
В крупных сервисах решить какую-нибудь задачу с помощью машинного обучения — означает выполнить только часть работы. Встраивать ML-модели не так уж просто, а налаживать вокруг них CI/CD-процессы еще сложнее. На конференции Яндекса «Data & Science: программа по заявкам» руководитель направления data science в компании YouDo Адам Елдаров рассказал о том, как управлять жизненным циклом моделей, настраивать процессы дообучения и переобучения, разрабатывать масштабируемые микросервисы, и о многом другом.
— Начнем с вводных. Есть data scientist, он в Jupyter Notebook пишет какой-то код, делает фиче-инжениринг, кросс-валидацию, тренирует модельки. Скор растет.

Но в какой-то момент он понимает: чтобы принести компании business value, он должен заделиверить решение куда-то в продакшен, в некий мифический продакшен, который вызывает у нас кучу проблем. Ноутбук, который мы пилили, в продакшен в большинстве случаев не отправить. И возникает вопрос: как этот код внутри ноутбука отгрузить в некий сервис. В большинстве случаев надо написать сервис, у которого есть API. Или они общаются через PubSub, через очереди.

Когда мы делаем рекомендации, нам надо часто обучать модели и переобучать их. Этот процесс надо мониторить. При этом надо всегда проверять тестами и сам код, и модели, чтобы в один момент наша модель не сошла с ума и не начала всегда предиктить нолики. Еще это нужно проверять на реальных пользователях через АB-тесты — что мы сделали лучше или как минимум не хуже.
Как мы подходим к коду? У нас GitLab. Весь наш код распиливается на много маленьких библиотек, которые решают конкретную доменную задачу. При этом это отдельный GitLab-проект, Git-контроль версий и модель ветвления GitFlow. Мы используем такие штуки, как pre-commit hooks — чтобы нельзя было закоммитить код, который не удовлетворяет нашим проверкам на стат-тесты. И сами тесты, юнит-тесты. Используем для них подход property based testing.

Обычно, когда вы пишите тесты, то подразумеваете, что у вас есть тестируемая функция и аргументы, которые вы руками создаете, некие примеры, и то, какие значения возвращает ваша тестируемая функция. Это неудобно. Код раздувается, многим в принципе лень это писать. В результате у нас куча кода, непокрытого тестами. Property based testing подразумевает, что все ваши аргументы имеют некое распределение. Давайте будем делать фазинг, и много раз семплировать из этих распределений все наши аргументы, вызывать с этими аргументами тестируемую функцию и проверять на некие свойства результат выполнения этой функции. В результате у нас кода гораздо меньше, и при этом тестов в разы больше.
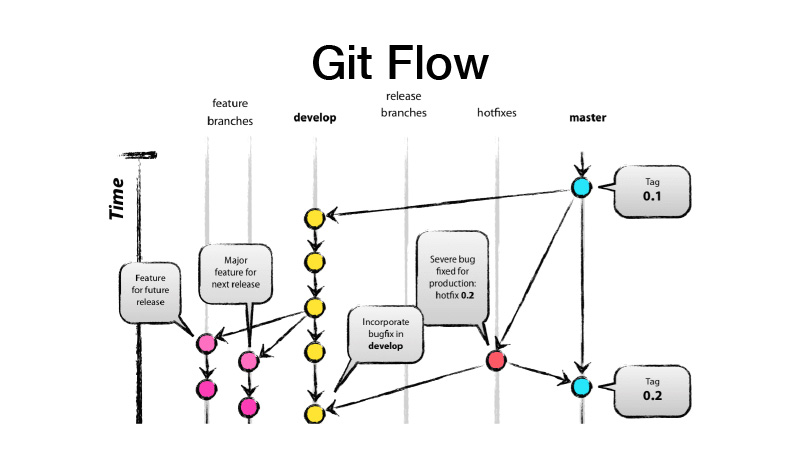
Что такое GitFlow? Это модель ветвления, которая подразумевает, что у вас есть две основные ветки — develop и master, где находится production ready-код, а вся разработка при этом ведется в ветке develop, куда все новые фичи попадают из фиче-бранчей. То есть каждая фича — новый фиче-бранч, при этом фиче-бранч должен быть короткоживущим, а по хорошему — еще и прикрытым через feature toggle. Мы потом делаем релиз, из dev перекидываем изменения в master и вешаем на это тег версии нашей библиотеки или сервиса.
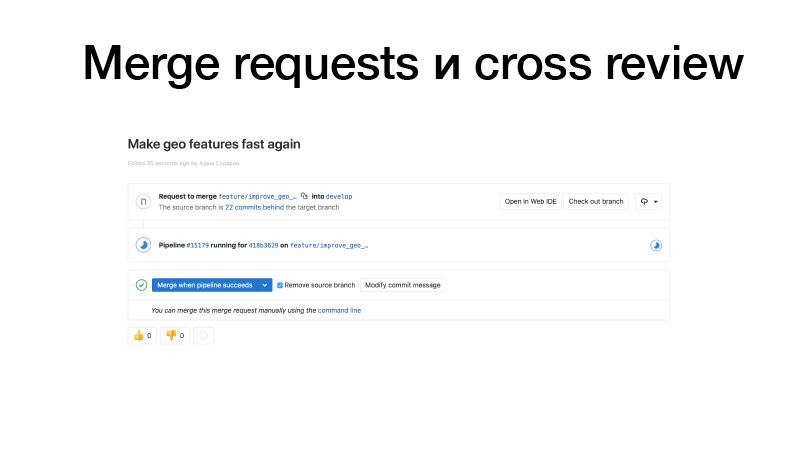
Делаем разработку, пилим какую-то фичу, пушим ее на GitLab, создаем merge request из фиче-бранча в дев. Срабатывают триггеры, прогоняем тесты, если все окей — можем замержить. Но мержим не мы, а кто-то из команды. Он ревьюит код, и тем самым повышается bus factor. Данный участок кода знают уже два человека. В результате — если кого-то собьет автобус, кто-то уже знает, что он делает.

