
Все медицинские учреждения, использующие продукт, условно можно разделить на две большие группы:
- Хостинг в дата центре нашего клиента, который полностью отвечает за работоспособность приложения, как за программную, так и за аппаратную часть. Например, если заканчивается место на диске, или не хватает производительности сервера по CPU;
- Self-hosted: размещают всё оборудование непосредственно у себя и сами отвечают за его работоспособность. Наш клиент предоставляет им приложение и его поддержку.
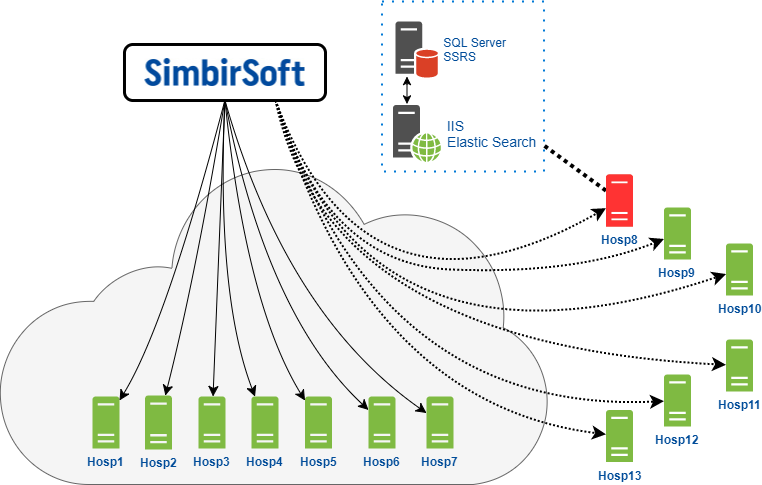
Вот так выглядит взаимодействие нашей команды с конечными серверами, которые хостятся непосредственно в облаке нашего клиента.

К этим серверам мы имеем доступ для проведения всех плановых работ и обслуживания, которое потребуется.
Вторая группа – self-hosted клиенты – для них облако клиента выступает в качестве шлюза, через которое мы подключаемся к этим серверам. Права в этом случае у нас ограниченные, зачастую мы не можем выполнять какие-то операции из-за настроек безопасности. К серверам мы подключаемся через RDP – протокол удаленного рабочего стола на OC Windows. Естественно, это все работает через VPN.
Здесь надо иметь ввиду, что каждый представленный на схеме сервер на самом деле является связкой сервера приложений и сервера базы данных. На БД сервере установлена соответственно СУБД MS SQL Server и служба отчетов SSRS. Причем версия MSSQL Server отличается во всех клиниках: 2008, 2012, 2014. Помимо самих версий, везде установлены разные Service Pack и патчи. В общем, полный зоопарк.
На сервере приложений у нас установлен веб сервер IIS и ElasticSearch. ElasticSearch представляет из себя поисковую систему, которая в том числе реализует полнотекстовый поиск.
Основной сущностью в терминах нашего продукта является “работа” (job). Работа — это абстрактная сущность, которая связывает воедино всю информацию, относящуюся к конкретному приему пациента. Эта информация включает:
- данные о докторе;
- данные о пациенте;
- данные о визите;
- аудиофайл (речь врача);
- документы (несколько версий);
- история обработки работы;
- данные об отделении и т. д.
На этой схеме показана упрощенная схема БД, из которой можно увидеть связи между основными таблицами. Это только базовая часть, на самом деле в базе данных более 200 таблиц.

Немного о клинике, где случился инцидент:
- 1500-2000 работ в день;
- 1000+ активных пользователей (докторов + секретарей);
- Self-hosted.
БД:
- Размер: 800+ Gb (750K+ работ, 2M+ документов);
- СУБД: MS SQL Server 2008 R2;
- Модель восстановления: Simple.
