
В интернете есть много статей о Sphinx, но, к сожалению, часть из них устарела, некоторые другие не претендуют на полный и точный how to. Так что в данном посте мы постарались изложить все шаги — установки, настройки, индексации и поддержке дельта индекса.

1. Установка Sphinx
Как уже было сказано Sphinx — это система полнотекстового поиска. Выбор на Sphinx пал не случайно, дело в том, что данная система является самой быстрой исходя из некоторых тестов сравнения скорости и возможностей движков подобных систем.
С документацией по установке все не так хорошо. Итак, для взаимодействия со Sphinx нам нужен — клиент MySQL (для работа с API Sphinx) и сам Sphinx. Ниже команды установки всех необходимых библиотек для Linux (в примере используется Linux Debian 8 64bit).
# Для установки клиента MySQL через apt-get прописываем необходимый репозиторий в /etc/apt/sources.list
deb http://repo.mysql.com/apt/debian/ wheezy mysql-5.6
deb-src http://repo.mysql.com/apt/debian/ wheezy mysql-5.6
# Установка клиента MySQL
apt-get install mysql-client unixodbc libpq5 libmysqlclient18
# Скачиваем последнюю версию Sphinx (на момент написания статьи 2.2.9)
wget http://sphinxsearch.com/files/sphinxsearch_2.2.9-release-1~wheezy_amd64.deb
# Устанавливаем
dpkg -i sphinxsearch_2.2.9-release-1~wheezy_amd64.deb
2. Настройка Sphinx
Если установка прошла нормально, то в Linux должен появится демон sphinxsearch, который пока можно остановить (
/etc/init.d/sphinxsearch stop). Далее нужно создать структуру каталогов для хранения индексов, в нашем случае их будет два — основной и дельта индекс. Основной хранит все данные, дельта только за сегодняшний день для ускорения индексации.mkdir /opt/sphinx
mkdir /opt/sphinx/data
# Основной индекс
mkdir /opt/sphinx/data/review
# Дельта индекс
mkdir /opt/sphinx/data/review_delta
# Логи
mkdir /opt/sphinx/log/
Редактируем конфигурацию Sphinx (по умолчанию /etc/sphinxsearch/sphinx.conf). Необходимо уточнить, что все отзывы хранятся в таблице review и индексируются поля:
- id — идентификатор отзыва;
- site_id — идентификатор сайта, на котором расположен отзыв;
- status — статус отзыва (Одобрен, На модерации, Спам, Удален);
- pros — достоинства;
- cons — недостатки;
- comment — комментарий.
# Базовая конфигурация источника, который будем индексировать (БД PostgreSQL)
source base {
type = pgsql
sql_host = 162.198.0.3
sql_user = postgres_login
sql_pass = postgres_password
sql_db = cackle
sql_port = 5179
}
# Базовая конфигурация индекса
index base {
# Кодировка
charset_type = utf-8
# Поддержка стемминга для Английских и Русских слов
morphology = stem_enru
# Минимальное слово для индексации 2 символа
min_word_len = 2
}
# Источник review наследованный от базовой конфигурации
source review : base {
# Перед индексацией очистить таблицу search_fulltext
# и вставить в неё максимальный id из таблицы review (данный id в search_fulltext нужен для дельта индекса)
sql_query_pre = DELETE FROM search_fulltext WHERE type = 'review'
sql_query_pre = INSERT INTO search_fulltext SELECT 'review', MAX(id) FROM review
# Индексируем поля id, site_id, status, pros, cons, comment из таблицы review
sql_query = SELECT id, site_id, status, pros, cons, comment FROM review
# Добавляем фильтр по идентификатору сайта
sql_attr_uint = site_id
# Добавляем фильтр по статусу отзыва (Одобрен, На модерации, Спам, Удален)
sql_attr_uint = status
}
# Индекс review наследованный от базовой конфигурации индекса работает с источником review
# и хранится в /opt/sphinx/data/review
index review : base {
source = review
path = /opt/sphinx/data/review
}
# Дельта источник наследованный от review
source review_delta : review {
# Так как не нужно, чтобы выполнялись sql_query_pre из родительской конфигурации источника review
# делаем обходной приём - вызов пустого SQL (SELECT 1)
sql_query_pre = SELECT 1
