
Пост подготовили участники команды Яндекс.Облака: Иван Веткасов — архитектор, Леонид Клюев — редактор
 Недавно мы рассказали об архитектуре Яндекс.Облака. Теперь давайте перейдем от теории к практике. В Облаке есть несколько сервисов для автоматизированного контроля за СУБД: Managed Service for ClickHouse, Managed Service for PostgreSQL и Managed Service for MongoDB. Все они являются платформенными и позволяют сосредоточиться на задаче хранения данных, а не на администрировании инфраструктуры. Но иногда бывает важно контролировать ещё и виртуальные машины кластера. Например, может возникнуть задача масштабирования в ответ на увеличение или снижение нагрузки. Обычно этот сценарий — один из самых трудоёмких с практической точки зрения. Сегодня мы расскажем, как Яндекс.Облако позволяет автоматизировать сложные задачи масштабирования, и убедимся, что база остаётся доступной в процессе изменения размера кластера.
Недавно мы рассказали об архитектуре Яндекс.Облака. Теперь давайте перейдем от теории к практике. В Облаке есть несколько сервисов для автоматизированного контроля за СУБД: Managed Service for ClickHouse, Managed Service for PostgreSQL и Managed Service for MongoDB. Все они являются платформенными и позволяют сосредоточиться на задаче хранения данных, а не на администрировании инфраструктуры. Но иногда бывает важно контролировать ещё и виртуальные машины кластера. Например, может возникнуть задача масштабирования в ответ на увеличение или снижение нагрузки. Обычно этот сценарий — один из самых трудоёмких с практической точки зрения. Сегодня мы расскажем, как Яндекс.Облако позволяет автоматизировать сложные задачи масштабирования, и убедимся, что база остаётся доступной в процессе изменения размера кластера.
Постановка задачи
При создании кластера каждого сервиса пользователь может определить число хостов кластера и зону доступности (availability zone, AZ), которая соответствует физическому дата-центру. Сейчас Яндекс.Облако использует три дата-центра Яндекса, расположенных в центральном регионе России. Поэтому рекомендованной является именно конфигурация кластера СУБД с тремя хостами — как наиболее соответствующая принципам построения отказо- и катастрофоустойчивой архитектуры.
Итак, представим себе ситуацию, когда нагрузка на кластер СУБД превысила возможности базы и назрела пора добавить вычислительных ресурсов. Сделать это можно как горизонтально — путем добавления хостов в кластер, так и вертикально — добавив ресурсов каждой машине кластера. Рассмотрим второй вариант, как наиболее трудоемкий и подверженный риску ошибок. Почему этот вариант трудоемкий? Потому что в общем случае процедура добавления ресурсов будет выглядеть примерно так: переключаем роль хоста; если это необходимо, останавливаем СУБД; выключаем виртуальную машину; меняем ее конфигурацию; запускаем; меняем параметры СУБД; запускаем СУБД; ждем синхронизации накопившихся изменений данных. И так для всех трех хостов по очереди. Много шагов — высок риск ошибиться. Можно автоматизировать этот процесс — только перед запуском выбранное решение по автоматизации необходимо протестировать. Обычно на тестирование не хватает времени, но в Яндекс.Облаке оно выполняется быстро и без лишних действий с вашей стороны. Приступим.
Предварительные шаги и процесс тестирования
Для подготовки нам понадобятся:
- Доступ к платформе. Сейчас настроить пробный период может любой желающий на сайте на сайте Яндекс.Облака.
- Облачная сеть (я в своем примере назову ее testvpc) и три подсети, расположенные в разных AZ. Диапазоны адресов подсетей в данном cлучае не важны.
- Бастионный хост. Несмотря на то, что в Яндекс.Облаке можно открыть внешний доступ к СУБД через публичный IP, публикация СУБД в открытом доступе является не самым правильным решением. Поэтому добавим к схеме бастионный хост, с которого и будем открывать подключения к хостам. В качестве такого хоста можно использовать машину с частичным (5-процентным) использованием ядра. На виртуальную машину необходимо установить clickhouse-client. Кроме того, согласно инструкции по подключению к сервису, нужно скачать SSL-сертификат.
