
Обнаружение атак является важной задачей в информационной безопасности на протяжении десятилетий. Первые известные примеры реализации IDS относятся к началу 1980-х годов.
Спустя несколько десятилетий сформировалась целая индустрия средств для обнаружения атак. На данный момент существуют различные виды продуктов, такие как IDS, IPS, WAF, брандмауэры, большинство из которых предлагает обнаружение атак на основе правил. Идея использовать техники выявления аномалий для обнаружения атак на основе статистики на производстве не кажется такой реалистичной, как в прошлом. Или всё-таки?..
Обнаружение аномалий в веб-приложениях
Первые межсетевые экраны, специально предназначенные для обнаружения атак на веб-приложения, начали появляться на рынке в начале 1990-х годов. С тех пор значительно изменились как методы атак, так и механизмы защиты, и злоумышленники в любой момент могут оказаться на шаг впереди.
В настоящее время большинство WAF пытаются детектировать атаки следующим образом: существуют некоторые механизмы, основанные на правилах, которые встроены в обратный прокси-сервер. Наиболее ярким примером является mod_security, модуль WAF для веб-сервера Apache, который был разработан в 2002 году. Выявление атак с помощью правил имеет ряд недостатков; например, правила не могут обнаружить атаки нулевого дня, в то время как те же самые атаки могут быть легко обнаружены экспертом, и это неудивительно, ведь человеческий мозг работает совсем не так, как набор регулярных выражений.
С точки зрения WAF атаки можно разделить на те, которые мы можем обнаружить по последовательности запросов, и те, где для решения достаточно одного HTTP-запроса (ответа). Наше исследование сосредоточено на обнаружении атак последнего типа — SQL Injection, Cross Site Scripting, XML External Entities Injection, Path Traversal, OS Commanding, Object Injection и др.
Но сначала давайте проверим себя.
Что подумает эксперт, когда увидит следующие запросы?
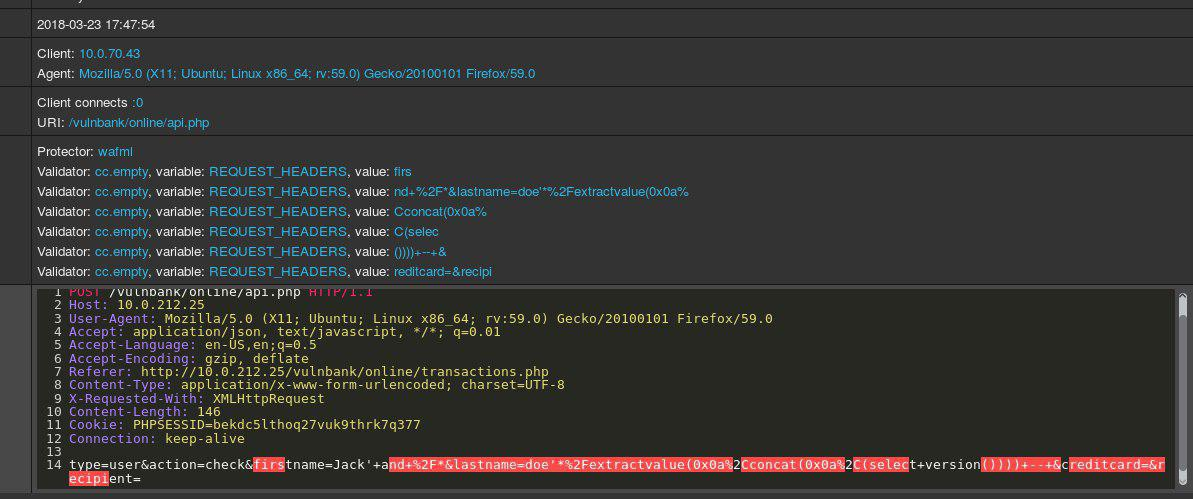
Взгляните на пример HTTP-запроса к приложениям:
Если бы вам было дано задание обнаруживать вредоносные запросы к какому-либо приложению, скорее всего, вам бы хотелось некоторое время понаблюдать за обычным поведением пользователей. Изучив запросы к нескольким конечным точкам приложения, вы можете получить общее представление о структуре и функциях неопасных запросов.
