
Я – Lead DevOps Engineer в международной SaaS-компании. Мы разрабатываем платформу для совместной работы кроссфункциональных команд. В статье поделюсь тем, как наша DevOps-команда решила проблему ежедневных серверных релизов монолитного stateful-приложения и сделала их автоматическими, невидимыми для пользователей и удобными для собственных разработчиков.
Наша команда разработки — это 60 человек, которые делятся на Scrum-команды, среди которых есть и команда DevOps. Большинство Scrum-команд поддерживают текущую функциональность продукта и придумывают новые фичи. Задача DevOps — создавать и поддерживать инфраструктуру, которая помогает приложению работать быстро и надёжно и позволяет командам быстро доставлять новый функционал до пользователей.
Наше приложение — это бесконечная онлайн-доска. Оно состоит из трех слоев: сайт, клиент и сервер на Java, который является монолитным stateful-приложением. Приложение держит постоянное web-socket подключение с клиентами, а каждый сервер держит в памяти кэш открытых досок.
Вся инфраструктура – более 70 серверов — находится в Amazon: более 30 серверов с нашим Java-приложением, веб-серверы, серверы баз данных, брокеры и многое другое. С ростом функциональности всё это необходимо регулярно обновлять, не нарушая работы пользователей.
Обновлять сайт и клиент просто: заменяем старую версию на новую, и при следующем обращении пользователь получает новый сайт и новый клиент. Но если мы сделаем так при релизе сервера, то получим downtime. Для нас это недопустимо, потому что главная ценность нашего продукта – совместная работа пользователей в режиме реального времени.
CI/CD процесс у нас — это git commit, git push, затем автоматическая сборка, автотестирование, деплой, релиз и мониторинг.
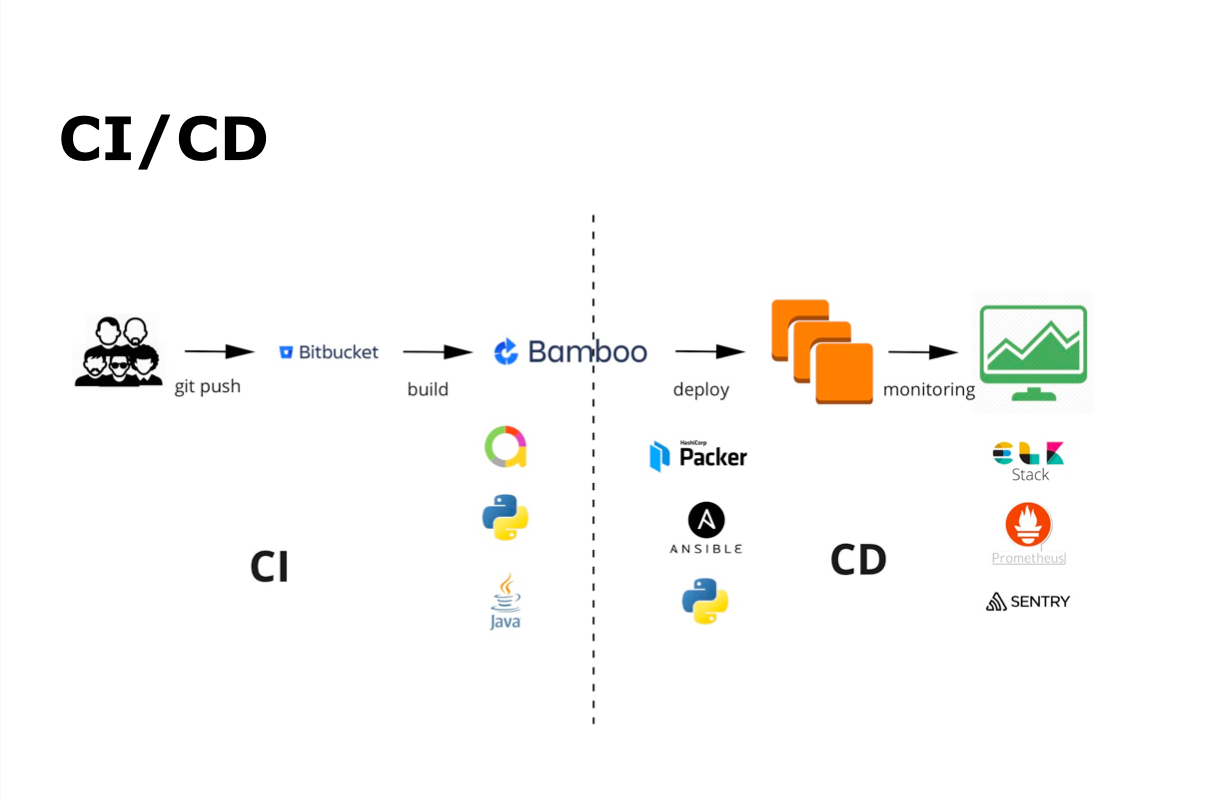
Для непрерывной интеграции мы используем Bamboo и Bitbucket. Для автоматического тестирования — Java и Python, а Allure — для отображения результатов автоматического тестирования. Для непрерывной доставки — Packer, Ansible и Python. Весь мониторинг осуществляется с помощью ELK Stack, Prometheus и Sentry.