- CLI. Работу с Яндекс.Облаком будем вести не через консоль, а через утилиту командной строки, которую также необходимо установить и инициировать согласно документации.
Сценарий тестирования будет простым: открываем три сессии подключения бастионного хоста к каждому хосту кластера БД, запускаем в цикле SQL-запрос с периодом, скажем, в 1 секунду, после чего отправляем команду на масштабирование кластера и смотрим на поведение системы.
Момент истины
Выберем СУБД для демонстрации масштабирования. В PostgreSQL хостам присваиваются роли, но в сервисе пока нет их прозрачного переключения при масштабировании — эта функциональность у нас в планах. Поскольку в остальном механика увеличения и уменьшения кластера примерно одинаковая в случае во всеми тремя СУБД, для примера возьмем ClickHouse.
Создадим объект эксперимента — кластер, состоящий из трех хостов, размещенных в разных виртуальных подсетях. Для этого введем команду
yc managed-clickhouse cluster create с необходимыми аргументами. Порядок аргументов соответствует их перечислению в выводе “yc --help”. Суть команды проста: создаем кластер ch-to-resize в production-окружении с размещением в виртуальной сети testvpc, задаем имя и пароль, объем дискового пространства 10 гигабайт и минимальный класс s1.nano. Этому классу соответствуют следующие характеристики: 1 CPU, 4 ГБ RAM. В дальнейшем для масштабирования мы перейдём к классу s1.micro, чтобы количество CPU и оперативной памяти выросло вдвое. Чтобы узнать, какие ещё классы хостов можно назначить, достаточно ввести команду
yc managed-clickhouse resource-preset list.
Таким образом, команда на создание кластера должна быть следующей:
yc managed-clickhouse cluster create --name ch-to-resize --environment production --network-name testvpc --host zone-id=ru-central1-a,subnet-id=e9bfnjacigdo9p6j7j2s,assign-public-ip=false,type=clickhouse --host zone-id=ru-central1-b,subnet-id=e2l8iamol3b9mrtskb8q,assign-public-ip=false,type=clickhouse --host zone-id=ru-central1-c,subnet-id=b0c6qit7u9e8r0egedvj,assign-public-ip=false,type=clickhouse --user name=test,password=test123123 --database name=testdb --clickhouse-disk-size 10 --clickhouse-resource-preset s1.nano --clickhouse-disk-type network-nvme –asyncВ ответ получим ID кластера и список hostnames его хостов:
yc managed-clickhouse cluster list
+----------------------+--------------+-----------------------------+--------+---------+
| ID | NAME | CREATED AT | HEALTH | STATUS |
+----------------------+--------------+-----------------------------+--------+---------+
| c9q7cr4ji2fe462qej8p | ch-to-resize | 2018-12-10T08:59:09.100272Z | ALIVE | RUNNING |
+----------------------+--------------+-----------------------------+--------+---------+
yc managed-clickhouse host list --cluster-id c9q7cr4ji2fe462qej8p
+-------------------------------------------+----------------------+---------+---------------+
| NAME | CLUSTER ID | HEALTH | ZONE ID |
+-------------------------------------------+----------------------+---------+---------------+
| rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net | c9q7cr4ji2fe462qej8p | ALIVE | ru-central1-a |
| rc1a-sgxazra54xv6lhni.mdb.yandexcloud.net | c9q7cr4ji2fe462qej8p | UNKNOWN | ru-central1-a |
| rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net | c9q7cr4ji2fe462qej8p | ALIVE | ru-central1-b |
| rc1b-j1rtvsuz6t8x6ev2.mdb.yandexcloud.net | c9q7cr4ji2fe462qej8p | UNKNOWN | ru-central1-b |
| rc1c-emo0f2990povj7ie.mdb.yandexcloud.net | c9q7cr4ji2fe462qej8p | UNKNOWN | ru-central1-c |
| rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net | c9q7cr4ji2fe462qej8p | ALIVE | ru-central1-c |
+-------------------------------------------+----------------------+---------+---------------+Откроем подключение к каждому хосту и запустим запрос к БД:
clickhouse-client --host rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net --secure --user test --password test123123 --database testdb --port 9440 -q "select concat(host_name, ' is alive\!') from system.clusters where replica_num = 1"
clickhouse-client --host rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net --secure --user test --password test123123 --database testdb --port 9440 -q "select concat(host_name, ' is alive!') from system.clusters where replica_num = 2"
clickhouse-client --host rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net --secure --user test --password test123123 --database testdb --port 9440 -q "select concat(host_name, ' is alive\!') from system.clusters where replica_num = 3"Наконец, отправим запрос на увеличение кластера:
yc managed-clickhouse cluster update --id c9q7cr4ji2fe462qej8p --clickhouse-resource-preset s1.micro -–asyncЕсли мы хотим уменьшить, а не увеличить объем ресурсов, то нужно указать меньший класс, сверившись с выводом
yc managed-clickhouse resource-preset list — например, s1.nano. При этом структура самой команды остается такой же.
Вывод запросов я перенаправил в файл. Вот сокращенный листинг:
rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net
Mon Dec 10 12:47:35 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive!
Mon Dec 10 12:47:36 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive!
Mon Dec 10 12:47:37 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive!
Mon Dec 10 12:47:38 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive!
Mon Dec 10 12:47:39 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive!
Mon Dec 10 12:47:40 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.7:9440: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7)
Mon Dec 10 12:47:51 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.7:9440: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7)
Mon Dec 10 12:48:02 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.7:9440: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7)
Mon Dec 10 12:48:11 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7)
Mon Dec 10 12:48:12 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7)
Mon Dec 10 12:48:13 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7)
Mon Dec 10 12:48:14 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7)
Mon Dec 10 12:48:15 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7)
Mon Dec 10 12:48:16 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7)
Mon Dec 10 12:48:17 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net:9440, 192.168.58.7)
Mon Dec 10 12:48:18 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive!
Mon Dec 10 12:48:19 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive!
Mon Dec 10 12:48:20 UTC 2018 rc1c-wcxq53lq096m0o6h.mdb.yandexcloud.net is alive!
rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:
Mon Dec 10 12:50:58 UTC 2018 rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net is alive!
Mon Dec 10 12:50:59 UTC 2018 rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net is alive!
Mon Dec 10 12:51:00 UTC 2018 rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net is alive!
Mon Dec 10 12:51:01 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.6:9440: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6)
Mon Dec 10 12:51:12 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.6:9440: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6)
Mon Dec 10 12:51:23 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.6:9440: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6)
Mon Dec 10 12:51:34 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.6:9440: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6)
Mon Dec 10 12:51:35 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6)
Mon Dec 10 12:51:36 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6)
Mon Dec 10 12:51:37 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6)
Mon Dec 10 12:51:38 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6)
Mon Dec 10 12:51:39 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6)
Mon Dec 10 12:51:40 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6)
Mon Dec 10 12:51:41 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6)
Mon Dec 10 12:51:42 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6)
Mon Dec 10 12:51:43 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net:9440, 192.168.58.6)
Mon Dec 10 12:51:44 UTC 2018 rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net is alive!
Mon Dec 10 12:51:45 UTC 2018 rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net is alive!
Mon Dec 10 12:51:46 UTC 2018 rc1a-qysm9t78x5ybdb78.mdb.yandexcloud.net is alive!
rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:
Mon Dec 10 12:49:15 UTC 2018 rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net is alive!
Mon Dec 10 12:49:16 UTC 2018 rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net is alive!
Mon Dec 10 12:49:17 UTC 2018 rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net is alive!
Mon Dec 10 12:49:18 UTC 2018 rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net is alive!
