
«Да я роботов по приколу изобретаю!» Рик Санчес
Многим известно, что в 2019 году АНБ решило предоставить открытый доступ к своей утилите для дизассемблирования (реверс-инжиниринга) под названием Ghidra. Эта утилита стала популярной в среде исследователей благодаря высокой «всеядности». Данный материал открывает цикл статей, посвященных плагину ghidra_nodejs для Ghidra, разработанному нашей командой (https://github.com/PositiveTechnologies/ghidra_nodejs). Задача плагина — десериализовать содержимое jsc-файлов, дизассемблировать байткод функций и декомпилировать их. В первой статье мы обсудим сущности и байткод движка V8, а также тезисно опишем сам плагин, про который подробно расскажем в последующих статьях.
Рано или поздно все сталкиваются с программами на языке JavaScript, их так и называют скриптами. JavaScript — это полноценный язык со своим стандартом ECMA Script, скрипты которого выполняются не только в браузере, но и на сервере.
Скрипты исполняются с помощью специальной программы, которую называют движком (engine) JavaScript. За годы движкостроения их понапридумывали предостаточно: V8, SpiderMonkey, Chakra, Rhino, KJS, Nashorn и т. д.
Скрипты выглядят как простой текст, написанный на языке JavaScript, то есть исходный код скрипта доступен всем и каждому. Поэтому любой движок выполняет следующие операции:
читает и синтаксически разбирает текст скрипта в некое дерево сущностей,
компилирует сущности в машинный код,
исполняет машинный код —
или:
читает и синтаксически разбирает текст скрипта в некое дерево сущностей,
компилирует сущности в байткод и сохраняет его в отдельном хранилище,
компилирует байткод в машинный код,
исполняет машинный код.
Повторим, скрипты выглядят и распространяются как простой текст. Поэтому для разработчиков серверных приложений на JavaScript актуален вопрос — как защитить свой скрипт от любопытных глаз. Самый распространенный способ — обфускация исходного кода.
С другим способом защиты кода столкнулись авторы статьи в одном из проектов. Это было серверное приложение JavaScript, запускаемое программной платформой Node.js. Оно выглядело как бинарный файл с расширением «.jsc», который представлял собой сериализованный байткод V8 (как выяснится в дальнейшем, это штатная возможность Node.js, используемая пакетом bytenode). Сериализация, напомним, это сохранение состояния объекта в последовательность байтов. Наша задача состояла в том, чтобы исследовать функции данного jsc-приложения на наличие уязвимостей и недокументированных возможностей.
Готовых инструментов для работы с сериализованными jsc-файлами не было найдено. Конечно, кроме самой Node.js. Для этого в Node.js применяется флаг «--print-bytecode». Но результат, предоставляемый Node.js, оставляет желать лучшего. Голый дизассемблер функций без перекрестных ссылок и без дополнительной информации по объектам — плохой помощник для полноценного реверс-инжиниринга при статическом анализе кода. Поэтому пришлось изобретать велосипед.
Node.js + bytenode
«Хватит глубоко копать, просто удивись!» Рик Санчес
Платформа Node.js — это JavaScript-окружение, построенное на движке Chrome V8. Платформа Node.js — это открытый проект. Чаще всего Node.js применяется для создания серверных приложений на языке JavaScript. Многие крупные компании используют эту платформу в своих проектах.
Одной из фишек Node.js является возможность добавлять пакеты (библиотеки с кодом) в свой скрипт. Утилита npm (node package manager — менеджер пакетов Node.js) позволяет получить доступ более чем к полумиллиону опенсорсных пакетов.
Пакет bytenode от Osama Abbas позволяет сохранить исходный скрипт в виде сериализованного представления байткода V8, которое так же замечательно выполняется, как и сам скрипт.

Так что же это за сериализация и байткод в движке V8? Посмотрим на конвейер компиляции V8 (на тот, который появился в 2017 году).