Тут хочется сделать небольшое пояснение. В SQL Server существует 3 модели восстановления: simple, bulk-logged и full. Про третью сейчас говорить не буду, поясню про первую и вторую. Основное отличие в том, что в модели simple мы не храним историю транзакций в журнале — как только транзакция была закоммичена, запись из транзакционного лога будет удалена. При использовании же режима восстановления full, вся история изменения данных у нас хранится в транзакционном логе. Что нам это даёт? В случае какой-то непредвиденной ситуации, когда нам нужно сделать откат базы из бэкапы, мы можем вернуться не только к какому-то определенному бэкапу, но можем вернуться в любую точку во времени, вплоть до определенной транзакции, т. е. У нас хранится в бэкапах не только определенное состояние базы в момент бэкапа, но также вся есть история изменения данных.
Я думаю, не стоит объяснять, что режим simple используется только в разработке, на тестовых серверах и его использование в продакшене — недопустимо. Вообще никак.
Но у клиники, видимо, были свои мысли на этот счёт ;)
Начало
Через несколько дней Новый год, все готовятся к празднику, покупают подарки, наряжают елки, проводят корпоративы и находятся в ожидании долгих выходных.
22 декабря (пятница) 1 день
14:31 Клиент сообщил, что не получил очередной ежедневный отчет. Отчет приходит на почту дважды в день по расписанию, нужен для контроля отправки данных во внешнюю интеграционную систему, не слишком критичный.
Причин могло быть несколько:
- Проблемы с SMTP, письма просто не были доставлены (сменили пароль, например, и никому не сообщили);
- Проблемы на стороне сервера отчетов;
- Что-то случилось с базой данных.
16:03Клиника иногда меняет пароль на SMTP, никого об этом не предупреждая, поэтому закончив текущие задачи, спокойно проверяем отчет вручную путем запуска через веб интерфейс — получаем ошибку, которая указывает на проблемы в базе данных.
Пример ошибки, которую мы получили при запуске отчета.
SQL Server detected a logical consistency-based I/O error: incorrect checksum (expected: 0x9876641f; actual: 0xa3255fbf). It occurred during a read of page (1:876) in database ID 7 at offset 0x000000006d8000 in file 'D:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA\ServerLive.mdf'.Это говорит о том, что в базе данных есть поврежденные страницы. У нас зародилось легкое чувство тревоги.
20:53 Для того, чтобы оценить масштабы повреждений запускаем проверку базы данных с помощью специальной команды DBCC CHECKDB. В зависимости от размера повреждений команда проверки может выполняться довольно долго, поэтому запускаем команду в ночь. Здесь нам повезло, что это произошло в пятницу во второй половине дня, т. е. у нас были как минимум все выходные на решение этой проблемы.
В тот момент ситуация выглядела следующим образом:
23 декабря (суббота) 2-й день
10:02 Утром обнаруживаем, что проверка базы с помощью CHECKDB зафейлилась — это было связано с недостатком свободного места на диске, т.к. в процессе проверки активно используется временная база tempdb, и в какой-то момент просто закончилось свободное место на диске.
Поэтому мы решаем вместо проверки всей базы сразу запустить потабличную проверку. Для этого служит команда DBCC CHECKTABLE.
10:46 Начать мы решаем с таблицы JobHistory, которая повреждена наверняка, т. к. именно она использовалась при генерации отчета. Эта таблица, как можно понять из названия хранит историю всех работ, т. е. переходы работ между стадиями.
Запускаем DBCC CHECKTABLE('dbo.JobHistory').
Проверка данной таблицы выявляет поврежденные таблицы в базе данных, что в принципе было ожидаемо.
12:00 В данный момент, если бы база данных использовала модель восстановления full, мы могли бы восстановить поврежденные страницы из бэкапа, и на этом все бы и закончилось, но наша база была в simple mode. Поэтому единственным вариантом для восстановления повреждений у нас остается запуск этой же команды со специальным параметром REPAIR_ALLOW_DATA_LOSS. При этом возможна потеря данных.
