
Всем привет,
В предыдущей статье я писал о том, что мы сделали новую in-memory БД — быструю и с богатыми функциональными возможностями — Reindexer.
В этой статье хочу рассказать как при помощи Reindexer можно реализовать полнотекстовый поиск по сайту, написав минимум application кода.

Вообще, полнотекстовый поиск по сайту — эта важная фича, в наше время, обязательная, для любого интернет сайта. От качества и скорости работы поиска зависит
как быстро пользователи найдут интересующую их информацию или товары, которые они планируют приобрести.
Лет 15-20 назад поиск был абсолютно не интерактивным и простоватым — на сайтах была поисковая строчка и кнопка "Искать". От пользователя требовалось корректно,
без опечаток, и в точной форме ввести, что он хочет найти и нажать кнопку "Искать". Дальше — секунды ожидания, перезагрузка страницы — и вот они результаты.
Зачастую, не те, которые ожидал увидеть пользователь. И все повторялось по новой: ввести новый запрос, кнопка "Искать" и секунды ожидания. По современным меркам — вопиющие издевательство над базовыми принципами UX и пользователями.
За последние десятилетия уровень поисковых движков в среднем заметно подрос — они уже готовы прощать пользователю опечатки, слова в разных словоформах, а самые продвинутые могут преобразовывать поисковые запросы, введённые транслитом или на неверной раскладке клавиатуры, например, так "zyltrc" — "яндекс", по ошибке, введенный на английской раскладке.
Так же, подросла и интерактивность поисковых движков — они научились выдавать "саггесты" — предложения пользователю, что дальше стоит ввести в поисковой строчке, например, пользователь начинает вводит "прези", а ему по мере ввода автоматически предлагается подставить слово "президент".
Еще более продвинутый вариант интерактивного поиска — "search as you type": выдача поиска автоматически отображается по мере того, как пользователь вводит запрос.
Возможностей появилось много, однако, они не бесплатные — чем больше ошибок поиск может исправить, тем медленнее он работает. А если поиск работает медленно, то о саггестах и instant поиске придётся забыть.
Поэтому, зачастую разработчикам приходится идти на компромисс — либо отключать часть функционала, либо отключать интерактивность, либо заливать железом и тратить много денег на серверную инфраструктуру.
Итак, это было немного лирики. Давайте перейдем к практике — реализуем при помощи Reindexer поиск по сайту, без компромиссов.
А начнем мы сразу с результатов — что получилось: распарсили весь Хабр, включая комментарии и метаданные, загрузили его их реиндексер, и сделали бэкенд и фронтенд поиска по всему Хабру.
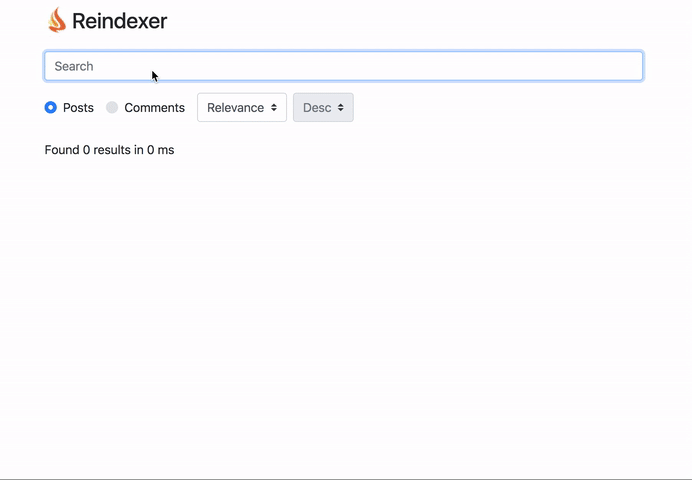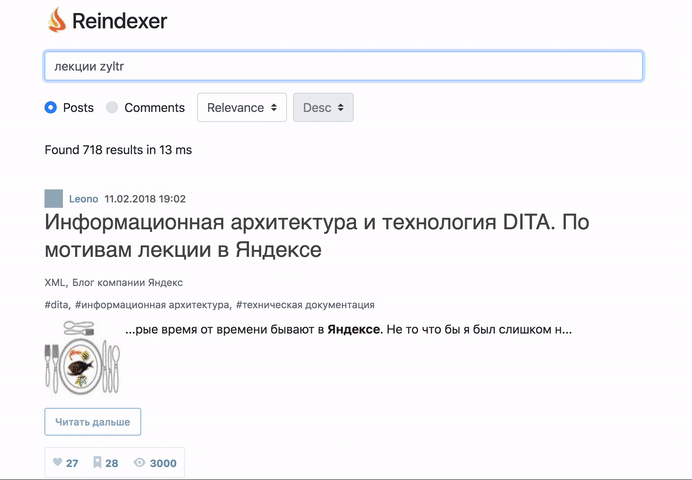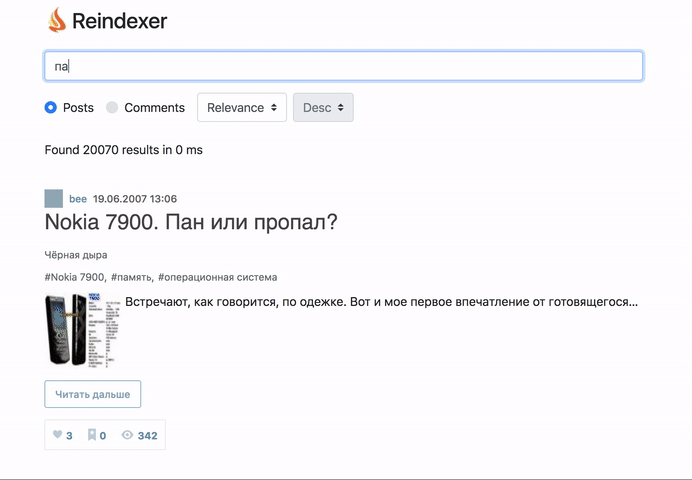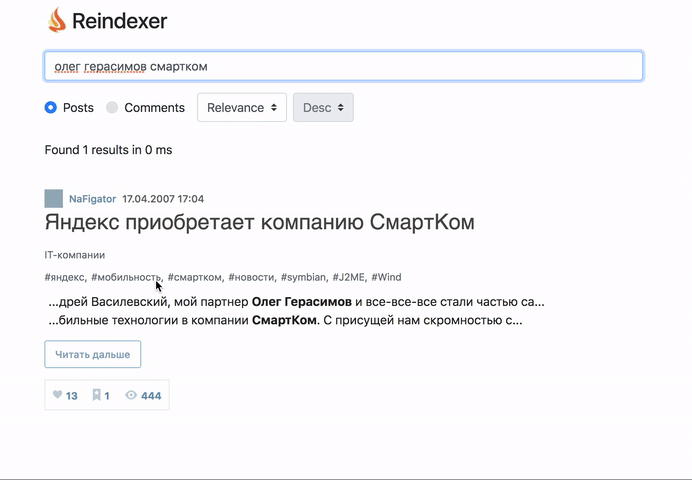
Пощупать вживую, то, что получилось можно тут: http://habr-demo.reindexer.org/
Если говорить про объем данных, то это — около 5гб текста, 170 тысяч статей, 6 миллионов комментариев.