Процитирую статью «Знай свой JIT: ближе к машине»:
«Раньше [до 2017 года] в схеме интерпретатора Ignition не было. Google изначально говорили о том, что интерпретатор не нужен — JavaScript и так достаточно компактный и интерпретируемый — мы ничего не выиграем. <...> В 2013—2014 году люди стали чаще использовать для выхода в интернет мобильные устройства, чем десктоп. В основном это не iPhone, а с устройств попроще — у них мало памяти и слабый процессор».
«Слабые» смартфоны стали тратить больше времени на анализ исходного кода скрипта, чем на его исполнение. И тогда появился интерпретатор Ignition. Введение байткода позволило снизить потребление памяти и накладные расходы на парсинг.
Байткод интерпретатора Ignition — это регистровая машина с аккумулятором. Включает в себя набор инструкций и регистров. Получается, что и байткод, и задействованные с ним объекты со своими классами хранятся внутри структур движка V8. Поэтому отпадает надобность постоянно анализировать исходный код скрипта. Сериализация — это способность движка V8 сохранить байткод и связанные с ним структуры в двоичном представлении. Десериализация (обратный процесс) позволяет двоичные данные преобразовать в байткод и связанные с ним объекты.
Пакет bytenode использует штатную возможность платформы Node.js — возможность получить сериализованный код. В Node.js компиляция происходит с помощью модуля vm и функции Script. Начиная с версии 5.7 модуль vm имеет свойство под названием produceCachedData в vm.Script. Это свойство позволяет сохранить байткод в кэше. Пример для версии выше 10:
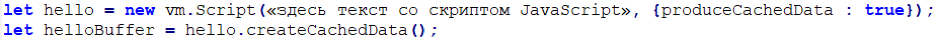
После выполнения данного кода в helloBuffer будут находится сериализованные данные.
Пакет bytenode сохраняет сериализованные данные в файле с расширением «jsc». С помощью этого же пакета файл с расширением «jsc» (далее будем называть такие файлы jsc-файлами) можно запустить на исполнение, как описано в статье «How to Compile Node.js Code Using Bytenode?».
Так вот. Jsc-файлы оказались хорошим способом скрыть исходный код скрипта от любопытных глаз.
Что делать?
«Wubba lubba dub dub». Рик Санчес
Чтение разнообразной литературы про Node.js и движок V8, статическое изучение исходников привело к следующим мыслям:
Необходим разборщик заголовков jsc-файлов.
Необходимо разобраться (попытаться) во внутренней кухне движка V8 — в его специфических объектах, в рамках которых создается байткод. Как результат — создать загрузчик для выбранного нами дизассемблера, который будет создавать похожие специфические объекты и отображать инструкции и операнды (желательно в формате как у Node.js, когда запускаем платформу с флагом «--print-bytecode» на jsc-файле).
Амбициозная мысль — попробовать написать декомпилятор для создаваемого байткода. То есть реализовать регистровую машину с аккумулятором, работающую с байткодом, в выхлоп С-подобного декомпилятора. Поэтому целевым дизассемблером была выбрана опенсорсная Ghidra с ее «всеядностью» в плане разных архитектур и с декомпилятором «из коробки».
Прежде чем стучаться в открытую дверь с табличкой «jsc-файл», попробуем описать некоторые понятия, касающиеся движка V8, вооружившись исходными кодами Node.js.
Вселенная V8
«Вселенная настолько велика, Морти, что ничего на свете не имеет значения». Рик Санчес
Устройство движка V8 непростое. Здесь только рассмотрим сущности, связанные с байткодом интерпретатора Ignition.
Isolate (изолятор) — независимая копия среды выполнения V8, включающая в себя собственную кучу. Два разных экземпляра Isolate работают параллельно, и их можно рассматривать как совершенно разные изолированные экземпляры среды выполнения V8.
Context (контекст для приложения) — выделенная область для переменных одного приложения JavaScript. Для каждого приложения JavaScript из числа работающих в одном и том же Isolate необходим свой контекст. Контекст применяется для того, чтобы приложения не мешали друг другу, например, путем изменения предоставленных встроенных объектов.
Closure (замыкание) — это функция, которая запоминает свои внешние переменные и может получить к ним доступ. В JavaScript все функции изначально являются замыканиями, проще говоря — все куски кода между фигурными скобками являются замыканиями. По сути, весь исходный код JavaScript — это набор различного кода в фигурных скобках, который можно представить в виде массива структур Closure. На рис. 2 показано, как замыкание выглядит в исходном коде, обрабатывается интерпретатором и сохраняется в сериализованном коде.