Запускаем. Проверка снова завершается с ошибкой — получаем ошибку, что восстановление этой таблицы невозможно, пока не будут восстановлены связанные таблицы. Таблица истории ссылается на таблицу работ (Jobs) по внешнему ключу, следовательно, делаем вывод, что повреждения есть также в основной таблице работ (Jobs).
13:30 Следующий шаг — это проверка таблицы Jobs, при этом — надеемся, что повреждения в индексе, а не в данных. В этом случае нам достаточно будет просто перестроить индекс для восстановления данных.
17:33 Через некоторое время обнаруживаем, что наш сервер недоступен по RDP. Вероятно, он был выключен, проверка не была завершена, работа приостановлена. Сообщаем в клинику, что сервер недоступен, просим поднять его.
Легкая тревога приобретает очень конкретные формы.
24 декабря (воскресенье) 3-й день
14:31 Ближе к обеду сервер поднимают, повторно запускаем проверку таблицы Jobs.
DBCC CHECKTABLE('dbo.Jobs')
16:05 Проверка не завершена, сервер недоступен. Опять.
Через некоторое время сервер снова недоступен, до того, как мы успели завершить проверку таблицы. В этот момент IT служба клиники выполняет ряд проверок сервера. Ждём окончания работ.
Из-за праздников коммуникации между нами и клиентом происходили медленно — ответы на вопросы мы ожидали по нескольку часов.
25 декабря (понедельник – Рождество) 4-й день
16:00 На следующий день сервер подняли, у клиента Рождество, а мы опять запускаем проверку таблицы, но на этот раз исключаем из проверки индексы, а оставляем только проверку данных. И через некоторое время сервер снова недоступен.
Что же происходит?
В этот момент начинают закрадываться мысли, что это всё не просто совпадение и есть подозрение на то, что это могут быть повреждения на уровне железа (посыпался жесткий диск). Мы предполагаем, что на диске есть поврежденные сектора и когда проверка пытается прочитать данные с этих секторов, система крашится. Сообщаем о своем предположении клиенту.
Клиент запускает проверку диска на хост машине.
17:19 IT служба клиники сообщила, что поврежден файл виртуальной машины — это плохо!(
Мы пока работать не можем, и ждем сигнала, когда они пофиксят проблему и мы сможем продолжить нашу работу.
26 декабря (вторник) 5-й день
14:05 IT служба клиники запускает другой процесс восстановления диска. Нам сказали, что мы можем параллельно запустить CHECKTABLE для проверки таблицы. Запускаем проверку снова — опять крашится виртуалка, сообщаем клиенту, что файл виртуальной машины все еще поврежден.
В эти дни все коммуникации с заказчиком проходят очень медленно с огромным временным лагом из-за праздников.
27 декабря (среда) 6-й день
14:00 Запускаем проверку диска средствами Windows — checkdisk внутри виртуальной машины — проблем не выявлено.
БД находится в режиме Simple, поэтому шансы на исправление текущей базы средствами СУБД стремятся к нулю, т.к. мы не можем восстановить отдельные поврежденные страницы.
Начинаем рассматривать вариант с откатом и восстановлением базы данных из бэкапа.
Проверяем бэкапы БД и обнаруживаем, что средствами СУБД бэкапы не делались, последний бэкап был в 2014 году, т.е. бэкапов базы нет. Почему не делались — вопрос отдельный, это ответственность клиники обеспечивать работоспособность и сохранность базы данных.
Велика вероятность того, что восстановить текущую БД не получится, начинаем рассматривать другие варианты отката.
Давайте поподробнее остановимся на ситуации с бэкапами в клинике.
Ситуация с бэкапами:
- Бэкапов БД нет (!!!)
- Снапшотов виртуальной машины тоже нет (!?)
- Зато есть бэкапы диска (full + inc)
База данных лежит на диске D, соответственно они делали еженедельно полные бэкапы и ежедневно инкрементальные бэкапы.
- каждую пятницу в 20:00 full backup
- каждый день incremental backup
- есть full backup от 15-го и 22-го числа
- есть ежедневные бэкапы вплоть до 21-го числа
Т.е. в принципе мы можем откатиться на состояние до возникновения проблемы.
