

Это вторая статья из серии статей об оптимизации кода. Из первой мы узнали, как находить и анализировать узкие места в коде, снижающие производительность. Мы предположили, что главная проблема в примере — медленное обращение к памяти. В этой статье рассмотрим, как снизить расходы при работе с памятью, а следовательно, и увеличить скорость программы.
Вот последняя версия кода:
void Modifier::Update()
{
for(Object* obj : mObjects)
{
Matrix4 mat = obj->GetTransform();
mat = mTransform*mat;
obj->SetTransform(mat);
}
}Оптимизация обращения к памяти
Если наше предположение насчёт памяти верно, мы можем ускорить программу несколькими способами:
- Обновить некоторые объекты в кадре, распределив расходы по большому количеству кадров.
- Обновлять параллельно.
- Создать некий плотный матричный формат (compressed matrix format), потребляющий меньше памяти, но требующий для своей обработки больше ресурсов процессора.
- Эффективно использовать возможности кеша.
Конечно, мы начнём с последнего шага. Разработчики процессоров понимают, что обращение к памяти — процесс медленный, и стараются максимально компенсировать этот недостаток при проектировании оборудования. Например, предварительно извлекаются из памяти данные, которые, вероятно, понадобятся. Когда программа действительно их запрашивает, продолжительность ожидания получается минимальной. Это легко реализовать, если программа обращается к данным последовательно, но совершенно невозможно при случайном обращении. Поэтому обращаться к данным в массиве гораздо быстрее, чем из связного списка (linked list). В сети есть много хорошей документации о работе кешей, так что если вы заинтересованы в создании высокопроизводительных программ, то обязательно изучите её. Вот хороший материал для начала.
Меняем схему размещения в памяти
Нашим первым шагом в оптимизации будет изменение не кода, а схемы размещения в памяти (memory layout). Я сделал простенький инструмент для работы с памятью, который гарантирует, что все данные определённого типа можно найти в одном пуле и что эти данные, насколько возможно, будут доступны по порядку. Так что теперь при размещении Object мы вместо хранения внутри этого экземпляра матриц и прочих типов будем хранить указатель на тип данных, лежащий в пуле таких типов.
В результате хранение данных класса Object меняется с такого:
protected:
Matrix4 mTransform;
Matrix4 mWorldTransform;
BoundingSphere mBoundingSphere;
BoundingSphere mWorldBoundingSphere;
bool m_IsVisible = true;
const char* mName;
bool mDirty = true;
Object* mParent;на такое:
protected:
Matrix4* mTransform = nullptr;
Matrix4* mWorldTransform = nullptr;
BoundingSphere* mBoundingSphere = nullptr;
BoundingSphere* mWorldBoundingSphere = nullptr;
const char* mName = nullptr;
bool mDirty = true;
bool m_IsVisible = true;
Object* mParent;Я так и слышу: «Но теперь используется больше памяти! В ней лежит и указатель, и сами данные, на которые она ссылается». Вы правы. Нам нужно больше памяти. Оптимизация — это зачастую компромисс: больше памяти или меньше точности в обмен на лучшую производительность. В нашем случае добавляется ещё один указатель (4 байта для 32-битной сборки), и нам нужно переходить по указателю из Object, чтобы найти настоящую матрицу, которую надо преобразовать. Да, это дополнительная работа, но поскольку искомые матрицы расположены по порядку, как и сами указатели, которые мы считываем из экземпляра Object, то схема должна работать быстрее, чем чтение из памяти в случайном порядке. Это означает, что нам нужно разместить данные по порядку в памяти, используемой объектами, нодами и модификаторами. В реальных системах такая задача может быть трудно решаемой, но поскольку мы рассматриваем пример, то для подкрепления своей позиции наложим произвольные ограничения.
Наш конструктор Object’а выглядел так:
Object(const char* name)
:mName(name),
mDirty(true),
mParent(NULL)
{
mTransform = Matrix4::identity();
mWorldTransform = Matrix4::identity();
sNumObjects++;
}А теперь выглядит так:
Object(const char* name)
:mName(name),
mDirty(true),
mParent(NULL)
{
mTransform = gTransformManager.Alloc();
mWorldTransform = gWorldTransformManager.Alloc();
mBoundingSphere = gBSManager.Alloc();
mWorldBoundingSphere = gWorldBSManager.Alloc();
*mTransform = Matrix4::identity();
*mWorldTransform = Matrix4::identity();
mBoundingSphere->Reset();
mWorldBoundingSphere->Reset();
sNumObjects++;
}Вызовы gManager.Alloc() являются вызовами простого распределителя блоков (block allocator).
Manager<Matrix4> gTransformManager;
Manager<Matrix4> gWorldTransformManager;
Manager<BoundingSphere> gBSManager;
Manager<BoundingSphere> gWorldBSManager;
Manager<Node> gNodeManager;Он предварительно распределяет большие куски памяти, а затем при каждом вызове Alloc() возвращает следующие N байтов: 64 байта для Matrix4 или 32 для BoundingSphere. Однако для конкретного типа нужно много памяти. Фактически это большой заранее размещённый в памяти массив заданного типа объектов. Одно из преимуществ такого распределителя — объекты заданного типа, размещённые в определённом порядке, будут идти в памяти один за другим. Если вы разместите объекты в том порядке, в каком вы хотите к ним обращаться, то аппаратная часть может эффективнее делать предварительную выборку, обрабатывая объекты в заданном порядке. К счастью, в нашем примере мы проходим по матрицам и прочим структурам в порядке их размещения в памяти.
Теперь, когда все объекты, матрицы и ограничивающие сферы хранятся в порядке обращения, перепрофилируем программу и посмотрим, изменилась ли производительность. Обратите внимание, что единственным изменением кода стало изменение размещения в памяти и способа использования данных посредством указателей. Например, Modifier::Update() становится:
void Modifier::Update()
{
for(Object* obj : mObjects)
{
Matrix4* mat = obj->GetTransform();
*mat = (*mTransform)*(*mat);
obj->SetDirty(true);
}
}Поскольку мы работаем с указателями на матрицы, больше не нужно копировать результаты матричного умножения обратно в объект с помощью SetTransform: мы преобразуем сразу на месте.
Как изменилась производительность
После изменений сначала проверяем, что код корректно компилируется и исполняется. Вот предыдущие результаты из контрольно-измерительного профиля:

А вот что получилось после изменения схемы размещения в памяти:

То есть мы ускорили программу с 17,5 мс на кадр до 10,15 мс! Стало почти вдвое быстрее после изменения всего лишь схемы размещения данных в памяти.
Запомните из этой серии статей главное: схема размещения данных в памяти критически важна для производительности вашей программы. Люди говорят об опасности поспешных оптимизаций, но, как подсказывает мой опыт, небольшая предусмотрительность относительно связи данных с порядком обращения и обработки может очень сильно повысить производительность. Если не можете заранее спланировать схему размещения, то старайтесь писать код, благоприятствующий реорганизациям схемы размещения и использования, это облегчит оптимизации. В большинстве случаев тормозит не код, а обращение к данным.
Следующее узкое место
Код стал быстрее, но достаточно ли? Конечно, нет. Характеристики производительности изменились, так что нужно перепрофилировать и найти следующего кандидата на оптимизацию. Сравним прогоны семплирующего профилировщика. Было:

Стало:

Обратите внимание, что семплирующий профиль не говорит нам, работает ли программа теперь быстрее. Он показывает лишь относительное количество времени, потраченное на каждую функцию. Теперь дольше всего работает функция умножения матричного оператора (matrix operator multiply function). Это не значит, что она замедлилась, просто по сравнению с другими на её выполнение стало уходить больше времени. Давайте посмотрим на наше семплирование, чтобы понять, где теперь находятся узкие места.
Сначала взглянем на Modifier::Update(). Матрица больше не копируется в стек. Это целесообразно, потому что мы передаём указатель в матрицу, а не копируем все её 64 байта.

Большая часть времени работы функции тратится на настройку вызова матричного умножения, а затем на копирование результата в расположение obj->mTransform (ниже показан сокращённый ассемблер).

