
Три года назад здесь уже обсуждали платье, которое разделило интернет. На днях обнаружилась похожая, ещё более интересная и сложнее объяснимая иллюзия. Какое имя вы слышите на этой аудиозаписи: «Йенни» или «Лорел»?
Как выяснилось, результаты не только различаются от человека к человеку, но даже для одного человека могут зависеть от используемого аудиооборудования. Всю неделю лингвисты спорят о причинах иллюзии, пристально разглядывая спектрограмму этого двухсекундного фрагмента. Вот она:
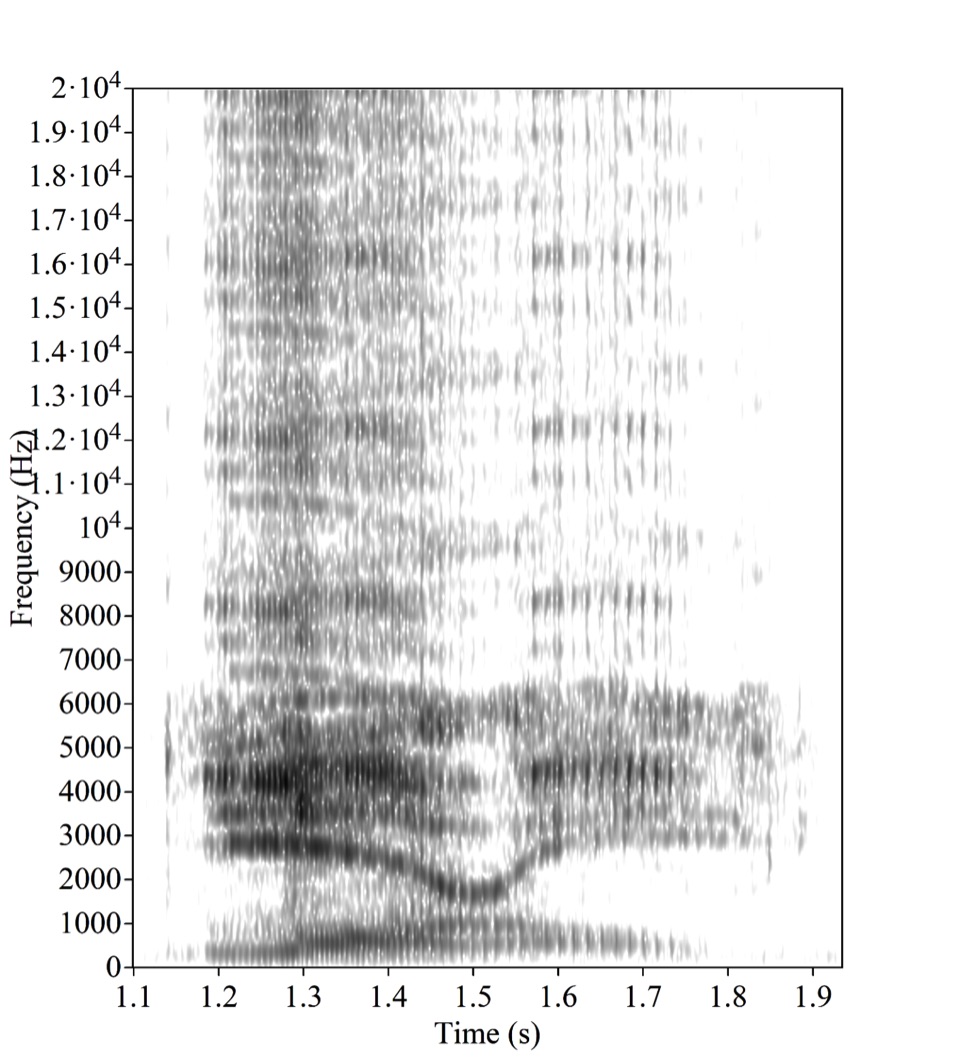
Для тех, кто видит спектрограмму звука впервые: по горизонтальной оси отложено время, по вертикальной — частоты, яркость точки соответствует амплитуде, с которой вибрирует «воображаемый камертон» соответствующей частоты в соответствующий момент времени. На спектрограмме речи всегда видны "форманты" — тёмные горизонтальные линии, извилистые и прерывистые; каждая форманта соответствует одной из резонансных частот речевого аппарата, а их вертикальные колебания — соответственно, изменениям этих резонансных частот в процессе речи.
Как объясняет Сюзи Стайлс, на участке низких частот до 5 КГц в человеческой речи присутствуют три форманты, которых обычно достаточно для разпознавания произносимых звуков. Эти три форманты соответствуют вертикальному (F1) и горизонтальному (F2) положению языка, и положению губ (F3). Сюзи даёт ссылку на ролик Общества Макса Планка, где диктор, находящийся в МРТ-камере, произносит по очереди все гласные и все согласные, так что за положением его органов речи при произношении каждого звука можно следить непосредственно.
И вот с выделением формант, по словам Сюзи, возникают проблемы: тёмные участки на спектрограмме yanni/laurel образуют рисунок из более чем трёх полос, которые разветвляются и пересекаются:

В частности, нижняя полоса (F1) может распознаться либо «горбом вверх», либо «горбом вниз»:
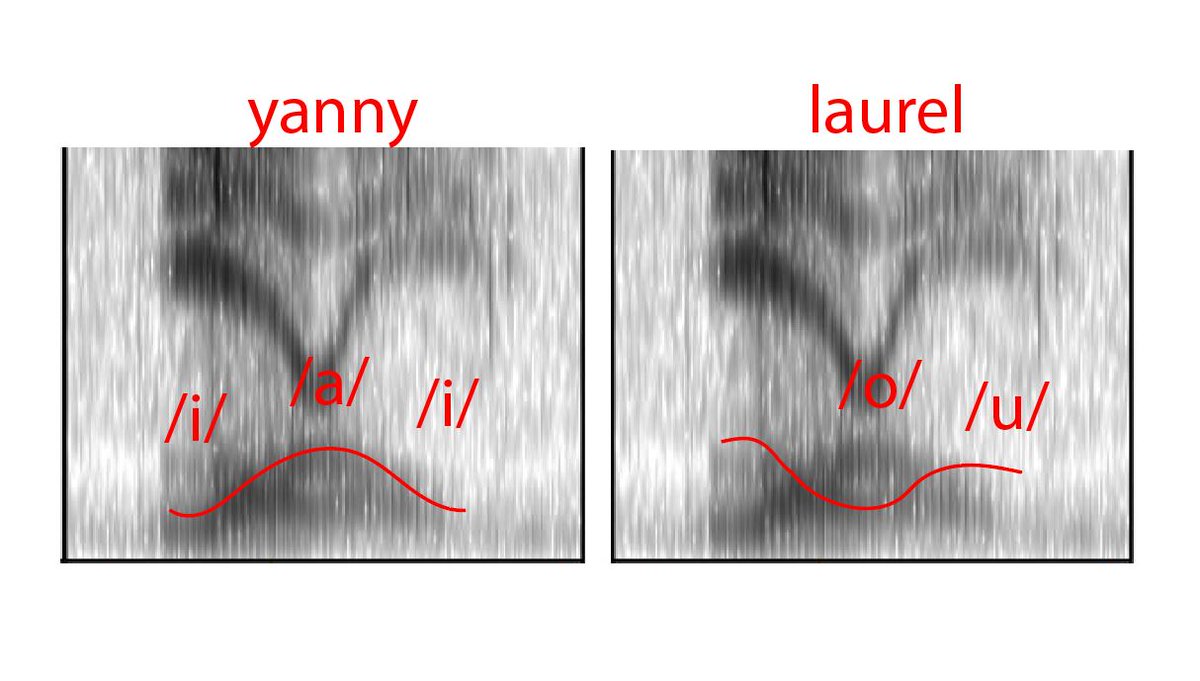
Первая линия соответствует последовательности гласных «высокий — низкий — высокий», т.е. [j?-?-]; вторая — «низкий — высокий — средний», т.е. [a-o-?-]. (На рисунке Сюзи очевидная ошибка: [u] — высокий гласный, и не может быть в конце второй последовательности.) По F2 видно, что последовательность гласных должна быть «передний — средний — передний», т.е. опять же [j?-?-]. Но если аудиосистема слушателя подавляет частоты между 2 и 3 КГц, то слушатель «домысливает» F2 на основании F1, и получает последовательность гласных «задний-средний», т.е. [-o-?-]:

Сюзи подводит итог своего анализа: вместо трёх ясных формант мы видим путаницу из тёмных пятен, которую можно расшифровать одним из двух способов:
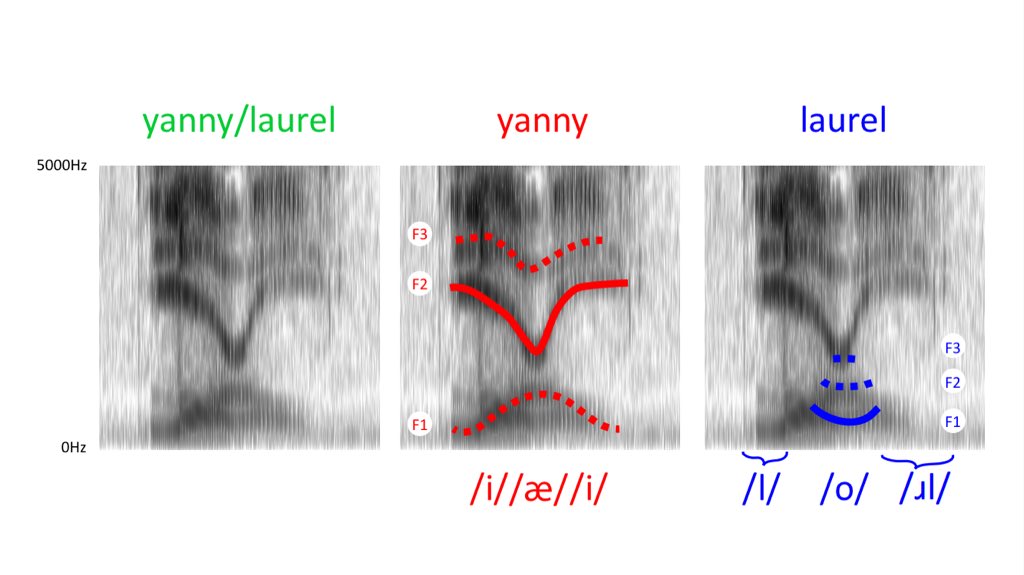
Немного другой анализ приводит Кэролин МакГеттиган. Когда стало известно, что «двусмысленный звук» не сконструирован коварными лингвистами для издевательства над нормальными людьми, а взят с сайта онлайн-словаря, пропущен через не очень качественные колонки, и записан не очень качественным микрофоном, — то Кэролин сравнила спектрограммы исходного звука с сайта, и получившегося «звука-иллюзии»:

В первом звуке F1 и F2 видны чётко, но очень близки; во втором, кроме добавления слабого шума, F1 и F2 слились в одну форманту, а исходная F3 стала восприниматься как F2. Кэролин отмечает, что «горб вниз» в F3 — это отличительная черта английского звука [?]; а в получившемся звуке он вместо этого стал восприниматься как «горб вниз» в F2, т.е. как последовательность гласных «передний — средний — передний» — пресловутая [j?-?-].
