
Поиск ассоциативных правил хорошо известный метод анализа данных. На Хабре уже была публикация с историей вопроса об этом методе и общими определениями. В этой статье пойдет речь об адаптации алгоритма поиска ассоциативных правил в данных полученных опросами респондентов. Результаты работы алгоритма продемонстрированы на данных европейского социального исследования (ESS).

Foto: Owen Humphreys/AP
Под результатами опроса понимается база ответов респондентов на вопросы исследования. Характер исследования — социологический, маркетинговый или любой другой, для последующего анализа не имеет значения. Помимо ESS, с примерами различных исследований можно ознакомиться на сайтах ВЦИОМ, Левада-Центр, TNS Russia и множества других организаций.
Особенностью опросов является то, что транзакции в исследовании не обязательно равновероятны. Как правило, у респондентов в исследовании определены веса. Алгоритм Apriori, в реализации Christian Borgelt (версия 6.18), позволяет использовать целочисленные положительные веса транзакций, которые определяют их кратность.
Исходные файлы этой программы находятся в открытом доступе. Небольшие изменения в ее коде позволяют определять положительные вещественнозначные веса транзакций в алгоритме поиска ассоциативных правил.
ESS — проект по измерению установок, представлений, мнений и поведения населения более 30 европейских стран. На сайте проекта выложены в открытый доступ методология и результаты опросов. В примерах использованы данные 6 волны (редакция 2.1).
Постановка задачи.
Пусть для анализа выбрана некоторая группы стран C, например, C = {Дания, Россия, Франция}.
Требуется на основе данных ESS выявить те признаки, доли которых для одной из стран C значительно превосходят доли этого признака в остальных странах C.
Подготовка данных.
Правило X -> Y должно показывать, что признак X более характерен для представителей страны Y.
Пусть веса респондентов ESS опроса (переменная dweight) представлены следующим образом: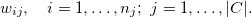 Здесь индекс j определяет страну, а индекс i перечисляет респондентов j-ой страны.
Здесь индекс j определяет страну, а индекс i перечисляет респондентов j-ой страны.
Нам требуется нормировать веса таким образом, чтобы сумма весов респондентов для каждой страны из C равнялась 100, то есть

При таком определении весов поддержка правила supp(X -> Yj) определяет долю признака X в стране Yj.
Поддержка признака X равна сумме долей этого признака по всем странам из C: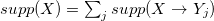 .
.
Тогда достоверность правила X -> Yj — это отношения доли признака X в стране Yj к сумме долей X по всем странам из C.
Данные опроса были загружены в среду R с помощью пакета foreign.
Ответы респондентов на общие для стран вопросы были конвертированы в базу транзакций с использованием пакета arules.
Нахождение и визуализация решения задачи.
При нахождении правил использовались следующие ограничения:
1) Правая часть Y, в правиле X -> Y, содержит только данные о стране;
2) Левая часть X состоит не более чем из 2 элементов (утверждений);
3) Минимально допустимые значения поддержки и достоверности правила — 3% и 2/3*100% соответственно.
Как известно, число полученных ассоциативных правил может быть достаточно большим. Для удобства отображения решения был использован сервис Tableau Public, который позволяет создавать панели управления визуализации данных.
