

Компания Netflix одержима вопросом доступности сервисов. Мы уже не раз рассматривали его в нашем блоге и рассказывали, как нам удаётся достичь своих целей. Мы используем circuit breakers, лимиты параллельных подключений, тестирование с помощью намеренного внедрения ошибок (chaos testing) и многое другое. Сегодня мы представляем вам ещё один инновационный подход, который существенно повышает стабильность приложения при экстремальных нагрузках и позволяет избежать каскадных сбоев в работе сервисов — адаптивные лимиты параллельных подключений. Больше не нужно тратить силы, чтобы определить лимиты параллельных подключений, позволяющие системе поддерживать небольшое время отклика. В рамках этого анонса мы также выкладываем в открытый доступ простую Java-библиотеку с возможностями интеграции для сервлетов, управляющих программ и gRPC.
Начнём с основ
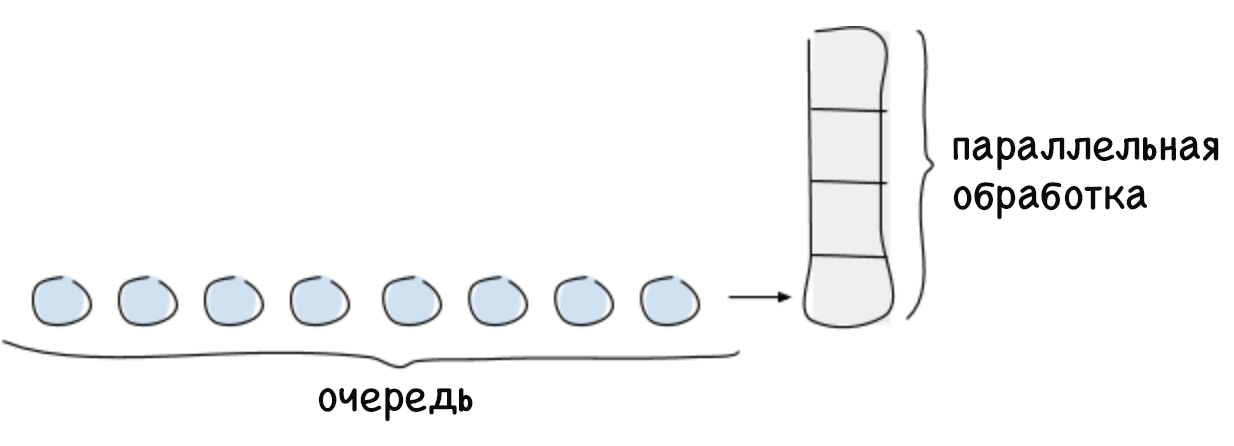
Лимит параллельных подключений — это максимальное количество запросов, которые система способна обрабатывать в определённый момент времени. Как правило, это количество зависит от ограниченного ресурса, например вычислительной мощности центрального процессора. Обычно лимит параллельных подключений системы рассчитывается по закону Литтла, который звучит так: для стабильной системы максимальное количество параллельных подключений равно произведению среднего времени, затрачиваемого на обработку запроса, и средней интенсивности поступающих запросов (L = ?W). Любые запросы сверх лимита параллельных подключений не могут быть немедленно обработаны системой, поэтому они попадут в очередь или будут отклонены. Формирование очереди — важная функция, которая позволяет полноценно использовать систему в случаях, если запросы поступают неравномерно и требуют различного количества времени на обработку.