Для нас важный момент: на уровне объектов в сериализованном коде замыкание выглядит как объект SharedFunctionInfo. Анализ показал, что все сериализованные данные выглядят как матрешка из SharedFunctionInfo-объектов, которые ссылаются друг на друга.
При сериализации SharedFunctionInfo-объект выглядит как большая структура, которая объединяет разные сущности, необходимые для обработки байткода. На рис. 3 показаны некоторые из них.

Hidden map (скрытый класс). Все объекты, создаваемые интерпретатором (например, тот же SharedFunctionInfo), строятся не на пустом месте, а на основе скрытого класса (Map-класс), который содержит набор типовых свойств. Скрытые классы уже есть внутри движка, они создаются во время выполнения (runtime). Ссылки на них хранятся в массиве roots_ объекта Heap.

И когда происходит сериализация (или десериализация), ссылка на скрытый класс сохраняется как индекс массива roots_. В node.exe (для версии 8.16.0) индекс для скрытого класса kSharedFunctionInfoMapRootIndex равен 0x13 (см. рис. 5). Количество и содержимое элементов в roots_ могут меняться от версии к версии движка V8 в Node.js. Поэтому важно обращать внимание на версию движка V8 при десериализации jsc-файла.

LexicalEnvironment (лексическое окружение) — это хранилище для данных в памяти и механизм для извлечения этих данных при обращении. Окружение может быть внутренним (структура ScopeInfo) и внешним (структура OuterScopeInfo). Цитата (ссылка):
«Каждый раз, когда в программе вызывается функция, внутри интерпретатора создается специальный словарь LexicalEnvironment (лексическое окружение), привязанный к этому вызову. Все определения констант, переменных и прочего внутри функции автоматически записываются в словарь. Имя определения (идентификатор, то есть имя константы, переменной и так далее) становится ключом, а значение определения становится значением в словаре. К таким определениям относятся аргументы, константы, функции, переменные и т. д.
<...>
Внешним окружением по отношению к функции считается окружение, в котором функция была объявлена (а не вызвана!)».
И там же: «...интерпретатор производит поиск значения идентификатора не только в локальном лексическом окружении (в том, где используется идентификатор), но и во внешнем окружении. Поиск начинается с локального окружения, и если в нем не найден нужный идентификатор, то просмотр идет дальше, вплоть до уровня модуля, а затем и до глобального уровня».
В примере на рис. 6 происходит обращение в функции constructor к переменной errorMessages. В интерпретаторе функция constructor представлена структурой SharedFunctionInfo, имеющей ScopeInfo (локальные переменные) и OuterScopeInfo (внешние переменные). В данном случае OuterScopeInfo хранит адрес структуры ScopeInfo вышестоящей SharedFunctionInfo, где и находится объявление переменной errorMessages.

Built-in (встроенные функции) — встроенные функции движка V8. Сами по себе они могут быть реализованы разными способами (builtinKind) и размещаются в глобальном массиве (builtins) движка V8.