При этом Continuous integration для библиотек обычно выглядит как тесты на любые изменения. И если мы релизим, это еще и паблишинг в приватный PyPI-сервер нашего пакета.
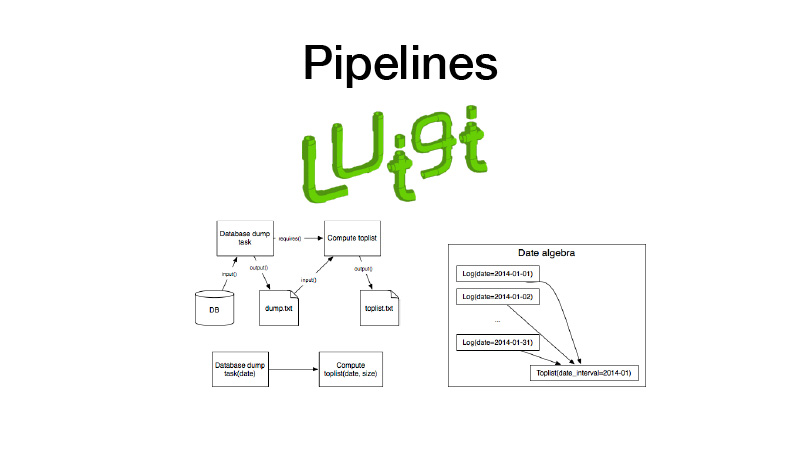
Далее мы это можем собрать в пайплайны. Для этого мы используем библиотеку Luigi. Она работает с такой сущностью, как таска, у которой есть аутпут, куда сохраняется артефакт, созданный во время выполнения таски. Есть параметр таски, который параметризует бизнес-логику, которую она выполняет, идентифицирует таску и ее аутпут. При этом у таски всегда есть требования, которые выставляют другие таски. Когда мы запускаем какую-то таску, все ее зависимости проверяются через проверку ее аутпутов. Если аутпут существует, наша зависимость не запускается. Если артефакт отсутствует на каком-то storage, он запускается. Тем самым формируется пайплайн, направленный циклический граф.
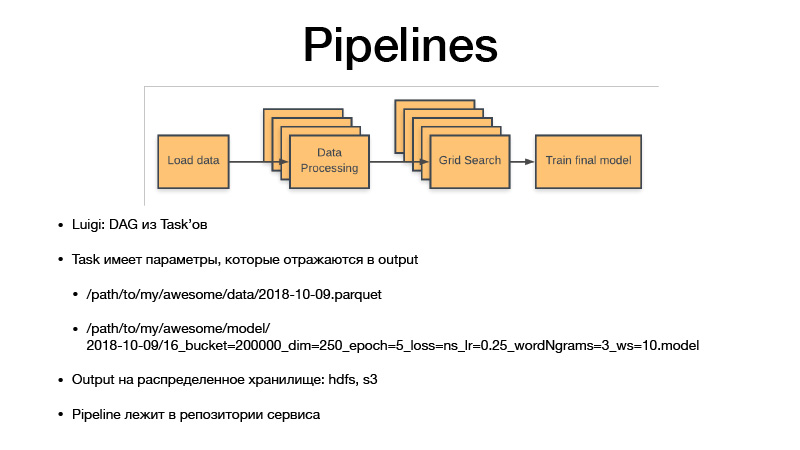
Все параметры идентифицируют бизнес-логику. При этом они идентифицируют артефакт. Всегда это дата с какой-то гранулярностью, сенситивностью, либо неделя, день, час, три часа. Если мы обучаем какую-то модельку, Luigi таска всегда имеет гиперпараметры этой таски, они просачиваются в артефакт, который мы продюссируем, гиперпараметры отражены в названии артефакты. Тем самым мы по сути версионируем все промежуточные дата-сеты и конечные артефакты, и они не перезаписываются никогда, всегда upend only на storage, и storage выступает HDFS и S3 приватный, который конечные артефакты видит пиклов каких-то, моделей или еще чего-то. И весь код пайплайна лежит в проекте сервиса в репозитории, к которому он относится.

Это надо как-то задеплоить. На помощь к на приходит HashiCorp стек, мы используем Terraform для декларирования инфраструктуры в виде кода, Vault для менеджмента секретов, там все пароли, явки к БД. Consul — сервис discovery, распределенный key value storage, который можно использовать для конфигурирования. И также Consul делает health checks ваших нод и ваших сервисов, проверяя их на доступность.
И — Nomad. это система оркестрации, шедулирования ваших сервисов и каких-то batch jobs.
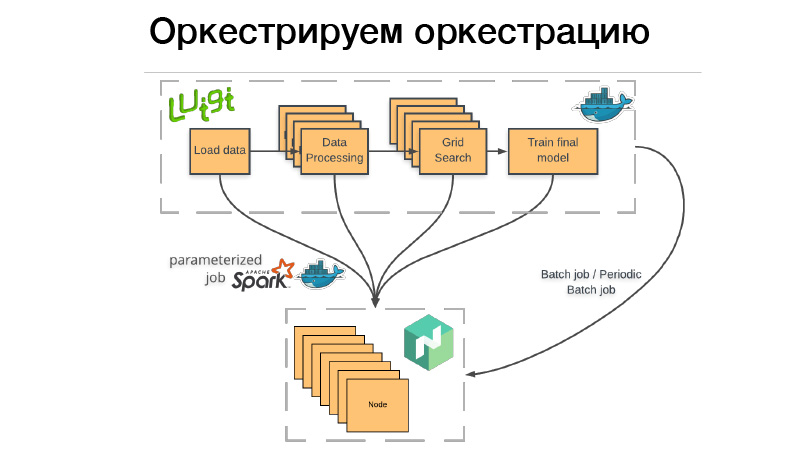
Как мы это используем? Есть Luigi пайплайн, мы его запакуем в Docker контейнер, бросаем в Nomad батч или periodic batch job. Batch job — это что-то выполнилось, закончилось, и если все удачно — все окей, мы можем вручную затриггерить его снова. Но если что-то произошло не так, Nomad ретраит это, пока не исчерпает попытки, либо это не закончится успешно.
