблема с тегированными шаблонными строками
Проблема в том, что спецификации ES2015 и ES2016 не позволяют использовать символы перехода вроде
\u (unicode) и \x (шестнадцатеричный), пока они не будут выглядеть как `\u00A9` или \u{2F804} или \xA9.Если у вас есть тегированная функция, внутри которой используются какие-то другие правила (например, правила терминала), требующие применения
\ubla123abla, что вовсе не похоже на \u0049 или \u{@F804}, то вы получите синтаксическую ошибку.В ES2018 правила уже позволяют использовать на первый взгляд неправильные символы перехода, пока тегированная функция возвращает значения в объект с «приготовленным» (cooked) свойством (неправильные символы «не определены»), а затем «сырое» свойство (с какими угодно символами).
function myTagFunc(str) {
return { "cooked": "undefined", "raw": str.raw[0] }
}
var str = myTagFunc `hi \ubla123abla`; //call myTagFunc
str // { cooked: "undefined", raw: "hi \\unicode" }>3. “dotall”-флаг для регулярных выражений
Хотя сегодня в регулярных выражениях точка (
.) должна соответствовать одному символу, но не соответствует символам новой строки вроде \n \r \f и так далее.К примеру:
//Before
/first.second/.test('first\nsecond'); //falseЭто расширение позволяет оператору-точке соответствовать любому одиночному символу. Чтобы это работало и ничего не сломало, нужно при создании регулярного выражения использовать флаг
\s.//ECMAScript 2018
/first.second/s.test('first\nsecond'); //true Notice: /s Вот весь API из предложения о внедрении фичи:

ECMAScript 2018?—?dotAll-фича для регулярных выражений, позволяющая символу точки с помощью флага /s соответствовать даже \n
4. Захваты именованных групп регулярных выражений