Разработчики пишут код, добавляют его в репозиторий, после чего запускается автоматическая сборка и автоматическое тестирование. Параллельно внутри команды собираются апрувы от других разработчиков и проводится Code Review. Когда выполнены все обязательные процессы, в том числе автотесты, команда мержит билд в основную ветку, и начинается сборка билда основной ветки и его отправка на автоматическое тестирование. Весь этот процесс отлажен и выполняется командой самостоятельно.
Параллельно со сборкой билда и тестированием запускается сборка AMI-образа для Amazon. Для этого мы используем Packer от HashiCorp, отличный opensource-инструмент, который позволяет собирать образ виртуальной машины. Все параметры передаются в JSON с набором ключей конфигурирования. Основным параметром является builders, который указывает, для какого провайдера мы создаем образ (в нашем случае — для Amazon).
Важно, что мы не только создаём образ виртуальной машины, а заранее его конфигурируем с помощью Ansible: устанавливаем необходимые пакеты и делаем настройку конфигурации для запуска Java-приложения.
Раньше мы пользовались обычными Ansible playbook, но это привело к большому количеству повторяющегося кода, который стало тяжело поддерживать в актуальном состоянии. Мы меняли что-то в одном playbook, забывали это сделать в другом и в результате сталкивались с проблемами. Поэтому мы начали использовать Ansible-roles. Мы сделали их максимально универсальными, чтобы использовать повторно в разных частях проекта и не перегружать код большими повторяющимися кусками. Например, роль «Monitoring» используем для всех типов серверов.
Со стороны Scrum-команд этот процесс выглядит максимально просто: команда получает в Slack уведомления о том, что билд и AMI-образ собраны.
Мы ввели пре-релизы, чтобы доставлять до пользователей изменения в продукте максимально быстро. На самом деле это канареечные релизы, которые позволяют безопасно тестировать новую функциональность на небольшом проценте пользователей.
Почему релизы называются канареечными? Раньше шахтеры, когда спускались в шахту, брали с собой канарейку. Если в шахте был газ, канарейка умирала, и шахтеры быстро поднимались на поверхность. Так и у нас: если с сервером что-то идёт не так, значит релиз не готов и мы можем быстро откатиться назад и большая часть пользователей ничего не заметит.
Как происходит запуск канареечного релиза:
На стороне Scrum-команд процесс запуска пре-релиза снова выглядит максимально просто: команда получает уведомления в Slack, что начался процесс, и через 7 минут новый сервер уже в работе. Дополнительно приложение посылает в Slack весь changelog изменений в релизе.
Чтобы этот барьер защиты и проверки надёжности сработал, Scrum-команды мониторят новые ошибки в Sentry. Это opensource-приложение для отслеживания ошибок в режиме реального времени. Sentry легко интегрируется с Java и имеет коннекторы c logback и log2j. При запуске приложения мы передаём в Sentry версию, на которой оно запущено, и при возникновении ошибки видим, в какой версии приложения она произошла. Это помогает Scrum-командам быстро реагировать на ошибки и быстро их исправлять.
Пре-релиз должен работать минимум 4 часа. За это время команда мониторит его работу и решает, можно ли выводить релиз на всех пользователей.
Несколько команд могут одновременно выводить свои релизы. Для этого они договариваются между собой, что попадает в пре-релиз и кто отвечает за конечный релиз. После этого команды либо совмещают все изменения в один пре-релиз, либо запускают несколько пре-релизов одновременно. Если все пре-релизы корректны, они выходят в качестве одного релиза на следующий день.