Periodic batch job — это ровно то же самое, только работает по расписанию.
Тут появляется проблема. Когда мы деплоим какой-то контейнер в систему оркестрации любую, надо указать, сколько надо памяти этому контейнеру, CPU или памяти. Если у нас пайплайн, который работает три часа, два часа из этого потребляет 10 Гб оперативной памяти, 1 час — 70 Гб. Если мы превышаем лимит, который мы ему выдали, Docker daemon приходит и убивает Dockers и (нрзб.) [02:26:13] Мы не хотим out of memory ловить постоянно, поэтому нам надо указать все 70 Гб, пиковую нагрузку на память. Но тут проблема, все 70 Гб на три часа будут аллоцированы и недоступны ни одной другой джобе.
Поэтому мы пошли другим путем. Весь наш Luigi пайплайн не запускает в себе какую-то бизнес-логику, он запускает просто набор кубиков в Nomad, так называемые параметризованные джобы. По сути, это аналог Server (нрзб.) [02:26:39] functions, AVS Lambda, кто знает. Когда мы делаем библиотеку, мы деплоим через CI весь наш код в виде параметризованных джоб, то есть контейнер с какими-то параметрами. Допустим, Lite JBM Classifier, у него есть параметр пути к входным данным для тренировки, гиперпараметры моделей и пути к выходным артефактам. Все это регистрируется в Nomad, и далее из Luigi пайплайна можем через API дергать все эти Nomad джобы, и при этом Luigi следит за тем, чтобы не запускать одну и ту же таску много раз.
Допустим, у нас процессинг текста всегда одинаковый. Есть условные 10 моделей, и мы не хотим каждый раз заново запускать процессинг текста. Он запустится всего один раз, и при этом будет готовый результат каждый раз переиспользоваться. И при этом все это работает распределенно, мы можем гигантский grid search запустить на большом кластере, успевай только железо докидывать.
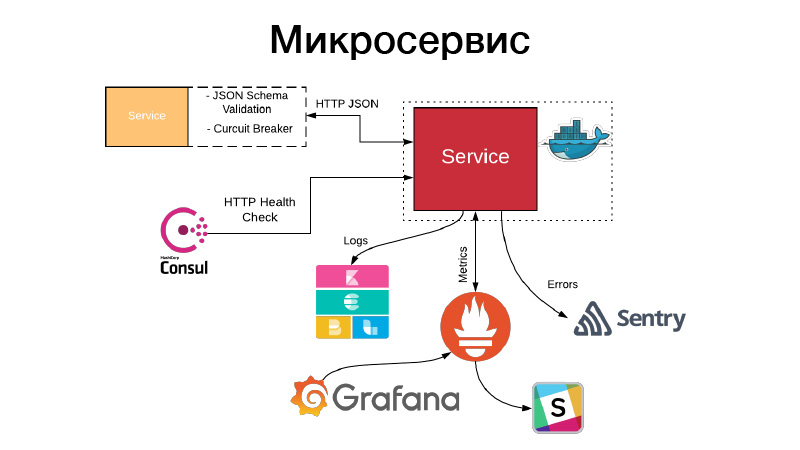
У нас есть артефакт, надо как-то в виде сервиса это оформить. Сервисы выставляют либо HTTP API, либо общаются через очереди. В данном примере это HTTP API, самый простой пример. При этом общение с сервисом, либо наш сервис общается с другими сервисами через HTTP JSON API валидирует JSON схему. У самого сервиса описан всегда JSON объект в документации к его API и схема этого объекта. Но не всегда все филды JSON объекта нужны, поэтому происходит валидация consumer driven contracts, валидация этой схемы, общение происходит через pattern circuit breaker, чтобы не позволять нашей распределенной системе выходить из строя из-за каскадных сбоев.
При этом сервис должен выставлять HTTP health check, чтобы Consul мог прийти и проверить доступность этого сервиса. При этом Nomad умеет делать так, что есть сервис три хелсчека подряд зафейлил, он может рестартануть сервис, чтобы помочь ему. Сервис пишет все свои логи в JSON формате. JSON logging driver используем и Elastics стек, на каждой точке FileBit забирает просто все JSON логи, кидает их в лог стеш, оттуда они в Elastic попадают, в KBan мы можем анализировать. При этом мы не используем логи для коллекции метрик и построения дашбордов, это неэффективно, мы для этого используем систему энторинга Prometheus, у нас есть процесс для создания из темплейтов для каждого сервиса дашбордов, и мы можем анализировать технические метрики, которые продюссируются сервисом.
При этом если что-то пошло не так, у нас прилетают алерты, но в большинстве случаев этого недостаточно. Нам на помощь приходит Sentry, это штука для анализа инцидентов. По сути, мы все логи уровня error перехватываем хендлером Sentry и пушим их в Sentry. И далее есть подробный traceback, есть вся информация о том, в каком окружении был сервис, какой версии, какие функции вызывались какими аргументами и какие переменные в данной области видимости были, с какими значениями. Все конфиги, все это видно, и это очень помогает быстро понять, что произошло, и устранить ошибку.