Это расширение привнесло из языков вроде Python, Java и прочих полезную фичу регулярных выражений под названием «именованные группы». Разработчики могут писать регулярные выражения так, чтобы для разных частей группы в регулярном выражении предоставлялись имена (идентификаторы) в формате (
?<nаme>...). А затем эти имена можно использовать для захвата любой группы.4.1 Базовый пример именованной группы
Воспользуемся именами (
?<yeаr>), (?<mоnth>) и ((?year)) для группирования разных частей регулярного приложения. В результате получим объект, который содержит свойство groups со свойствами year, month и year, имеющими соответствующие значения.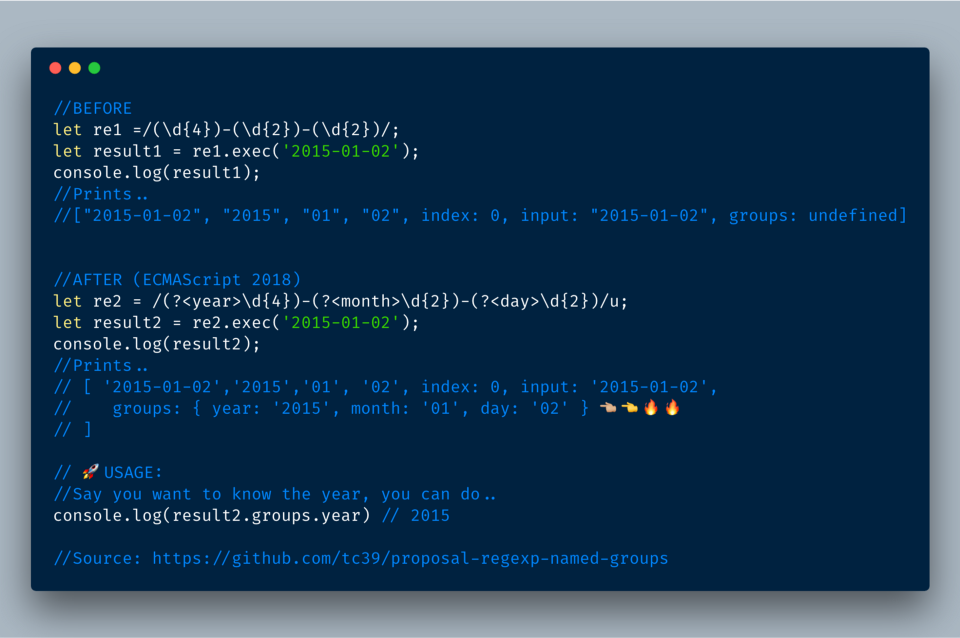
ECMAScript 2018?—?Пример именованных групп в регулярном выражении
4.2 Использование именованных групп внутри регулярного выражения
Можно использовать формат
\k<grоup name> для обратной ссылки на группу внутри самого регулярного выражения: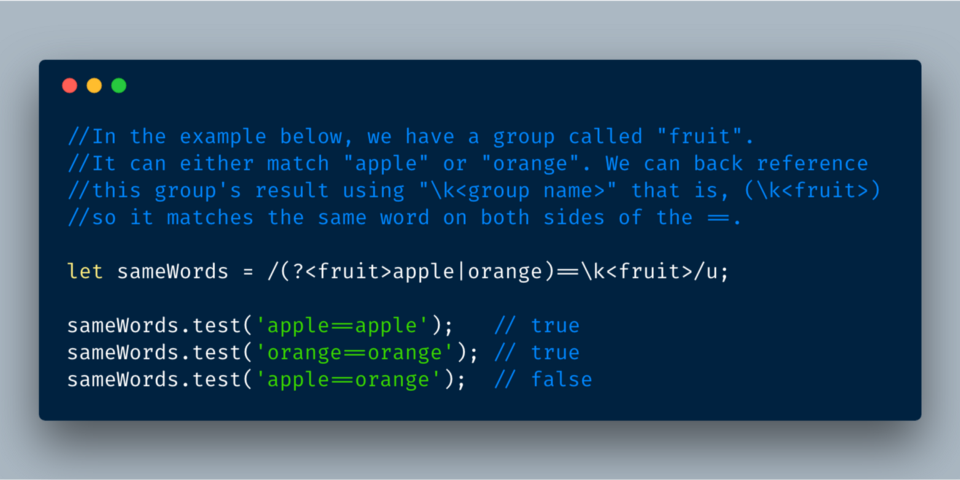
ECMAScript 2018?—?Обратное ссылание на именованную группу в регулярном выражении с помощью \k<grоup name>
4.3 Использование именованных групп в String.prototype.replace
Фича с именованными группами встроена и в строковый метод экземпляра класса
replace. И благодаря этому можно легко менять местами слова в строке. Например, изменить “firstName, lastName” на “lastName, firstName”.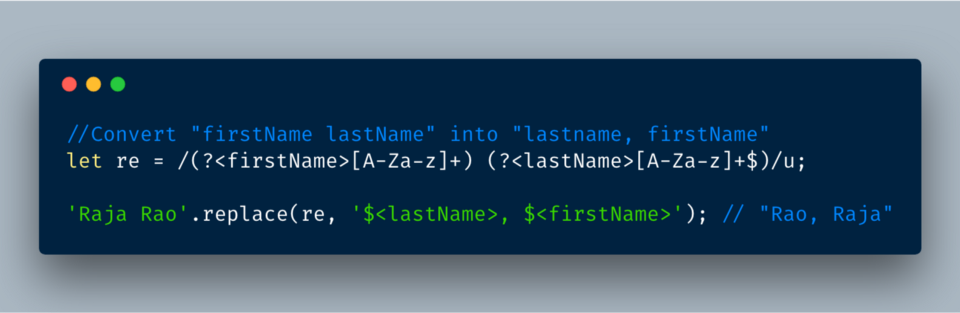
ECMAScript 2018?—?Использование именованных групп в функции replace
5. Rest-свойства объектов
Оператор rest
... (три точки) позволяет извлекать свойства объекта, которые ещё не извлечены.5.1 Можно использовать rest для извлечения только нужных вам свойств