Мы делаем релиз ежедневно:
Всё построено с помощью Bamboo и Python-приложения. Приложение проверяет количество запущенных серверов и готовит к запуску такое же количество новых. Если серверов не хватает, они создаются из AMI-образа. На них разворачивается новая версия, запускается Java-приложение и сервера вводятся в работу.
При мониторинге Python-приложение с помощью Prometheus API проверяет количество открытых досок на новых серверах. Когда оно понимает, что всё работает исправно, то закрывает доступ на старые сервера и переводит пользователей на новые.
Процесс переноса пользователей между серверами отображается в Grafana. В левой половине графика отображаются серверы, запущенные на старой версии, в правой — на новой. Пересечение графиков — это момент переноса пользователей.

Команда наблюдает за ходом релиза в Slack. После окончания релиза весь changelog изменений публикуется в отдельном канале в Slack, а в Jira автоматически закрываются все задачи, связанные с этим релизом.
Состояние доски, на которой работают пользователи, мы храним в памяти приложения и постоянно сохраняем все изменения в базу данных. Для переноса доски на уровне кластерного взаимодействия мы загружаем её в память на новом сервере и посылаем клиентам команду на переподключение. В этот момент клиент отключается от старого сервера и подключается к новому. Через пару секунд пользователи видят надпись — Connection restored. При этом они продолжают работать и неудобств не замечают.
К чему мы пришли после десятка итераций:
Это стало возможным не сразу, мы много раз наступали на одни и те же грабли и набили много шишек. Хочу поделиться уроками, которые мы получили.
Сначала ручной процесс, и только потом его автоматизация. Первыми шагами не нужно углубляться в автоматизацию, потому что можно автоматизировать то, что в итоге не пригодиться.
Ansible – хорошо, но Ansible roles – лучше. Мы сделали наши роли максимально универсальными: избавились от повторяющегося кода, благодаря чему они несут только ту функциональность, которую должны нести. Это позволяет существенно экономить время за счёт переиспользования ролей, которых у нас уже более 50.
Переиспользуйте код в Python и разбивайте его на отдельные библиотеки и модули. Это помогает ориентироваться в сложных проектах и быстрее погружать в них новых людей.
Процесс невидимого деплоя у нас ещё не закончен. Вот некоторые следующие шаги:
Сначала про нашу инфраструктуру
Наша команда разработки — это 60 человек, которые делятся на Scrum-команды, среди которых есть и команда DevOps. Большинство Scrum-команд поддерживают текущую функциональность продукта и придумывают новые фичи. Задача DevOps — создавать и поддерживать инфраструктуру, которая помогает приложению работать быстро и надёжно и позволяет командам быстро доставлять новый функционал до пользователей.
Наше приложение — это бесконечная онлайн-доска. Оно состоит из трех слоев: сайт, клиент и сервер на Java, который является монолитным stateful-приложением. Приложение держит постоянное web-socket подключение с клиентами, а каждый сервер держит в памяти кэш открытых досок.
Вся инфраструктура – более 70 серверов — находится в Amazon: более 30 серверов с нашим Java-приложением, веб-серверы, серверы баз данных, брокеры и многое другое. С ростом функциональности всё это необходимо регулярно обновлять, не нарушая работы пользователей.
Обновлять сайт и клиент просто: заменяем старую версию на новую, и при следующем обращении пользователь получает новый сайт и новый клиент. Но если мы сделаем так при релизе сервера, то получим downtime. Для нас это недопустимо, потому что главная ценность нашего продукта – совместная работа пользователей в режиме реального времени.
Как у нас выглядит CI/CD процесс
CI/CD процесс у нас — это git commit, git push, затем автоматическая сборка, автотестирование, деплой, релиз и мониторинг.
Для непрерывной интеграции мы используем Bamboo и Bitbucket. Для автоматического тестирования — Java и Python, а Allure — для отображения результатов автоматического тестирования. Для непрерывной доставки — Packer, Ansible и Python. Весь мониторинг осуществляется с помощью ELK Stack, Prometheus и Sentry.
Разработчики пишут код, добавляют его в репозиторий, после чего запускается автоматическая сборка и автоматическое тестирование. Параллельно внутри команды собираются апрувы от других разработчиков и проводится Code Review. Когда выполнены все обязательные процессы, в том числе автотесты, команда мержит билд в основную ветку, и начинается сборка билда основной ветки и его отправка на автоматическое тестирование. Весь этот процесс отлажен и выполняется командой самостоятельно.