Mon Dec 10 12:49:19 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.8:9440: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8)
Mon Dec 10 12:49:30 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.8:9440: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8)
Mon Dec 10 12:49:41 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.8:9440: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8)
Mon Dec 10 12:49:52 UTC 2018 Code: 209. DB::NetException: Timeout: connect timed out: 192.168.58.8:9440: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8)
Mon Dec 10 12:49:56 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8)
Mon Dec 10 12:49:57 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8)
Mon Dec 10 12:49:58 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8)
Mon Dec 10 12:49:59 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8)
Mon Dec 10 12:50:00 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8)
Mon Dec 10 12:50:01 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8)
Mon Dec 10 12:50:03 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8)
Mon Dec 10 12:50:04 UTC 2018 Code: 210. DB::NetException: Connection refused: (rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net:9440, 192.168.58.8)
Mon Dec 10 12:50:05 UTC 2018 rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net is alive!
Mon Dec 10 12:50:06 UTC 2018 rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net is alive!
Mon Dec 10 12:50:07 UTC 2018 rc1b-2t82xtpscgr4gi6j.mdb.yandexcloud.net is alive!В листинге видны моменты выключения каждого хоста кластера (когда начинаются connect time out), моменты включения хоста и начала загрузки ClickHouse (когда начинаются connection refused), а также моменты, когда хост возвращается в строй. Самое главное — разнесение временных периодов, когда хосты были недоступны. Всё то время, пока шло масштабирование, как минимум два хоста были доступны для выполнения запросов. Это видно на графике:
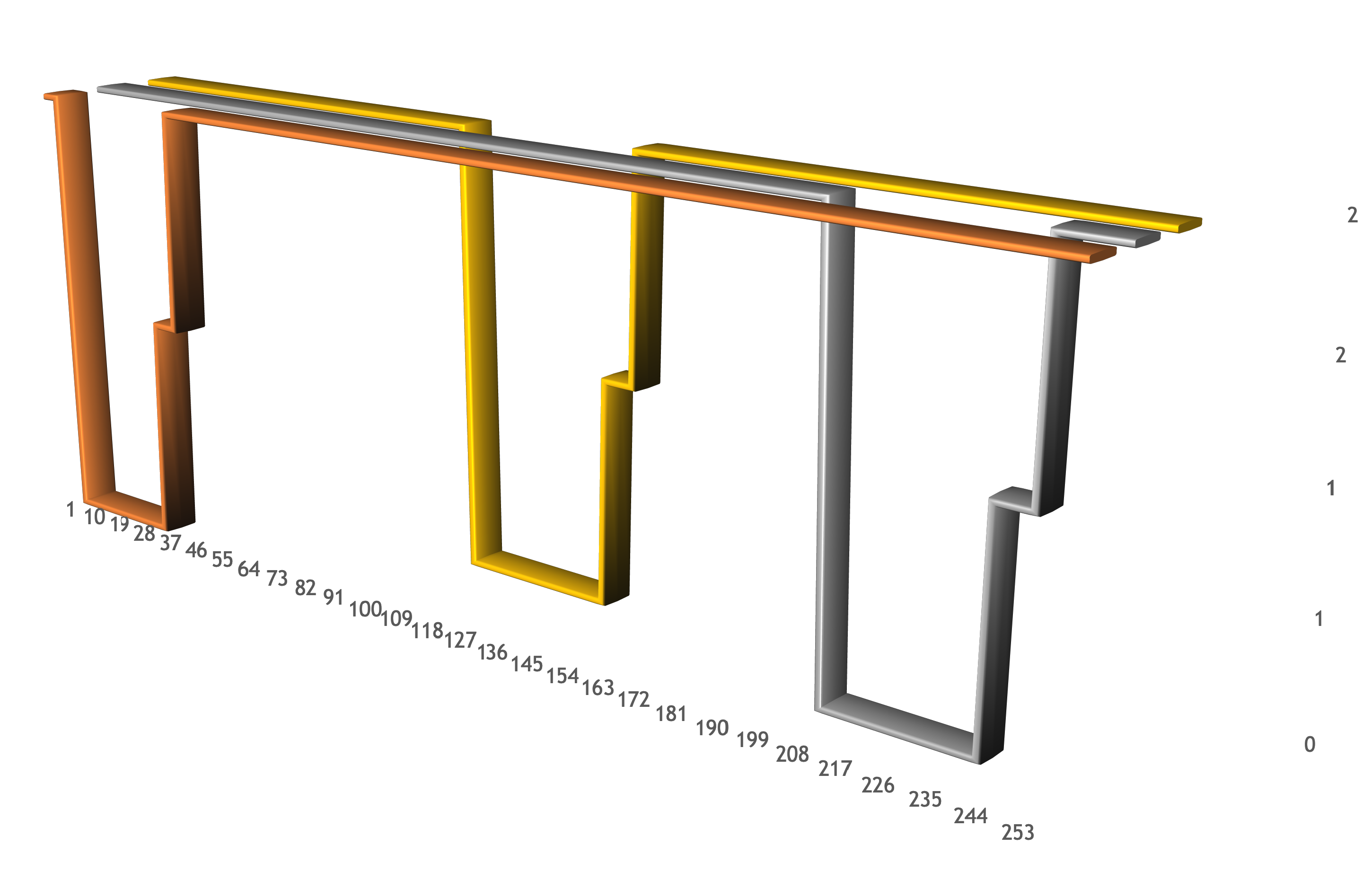
Выводы и best practices