ECMAScript 2018?—?Деструктурирование объекта с помощью rest
5.2 Even better, you can remove unwanted items!
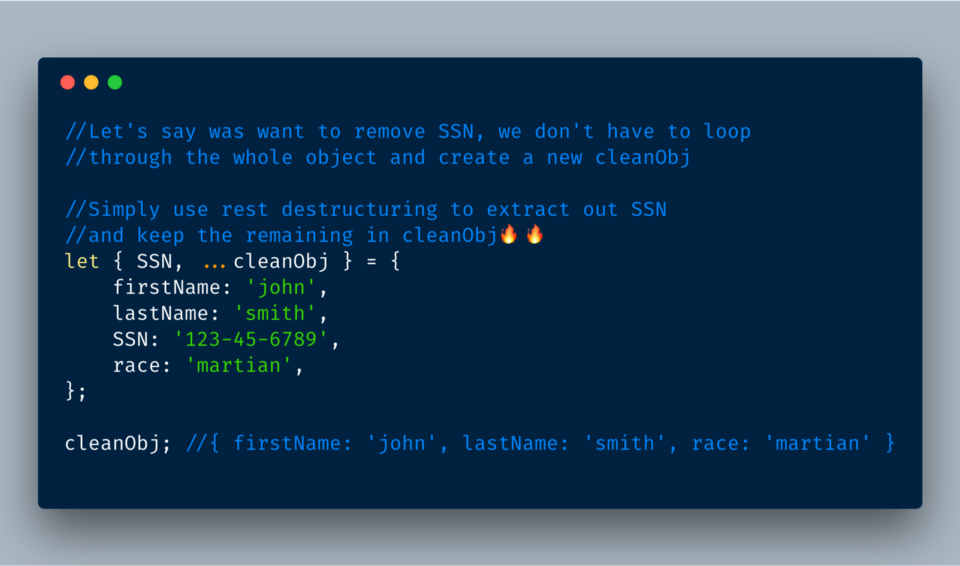
ECMAScript 2018?—?Object destructuring via rest
6. Spread-свойства объектов
Spread-свойства выглядят так же как и rest-свойства с тремя точками
…, но только spread используются для создания (реструктурирования) новых объектов.Подсказка: оператор spread используется справа от знака равенства, rest — слева.
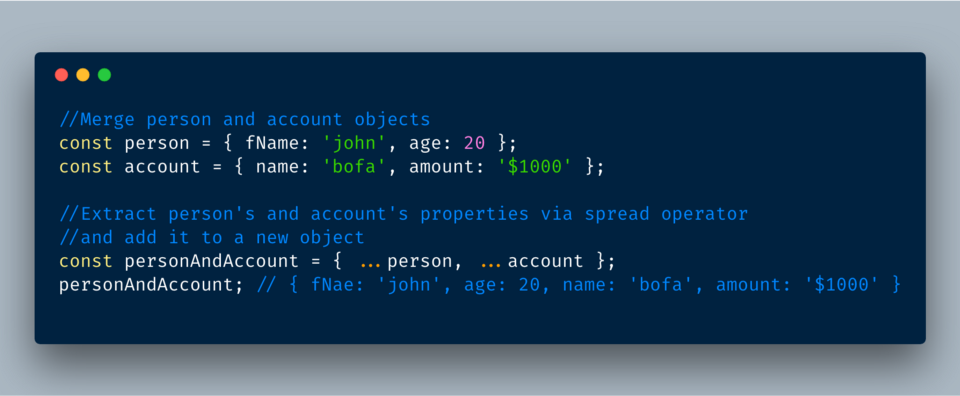
ECMAScript 2018?— Реструктурирование объекта с помощью rest
7. Lookbehind-утверждения для регулярных выражений
Это расширение для регулярных выражений, позволяющее проверять, существует ли какое-то строковое значение непосредственно перед другим строковым.
Можно использовать группу (
?<=…) для положительного утверждения, а группу (?<!…) — для отрицательного утверждения. По сути, оно будет соответствовать до тех пор, пока проходит утверждение -ve.Положительное утверждение: допустим, нужно удостовериться, что перед словом winning есть знак # (#winning), и регулярное выражение должно вернуть строку “winning”.
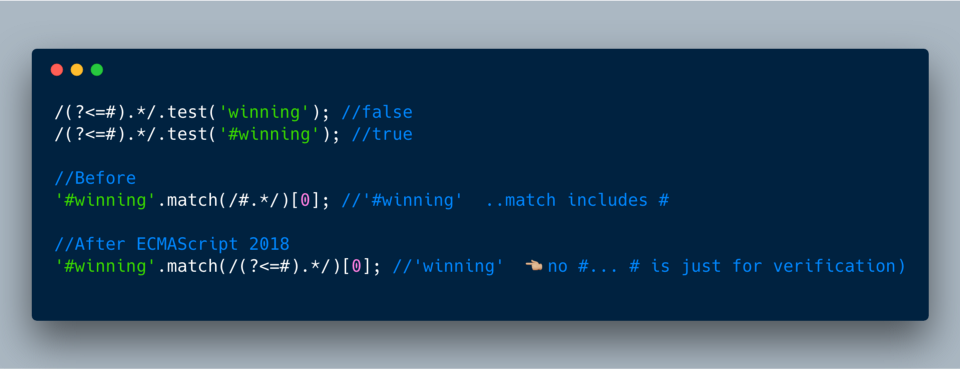
ECMAScript 2018?—?(?<=…) для положительного утверждения
Отрицательное утверждение: пусть нам нужно извлечь числа из строк, в которых перед числами стоят знаки €, но не $.