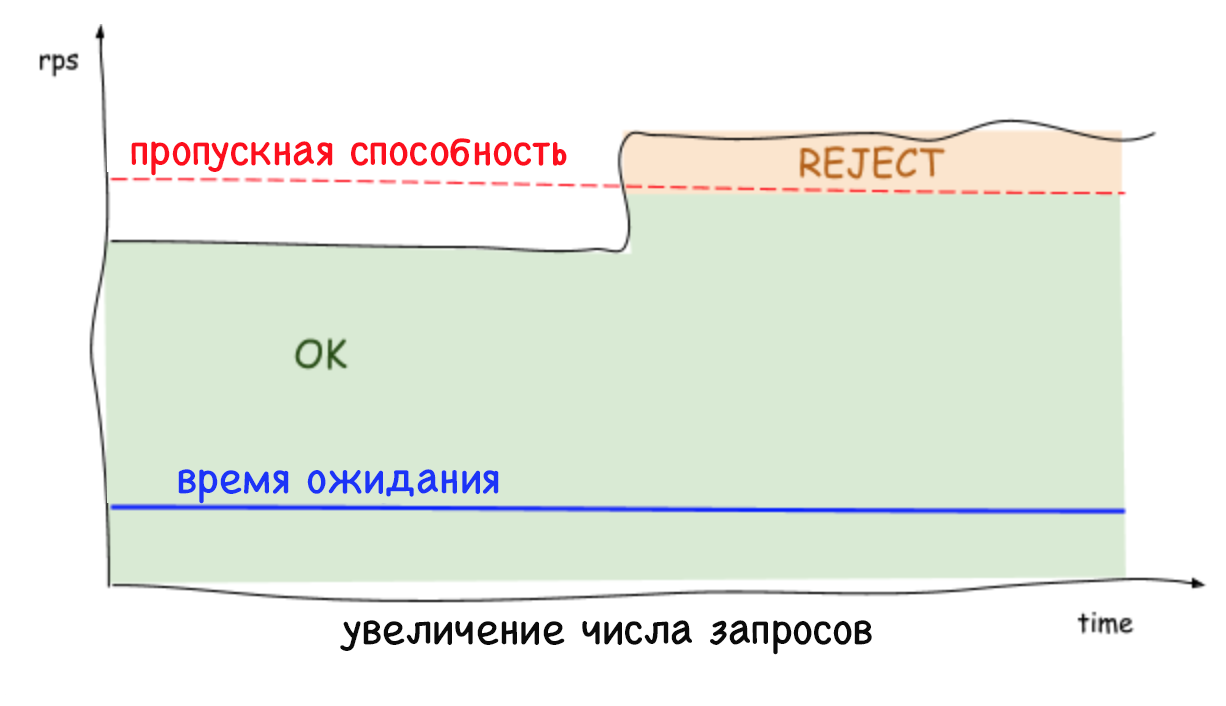
При отсутствии лимита для очереди может произойти сбой системы, например, если в течение длительного времени интенсивность поступления запросов будет превышать скорость их обработки. По мере роста очереди растёт и задержка, что приводит к превышению времени ожидания запросов. Это продолжается до тех пор, пока не кончится свободная память, после чего система падает. Если не уследить за возрастающим временем задержки, оно начнёт негативно влиять на вызывающие сервисы и приведёт к каскадным сбоям в системе.

Применение лимитов параллельных подключений — стандартная практика, однако сложность заключается в их определении для больших динамических распределённых систем, где такие параметры, как время задержки и возможное количество параллельных подключений, постоянно меняются. Суть нашего решения — в возможности динамически определять лимит параллельных подключений. Этот лимит можно представить как количество поступивших запросов (выполняемых параллельно и поставленных в очередь), которое система способна обрабатывать, пока её производительность не начнёт снижаться (а время задержки — увеличиваться).
Решение
Ранее сотрудники Netflix определяли не подлежащие изменению лимиты параллельных подключений вручную с помощью трудоёмкого тестирования производительности и профилирования. Полученное в результате число было верным для конкретного периода времени, однако вскоре топология системы начинала меняться из-за частичных отказов, автоматического масштабирования или внедрения дополнительного кода, который влиял на время задержки. В итоге лимит устаревал. Мы знали, что способны на большее, что нам уже недостаточно просто определять лимиты подключений статически. Нам нужен был способ автоматического определения свойственных самой системе лимитов. При этом мы хотели, чтобы этот способ:
- не требовал ручной работы;
- не требовал централизованной координации;
- мог определить лимит без какой-либо информации об аппаратном обеспечении или топологии системы;
- адаптировался к изменениям в топологии системы;
- был прост с точки зрения внедрения и необходимых вычислений.
Для решения этой проблемы мы обратились к проверенному алгоритму отслеживания перегрузок в протоколе TCP. Этот алгоритм определяет количество пакетов данных, которые можно передать параллельно (т. е. размер окна переполнения), не увеличивая время задержки и не превышая время ожидания. Эти алгоритмы используют различные показатели, чтобы определить лимит передаваемых одновременно пакетов и изменить размер окна переполнения соответствующим образом.