Расшифровка способов реализации перечисления builtinKind:
CPP — встроенная функция Builtin, написана на C++;
API — встроенная функция Builtin, написана на C++ с использованием API обратных вызовов (callbacks);
TFJ — встроенная функция Builtin, написана на Turbofan (JS linkage);
TFS — встроенная функция Builtin, написана на Turbofan (CodeStub linkage);
TFC — встроенная функция Builtin, написана на Turbofan (CodeStub linkage and custom descriptor);
TFH — встроенная функция Builtin, написана как обработчик для Turbofan (CodeStub linkage);
ASM — встроенная функция Builtin, написана на платформонезависимом ассемблере.
Среди встроенных функций могут быть и математические функции, и функции преобразования строк в числа, и другие. Встроенные функции напрямую вызываются из байткода — «StackCheck», «Construct», «ConsoleLog», «CreateGeneratorObject», «JsonParse» и т. п.
FunctionData (байткод) — это структура, которая хранит так называемый массив ConstantPool для констант и непосредственно сам байткод. Как говорилось ранее, интерпретатор V8 — это регистровая машина с аккумулятором. Интерпретатор использует следующие регистры (ниже показано написание регистров, принятое для отображения в листинге с байткодом):
«<this>», «<closure>», «<context>» — внутренние регистры интерпретатора, необходимые для его работы (грубо говоря, «<closure>» хранит ссылку на SharedFunctionInfo, «<context>» хранит ссылку на ScopeInfo);
регистр аккумулятора ACCU;
регистры аргументов a0, a1, a2… и регистры функции r0, r1, r2... Каждый регистр внутри байткода кодируется четырьмя байтами. Старший бит определяет тип регистра — аX или rX. Остальные биты — номер регистра. Поэтому количество регистров функций может быть до 0х7FFFFFFB штук, а регистров аргументов — 0х7FFFFFFE (лишь бы под хранение значений регистров в интерпретаторе хватило памяти).
Каждая инструкция байткода читает либо изменяет состояние аккумулятора ACCU. Операнды инструкции — это регистры r0, r1 и т. д., которые представляют собой либо индексы на ConstantPool (в дизасме они выглядят как числа в квадратных скобках), либо индексы на переменные из массивов StackLocal/ContextLocal структур лексического окружения ScopeInfo/OuterScopeInfo.
Давайте оценим масштаб разбора FunctionData на примере дизассемблирования функции-конструктора для класса GenericError наследуемого от базового класса Error. На рис. 8 слева показан исходный код конструктора класса GenericError, справа — его байткод в SharedFunctionInfo-объекте.

Структура SharedFunctionInfo для функции-конструктора будет иметь имя «GenericError». Поле Flags структуры ScopeInfo сообщит нам, что это функция является конструктором класса (Flags.FunctionKind = DerivedConstructor) и у нее есть внешнее лексическое окружение (Flags.HasOuterScopeInfo = True). Функция принимает два аргумента a0 («code») и a1 («err»). Функция имеет внутренние локальные переменные StackLocals: r0 (специальное имя «.new.target»), r1 (специальное имя «.this_function»), r2 (переменная с именем «message»). Специальные имена всегда начинаются с точки, и они необходимы для движка V8 при создании машинного кода из байткода. Функция не имеет контекстных переменных ContextLocals. Если StackLocals являются локальными переменными, то ContextLocals — это локальные контекстные переменные. Это связано с тем, что движок V8 рассматривает каждую SharedFunctionInfo как некий контекст со своим байткодом и локальными переменными. И мы можем обращаться через контекст к переменным текущей функции, или к контексту другой функции, или к специально созданному контексту (особенно когда применяются асинхронные вызовы async/await).
Далее следуют инструкции байткода. Инструкции идут в той же последовательности, как и строки в исходном коде скрипта. Краткое описание каждой инструкции можно найти в исходном коде Node.js.