ECMAScript 2018?—?(?<!…) для отрицательных утверждений
8. Вывод на основании Unicode-свойств (Unicode Property Escapes) для регулярных выражений
Было трудно писать регулярные выражения для поиска соответствия с разными символами Unicode. Такие вещи, как
\w, \W, \d и т. д. соответствуют только символам латинского алфавита и числам. А что насчёт чисел в других языках, например, хинди, греческом и прочих?Нам помогут Unicode Property Escapes. Unicode добавляет к каждому символу свойства с метаданными и использует их для группирования или охарактеризования разных символов.
К примеру, БД Unicode группирует все символы хинди (??????) по свойству
Script со значением Devanagari, а также по свойству Script_Extensions тоже со значением Devanagari. Так что можно поискать по Script=Devanagari и получить все символы хинди.Devanagari можно использовать и для других языков полуострова Индостан — маратхи, санскрита и так далее.
Начиная с ECMAScript 2018 можно использовать
\p вместе с {Script=Devanagari} для вывода всех символов языков Индии. Комбинация \p{Script=Devanagari} в регулярном выражении находит все Devanagari-символы.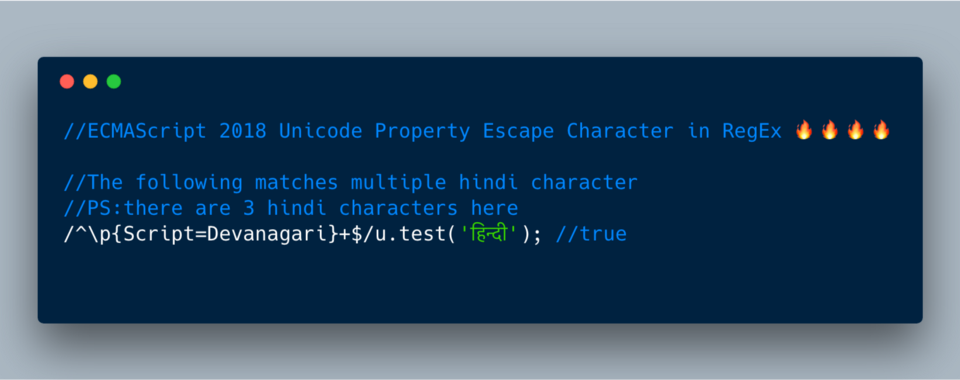
ECMAScript 2018?—?\p
//The following matches multiple hindi character
/^\p{Script=Devanagari}+$/u.test('??????'); //true
//PS:there are 3 hindi characters hТакже БД Unicode группирует все греческие символы по свойству
Script_Extensions (и Script) со значением Greek. Так что можно найти эти символы с помощью Script_Extensions=Greek или Script=Greek.Комбинация
\p{Script=Greek} в регулярном выражении находит все Greek-символы.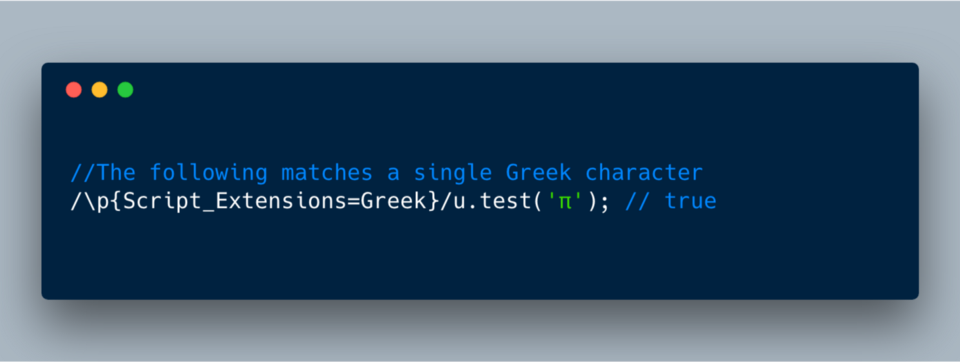
ECMAScript 2018?—?\p
//The following matches a single Greek character
/\p{Script_Extensions=Greek}/u.test('?'); // trueБолее того, БД Unicode хранит разные типы эмодзи с булевым свойствами
Emoji, Emoji_Component, Emoji_Presentation, Emoji_Modifier и Emoji_Modifier_Base, чьи значения равны `true`. Комбинации \p{Emoji}, \Emoji_Modifier и т.д. соответствуют разным типам эмодзи.