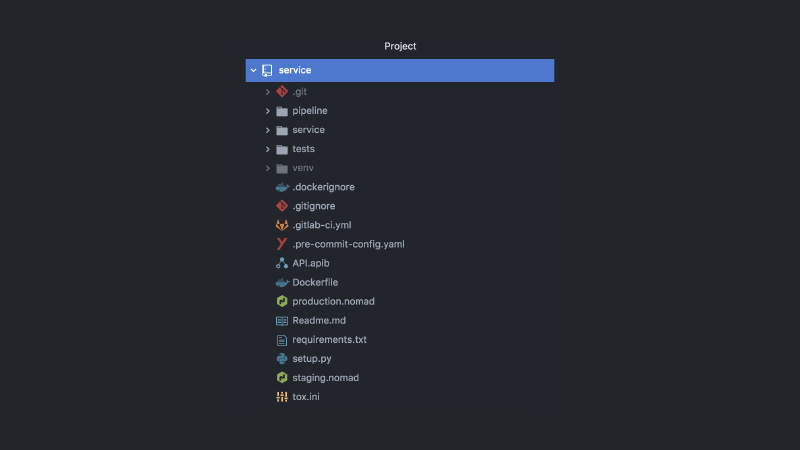
В результате сервис выглядит как-то так. Отдельный GitLab проект, код пайплайна, код тестов, сам код сервиса, куча конфигов разных, Nomad, CI-конфиги, документации к API, коммит хуки и прочее.
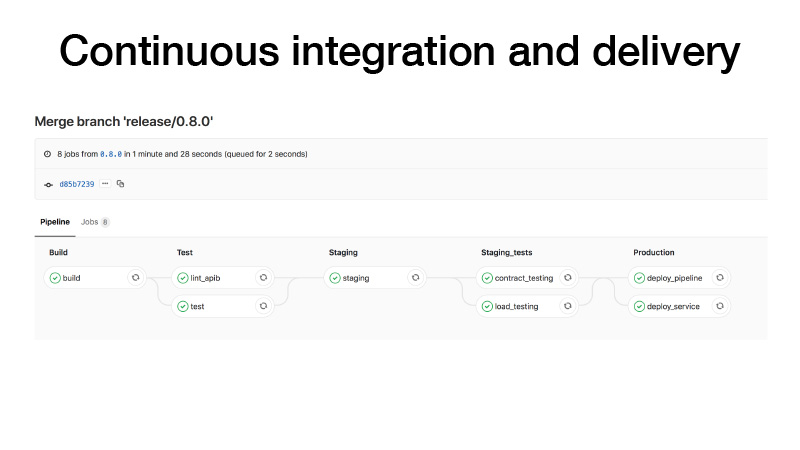
CI, когда мы делаем релиз, делаем следующим образом: билдим контейнер, прогоняем тесты, кидаем на стейджинг кластер, прогоняем там контракт тестирования нашего сервиса, проводим нагрузочное тестирование, чтобы удостоверить, что у нас предикт не слишком медленный и держим нагрузку, которая нам мнется. Если все окей, мы деплоим этот сервис на продакшен. И тут есть два пути: мы можем задеплоить пайплайн, если periodic batch job, она где-то в фоне работает и продюссирует артефакты, либо ручками триггерим какой-то пайплайн, он обучает какую-то модельку, после этого мы понимаем, что все окей и деплоим сервис.

Что еще происходит в этом случае? Я говорил, что в разработке фиче-бранчей есть такая парадигма, как feature toggles. Фичи по-хорошему надо прикрыть какими-то тогглами, чтобы просто на бою вырубить фичу, если что-то пошло не так. Мы тогда можем собирать все фичи в релиз-трейны, и даже если фичи недоделанные, то мы их можем деплоить. Просто фиче-тоггл будет выключен. Так как мы все дата-саентисты, мы хотим еще и АВ-тесты сделать. Допустим, мы LightGBM заменили на CatBoost. Мы хотим это проверить, но при этом АВ-тест менеджится с привязкой к какому-нибудь userID. Feature toggle привязывается к userID, и тем самым проходит АВ-тест. Нам здесь надо проверить эти метрики.
Все сервисы деплоятся в Nomad. У нас два кластера продакшена Nomad — один для batch job, другой для сервисов.
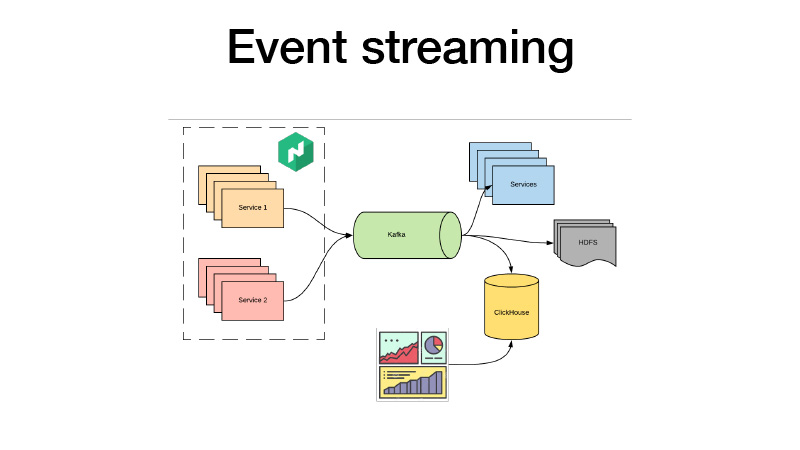
Все свои бизнес-ивенты они пушат в Kafka. Оттуда мы их можем забрать. По сути, это лямба-архитектура. Мы можем подписываться на HDFS какими-то сервисами, делать какую-то реалтайм-аналитику, и при этом мы все сгребаем в ClickHouse и строим дашборды, чтобы анализировать все бизнес-ивенты для наших сервисов. Мы можем анализировать АВ-тесты, что угодно.