# Для индексации выбираем всё те же поля, но с id, которые больше чем id из таблицы search_fulltext
sql_query = SELECT id, site_id, status, pros, cons, comment FROM review WHERE id > (SELECT id FROM search_fulltext WHERE type = 'review')
}
# Дельта индекс
index review_delta : review {
source = review_delta
path = /opt/sphinx/data/review_delta
}
# Конфигурация демона searchd
# обязательно пропишите версию mysql (mysql_version_string = 5.5.21) без этого к клиенту было не подключится
searchd {
listen = localhost:9306:mysql41
mysql_version_string = 5.5.21
log = /opt/sphinx/log/searchd.log
query_log = /opt/sphinx/log/query.log
pid_file = /opt/sphinx/log/searchd.pid
}
3. Запуск
Все готово, можно запустить демона searchd (/etc/init.d/sphinxsearch start) и начать индексацию review (основной индекс):
indexer --config /etc/sphinxsearch/sphinx.conf review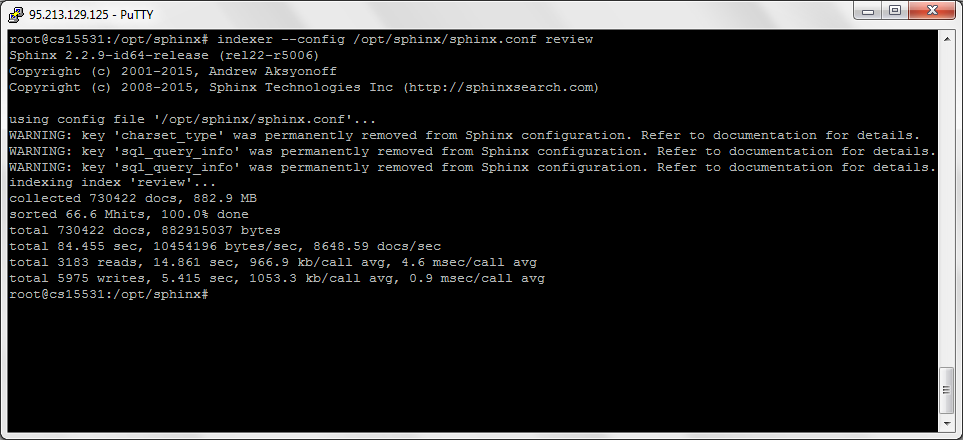
Итак, все 730422 отзыва были проиндексированы за 84 секунды. Теперь можно подключится к Sphinx через MySQL (mysql://localhost:9306) и попробовать поиск через SQL команды:
# Найти id отзывов на сайте с идентификатором 1 и текстом 'тест', сортировка на id, выборка от 0 до 15
SELECT id FROM review WHERE site_id = 1 AND MATCH('тест') ORDER BY id DESC LIMIT 0,15
# Найти id отзывов на сайтах с идентификаторами 1, 2, 738, 35302 и статусами 1 (одобрен), 3 (спам)
SELECT id FROM review WHERE site in (1, 2, 738, 35302) AND status in (1, 3) AND MATCH('хороший продукт')
ORDER BY id DESC LIMIT 0, 15
За несколько миллисекунд мы получим id отзывов, по которым далее можно сделать выборку из основной БД из таблицы review и вернуть результат клиенту.
4. Настройка дельта индекса
Как уже было сказано, дельта индекс нужен для быстрой индексации небольшого размера данных. В нашем случае это все новые отзывы накопленные за текущий день. Для данной настройки создаем в кроне 2 джобы:
crontab -e
# Каждые 5 минут запускаем индексацию review_delta (все отзывы id которых больше чем id из таблицы search_fulltext)
*/5 * * * * indexer --rotate --quiet --config /etc/sphinxsearch/sphinx.conf review_delta
# Раз в сутки (в час ночи) выполняем скрипт review_update.sh
0 1 * * * /opt/sphinx/review_update.sh
Скрипт review_update.sh запускает индексацию review_delta, обновляет максимальный id в таблице search_fulltext и мержит результат review и review_delta индексов.
PGPASSWORD=postgres_password;
export PGPASSWORD;
indexer --rotate --quiet --config /etc/sphinxsearch/sphinx.conf review_delta;
psql --host 162.198.0.3 --port 5179 --username "postgres_login" -c "UPDATE search_fulltext SET id = (SELECT MAX(id) FROM review) WHERE type = 'review'" "cackle";
indexer --merge review review_delta --rotate --quiet --config /etc/sphinxsearch/sphinx.conf;
После этого в SQL запросы поиска можно добавить таблицу review_delta и тогда выборка будет сразу из 2 индексов — основного и дельта.
# Найти id отзывов на сайте с идентификатором 1 и текстом 'тест', сортировка на id, выборка от 0 до 15
SELECT id FROM review, review_delta WHERE site_id = 1 AND MATCH('тест') ORDER BY id DESC LIMIT 0,15
# Найти id отзывов на сайтах с идентификаторами 1, 2, 738, 35302 и статусами 1 (одобрен), 3 (спам)
SELECT id FROM review, review_delta WHERE site in (1, 2, 738, 35302) AND status in (1, 3) AND MATCH('хороший продукт')
ORDER BY id DESC LIMIT 0, 15
Данная реализация заняла всего день работы, в итоге с помощью неё мы создали стабильный полнотекстовый поиск, который без единого сбоя работает уже несколько месяцев. Кстати, добавив подобную конфигурацию и джобу (review заменяется на comment) для системы комментирования Cackle Comments, был реализован поиск по комментариям.
Вопросы приветствуются. Спасибо за внимание. Всем успехов!
Комментарии (14)

