
Часто ли вы запускаете поиск по текстовым файлам? Я — каждый день уже больше 25 лет.
Мои задачи очень разные по сложности и объему.
Во-первых, как программисту, мне, конечно, нужны поиски в кодах. Это задачи простые (наборы папок и файлов малы) и быстрые (результаты появляются почти сразу).
Во-вторых, как оператору, мне приходится искать по сотням (иногда тысячам) папок среди тысяч (иногда сотен тысяч) файлов. Это задачи тяжелые и по объемам результатов, и по времени их получения. Обычно результаты таких поисков еще требуют дальнейшей ручной или программной обработки.
Вся работа происходит в Windows.
Расскажу куда завело меня желание иметь подходящий инструмент для таких задач.
В начале был TextPad
Больше 10 лет TextPad был моим основным легким инструментом.
Тогда (до и немного после 2000) он прекрасно справлялся.
Поиск по файлам выглядел так (TextPad, 2004)

(+) В диалоге мало настроек, поэтому он не заслоняет содержимое файлов.
(+) Вкладка с результатами поиска имеет спец.поведение — Ввод/ДвКлик позволяют открыть найденный фрагмент. В остальном это обычный текст "в памяти" редактора.
(+) Есть настройка File counts only для поиска не самих фрагментов, а только их количества по файлам. Это заметно ускоряет предварительный поиск.
(-) В диалоге мало настроек и мало команд. Окно диалога фиксированного размера.
(-) Вычурный язык регулярных выражений, например, вместо принятого сейчас \w нужно было писать [:word:].
В целом тут качественно, но скромно.
Шатания и сравнения
Ограниченность TextPad и его заморозка вели к постоянным пробам других редакторов.
Теперь уже не вспомнить все перепробованные, но среди них были:
- MS Visual Studio. Тяжелый монстр.
- Eclipse. Тоже монстр.
IntelliJ IDEA. Очаровательный. Служил и служит поставщиком примеров того, как можно сделать удобно.
ВпечатленияТот старый IDEA уже утерян. Для сравнения текущая реализация в PyCharm, 2017.1.3

(+) Невообразимое число настроек и режимов.
(+) Самодостаточность диалога: видны и результаты, и исходные тексты, и статистика поиска.
(-) Нет ограничения на глубину поиска по папкам — либо одна, либо сразу все.
(-) Нет (не знаю способа) поиска по нескольким папкам.
(-) Нет (не знаю способа) вывода результатов в текстовом формате.
В целом это мощно, но не универсально.
- Notepad++. Не помню, что помешало на него перейти.
SublimeText3, 2013. Хакерский инструмент — отличная работа, минимум средств, но требуется много держать в голове.
Впечатления
(+) Минимум контролов.
(-) Разные настройки "где искать" все в одном поле. Нужно учитывать их взаимодействие.
(-) Только прикрепленный диалог.
(+) Результаты сразу попадают в текстовую вкладку, и они наглядные.
(-) Результаты фиксированного формата: полный путь и имя файла, потом найденные в нем строки. От локализации найденных фрагментов есть только номера строк.
(+) Есть настройка "Контекст", чтобы в Результаты попадали найденные строки вместе с соседями.
Есть такой парень
Взяв за основу принцип "Нет идеального инструмента? Создавай", изменил направление усилий.
Стал обращать внимание на отзывчивость разработчиков. И в 2012 году мне повезло с SynWrite.
Единственный разработчик, Алексей Торгашин, принимал большинство идей, делал быстро и качественно. Типичное время реализации — день-два. На форуме попросил его о доделке, потом еще об одной, потом еще о десяти, и еще… Где-то третьем десятке понял, что мы удачно встретились.
С моей подачи Алексей довел поиск по файлам до такого состояния (SynWrite, 2016)