В нашей версии движка V8 было 167 инструкций, часто используемых — несколько десятков. Своеобразность инструкций байткода связана с тем, что байткод не является самоцелью всего движка, он лишь трамплин для создания машинного кода компилятором TurboFan. Поэтому некоторые специфические операнды байткода и необычные инструкции избыточны — их задача более строго и типизированно отражать исходный код скрипта. То есть, имея на руках дизасм байткода, МОЖНО восстановить исходный код скрипта. Вручную можно. Наша задача — попробовать сделать это автоматически с помощью декомпилятора.
Заголовок jsc-файла
«Расслабься, Морти! Это всего лишь набор нулей и единиц». Рик Санчес
Сразу скажем, что изучалась версия Node.js 8.16 (версия движка V8 — 6.2.414.77). Все версии программной платформы доступны на официальном сайте.

Jsc-файл состоит из заголовка и сериализованных данных. В таблице показана структура заголовка.

На что стоит обратить внимание? Во-первых, на поле kVersionHash, которое хранит хеш от версии движка V8, представленной в виде строки. Например, для 6.2.414.77 (этот движок используется в Node.js версии 8.16.0) значение хеша будет 0x35BA122E. Поле kVersionHash является одним из обязательным полей, которое проверяет Node.js при запуске jsc-файла. Движок V8 не стоит на месте, выходят новые релизы, со временем меняется формат сериализованных данных. Поэтому отслеживание версий при десериализации является обязательным условием.
Во-вторых, стоит присмотреться к полю kNumReservationsOffset. Это количество записей в разделе «Reservation Data» (фрагменты кучи, управляемые движком V8). Каждая запись — это количество байтов для выделенного куска памяти на куче. Поясним, зачем и почему это так. При анализе скрипта (еще на этапе компиляции в байткод) все значения JavaScript в движке V8 представляются как объекты и размещаются на куче, независимо от того, являются ли они объектами, массивами, числами или строками. Объекты размещаются на куче друг за другом стык в стык.
При сериализации объекты специальном образом обрабатываются и записываются в бинарный поток в том же порядке, как они расположены на куче. И если объект уже был сериализован и он снова встречается (у разных объектов могут быть общие объекты; например, какие-нибудь объекты-строки с одинаковым значением), то в бинарном потоке объект не дублируется, а записывается как ссылка на его первое вхождение. И эта ссылка будет числом — смещением в куче (такая техника называется Pointer Compression, когда указатель можно записать в виде смещения относительно базы). Когда происходит десериализация, движок V8 создает объекты из бинарных данных в том же порядке и правильно обрабатывает ссылки-смещения.
Вывод: наш загрузчик при десериализации ДОЛЖЕН обрабатывать поток сериализованных данных так же, как и движок V8 (эмулировать расположение объектов на куче).
Со смещения 0x3C начинается непосредственно сам поток сериализованных бинарных данных. О них пойдет речь в следующей части.
Загрузчик сериализованных данных движка V8
«Ненавидь игру, а не игрока, сынок». Рик Санчес
В телеграфном стиле кратко пройдемся по тому, как работает загрузчик движка V8. Именно на его логику мы ориентировались при создании своего загрузчика в плагине. Развернутая статья про загрузчик выйдет позднее.
1) Где происходит чтение сериализованных данных? Находим функцию в deserializer.cc в исходных кодах Node.js.

Наш загрузчик следует логике этой функции при разборе сериализованных данных.
2) Существует несколько форматов кодирования чисел, про которые должен знать загрузчик:
a. Формат хранения чисел — variable-length encoded (функция GetInt в файле snapshot-source-sink.h в исходных кодах Node.js). В сериализованных данных в этом формате хранятся, например, размеры объектов.

b. Формат хранения чисел — zigzag coding (файл source-position-table.cc в исходных кодах Node.js). Включает в себя два метода кодирования. Первый — variable-length integer coding (популярный метод «сжатия» целых чисел; идея состоит в 7-битной кодировке: один байт содержит 7 бит информации, а старший бит указывает, содержит ли следующий байт полезную информацию). Второй — zigzag-способ кодирования положительных и отрицательных чисел (знаковый бит из старшего бита числа переносим в младший бит). В сериализованных данных в этом формате хранятся данные структуры SourcePositionTable (специальная таблица соответствий номеров строк кода исходного скрипта и смещений внутри байткода).