Поиск работает со всеми фичами — транслит, неверная раскладка клавиатуры, опечатки и словоформы.
Однако, дисклеймер — все же собранный "на коленке" проект, за неделю, свободными от прочих дел вечерами. Поэтому прошу не судить строго.
Работает на 1-м VPS 4x CORE, 12 GB RAM. Минимально, можно было бы ужать до 1x CORE, и 10GB RAM, но оставили немного резерва — вдруг хабро-эффект, сами понимаете.
Реализация всего проекта < 1000 строчек, из которых заметная часть — парсер страничек habra, раскладывающий html по структурам с данными.
Дальше в статье расскажу, как это реализовано.
Бэкенд
Структура и используемые компоненты
Бэкенд — это golang приложение. В качестве http сервера и роутера используются fasthttp и fasthttprouter. В данном конкретном случае, можно было бы
использовать любой другой набор сервера и роутера, но решил остановиться на них.
В качестве БД используется reindexer, а для парсинга html страниц — замечательная библиотечка goquery
Структура приложения очень простая и состоит всего из 4-ех модулей:
- Репозиторий — отвечает за работу с хранилищем данных, так же в нем описание моделей данных
- HTTP — отвечает за обработку запросов
- Парсер — отвечает за парсинг страничек Хабра
- main — обработка интерфейса командной строки и запуск/инициализации компонентов
Методы API
- /api/search – полнотекстовый поиск постов и комментариев
- /api/posts/:id — получение поста по ID
- /api/posts — получение листинга постов с фильтрацией
Модели данных
Модели данных — это golang структуры. При работе с Reindexer в тэгах полей структуры описываются индексы, которые будут построены по полям.
Остановлюсь на выборе индексов подробнее — от выбора индексов зависит как и скорость выполнения запросов, так и потребляемая память.
Поэтому очень важно назначить правильные индексы полям, по которым предполагается поиск или фильтрация.
Структура с постом:
type HabrPost struct {
// Уникальный ID записи. Заводим для него индекс имя `id` и флаг 'pk' - Primary Key
// Это означает, что будет быстрый поиск по полю `id`, и то что Reindexer не разрешит вставить несколько записей с одинаковым id
ID int `reindex:"id,,pk" json:"id"`
// Время поста. В методах API, могут быть сортировки по этому полю, поэтому лучше использовать тип индекса `tree`
Time int64 `reindex:"time,tree,dense" json:"time"`
// Текст поста. Самостоятельных выборок с фильтрацией по полю text нет, поэтому тип индекса `-` - только хранение данных
Text string `reindex:"text,-" json:"text"`
// Заголовок поста. Самостоятельных выборок с фильтрацией по полю title нет, поэтому тип индекса `-` - только хранение данных
Title string `reindex:"title,-" json:"title"`
// Ник пользователя. Методы API предусматривают выборку по имени пользователя, поэтому тип индекса по умолчанию `HASH`
User string `reindex:"user" json:"user"`
// Массив хабов. Обычный HASH индекс, по полю массиву
Hubs []string `reindex:"hubs" json:"hubs"`
// Массив тэгов. Обычный HASH индекс, по полю массиву
Tags []string `reindex:"tags" json:"tags"`
// Количество лайков. Для поля не строится отдельный индекс. Запросов API с фильтрацией по этому полю нет.
// Сортировка по полю `likes` используется только в полнотекстовых запросах, а для сортировки результатов полнотекстового
// поиска по другому полю индекс не используется
Likes int `reindex:"likes,-,dense" json:"likes,omitempty"`
// Количество добавлений в закладки. Тип индекса выбран по аналогии с `likes`
Favorites int `reindex:"favorites,-,dense" json:"favorites,omitempty"`
// Количество просмотров. Тип индекса выбран по аналогии с `likes`
Views int `reindex:"views,-,dense" json:"views"`
// Флаг, если картинка. В запросах не участвует
HasImage bool `json:"has_image,omitempty"`
// Комментарии к статье - массив
Comments []*HabrComment `reindex:"comments,,joined" json:"comments,omitempty"`
// Определение полнотекстового индекса. Поиск по полям title, text, user
// Название полнотекстового индекса - `search`
// Флаг `dense` - уменьшает потребление памяти при построении индекса, но построение индекса будет медленнее
_ struct{} `reindex:"title+text+user=search,text,composite;dense"`
}
Структура с комментария заметно проще, поэтому не будем на ней останавливаться.
Реализация метода поиска
Хендлер
На уровне REST API обработчик — это обычный хэндлер fasthttp. Его основная задача — получить параметры запроса, вызвать метод поиска в репозитории и отдать ответ клиенту.
func SearchPosts(ctx *fasthttp.RequestCtx) {
// Получить параметры запроса
text := string(ctx.QueryArgs().Peek("query"))
limit, _ := ctx.QueryArgs().GetUint("limit")
offset, _ := ctx.QueryArgs().GetUint("offset")
sortBy := string(ctx.QueryArgs().Peek("sort_by"))
sortDesc, _ := ctx.QueryArgs().GetUint("sort_desc")
// Сходить в репозиторий
items, total, err := repo.SearchPosts(text, offset, limit, sortBy, sortDesc > 0)
// Сформировать ответ клиенту
resp := PostsResponce{
Items: convertPosts(items),
TotalCount: total,
}
respJSON(ctx, resp)
}
Основную задачу обращения к поиску выполняет метод репозитория SearchPosts — он формирует запрос (Query) в Reindexer, получает ответ и преобразует ответ из
[]interface{} в массив указателей на модели HabrPost.
func (r *Repo) SearchPosts(text string, offset, limit int, sortBy string, sortDesc bool) ([]*HabrPost, int, error) {
// Создаем новый запрос к Reindexer
query := repo.db.Query("posts").
// Обращаемся к полнотекстовому индексу `search`, предварительно превратив введенную строку в DSL
Match("search", textToReindexFullTextDSL(r.cfg.PostsFt.Fields, text)).