(+) Есть извлечение папки из текущего файла Current folder.
(+) Можно сортировать файлы по дате модификации.
(+) Есть список готовых наборов для поиска preset и быстрый доступ к ним (F3).
(-) Диалог очень перегружен и занимает много места.
(-) Результаты оформлены в виде контрола дерево в нижней панели. Чтобы получить их в текстовом виде нужно вызывать команду из локального меню.
"Чего тебе надобно, старче?"
С SynWrite искать стало значительно удобнее. Как известно аппетит приходит во время еды, поэтому мои хотелки все множились. Вот только отношение к ним у разработчика, моей золотой рыбки, было все более критическим — "Почернело синее море".
Вот что хотелось получить
- Обязательно нужны результаты сразу в текстовом виде (для дальнейшей обработки).
- Результаты должны быть самодостаточными! Чтобы их можно было сохранять, закрывать, открывать — и они оставались свежими, то есть готовыми к работе.
- Нужен поиск в файлах на диске и в открытых (измененных) файлах.
- Диалог при решении простых задач должен быть компактным. В частности контролы для "замен" и редких настроек не должны мешать при обычном поиске.
- Обязательно нужна опция для результатов вместе с соседними строками.
- Обязательно нужен режим "полное описание одного результата в одной строке" (для дальнейшей обработки).
- Справочная информация о том, как заполнять поля, нужна не во внешнем файле или облачной странице, а прямо тут же, например, в тултипах.
Сделай сам!
Мне повезло еще раз. Алексей создал новый редактор CudaText и прикрутил к нему Python API.
Наконец-то, можно было сделать все как хочется в виде плагина на Питоне.
Первая версия вышла в мае 2016.


Это, конечно, не совсем первый блин, но желание "все запихать в пирогдиалог" явно просматривается.
Вот что я применяю сейчас

Реализованы все хотелки из списка "Чего тебе".
(1) Результаты можно видеть либо внутри диалога, либо сразу выводить в файл (если [x] Send).
(2) Результаты самоописательные. В тексте

достаточно информации, что узнать полное имя файла и место найденного фрагмента.
1:21:6 означает: 1 строка, 21 колонка, длина фрагмента 6.
Плагин умеет эту информацию извлекать и использовать.
(3) Есть поиск по несохраненным документам. Для этого в поле In folder вводится специальная строка <Open Files> (работают сокращения <Tabs> и <t>).
(4) У диалога можно скрывать контролы, нужные для задания исключенных файлов, для выполнения замен, для показа результатов и исходников.
• Минимальный набор 
• Минимальный набор и замены 
• Минимальный набор и задание исключений для файлов 
(7) В тултипах у подписей к свободно заполняемым полям есть пояснения


Более подробная информация доступна при вызове Alt+H

Реализовано еще много разных штук.
Глубина обхода может быть нулевая (
Only), полная (+All), либо от 1 (+1 level) до 5 (+5 levels) уровней.
Редко применяемые параметры поиска появляются по
For search

• Можно пропускать поиск в *скрытых* и/или *двоичных* файлах.
• Можно предварительно отсортировать файлы по дате.
• Можно остановить поиск после нахождения заданного числа фрагментов и/или файлов.
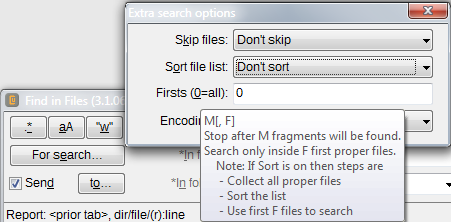
• Можно указать кодировки, которые будут применяться при попытках прочитать файлы (до первой успешной).- Если результаты будут появляться не внутри диалога (
[x] Send), то для них есть дополнительные параметры

• `Report to` - выводить в новый таб, в последний использованный таб, в файл с конкретным именем и открыть его.
• `Append` - дополнять предыдущие результаты.
• `Tree type` - можно по разному разбивать строки
`<path><file><r:c:l><line>`, то есть `<путь><файл><место><строка с фрагментом>`
в частности, вообще не разбивать ("Чего тебе"-6). Возможные варианты описаны в Справке
• `Align (r:c:l)` - дополнять пробелами данные из `<r:c:l>` так, чтобы все `<строки с фрагментом>` начинались с общей колонки.
Пример: 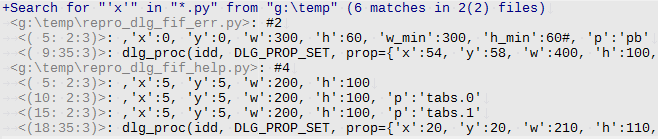
• `Add context` - дополнять результаты соседними строками ("Чего тебе"-5).Можно запоминать параметры поиска — делать пресеты. Первые пять пресетов применяются по
Ctrl+1(..5), остальные — из меню или диалогаPresets
диалог Presets
Можно запоминать место/размеры диалога/контролов — делать Layout. Первые пять Layout применяются по
Alt+1(..5), остальные — из меню.
Почти все в диалоге можно сделать без мышки. Для этого есть
Хоткеи
Для команд есть
МенюКнопка с гамбургером — это просто "=" с подчеркиванием, поэтому она доступна по
Alt+=.

