
В Индии есть местный аналог нашего ИНН — «адхар». К нему прикручена электронная система «еАдхар». В «еАдхаре» каждое письмо блокируется паролем. И всё бы хорошо, но пароль составляется по простому шаблону: первые четыре буквы имени капсом плюс год рождения.
Четыре заглавные буквы и четыре цифры. Из них можно составить 2 821 109 907 456 комбинаций. Если проверять тысячу комбинаций в секунду, на один пароль уйдёт лет девяносто.
Долговато. Может ускоримся в пару (миллиардов) раз?
92 года > 52 дня. Группируем
С тремя триллионами комбинаций мы чуть-чуть хватили лишнего. Всё-таки шаблон известен:
([A-Z][A-Z][A-Z][A-Z]) ([0–9][0–9][0–9][0–9])
(4 заглавные буквы) (4 цифры)
(Группа 1) (Группа 2)Если учесть этот шаблон, то строки вроде S2N65GE1 можно сразу отбросить. Сколько тогда получится комбинаций?
Первая группа — четыре буквенных символа. 26 вариантов, 4 позиции, получаем:
4 позиции по 10 цифр, аналогично:
Из этого получаем суммарное число комбинаций:
Прикинем, насколько быстрее теперь будет брутфорс. Снова исходим из 1000 попыток в секунду:
Или 52 дня, 21 час, 22 минуты и 40 секунд. Вместо 92 лет. Неплохо. Но всё равно долго. Что ещё можно сделать? То же самое — уменьшить количество комбинаций.
52 дня > 12 часов. Включаем здравый смысл
Первая и вторая группа — не случайный набор символов, а первые буквы имени и год рождения. Начнём с года рождения.
Подбирать пароли для родившихся в 1642 или 2594 смысла нет. Так что диапазон комбинаций можно смело уменьшить с 0000–9999 до 1918–2018. Так мы охватим плюс-минус всех ныне живущих в возрасте от 0 до 100 лет. Благодаря этому сокращается и число комбинаций, и время соответственно:
Или 12 часов, 41 минута и 37 секунд.
12 часов > 2 минуты. Жертвуем точностью
12 часов — это классно, но… We need to go deeper.
Сейчас у нас есть 45 миллионов комбинаций, которые точно покрывают всех пользователей «еАдхара». Но что если пожертвовать их малой долей ради прироста скорости?
Цифровые комбинации мы довели до совершенства. С буквами сделаем нечто подобное. Логика проста: нет года рождения 9999, и точно так же нет индийского имени c «AAAA» в начале. Но как определить все подходящие комбинации?

Я собрал индийские имена с сайта-каталога, в этом мне очень помог Photon. В итоге получилось 3 283 уникальных имени. Осталось обрезать первые четыре буквы и убрать дубликаты:
grep -oP ”^\w{4}” custom.txt | sort | uniq | dd conv=ucase
Получилось 1 598 префиксов! Дубликатов оказалось довольно много, потому что первые четыре буквы в таких именах как «Sanjeev» и «Sanjit» — одинаковые.
1 598 префиксов — маловато для полуторамиллиардного населения? Согласен. Но не забывайте, что это именно префиксы, а не имена. Я выложил получившийся список на Гист. На самом деле их должно быть больше. Можно заморочиться, собрать 10 000 имён с других сайтов и получить 3 000 уникальных префиксов, но у меня не было на это времени. Так что будем отталкиваться от 1 598.
Подсчитаем, сколько времени нужно теперь:
Или 2 минуты и 39.8 секунды.
2 минуты > 2 секунды. Википедия в помощь
2 минуты 40 секунд — это время, которое понадобится на перебор всех комбинаций. А что если одиннадцатая комбинация правильная? Или последняя? Или первая?
Сейчас перечень комбинаций отсортирован по алфавиту. Но это бессмысленно — кто сказал, что имена на «А» встречаются чаще, чем на «B», или что годовалых детей больше, чем семидесятилетних стариков?