ReqTotal()
// Заказываем получение результатов в виде сниппетов:
// Эта запись означает, что в сниппет будет содержать 30 символов до и 30 символов после найденного слова
// найденное слово будет заключено в тэги <b> и </b> и каждая строчка с найденным словом будет начинаться
// на "...", а заканчиваться на "...<br/>"
query.Functions("text = snippet(<b>,</b>,30,30, ...,... <br/>)")
// Полнотекстовый поиск по умолчанию сортирует по релевантности и игнорирует направление сортировки
// наиболее релевантные записи - выше
// Если требуется сортировка по другому полю, то ее нужно заказать явно вызовом метода `query.Sort`
if len(sortBy) != 0 {
query.Sort(sortBy, sortDesc)
}
// Наложим пэйджинг
applyOffsetAndLimit(query, offset, limit)
// Исполнение запроса. Поиск и формирование результатов будет происходить во время вызова query.Exec ()
it := query.Exec()
// Обработаем ошибку, если она была
if err := it.Error(); err != nil {
return nil, 0, err
}
// По завершении выборки итератор нужно закрыть. Он держит внутренние ресурсы
defer it.Close ()
// Фетчим полученные результаты выборки
items := make([]*HabrPost, 0, it.Count())
for it.Next() {
item := it.Object()
items = append(items, item.(*HabrPost))
}
return items, it.TotalCount(), nil
}Формирование DSL и правил поиска
Обычно, поисковая строка сайта предполагает ввод запроса обычным человеческим языком, например, "Большие данные в науке" или "Rust vs C++", однако, поисковые движки требуют передачи запроса в формате специального DSL, в котором указывается дополнительные параметры поиска.
В DSL указывается по каким полям будет происходить поиск, подстраиваются релевантности — например, в DSL можно задать, что результаты, найденные по полю "заголовок"- более релевантные, чем результаты в поле "текст поста". Так же, в DSL настраиваются опции поиска, например, искать ли только точные вхождения слова или заодно, искать слово с опечатками.
Reindexer — не исключение, он так же предоставляет для Application DSL интерфейс. Документация по DSL доступна на github
За преобразование текста в DSL отвечает функция textToReindexFullTextDSL. Функция преобразовывает текст так:
| Введеный текст | DSL | Комментарии |
|---|---|---|
| Большие данные | @*^0.4,user^1.0,title^1.6 *большие*~ +*данные*~ |
Релевантность нахождения в поле tilte — 1.6, в поле user — 1.0 |
в остальных — 0.4. Искать слово большие во всех словоформах |
||
| как префикс или суффикс, а так же искать с опечатками и искать | ||
все словоформы, данные, как суффикс или префикс |
Получение и загрузка данных
Для удобства отладки, мы разделили процесс получения/парсинга данных с Хабра и загрузку их в реиндексер на два отдельных этапа:
Парсим Хабр
За загрузку и парсинг страничек Хабра отвечает функция DownloadPost — ее задача скачать с Хабра статью с указанным ID, распарсить полученную html страничку, а так же загрузить первую картинку из статьи и сделать из нее thumbinail.
Результат работы функции DownloadPost — заполненная структура HabrPost со всеми полями, включая комментарии к статье и массив []byte с картинкой.
Как устроен парсер, можно посмотреть на github
В режиме импорта данных приложение вызывает DownloadPost в цикле с ID от 1 до 360000 в несколько потоков, а результаты сохраняет в набор json и jpg файлов.
При скачивании в 5 потоков — весь Хабр скачивается примерно за ~8 часов. Из возможных 360000 статей — корректные статьи есть только по 170000 ID-шникам, по остальным ID
возвращается та или иная ошибка.
Суммарный объем распарсенных данных — около 5gb.
Загружаем данные в Reindexer
После завершения импорта Хабра у нас есть 170к json файлов. За загрузку сета файлов в Reindexer отвечает функция RestoreAllFromFiles
Эта функция преобразует каждый сохранённый JSON в структуру HabrPost и загружает ее таблички posts и comments. Обратите внимание, комментарии выделены в отдельную табличку, чтобы была возможность поиска по отдельным комментариям.
Можно бы поступить по другому и хранить все в одной таблице (это, кстати, уменьшило бы размер индекса в памяти), но тогда бы не было возможность поиска отдельных комментариев.
Эта операция не очень долгая — на загрузку всех данных в Reindexer уходит примерно 5-10 минут, в один поток.
Настройка полнотекстового индекса
У полнотекстового индекса есть целый набор настроек. Эти настройки вместе с настройками из DSL напрямую определяют качество поиска.
В настройки входит:
- список "стоп слов": это слова, которые часто употребляются в документах и не несут никакой смысловой нагрузки.
- опции построения индекса: поддержка транслита/опечатки/неверная раскладка клавиатуры
- коэффициенты формулы вычисления релевантности. В нее входят: функция bm25, дистанция между найденными словами, длина слова из запроса, признаки точного/не точного совпадения.
В нашем приложении за установку параметров поиска отвечает функция репозитория Init
Про фронтенд и баг Chrome с "бесконечным" скролом
Фронтенд реализован на vue.js — https://github.com/igtulm/reindex-search-ui
Когда делали "бесконечный" скрол с подгрузкой результатов столкнулись с очень неприятным багом Google Chrome — по мнению последнего, загрузка ответа от сервера при скроле иногда занимает 3-4 секунды.

Как так! У нас же быстрый бэкенд с реиндексером, отвечающий за миллисекунды -а тут, целых 4 секунды. Стали разбираться:
По логам сервера все хорошо — ответы отдаются за считанные миллисекунды.
2018/04/22 16:27:27 GET /api/search?limit=10&query=php&search_type=posts 200 8374 2.410571ms
2018/04/22 16:27:28 GET /api/search?limit=10&offset=10&query=php&search_type=posts 200 9799 2.903561ms
2018/04/22 16:27:34 GET /api/search?limit=10&offset=20&query=php&search_type=posts 200 21390 1.889076ms
2018/04/22 16:27:42 GET /api/search?limit=10&offset=30&query=php&search_type=posts 200 8964 3.640659ms
2018/04/22 16:27:44 GET /api/search?limit=10&offset=40&query=php&search_type=posts 200 9781 2.051581ms Логи сервера, конечно, не истина в последней инстанции. Поэтому, посмотрел на трафик tcpdump-ом. И tcpdump тоже подтвердил, что сервер отвечает за миллисекунды.
Попробовали в Safari и Firefox — в них такой проблемы нет. Следовательно, проблема явно не во времени ответа бэкенда, а где то еще.