ECMAScript 2018?— Использование \p для разных эмодзи
//The following matches an Emoji character
/\p{Emoji}/u.test('?'); //true
//The following fails because yellow emojis don't need/have Emoji_Modifier!
/\p{Emoji}\p{Emoji_Modifier}/u.test('?'); //false
//The following matches an emoji character\p{Emoji} followed by \p{Emoji_Modifier}
/\p{Emoji}\p{Emoji_Modifier}/u.test(''); //true
//Explaination:
//By default the victory emoji is yellow color.
//If we use a brown, black or other variations of the same emoji, they are considered
//as variations of the original Emoji and are represented using two unicode characters.
//One for the original emoji, followed by another unicode character for the color.
//
//So in the below example, although we only see a single brown victory emoji,
//it actually uses two unicode characters, one for the emoji and another
// for the brown color.
//
//In Unicode database, these colors have Emoji_Modifier property.
//So we need to use both \p{Emoji} and \p{Emoji_Modifier} to properly and
//completely match the brown emoji.
/\p{Emoji}\p{Emoji_Modifier}/u.test(''); //trueНаконец, можно использовать заглавный символ перехода \P вместо \p для исключения соответствующих символов.
Источники:
- ECMAScript 2018 Proposal
- https://mathiasbynens.be/notes/es-unicode-property-escapes
8. Promise.prototype.finally()
Finally() — новый метод экземпляра класса, добавленный для промисов. Задача в том, чтобы позволить выполнять коллбэки даже после того, как resolve или reject помогут всё вычистить. Коллбэк finally вызывается без каких-либо значений и выполняется несмотря ни на что.Рассмотрим разные случаи.

ECMAScript 2018?—?finally() в случае с разрешением
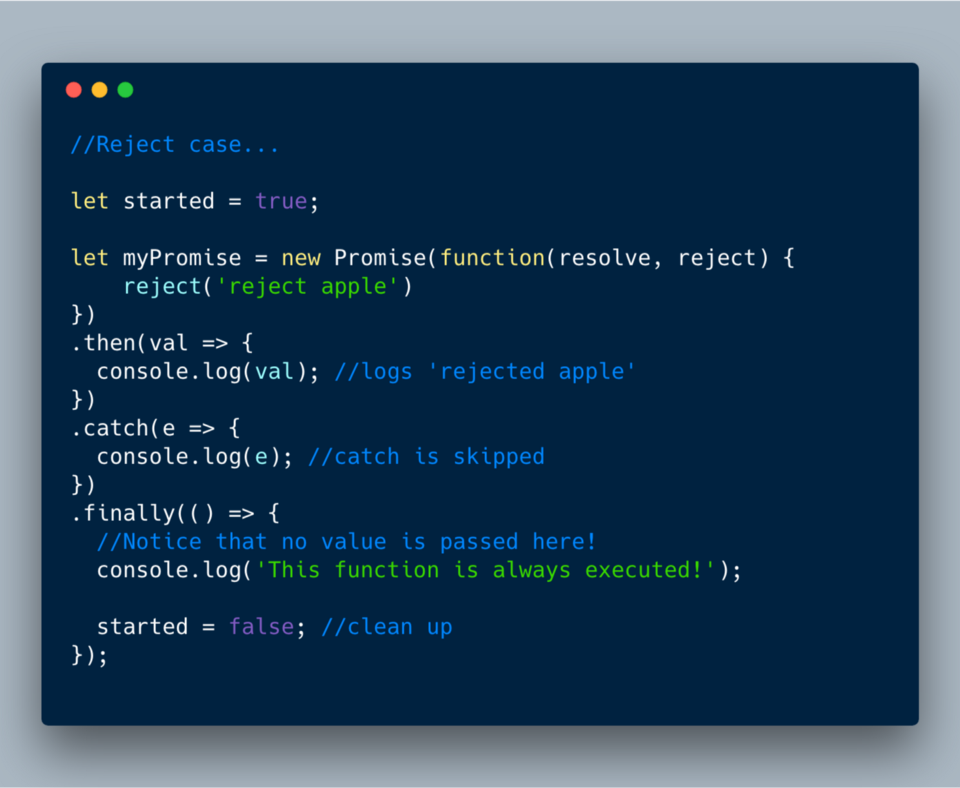
ECMAScript 2018?—?finally() в случае с отказом

ECMASCript 2018?—?finally() в случае с ошибкой, брошенной из промиса

ECMAScript 2018?—?Случай с ошибкой, брошенной из **catch**
9. Асинхронная итерация
Это чрезвычайно полезная фича. Она позволяет легко создавать циклы асинхронного кода!