Нужно учесть вероятность каждой комбинации. На Википедии пишут:
В Индии более 50% населения младше 25 лет и более 65% — младше 35.
Исходя из этого, вместо перечня 1–100 можно попробовать такой:
25–01 (в обратном порядке, потому что с возрастом выше шанс того, что у человека есть адхар)
25–35
36–100Тогда получается, что вероятность первых комбинаций возрастает до 50%. Мы взломали половину паролей за секунд! В следующие секунд, мы подберём ещё 15% паролей. Итого — 65% паролей за 55.9 секунды.
Теперь к именам.
В Гугле легко найти ТОП-100 имён любой страны. Исходя из данных по Индии, я передвинул соответствующие комбинации наверх списка. Будем считать, что 15% населения Индии носит популярные имена. Значит 15% паролей можно взломать практически мгновенно.
Индусы — 80% населения Индии. Значит, если поставить индуистские имена выше в списке, то это ускорит 80% попыток. После предыдущего шага у нас осталось попыток. Если из них 80% имён — индуистские, то 79% (оставляем 1% на популярные, но не индуистские имена) мы взломаем в следующие 65% попыток.
Посчитаем всё вместе, с учётом возрастной статистики. Разобьем на группы:
100: Общее количество {
50: от 00 до 25 лет {
7: популярные имена,
43: непопулярные имена {
34: индусы,
9: не индусы
}
}
15: от 26 до 35 лет {
3: популярные имена,
13*: непопулярные имена {
10: индусы,
3: не индусы
}
}
45: от 36 до 100 лет {
7: популярные имена,
38: непопулярные имена {
30: индусы,
8: не индусы
}
}
}Теперь сделаем эффективный алгоритм для взлома паролей:
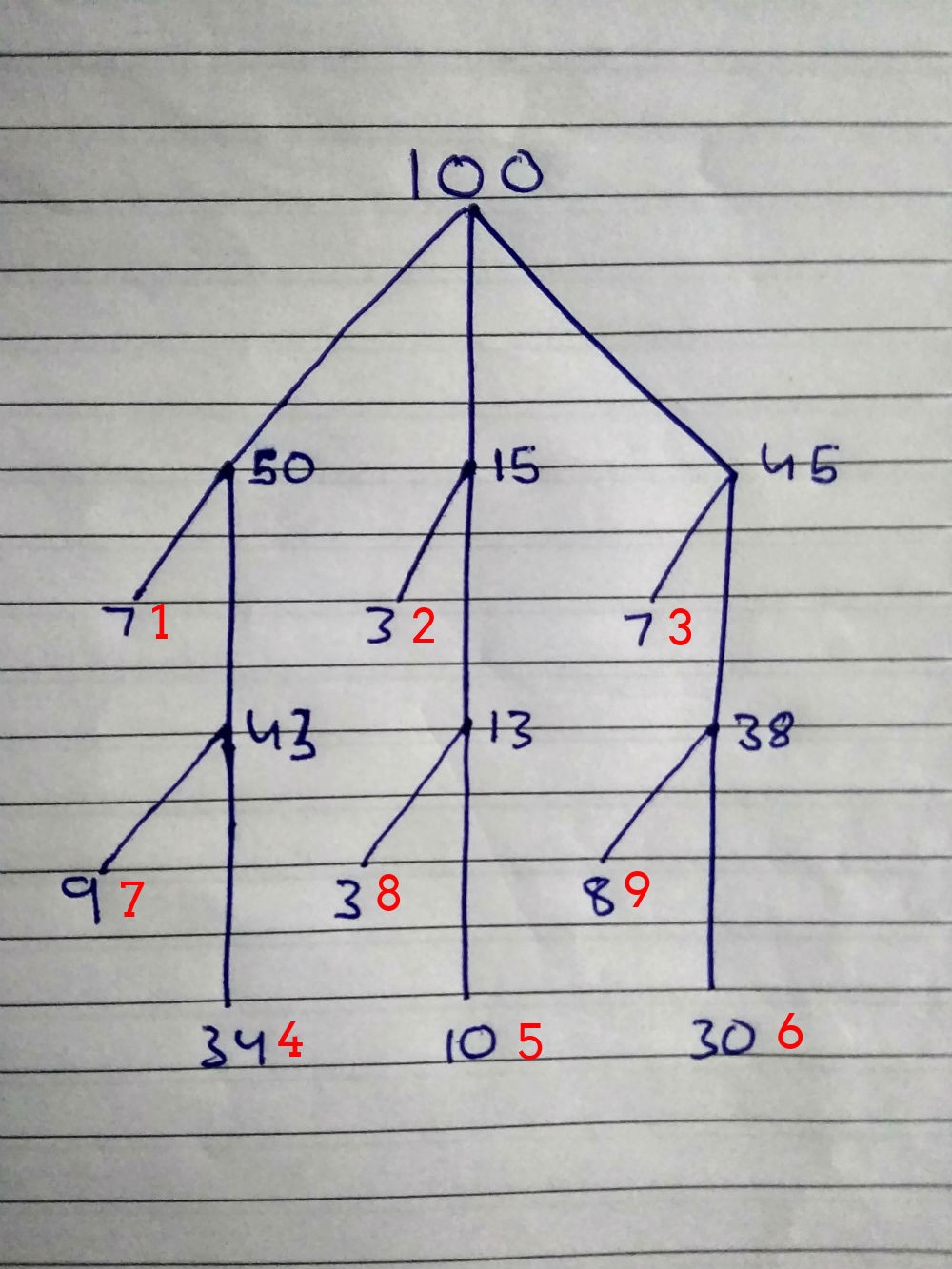
Красные числа — это поисковый приоритет. Комбинации для людей первой группы протестируем первыми, потом вторые, потом третьи и так далее.
Сколько теперь нужно времени для взлома?
Фаза №1