Кажется, проблема все же в Chrome.
Несколько часов гугления принесли плоды — на stackoverflow есть статья с workaround
И добавление магического "workaround" из статьи отчасти исправило проблему в Chrome:
mousewheelHandler(event) {
if (event.deltaY === 1) {
event.preventDefault();
}
}Однако, все равно, если очень-очень активно скролить тачпадом, изредка, возникает задержка.
Что еще — небольшой бонус трек, вместо заключения
С момента публикации предыдущей статьи в Reindexer-е появилось много новых возможностей. Самая главная из них — полноценный серверный (standalone) режим работы.
golang API в серверном режиме, полностью совместимо с API в embeded режиме. Любые существующее приложения можно перевести с embeded на standalone заменой одной строчки.
Вот так приложение будет работать в embeded режиме, сохраняя данные на локальной файловой системе в папке /tmp/reindex/testdb
db := reindexer.NewReindex("builtin:///tmp/reindex/testdb")Вот так приложение будет работать с standalone сервером, по сети:
db := reindexer.NewReindex("cproto://127.0.0.1:6534/testdb")Standalone сервер можно либо установить с dockerhub, либо собрать из исходников
И еще, мы открыли телеграмм официальный канал поддержки Reindexer. Если есть вопросы или предложения — добро пожаловать!
Комментарии (43)

awesomer
23.04.2018 08:55Спасибо, интересно описано как реализовали решение прикладной задачи.
Но — по поводу Reindexer — не раскрыто. Почему он?
Не очень понятно, а в чем преимущество по сравнению с другими полнотекстовыми движками, коих просто большая куча — ведь алгоритм довольно примитивен, вот их и делают все,кому не лень, то есть кому это интересно.
Ну например Bleve — и быстрый и универсальный и написан здорово (хоть учись на его примере на Go писать). При этом чистый Go, если использовать backend-DBMS BoltDB. То есть никаких проблем с компиляцией ни на каких платформах.
Чистый С++, кроме ограничений на компиляцию — какой бонус даете?
Насчет ограничений на компиляцию поясняю: в полноценной установке Linux — проблем не будет, это да. Но в Windows это дополнительные танцы, в Docker это дополнительное время — на установку сишного компилятора и т.п.
Мы за это платим — а что нам это дает.
Тем не раскрыта.
olegator99
23.04.2018 09:42Преимущество — в сочетании функциональности и скорости работы. Бесспорно, есть ряд существующих решений, однако они либо работают медленно — например эластик, либо плохо реализуют "fuzzy" поиск с опечатками и словоформами, либо не имею своего хранилища.
Если говорить, про bleve — я полгода назад его пробовал. Опыты закончились тем, что он вставлял 10к записей по 1кб примерно 5 минут, а попытка вставить 100к записей закончилась OOM на машине с 16GB ОЗУ. Возможно сейчас что-то изменилось.
На мой взгляд, эта проблема как раз уходит корнями в заметный оверхед golang на GC — для БД вообще, и для поиска в частности, требуется развесистая структура данных, состоящая из множества мелких элементов. Это как раз одна из причин, почему выбран C++ тут уже отвечал подробно, почему C++
В конфигурации с reindexer сервером в docker-е, установка C++ компилятора не требуется, т.к. в docker образе все необходимое для работы уже собрано.
А для сборки golang приложения с сетевым коннектором к реиндексеру — C++ тулчейн не требуется.
awesomer
23.04.2018 11:22Да, индексирует Bleve не очень быстро. Зато функция поиска по уже проиндексированному — быстра.
А SphinxSearch (или его форк — Мантикора)?
Уж в чем-чем, а в отсутствии скорости их обвинить нельзя.
Как писал как-то на Хабре автор проекта Сфинкс, что скорость для них настолько важна, что если ошибка позволяет не падать, то они ее предпочитают игнорировать — все ради скорости.
Про опечатки — и Сфинкс и Bleve и Elastic — оставляют эти вещи на усмотрение конкретного пользователя инструмента.
Уж очень индивидуальна настройка на конкретных данных.
Дело инструмента — предоставить возможности для подстройки. А подстраивать его под конкретные данные — нужно на месте.
olegator99
23.04.2018 11:55Если говорить про sphinx — у 2.x нет своего стораджа, и от application требуется много телодвижений для хранения данных отдельном хранилище и поддержания синхронизации. Это большая проблема, например, ребята из ivi в итоге пожертвовали производительностью и перешли со sphinx на elastic.
А 3.0 по моему до сих пор closed-source, да и на момент когда мы начинали делать свой — его вообще не было.
А так, да мы конечно не изобрели какую то инопланетную технологию, однако если сравнивать с эластик и co, у нас скорость поиска в 10 раз выше, при ± сравнимом качестве.
awesomer
23.04.2018 12:25Это большая проблема, например, ребята из ivi в итоге пожертвовали производительностью и перешли со sphinx на elastic.
Как это «нет стораджа»?
Сфинкс вполне себе законченное решение. А не просто библиотека для реализации поиска как к примеру Lucene
Вы об этом их докладе?
habrahabr.ru/post/354034/#comment_10769824
Насколько я понял — дело в размерах данных и требованиях надежности/расширяемости у ivi.
Индекс Сфинкса просто перестал умещаться на 1 сервер и никаких решений по разбиению индекса Сфинкс не предлагает.
Поэтому ivi и перешла на Elastic. И прекрасно осознавала почему именно им приходится жертвовать производительностью.
А так, да мы конечно не изобрели какую то инопланетную технологию, однако если сравнивать с эластик и co, у нас скорость поиска в 10 раз выше, при ± сравнимом качестве.
Простите, в 10 раз?
За счет чего?
Что там такого можно придумать в примитивном алгоритме?
Ну разве что весь индекс в оперативку запихивать, но это вступает в противоречие с докладом ivi. А вы позицируете себя как решение, лучше Эластика, да?tulm
23.04.2018 15:24Можете пояснить фразу «примитивный алгоритм» (встретил несколько раз в ваших комментариях). Что в нем примитивного и какой алгоритм по вашему можно считать непримитивным?
awesomer
23.04.2018 16:01Можете пояснить фразу «примитивный алгоритм»
Полнотекстовый поиск — это очень просто:
1) Делим текст на слова. Выбрасываем слова, не несущие самостоятельного смысла (например «чтобы», «как», «но» и т.п.). Это же просто?
2) Прогоняем слова через алгоритм стемминга, например, такой snowball.tartarus.org/algorithms/russian/stemmer.html и получаем т.н. «термы». Как вы видите, алгоритм прост.