Теперь вам на анализ попадает такой запрос:

Сразу бросается в глаза, что здесь что-то не так. Потребуется некоторое время, чтобы понять, что здесь действительно такое, и как только вы определите часть запроса, которая кажется аномальной, вы можете начать думать о том, какой это тип атаки. По сути, наша цель состоит в том, чтобы заставить наш «искусственный интеллект для обнаружения атак» работать таким же образом — напоминать человеческое мышление.
Неочевидным моментом остается то, что некоторый трафик, который на первый взгляд выглядит вредоносным, может быть нормальным для определенного веб-сайта.
К примеру, давайте рассмотрим следующие запросы:
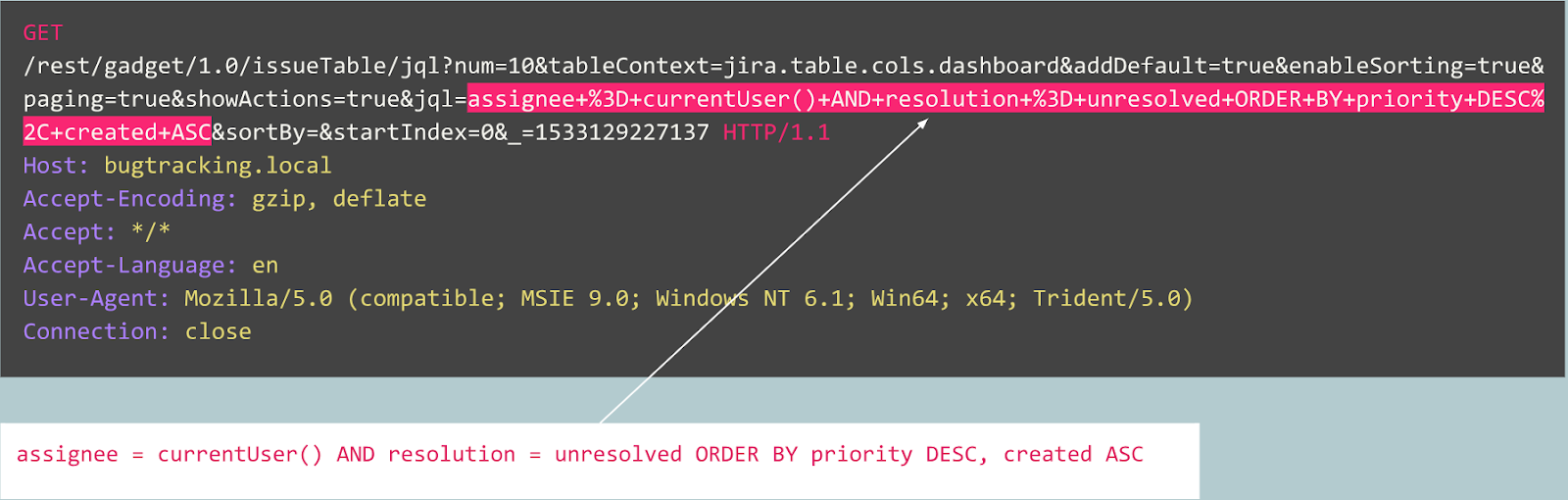
Является ли этот запрос аномальным?
Фактически этот запрос является публикацией бага в трекере Jira и является типичным для этого сервиса, что означает, что запрос является ожидаемым и нормальным.
Теперь рассмотрим следующий пример:

На первый взгляд, запрос выглядит как обычная регистрация пользователя на веб-сайте, основанном на Joomla CMS. Однако запрашиваемая операция — это user.register вместо обычной registration.register. Первый вариант устарел и содержит уязвимость, позволяющую любому зарегистрироваться в качестве администратора. Эксплойт для этой уязвимости известен как Joomla < 3.6.4 Account Creation / Privilege Escalation (CVE-2016-8869, CVE-2016-8870).