1 = 11 секунд для взлома 7 паролей
2 = 3 секунды для взлома 3 паролей
3 = 11 секунд для взлома 7 паролей
Мы взломали пароли 17 человек, осталось 83. Удалим предыдущие комбинации из списка и будем пробовать следующие наборы — 4, 5, 6.
Фаза №2
4 = 54 секунды для взлома 34 паролей
5 = 16 секунд для взлома 10 паролей
6 = 47 секунд для взлома 30 паролей
Снова удаляем комбинации предыдущих фаз.
Фаза №3
7 = 14 секунд для взлома 9 паролей
8 = 5 секунд для взлома 3 паролей
9 = 12 секунд для взлома 8 паролей
Суммарное время: секунды или 2 минуты и 13 секунд.
Взломанных паролей: 100
Среднее время для одного пароля: секунды.
92 года > 1.73 секунды. Ниче так, да?
Комментарии (58)

RedComrade
22.08.2018 23:16Раджит Кутропали говорит:«Святая корова!», если материал оригинальный — похвально, сам себе CTF
zzzmmtt
23.08.2018 10:21+2zanuda_mode_on Раджеш Кутраппали zanuda_mode_off
fireSparrow
23.08.2018 10:36+2Префикс всё равно «РАДЖ».
zzzmmtt
23.08.2018 10:38+1В кириллическом написании верно, если там латиница, то RAJI и RAJE — таки отличаются.
walkman7
23.08.2018 14:49Secret passwordRAJE1982Alek_roebuck
22.08.2018 23:35+1Очень впечатлили первые два шага. Сделаем дикую, абсурдную ошибку в исходном подсчёте, получим три триллиона комбинаций. Затем ошибку очевидным образом исправим — и вот мы получили всего 46 миллионов, какая титаническая работа!
Следующие пункты не читал, но позвольте угадать: вы посмотрели популярные имена, верно?atamanenko Автор
23.08.2018 00:08Либо автор просто добивался «вау-эффекта», как писал KennyGin ниже, либо пытался продемонстрировать, насколько большая разница в количестве комбинаций между случайным набором буквоцифр и шаблонным.
Следующие пункты не читал, но позвольте угадать: вы посмотрели популярные имена, верно?