c. Формат хранения чисел — SMI (small integer). В 32-битной версии движка V8 младший бит в SMI-числе означает следующее: 1 — число является указателем, 0 — это обычное число. Чтобы получить значение SMI надо выполнить сдвиг на один бит вправо «SMI >> 1». В сериализованном коде в формате SMI хранятся числовые значения полей внутри объектов (например, поле Length в объекте FixedArray).
3) Формат сериализованных данных:
<опкод> (один байт) <данные опкода> (N байт)
В движке V8 каждый объект состоит из набора полей (прямая аналогия с полями класса в объектно-ориентированном программировании). Каждое поле может быть «указателем» на другой объект. Этот объект может быть встроенным (хранится в массиве roots_ объекта Heap), либо уже созданным на ранних шагах десериализации (на него должна храниться так называемая обратная ссылка), либо это новый объект (в этом случае запускается десериализация его полей).

4) Какие опкоды реализованы в загрузчике (здесь перечислены опкоды, которые мы реализовывали в нашем плагине):
00h-04h (kNewObject) = создание нового объекта. Объект всегда размещается в «Reservation Data» (фрагменты кучи, управляемой движком V8). Как выбирается конкретный фрагмент? С помощью нехитрой операции: опкод & 7. Существуют следующие фрагменты:
0 = NEW_SPACE (в этом фрагменте кучи размещаются «новые» JavaScript-объекты, сюда попадают объекты, собранные с помощью «сборщика копий» — copying collector),
1 = OLD_SPACE (в этом фрагменте кучи размещаются «старые» JavaScript-объекты; тут могут быть указатели на фрагмент с «новыми» JavaScript-объектами),
2 = CODE_SPACE,
3 = MAP_SPACE,
4 = LO_SPACE (для хранения large objects);
08h-0Ch (kBackref) = обратная ссылка на объект. Для уменьшения размера сериализованных данных нет необходимости снова сериализовать уже сериализованные объекты. Для этого используют так называемые обратные ссылки. Все объекты создаются в своих фрагментах кучи: NEW_SPACE, OLD_SPACE, CODE_SPACE, MAP_SPACE, LO_SPACE. Поэтому опкодов для обратных ссылок тоже пять, на каждый вид фрагмента кучи. Все объекты во фрагменте кучи располагаются последовательно друг за другом. Получается, что значение обратной ссылки — это, по сути, смещение объекта внутри фрагмента кучи.
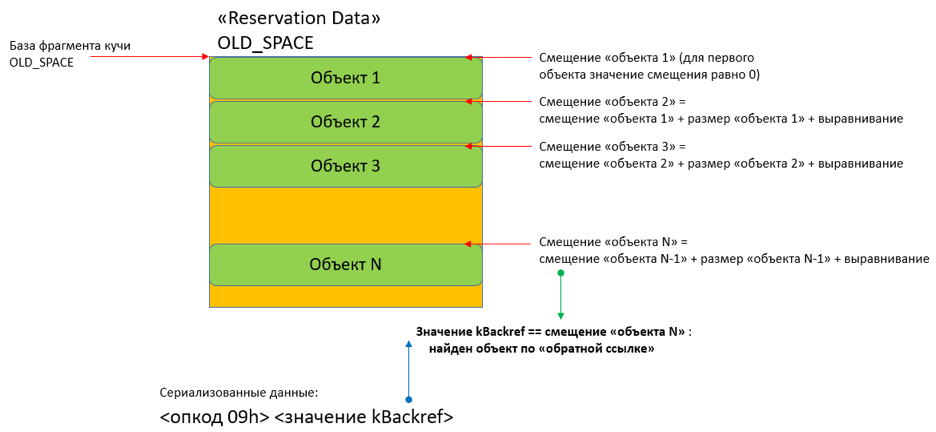
Наш загрузчик плагина поступает похожим образом: ведет список созданных объектов для каждого фрагмента кучи. Размеры объектов с учетом выравнивания загрузчик тоже отслеживает. При появлении в сериализованных данных обратной ссылки загрузчик находит объект, обходя список созданных объектов. Найденный объект параллельно записываем в массив «горячих ссылок» (hot_objects, массив небольшой, всего 7 элементов). Массив hot_objects необходим для обработки опкода kHotObject.
05h (kRootArray) = найти объект Map-класса в массиве roots_ объекта Heap и записать указатель на объект в текущее смещение десериализованного объекта. Индекс для массива roots_ находится в данных опкода. Сам объект параллельно записываем в массив «горячих ссылок» (hot_objects). Массив hot_objects необходим для обработки опкода kHotObject.
0Dh (kAttachedReference) = найти объект в массиве attached_objects и записать указатель на объект в текущее смещение десериализованного объекта. Для нашего загрузчика плагина массив attached_objects содержит один элемент с нулем (т. е. не используется).
0Eh (kBuiltin) = найти объект в массиве builtins и записать указатель на объект в текущее смещение десериализованного объекта. Пример распространенного встроенного объекта — «InterpreterEntryTrampoline».