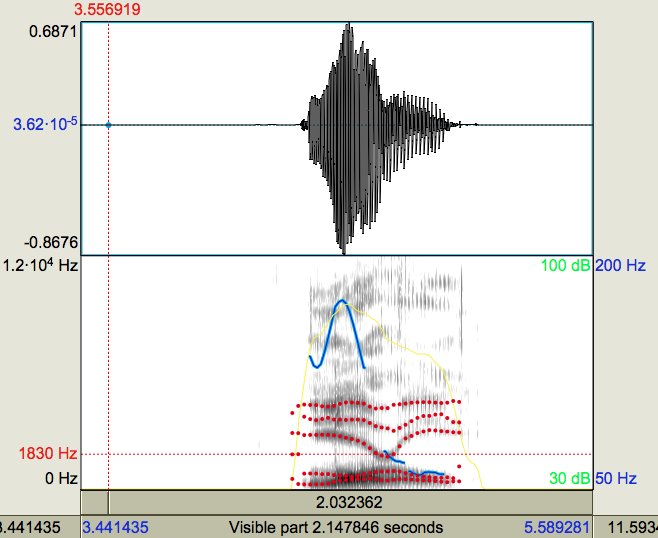
Кроме этих двух объяснений иллюзии, лингвисты предложили ещё несколько. Бенджамин Муссон обратил внимание, что на высоких частотах (5-9, 9-13, 13-17 КГц) содержатся более слабые повторы F1-F3:

В человеческой речи таких «повторяющихся формант» не бывает, так что Бенджамин обвиняет в иллюзии именно их. (Вероятнее всего, это артефакт аудиосжатия, использованного для «двусмысленного звука».)
NY Times — обсуждение иллюзии дошло даже дотуда! — тоже обвиняет в иллюзии усиление высоких частот, произошедшее при перезаписи:

Более того, в своей заметке они реализовали «интерактивную иллюзию» — частотный фильтр, настройку которого можно плавно менять ползунком, чтобы любой мог убедиться: если усиливать низкие частоты и подавлять высокие — то звук превращается в Laurel, если наоборот — то в Yanny.
Пользуясь поводом, упомяну здесь ещё и мою собственную акустико-фонетическую интерактивную штуку, написанную на коленке под вдохновением давнишнего квеста от Meklon'а. (Я ни разу не фронтендер, и охотно приму PR с более дружественным UI.) Эта интерактивная штука позволяет рисовать по спектрограмме и прямо в реальном времени слушать, какой получается звук; в частности, можно взять существующий звук и попытаться обвести его форманты, или дорисовать новые, или выборочно стереть какой-нибудь диапазон частот.
Как выяснилось, результаты не только различаются от человека к человеку, но даже для одного человека могут зависеть от используемого аудиооборудования. Всю неделю лингвисты спорят о причинах иллюзии, пристально разглядывая спектрограмму этого двухсекундного фрагмента. Вот она:
Для тех, кто видит спектрограмму звука впервые: по горизонтальной оси отложено время, по вертикальной — частоты, яркость точки соответствует амплитуде, с которой вибрирует «воображаемый камертон» соответствующей частоты в соответствующий момент времени. На спектрограмме речи всегда видны "форманты" — тёмные горизонтальные линии, извилистые и прерывистые; каждая форманта соответствует одной из резонансных частот речевого аппарата, а их вертикальные колебания — соответственно, изменениям этих резонансных частот в процессе речи.
Как объясняет Сюзи Стайлс, на участке низких частот до 5 КГц в человеческой речи присутствуют три форманты, которых обычно достаточно для разпознавания произносимых звуков. Эти три форманты соответствуют вертикальному (F1) и горизонтальному (F2) положению языка, и положению губ (F3). Сюзи даёт ссылку на ролик Общества Макса Планка, где диктор, находящийся в МРТ-камере, произносит по очереди все гласные и все согласные, так что за положением его органов речи при произношении каждого звука можно следить непосредственно.
И вот с выделением формант, по словам Сюзи, возникают проблемы: тёмные участки на спектрограмме yanni/laurel образуют рисунок из более чем трёх полос, которые разветвляются и пересекаются:
В частности, нижняя полоса (F1) может распознаться либо «горбом вверх», либо «горбом вниз»:
Первая линия соответствует последовательности гласных «высокий — низкий — высокий», т.е. [j?-?-]; вторая — «низкий — высокий — средний», т.е. [a-o-?-]. (На рисунке Сюзи очевидная ошибка: [u] — высокий гласный, и не может быть в конце второй последовательности.) По F2 видно, что последовательность гласных должна быть «передний — средний — передний», т.е. опять же [j?-?-]. Но если аудиосистема слушателя подавляет частоты между 2 и 3 КГц, то слушатель «домысливает» F2 на основании F1, и получает последовательность гласных «задний-средний», т.е. [-o-?-]:
Сюзи подводит итог своего анализа: вместо трёх ясных формант мы видим путаницу из тёмных пятен, которую можно расшифровать одним из двух способов:
Немного другой анализ приводит Кэролин МакГеттиган. Когда стало известно, что «двусмысленный звук» не сконструирован коварными лингвистами для издевательства над нормальными людьми, а взят с сайта онлайн-словаря, пропущен через не очень качественные колонки, и записан не очень качественным микрофоном, — то Кэролин сравнила спектрограммы исходного звука с сайта, и получившегося «звука-иллюзии»:
В первом звуке F1 и F2 видны чётко, но очень близки; во втором, кроме добавления слабого шума, F1 и F2 слились в одну форманту, а исходная F3 стала восприниматься как F2. Кэролин отмечает, что «горб вниз» в F3 — это отличительная черта английского звука [?]; а в получившемся звуке он вместо этого стал восприниматься как «горб вниз» в F2, т.е. как последовательность гласных «передний — средний — передний» — пресловутая [j?-?-].
Кроме этих двух объяснений иллюзии, лингвисты предложили ещё несколько. Бенджамин Муссон обратил внимание, что на высоких частотах (5-9, 9-13, 13-17 КГц) содержатся более слабые повторы F1-F3:
В человеческой речи таких «повторяющихся формант» не бывает, так что Бенджамин обвиняет в иллюзии именно их. (Вероятнее всего, это артефакт аудиосжатия, использованного для «двусмысленного звука».)
NY Times — обсуждение иллюзии дошло даже дотуда! — тоже обвиняет в иллюзии усиление высоких частот, произошедшее при перезаписи:
Более того, в своей заметке они реализовали «интерактивную иллюзию» — частотный фильтр, настройку которого можно плавно менять ползунком, чтобы любой мог убедиться: если усиливать низкие частоты и подавлять высокие — то звук превращается в Laurel, если наоборот — то в Yanny.
Пользуясь поводом, упомяну здесь ещё и мою собственную акустико-фонетическую интерактивную штуку, написанную на коленке под вдохновением давнишнего квеста от Meklon'а. (Я ни разу не фронтендер, и охотно приму PR с более дружественным UI.) Эта интерактивная штука позволяет рисовать по спектрограмме и прямо в реальном времени слушать, какой получается звук; в частности, можно взять существующий звук и попытаться обвести его форманты, или дорисовать новые, или выборочно стереть какой-нибудь диапазон частот.
dioneo
Можно слышать, то что ожидаешь услышать. У кого не получается — просто несколько раз произнесите противоположный вариант одновременно с аудио.
RusTech
прослушал раз 50, и проговаривая и меняя устройства, но всегда «лорел»
SONce
Сделал аналогично. Даже усердно пытался найти Лорел, но всегда получается Яни.