Процесс поиска разбит на три последовательные фазы:
• формируется коллекция подходящих файлов,
• из файлов извлекаются фрагменты,
• заполняется отчет о результатах.
Информация о каждой фазе и их смене отображается в статус-контроле.
Escпозволяет прервать работу только текущей фазы и перейти к следующей с уже накопленными данными.
Кроме задаваемых пользователем обычных параметров есть много редко изменяемых опций. Сейчас их 19 и для них отдельный диалог
диалог Options
Например, среди опций есть такие:
• Использовать выделенный текст для заполнения поляFind whatпри открытии диалога.
• Прерывать однимESCвсе фазы поиска.
• Закрывать диалог при удачном поиске и выводе результатов в файл.
• Сворачивать предыдущие результаты при дописывании новых в тот же файл.
• Сохранять все параметры поиска в первой строке результатов. Это позволяет позже загрузить их в диалог.
• Пропускать файлы с размером больше заданного.
• Задать стиль для найденных фрагментов. Доступны цвет/жирность/наклонность текста, цвет фона, стиль рамки с каждой стороны. На снимках выше установлен стиль "рамка точками под фрагментом".
- Часть команд плагина работают до и после диалога.

• `Find in *` - вызывать диалог с готовыми параметрами для разных поисков.
• `Navigate to *` - прыжки из результатов в исходники, с разными размещениями места, где открыть исходник.
• `Jump to *` - прыжки к следующему/предыдущему фрагменту этого же исходника, к фрагменту в следующем исходнике, к фрагменту в следующей папке.
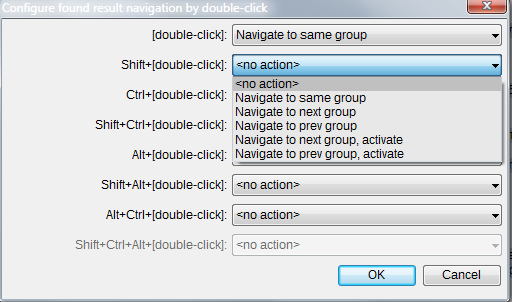
• `Configure *` - какой прыжок делать при двойном клике в результатах, разные прыжки при разных зажатых модификаторах
CudaText и Python
Несколько слов о платформе, на которой вырос мой плагин.
Алексей Торгашин сделал SynWrite на Дельфи. Половина кодов этого редактора были лицензированы у другого разработчика, и это мешало внедрению новых идей. А еще Дельфи платный. Из-за этого Алексей перешел на Free Pascal и IDE Lazarus, реализовал недостающие части самостоятельно и создал в 2015 году CudaText, а SynWrite заморозил. Возможность начать с чистого листа была использована толково — он сделал несколько сильных проектных улучшений.
- Настройки стали накладываться слоями: умолчание, общие, лексовые, текущего файла. Они стали храниться в
json, а не вini. Изменение настроек стало обычным редактированием текста в форматеjson. - Ядро избавилось от огромного множества некритичных сервисов. В частности, от поиска по файлам, макросов, вызова внешних утилит, конфигуратора меню, сниппетов, сортировок, фаворитов и пр.
- Для создания таких сервисов ядро предоставляет Python API, в которое входит GUI библиотека. Сейчас плагинами реализованы все прежние сервисы и добавлена масса новых.
- Кроме того ядро само стало многомодульным. Появились компоненты маркеров, букмарков, атрибутов для скобок и пр.
Здесь хорошо видно влияние Sublime Text. Насколько я знаю, Алексей не скрывает, что учитывает идеи из Sublime и его плагинов. На Atom и Brackets он тоже поглядывает.
Получилось само по себе хорошо, а с учетом высокой продуктивности и отзывчивости Алексея — отлично. Чтобы пояснить о какой продуктивности и отзывчивости идет речь, приведу несколько фактов:
- Алексеем создано: лексеров — 201, линтеров — 34, сниппет-наборов — 12, плагинов — 93.