С чего мы начинали
Конечно, сперва мы изучили существующие решения проблемы. Различные попытки создания алгоритмов детектирования атак, основанных на статистике или машинном обучении, предпринимались на протяжении десятилетий. Одним из наиболее популярных подходов является решение задачи классификации, когда классы представляют собой что-то вроде «ожидаемые запросы», «SQL-инъекций», XSS, CSRF и т. д. Таким способом можно достичь некоторой хорошей точности для набора данных с помощью классификатора, однако такой подход не решает очень важные с нашей точки зрения проблемы:
- Выбор класса ограничен и определен заранее. Что, если ваша модель в процессе обучения представлена тремя классами, скажем «нормальные запросы», SQLi и XSS, а во время эксплуатации системы она сталкивается с CSRF или с атакой нулевого дня?
- Значение этих классов. Предположим, вам нужно защитить десять клиентов, каждый из которых запускает совершенно разные веб-приложения. Для большинства из них вы не представляете, как на самом деле выглядит SQL-инъекция для их приложения. Это означает, что вам придется каким-то образом искусственно создавать наборы данных для обучения. Такой подход неоптимален, поскольку в конечном итоге вы будете учиться на данных, отличающихся распределением от реальных данных.
- Интерпретируемость результатов модели. Хорошо, модель выдала результат «SQL-инъекция», и что теперь? Вы и, что важнее, ваш клиент, который первым видит предупреждение и обычно не является экспертом по веб-атакам, должны угадать, какую часть запроса ваша модель считает вредоносной.
Помня обо всех этих проблемах, мы все равно решили попробовать обучить модель классификатора.
Поскольку протокол HTTP — текстовый протокол, было очевидно, что нам нужно взглянуть на современные классификаторы текста. Одним из хорошо известных примеров является сентимент-анализ в наборе данных обзора фильмов IMDB. Некоторые решения используют RNN для классификации обзоров. Мы решили попробовать аналогичную модель с RNN-архитектурой с некоторыми небольшими отличиями. Например, в RNN-архитектуре на естественном языке применяется векторное представление слов, однако неясно, какие слова встречаются в неестественном языке, таком как HTTP. Поэтому мы решили для нашей задачи использовать векторное представление символов.
Готовые представления не решают нашу проблему, поэтому мы использовали простые отображения символов в числовые коды с несколькими внутренними маркерами, такими как
GO и EOS.После завершения разработки и тестирования модели все предсказанные ранее проблемы стали очевидными, но по крайней мере наша команда перешла от бесполезных предположений к некоторому результату.
Что дальше?
Далее мы решили сделать некоторые шаги в направлении интерпретируемости результатов модели. В какой-то момент мы натолкнулись на механизм внимания «Attention» и начали имплементировать его в нашу модель. И это дало многообещающие результаты. Теперь наша модель начала выводить не только метки классов, но и коэффициенты внимания для каждого символа, который мы передали модели.
Теперь мы могли визуализировать и показать в веб-интерфейсе точное место, где обнаружена атака «SQL-инъекция». Это был хороший результат, однако другие проблемы из списка все еще оставались нерешенными.
Было очевидно, что нам следует продолжать двигаться в направлении извлечения выгоды из механизма внимания и отойти от задачи классификации. После прочтения большого количества связанных исследований о моделях последовательностей (о механизмах внимания [2], [3], [4], о векторном представлении, об архитектурах автоэнкодеров) и экспериментов с нашими данными, мы смогли создать модель обнаружения аномалий, которая в конечном итоге работала бы более или менее таким образом, как это делает эксперт.