Пробовал и на дешевых наушниках и на настоящих маршалах и на всем в доме что может производить звук.
dioneo
Пробуйте интонацию повторять только звуком l-l или только звуком i-i.
zzzmmtt
При прослушивании в наушниках или с телефона всегда слышу Яни, если слушать одним ухом — иногда слышу Лорел. Супруге дал послушать, она ещё не слышала и на значал чего ждать, она услышала Яни.
earl911
Существует поверье, что в древности, с помощью этого звука, искали себе вторую половинку. Если слышимый звук совпадал, считалось что и в браке супруги будут друг-друга понимать :D
BelerafonL
В статье же есть ссылка на интерактивный эквалайзер от NY Times, у кого что-то не получается услышать, там всё получится.
rstepanov
Есть положения эквалайзера, в которых по желанию можно слышать оба варианта одновременно.
lolmaus
Охренеть!
Найдя пограничное положение ползунка, я добился того, что одним ухом слышу Йенни, а другим Лорэл. Достаточно повернуть голову.
Кроме того, я могу "менять" звучание в зависимости от того, на какую надпись смотрю глазами!
pavlick
мои уши говорят, что хоть какие-то признаки Yanny появляются только в трех правых квадратиках. В остальной области ползунка услышать что-то отличное от Laurel вообще не получается
TRIMER
Забавно. У меня с точностью наоборот. В двух левых одновременно Лорел/Ени, а во всех остальных только Ени.
SilverHorse
Похоже, это сильно зависит от того, к каким частотам по умолчанию восприимчивы ваши уши и мозг больше всего. Я в оригинале и в центральном положении ползунка на NYT слышу только «Yerei/Yenei» или «Ierei/Ienei» (слушание сотен часов японского что ли сказывается), с сильным первым йотом и ударением на вторую гласную. Если сместить на третью-вторую справа позицию — четко слышится «Yanny» по всем правилам произношения, в крайнюю правую — вообще «йены, йены» роботизированным басом. Долго ломал голову, где тут «Laurel», пока не сместил ползунок до упора влево и не слушал это полминуты, насильно заставляя себя игнорировать йот в начале (примерно так же, как можно сосредоточиться на тикающих часах и либо слышать только их, либо не слышать их вообще, «переучив» краткосрочную слуховую память) — и я стал слышать «Laurel» таким глубоким баритоном. Причем иллюзия сохранилась, даже когда я смещал ползунок снова до упора вправо — при этом «Laurel» переходило в что-то вроде «Qworrow».
Но: когда я выключил это и полминуты посидел в полной тишине — я снова вернулся к «Yenei». И это похоже на особенность корректировки, которую мой мозг делает на мой собственный голос — я слышу свой собственный голос при разговоре достаточно высоким, хотя в реальности у меня довольно низкий баритон, что при прослушивании собственного голоса в записи надрывает шаблон. Так что это может быть подсказкой, как можно себя «переучивать» между двумя вариантами.
vbif
Обычно бывает наоборот: себе свой голос кажется более низким.
EugeneButrik
«Мандриан»«йэлли» )sasha1024
«Яни» и не должно получиться, должно получиться /й/+[?]+/ни/, что как по мне ни разу не /йани/, а жёсткое /йэ?ны/ (хотя вот тут оспаривают, говорят, что воспринимать [?] как /а/ — тоже своего рода норма, но от меня это достаточно далёкая).
EugeneButrik
Гласные не суть. Я в упор не слышу звук «н».
alivespirit
Еще очень интересный момент — когда ползунок по центру — слышу Laurel, когда резко перемещаю вправо — Yanny, но если ползунок перемещать медленно от центра вправо — тогда до конца слышу Laurel.
Bonio
Что ты наделал! Я до этого слышал Yanny, как ни пытался там расслышать что-то другое, а после того, как покрутил ползунок стал слышать Laurel, совершенно другой звук! Даже интонация другая. А Yanny теперь не слышу вообще. Удивительно.
VEG
После нескольких минут в этом эквалайзере я одновременно слышу оба варианта в обычной записи, будто одновременно два разных человека говорит. Изначально было только «Яни». Любопытненько.
AlexxFFC
Слышу только Лорел. Так же, и на китайских вкладышах слушал, и дома на комплекте Ямахи. Забавная хрень :) Но, поскольку изначально было именно «Лорел», то что может сказать то, что большинство (по голосованию) слышит «Яни»?
tyomitch Автор
Скорее всего, этот вопрос сейчас станет темой не одной докторской :)
sasha1024
Есть пруф, что изначально было записано именно «Лорел»? Или Вы имели в виду — Вам изначально слышалось? (Так Вам же и сейчас слышится то же?)А, всё, вопрос снят, вижу: «взят с сайта онлайн-словаря [для laurel]».(1) Небольшой фикс: не «Яни», а «Eны»/«Ени», я так понимаю «Яни»/«Янни» там появилось от переводчиков, которые сами слышали «Лорел» и поэтому транскрибировали английское «Yanny» чисто наугад. (2) Я думаю, выборка нерепрезентативна, мне кажется, большинство как раз слышат «Лорел» (судя по другим пабликам; сам я сначала слышал «Eны», а потом «Лорел»); восприятие «Eны» часто ассоциируют с детьми / молодым возрастом, если это правда, то это говорит о возрастной категории контингента хабра (школьники/студенты/молодые).
tyomitch Автор
Англоязычные эксперты утверждают, что там [j?n?]; русскоязычному уху это должно казаться чем-то промежуточным между «Ены» и «Яни».
sasha1024
Честно говоря, я не понимаю, как [?] для русскоязычного уха может превратиться в /а/, по-моему, это чисто /э/ (при чём не просто /э/, а крайняя форма /э/) — ну да ладно, спорить не буду.
tyomitch Автор
sasha1024
Произносить пять, взять, часть как пэть, взэть, чэсть? Ну, не знаю, я не спорю, что такое может быть (наверное, в каких-то регионах, может, даже в центральных) — но для меня лично это как-то дико. И уж английское [?] ниразу для меня не /а/, хотя бы на этом видео.
tyomitch Автор
Я согласен, что «в среднем по больнице» [?] воспринимается как /э/ — и именно поэтому в первой строчке поста я написал «Йенни», а не «Янни».
Я пытаюсь вам объяснить, что «Янни» — это не ляп переводчиков, а часть людей (в том числе, комментаторы в этом топике) действительно так слышат.
sasha1024
Да, спасибо, я уже понял.
Bhudh
Вы забываете о мягкости (по научному: палатализации) предшествующих согласных.
Вы произно?сите /п??т?/, /вз??т?/, /ч??ст?/, а не /п?т?/, /вз?т?/, /ч?ст?/. Просто Вы не воспринимаете этот звук как /?/, так как в школе Вам сказали, что это /а/.
Chamie
Только не говорите, что «пьэть» для вас будет звучать так же, как «пять».
Bhudh
Разумеется, не скажу, ведь «пьэть» (петь) это [p?et?], а пять это [p??t?].
sergku1213
Очень чётко слышно «Лорел». Яни совсем не похоже.
tapk
Очень чётко слышно «Йенни». «Лорел» пробивается, но как бы на заднем фоне.
Hellsy22
Я слышу только «Йенни». Никакого «Лорел» мне даже отдаленно не слышно.
e_fail
У меня вообще смешно — читая статью, в сэмпле на Soundcloud отчётливо слышал «Йени». Дочитал до конца, зашёл по ссылке на NY Times, в дефолтном среднем положении ползунка — тоже отчётливое «Йени». Подвигал ползунок туда-сюда, послушал оба варианта, вернул ползунок в середину — теперь слышу в этом положении «Лорел», а зона «Йени» начинается ощутимо правее. Видимо, какой-то глюк на сайте, подумал я. Зашёл ещё раз на Soundcloud — теперь тот же сэмпл отчётливо слышится как «Лорел».
«The New York Times has completely warped my fragile little mind»
ttools
У вас слишком качественные устройства ) Возьмите китайские наушники за 50 руб. Они надежно отрезают бас
dioneo
Это «йа а йа» или «ля а ля»?
EugeneButrik
Это
tvr
А говорящая собака чау-чау,
Произнесла довольно внятно: «Вау-вау».
IgorGIV
Вот Вам 2 интересных факта:
1. Запустите воспроизведение этого звукового файла, например, в Media Player Classic и нажмите ctrl+down (это замедлит воспроизведение вдвое, а также снизит частоту звука) и Вы чётко услышите «йеи»;
2. Запустите воспроизведение файла через колонки и попробуйте распознать слово смартфоном и получите, например, moral (что по сути ближе всего к loral, чем к yanny).
Leeloush_Keer
Я услышал в первый раз "пьяный"
dragefabeldyr
я тоже слышу «пьяный»
clawham
а есть ссылка на оригинальный ролик ато весь ютуб полон переработанными файлами и то отчетливо слышно лорель то янни. причем у всех кому показал
trimtomato
Все началось с реддита.
clawham
прошелся по офису (4 мужика и 5 женщин — только паре первый звук напомнил енни ито только когда я переспросил точно ли не енни. там просто явно в первом повторе или глюк ару или эхо какоето но второй повтор четкий и ясный лорел
Fllash
Даже близко никакого «лорел» не улавливаю. Кто-то его правда слышит, из здесь присутствующих?
VaalKIA
Я до первого слова, слышу глухое я которое тут же продолжается чётким Лорел, у второго повтора уже никаких артефактов нет.