fuCtor
05.07.2015 18:23+6Т.е. вы во так просто без тюнинга используете Sphinx? Никаких словарей, стоп слов и т.д. не подключаете?


igor_suhorukov
06.07.2015 08:19+1Рассматривали ли альтернативы Apache Solr или Elasticsearch при выборе?

e-commerce Автор
06.07.2015 11:31Solr да, так как у него уже готовый Java API, но начав разбираться, поняли, что там все как-то сложно (имхо).

DarkGenius
06.07.2015 09:20С каких ресурсов система извлекает отзывы? Как система определяет, является ли текст отзывом?
e-commerce Автор
06.07.2015 11:34+1Сбор отзывов происходит — от юзеров, с follow-up рассылки и Яндекс.Маркета. Про «Как система определяет» не совсем понимаю, мы просто индексируем весь текст отзыва — достоинства, недостатки и комментарий, хотели ещё и имя юзера индексировать, но потом поняли, что там могу быть проблемы.
DarkGenius
06.07.2015 11:59Вы можете извлечь достоинства и недостатки из отзыва, если они явно не размечены?

mtyurin
06.07.2015 13:26на max(id), если без лишних оговорок, имеем гонку — могут теряться некоторые документы

stalkerg
06.07.2015 14:39-1А при использовании Postgres можно обойтись встроенными функциями, что упрощает инфраструктуру.

amarao
Повторяюсь, но: «Какл» для русского уха крайне неблагозвучное название. Его стоит поменять на что-то менее ушеоскорбительное.
Solovej
Каждая статья сопровождается таким комментарием. Название у продукта нормальное, кому не нравится тот не использует.
Что то я не виду у народа особого рвения переименовывать наш геологический институт: ВСЕГЕИ
И что же теперь в хороший институт не идти если у него своеобразное сокращение?
Мы же IT-шники для нас главное качество продукта или на деле это не так?
amarao
А что мне делать, если в ленте постоянно появляется упоминание каклов? У «всегеи» название забавное, но не неблагозвучное. А тут чистой воды какофония, в буквальном и переносном смыслах.
Я всё жду, когда до руководства «какла» дойдёт, что быть «каклом» как-то неприлично и они-таки переименуются.
Blumfontein
Забавно, на сайте полное название значится «ВСЕРОССИЙСКИЙ НАУЧНО-ИССЛЕДОВАТЕЛЬСКИЙ ГЕОЛОГИЧЕСКИЙ ИНСТИТУТ им. А.П. КАРПИНСКОГО», что по логике вещей должно сокращаться как ВСЕНИГЕИ.