Автоэнкодеры
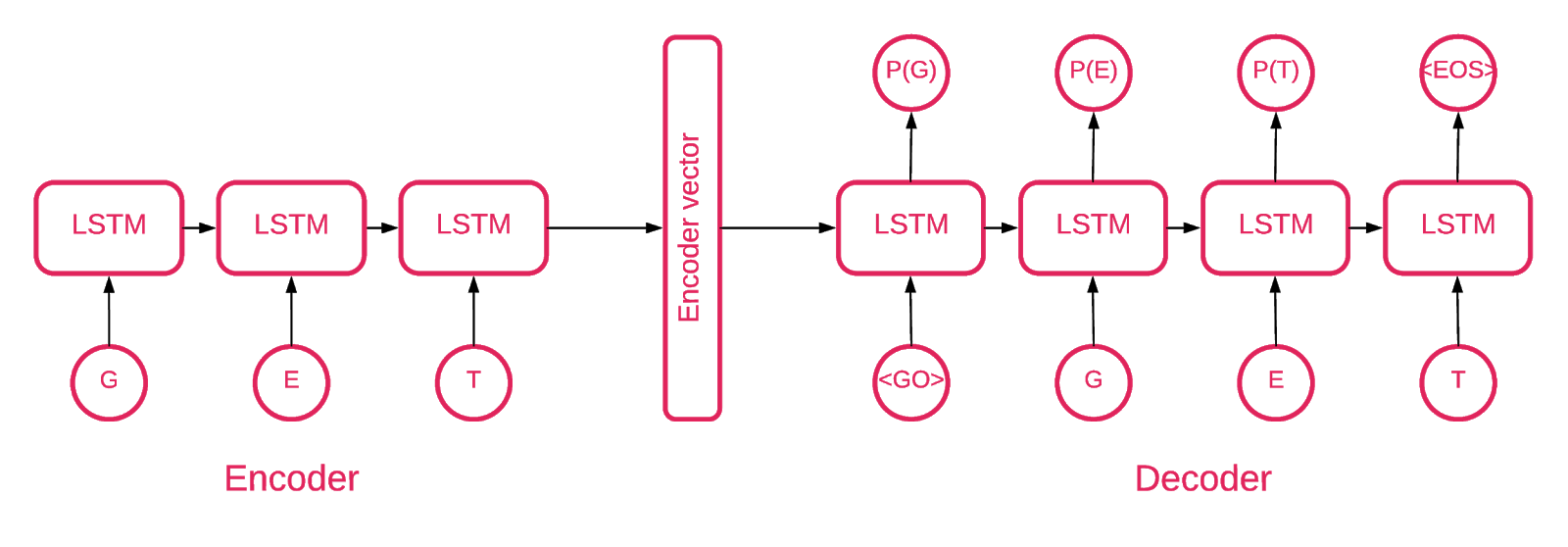
В какой-то момент стало ясно, что архитектура Seq2Seq [5] больше всего подходит для нашей задачи.
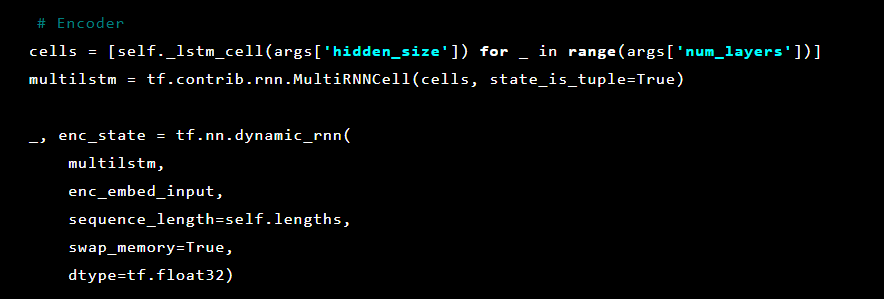
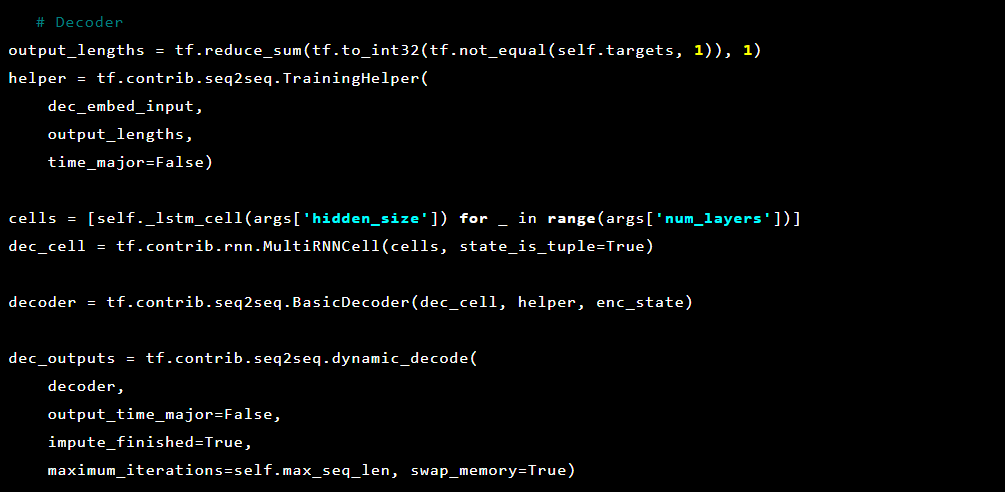
Модель Seq2Seq [7] состоит из двух многослойных LSTM — кодера и декодера. Кодер отображает входную последовательность в вектор фиксированной длины. Декодер декодирует целевой вектор, используя выход кодера. При обучении автоэнкодер представляет собой модель, в которой целевые значения устанавливаются такими же, как входные значения.