VaalKIA
Попробовал другие наушники капельки, подёргал громкость и т.п. Никакого Яни даже близко нет, всё что есть, это очень глухое "я" похожее на всхлип (когбуд-то кошка мяукнула), начинающееся до чёткого и громкого слова Лорел перед обоими повторами.
Chamie
Там не «яни», там «ены».
andersong
Ваше «как будто» бесподобно)
Fllash
Upd: не сочтите психом, но сейчас, выпив бокал пива и выкурив сигарету… я слышу этот «лорел» Оо
*убежал за шапочкой из фольги, на всякий*
VaalKIA
Ну вот, первый, обращённый в нашу веру, уже есть! Вытравим, калёным железом сатанинский морок Яни, который не способен замарать истинно верующих!
HaZeR
Первые разы было йени, минут через 5 лорел. Почему хз. После перерыва опять йени.
Ради поржать проверил версию с сигаретой. Реально меняет на лорел :)
VaalKIA
Просто давно известно, что дым изгонят дьявольских духов, покайся пока не поздно!
P.S. В принципе, совершенно чётко установлено, что даже обычная еда и прочие вещества, попадающие в кровь, влияют на цветовосприятие и слух. Как обычно, наиболее легче слух притупить, чем обострить, при этом страдают высокие частоты, как самые сложные и ресурсоёмкие для распознования.
VaalKIA
Я думаю, что стаканчик спиртного, поможет легко услышать Лорал, для тех кто слышит Йени. А вот, тем у кого уже ухо высокие плохо воспринимает, мало что поможет, хотя я, сейчас, съел шоколадку и смог услышать уже две буквы вместо одной и гораздо громче: ЙееЛорал, типа того.
sincosxy
Это очень любопытно, стакан пива поменял Йены на Лорел.
За вчерашний день восприятие этой аудиозаписи поменялось раз 15, утром йены, в обед лорел, к вечеру можно было различить оба варианта при небольшом мысленном усилии: ждешь лорел — получаешь лорел и наоборот.
После стакана пива кроме лорел ничего больше не слышно.
Сегодня с утра йени, после завтрака лорел.
Arson
Вобщем мнение моё такое, взяли 2 звука и хитро свели. Вот скрин диапазана в котором слышно только Лорел и ничего более.
yadi.sk/i/g_H8f-je3W65ub
Соответсвенно если этот диапазон отрезать то слышно только Йенни, а в исходном файле всё смешано и каждый слышит то- что подчеркнула аудиосистема. Просто Лорел в более низком регистре, а Йенни в более высоком.
Arson
И ещё, изначально более чётко слышал Йении, но кусочек Лорел проскальзывал, когда вырезал нужную частоту и несколько раз прослушал только Лорел, то и в исходном файле начал более чётко выделять сразу оба слова.
tyomitch Автор
Не было «двух хитро сведённых звуков». Это студийная запись профессионального чтеца, перезаписанная с дешёвых колонок; оригинал доступен на www.vocabulary.com/dictionary/laurel
Arson
Скажите пожалуйста какие колонки и как надо перезаписывать чтобы получить два ограничения в спектре? Вот картинка на которой чётко видно что один спектр ровно срезан по 6.4 кГц, а остальная часть идёт гораздо выше. Такое обычно получается когда несколько файлов склеиваешь у которых изначально разная частота сэмплирования.
tyomitch Автор
Где именно вы взяли анализируемый файл? У меня спектр получился иным.
Arson
Скачал с вашего саундклауда.
Arson
Вот ещё две картинки и звуковой файл в котором слышно спектры с этих скринов.
1, 2, звук.
SkyPhantasm
Чётко слышал Енни, недоумевал откуда там может взятся лорал. Послушал пару раз вашу ссылку. ВСЁ. Больше никаких Енни
Arson
Простите, я не специально :)
SkyPhantasm
Наоборот это интересно, теперь вот мучаюсь вопросом как снова слышать Янни.
EugeneButrik
Зачем? Вашу нейронную сеть перенастроили на нормальную работу. Что за тяга к глюкам? :)
SkyPhantasm
Это не тяга к глюкам, а попытка воспроизвести баг. После суток, с прослушиванием на разных устройствах теперь стабильно Лорел. Из 4-х людей которым показал это все 4 слышали Енни. Только один после прослушивания «студийного лорел» начал слышал лорел в записи. Пока что моё предположение: «перенастраиваются» люди что часто слышат английскую речь.
grokinn
Вот после прослушивания оригинала я слышу на этой запись лорел, а до прослушивания оригинала был йенни.
pyJIoH
Фак мой мозг, после оригинала я начал слышать Лорел, дошел до того, что смог регулировать, что я хочу услышать. За один раз могу и йени и лорел услышать по очереди. Ураааа
kozyabka
«что подчеркнула аудиосистема» мы вот с женой на одной АС слышим разные слова)
Arson
Ну индивидуальные особенности слуха тоже нельзя отбрасывать, вероятно жена ваша услышала Йенни, а вы Лорел?
kozyabka
Да. Но я был уставший после написания музыки громко. Сегодня могу расслышать Йенни но при желании, по дефолту таки Лорел
Nikita_64
В первый раз услышал Йенни, потом многократно — Лорел, причем пытался снова услышать Йенни — бесполезно, попробую завтра снова.
Politura
Вот-здесь наглядное объяснение, когда можно самому услышать один и другой вариант:
www.youtube.com/watch?v=c3GNT8Ac050
tyomitch Автор
Это «объяснение» не касается двух самых интересных вопросов:
1) почему разные люди слышат разные слова;
2) почему манипуляции с частотами меняют слышимое слово.
Politura
1. Из ролика все можно прочувствовать на себе: если я изначально слышал лорел, то понизив высоту звука я уже слышу что-то более близкое к ямми.
Следовательно, у людей, что изначально слышат ямми, либо колонки на ноутах искажают звук так, что понижается его высота, либо эти, скажем, искажения относительно других людей происходят в ушах-мозгу.
2. Меняется высота звука — срабатывает другой паттерн распознавания.
tyomitch Автор
Sadler
Этот пример находится на границе двух паттернов, и любая случайность может вывести его из равновесия, даже ожидание услышать определённый вариант. Паттерны у разных людей схожи, т.к. наиболее эффективны для данного языка, но у некоторых людей граница паттернов более смещена от усреднённой, и они слышат только одно слово или чаще слышат одно слово. Теоретически возможно создать такую запись для любой пары слов, если иметь вывод классификатора.
tyomitch Автор
Не было бы удивительно, если бы пример, находящийся на границе двух паттернов, распознавался как «что-что? можно ещё раз?» — как в ролике с Мутко.
Здесь же половина слышат чёткое Laurel, половина — чёткое Yanny.
Spaceoddity
симультанный контраст в звуковом диапазоне
Wesha
vlreshet
А что должно видеться на второй картинке, вместо женщины в шляпе с пером?
tyomitch Автор
Старуха в косынке с острым подбородком.
vlreshet
Как её увидеть?) С коллегой уже все глаза сломали
UPD. а, всё, получилось. Странная, конечно, старуха с перьем)
RomanoBruno
skssxf
Кстати, кто-нибудь, кроме меня видит на этой картинке большое лицо, которое смотрит из левого верхнего угла в правый нижний?
polsok
Скажи это Иисусу
Spaceoddity
Ну там же очевидное наложение двух, предварительно отфильтрованных, звуковых сигналов. Да ещё к тому же убитое многократными кодеками.
А дальше уже срабатывает паттерн в голове — когда начинаешь повторять подряд одно и то же слово/фразу — мозгу трудно определить первый слог и быстро перестроиться. Поэтому распознаванием даже можно управлять «силой воли».
Ну вообще очередная срежессированная «мистификация».
Вот, поигрался я с параметрическим эквалайзером — нашёл более-менее граничную частоту (но я даже наушники не одевал). Попробуйте усилием воли переключать распознавание с «йенни» на «лорел».
soundcloud.com/user-823965336/yanny-laurel-by-tyomitch2
Druu
Человек с разной громкостью воспринимает разные частоты, с-но если у вас в записи есть две форманты на примерно одинаковом уровне, то при исходной частоте вы, например, громче слышите первую форманту. При повышении общей частоты записи первая форманта выпадает из "наиболее слышной" части спектра, вторая — наоборот попадает и вы начинаете слышать ее. Учитывая, что "ачх" системы уши-мозг у каждого человека разная (и вообще говоря даже у одного человека она разная, может легко поменяться за минуту, если например вы послушали фоном что-то относительно громкое на определенных частотах), то и получается, что этот порог, когда форманты меняются местами, у каждого свой.
HappyLynx
В ваших рассуждениях есть изъян.
Мы слушаем с женой с одного телефона с внешнего динамика с одного расстояния и под одним углом. Она слышит Яни, я слышу Лорел. Затем проходит 2 часа, слушаем — она слышит Лорел, я слышу Яни.
AlexanderS
Так он там частотой поигрался! Может это намёк на то, что у всех разные наушники? Я перебрал три своих — всё равно лорел слышу ))
Чуть ниже есть ссылка на ролик, в котором Мутко якобы выругался. Вот это реально непонятно — я слышу то, что ожидаю! Ожидаешь мат — будет мат, ожидаешь «с этим» — реально слышышь «с этим». Как так?
Politura
Наушники обычно передают звук более чисто, чем дешевые громкоговорители.
Можно попробовать послушать на ноуте с плохими встроенными колонками, или каком-нибудь дешевом телефоне.