3) По каждой терме индекс типа такого roaringbitmap.org в котором отражаем вхождение терм в тексты. Ну тут немного похитрее, но тоже ничего гениального.
4) Записываем полученный индекс в банальную СУБД типа key-value
5) При поиске ранжируем с ипользованием ru.wikipedia.org/wiki/Okapi_BM25
И общедоступные полнотекстовые движки — просто вариации вышеприведенного алгоритма.
У кого-то по умолчанию игнорируются и выбрасываются на этап 1) одни слова, у кого-то другие.
У кого-то используется один алгоритм стемминга, а у кого-то другой.
Вот в той части алгоритма, что работает с bitmap-индексов и key-value (этап номер 3) — отличий больше. Скажем, у ElasticSearch индекс автоматически размазывается по кластеру.
Возможно и использование других функций ранжирования.
В развитых движках все эти вещи можно подстроить, предусмотрено множество возможностей для конфигурирования. Сравнивать столько гибко конфигурируемые системы по тому, что по умолчанию идет из коробки — некорректно.
Но суть от этого не меняется — весь поиск это:
а) Ищем в key-value
б) Затем просматриваем bitmap
И если качество поиска еще может отличаться (настроек-то уйма), но вот скорость… Для того, чтобы утверждать
у нас скорость поиска в 10 раз выше, при ± сравнимом качестве
нужно предложить миру совершенно иной алгоритм.
Если про Elastic я еще могу согласиться — поисковый индекс в кластере все же не всегда способствует ускорению одиночного поиска.
Но насчет того — с чего Reindexer в 10 раз быстрее Sphinx, который заточен именно на скорость?
С качеством поиска не все так просто:
youtu.be/wCGBTjHikwA
Потому и интересно — ведь если устранены недостатки полнотекстовых поисков — то в основе должен лежать алгоритм, который вполне потянет на докторскую диссертацию.olegator99
23.04.2018 17:34+1Описанное это очень базовый алгоритм, который был у нас в первой версии год назад, и действительно был написан чуть ли не за пару вечеров.
Но это не fuzzy поиск, а простой поиск по точным вхождениям + вхождения словоформ.
На шаге 3 битмапа не достаточно, требуется хранить не просто факт вхождения терм-ы в документ, а еще и список позиций вхождения (как минимум это требуется для bm25), и для вычисления релевантности по дистанции между словами.
на шаге 4 — k-v очень неэффективная структура для хранения индекса слов. Дело в том, что по ней дорого искать с опечатками/суффиксами/транслитами. Прийдется либо раздувать индекс до гигантских размеров на весь хабр получилось бы примерно ~ 100м записей с суффикасми/транслитами/опечатками/корнями, либо на каждом запросе сканировать огромные ренжи по k-v. И то и то очень затратно, и как следствие поиск будет работать очень медленно. И при построении индекса аллоцировать огромное количество мелких участков памяти.
У нас в этом месте используется suffix array.
Пункт 5 — это самый томный момент. По каждой term у нас есть N вариантов опечаток/словоформ (N может доходить до нескольких 10-ков)
*M слов из индекса, в которых встречается каждый вариант (M может доходить до 100-тысяч, при поиске суффиксов из 2-3 букв)*K документов, в которых эти слова встречаются*T — количество терм в запросе.
И вот это все надо пересечь и вычислить релевантность каждого сочетания.
С bm25 кстати, тоже не все так просто — оригинальная bm25 не учитывает, что у документа может быть несколько полей, по каждому из которых нужно вести отдельный учет статистики, и что финальные результаты формулы нужно нормализовать с учетом весов полей.
Ничего гениального в этом конечно нет. Но реализация требует далеко не один человеко-месяц, на разработку минимально алоцирующих/быстрых контейнеров, на тщательную оптимизацию и отладку работы формул — и тд. и тп.
Тут как говорится, весь дьявол — в деталях.
Кстати, про 10x от сфинса лично я никогда не утверждал, более того в предыдущей статье есть конкретные цифры:
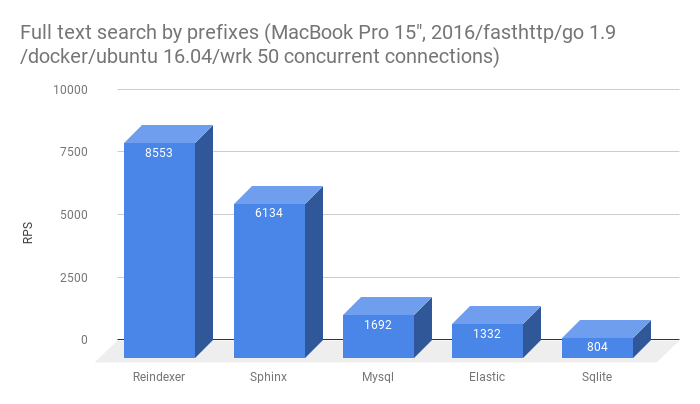
Как видите, Reindexer не принципиально быстрее Sphinx, но существенно быстрее всех остальных.
Если говорить про sphinx — у него проблема в отсутствии своего storage, т.е.
Т.е. sphinx 2.x не умеет хранить и отдавать документы целиком, а грубо говоря, может отдавать только ID документов. Поэтому, рядом со sphinx нужно держать какой нибуть K-V, и постоянно синхронизировать данные, что зачастую очень накладно.awesomer
23.04.2018 18:52А вот за описание как у вас устроено — отдельное спасибо.
но существенно быстрее всех остальных
Еще раз обращаю внимание: что если речь не идет о кластере — то никаких преимуществ ElasticSearch вы наблюдать не сможете. Эластик показывает чудеса именно в кластере.
Оно как-то там само внутри работает, индекс распределяет и перераспределяет — автоматически и хорошо.
Т.е. sphinx 2.x не умеет хранить и отдавать документы целиком, а грубо говоря, может отдавать только ID документов.
Sphinx умел хранить сами документы еще лет 5 назад, когда я им пользовался.olegator99
23.04.2018 21:00Репликация и кластеризация у нас в есть в ближайших планах. Правда пока с большим упором на репликацию, недели чем на кластеризацию.
Кластер хорош, когда объем данным заведомо больше, чем поместится в RAM одного сервера — например это актуально для поиска по террабайтам. В этой нише, действительно эластик хорош, а у reindexer в текущем виде для этой задачи не подойдет.
Однако, если говорить про задачу поиска по контенту сайта (или например, сервиса с VoD/TV контентом), то пока индекс целиком влезает в RAM одного сервера — это самая быстрая и эффективная конфигурация по критерию — количество обслуживаемых системой пользователей/количество используемых серверов.