Синим цветом на рисунке изображён неизвестный нам лимит параллельных подключений к системе. Сначала клиент отправляет малое количество параллельных запросов, а затем начинает периодически проверять систему, может ли она обработать больше запросов, увеличивая окно переполнения, пока это не повлечёт за собой увеличение задержки. Когда задержка всё-таки увеличивается, отправитель решает, что достиг лимита, и вновь уменьшает размер окна переполнения. Такое непрерывное тестирование лимита отражается на графике, который вы видите выше.
Наш алгоритм опирается на алгоритм отслеживания перегрузок в протоколе TCP, который рассматривает соотношение между минимальным временем задержки (лучший возможный сценарий, в котором очередь не используется) и временем задержки, которое периодически измеряется по мере выполнения запросов. Это соотношение позволяет определить, что сформировалась очередь, которая провоцирует увеличение задержки. Данное соотношение даёт нам градиент или величину изменения времени задержки: градиент = (RTTnoload/RTTactual). Если значение равно единице, то мы понимаем, что очереди нет и лимит можно увеличить. Значение меньше единицы указывает на то, что очередь переполнена и лимит необходимо уменьшить. С каждым новым измерением времени задержки лимит корректируется на основе вышеуказанного соотношения, а вместе с ним меняется и допустимый размер очереди в соответствии с этой простой формулой:
Новый_лимит = текущий_лимит ? градиент + размер_очередиЗа несколько итераций алгоритм вычисляет лимит, который позволяет не только поддерживать время задержки на низком уровне, но и сформировать необходимую очередь запросов на случай вспышек активности. Допустимый размер очереди можно настроить. Он используется для определения того, насколько быстро может возрасти лимит параллельных подключений. В качестве размера по умолчанию мы выбрали квадратный корень из значения текущего лимита. Этот выбор обусловлен полезным свойством квадратного корня: при малых значениях он будет достаточно большим по сравнению с лимитом, чтобы обеспечить быстрый рост, однако при больших значениях, напротив, его относительная величина будет меньше, что позволит повысить стабильность системы.
Адаптивные лимиты в действии
Адаптивные лимиты на стороне сервера отклоняют излишние запросы и поддерживают низкое время задержки, что позволяет экземпляру системы защищать себя и сервисы, от которых он зависит. Ранее, когда не было возможности отклонить излишние запросы, любой устойчивый рост количества запросов в секунду или времени задержки приводил к ещё большему увеличению этого времени и в конечном итоге к падению всей системы. Сегодня сервисы могут избавиться от лишней нагрузки и поддерживать низкое время задержки одновременно с работой других стабилизирующих инструментов, таких как автоматическое масштабирование.
Важно помнить, что лимиты устанавливаются на уровне сервера (и без какой-либо координации), что трафик на каждый сервер может резко падать и возрастать. Поэтому нет ничего удивительного в том, что выявленный лимит и количество параллельных подключений может быть разным в зависимости от сервера. Это особенно верно в условиях облачной среды со множеством клиентов. В результате может сложиться ситуация, когда один сервер окажется перегружен, хотя остальные будут свободны. При этом при балансировании нагрузки на стороне клиента всего один повторный запрос достигнет сервера со свободными ресурсами почти в 100 % случаев. И это ещё не всё: больше нет причин волноваться о том, что повторные запросы спровоцируют DDOS-атаку, так как сервисы в состоянии быстро (меньше чем за миллисекунду) отклонить трафик при минимальном влиянии на производительность.
Заключение
Применение адаптивных лимитов параллельных подключений избавляет нас от необходимости вручную определять, как и в каких случаях наши сервисы должны отклонять трафик. Более того, это ещё и повышает общую надёжность и доступность всей нашей экосистемы, основанной на микросервисах.
Мы рады поделиться с вами нашими методами реализации и общей интеграции этого решения, которые вы можете найти в общедоступной библиотеке по адресу: github.com/Netflix/concurrency-limits. Мы надеемся, что наш код поможет пользователям защитить свои сервисы от каскадных сбоев и проблем с возрастающим временем задержки, а также повысить их доступность.