- С октября 2015 года было более 1200 пожеланий (не претензий) на ГитХабе, из которых более 90% удовлетворены.
CudaText свободный, с открытыми исходниками, есть сборки для Win/Linux/Mac/BSD. Сам я пользуюсь только Win-версией, но вижу пожелания и претензии от пользователей с Linux и Mac. На этом же Лазарусе написан, кстати, Total Commander.
Интересно сравнивать Python API у Sublime и у CudaText. Они совсем разные.
• У Sublime — объектный стиль типа DOM.
• У CudaText — процедурный стиль типа API OS, например, WIN32.
Видимо это различие происходит от языков реализации. Если редактор сам реализован на Питон, то DOM стиль API для него естественный — можно хранить ссылки на объекты. А если редактор на Паскале, то хранить он может только handler-ы.
• У Sublime API нет GUI. Плагин, видимо, может использовать Python GUI (Tk? WxPython? Qt?), но стилистика будет контрастировать с Sublime.
• CudaText предоставляет для плагинов GUI в общей стилистике приложения. Во-первых, есть богатый арсенал базовых контролов: checklistbox, listview, checklistview, treeview и, конечно, обычные кнопки, чеки, одно- и много-строчные редакторы, комбобоксы и пр. Во-вторых, есть возможность встраивать компоненты CudaText в GUI. На снимках выше это статус-контрол, локальное меню и редактор-контролы с результатами/исходниками. Такого взаимодополнения чистым Python GUI вообще не достичь.
Поскольку я уже создал десяток плагинов для CudaText, и большинство из них общались с пользователем с помощью диалоговых окон, мне теперь крайне сложно представить, как можно создавать плагины без этого богатства. Конечно, если у плагина только один диалог, который позволяет задавать настройки, то редактирование json дает адекватную замену. Но такое редактирование выполняется "до запуска" плагина, оно не может помочь, если нужна живая runtime реакция пользователя.
Есть ли предел?
Примерно раз в два-три месяца, а длится это, напомню, уже два с половиной года, мне кажется, что "это финал" — диалог вылизан, результаты показаны всеми способами, все полезные команды есть. Но поскольку этот инструмент постоянно в работе, поскольку применяются практически все его штучки, то пока руки кнопят очередной поиск или изучают очередные результаты, голова ищет новые улучшения. И находит!
Например, за время написания этого поста родились такие:
• Можно выделить текст в контролах Результаты или Исходник и дать команду на его поиск.
• Можно перехватывать события "открыт файл" с результатами и восстанавливать стиль найденных фрагментов.
Кроме того, мне интересно понять — может ли коллективный разум подсказать новые ходы в этой игре. Поэтому завершаю вопросом к коллегам программистам:
Что еще полезного можно добавить в "поиск по файлам" внутри текстового редактора?
• Язык: Python 3.5
• GUI библиотека: CudaText API
• Разработчики: Андрей Квичанский
• Объем кода: >300 Кб
• Число ToDo для плагина: >250
• Число bug/wish для CudaText API: >150
• Форум плагина: GitHub issues
• Скачать сборку CudaText под свою ОС, распаковать или установить.
• Запустить CudaText и вызвать команду меню Plugins/Addons Manager/Install...
• Ввести "find", чтобы фильтр оставиль только FindInFile, установить (может быть потребуется перевызов CudaText, на Win не нужно).
• Вызвать команду меню Plugins/Find in Files/Find in files...
Комментарии (38)