Возникает вопрос: как уменьшить стоимость вызова функции? Ответ простой: нужно инлайнить её. Но если присмотреться к функции матричного умножения, то станет понятно, что она уже готова для инлайнинга. Тогда в чём дело?
Если функция достаточно маленькая, то компиляторы зачастую решают инлайнить её автоматически. Но программисты могут управлять этим поведением. Можно изменить максимальный размер инлайненной функции, а ещё некоторые компиляторы позволяют инлайнить «принудительно», хотя это имеет свою цену. Размер кода может увеличиться, а кеш начнёт буксовать при исполнении большего количества байтов из разных мест.
Есть SIMD?
Оператор матричного умножения использует одиночные числа с плавающей запятой, а не SIMD (Single Instruction Multiple Data: современные процессоры предоставляют инструкции, которые умеют выполнять одну инструкцию в нескольких экземплярах данных — вроде одновременного умножения четырёх чисел с плавающей запятой). Даже если сказать компьютеру, что хочешь использовать SIMD, он вас проигнорирует и сгенерирует подобный код:

Здесь нет SIMD-инструкций, потому что им нужны данные, выравненные по 16 байтов, а у нас только 4-байтное выравнивание. Конечно, можно загрузить невыравненные данные, а затем перенести их в SIMD-регистры. Но если объём SIMD-обработки не слишком велик, то скорость работы может оказаться ниже, чем при использовании одного числа с плавающей запятой за раз. К счастью, мы написали диспетчер памяти для таких объектов, так что можно принудительно сделать для наших матриц 16-байтное (или ещё более крупное) выравнивание. В этом примере я остановился на 16. Также я заставил библиотеку Vectormath генерировать только SIMD-инструкции.
При следующем прогоне профилировщика выяснилось, что средняя длительность кадра снизилась с 10,15 примерно до 7 мс!