Sphinx не хранит всю строчку с сущностью, а только те поля на которые накинуты полнотекстовые индексы. Это не равно всему документу....
donRumatta
24.04.2018 13:41Sphinx хранит атрибутами ровно те поля сущности, которые указаны в структуре индекса, и с полнотекстовыми полями они никак не связаны. Другой вопрос, что это очень накладно, особенно со строковыми атрибутами, держать в Sphinx-e то, что не используется в поиске. Но имея ID не проблема сходить в БД, запросы будут максимально эффективными.
olegator99 Автор
25.04.2018 10:39На практике, в нагруженных системах запросы, даже по ID не пропускают в БД сразу, а отдают из in-memory кэша, например как было у ivi. А это вызывает необходимость поддерживать консистентность данных сразу в трех местах: БД, кэш, Sphinx 2.x.
olegator99 Автор
25.04.2018 10:31Да, весь индекс впихнуть в память. Противоречия, на самом деле нет — есть разные пути решения задачи.
в соседнем комментарии написал детали
awesomer
23.04.2018 11:34Преимущество — в сочетании функциональности и скорости работы. Бесспорно, есть ряд существующих решений, однако они либо работают медленно — например эластик, либо плохо реализуют «fuzzy» поиск с опечатками и словоформами, либо не имею своего хранилища.
Все на так просто.
Андрей Аксенов «Выбираем поисковик умом головы»
Highload. Почему оно не находится! / Андрей Аксенов (Sphinx)
Потому мне и не вериться, что в столь примитивном алгоритме как полнотекстовый поиск вы сделали нечто волшебное, благодаря чему оно ищет прямо-таки лучше всех прямо из коробки.
У вас же нет там ИИ?
awesomer
23.04.2018 11:45однако они либо работают медленно — например эластик
Тут надо понимать — Эластик это кластерная система. Потому его не очень быстрая работа закономерна.
Почему ivi перешел со Sphinx на Elasticsearch / Евгений Россинский (ivi)
И если вам кластер не нужен — вряд ли стоит заморачиваться с Эластиком.
А вот если ваши данные не вмещаются на одну машину — Эластик разрулит в кластере на высшем уровне.
Если говорить, про bleve — я полгода назад его пробовал. Опыты закончились тем, что он вставлял 10к записей по 1кб примерно 5 минут, а попытка вставить 100к записей закончилась OOM на машине с 16GB ОЗУ. Возможно сейчас что-то изменилось.
То есть преимущества Reindexer — в быстром обновлении поискового индекса большими массивами данных?
olegator99
23.04.2018 11:57По моим тестам в bleve не влезет и 10% habrhabra — закончится RAM.
Поэтому преимущество Reindexer на этой задаче такое — он работает, а bleve нет.awesomer
23.04.2018 12:59По моим тестам в bleve не влезет и 10% habrhabra — закончится RAM.
Сколько было RAM?
Какой backend использовали для Bleve?
А как вы себя позицируете?
То вы лучше кластерного ElasticSearch, то вы лучше заточенного на скорость Sphinx, то вы лучше embedded-библиотеки Bleve?
Можно этот момент поподробнее?olegator99
23.04.2018 15:46С bleve последний раз пробовал что то делать ~полгода назад. на основании примера из этой статьи https://habrahabr.ru/post/333714/ и оригинальной документации.
По воспоминаниям, пробовал разные бэкенды. Но сама суть такова: на объеме данных 100к x 1к через 10-20 минут индексации получал OOM на машине с 16GB.
По позиционировании очень просто — Reindexer очень быстрая in-memory DB общего назначения с богатыми возможностями поиска и фильтрации.
Сравнительные характеристики по скорости работы были в предыдущей статье — их можно посмотреть и сделать выводы. (bleve туда не попал, потому что не смог переварить тестовый датасет)
Оценить качество и скорость поиска можно в демке из этой статьи.
awesomer
23.04.2018 16:15Поэтому преимущество Reindexer на этой задаче такое — он работает, а bleve нет.
Оставим Bleve, все же это embedded-решение.
То есть преимущества Reindexer — в быстром обновлении поискового индекса большими массивами данных?
однако если сравнивать с эластик и co, у нас скорость поиска в 10 раз выше, при ± сравнимом качестве.
Если вы сравнивали скорость с Elastic — то какой был кластер?
Без кластера смысла в этом сравнении нет, так как именно отличное управление индексом в кластере и есть самый главный плюс Elastic, из чего и следуют другие его особенности — возможность работы с огромными массивами данных, устойчивость к выходу из строя отдельных серверов кластера.
На одиночной машине Elastic и не будет самым быстрым. Не для этого он создавался.
И еще один вопрос:
А как вы получили в 10 раз большую производительность, чем у Sphinx? Имхо, это невозможно, если не подходить в данным искусственно.


AMorgun
23.04.2018 15:24Вы так сконцентрировались на опечатках, что нет способа искать по точному слову.
Написал "scala" functional получил scalar, escalation
Скорость впечатляет.
olegator99
23.04.2018 15:27Перестарались :)
За замечание — спасибо, попробуем подтюнить — ведь это параметр настройки. Коэффициенты релевантности вхождения по опечаткам/словоформам/транслиту можно аккуратно крутить в обе стороны.
olegator99
23.04.2018 23:21Внимательно посмотрел на результаты запроса "scala" functional. На первых 3-ех страницах ответы только про Scala, дальше начинают попадаться результаты со scalar и прочими опечатками.
На мой вкус — это ожидаемое поведение поиска: в начале выдачи разместить точные совпадения, а потом шлейф разультатов с разнообразными словоформами.
Я вот еще обратил внимание по логам сервера, что был запрос по слову scala с сортировкой по времени поста. Могу предположить, что речь идет именно про этот запрос. При сортировке по времени релевантность не учитывается, и на первых местах могут быть слабо-релевантные ответы.
Есть несколько способов избежать этого эффекта. Можно, например, увеличить порог релевантности, тем самым убрав слабо-релевантные ответы.
Можно явно задать поиск по точному совпадению, вообще исключив из выдачи все опечатки/суффиксы — это делается просто, на уровне преобразования поискового запроса в DSL

babylon
23.04.2018 17:50От логических ошибок избавиться сложнее. Когда кажется, что работает как задумано. Тут нужны тестеры со стороны.
technik
23.04.2018 19:21Скорость работы сайта и впрямь фантастическая для такого массива.