0Fh (kSkip), 15h-17h (kWordAligned, kDoubleAligned, kDoubleUnaligned) = наш загрузчик эмулирует эти опкоды выравнивания данных на куче.
18h (kSynchronize) = это точка останова десериализации. Процесс десериализации завершен.
19h (kVariableRepeat) = используется для повторения предыдущего десериализованного значения. Количество повторов передается в данных опкода.
1Ah (kVariableRawData) = используется, когда необходимо в объект записать «сырые» данные. Размер данных должен быть выровнен (находится в данных опкода).
38h-3Fh (kHotObject) = найти объект в массиве «горячих ссылок» hot_objects и записать указатель на объект в текущее смещение десериализованного объекта.
4Fh (kNextChunk) = это инструкция движку V8 «перейти к следующему зарезервированному chunk». Инструкция связана с фрагментами кучи «Reservation Data» и размещением в них так называемых пустышек (FILLER-объектов). Пустышки резервируют память во фрагменте кучи. Загрузчик учитывает эти FILLER-объекты для правильного вычисления значений обратных ссылок.
80h-9Fh (kRootArrayConstants) = найти объект в массиве roots_. Индекс для массива roots_ вычисляется по формуле: «значение – 80h». Указатель на найденный объект записываем в текущее смещение десериализованного объекта.
C0h-DFh (kFixedRawData) = используется, когда необходимо в объект записать «сырые» данные (фиксированное количество байтов). Количество байтов считается по формуле: «значение – BFh».
E0h-EFh (kFixedRepeat) = используется для повторения предыдущего десериализованного значения фиксированное число раз. Количество повторов считается по формуле: count = (value – DFh).
5) Какие объекты загрузчик в плагине разбирает в ходе десериализации:
- SharedFunctionInfo (closure-объект),
- ScopeInfo и OuterScopeInfo (лексическое окружение),
- FunctionData (объект с байткодом),
- FixedArray, FixedCOWArray (представляют собой словарь «ключ — значение»; ключом могут быть и сами объекты),
- ConsString (представляет собой бинарное дерево, где листьями выступают, например, обычные строки-объекты ConsOneByteString),
- HandlerTable (обработчики исключений),
- SourcePositionTable (специальная таблица соответствий номеров строк кода исходного скрипта и смещений внутри байткода).
Разбор перечисленных объектов необходим, чтобы правильно сформировать данные для дизассемблера байткода и для последующей работы декомпилятора.
Дизассемблер плагина
— Зачем кому-то вообще это делать?
— Затем, что если этот кто-то и мог бы это сделать, а он не может, то потому, что он может, но он не может.
(Рик и Морти)
И снова кратко пройдемся по тому, как работает дизассемблер плагина. Развернутые статьи про процессорный модуль выйдут позже.
1) Где находится байткод: в созданных загрузчиком объектах SharedFunctionInfo:
В объекте SharedFunctionInfo > FunctionData:
поле kBytecode = непосредственно сам байткод;
поле kConstantPool = массив из констант, строк, словарей и других объектов;
поле kSourcePositionTable = таблица соответствий номеров строк кода исходного скрипта и смещений внутри байткода;
kHandlerTable = таблица с обработчиками исключений.
В объекте SharedFunctionInfo > ScopeInfo находится лексическое окружение для байткода функции.
2) Как выглядит инструкция байткода V8:
Ширина (опционально, 1 байт):
0 — Wide,
1 — ExtraWide.
Опкод (1 байт).
Операнды (могут кодироваться 1, 2 или 4 байтами каждый).