Это перевод :)taujavarob
23.08.2018 22:12Это перевод :)
Редакторам Хабра 101 раз говорили как правильно сделать оформление переводной статьи. — Им что горохом об…
aamonster
22.08.2018 23:37/me не очень понял, как оный индус собирается брутфорсить 1000 паролей в секунду. Его что, сайт пароле эдак на третьем или пятом не заблокирует минут на пять?
А "пароль" из первых букв имени и года рождения — это вообще гордо :-). Если ломать конкретную учётку — брутфорс не нужен, просто зайти...
atamanenko Автор
23.08.2018 00:09Пароли на PDF-письмах, а не на сайте.

ris58h
23.08.2018 11:32Меня интересует вопрос: от кого вообще должен защитить этот пароль? От недобросовестного работника еАдхара? Почтового сервера/клиента? Соседа по индийской общаге?
Злоумышленник же сперва должен это письмо как-то получить.
Автора спросили об этом в комментариях. Его ответ в моём вольном переводе:
1. Множество этих файлов проиндексировано гуглом.
2. А что если сервер взломают?
Но это проблема безопасного хранения, на мой взгляд.
KennyGin
22.08.2018 23:37+1Какая забавная статья.
Берётся исходная задача «Перебрать комбинации из первых четыре буквы имени капсом плюс год рождения». Дальше число этих комбинаций грубейшим образом оценивается сверху как "Всевозможные комбинации из четырёх заглавных букв и четырёх цифр".
Получаем исполинские 92 года на перебор. Дальше за два шага просто возвращаемся к исходной задаче, и вот мы уже сократили перебор до 12 часов. Дешёвый ВАУ-эффект обеспечен!
P.S. К оставшимся двум шагам оптимизации претензий нет, путь это и довольно тривиальные вещи. Но ведь «12 часов -> 2 секунды» это совсем не так круто как «92 года -> 2 секунды», да?..atamanenko Автор
23.08.2018 00:19Мне кажется, главную задачу своего вау-эффекта автор достиг — пост подлил масла в и так большой огонь вокруг дырявости еАдхара. Там куча проблем, уже и петицию организовали по этому поводу.

denis-19
23.08.2018 07:02Годы и секунды это замечательно. Как и regular expressions.
Константы для первого, которые всегда лучше помнить.
Год — 8760 часов, 31 536 000 секунд.
Один миллион секунд — 11,5 суток.
Один миллиард секунд — 31 и ? лет.
Один триллион секунд — 31?710 лет.TimsTims
23.08.2018 11:02+1Редко, когда нужно считать года в секундах, но даже если это использовать в коде, то читающий код ничего бы не понял, откуда взялась константа 31536000. Я бы написал более менее явно: 60*60*24*365. Уж что-что, а 24 и 365 обычного человека подтолкнут на мысль, что это время. Ну и опять-же 31536000 в отличии от 86400 вовсе не константа, а зависит от високосности года…
Fortop
23.08.2018 15:28+1И даже 86400 не константа
Дополнительная секундаalexeykuzmin0
23.08.2018 15:40Смотря в какой предметной области. Если мне система нагрузочного тестирования пишет «тест выполнялся 1 сутки, 2 часа 3 минуты 4 секунды», то я ожидаю, что продолжительность суток — константа.
yurisv3
23.08.2018 09:10Уже с первого взгляда бросаются в глаза две большие лажи:
1) Индийский ИНН — это PAN, а не Aadhaar.
2) Aadhaar — это БИОМЕТРИЧЕСКИЙ личный ID.
Примитивный пароль точно соответствует «ценности» закрытого им PDF. Который просто ваша копия, исключительно для удобства — точно такую же может невозбранно сделать ЛЮБОЙ, тупо сфотографировав или отсканировав оригинал (саму карточку).
Практическая ценность этой копии для левого человека равна НУЛЮ, ибо персональные БИОМЕТРИЧЕСКИЕ данные лежат в центральной базе. Доступа к которой собственно карточка никак не дает.