Ждем обновления от клиники, чтобы начать откат базы из бэкапа.
Одновременно с этим клиника отправила запрос поставщику железа (HP) с пометкой “срочно”.
28 декабря (четверг) 7-й день
13:13 IT-служба клиники начинает настройку новой виртуальной машины, т.к. пофиксить повреждения в файле старой виртуальной машине не получается.
19:09 Доступна новая виртуалка с установленным SQL Server.
Следующий шаг — восстановление базы из бэкапа диска. Для начала решаем откатиться на 22-е число, если проблема все еще присутствует, то откатываемся на 21-е, 20-е и так далее, пока не придем к рабочему состоянию.
На дворе было 28-е число, мы на корпоративе, и тут нам сообщают, что у клиники проблемы с восстановлением бэкапа, потому что БЭКАПЫ ПУСТЫЕ!
Вот так новость!
Во время восстановления бэкапа диска D от 21-го числа выясняется, что он пустой, как и все остальные. Прямо бэкапы шредингера получаются — они вроде как и есть, но в то же время их нет. Не до конца понятно, как такое вообще вышло, но, насколько нам удалось понять, дело в недостаточном месте на диске для хранения бэкапов диска. Они выделили под хранение бэкапов 500 Gb, но в момент инцидента база данных уже весила 800 Gb, следовательно, бэкап в принципе не мог пройти успешно. Т.е. бэкапы исправно делались по расписанию, но из-за недостатка места они завершались с ошибкой и соответственно были пустыми, а IT-службе клиники даже в голову не пришло проверить, что с ними все в порядке. Не надо так.
29 декабря (пятница) 8-й день
13:11 Обсуждение дальнейших действий. Возможные варианты:
- Попытаться скопировать файлы базы данных (.ldf +.два файлы) — шансы на успех очень невысокие;
- Попробовать сделать бэкап БД — опять же шансов очень мало;
- Настроить репликацию — может сработать.
На новом сервере выделили 1 Tb диск, чего очевидно недостаточно, если мы попытаемся сделать бэкап и восстановить из него, т.к. в худшем случае без компрессии бэкап будут занимать столько же места, сколько исходная база данных, т.е. 800 Gb.
Просим добавить места на новом сервере и приступаем к копированию файлов БД.
На новом сервере создана база данных и восстановлена схема БД — это позволит хотя бы обрабатывать новые работы. Клиника уже хотя бы сможет принимать новых пациентов, пользуясь такой системой.
14:36 Поэтому приступаем к варианту номер один, хотя особо на успех не рассчитываем.
Останавливаем SQL Server, начинаем копирование файла данных (mdf) и лога (ldf).
16:13 Через полтора файл лога скопировался успешно (48 Gb), и уже скопировано 50 гб файла данных (795 из 846 Гб осталось). При такой скорости для завершения копирования понадобится около 12 часов.
16:30 Старый сервер БД выключился во время копирования файла, что вполне ожидаемо.
17:09 Поэтому переходим к следующему варианту — настройке репликации, при этом мы можем указать какие данные будут реплицироваться, т. е. мы можем сначала исключить заведомо поврежденные таблицы и сначала скопировать неповрежденные данные, а затем по частям переносить проблемные таблицы. Но этот вариант, к сожалению, тоже не работает, т. к. мы не можем даже создать публикацию с определенными таблицами из-за повреждения БД.
Рассматриваем еще варианты переноса данных.
20:01 В итоге, начинаем просто потаблично переносить данные со старого на новый сервер путем импорта-экспорта в порядке приоритета.
21:35 Сначала наиболее критичные данные, затем архивные и менее критичные (~300 Гб). В первой волне экспорта осталось менее 300 Гб данных. Исключена также таблица Documents (300Гб). Запускаем процесс копирования в ночь.
30 декабря (суббота) 9-й день
15:00 Продолжаем переносить данные. Таблица Jobs недоступна вообще. Основная часть таблиц была скопирована к этому времени.