Скажите, а вы не думаете создать какой-то отдельный продукт или подробную инструкцию для индексирования сайтов, чтобы можно было скачать весь массив данных со стороннего сайта, а потом развернуть его у себя на хостинге или в локалке и искать по нему?awesomer
23.04.2018 20:15Скорость работы — самая что ни на есть рядовая для любой зрелой системы полнотекстового поиска.
Другое дело, что в большинстве случаев используется банальный MySQL и даже полнотекстовый поиск там программисты не всегда умеют задействовать.
olegator99
23.04.2018 22:15Спасибо за отзвыв!
Индексирование произвольного сайта в интернете, с произвольной структурой страниц — это задача поискового робота — в этом случае, робот не вникает в сущности которые есть на сайте, а оперирует набором страниц и текстов — нормализуя любой контент в вид удобный для индексации, это весьма сложная задача, которую решают Яндекс и Гугл. А делать аналог Яндекс-а или Гугла — не входит в наши планы :)
Другой подход — скраппинг сайта — когда предварительно анализируются модели данных использующиеся сайтом, и индексация сайта сводится к типизированному парсингу страниц сайта. В результате мы получаем набор структурированных данных, близкий к внутреннему формату БД сайта.
В данном случае мы пошли этим путем. Он дает лучшие результаты — т.к. исходные данные структурированы. Однако этот подход не универсальный и требует немного реверс инженеринга и реализации парсера/логики обхода страниц для каждого конкретного сайта.
babylon
24.04.2018 01:25это весьма сложная задача, которую решают Яндекс и Гугл.
В этом как раз многие не уверены. Есть запросы с нулевой выдачей:)
awesomer
24.04.2018 08:56В этом как раз многие не уверены. Есть запросы с нулевой выдачей:)
В любом случае Гугль и Яндекс используют совсем другого уровня алгоритмы, с нейронными сетями и пр.
Здесь же все просто — «запрос — учитываем искаженные словоформы — ответ»olegator99 Автор
24.04.2018 11:55Простите, не удержался,
Но на вашем уровне оценки сложности алгоритмов, у яндекса и гугла тоже все просто:
"запрос — учитываем искаженные словоформы — пропускаем через нейронку — мап-редьюус ответ"
awesomer
24.04.2018 14:18Я вот тоже не удержался наивным восторгам комменаторов по поводу скорости вашего поиска.
- Тем более, что речь идет об одном пользователе, делающим запрос.
- Тем более, что речь идет об оценке на глазок. Бьюсь об заклад, что на глазок отличить даже самый медленный (по вашем тестам) Elastic от вашего Reidexer — невозможно
Это ни в коем случае не умиляет вашу работу, вы проделали большую работу, но…
Имхо, простой полнотекстовый поиск (без нейронных сетей и без нечеткого fuzzy-поиска) вполне себе можно давать как курсовую для студента 2-го курса по специальности «программирование».
Понятно, что до вашего уровня, до возможности использования на серьезных задачах — этот студент не дотянет.
Но весь алгоритм, упомянутый тут ( habrahabr.ru/post/354034/#comment_10770532 ), реализовать студент вполне себе должен смочь.
И студенческая работа так же будет летать. Ибо тормозить там просто нечему.
Другое дело, что ваш проект должен также хорошо повести себя и на серьезных нагрузках плюс реализует работу со словоформами, нечеткий поиск и пр., чего нельзя ожидать от студенческой курсовой.
Еще раз замечу, что цель моих замечаний было не умолить вашу работу.
Вы познакомили людей с новым миром — с миром полнотекстового поиска ( а там много чего Reindexer, ElasticSearch, SphinxSearch, ManticoreSearch, Bleve, MySQL, PostgreSQL — и это только то, что пришло сходу в голову ). Где все летает на таких задачах и на таких данных.
Меня удивляет, почему программисты до сих пор не были ни с чем подобным знакомы — инструментов-то много для этого (см. выше список). И воспринимают рядовой факт как откровение — «о, мгновенно! вау!»tulm
24.04.2018 17:07реализовать студент вполне себе должен смочь.
Студент из Хельсинки сделал Linux, к примеру. И гугл, кстати, тоже делали студенты, как и многие другие значимые для it-сообщества проекты и сервисы. Вы явно недооцениваете студентов!
То есть, по вашему, наличие нейронной сети в полнотексте сразу сделает алгоритм сложным? Если бы в Reindexer'е было реализовано нечто подобное, то вы бы все равно поравли статью на цитаты ровно так же (ничего личного, просто посмотрел вашу история комментариев). Ну согласитесь же :)
Слежу за Reindexer с момента появления первой статьи. Исчерпывающая документация, привлекательные бенчмарки, понятный исходный код и экзамплы. Все это делает для меня этот продукт интересным для его дальнейшего использования. К слову, если вы с чем то не согласны, а вы эксперт в этой области (по крайней мере, вижу, что разбираетесь), то можете провести сравнительный анализ полнотекстовых поисковиков, предоставить какие-либо доказательства, и помочь не только всем нам, наивным комментаторам, лучше разобраться в этой теме, но возможно и поможете Reindexer'у дальше в развитии. А пока — у вас много писанины, но полезной информации для себя я не смог подчерпнуть, к сожалению.awesomer
24.04.2018 17:51но полезной информации для себя я не смог подчерпнуть, к сожалению.
лучше сами думайте. своей головой.
отправную точку в виде ссылок я уже дал.
Все это делает для меня этот продукт интересным для его дальнейшего использования.
У меня где-то написано, что Reindexer плохой?
Написано, что заявленный коэффициент превосходства по производительности в 10 раз — это… скажем мягко, напоминает маркетинговый ход.
Reindexer сравнивается с ElasticSearch на одиночном сервера. Но ElasticSearch высокоэффективен именно что в кластере, а не на одиночном сервере.
И люди, которые восхищаются — люди, посмотрите альтернативы. Там тоже все визуально выглядит как «мгновенно». Это не значит, что Reindexer плохой.
Этой технологии в доступных всем и каждому продуктах (некоммерческих) — уже больше 15-ти лет. 15 лет уже все летает и вы можете это использовать совершенно бесплатно.
awesomer
24.04.2018 18:16То есть, по вашему, наличие нейронной сети в полнотексте сразу сделает алгоритм сложным?
Не сложным, а потенциально более умным.
Относительно уже готового продукта, каким является Reidexer — сложность уже не важна. Мы просто используем готовый продукт.
Если бы в Reindexer'е было реализовано нечто подобное, то вы бы все равно поравли статью на цитаты ровно так же
Не-а.
Если бы там были бы зачатки ИИ, то мои комментарии были бы более заинтересованные.
Но Reindexer — это всего лишь определенным образом оттюнингованная вариация алгоритма описанного habr.com/post/354034/#comment_10770532
Еще раз: я нисколько не умоляю проделанную авторами Reindexer большую работу.