Зачем вообще там (ПДФ) пароль? А фиг его знает. Чисто «для порядка». Тут так принято.DimaTiunov
23.08.2018 09:35Будет слив баз связанных с этой, будет смысл)
yurisv3
23.08.2018 12:02Хахаха, имея копию базы биометрии — можно сгенерировать сколько угодно ВАЛИДНЫХ Aadhaar ID, на любые входные персональные данные (ФИО/адрес), и никаких «запароленных» PDF для этого не надо.
Так в в чем «будет смысл»? — раскройте пожалуйста.
tangro
23.08.2018 10:48Кому-то же в голову пришло пароль делать по такому вот паттерну. И на всём пути разработки архитектуры, кода, приёмки, внедрения никто не встал и не сказал «да это же бред!». Наверное, «кого надо» фирма делала и протестовать было нельзя.
ris58h
23.08.2018 11:29+2Когда получал визу в Финляндию, тоже получал зашифрованный PDF. Пароль: первые четыре символа номера паспорта + дата рождения.
Link
Open PDF attachment (using 4 characters of Passport Number + Date Of Birth (ddmmyyyy) as entered in the online visa application form)
Предлагаю поломать!
vlivyur
23.08.2018 12:28Только если номер паспорта был указан с пробелом, я так и не смог подобрать пароль. Там где-то про пробел было упомянуто, но ни с ним, ни без него не получалось.
ris58h
23.08.2018 12:48Для просмотра и печати визовой анкеты, пожалуйста, используйте пароль в формате, указанном ниже:
Первые 4 цифры номера паспорта+ дата рождения(ддммггг), как указано в визовой анкете
— Если Вы ввели номер паспорта в следующем формате: 72 1234567 и дату рождения: 01.01.1990, пожалуйста, используйте пароль: 72 101011990, чтобы открыть PDF.
— Если Вы ввели номер паспорта в следующем формате: 721234567 и дату рождения: 01.01.1990, пожалуйста, используйте пароль: 721201011990, чтобы открыть PDF.vlivyur
23.08.2018 14:13Вот-вот. Именно в таком виде у меня и не сработало. И первые четыре символа и первые четыре цифры с пробелами и без пробелов никак не распознавались как валидные (72 1, 72 12, 7212 не подходили). А если в анкете без пробела указывать, то всё хорошо.
Arty_Fact
23.08.2018 15:29У меня принял «3 2 3 4 23313», «DF23 124531», " 1 2 3 4". Символы не принимает. А вот пробелы и буквы в любом порядке.
Arty_Fact
23.08.2018 12:54А можно указать номер паспорта в любом формате, например " ## # # ######" и тогда первыми символами пароля будет пара пробелов. Но не помню, есть ли валидация на введенные символы в это поле, возможно, туда можно надолбить что угодно, в том числе и непечатные символы. Тогда забрутить будет крайне сложно.
Zencaster
23.08.2018 11:45100: Общее количество {
50: от 00 до 25 лет
15: от 26 до 35 лет
45: от 36 до 100 лет
}
итого 110?atamanenko Автор
23.08.2018 11:46О, спасибо, даже не заметил. Там, очевидно, 35 вместо 45 должно было быть.
UPD: Хотел исправить, но у автора всё подогнано под 45. То ли я чего-то неправильно понял, то ли он всё-таки ошибся.Yuretz85
23.08.2018 15:09Скорей всего, потому как он писал что 65% это люди до 35 лет, соответственно остальные 35% — это люди от 36 лет
celebrate
23.08.2018 17:29Как обладатель Aadhar карты, я не очень понимаю, как можно воспользоваться полученным номером. Это все равно, что в России получить список всех ИНН. Ну получили и что дальше?