Еще вариант: на колонках, или в системе может быть встроенный эквалайзер, который включен в определенный режим, что делает эти искажения.
AlexanderS
Насколько я понял на одном и том же звуковом тракте разные люди слышат разное. Я думаю тут даже больше дело не в частотной игре, а в том что у разных людей получается по разному мозг что ли работает?)
Chamie
Тут и то, и другое.
Barabas79
Есть похожая иллюзия (матерное описание ролика, хотя мата нету)
www.youtube.com/watch?v=4SwHAhcL5IA
tommyangelo27
Тоже сразу про Мутко подумал.
sena
Да на каждом шагу coub.com/view/xw2k0 ;)
numitus2
Интересно когда смотрю ролик и вижу подпись, то слышу с матом. А если переслушиваю с закрытыми глазами, то слышу нормально.
Wizard_of_light
Я слышу что-то вроде «йерейл».
wiwrel
Аналогично, только я слышу «Йе-рэй»
Zavtramen
И я, что-то типа «ёррей»
prazdnik
«Йе-ный, йе-ный» четко. Пытался услышать другое, не получилось.
u007
Это «Генри»
madfly
Вот-вот. Надо третий пункт в голосовалку.
jrthwk
Услышал краем уха по телевизору — удивился чего это там «левой-левой-левой» говорят…
ksantd
я с женой поругался по этому поводу))) тоже «левой» слышу )
Farrad
Отчетливо слышно «Генри», произнесенное картавым человеком.
dioneo
Ну можно ещё тогда добавить, что китайцы слышат. Мы слышим только те звуки, которые сами умеем произносить. Звуки другого языка кажутся нам исковерканными звуками нашего языка.
Barafu_Albino_Cheetah
Ага. Японцы устраивают концерты ботов, которые верещат неопределенную чушь, а все слышат в них слова на своём языке, и даже не верят, что это программно сгенерированный рандом.
edtun
Хм, а я четко воспринимаю как японский, хотя сам русскоязычный всегда был, а японский у меня только в аниме с субтитрами. Откуда подобная информация про то, что слышат «слова на своём языке»?
Barafu_Albino_Cheetah
До того, как опубликовали рассказ о том, что это просто набор звуков, на европейском форуме игры народ пытался разобрать слова, спорили, английский это, немецкий или русский. Любой анимешник сразу узнает характерные интонации анимешной песни, так что с ним всё ясно. Надо попробовать поискать европейскую музыку с таким «вокалом», уж небось кто-нибудь да сделал.
Да и просто комментарии на Ютубе встречаются, типа «помогите, половину понял, половину нет».
prostosergik
Есть уже =)
Barafu_Albino_Cheetah
Эта песня спета человеком, у неё есть конкретные слова
prostosergik
Не знал. Странно, я там все время слышал билеберду на смеси языков.
Barafu_Albino_Cheetah
Там очень много лексики из игры, поэтому на слух не понятно. Так же, как и во всех попытках подобрать слова под Calamari Inkantation очень много сленга игроков, поэтому со стороны они бессмысленные.
Incidence
як цуп-цоп же )
vlreshet
А откуда информация что это рандом? Просто в описании видео ничего такого нет, а слова реально крайне похожи на японский.
p.s. если что — я не троль, мне правда интересно)
Barafu_Albino_Cheetah
Официальная вики игры. Этого вам хватит? :)
sincosxy
Еще где-то читал, что настройки микрофонных усилителей в радиостанциях разных стран отличаются, затачиваются под конкретный тембр голоса.
Например, высокие частоты в китайской речи несут больше смысловой нагрузки, чем, например, в русской речи, поэтому при соответствующих настройках звучание раций из разных стран отличается.
Samouvazhektra
Дочка тоже типа такого слышит. А я чисто лорел. Наушники один и те же. Так что не только в аппаратуре дело
ThisIsSparta
А вы говорите аудиофиоы…
Если даже в таком простом тесте, безо всяких 40кГц люди делятся на два лагеря, то как вы можете говорить, что аудиофиоы «чего то там на самом деле» не слышат(я не говорю про прогретые провода и подставки под них;))
markmariner
Потому, что здесь есть доказательства присутствия и тех и других звуков в записи. Никаких же физических подтверждений «прогрева проводов» не существует.
tyomitch Автор
Доказательств присутствия «Yanny» в записи нет. Есть доказательства того, что половина людей слышат «Yanny» в этой записи.
(Точно так же, как сфотографированное платье было одного конкретного цвета, но половина людей видели на фотографии другой цвет.)
Druu
Как это нет? А в обсуждаемой статье что? :)
tyomitch Автор
В ней — попытки объяснить то, почему половина людей слышат «Yanny» в этой записи, хотя «Yanny» в ней нет :-)
markmariner
Вероятно никто не говорил Енни на самом деле. Но те деформации, которые были сделаны с файлом, добавили в него искажения, которые могут слышаться, как Енни, что и подтверждают манипуляции NYT с частотами.
Einherjar
Слышу только Yanny, попробовал в эквалайзере чуток придушить все что выше 3,5 кгц — тогда слышно Laurel. Полагаю Laurel слышат те у кого туго с воспиятием высоких и/или низкосортное или бытовое оборудование заточенное под бубнеж басами вместо линейного воспроизведения.
Nuwen
Ну вот. Недавно я узнал на этом сайте, что еле слышный свист тишины, воспринимаемый мною с детства, называется тиннитус и является расстройством. А теперь же я узнаю, что мой слух подобен низкосортному бытовому оборудованию.
xgarfieldx
у меня с детства тиннитус, но я хоть убей слышу «Йенни». Даже на сайте NY Times если двинуть ползунок на максимум на «Лорел», я все равно слышу «Йенни» и «Лорел» одновременно)
Pativen
Я когда узнал, что этот свист оказывается тиннитус, не мог жить месяц нормально и спать, все время обращал внимание на звон, до этого воспринималось как естественное. Сейчас уже смог взять себя в руки.
SlimShaggy
Точно ли расстройством? Мне всегда казалось, что этот эффект есть у всех и вызван попыткой слуха адаптироваться к тишине, выкручивая чувствительность до максимума, в результате чего вылезают всякие собственные шумы и огрехи слуховой «подсистемы» — точно так же, как в полной темноте мы видим не абсолютную черноту, а «шум матрицы». Иначе откуда взялось выражение «звенящая тишина»?
TheOleg
Вот многие пишут, что зависит от оборудования и устройства. А я везде(колонки/наушники/телефон) слышал Лорел и только один раз из плохих динаминов монитора!!! услышал Йенни.
untilx
Изначально слышал yanny, сколько ни крутил эквалайзер в обе стороны. После перерыва в самом правом положении услышал lorel, сместил чуть левее — yanny, вернул обратно — yanny. Сейчас вообще слышу оба варианта одновременно, но на 3/4 вправо от lorel остаётся только бульканье в районе буквы r.
SelenIT3
Судя по NYTовскому эквалайзеру, да, «Yanny» создается именно за счет ВЧ-части спектра. Но ирония в том, что, судя по их же расследованию, эта самая ВЧ-часть — ничто иное, как гармоники из-за перезаписи на низкосортном бытовом оборудовании. Так что оптимальная ситуация для «Yanny» — комбинация хреновой электроники (вносящей тучу гармоник) с хорошей акустикой (добросовестно передающей их все:).
Sadler
Gl_Proxy
Да это все легко проверить, сначала слушал через динамики телефона, всегда было Лорел, подключил хорошие наушники и сразу стало отчетлива Йенни.
Попробуйте и сразу услышите разницу, если вы через колонки слушали, в наушниках высокие частоты лучше воспринимаются.
mwizard
Я слышу что-то типа «Юрий», и никак не могу услышать ни один из двух «правильных» вариантов.
QDeathNick
А что такое Экалиг вы случайно не знаете?
VaalKIA
Икарус?
QDeathNick
Да, люди не знающие английского алфавита так его читают. Часто не привыкшие к английской речи, ищут в английских словах русские.
tyomitch Автор
«Кинь бабе лом»?
QDeathNick
Как-то в 90-х заехал в глухую тамбовскую Сосновку, а там в ларьке кассета продавалась "Ace от Васи".
hdfan2
Незабвенное «Водки найду»
Chosen_One
Слышу Lorel, а как только взял аудиофильский кабель — сразу ламповое Yanny )
spax555
Смешно же, зачем минусить.
Chosen_One
Спасибо, видимо владельцы кабелей. Сначала на ПК слышал Йенни, потом на планшете Лорел, после этого на ПК тоже Лорел. Дитё в этот же момент слышит Йенни. Сегодня утром на планшете впервые услышал Йенни, побежал показать жене — начал слышать Лорел, а она Йенни.
CrazyLazy
Хмм ...
Минут 20 спустя (после того как перезапустил компьютер (надо было)) — теперь только Laurel… но уже везде. o_O
CyberAndrew
Вам не кажется, что просто время от времени меняют файл?
CrazyLazy
Вполне возможно… вот только я уже больше не слышу Yanny… вообще.