AMI-образ
Параллельно со сборкой билда и тестированием запускается сборка AMI-образа для Amazon. Для этого мы используем Packer от HashiCorp, отличный opensource-инструмент, который позволяет собирать образ виртуальной машины. Все параметры передаются в JSON с набором ключей конфигурирования. Основным параметром является builders, который указывает, для какого провайдера мы создаем образ (в нашем случае — для Amazon).
"builders": [{
"type": "amazon-ebs",
"access_key": "{{user `aws_access_key`}}",
"secret_key": "{{user `aws_secret_key`}}",
"region": "{{user `aws_region`}}",
"vpc_id": "{{user `aws_vpc`}}",
"subnet_id": "{{user `aws_subnet`}}",
"tags": {
"releaseVersion": "{{user `release_version`}}"
},
"instance_type": "t2.micro",
"ssh_username": "ubuntu",
"ami_name": "packer-board-ami_{{isotime \"2006-01-02_15-04\"}}"
}],
Важно, что мы не только создаём образ виртуальной машины, а заранее его конфигурируем с помощью Ansible: устанавливаем необходимые пакеты и делаем настройку конфигурации для запуска Java-приложения.
"provisioners": [{
"type": "ansible",
"playbook_file": "./playbook.yml",
"user": "ubuntu",
"host_alias": "default",
"extra_arguments": ["--extra_vars=vars"],
"ansible_env_vars": ["ANSIBLE_HOST_KEY_CHECKING=False", "ANSIBLE_NOCOLOR=True"]
}]
Ansible-roles
Раньше мы пользовались обычными Ansible playbook, но это привело к большому количеству повторяющегося кода, который стало тяжело поддерживать в актуальном состоянии. Мы меняли что-то в одном playbook, забывали это сделать в другом и в результате сталкивались с проблемами. Поэтому мы начали использовать Ansible-roles. Мы сделали их максимально универсальными, чтобы использовать повторно в разных частях проекта и не перегружать код большими повторяющимися кусками. Например, роль «Monitoring» используем для всех типов серверов.
- name: Install all board dependencies
hosts: all
user: ubuntu
become: yes
roles:
- java
- nginx
- board-application
- ssl-certificates
- monitoring
Со стороны Scrum-команд этот процесс выглядит максимально просто: команда получает в Slack уведомления о том, что билд и AMI-образ собраны.
Пре-релизы
Мы ввели пре-релизы, чтобы доставлять до пользователей изменения в продукте максимально быстро. На самом деле это канареечные релизы, которые позволяют безопасно тестировать новую функциональность на небольшом проценте пользователей.
Почему релизы называются канареечными? Раньше шахтеры, когда спускались в шахту, брали с собой канарейку. Если в шахте был газ, канарейка умирала, и шахтеры быстро поднимались на поверхность. Так и у нас: если с сервером что-то идёт не так, значит релиз не готов и мы можем быстро откатиться назад и большая часть пользователей ничего не заметит.
Как происходит запуск канареечного релиза:
- Команда разработчиков в Bamboo нажимает на кнопку > вызывается Python-приложение, которое запускает пре-релиз.
- Оно создаёт новый instance в Amazon из подготовленного заранее AMI-образа с новой версией приложения.
- Instance добавляется в необходимые target groups и load balancers.
- С помощью Ansible настраивается индивидуальная конфигурация для каждого instance.
- Пользователи работают с новой версией Java-приложения.
На стороне Scrum-команд процесс запуска пре-релиза снова выглядит максимально просто: команда получает уведомления в Slack, что начался процесс, и через 7 минут новый сервер уже в работе. Дополнительно приложение посылает в Slack весь changelog изменений в релизе.
Чтобы этот барьер защиты и проверки надёжности сработал, Scrum-команды мониторят новые ошибки в Sentry. Это opensource-приложение для отслеживания ошибок в режиме реального времени. Sentry легко интегрируется с Java и имеет коннекторы c logback и log2j. При запуске приложения мы передаём в Sentry версию, на которой оно запущено, и при возникновении ошибки видим, в какой версии приложения она произошла. Это помогает Scrum-командам быстро реагировать на ошибки и быстро их исправлять.
Пре-релиз должен работать минимум 4 часа. За это время команда мониторит его работу и решает, можно ли выводить релиз на всех пользователей.