Но без Jobs это всё бесполезно, т. к. она является главным связующим звеном между всеми данными и придает им смысл и ценность с точки зрения бизнеса. Без неё у нас просто есть разрозненный набор данных, который мы никак не можем использовать.
Также к этому моменту закончено восстановление схемы базы данных.
Последствия инцидента:
К этому моменту мы имеем огромную потерю живых данных.
Т.е. формально кое-какие данных у нас есть в базе, но, по сути, нет никакой возможности их использовать или связать между собой, так что можно говорить о полной потере данных.
Потеряны данные более чем о 750 000 приемах пациентов.
Это реально грустно!
- Это огромный удар по репутации нашего клиента, который может обернуться для них большими проблемами в бизнесе при заключении новых контрактов и поиске новых клиентов.
- Потеря такого количества данных для клиники может грозить серьезными проблемами и штрафами, т.к. это конфиденциальные данные, содержащие врачебную тайну и от них, в прямом смысле, зависят жизни людей.
Мы стали думать, что мы можем сделать в этой ситуации. Стали перебирать систему по косточкам, чтобы найти зацепки.
15:16 Анализируя все аспекты системы, мы понимаем, что можем попытаться извлечь недостающие данные из индекса ElasticSearch. Все дело в том, что из-за неверной настройки индексов ElasticSearch, в нем хранятся не только те поля, по которым осуществляется полнотекстовый поиск, а вообще все, т. е. по сути там лежит полная копия данных и мы теоретически можем извлечь оттуда данные о работах и положить их обратно в нашу базу данных. Есть надежда, что данные всё-таки получится восстановить.
Баг, которому можно поставить памятник!

18:00 Быстро была написана утилита для извлечения данных и через несколько часов убеждаемся, что подход работает и данные получится восстановить.
20:00 Начато восстановление работ из ElasticSearch с помощью написанной утилиты. Подход сработал, данные о работах можем восстановить. Параллельно начинаем извлечение последних версий документа для каждой работы.
31 декабря (воскресенье — Новый Год) 10-й день
14:09 За ночь было восстановлено 188 811 работ.
20:13 Видя наши успехи клиника решает отложить передачу сервера в сервис HP, чтобы дать нам время извлечь со старого сервера по максимуму данных.
С такими новостями мы и встретили Новый год))
01 января (понедельник) 11-й день
11:23 Идет подготовка для запуска системы после инцидента:
- переконфигурирован IIS на App сервере;
- перенастроены все необходимые сервисы для работы с новым сервером БД;
- восстановлены триггеры, хранимые процедуры, функции.
14:28 Затем начали копировать таблицу документов, которая при первичном переносе была пропущена из-за большого размера.
— Старый DB сервер снова выключился. Очевидно, что таблица Documents также повреждена, именно с ней хранится вся информация по пациентам. К счастью, она повреждена не полностью, мы можем делать к ней запросы и когда запрос к нам возвращает поврежденную запись, в этот момент сервер падает и выключается. Часть данных при этом извлечь мы можем.
Соответственно сигнализируем клиенту, они поднимают сервер, и мы параллельно продолжаем подготавливать новую БД к запуску системы.
18:01 Восстановление всех ограничений целостности после переноса основной части данных.
22:02 Восстановление ограничений завершено. Мы просто по максимуму переносили сырые данные. Наличие ограничений целостности сильно бы усложнило нашу задачу.
02 января (вторник) 12-й день
05:52 Старый DB сервер снова выключился во время копирования документа. Его оперативно поднимают, чтобы мы могли продолжить работу.
09:00 Удалось пакетно восстановить около 200.000 документов (примерно 20%)
Мы начали использовать разные методы восстановления: сортировку по разным столбцам, чтобы доставать данные с конца или начала таблицы, до того момента пока мы не наткнемся на какую-то поврежденную часть таблицы.
13:42 Начато копирование архивных работ в таблице – она, к счастью, не повреждена.
17:08 Восстановлены все архивные работы (491 380 шт).