Идея состоит в том, чтобы научить сеть декодировать вещи, которые она видела, или, другими словами, приближать тождественное отображение. Если обученному автоэнкодеру дают аномальный образец, он, вероятно, воссоздает его с высокой степенью ошибки, просто потому, что никогда его не видел.
Решение
Наше решение состоит из нескольких частей: инициализация модели, обучение, прогнозирование и проверка. Большая часть кода, расположенного в репозитории, мы надеемся, не требует пояснений, поэтому сосредоточимся только на важных частях.
Модель создается как экземпляр класса Seq2Seq, который имеет следующие аргументы конструктора:
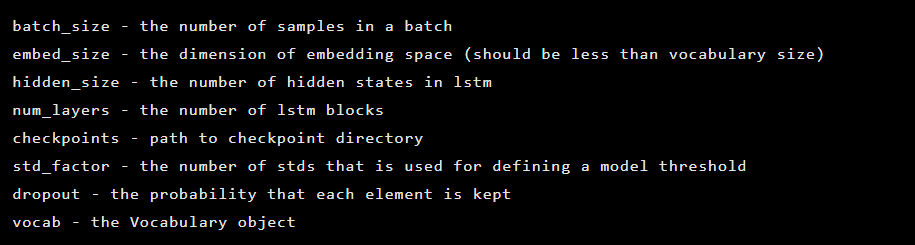
Далее инициализируются слои автоэнкодера. Сначала кодер:
Затем декодер:
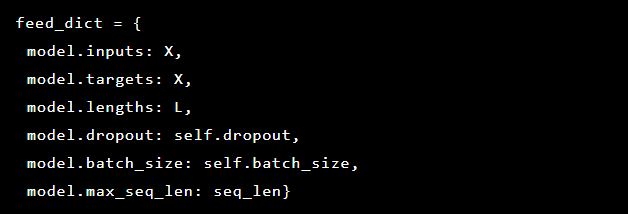
Так как проблема, которую мы решаем, заключается в обнаружении аномалий, целевые значения и входные данные совпадают. Таким образом, наш feed_dict выглядит так:
После каждой эпохи лучшая модель сохраняется в качестве контрольной точки, которую затем можно загрузить. В целях тестирования было создано веб-приложение, которое мы защитили моделью, чтобы проверить, окажутся ли реальные атаки успешными.
Вдохновленные механизмом внимания, мы попытались применить его к модели автоэнкодера, чтобы отмечать аномальные части данного запроса, но заметили, что вероятности, выводимые из последнего слоя, работают лучше.

На этапе тестирования на нашей отложенной выборке мы получили очень хорошие результаты: precision и recall близки к 0,99. И ROC-кривая стремится к 1. Выглядит потрясающе, не правда ли?
Результаты
Предлагаемая модель автоэнкодера Seq2Seq оказалась способной обнаруживать аномалии в HTTP-запросах с очень высокой точностью.
Эта модель действует подобно человеку: изучает только «нормальные» запросы пользователя к веб-приложению. А когда обнаруживает аномалии в запросах, то выделяет точное место запроса, которое считает аномальным.
Мы протестировали эту модель на некоторых атаках на тестовом приложении и результаты оказались многообещающими. Например, изображение выше показывает, как наша модель обнаружила SQL-инъекцию, разделенную на два параметра в веб-форме. Такие SQL-инъекции называются фрагментированными: части полезных данных атаки доставляются в нескольких HTTP-параметрах, что затрудняет обнаружение для классических WAF на основе правил, поскольку они обычно проверяют каждый параметр по отдельности.