Несколько команд могут одновременно выводить свои релизы. Для этого они договариваются между собой, что попадает в пре-релиз и кто отвечает за конечный релиз. После этого команды либо совмещают все изменения в один пре-релиз, либо запускают несколько пре-релизов одновременно. Если все пре-релизы корректны, они выходят в качестве одного релиза на следующий день.
Релизы
Мы делаем релиз ежедневно:
- Вводим новые сервера в работу.
- Мониторим активность пользователей на новых серверах с помощью Prometheus.
- Закрываем доступ новых пользователей на старые сервера.
- Перебрасываем пользователей со старых серверов на новые.
- Выключаем старые сервера.
Всё построено с помощью Bamboo и Python-приложения. Приложение проверяет количество запущенных серверов и готовит к запуску такое же количество новых. Если серверов не хватает, они создаются из AMI-образа. На них разворачивается новая версия, запускается Java-приложение и сервера вводятся в работу.
При мониторинге Python-приложение с помощью Prometheus API проверяет количество открытых досок на новых серверах. Когда оно понимает, что всё работает исправно, то закрывает доступ на старые сервера и переводит пользователей на новые.
import requests
PROMETHEUS_URL = 'https://prometheus'
def get_spaces_count():
boards = {}
try:
params = {
'query': 'rtb_spaces_count{instance=~"board.*"}'
}
response = requests.get(PROMETHEUS_URL, params=params)
for metric in response.json()['data']['result']:
boards[metric['metric']['instance']] = metric['value'][1]
except requests.exceptions.RequestException as e:
print('requests.exceptions.RequestException: {}'.format(e))
finally:
return boards
Процесс переноса пользователей между серверами отображается в Grafana. В левой половине графика отображаются серверы, запущенные на старой версии, в правой — на новой. Пересечение графиков — это момент переноса пользователей.
Команда наблюдает за ходом релиза в Slack. После окончания релиза весь changelog изменений публикуется в отдельном канале в Slack, а в Jira автоматически закрываются все задачи, связанные с этим релизом.
Что такое перенос пользователей
Состояние доски, на которой работают пользователи, мы храним в памяти приложения и постоянно сохраняем все изменения в базу данных. Для переноса доски на уровне кластерного взаимодействия мы загружаем её в память на новом сервере и посылаем клиентам команду на переподключение. В этот момент клиент отключается от старого сервера и подключается к новому. Через пару секунд пользователи видят надпись — Connection restored. При этом они продолжают работать и неудобств не замечают.
Чему мы научились, пока делали деплой невидимым
К чему мы пришли после десятка итераций:
- Scrum-команда сама проверяет свой код.
- Scrum-команда сама решает, когда запустить пре-релиз и вывести часть изменений на новых пользователей.
- Scrum-команда сама решает, готов ли её релиз к выходу на всех пользователей.
- Пользователи продолжают работать и ничего не замечают.
Это стало возможным не сразу, мы много раз наступали на одни и те же грабли и набили много шишек. Хочу поделиться уроками, которые мы получили.
Сначала ручной процесс, и только потом его автоматизация. Первыми шагами не нужно углубляться в автоматизацию, потому что можно автоматизировать то, что в итоге не пригодиться.
Ansible – хорошо, но Ansible roles – лучше. Мы сделали наши роли максимально универсальными: избавились от повторяющегося кода, благодаря чему они несут только ту функциональность, которую должны нести. Это позволяет существенно экономить время за счёт переиспользования ролей, которых у нас уже более 50.
Переиспользуйте код в Python и разбивайте его на отдельные библиотеки и модули. Это помогает ориентироваться в сложных проектах и быстрее погружать в них новых людей.
Следующие шаги
Процесс невидимого деплоя у нас ещё не закончен. Вот некоторые следующие шаги:
- Позволить командам выполнять не только пре-релизы, но и все релизы.
- Сделать автоматические откаты в случае ошибок. Например, пре-релиз должен автоматически откатываться, если в Sentry обнаружены критичные ошибки.
- Полностью автоматизировать релиз при отсутствии ошибок. Если на пре-релизе не было ни одной ошибки, значит он может автоматически выкатываться дальше.
- Добавить автоматическое сканирование кода на потенциальные ошибки безопасности.
alex005
Не подскажите, что планируете использовать для автоматического анализа безопасности? Есть ли универсальные инструменты, например под node.js?