Все мои критические комментарии сводятся к всего двум моментам:
1) Авторы Reindexer пишут насколько далеко они сумели обогнать популярный ныне ElasticSearch.
Но при этом есть важный момент — Elastic просто замечательно распределяет поисковый индекс по кластеру из множества серверов. Чего Reindexer не умеет. На одиночной машине Эластик не отличается выдающимися характеристиками. Использование на Эластика одиночной машине — не целесообразно и по особенностям реализации (JVM все же много отъедает). Но именно сравнение на одиночной машине и проводят авторы Reindexer.
2) Восхищенные отзывы людей, которые, видимо, больше никаких других систем полнотекстового поиска и не знают.
Хотя одна из первых полноценных библиотек для реализации полнотекстового поиска была опубликована в OpenSource еще 1999 году; а первые полноценные некоммерческие реализации появились в 2003 году — может и раньше.
Исчерпывающая документация, привлекательные бенчмарки, понятный исходный код и экзамплы
На сегодня (и уже много лет как) существует несколько быстрых продуктов для полнотекстового поиска, и с хорошей документацией, я некоторые из них уже упоминал в комментариях, не буду повторять.
Я еще раз подчеркиваю — это ни в коей мере не должно восприниматься, что Reindexer плохая система.
babylon
24.04.2018 17:26Господин хороший вы понимаете как работают нейронные сети? Если вы думаете что они сами себя сингулярно настраивают, то я человечеству не завидую.
awesomer
24.04.2018 17:40кажись промазал
комментарий адресуется tulm:
Вы явно недооцениваете студентов!
У меня русским языком уже написано выше, но давайте я еще раз пожую специально для вас:
любому студенту второго курса по специальности «программист» и т.п., который действительно хочет стать программистом задача по реализации полнотекстового поиска типа Reindexer (но с рядом упрощений, все же Reindexer это серьезный проект) — вполне по плечу.
То есть, по вашему, наличие нейронной сети в полнотексте сразу сделает алгоритм сложным?
это совсем другой объем работы.
если студент и сделает рабочий поиск с такой сетью — то это уже дипломный проект, а никак не курсовая.
как тут правильно заметил babylon, даже если вы и добавите в алгоритм нейросетку (готовых решений полно) — сама по себе она не будет «думать». научить нейросетку адекватно принимать решения, хотя бы про опечатки — если студент действительно это сделает, то его с распростертыми объятиями возьмут, несмотря на то, что джунов уже перебор и начинающим трудно найти работу.
но такого студента, действительно научившего нейросетку искать с опечатками, и что важно, правильно понимать что подразумевал человек — возьмут работать с превеликим удовольствием.tulm
24.04.2018 18:19Хорошо. Тогда я тоже перефразирую немного, раз не поняли. Ваше сравнение с тем, что сможет написать студент, а что не сможет — дело бессмысленное и ненужное. Второе, сказанное про нейросеть. Будь здесь алгоритм сложнее, использующий нейронные сети, то мы бы точно так же читали подобные скептические сообщения от вас. На этом остановимся.
awesomer
25.04.2018 08:18Будь здесь алгоритм сложнее, использующий нейронные сети, то мы бы точно так же читали подобные скептические сообщения от вас.
Реализаций полнотекстового поиска полным-полно — то есть с чем сравнить. Чего нельзя сказать о нейросетках, заточенных для такого же поиска. Мои комментарии являются скептическими как раз по причине знакомства с альтернативами.
Автор в комментах отписался о 10 кратном превосходстве по сравнению с одним из самых известных продуктов этого типа ElasticSearch… но видите ли — Эластик силен не скоростью как таковой, а своей потрясающей работой в кластере, чего не умеет Reindexer. На одиночном сервере имеет смысл сравнивать с SphinxSearch. И тут коэффициент даже у авторов получился куда как меньше.
Во вторых — сравнение на нагрузке от одиночного клиента это явно не то, как нужно сравнивать продукты такого класса.
Нейросетки для поиска же на сегодня — это скорее исследовательский проект. И если бы был опубликован подобный Reindexer рабочий продукт на нейросетке — это был бы взрыв в технологиях.olegator99 Автор
25.04.2018 09:31Со Sphinx Reindexer сравнивать влоб не совсем корректно. Reindexer это полноценная БД, позволяющая работать с данными, например вставлять/удалять/делать сложные выборки с JOIN, а Sphinx это движок полнотекстового поиска.
Полнотекстовый поиск это одна из фич Reindexer, а не основное предназначение.
На берегу, когда мы проектировали систему, а задачи у нас ± такие же как у ivi, только данных побольше (есть TV контент и поддержка IPTV приставок со своей горой специфики усложняющей логику), мы не планировали тащить в Reindexer полнотекстовый поиск, а думали как и ivi использовать тот же sphinx сбоку.
Однако анализ показал, что это решение будет крайне накладным. Основные причины, такие же как у ivi:
- необходимость синхронизации данных между кэшем с контентом и поисковым движком (Redis у ivi, Reindexer у нас)
- У sphinx не хватает возможностей фильтрации контента. В ivi, как я понял эту проблему решали просто развернув табличку доступности контента геолокациям/устройствам, тем самым помножив количество контента на количество сочетаний доступности. Мы эту проблему в Reindexer-е решили на уровне движка БД — каждая единица контента содержится в индексе в единственном экземпляре. Грубо говоря — задача имеет три решения
- "залить железом" -> кластер эластик
- "развернуть сущности для сложной фильтрации линейно, и упереться в объем RAM и время построения индекса" -> sphinx + redis
- "выполнять требования бизнеслогики на уровне БД, убрав квадратичные и кубические зависимости потребляемой памяти от количества правил фильтрации" -> сделать и использовать Reindexer
На задаче, когда количество контента небольшое (а фильмы+сериалы+TV каналы+TV программа + все их метаданные — это всего лишь несколько сотен тысяч-несколько миллионов строчек БД) — размазывание индексов по кластеру — лишний оверхед. Весь контент со всеми индексами гарантированно влезут в RAM одного сервера с огромным запасом.
Тут нет никакого бонуса от кластеризации и распределения индексов по нодам.
В итоге конфигурация ~10 серверов Reindexer даст такую же производительность, как кластер эластик со ~100 серверами.
PS. Да, сейчас у нас репликация данных между Reindexer нодами реализована на уровне приложения, и это увы на практике работает не очень хорошо. Поэтому мы и планируем перенести репликацию данных в сам Reindexer.
babylon
Обожаю Reindexer