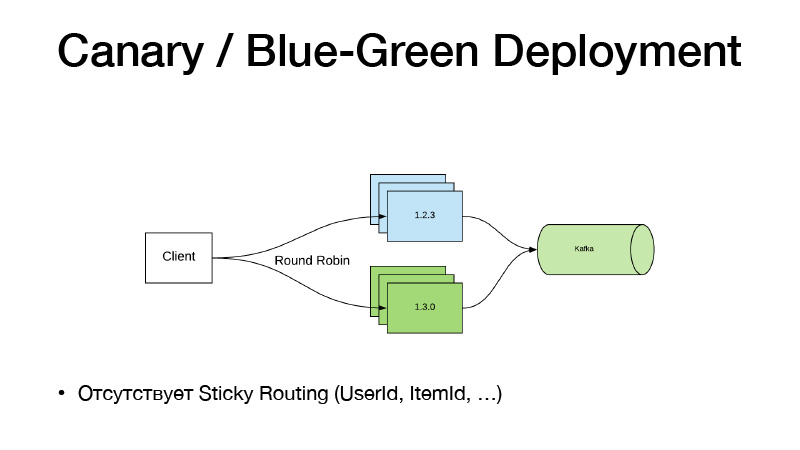
А если мы не меняли код, не надо использовать feature toggles. Мы только ручками затриггерили какой-то пайплайн, он обучил нам новую модельку. У нас есть к ней новый путь. Мы просто меняем в конфиге Nomad-путь к модельке, делаем релиз нового сервиса, и тут нам на помощь приходит парадигма Canary Deployment, она доступна в Nomad из коробки.
У нас есть текущая версия сервиса в трех инстансах. Мы говорим, что хотим три канарейки — деплоятся еще три реплики новых версий, не вырубая старые. В результате трафик начинает сплититься на две части. Часть трафика попадает на новые версии сервисов. Все сервисы пушат все свои бизнес-ивенты в Kafka. В результате мы можем в реальном времени анализировать метрики.
Если все окей, то мы можем сказать, что все окей. Деплой, Nomad пройдет, аккуратно выключит все старые версии и заскейлит новые.
Эта модель плоха тем, что если нам надо привязывать роутинг версий по какой-то сущности, User Item. Такая схема не работает, потому что трафик балансируется через round-robin. Поэтому мы пошли следующим путем и распилили сервис на две части.
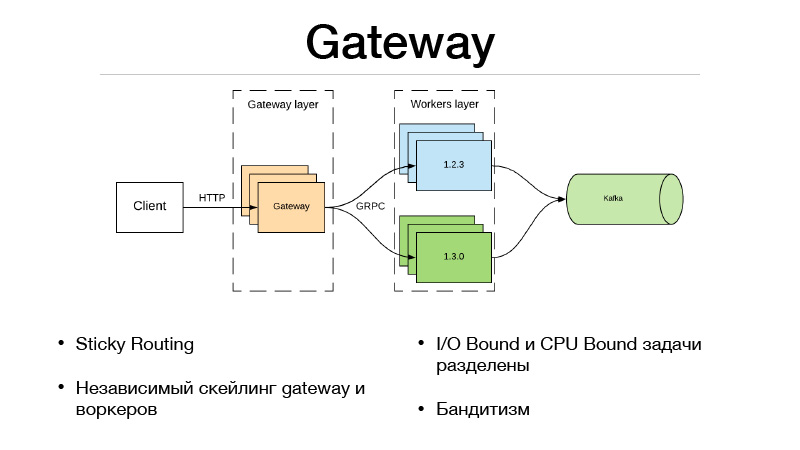
Это слой Gateway и слой workers. Клиент общается по HTTP со слоем Gateway, вся логика выбора версий и балансировки трафика находится в Gateway. При этом все I/O Bound-задачи, которые нужны для выполнения предикта, тоже находятся в Gateway. Допустим, нам в предикте в запросе приходит userID, который нам надо обогатить какой-то информацией. Мы должны дернуть другие микросервисы и забрать всю инфу, фичи или базы. В результате все это происходит в Gateway. Он общается с workers, которые находятся только в модельке, и делает одну вещь — предикт. Входные данные и выходные данные.
Но так как мы распили наш сервис на две части, появился overhead из-за удаленного сетевого вызова. Как это нивелировать? На помощь приходит JRPС-фреймворк от Google, RPC от Google, который работает поверх HTTP2. Можно использовать мультиплексию и сжатие. JPRC использует протобаф. Это строго типизированный бинарный протокол, который имеет быструю сериализацию и десериализацию.
В результате мы также имеем возможность независимо скейлить Gateway и worker. Допустим, мы не можем держать какое-то количество открытых HTTP-коннектов. Окей, скейлим Gateway. У нас слишком медленный предикт, не успеваем держать нагрузку — окей, скейлим workers. Этот подход очень хорошо ложится на многоруких бандитов. В Gateway, так как реализована вся логика балансировки трафика, он может ходить во внешние микросервисы и забирать у них всю статистику по каждой версии, а также принимать решение о том, как балансировать трафик. Допустим — с помощью Thompson Sampling.
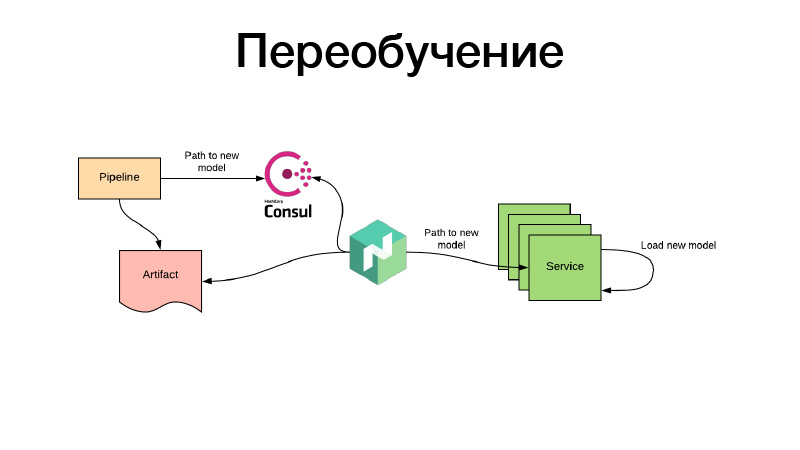
Все окей, модели как-то обучались, мы их в конфиге Nomad прописывали. А что если есть моделька рекомендаций, которая во время обучения уже успевает устареть, и нам надо их постоянно переобучать? Все делается так же: через periodic batch jobs продюссируется какой-то артефакт — допустим, каждые три часа. При этом в конце своей работы пайплайн кладет путь новой модели в Consul. Это key value storage, которое используется для конфигурирования. Nomad умеет темплейтировать конфиги. Пусть будет переменная окружения на основе значений key value storage Consul. Он следит за изменениями и, как только появляется новый путь — решает, что можно пойти двумя путями. Он скачивает по новой ссылке сам артефакт, кладет контейнер сервиса в Docker c помощью volume и перезагружает — причем делает все это так, чтобы не было даунтайма, то есть потихоньку, поштучно. Либо он рендерит новый конфиг и сообщает о нем сервису. Либо сам сервис его детектит — и внутри себя может самостоятельно, вживую проапдейтить свою модельку. На этом все, спасибо.