Система готова к запуску: пользователи могли создавать и обрабатывать новые работы.
К сожалению, из-за частичного повреждения таблицы документов, нельзя просто перенести все данные из неё, как с другими таблицами, т.к. таблица частично повреждена. Поэтому, при попытке извлечь все данные запрос падает с ошибкой при попытке чтения поврежденных страниц. Поэтому извлекаем данные точечно, используя разные сортировки и размер выборки:
- Сортировка по разным полям (ID, DateTime);
- Сортировка по возрастанию, убыванию;
- Работа с небольшими группами строк (1000, 100);
- Извлечение работ по ID.
03 января (среда) 13-й день
08:58 Продолжали процесс восстановления документов. Документы были восстановлены только для активных, незавершенных работ. К этому моменту 1000 работ (активных) без документов.
11:38 Перенесены все SQL Jobs
13:17 5 работ без документов, 231 работа отсутствует, но есть аудиофайл, нужно пересинхронизировать.
04 января (четверг) 14-й день
Начато ручное восстановление и проверка оставшихся работ.
Система работает, мониторинг и исправление ошибок в онлайн режиме.
05 января (пятница) 15-й день
Запланирован перенос отчетов в SSRS.
Перенос на новый сервер невозможен, т.к. в клинике установили более старую версию SQL Server и перенести БД со старого сервера не получится.
Варианты:
- Обновить SQL Server с 2008 до 2008 R2;
- Настраивать всё с нуля.
Было решено дождаться обновления SQL Server.
09:21 Начато фоновое восстановление документов для завершенных работ — процесс долгий и займет несколько дней.
13:28 Изменение приоритета восстановления документов по департаментам.
18:18 Клиника дала доступ к SMTP, настройка почты
Результат:
- Восстановлены почти все данные (потеряно всего 5 работ);
- Выданы рекомендации по обслуживанию БД, чтобы предотвратить такие ситуации;
- Настроены бэкапы БД средствами SQL Server;
- Дополнительный мониторинг за бэкапами с нашей стороны, алерты в случае фэйла.
Комментарии (23)

periskop
13.12.2018 11:45Еще вопросы, если не возражаете.
- А по другим клиентам настроили мониторинг бэкапов?
- Какие именно рекомендации по обслуживанию БД были выданы?
- Удалось ли выяснить, почему падала виртуалка?
- Что бы за гипервизор? Что использовалось в качестве хранилища?
SSul Автор
13.12.2018 13:25А по другим клиентам настроили мониторинг бэкапов?
— Ответили выше.
Какие именно рекомендации по обслуживанию БД были выданы?
— Перевести модель восстановления БД в режим full, мониторить состояние бэкапов, выполнять бэкапы с проверкой CHECKSUM и проверять бэкапы после создания RESTORE VERIFYONLY. Также, рекомендовали регулярно проводить восстановление из бэкапов на специальном стенде.
Удалось ли выяснить, почему падала виртуалка?
— Нет, наверняка выяснить не удалось, т.к. доступа к хостовой машине и логам не было, но сложилось впечатление, что в поврежденных секторах диска были не только файлы бд, но и какие-то системные, что и приводило к крашу.
Что бы за гипервизор? Что использовалось в качестве хранилища?
— Это выяснить не удалось, т.к. между IT службой клиники и нашей командой был заказчик в качестве посредника, и не вся информация до нас доходила.
little-brother
13.12.2018 11:48+1Где хранить файлы конечно тема спорная. Но в данном случае хранение в базе мне видится излишним: если аудио-записи и генерируемые документы (их вообще можно не хранить, а генерировать по запросу) хранились бы как отдельные файлы в файловой системе, то сама база была бы значительно меньше, как и вероятность сбоя (транзакции по обновлению информации по работам минимальны). Создание бэкапа базы было бы простым и быстрым.
А так по сути сами придумали проблему, сами решили.