На первый взгляд, развитие проектов с базами данных включает в себя большое количество рутинной работы. Базу необходимо поддерживать, то есть создавать резервные копии, наладить процесс регулярного обновления СУБД и т. д. Облачные сервисы управления появились в первую очередь для того, чтобы снять с вас эти трудоёмкие функции. Однако в реальной production-среде полезно, чтобы системы были не только управляемыми с точки зрения обслуживания, но и эластичными — реагирующими на рост и спад нагрузки. Мы рассказали, как увеличить производительность базы в Яндекс.Облаке, сохранив работоспособность проекта для пользователей. Если база настроена правильно, то при росте трафика происходит увеличение объема доступных ресурсов, а при спаде — кратное уменьшение, которое в том числе снижает ваши расходы.
О каких подходах, инструментах или технологиях в облачной тематике вам бы хотелось узнать? Предлагайте в комментариях темы для следующих постов Яндекс.Облака.
IgnisNoir
С ценами все также печально?
Leono Автор
Вот стороннее исследование о скорости ClickHouse. В других облаках (с другими СУБД) для реализации тех же задач потребуется более производительная и более дорогая машина. Вот наши цены: cloud.yandex.ru/docs/managed-clickhouse/pricing
IgnisNoir
Прошу прощения, а зачем сравнивать CH в вашем облаке с другими базами в других местах? Ну да ладно. Это еще можно понять в некоторых случаях.
Но у вас и другие цены не маленькие. При том что ваши сервера находятся в России(что конечно для некоторых в плюс) и ставят под угрозу бизнес в связи с нашей политикой блокировок и остальных факторов. Также у вас (я надеюсь пока что) нет такой большой инфраструктуры как в других облаках за что собственно и можно доплатить. Также у вас нет нормального тестового периода как у других. Да вы выдаете небольшую сумму, но ее определенно не хватит чтобы попробовать сервисы в реальном продакшн окружении.
Пока что выгоднее по всем позициям поднять свой сервис на чужом облаке, а в спорных позициях(вроде CH) лучше переплатить из-за геолокации.
И субъективно, возможно я в данный момент не прав, но поддержка у вас раньше никогда не блистала. Сколько раз в прошлом я пытался достучатся до нормальной поддержки по платным продуктам вроде диска, музыки и так далее столько же раз я не получал никакого ответа или отвечали примерно через недели две. Так что с такими ценами я бы поопасался брать у вас продукт