— Начнем с вводных. Есть data scientist, он в Jupyter Notebook пишет какой-то код, делает фиче-инжениринг, кросс-валидацию, тренирует модельки. Скор растет.
Но в какой-то момент он понимает: чтобы принести компании business value, он должен заделиверить решение куда-то в продакшен, в некий мифический продакшен, который вызывает у нас кучу проблем. Ноутбук, который мы пилили, в продакшен в большинстве случаев не отправить. И возникает вопрос: как этот код внутри ноутбука отгрузить в некий сервис. В большинстве случаев надо написать сервис, у которого есть API. Или они общаются через PubSub, через очереди.
Когда мы делаем рекомендации, нам надо часто обучать модели и переобучать их. Этот процесс надо мониторить. При этом надо всегда проверять тестами и сам код, и модели, чтобы в один момент наша модель не сошла с ума и не начала всегда предиктить нолики. Еще это нужно проверять на реальных пользователях через АB-тесты — что мы сделали лучше или как минимум не хуже.
Как мы подходим к коду? У нас GitLab. Весь наш код распиливается на много маленьких библиотек, которые решают конкретную доменную задачу. При этом это отдельный GitLab-проект, Git-контроль версий и модель ветвления GitFlow. Мы используем такие штуки, как pre-commit hooks — чтобы нельзя было закоммитить код, который не удовлетворяет нашим проверкам на стат-тесты. И сами тесты, юнит-тесты. Используем для них подход property based testing.
Обычно, когда вы пишите тесты, то подразумеваете, что у вас есть тестируемая функция и аргументы, которые вы руками создаете, некие примеры, и то, какие значения возвращает ваша тестируемая функция. Это неудобно. Код раздувается, многим в принципе лень это писать. В результате у нас куча кода, непокрытого тестами. Property based testing подразумевает, что все ваши аргументы имеют некое распределение. Давайте будем делать фазинг, и много раз семплировать из этих распределений все наши аргументы, вызывать с этими аргументами тестируемую функцию и проверять на некие свойства результат выполнения этой функции. В результате у нас кода гораздо меньше, и при этом тестов в разы больше.
Что такое GitFlow? Это модель ветвления, которая подразумевает, что у вас есть две основные ветки — develop и master, где находится production ready-код, а вся разработка при этом ведется в ветке develop, куда все новые фичи попадают из фиче-бранчей. То есть каждая фича — новый фиче-бранч, при этом фиче-бранч должен быть короткоживущим, а по хорошему — еще и прикрытым через feature toggle. Мы потом делаем релиз, из dev перекидываем изменения в master и вешаем на это тег версии нашей библиотеки или сервиса.
Делаем разработку, пилим какую-то фичу, пушим ее на GitLab, создаем merge request из фиче-бранча в дев. Срабатывают триггеры, прогоняем тесты, если все окей — можем замержить. Но мержим не мы, а кто-то из команды. Он ревьюит код, и тем самым повышается bus factor. Данный участок кода знают уже два человека. В результате — если кого-то собьет автобус, кто-то уже знает, что он делает.
При этом Continuous integration для библиотек обычно выглядит как тесты на любые изменения. И если мы релизим, это еще и паблишинг в приватный PyPI-сервер нашего пакета.
Далее мы это можем собрать в пайплайны. Для этого мы используем библиотеку Luigi. Она работает с такой сущностью, как таска, у которой есть аутпут, куда сохраняется артефакт, созданный во время выполнения таски. Есть параметр таски, который параметризует бизнес-логику, которую она выполняет, идентифицирует таску и ее аутпут. При этом у таски всегда есть требования, которые выставляют другие таски. Когда мы запускаем какую-то таску, все ее зависимости проверяются через проверку ее аутпутов. Если аутпут существует, наша зависимость не запускается. Если артефакт отсутствует на каком-то storage, он запускается. Тем самым формируется пайплайн, направленный циклический граф.
Все параметры идентифицируют бизнес-логику. При этом они идентифицируют артефакт. Всегда это дата с какой-то гранулярностью, сенситивностью, либо неделя, день, час, три часа. Если мы обучаем какую-то модельку, Luigi таска всегда имеет гиперпараметры этой таски, они просачиваются в артефакт, который мы продюссируем, гиперпараметры отражены в названии артефакты. Тем самым мы по сути версионируем все промежуточные дата-сеты и конечные артефакты, и они не перезаписываются никогда, всегда upend only на storage, и storage выступает HDFS и S3 приватный, который конечные артефакты видит пиклов каких-то, моделей или еще чего-то. И весь код пайплайна лежит в проекте сервиса в репозитории, к которому он относится.
Это надо как-то задеплоить. На помощь к на приходит HashiCorp стек, мы используем Terraform для декларирования инфраструктуры в виде кода, Vault для менеджмента секретов, там все пароли, явки к БД. Consul — сервис discovery, распределенный key value storage, который можно использовать для конфигурирования. И также Consul делает health checks ваших нод и ваших сервисов, проверяя их на доступность.