Посмотрим на семплирующий профиль:
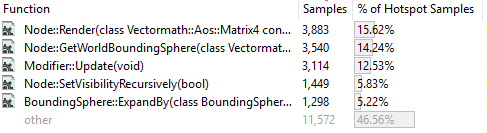
Исчез оператор матричного умножения. Преобразование SIMD-инструкций настолько уменьшило размер функции (с 1060 байтов примерно до 350), что компилятор смог её инлайнить. Код матричного умножения был включён в каждую вызывавшую его функцию, теперь они не вызывают экземпляр функции умножения. В качестве побочного эффекта размер кода увеличился (.exe-файл вместо 255 стал занимать 256 Кб, так что меня это не слишком волнует), но зато теперь не нужно копировать параметры функций в стек ради их использования вызываемой функцией.
Рассмотрим подробнее Modifier::Update():
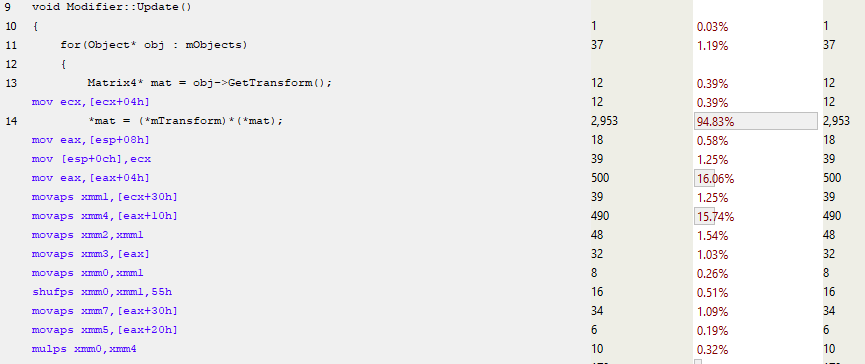
В 13-й строке берётся указатель на mTransform, и почти сразу после этого матричный SIMD-код использует MOVAPS-инструкцию (Move Aligned Single-Precision Floating-Point Values) для заполнения xmm-регистров. Так что мы не только одновременно обрабатываем по четыре числа с плавающей запятой с помощью инструкций вроде MULPS (Multiply Packed Single-Precision Floating-Point Values), но и одновременно загружаем эти числа. В результате сильно уменьшается количество инструкций в функции и вырастает производительность. Тормоза всё ещё есть, их можно приписать промахам кеша, однако сейчас производительность повысилась, и во многом благодаря улучшению использования инструкций и инлайнингу. Раньше в коде часто вызывалось матричное умножение, а теперь мы избавились от значительного объёма вызовов функций.
Итак, мы снизили длительность обработки фрейма с 17,5 примерно до 7 мс, то есть в 2,5 раза подняли производительность без ухудшения кода. Он стал выполняться быстрее без значительного увеличения сложности. Мы ограничили способ размещения данных в памяти, но всё ещё можем вносить низкоуровневые изменения без изменения высокоуровневого кода.
Дополнительное задание: виртуальные функции
В своей презентации 2009 года я пошёл гораздо дальше, чем здесь: сломал код, убрал все виртуалы и сделал код менее гибким, но ещё вдвое увеличил производительность. Я не буду сейчас этого делать. Уверен, мы можем оптимизировать наш пример ещё больше, но за это придётся заплатить читабельностью, расширяемостью, портируемостью и удобством сопровождения. Вместо этого мы пройдёмся по реализации и рассмотрим влияние виртуальных функций.
Виртуальными называют функции в базовом классе, которые можно переопределить в производных классах. Например, в классе Object бывает виртуальная функция Render(), от которой можно наследовать и создать объекты Cube() и Elephant(), определяющие функциональность Render(). Эти новые объекты можно добавить к одному из Node’ов, и при вызове Render() через указатель в нашем исходном Object будут вызваны переопределённые функции Render() — и нарисуют на экране кубик или слона.
Самым простым тестом для нашего примера будет метод SetVisibilityRecursively() в Object’ах и Node’ах. Он используется при отбраковке (culling phase), когда нода находится целиком внутри или снаружи усечённой фигуры (frustum), так что её дочерние элементы могут быть просто назначены видимыми или невидимыми. В случае с Object’ом всего лишь задаётся внутренний флаг:
virtual void SetVisibilityRecursively(bool visibility)
{
m_IsVisible = visibility;
}В случае с Node для всех дочерних элементов вызывается SetVisibilityRecursively():
void Node::SetVisibilityRecursively(bool visibility)
{
m_IsVisible = visibility;
for(Object* obj : mObjects)
{
mObjects[i]->SetVisibilityRecursively(visibility);
}
}Вот что мы видим в Node-версии при анализе семплирующего профиля:
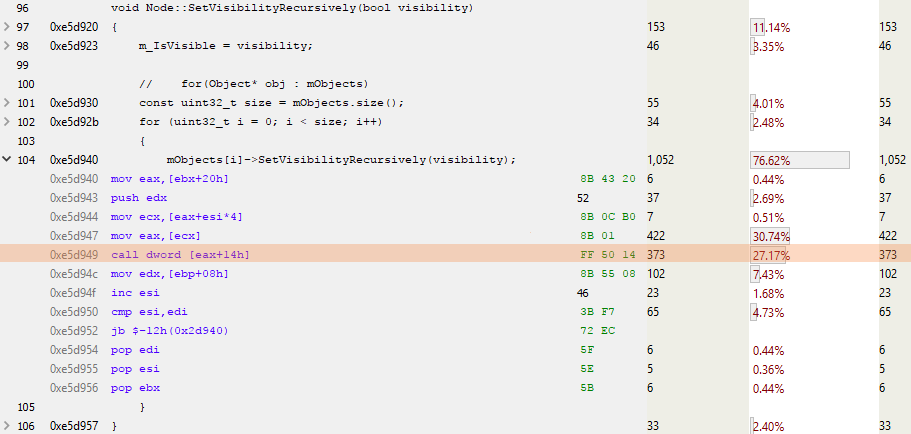
ESI — счётчик для цикла, а EAX — указатель на следующий объект. Интересна выделенная строка CALL DWORD [EAX+14h]: здесь вызывается виртуальная функция, расположенная в 0 ? 14 (десятичное 20) байтах от начала виртуальной таблицы. Поскольку указатель занимает 4 байта, а все разумные люди начинают счёт с 0, то это вызов пятой виртуальной функции в виртуальной таблице объекта. Или, как мы видим ниже, SetVisibilityRecursively():

Для вызова виртуальной функции нужно сделать чуть больше работы. Виртуальная таблица должна быть загружена, потом в ней ищется виртуальная функция, вызывается, ей передаются какие-то параметры, а также «этот» указатель.
Виртуально отсутствующие виртуалы
В следующем примере кода я в Node’ах и Object’ах заменил виртуальные функции нормальными. Это значит, что мне нужно держать два массива в каждом Node (Node’ах и Object’ах), поскольку они отличаются друг от друга. Пример:
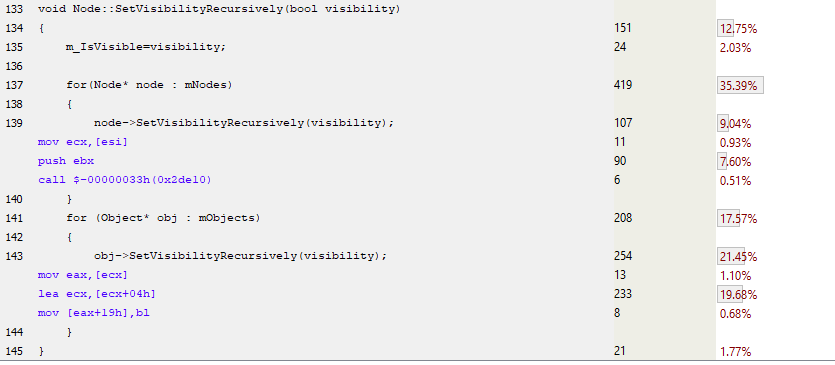
Как видите, здесь нет загрузок виртуальных таблиц и разыменования виртуальных функций. В первом случае есть лишь простой вызов функции для реализации Node::SetVisibilityRecursively(), а во втором случае в реализации Object’а функция полностью инлайнена. Компилятор не может инлайнить виртуальные функции, потому что при компиляции их невозможно определить, только во время исполнения. Так что эта невиртуальная реализация должна работать быстрее. Давайте профилируем и узнаем.