У нас появился новый цикл “for-await-of”, в котором можно вызывать функции
async, которые в цикле возвращают промисы (или массивы с несколькими промисами). Особенно приятно, что цикл ждёт разрешения каждого промиса, прежде чем выполнять новый цикл.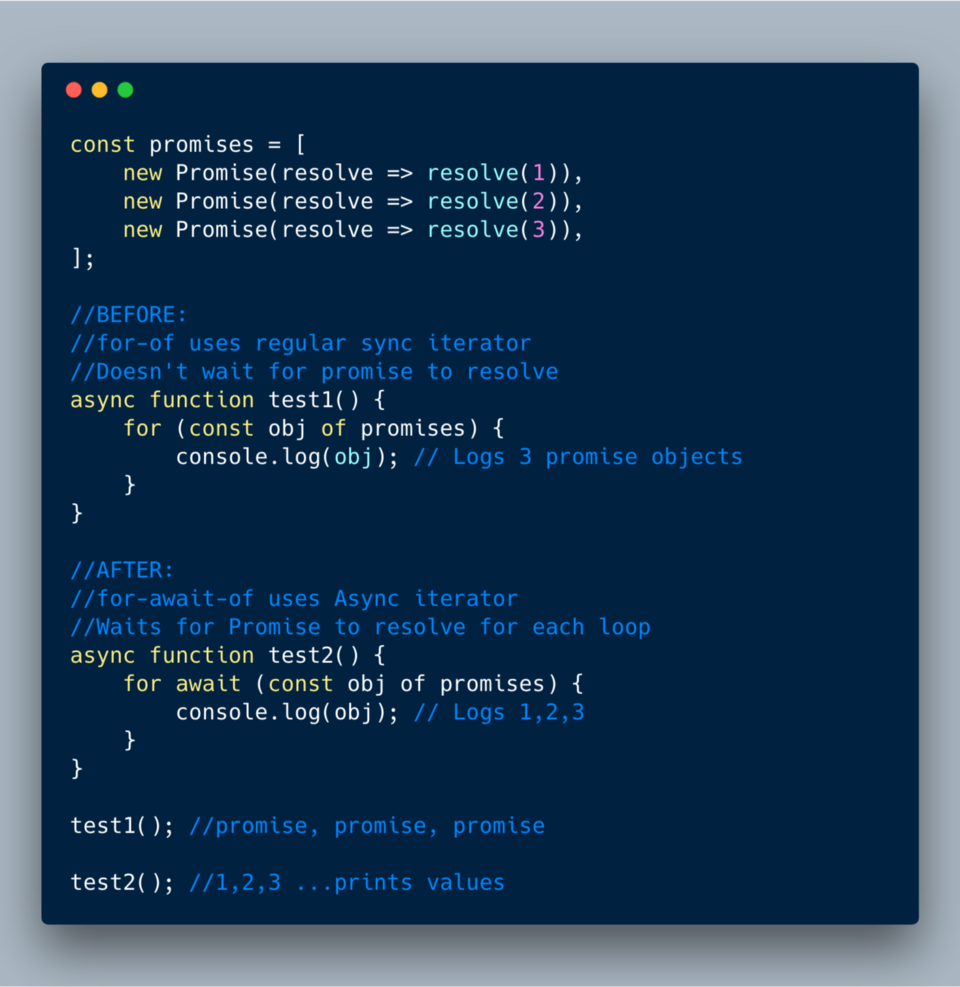
ECMAScript 2018?—?Асинхронный итератор в цикле for-await-of