И — Nomad. это система оркестрации, шедулирования ваших сервисов и каких-то batch jobs.
Как мы это используем? Есть Luigi пайплайн, мы его запакуем в Docker контейнер, бросаем в Nomad батч или periodic batch job. Batch job — это что-то выполнилось, закончилось, и если все удачно — все окей, мы можем вручную затриггерить его снова. Но если что-то произошло не так, Nomad ретраит это, пока не исчерпает попытки, либо это не закончится успешно.
Periodic batch job — это ровно то же самое, только работает по расписанию.
Тут появляется проблема. Когда мы деплоим какой-то контейнер в систему оркестрации любую, надо указать, сколько надо памяти этому контейнеру, CPU или памяти. Если у нас пайплайн, который работает три часа, два часа из этого потребляет 10 Гб оперативной памяти, 1 час — 70 Гб. Если мы превышаем лимит, который мы ему выдали, Docker daemon приходит и убивает Dockers и (нрзб.) [02:26:13] Мы не хотим out of memory ловить постоянно, поэтому нам надо указать все 70 Гб, пиковую нагрузку на память. Но тут проблема, все 70 Гб на три часа будут аллоцированы и недоступны ни одной другой джобе.
Поэтому мы пошли другим путем. Весь наш Luigi пайплайн не запускает в себе какую-то бизнес-логику, он запускает просто набор кубиков в Nomad, так называемые параметризованные джобы. По сути, это аналог Server (нрзб.) [02:26:39] functions, AVS Lambda, кто знает. Когда мы делаем библиотеку, мы деплоим через CI весь наш код в виде параметризованных джоб, то есть контейнер с какими-то параметрами. Допустим, Lite JBM Classifier, у него есть параметр пути к входным данным для тренировки, гиперпараметры моделей и пути к выходным артефактам. Все это регистрируется в Nomad, и далее из Luigi пайплайна можем через API дергать все эти Nomad джобы, и при этом Luigi следит за тем, чтобы не запускать одну и ту же таску много раз.
Допустим, у нас процессинг текста всегда одинаковый. Есть условные 10 моделей, и мы не хотим каждый раз заново запускать процессинг текста. Он запустится всего один раз, и при этом будет готовый результат каждый раз переиспользоваться. И при этом все это работает распределенно, мы можем гигантский grid search запустить на большом кластере, успевай только железо докидывать.
У нас есть артефакт, надо как-то в виде сервиса это оформить. Сервисы выставляют либо HTTP API, либо общаются через очереди. В данном примере это HTTP API, самый простой пример. При этом общение с сервисом, либо наш сервис общается с другими сервисами через HTTP JSON API валидирует JSON схему. У самого сервиса описан всегда JSON объект в документации к его API и схема этого объекта. Но не всегда все филды JSON объекта нужны, поэтому происходит валидация consumer driven contracts, валидация этой схемы, общение происходит через pattern circuit breaker, чтобы не позволять нашей распределенной системе выходить из строя из-за каскадных сбоев.
При этом сервис должен выставлять HTTP health check, чтобы Consul мог прийти и проверить доступность этого сервиса. При этом Nomad умеет делать так, что есть сервис три хелсчека подряд зафейлил, он может рестартануть сервис, чтобы помочь ему. Сервис пишет все свои логи в JSON формате. JSON logging driver используем и Elastics стек, на каждой точке FileBit забирает просто все JSON логи, кидает их в лог стеш, оттуда они в Elastic попадают, в KBan мы можем анализировать. При этом мы не используем логи для коллекции метрик и построения дашбордов, это неэффективно, мы для этого используем систему энторинга Prometheus, у нас есть процесс для создания из темплейтов для каждого сервиса дашбордов, и мы можем анализировать технические метрики, которые продюссируются сервисом.
При этом если что-то пошло не так, у нас прилетают алерты, но в большинстве случаев этого недостаточно. Нам на помощь приходит Sentry, это штука для анализа инцидентов. По сути, мы все логи уровня error перехватываем хендлером Sentry и пушим их в Sentry. И далее есть подробный traceback, есть вся информация о том, в каком окружении был сервис, какой версии, какие функции вызывались какими аргументами и какие переменные в данной области видимости были, с какими значениями. Все конфиги, все это видно, и это очень помогает быстро понять, что произошло, и устранить ошибку.
В результате сервис выглядит как-то так. Отдельный GitLab проект, код пайплайна, код тестов, сам код сервиса, куча конфигов разных, Nomad, CI-конфиги, документации к API, коммит хуки и прочее.
CI, когда мы делаем релиз, делаем следующим образом: билдим контейнер, прогоняем тесты, кидаем на стейджинг кластер, прогоняем там контракт тестирования нашего сервиса, проводим нагрузочное тестирование, чтобы удостоверить, что у нас предикт не слишком медленный и держим нагрузку, которая нам мнется. Если все окей, мы деплоим этот сервис на продакшен. И тут есть два пути: мы можем задеплоить пайплайн, если periodic batch job, она где-то в фоне работает и продюссирует артефакты, либо ручками триггерим какой-то пайплайн, он обучает какую-то модельку, после этого мы понимаем, что все окей и деплоим сервис.
Что еще происходит в этом случае? Я говорил, что в разработке фиче-бранчей есть такая парадигма, как feature toggles. Фичи по-хорошему надо прикрыть какими-то тогглами, чтобы просто на бою вырубить фичу, если что-то пошло не так. Мы тогда можем собирать все фичи в релиз-трейны, и даже если фичи недоделанные, то мы их можем деплоить. Просто фиче-тоггл будет выключен. Так как мы все дата-саентисты, мы хотим еще и АВ-тесты сделать. Допустим, мы LightGBM заменили на CatBoost. Мы хотим это проверить, но при этом АВ-тест менеджится с привязкой к какому-нибудь userID. Feature toggle привязывается к userID, и тем самым проходит АВ-тест. Нам здесь надо проверить эти метрики.