P.S. Возможно для хранения в базе были какие весомые причины, напр. требования заказчиков.periskop
13.12.2018 11:54+1Если хранить не в БД, будут дополнительные костыли. Но вообще есть такая вещь как FILESTREAM.
Sioln
13.12.2018 11:54Хранение файлов в бд убирает вопрос консистентности бэкапов.
Ибо, если они хранятся раздельно, то и бэкапятся раздельно с БД.
И вы имеете БД на момент времени X, а файлы на момент времени Y.
Но, да, хранение в БД — большой оверхед. Особенно с точки зрения конкурентной работы. Транзакции значительно дольше.little-brother
13.12.2018 12:03Если в имени файла задавать дату-время, то вопроса о том, когда какой файл был создан, не будет.
SSul Автор
13.12.2018 12:03Всё верно, на это были требования. Сейчас в БД лежат только документы, аудио хранятся в файловой системе. Но тут скорее проблема не в этом, а промах в администрировании: если бы всё было настроено правильно, не важно какой был бы размер БД и что в ней хранилось.
Kriminalist
13.12.2018 12:51Я так понял, что клиника данные пациентов в открытом виде хранит, без шифрования?
SSul Автор
13.12.2018 13:26Открытого доступа к данным нет, аудио файлы на диске зашифрованы. На уровне БД настройки шифрования в разных клиниках различаются, как писали в статье, обеспечение сохранности данных — это зона ответственности клиники.
molec
13.12.2018 13:01Ух. Если честно, я бы очень не хотел, чтобы аудио файл моих разговоров с врачом бесконтрольно вместе с его расшифровкой летал между кабинетом, клиникой и Вами. Я надеюсь, что данные обрабатываются максимально неперсонализированно, но вероятность проблем с конфиденциальностью сильно больше, чем если бы всего этого не было.
Зачем вообще хранятся историчные аудио, если уже есть их расшифровка? Производятся ли какие-то шаги, чтобы снизить возможный урон? Алгоритм разбора настолько тяжелый, что его совсем нереально запускать на АРМ врача?SSul Автор
13.12.2018 14:14Старые аудио удаляются в соответствии в data retention policy.
Сложность расшифровки связана со спецификой и сложностью распознавания медицинской терминологии и для клиники экономически выгоднее отдать транскрибирование на аутсорс, чем делать это своими силами. Это позволяет экономить приличные суммы ежегодно.
Naves
13.12.2018 13:31Непонятно, почему сразу после выявления ошибок DBCC не скопировали файлы базы. При их копировании сразу бы обнаружили аппаратные проблемы. Пытаться чинить с помощью DBCC базу на поврежденном диске — прямой путь окончательно убить базу. Если нет места, купить в магазине 4тб диск и подключить его куда угодно…
SSul Автор
13.12.2018 14:03В момент выявления ошибок не было мыслей куда-то копировать файлы, т.к. ещё не было догадок про аппаратные проблемы и мы даже предположить не могли, что могут отсутствовать бэкапы на лайв системе.
Naves
13.12.2018 14:46<ворчание mode=on>Привыкли уже все работать на виртуалках, отвыкли как ломаются базы при аппаратных проблемах дисков или памяти, или как безвозвратно бьется лог-файл при отключении питания (когда отключают сам бесперебойник), что база не работает уже ни в каком из режимов suspect.
Оставлю ссылку на всякий случай dba.stackexchange.com/a/29758Sioln
13.12.2018 16:21На виртуалке испытал на себе всю надёжность ReFS. Убился весь раздел, целиком. При том, что носитель хоста — нормальный.
Так что виртуалки, они разные =)
periskop
Вы молодцы.
А вот тут я бы не был столько категоричным, все зависит от обстоятельств.
Sioln
Тоже резануло. Или аргументация нужна дополнительная (не везде важно откатиться по логу с точностью до транзакции) либо не стоит столь категорично.
SSul Автор
В принципе да, согласны — есть кейсы, когда это нормально, но в контексте нашего случая, когда система работает в OLTP режиме — это не вариант.
periskop
В такой формулировке согласен полностью.