Код модели и данные обучения и теста опубликованы в виде ноутбука Jupyter, чтобы каждый мог воспроизвести наши результаты и предложить улучшения.
В заключение
Мы полагаем, что наша задача была довольно нетривиальной. Нам бы хотелось при минимуме затраченных усилий (в первую очередь — чтобы избежать ошибок из-за переусложнения решения) придумать такой способ детектирования атак, который бы как по мановению волшебной палочки научился решать сам, что хорошо, а что плохо. Во вторую очередь, хотелось избежать проблем с человеческим фактором, когда именно эксперт решает, что является признаком атаки, а что нет. Подводя итог, хочется отметить, что автоэнкодер с архитектурой Seq2Seq для задачи поиска аномалий, на наш взгляд и для нашей проблемы, справился отлично.
Также нам хотелось решить проблему с интерпретируемостью данных. Обычно пользуясь сложными нейросетевыми архитектурами сделать это очень сложно. В череде преобразований в итоге уже сложно сказать, что именно, какая часть данных повлияла на решение больше всего. Однако после переосмысления подхода к интерпретации данных моделью для нас оказалось достаточным получать вероятности для каждого символа с последнего слоя.
Хочется отметить, что это не совсем продакшн-версия. Мы не можем раскрывать детали имплементации данного подхода в реальный продукт, и хотим предупредить, что просто взять и встроить это решение в какой-то продукт не получится.
Репозиторий на GitHub: goo.gl/aNwq9U
Авторы: Александра Мурзина (murzina_a), Ирина Степанюк (GitHub), Федор Сахаров (GitHub), Арсений Реутов (Raz0r)
Ссылки:
Комментарии (5)

actorai
06.02.2019 17:04сколько запросов в секунду классифицирует сеть на CPU? Это ключевой вопрос, потому что даже если использовать эту сеть как WAF для небольшого хостинга, придется обрабатывать десятки тысяч запросов в секунду. Какие для этого мощности потребуются?
murzina_a
06.02.2019 18:24Еще раз хочется уточнить, что представленное решение — попробованный нами подход к задаче детекта атак. И конкретно для такой версии мы, конечно, не замеряли производительность. Данное решение — не продакшн версия по многим причинам!
В любом случае предполагается, что модель, как компонент веб-файрвола, может скалироваться как и остальные его части в зависимости от нагрузки. О продакшн версии как-нибудь в другой статье.
Ishitori
09.02.2019 06:43Спасибо за статью. К сожалению, я не все понял, и хотел уточнить у Вас кое-какие детали.
Каким образом Вы с помощью автоэнкодера решаете аномален ли запрос или нет? Выдаёт ли Ваша модель ответ вида Да/Нет? Расскажите подробнее как выглядит ответ для НЕ аномального запроса? Или это отдельная модель на основе кодера — используете мультатскинг?
Когда декодер выдаёт результат, то длина выходного вектора в общем то может не равняться длине входа. Как Вы потом эти вероятности маппите на исходный входной текст запроса, если размеры не совпали?
Допустим вероятности получены и их количество равно количеству символов входного запроса. Как Вы определяете трешхолд вероятности выше «нормальной», что символ должен быть помечена как аномальный символ? Просто используете 0.5?
Как Вы решали проблему несбалансированных классов примтреннировке? Ведь аномальных запросов намного меньше, чем нормальных и модель, не так ли?
Как выглядела Ваша тренировочная выборка — Вы вручную разметили в анормальных запросах аномальные куски текста?
ElvenSailor
Какова вероятность того, что данные, на которых обучают сеть, и которые предполагаемо чистые, уже содержат реальную вредную активность?
murzina_a
да, вероятность попадания запросов с атаками в выборку для обучения есть, но тестирование модели происходит на заготовленной отложенной выборке и если после обучения модель на заготовленных чистых данных дает плохой результат — повод не деплоить конкретно эту версию.
В продакшн версии у нас на обучение идут только те запросы, которые прошли стандартные правила и прошлую версию модели.