Все сервисы деплоятся в Nomad. У нас два кластера продакшена Nomad — один для batch job, другой для сервисов.
Все свои бизнес-ивенты они пушат в Kafka. Оттуда мы их можем забрать. По сути, это лямба-архитектура. Мы можем подписываться на HDFS какими-то сервисами, делать какую-то реалтайм-аналитику, и при этом мы все сгребаем в ClickHouse и строим дашборды, чтобы анализировать все бизнес-ивенты для наших сервисов. Мы можем анализировать АВ-тесты, что угодно.
А если мы не меняли код, не надо использовать feature toggles. Мы только ручками затриггерили какой-то пайплайн, он обучил нам новую модельку. У нас есть к ней новый путь. Мы просто меняем в конфиге Nomad-путь к модельке, делаем релиз нового сервиса, и тут нам на помощь приходит парадигма Canary Deployment, она доступна в Nomad из коробки.
У нас есть текущая версия сервиса в трех инстансах. Мы говорим, что хотим три канарейки — деплоятся еще три реплики новых версий, не вырубая старые. В результате трафик начинает сплититься на две части. Часть трафика попадает на новые версии сервисов. Все сервисы пушат все свои бизнес-ивенты в Kafka. В результате мы можем в реальном времени анализировать метрики.
Если все окей, то мы можем сказать, что все окей. Деплой, Nomad пройдет, аккуратно выключит все старые версии и заскейлит новые.
Эта модель плоха тем, что если нам надо привязывать роутинг версий по какой-то сущности, User Item. Такая схема не работает, потому что трафик балансируется через round-robin. Поэтому мы пошли следующим путем и распилили сервис на две части.
Это слой Gateway и слой workers. Клиент общается по HTTP со слоем Gateway, вся логика выбора версий и балансировки трафика находится в Gateway. При этом все I/O Bound-задачи, которые нужны для выполнения предикта, тоже находятся в Gateway. Допустим, нам в предикте в запросе приходит userID, который нам надо обогатить какой-то информацией. Мы должны дернуть другие микросервисы и забрать всю инфу, фичи или базы. В результате все это происходит в Gateway. Он общается с workers, которые находятся только в модельке, и делает одну вещь — предикт. Входные данные и выходные данные.
Но так как мы распили наш сервис на две части, появился overhead из-за удаленного сетевого вызова. Как это нивелировать? На помощь приходит JRPС-фреймворк от Google, RPC от Google, который работает поверх HTTP2. Можно использовать мультиплексию и сжатие. JPRC использует протобаф. Это строго типизированный бинарный протокол, который имеет быструю сериализацию и десериализацию.
В результате мы также имеем возможность независимо скейлить Gateway и worker. Допустим, мы не можем держать какое-то количество открытых HTTP-коннектов. Окей, скейлим Gateway. У нас слишком медленный предикт, не успеваем держать нагрузку — окей, скейлим workers. Этот подход очень хорошо ложится на многоруких бандитов. В Gateway, так как реализована вся логика балансировки трафика, он может ходить во внешние микросервисы и забирать у них всю статистику по каждой версии, а также принимать решение о том, как балансировать трафик. Допустим — с помощью Thompson Sampling.
Все окей, модели как-то обучались, мы их в конфиге Nomad прописывали. А что если есть моделька рекомендаций, которая во время обучения уже успевает устареть, и нам надо их постоянно переобучать? Все делается так же: через periodic batch jobs продюссируется какой-то артефакт — допустим, каждые три часа. При этом в конце своей работы пайплайн кладет путь новой модели в Consul. Это key value storage, которое используется для конфигурирования. Nomad умеет темплейтировать конфиги. Пусть будет переменная окружения на основе значений key value storage Consul. Он следит за изменениями и, как только появляется новый путь — решает, что можно пойти двумя путями. Он скачивает по новой ссылке сам артефакт, кладет контейнер сервиса в Docker c помощью volume и перезагружает — причем делает все это так, чтобы не было даунтайма, то есть потихоньку, поштучно. Либо он рендерит новый конфиг и сообщает о нем сервису. Либо сам сервис его детектит — и внутри себя может самостоятельно, вживую проапдейтить свою модельку. На этом все, спасибо.
Комментарии (8)

lumaxy
04.11.2018 16:33Мой опыт по ML ограничен онлайн-курсами на Coursera, соревнованиями на Kaggle, и книгами по ML. В результате совершенно не представляю, как модели встраиваются в процесс в реальной жизни. Начало статьи просто супер, прям вселило надежду, но после картинки «Проблемы» начался текст, от которого я вспомнил анекдот, где ребенок в конце спрашивает: «Папа, а ты с кем сейчас разговаривал ?» :)
Короче, теперь жду то же самое, но «for Dummies»…AntonEryomin
06.11.2018 15:09Мне в своё время помог небольшой опыт работы с фреймворком Flask и понимание того, что модели это те же самые микросервисы. Он для начала и не только, очень хороший. Так же сейчас есть ряд фреймворков, в которых есть сильный упор на прод, например, вот тут: www.tensorflow.org/serving
sshikov
>повышается buzz factor
bus, вообще-то.
Leono Автор
спасибо!
sshikov
Да не за что, вам спасибо.
Это же распознанный текст? Немного портит впечатление от очень интересной темы. Мы на других технологиях работаем, и все равно я для себя почерпнул кое-что, что можно будет попробовать.
Leono Автор
Это расшифровка, составленная вручную.
finlandcoder
> повышается buzz factor
Тут нет опечатки. Именно buzz (жужжание). Жужжишь на собеседовании, что знаешь ML и вообще ту гуру Conv NN. А на проде — «таак… ввели 2, получили 5. ввели 2.0001, получили NaN. Ждём патча. А пока я это закомментирую.»
alex77_t
«А зачем тебе жужжать если ты не пчела? по-моему так..»
en.wikipedia.org/wiki/Bus_factor