Эта оптимизация очень мало изменила производительность: с 6,961 на 6,963 мс. Означает ли это, что наш код замедлился на 0,002 мс? Вовсе нет. Такое различие можно отнести к шумовому фону системы, представляющей собой персональный компьютер под управлением ОС, которая одновременно выполняет множество задач (обновляет мою ленту в Twitter, проверяет почту, обновляет анимационные гифы на странице, которую я забыл закрыть). Чтобы понять, насколько ваша ОС влияет на исполняемый код, можно воспользоваться бесценным инструментом Windows Performance Analyser. Эта софтина не только покажет производительность вашего кода, но и холистически отобразит всю вашу систему. Так что если код неожиданно стал обрабатываться вдвое дольше, то проверьте, не виноват ли в этом кто-то посторонний, крадущий ваши циклы процессора. Также можете почитать превосходный блог Брюса Доусона.
Итак, удаление виртуальных функций очень мало влияет на производительность кода. Несмотря на уменьшение количества поисков по виртуальной таблице и исполнение меньшего количества инструкций, программа работает с той же скоростью. Вероятнее всего, дело в Чудесах Современного Оборудования — предсказание ветвления и спекулятивное исполнение хороши не только для хакинга, но и для того, чтобы взять ваш повторяющийся код и вычислить, как исполнить его максимально быстро.
Процитирую Генри Петроски (Henry Petroski):
«Самое удивительное достижение современной индустрии ПО — продолжение отказа от устойчивых и ошеломляющих успехов индустрии аппаратной».
Я показал вам, что виртуальные функции не бесплатны в использовании, но в данном случае стоимость пренебрежимо мала.
Резюме
Мы профилировали образец кода, выявили узкие места и постарались уменьшить их влияние. После каждого изменения кода мы перепрофилировали его, чтобы понять, стало хуже или лучше (ошибки полезны, мы на них учимся). И на каждом этапе мы лучше понимаем код: как он исполняется, как обращается к памяти. Наше решение минимально изменяет высокоуровневый код и снижает длительность отрисовки отдельного кадра с 17 до 7 мс. Мы узнали, что память работает медленно и для написания быстрого кода нужно работать с железом.
В третьей части серии мы рассмотрим определение, анализ и оптимизацию узких мест производительности, которые мы недавно обнаружили в League of Legends.
svr_91
Нифига не понял.
1) Вы убрали копирование в стек и из стека, и сказали, что программа ускорилась из-за использования самописного аллокатора
2) Вы начали использовать SIMD инструкции, и выигрыш от них записали на счет заинлайненных функций.
Что-то здесь явно не так
QtRoS
Да перевод ни о чем, чего только стоит слово «кадр» для стекового фрейма (предположительно, оригинал не читал). AloneCoder, может в черновики и на доработку?
Amomum
По-русски его называют и кадром тоже. ru.wikipedia.org/wiki/%D0%A1%D1%82%D0%B5%D0%BA%D0%BE%D0%B2%D1%8B%D0%B9_%D0%BA%D0%B0%D0%B4%D1%80 например.
QtRoS
В статье на профильном ресурсе уместнее более распространенный вариант.
P.S. В университетских лекциях (и билетах) эта тема называлась «Дисплей памяти функции»… Но это прямо совсем экзотика.
Amomum
Если верить количеству результатов в гугле, «стековый фрейм» действительно популярнее (2600 результатов против 1400). Лично я никогда не сталкивался с «фреймом», но большой разницы не вижу — что так калька с английского, что эдак.