rezdm
17.07.2018 11:18+1Для разработки под виндой я просто поставил Unix utils (те, которые без cygwin'а) и радуюсь обычным ls, find, awk (gawk),…
KUbo_0
17.07.2018 14:23я это счастье с OpenServer познал ConEmu > Settings > Startup > Environment > set PATH = %openserver%PortableGit\usr\bin\
rezdm
17.07.2018 14:29Несколько раз перечитал, пока не понял, что OpenServer — это не SCO OpenServer ;)
Из опыта более позднего, все эти тулзы приходят вместе с git'ом. Просто его поставить (речь итолько под win)
NeoCode
17.07.2018 11:24Total Commander'а обычно хватает. А для поиска по коду средствами различных IDE не хватает одной простой фичи — чекбоксов "искать в коде", "искать в строках" и "искать в комментариях". Довольно часто например хочется исключить комментарии из поиска.
kvichans Автор
18.07.2018 11:08Total Commander'а обычно хватает.
Все средства хороши. Я тоже не упускаю возможности искать в ТС и/или из командной строки.
"искать в коде", "искать в строках" и "искать в комментариях"
Подумаю над этим. Потребуется более глубокое взаимодействие с лексером. Интересная тема.
ovsale
17.07.2018 14:13А зачем вы запускаете поиск по текстовым файлам каждый день уже больше 25 лет? Интересен юзкейс. 5 лет пишу программу организации файлов при помощи иерархических тегов и мне интересно является ли ваш кейс потенциально тегируемым.
kvichans Автор
17.07.2018 14:22Если бы задача сводилась к ограниченному числу *типичных кейсов*, я бы и сам написал для нее автомат для решения. Все упирается в бесконечное разнообразие форматов, на которых люди пишут свои документы. Например, одно из применений моего плагина связано с анализом нормативных документов для составления строительных смет (ГЭСН/ФЕР/ТЕР/...), и тут новые форматы появляются *каждый месяц* в течение десятилетий.
ovsale
17.07.2018 15:46на самом деле *каждый месяц* это редко. это всего 300 за 25 лет. не помогло бы мое решение? www.youtube.com/watch?v=MYBnceFUxYg
не рекламирую свое не отрицаю ваше просто интересно подходит ли мое решение для вашего кейса в теории.kvichans Автор
17.07.2018 19:45- Мне понравилось ваше демо. Тегированная FS — это интересно.
- Только это пока видна лишь заготовка полезной программы.
- В демо не раскрыт способ, которым теги ставятся. ИМХО, это тяжелая GUI задача.
- В демо вы несколько раз показываете наложение разных условий (несколько тегов, типы и теги). Видно, что работает зашитая логика И/ИЛИ, которая не очевидна, и, более того, не полностью совпадает с ожидаемой или требуемой.
- Автономная программа, видимо, будет маловостребованной. Нужна интеграция с чем-то привычным.
- Для моего кейса это никак не подходит.
- Теги хороши, когда есть устойчивый набор файлов (библиотека статей/видео/ссылок), пополняемый не слишком часто, и из-за этого есть возможность его ручного тегирования.
- У меня документы появляются в огромных количествах и расстановка тегов для них — это само по себе не просто.
- А главное те запросы, которые я запускаю плагином, плохо тегируются.
- В самом плагине нет преград к использованию при поиске доп.информации о файлах в виде иерархических тегов. Уже есть (в другом плагине) проверенное GUI решение для поиска с учетом древовидных параметров.
ovsale
17.07.2018 19:57— это intro видео. оно должно показать потенциальную красоту использования вложенных тегов. видео про тегирование: youtu.be/nXbCy_7fRfs
— увы возможности интеграции с традиционными программами крайне ограничена. в силу того что они не понимают вложенные теги. есть плагин для браузеров. см. видео выше.
— насколько в «огромных» количествах появляются документы?
— «В самом плагине нет преград к использованию при поиске доп.информации о файлах в виде иерархических тегов». что значит «в виде иерархических тегов»?kvichans Автор
17.07.2018 20:08в виде иерархических тегов?
Это когда, как у вас, теги связаны в дерево. Например, в плагине "Настройки" есть дерево секций, по которым разложены опции. При поиске можно использовать фильтр, внутри которого указать из какой(их) секции(й) нужны опции