Пробовал в разных браузерах (Firefox, Chrome, Vivaldi, Edge). IP адрес у меня правда статический поэтому поменять этот параметр не получиться. Пробовал с мобильного (мобильный интернет) — слышу только Laurel…
Chosen_One
Не, одновременно слушаю с женой и ребенком — и слышим разные имена.
useluch
На встроенных в ноут колонках слышу lourel, а когда подключаю внешние bose companion 3 series 2, то yanny.
bonsai
На колонках Logitech Z906 5.1 (сабвуфер помогает по низким частотам, да) явно Yenny
В наушниках (дешёвые Creative) — явно Laurel
Жена на колонках услышала Morrew\Morrel
Хорошая звуковая иллюзия ;)
MetromDouble
Сначала слышал Яни. Думал, что люди, слышащие Лорел — идиоты или тролли. Потом послушал игры людей с частотами на ютубе, ничего не изменилось. Вернулся сюда, послушал и, о, чудо, тоже стал слышать Лорел. Понял, что идиот — это я) И только минут через 10 научился переключать сознанием воспринимаемый звук.
P.S. Платье для меня — жёлтое, как бы я ни напрягался :)
mindcaster
А я не могу переключиться. Раньше слышал Йенни, но поигравшись с инструментом от NY Times теперь слышу Лорель повсюду. Очень странное впечатление, что сломал себе мозг случайно.
trimtomato
Это самые адекватные объяснения которые я читал.
Если я не ошибаюсь, источник звука не человек (в словаре же синтезатор). Этого достаточно для объяснения странных формант, поэтому не нужно прибавлять аудиосжатие в объяснение.
Revetements_Etales
www.wired.com/story/yanny-and-laurel-true-history
trimtomato
Значит все-таки ошибался. Это важный момент. Спасибо.
Druu
Внезапно лолд. Зачем нужен опера сингер для записи слов в словаре? Уж с чем хорошая дикция имеет минимум общего — так это с академ. вокалом.
Ztare
Где-то читал, что для озвучки разных языков оперные певцы хорошо подходят — они знают и умеют идеально произносить транскрипции.
Revetements_Etales
Собственно, там об этом тоже написано
Oll123
Сегодня видел хорошую гипотезу о том, что с возрастом уровень восприятия звукового диапазона снижается (что вроде как медицинский факт) и следовательно люди 35+ будут слышать лорелл почти всегда.
Предполагаю? что благодаря нарушениям кровоснобжения (например курение, сужающие сосуды) можно получить Лорелл, в то время как расширение (плюс опять же молодость) — наоборот, приведет к Яни.
Лично я слышу всегда Лорелл, но я и не могу сказать что отлично слышу\молод, так что все сходится )
mactep3230
Похоже на правду. Несмотря на 35+, слышу частоты примерно до 19кГц. Отчетливо услышал yanni.
Welran
40 лет слышу йенни, друг 39 то же. Только на nytimes при сдвиге на 1 деление начинаю слышать лорел
vvadzim
42, йеней.
После тренировки на НЙТ в основном лорел, но могу слышать и лорел и йеней и оба вместе.
Corewood
22, Lorel. Пора менять образ жизни…
mactep3230
Что за… После обеда послушал через наушники. Услышал лорал. Ну, понятно, думаю… Слушаю через динамик, все равно Лорал. Только глухой не расслышит ) Пожалуй надо скачать, а то параноя начинается. Кто подменил файлы? )
Druu
Там же нцать раз пережатый звук. Все высокие частоты, которые гипотетически могли бы быть слышны, обрезаны нафиг.
tyomitch Автор
Утверждается, что разница не в высоких частотах на границе слышимости, а в чувствительности к диапазону 5-10 КГц по сравнению с более низкими частотами.
Rohan66
Слышу янни (50+), сыну 21 — слышит лорел. На работе ребятам под 30 — янни.
Barafu_Albino_Cheetah
А я не понял прикола. Я отчётливо слышу оба слова по-очереди…
gohan
Я слышу только Laurel, на любых устройствах. Платье видел всегда чёрно-синим. И что теперь? Меня будут убеждать, что я больной? Но ведь платье на самом деле чёрно-синее было и произносят тут на самом деле Laurel.
А вот на записи с Мутко я как-то в самом начале слышал «б**дь» (давно), но потом стал слышать «с этим» и слышу только так, в том же самом ролике.
gohan
UPD — после длительной паузы услышал всё-таки yanni, на тех же наушниках с того же лаптопа. Но слышу так только первые 1-2 раза, потом переходит на Laurel надёжно.
Barafu_Albino_Cheetah
Платье на самом деле синее, а на фото — серое. Это как медведя нарисовать зелёным фломастером, и спросить «какого цвета медведь?». На самом деле бурый, а на рисунке — зелёный. Если рисунок хороший, невнимательный зритель может и не заметить, что рисунок зелёный. Потому что медведь бурый.
Так что парадокс вызван тем, что вопрос недостаточно точный для однозначного ответа.
gohan
Ну на самом деле я вижу платье как голубое и грязно-тёмно-коричневожёлтое. Но белый цвет в синем/голубом не могу углядеть никак.
Вот ещё очень рекомендую для любителей звуковых иллюзий, довольно чёткий русский текст из музыки Skyrim («погоди, погоди на часы посмотри» и всё такое):
www.youtube.com/watch?v=lyLZNY7HsSY
Fedcomp
Прочитал все коментарии и не могу понять одного, я один могу одновременно слышать и тот и другой?
sincosxy
Тоже слышу оба, но не всегда. Восприятие скачет туда-сюда, то лорел, то йены, то сразу оба получается различать.
Habetdin
Я слышу Laurel, но если вслушиваюсь — слышу сиплым шёпотом/шумом Yanni поверх Laurel.
А так — каждый улавливает, в силу возможностей акустики и своих ушей, что-то одно, а вот распознаёт под влиянием различных факторов (языковые особенности, когнитивные искажения, etc) порой что-то совсем иное.
vvadzim
Неа, не один. Но я после тренировки)
Chamie
Со второй попытки услышать «lorel» на NYT'овском эквалайзере (уже после прослушивания оригинала на Vocabulary.com) стал различать оба везде кроме крайних позиций эквалайзера. Просто они по таймингу ключевых позиций полностью совпадают, и их трудно разделить. Ени звучит выше, лорел — низким голосом диктора.
vasimv
Опять по кукам выдают одним один вариант, а другим — другой (и несколько промежуточных, чтобы остальным не скучно было)?
Fedcomp
У меня в наушниках Laurel, а если с ноутбучных колонок — оба варианта слышу одновременно.
sincosxy
Тоже подозревал подвох, пока не скачал mp3
hexploy
Слышу набор звуков «еаи», если прислушаться то «еай».
Кажется, я понял почему я частенько переспрашиваю людей что же они сказали.
DevVadim
Влияет ли тип драйверов в наушниках (если ты слушаешь в них), на то, что ты слышишь? Интересно было бы сравнить чистую арматуру с наушниками для басхэдов.
alex319
Мне кажется что причина в частотах, распознаваемых ухом. Ну знаете, возрастные изменения и все такое. Я слышу перед Лорел только неясный щелчок и все. А мой сын слышит я в самом начале Я и достраивает слово.
2166618
Мне кажется первая аудио иллюзиюя был в MK2.
Всегда слышал что-то типа yuppi, а позже на ютубе выложили что это Toasty.
mwaso
Супруга уверяет, что четко слышит слово «левый».
vvadzim
На НЙТ сначала четко слышал йеней. Это по-умолчанию, посередине, на 5-м делении. На четвёртом слева тоже йеней. На третьем — лорал. Начал по миллиметру сдвигать вправо. В итоге на 5-м четко слышал лорал. А ведь до этого — йеней. Слышал лорал да 9-го деления. Потом йеней. Начал сдвигать по миллиметру влево. Пока писал коммент — четко слышал на пятом ДВА голоса, йеней и лорал. Пока дописал досюда — победил лорал. Четко так победил, сколько не вслушивался, йеней назад не вылезал. Поигрался с ползунком, теперь могу заставить ползунком свои уши слышать то лорел, то йеней, то оба вместе… Вот, а теперь могу переключаться усилием воли))
p_fox
По-моему, если вы слышите что-то отличное от «йеней», то вам просто стоит проверить свой слух.
HappyLynx
А вот сейчас обидно было.
Amissus
На самом деле там "laurel".
Аудиозапись была создана из записи 2007 года для слова «Лорел» на сайте Vocabulary.com
https://www.wired.com/story/yanny-and-laurel-true-history/
У произносимого слова «Янни» примерно такая же волновая характеристика, как и у «Лорел». Его волна тоже имеет вид «вверх-вниз-вверх», но только с немного другими акустическими характеристиками. Низкое качество записи и несколько наложенных друг на друга частот выше 4,5 кГц — причина того, что некоторые люди слышат слово «Янни».
tyomitch Автор
Ссылка на Vocabulary.com в посте присутствует с самого начала.
«примерно такая же волновая характеристика» — нет, они достаточно непохожи. У последовательности гласных «а-у-а» тоже будет волна «вверх-вниз-вверх», но никто ведь не слышит в этой записи слово «лагуна».
tyomitch Автор
Во-первых, те, кто слышат «Янни», слышат его совершенно чётко.
Во-вторых, низкое качество записи и наложение посторонних частот — это совершенно обычно для интернет-роликов; но в подавляющем их большинстве таких эффектов не возникает.
vitkt
А я поигрался с повышением\понижением тона, в итоге, если тон понизить — будет слышен «Йенни», если повысить — «Лорел». А если понизить не сильно — я отчётливо слышу и то, и другое одновременно (смещение с инвертированием фазы тоже помогло). После этого, кстати, мне стало легко концентрироваться на нужном слове в оригинальной дорожке.