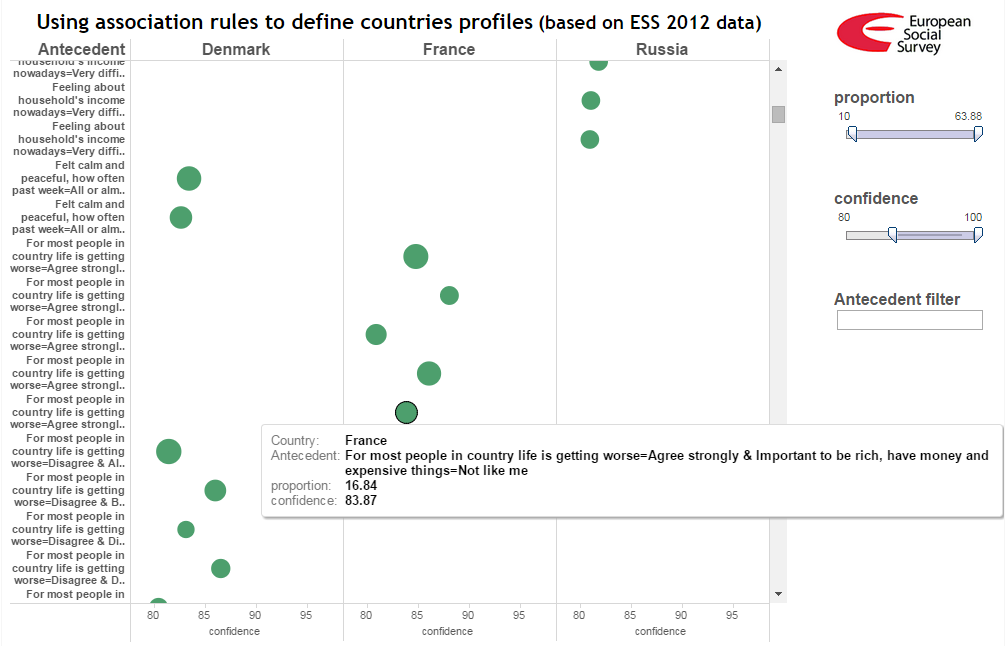
Выделенное правило сообщает, что около 17% жителей Франции, достигших 15 летнего возраста:
— полностью согласны с утверждением, что для большинства жителей страны жизнь становиться скорее хуже, чем лучше
и
— не олицетворяют себя с человеком, для которого важно быть богатым, иметь много денег и дорогие вещи.
Уровень достоверности этого правила высокий — 84 %. Он показывает, что суммарные доли респондентов, ответивших в точности так же в Дании и России, более чем в 5 раз меньше 17% (так как 0.84 / 0.16 > 5).
Вычислим левую часть X этого правила по каждой стране в отдельности. Получаем следующие результаты

Кому интересно посмотреть на получившиеся правила самостоятельно, могут пройти по этой ссылке.
Что касается маркетинговых опросов. По их результатам, например, можно проводить поиск правил в группах лояльных потребителей различных марок товаров одного вида. В этом случае производитель марки N выявляет особенности «своих» покупателей и получает информацию об отличительных характеристиках потребителей, предпочитающих продукцию конкурентов.
Поиск ассоциативных правил в базе взвешенных транзакций позволяет решать задачи разведочного анализа данных полученных опросами респондентов. Этот метод обнаруживает характерные события опираясь на их точечные значения (доли). В следующей части статьи будут рассмотрены способы статистической оценки этих результатов.
Foto: Owen Humphreys/AP
Под результатами опроса понимается база ответов респондентов на вопросы исследования. Характер исследования — социологический, маркетинговый или любой другой, для последующего анализа не имеет значения. Помимо ESS, с примерами различных исследований можно ознакомиться на сайтах ВЦИОМ, Левада-Центр, TNS Russia и множества других организаций.
Определения и примеры ассоциативных правил
Термин транзакция, применительно к опросам, означает набор ответов на вопросы исследования, полученные от одного респондента. Пример транзакции в опросе: Пол = Женский, Образование = Высшее, Семейное положение = Не замужем,….
Количественные переменные в опросе зачастую бывают представлены в виде сегментов: Возраст = 18-25, Объем потребления прохладительных напитков за последние 6 мес. = 5-10 литров.
Таким образом, всевозможные ответы на вопросы исследования определяют конечное множество I, а данные опроса представляют собой набор транзакций D, число которых равно числу респондентов исследования.
Пусть A — некоторое непустое подмножество I. Число транзакций из D, содержащих все элементы из A, называется поддержкой A и обозначается supp(A).
Ассоциативное правило X -> Y, это пара непересекающихся подмножеств X, Y из множества I. Две основные характеристики правила X -> Y — его поддержка и достоверность:
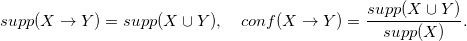
Пример ассоциативного правила Возраст = 55+ -> Социальный статус = Пенсионер. Его поддержка 0.3 означает, что 30 % респондентов исследования имеют возраст не менее 55 лет и являются пенсионерами. Достоверность правила 0.7 показывает, что среди респондентов исследования в возрасте не менее 55 лет 70 % являются пенсионерами.
Количественные переменные в опросе зачастую бывают представлены в виде сегментов: Возраст = 18-25, Объем потребления прохладительных напитков за последние 6 мес. = 5-10 литров.
Таким образом, всевозможные ответы на вопросы исследования определяют конечное множество I, а данные опроса представляют собой набор транзакций D, число которых равно числу респондентов исследования.