И вообще говоря, при использовании Аадхар карты там надо предоставлять отпечаток своего пальца.
hippohood
23.08.2018 18:04+1Мне всегда было интересно насколько случайны биометрические пароли. То есть, допустим отпечаток пальца позволяет снять 15 параметров некоторые принимают 10 значений (от балды цифры). Вот вам полтриллиона возможных значений. Но как бы очевидно что они распределены сильно неравномерно и почти наверняка не независимы. Наверняка какая-то хэш функция делает на это поправку, растягивая поле значений там где они кучкуются, и, соответсвенно, сжимает для редких комбинаций. Но насколько эффективно она работает зависит от использованной выборки отпечатков пальцев. Возможно в Силиконовой долине использовали местную полицейскую БД для определения как распределены измеряемые параметры. Тогда весьма вероятно что алгоритм хорошо различает отпечатки пальцев афроамериканцев и латиноамериканцев, но шведы для нее все на одно "лицо" и для многих шведов она генерирует один и тот же хэш. Знающий хакер может написать таргетирванный червь, который будет подбирать хэш исходя из дополнительной информации (место проживания, раса, национальность, родственники) и будет удаленно ломать большой процент биометрик, просто потому что будет часто натыкаться на кластеры родственников, чьи биометрики неразличимы для алгоритма распознавания.
Это уже известная проблема в распознавании лиц (азиаты все на одно лицо для калифорнийских алгоритмов) и наоборот.alexeykuzmin0
23.08.2018 18:25У биометрических систем свои минусы есть. Например, сложно пароли менять в случае утечки.
hippohood
23.08.2018 21:41Так и я о недостатках. У них недостаток еще в то что их можно без вашего ведома скопировать — в недалеком будущем даже с фотографии например. Но я о том что мне еще кажется что их устойчивость к перебору можно сильно
Sabubu
Это известная особенность, что естественные идентификаторы (имена, фамилии итд) легко перебираются. То же самое, если зашехировать имя или телефон — их легко восстановить, так как их очень ограниченное количество.
atamanenko Автор
Печально, что такие слабые пароли используют для доступа к чувствительной информации. Ещё и в масштабе практически всего населения
Mike_soft
не зря ж есть понятие «индусский код»
Zet_Roy
Только данные отсталой страны никому ненужны.
TimsTims
Ошибаетесь. Индия многим людям видится как один из самых крупнейших и перспективных рынков сбыта всего чего угодно. Там много бедных людей, но и ещё больше богатых, их в больше, чем в других странах.
scruff
Ошибаетесь. Возьмите тех же сетевиков или архитекторов — да их поболее будет чем любой другой рассы, ну может китайцы еще где-то рядом. Но если взять то количесвто специалистов и поделить на общее количество жителей страны — вот тогда действительно печалька.
bask
Я однажды смотрел интервью с одним болливудским известным актёром. Его спросили: «Почему бы вам не поехать сниматься в Голливуде?». Он ответил: «А зачем? Здесь, в Индии, меня смотрит миллиард зрителей, а в Голливуде меня покажут меньше чем 500 млн»
ICELedyanoj
Это известная проблема с государственными органами. Часто любые, даже самые благие начинания, сталкиваются с ленью на местах.
Живой пример. Украинская налоговая выдаёт каждому человеку свой собственный ИНН. Кроме этого внедрены цифровые сертификаты, которые могут быть использованы человеком в качестве цифровой подписи. Например — при получении кредита, или сдаче налоговых документов онлайн.
И переходим к смешному моменту. Налоговая выдаёт человеку сертификат на диске, при этом пароль к этому сертификату уже установлен (и, довольно часто, написан маркером на конверте с диском). И угадайте с трёх раз что это за пароль? Я опросил нескольких знакомых — у всех одно и то же. В качестве пароля налоговая использует ИНН, который является открытой информацией.
Понятно, что сертификат можно перевыпустить онлайн. Понятно, что пароль нельзя использовать без сертификата. Тем не менее — вот такая безопасность.
saipr
А у нас что по-другому?
Это как? Не в смысле техники, а юридически!
Но если есть доступ по сертификату, зачем нужен пароль? Почему просто не использовать сертификаты и забыть про пароли!
alexeykuzmin0
А с телефоном-то что не так? Их в России пара сотен миллионов