Можно выделить несколько основных групп по типам инструкций: загрузка в аккумулятор (префикс Lda), запись из аккумулятора в другое место (префиксSta), работа с регистрами (Mov/Ldar/Star), математика (префиксы Add/Sub/Mul/Div/Mod), булевы операции (BitwiseOr/ BitwiseXor/ BitwiseAnd/LogicalNot), сдвиговые(префикс Shift), многоцелевые встроенные инструкции (префикс Call/Invoke/Construct и без префикса StackCheck/TypeOf/ToName/ToNumber/ToObject/Illegal), инструкции сравнения (префикс Test), создание объектов (префикс Create), условные переходы (префикс Jump), циклы (префикс For), инструкции генерацииисключений (префикс Throw), инструкции отладки (префикс Debug), ветвления (SwitchOnSmiNoFeedback).
Вывод: в Node.js версии 8.16.0 представлено 167 инструкций.

Числовые операнды в инструкции имеют обратный порядок байтов (little-endian).
3) Процессорный модуль для плагина был написан под фреймворк Ghidra. Описание инструкций байткода происходит на языке SLEIGH. Описание анализатора и загрузчика и переопределение инструкций p-code для некоторых операций V8 выполнены на Java. При загрузке файла в Ghidra загрузчик разбирает jsc-файл, разбивая его на функции и определяя необходимые для анализа и декомпиляции сущности.
4) Аргументы функции и регистры тяжело было реализовать в точности как в Node.js. Был вариант реализовать их как регистры или сделать для каждой функции хранилище наподобие стека. Для большего соответствия выводу Node.js и для удобства восприятия было принято решение воспользоваться регистровой моделью, хоть она и накладывала ограничения на количество регистров, с которыми может работать функция (a0-a125, r0-r123).
Результатом всей этой нашей работы стал плагин ghidra_nodejs для дизассемблера Ghidra (https://github.com/PositiveTechnologies/ghidra_nodejs).
Послесловие
«Когда ты изобретаешь телепортацию, то сразу обнаруживаешь неприятную вещь: ты последний во Вселенной, кто ее изобрел». Рик Санчес
или
«Хорошему приключению нужен хороший конец!» Рик Санчес
В презентации «DLS Keynote: Ignition: Jump-starting an Interpreter for V8» есть фраза: «JavaScript is hard! V8 is complex!» Приходится согласится, что устройство V8 (в частности, интерпретатора Ignition) непростое. И даже попытка в нем разобраться достойна внимания.
В итоге свою задачу для анализа серверного приложения мы выполнили. Смогли получить читабельный код. Надеемся, что данный инструмент поможет нашим читателям при работе с сериализованным байткодом движка V8.
Большое спасибо Владимиру Кононовичу, Вячеславу Москвину, Наталье Тляповой за исследование Node.js и разработку модуля.
Автор: Сергей Федонин.




DrMefistO
Круто получилось!:) Рад был в этом участвовать.