Секция добавляется в фильтр при выборе из меню.
Quiensabe
17.07.2018 21:26Интересное демо! А вы не думали о возможностях автоматического тегирования?
Например, если у пользователя есть папка «фильмы» — автоматически помечать ее содержимое этим тегом, если файл в формате видео, имеет вес от нескольких сотен мегабайт и продолжительность больше нескольких минут…
Понятно, что такой поиск будет не всегда отрабатывать на 100%. Но это, в тоже время, поле для экспериментов в области машинного обучения, облачной системы обмена «правилами тегирования» и множества других техник. Я к тому, что если подумать, как мы будем работать с компьютером лет через 5-10 — приходит в голову что-то сильно отличное от «проводника»…
У меня есть наработки по этому направлению. Если интересно можем обсудить.ovsale
17.07.2018 22:47спасибо. конечно думал. у меня автоматически назначаются типы. и по сути они являются автоматически назначаемыми тегами. типы у меня можно кастомизировать. что правда пока не отражено в документации.
потенциально да. можно добавить автотегирование. сейчас этого нет. и например вот почему. я по статистике добавляю в среднем 2 объекта в день. что занимает 2 минуты. есть возможность группового тегирования и редактирования тегов. взял все фотки из малайзии добавил тег «фото: место: малайзия». потом все фотки за 2015 год и добавил тег «фото: год:2015». потратил 10 мин на тегирование фоток за последние несколько лет и планирую получать удовольствие от использования все оставшиюся жизнь) к сож версию с более продвинутой поддержкой фотографий еще не выложена в загрузки — не закончил.
Fracta1L
18.07.2018 09:40Возможно, я чего-то не понял, но чем это отличается от иерархии каталогов и файлов?
ovsale
18.07.2018 11:27тем что файл может лежать в нескольких «папках»
Fracta1L
18.07.2018 13:57Но есть же ссылки.
kvichans Автор
18.07.2018 14:14Мягкие и жесткие ссылки в Файловой Системе дают для некоторых файлов альтернативные пути хранения. Дерево превращается в Сеть. Но, насколько я знаю, у пользователя нет простого способа увидеть и использовать все эти альтернативы, если он видит конкретный файл. Если в пути к файлу одна из промежуточных папок (в том числе и последняя) станет результатом новой ссылки, описание файла никак не изменится.
То есть ссылки — это исключительно про папки.
А теги — это про свойства файлов.
kvichans Автор
18.07.2018 11:49Обычная иерархия файлов — это один из способов для их структурирования.
Поскольку файлов часто очень много (например, у меня на С-диске 640К/83К файлов/папок), полезной будет почти любая дополнительная система доступа. Предлагаемые ovsale теги — это как раз про это. То что его теги образуют дерево, особенность реализации. Это полезно для манипуляций, но имеет обычные проблемы всех "каталогов": единственность родителя входит в противоречие с интуитивными связями между тегами.
В идеале, хотелось бы иметь СУБД, в которой у файлов кроме атрибутов "имя", "тип", "папка" были наборы произвольных свойств и поиск по ним. Теги стали бы одним из таких свойств.ivan386
19.07.2018 10:27В файловой системе NTFS у файлов и катологов есть альтернативные потоки. Туда можно записывать теги. Только соответственно нужна программа которая будет это делать.
kvichans Автор
19.07.2018 11:09Да, замечательная вещь — доп.потоки у файлов. Давно на них облизываюсь. Например, удобно хранить в них всю историю изменений файла, то есть данные для undo/redo. Но теги — нет, так как к ним имхо нужен ручной простой независимый доступ.
(Учтите, что я тут про теги пишу как диванный аналитик. Это не у меня, а у ovsale есть программа для работы с тегами)
GeekberryFinn
18.07.2018 04:26А зачем вы запускаете поиск по текстовым файлам каждый день уже больше 25 лет?
А вы что никогда не программировали? O_O
Такой поиск нужен, чтобы найти искомый кусок кода в сотнях файлов с кодом.kvichans Автор
18.07.2018 10:52Такой поиск нужен, чтобы найти искомый кусок кода в сотнях файлов с кодом.
Это, конечно, нужно любому программисту.
Но бывает (как у меня) совмещение ролей: сам создаешь программу и сам ей пользуешься. И вот при использовании, то есть при работе оператором, нужно искать не куски кода, а куски входящих/выходящих данных, и их уже не сотни файлов, а на порядок больше.
ovsale
18.07.2018 11:24я пишу в эклипсе и там есть удобный поиск по воркспейсу. а вот куски кода не попавшие в проект у меня лежат в tags4info и я их при необходимости нахожу без поиска. у меня есть тег «программирование: код» которым протегированы все что является кодом. иногда несколько фалов кода лежат в папке а папка протегирована.
я пытаюсь уйти от поиска к вложенным тегам. но поиск по коду конечно тегами не заменишь

ivan386
17.07.2018 21:21Я вот мечтаю о ссылках в исходниках. Чтоб кликнул на import и открылся этот файл или на вызов функции и открылся её исходник.
immaculate
18.07.2018 03:45Это уже есть в IDEA для многих языков. Поэтому я давно перешел на нее, хотя до этого был яростным противником IDE. Просто с какого-то момента стало понятно, что я значительную часть своего времени трачу на рутину, которая уже реализована в идее.
kvichans Автор
18.07.2018 11:00Это две разные по трудности задачи
- "Клик по import". Любой редактор с плагинами может дать команду "выделить из строки и открыть файл ". Например, в CudaText я себе это реализовал в одном из первых плагинов: нажимаю Ctrl+Shift+O и файл открывается.
- "Открыть исходник фукции". Это очень тяжелая задача, так как требует глубокого анализа "кто-где". Решено в серьезных IDE.
immaculate
Мне для сложных случаев проще использовать командую строку с ack-grep или аналогом (silversearcher, да много их). Если поиска в Idea недостаточно, то в командной строке я могу быстро набросать любую возможную комбинацию из find, ack, xargs, grep.
Мне это как-то проще, чем целиться мышкой в десятки чекбоксов.