Пусть A — некоторое непустое подмножество I. Число транзакций из D, содержащих все элементы из A, называется поддержкой A и обозначается supp(A).
Ассоциативное правило X -> Y, это пара непересекающихся подмножеств X, Y из множества I. Две основные характеристики правила X -> Y — его поддержка и достоверность:
Пример ассоциативного правила Возраст = 55+ -> Социальный статус = Пенсионер. Его поддержка 0.3 означает, что 30 % респондентов исследования имеют возраст не менее 55 лет и являются пенсионерами. Достоверность правила 0.7 показывает, что среди респондентов исследования в возрасте не менее 55 лет 70 % являются пенсионерами.
Особенностью опросов является то, что транзакции в исследовании не обязательно равновероятны. Как правило, у респондентов в исследовании определены веса. Алгоритм Apriori, в реализации Christian Borgelt (версия 6.18), позволяет использовать целочисленные положительные веса транзакций, которые определяют их кратность.
Исходные файлы этой программы находятся в открытом доступе. Небольшие изменения в ее коде позволяют определять положительные вещественнозначные веса транзакций в алгоритме поиска ассоциативных правил.
ESS — проект по измерению установок, представлений, мнений и поведения населения более 30 европейских стран. На сайте проекта выложены в открытый доступ методология и результаты опросов. В примерах использованы данные 6 волны (редакция 2.1).
Постановка задачи.
Пусть для анализа выбрана некоторая группы стран C, например, C = {Дания, Россия, Франция}.
Требуется на основе данных ESS выявить те признаки, доли которых для одной из стран C значительно превосходят доли этого признака в остальных странах C.
Подготовка данных.
Правило X -> Y должно показывать, что признак X более характерен для представителей страны Y.
Пусть веса респондентов ESS опроса (переменная dweight) представлены следующим образом:
Здесь индекс j определяет страну, а индекс i перечисляет респондентов j-ой страны. Нам требуется нормировать веса таким образом, чтобы сумма весов респондентов для каждой страны из C равнялась 100, то есть
При таком определении весов поддержка правила supp(X -> Yj) определяет долю признака X в стране Yj.
Поддержка признака X равна сумме долей этого признака по всем странам из C:
.Тогда достоверность правила X -> Yj — это отношения доли признака X в стране Yj к сумме долей X по всем странам из C.
Данные опроса были загружены в среду R с помощью пакета foreign.
Ответы респондентов на общие для стран вопросы были конвертированы в базу транзакций с использованием пакета arules.
Нахождение и визуализация решения задачи.
При нахождении правил использовались следующие ограничения:
1) Правая часть Y, в правиле X -> Y, содержит только данные о стране;
2) Левая часть X состоит не более чем из 2 элементов (утверждений);
3) Минимально допустимые значения поддержки и достоверности правила — 3% и 2/3*100% соответственно.
Как известно, число полученных ассоциативных правил может быть достаточно большим. Для удобства отображения решения был использован сервис Tableau Public, который позволяет создавать панели управления визуализации данных.
Выделенное правило сообщает, что около 17% жителей Франции, достигших 15 летнего возраста:
— полностью согласны с утверждением, что для большинства жителей страны жизнь становиться скорее хуже, чем лучше
и
— не олицетворяют себя с человеком, для которого важно быть богатым, иметь много денег и дорогие вещи.
Уровень достоверности этого правила высокий — 84 %. Он показывает, что суммарные доли респондентов, ответивших в точности так же в Дании и России, более чем в 5 раз меньше 17% (так как 0.84 / 0.16 > 5).
Вычислим левую часть X этого правила по каждой стране в отдельности. Получаем следующие результаты
Кому интересно посмотреть на получившиеся правила самостоятельно, могут пройти по этой ссылке.
Что касается маркетинговых опросов. По их результатам, например, можно проводить поиск правил в группах лояльных потребителей различных марок товаров одного вида. В этом случае производитель марки N выявляет особенности «своих» покупателей и получает информацию об отличительных характеристиках потребителей, предпочитающих продукцию конкурентов.
Поиск ассоциативных правил в базе взвешенных транзакций позволяет решать задачи разведочного анализа данных полученных опросами респондентов. Этот метод обнаруживает характерные события опираясь на их точечные значения (доли). В следующей части статьи будут рассмотрены способы статистической оценки этих результатов.