CyberAndrew
Мне кажется, что просто каждый час меняется аудиофайл на сайте, вот и получаются якобы разные результаты. Потому что вчера я отчетливо слышал Янни, а сейчас отчетливо слышу Лорел. И чтобы они хоть как-то были похожи — ни капельки такого нет. Почему? Потому что меняют файл.
Sliptip
Шапочку из фольги подогнать?) Если несколько людей слушают вместе и слышат разное, то что это? Каждому отдельно в уши свою версию подают?)
TRIMER
Скачайте файл и слушайте локально.
Fllash
Любопытная всё-таки штука. Саму запись в редакторах не разбирал, но складывается ощущение, что она сделана по принципу чересстрочных рисунков (помните, там решетку сверху накладываешь — видишь одно. Чуть сдвинешь — рисунок другой)
VioletGiraffe
Дело не в АЧХ. Как я только ни пытался услышать Yanni — ни в какую, ни одного звука даже похожего не слышу. Пробовал на разных компах, в разных наушниках, даже в Sennheiser HD800. Более того, никакие настройки эквалайзера не помогли мне услышать Yanni. Пробовал и 2-3 кГц задирать, и только от 4 кГц и выше оставлять, и другие полосы вырезать или поднимать — никак.
А вот что заставляет меня думать, что дело не в слухе, а в мозге: с помощью демки от NY Times я нахожу положение слайдера, при котором я ещё слышу Янни, но уже с трудом — нужно концетрировать внимание, чтобы продолжать слышать именно так. И вот в этом положении спустя секунд 20-30 я теряю способность слышать Янни и начинаю слышать только Лорел, как бы я ни старался. Не трогая ползунка. Звук не меняется, а восприятие меняется.
Когда я слышу Янни, то, что раньше было звуками Л и Р, воспринимается как какое-то фоновое бульканье. Когда слышу Лорел, звуки Я/И кажутся просто шумом/щелчком в самом начале и конце записанного фрагмента.
В тему: www.youtube.com/watch?v=evQsOFQju08
SelenIT3
Похоже, мозгу всё-таки нужны «зацепки», чтобы достроить ту или иную версию. У меня тоже в той демке переход от «лорэл» к «йены» и обратно происходит в разных положениях ползунка — туда аж на 9 (предпоследнем) делении, обратно где-то на 7...7.5 (и чуть ниже 7.5 возникает описанный вами эффект — мозг какое-то время «цепляется» за один паттерн распознавания, но потом срывается на «дефолтный»:). Но ведь ниже 7 деления «йены» никаким волевым усилием не получается, даже на короткое время...
useluch
Надо показать жене, когда она следующий раз скажет «я тебе говорила».
Vaskrol
А я сразу слышал оба имени и недоумеваю, как другие слышат что-то одно. Мне кажется, что просто тупо наложены 2 дорожки, Лорел на низких и Енни на высоких.
minamoto
Не работает… Выкрутил в крайне левое положение — все равно слышу Yanny, хотя менее четко.
SchmeL
Ну это почти как с этим видео:
Я хочу вас от всей души поздравить бл@*
youtu.be/4SwHAhcL5IA
Но если
alexisneverlate
>>А я сразу слышал оба имени и недоумеваю, как другие слышат что-то одно. Мне кажется, что просто тупо наложены 2 дорожки, Лорел на низких и Енни на высоких.
Именно.
Но в зависимости от степени твоей концентрации одно может переходить в другое как в середине так и в самом конце частот.
Вчера был вариант с ползунком частот — у меня иногда переключение было в серединке, а иногда почти с самого «краю».
Т.е. смотря как ухо включить)
er1
Я бы не сказал, что она настолько сложнее платья. Но интересная, так как лучше иллюстрирует работу мозга. Видно, что мы не просто воспринимаем все звуки, а они сначала проходят через фильтр мозгом (сейчас в телефонах модно подобное встраивать в камеру, но куда им до нас). Мозг фильтрует то, что считает шумом и оставляет более ценную с его точки зрения часть. Хороший способ навести на размышления, что мы воспринимаем мир не напрямую таким, какой он есть. И вечный для меня вопрос — а каким его видят другие люди.
Helium4
Общался с производителем пигментных паст для тонировки лакокраски. Вы не представляете, как сложно согласовывать некоторые цвета, особенно когда спектрофотометр у заказчика барахлит. И это в среде технологов, без звена конечного покупателя.
ЗЫ Yanny
spax555
Вывода тут два:
01. С низкокачественных аудиоисточников (пластиковые пк-колонки, битсы, айфоны и т.п.) слышится Лорел. С качественных (в том числе винила) слышится Янни.
02. Люди с плохим музыкальным вкусом или не воспринимающие большой спектр акустических частот вне зависимости от источника почему-то слышат Лорел. Все остальные — Янни.
vbif
Вы тестировали на виниле o_O?
SelenIT3
Похоже, схема чуть сложнее:
parakhod
Вы, на самом деле, дали абсолютно правильный ответ, поверьте человеку с 18-летним опытом работы звукорежиссёром.
Всё, на чём высокие частоты зарубаются (в том числе и плохие уши) "телефонит" звук, и ухо настраивается на главную голосовую формату в районе 1-1.5 кГц.
Если же в источнике превалируют высокие частоты (или в ушах меньше ваты), воспринимаются форманты где-то на 2.5 кГц.
Да, тот же эффект превалирования формант на 1кГц может возникать и из-за собственных резонансных частот акустики (особо хреновой и дешёвой), а также и при изменении громкости без тонкоррекции (статья про кривые равной громкости из педивикии в помощь).
vbif
Вряд ли даже дешёвая карта или наушники будут «телефонить», это должно быть нечто совсем уж экстремальное, типа наушников ТОН-2, или передачи по телефону/скайпу. Любые современные наушники 15 кГц должны выдавать, а они вряд ли как-то влияют на восприятие. А вот давать гармонические искажения, или модуляции с частотой дискретизации — запросто.
Я послушал видео с обрезкой сначала низких, а потом высоких частот как на свистке DEXP за 100 рублей в нонейм-затычках, и на SB049 в наушниках JVC RX300 — и мне слышится loral во всех случаях.
parakhod
"Телефонить" может даже достаточно дорогая акустика, нелинейность АЧХ имеется у любых колонок и наушников, и весьма приличная — если же мерить и собственные резонансные частоты и фчх то вообще душераздирающая картина будет. Более-менее нормальную частотку можно ожидать только от студийных мониторов в заглушенной комнате (причем не новых в пластиковых корпусах, как сейчас любят).
АЧХ карт и усилителей вообще принимать во внимание не стоит — их вклад пренебрежимо мал.
А вообще хотите нормально проверить — возьмите параметрический эквалайзер, заберите полосу шириной герц в 500 вначале на килогерце, а потом передвиньте на 2.5-3. И будет вам и то, и другое.
Что касается гармонических искажений — они вообще ни на что не влияют. Что вы имеете в виду под модуляциями — ума не приложу.
vbif
Купите свисток за 100 рублей и послушайте как звучит плавное увеличение тона в районе 15-20 кГц. Явно слышны биения, будто при настройке АМ-приёмника. На «нормальной» звуковой карте ничего лишнего не слышно. Полагаю, дело в плохой (или отсутствующей) фильтрации частот выше 20кГц и нелинейности дальнейшего тракта, отчего и появляются эти биения.
parakhod
Ещё раз — я проработал звукорежиссёром кино 18 лет и у меня первое образование — электроника, так что пожалуйста, не надо просить меня что-то купить и что-то послушать, я по-моему все виды возможного говна и слышал и видел. И, поверьте, процентов 70 даже молодых людей не слышит даже 15кГц, у многих даже 12 расслышать вызывает проблему.
То же самое с динамикой — для большинства расслышать разницу меньше 6дб — задача непреодолимая.
Так что все эти стенания про разительную разницу аудиотракта в зависимости от цены — чаще всего чистое фантазирование.
Я где-то 10 лет назад про это цикл заметок писал, где-то должно было остаться, ещё вполне актуально многое.
Ну а всем, кто хочет оценивать звук или звуковое оборудование на слух, я очень советую пройти классический тест golden ears, он сейчас онлайн доступен. Слушать можно на чём угодно — это разницы не имеет. Всё профессиональные звукорежиссёры, кто проходил последнюю версию, сталкивались только с проблемой отличения MP3 с битрейтом 256 от оригинала — это действительно сложная задача.
Большинство же теоретиков от аудиофилии рубилось уже на самом первом этапе, когда надо было услышать задир или провал полосы на 3дб.
Кстати, реально попробуйте на досуге — очень забавный тест.
vbif
Так речь идёт не про Hi-End, а наоборот даже — про Low-end. Купить я вам предлагал чтобы спуститься из мира профессионального оборудования в то, что слышит «народ». Там реально куча забавных «эффектов» обнаруживается.
parakhod
Hi-end это из области маркетинга термин. Профессиональное оборудование отличается не выдающимися характеристиками, а стабильностью и неубиваемостью. Дешевенький микрофон AKG может звучать в разы интереснее и прозрачнее, чем рабочая лошадь mkh-416 с четырехциферным ценником в еврах, однако он сдохнет в первую же неделю на съёмочной площадке всего лишь от повышенной влажности, а 16-й будет и под дождем, и в -40, и в +50 нормально работать.
Ну и не думайте, пожалуйста, что профессионалы живут в волшебном мире с феями и референсы и комнатами прослушивания. Даже в любой распальцованной студии мастеринга обязательно живёт "говноконтроль" — чаще всего двухкассетник из 80-х. И на нём всё проверяется в обязательном порядке (а многие и сводят на таком). Всё же понимают, что будет с фонограммой дальше и кто и где будет ее слушать.
В кино же ещё хуже (особенно если кино телевизионное), когда я работал с Урсуляком, к примеру, мы с ним перезаписывали (сводили т.е) каждую сцену с контролем на krk v6 (тоже не бог весть какой хайэнд, но очень честный контроль), но потом слушали всё через динамик дешёвого телевизора Sony, на которое выводилось и видео. И делали коррекцию если что-то пропадало, или, наоборот, начинало выпирать.
Хуже того — в телевидении ещё и вещательный тракт — это полный финиш. Так что, к примеру, на той же Ликвидации, когда мы перезаписывали 6ю что-ли серию, склеенные первую и вторую уже эфирили. Так мы скачивали с торрента то, что народ записал с эфира во Владивостоке (орбиты, у них все а несколько часов раньше чем в МСК) и слушали, насколько в эфире было всё зажато и обрублено, чтобы на оставшиеся серии уже внести коррективы.
Так что и про "забавные эффекты" мы тоже слегка того, наслышаны ))))
vbif
А по поводу GE онлайн: не поделитесь ссылкой, что удалось нарыть — протухло.
joshhhab
Lorel слышат те, у кого с высокими частотами на слух проблемы, янни наоборот, у кого все в порядке. У меня с высокими проблемы, поэтому только лорел во всех вариантах
CKA3ATb_BCEM
Мы на работе генератором частот проверяли кто до куда слышит, люди, которые не слышали высоких частот тоже могли услышать янни. Произносится всё в диапазоне обычной речи же
vbif
Я вот ещё слышу 17,5, но чёткого Yanny не слышал ни в одном из вариантов.
TheShock
Моему отцу 60, какие там уже высокие частоты. Он слышит Янни, я — Лорел
parakhod
Очень тривиальный эффект, человеческое ухо способно достаточно хорошо отфильтровывать сигнал с достаточно узким спектром (эффект «телефона»), соответственно если наложить два подобных сигнала со схожей амплитудной характеристикой, но находящиеся в разных частотных полосах, то наш слух будет способен выделить что один, что другой. Рубаните все частоты выше 2,5-3 кГц — будет чистое «lorel», рубаните наоборот весь низ — будет «yanni».
Не удивлюсь если кому-то особо неленивому и 3 и 4 слова в подобную игрушку удастся засунуть.
u007
Мне кажется, нам просто необходимо масштабное исследование. С подведением статистики по возрасту испытуемых, полу, образу жизни, уровнем дохода, и тому, что они слышат в этой записи.
u007
Через 20 лет проверить динамику изменений: здоровье, слух, когнитивные нарушения, уровень интеллекта. Результат запатентовать и использовать для предсказания отклонений на ранних стадиях)
А если ещё и обнаружатся зависимости между IQ и ответом на этот вопрос, работодатели смогут включить Тест Лорэла в собеседования.
Kehit
Yanny со звуком R по середине на заднем фоне, из-за чего многие выбирают лаурел, хотя это йенни. ?\_(?)_/? Мой друг сказал вообще Moral.
Проверил на 4 разных устройствах, немного отличалось, но слово оставалось таким же. Где тут можно услышать L в начале и конце я не понимаю.
paranoya_prod
Слушал на ноуте в наушниках, слышал «Лорел». Давал слушать коллегам со смартфона, все слышали «Йени», один слышал «левой», я слышал «лорел». Дал послушать ещё двум человекам на вытянутой руке и слегка наклоненным телефоном, они услышали «йенни», я так же услышал «йении». Проверил, близко слышу «Лорел» на вытянутой и почти таком же наклоне слышу «Йенни». С платьем такого не было, оно всегда было правильным.
delimer
Забавно утром прослушал и слышал Йени, а сейчас уже Лорал. Зашел на NYtimes и начал двигать ползунок. Пока ползунок в центе то слышу Лорал, пришлось сдвинуть на пару делений вправо, чтобы услышать Йени, но зато если потом ползунок медленно вести влево, то можно дойти первого деления слева от центра и слышать Йени. Если потом на десяток секунд прерваться и снова запустить звук, то будет уже Лорал.
springimport
Слушаю уже несколько дней. Что на айфоне, что в крутых наушниках — все Yanny.
sasha1024
Вот здесь хорошее видео, на котором многие могут услышать оба варианта: «Yanny / Laurel — Removing High/Low Frequencies» <https://www.youtube.com/watch?v=OF9J14ba3Hw>.
vbif
Лично я ни на одном не услышал Yanny
sasha1024
У меня последовательно смещалось от [йэ?ны] к [ло?рел] — в смысле, что:
sasha1024
«несмотря на то, что во всех других местах, уже слышал только [йэ?ны]» — опечатка, должно быть «несмотря на то, что во всех других местах уже слышал только [ло?рэл]»
sasha1024
Опа, а сейчас снова [йэ?ны]. Совет — попробуйте перед 0:19 ожидать услышать женский голос (т.е. голос-то всё равно будет мужской, но, возможно, ожиданием женского Вы настроите себя на восприятие более высоких частот). Хотя сейчас я уже засомневался, что я реально там слышал [ло?рел] (мне сейчас кажется, что я просто случайно включил 0:12 один раз вместо 0:19).
vbif
Более того, на втором в начале появился звук «К», получилось что-то типа «klorel»
sasha1024
На 0:12 [k] не слышу.
vbif
А на 0:19?
sasha1024
Сейчас не слышу — жалко, что я не обратил на это внимания тогда, когда мне там слышалось [лорэл] (если оно, конечно, действительно там слышалось, а не я перепутал фрагмент), может, тогда и был [к], но как теперь узнаешь.
sasha1024
Опа, снова, [лорэл] — нет, [к] не слышно.
vbif
Даже в крайнем положении Yanny Laurel до конца не уходит. L становится тише и превращается в непонятное ухание, но не исчезает совсем, r всё ещё непохоже на n, хотя последняя l скорее угадывается, чем реально звучит, и больше похожа на обрыв записи.
sasha1024
А Вы пробовали начинать сразу с правого крайнего положения? (Просто у меня есть некоторая инерция — я когда слышал что-то, то при незначительном смещении ползунка продолжаю его слышать: я так почти до крайнего 1.0 дотянул лорэл и до 0.4 йэны — хотя вообще граница для меня сейчас где-то по 0.6 проходит.)
tom280586
Теперь ждем, когда целый текст так запишут.
Nooll_pointer
Через наушники слышу Yanny, а через колонки ноута слышно отчетливое Laurel.
sva89
Лично я слышу Йенни, а жена стоит рядом и слышит Лорел. Надо проверить вечером.
sva89
И, в подтверждение слов некоторых комментаторов, настал вечер и я слышу Лорел.
sswwssww
В винде, свойства динамика-улучшения-изменение высоты тона.Меняйте от -4 до 4. -4 =Лорал ,4 = Янни.
smallreg
На хреновеньких динамиках ноутбука получается «Ерэл» (пофантазировав, можно представить «енни». В хреновеньких наушниках затычках всегда «лорэл». По звук слышу, что в низких частотах записан один звук, а в высоких — другой. На случайность это мало похоже.
taujavarob
Как же мы вообще понимаем что нам говорит иной человек?
dioneo
Можно послушать: http://www.ipachart.com/
Представьте, что на необитаемом острове живут люди, которые произносят свои имена, как: ?, f, m, ?, ?, ?, x, ?. Через очень короткий промежуток времени, слыша каждый такой звук вы будите представлять одного конкретного человека, а не двух людей сразу, даже если звуки очень похожи.
DmitryShagin
При первом прослушивании был увверен, что сначала произносится Yanny, а затем — Laurel. При повторных прослушиваниях слышу только Laurel, вне зависимости от воспроизводящей аппаратуры. Произнесение вслух Yanny тоже не помогает.
eboook
слышу только Laurel-передвигая ползунок вправо почти до упора, тольео в конце искаженное Yanny
unwrecker
Весь день на работе слышал йени. Пришел домой, выпил чаю, теперь лорел и иногда йени. Так что пиво пить необязательно :) Любое питьё (или может еда) тоже меняет восприятие звука.
Harrix
Что за магия? Слышу Yanny в оригинальном звуке только. Попробовал NY Times крутить ползунки. В крайнем левом положении несколько раз услышал Laurel, а потом как отрубило: всегда слышу даже в крайнем левом положении только Yanny. Даже стали появляться плохие мысли, что NY Times что-то подкручивает.
LanMaster
У меня есть, КМК, гораздо более точная спектрограмма этого звука
mbait
Где вариант «слышу оба слова одновременно»? «Laurel» — низкий голос, «Yanny» — высокий.
tyomitch Автор
В опросе можно поставить сразу обе галочки.
64 человека так и сделали.
sasha1024
Я лично поставил обе галочки, потому что я слышал сначала Ены, а потом Лорел (а не оба сразу). И кстати, интересный нюанс: я читал отзывы большого количества людей, которые слышали сначала Ены, а потом Лорел (как и я) — но есть ли хоть один, который сначала (стабильно) слышал Лорел, а потом стал (стабильно) слышать Ены?
ABVBAV
Вот тут отчетливо на среднем значении ползунка можно за один повтор услышать сразу два слова одновременно.