
 «Те, кто не помнит прошлого, обречены повторить его» — Джордж Сантаяна, 1905
«Те, кто не помнит прошлого, обречены повторить его» — Джордж Сантаяна, 1905Свою лекцию Тьюринга 4 июня 2018 года мы начали с обзора компьютерной архитектуры, начиная с 60-х годов. Кроме него, мы освещаем актуальные проблемы и пытаемся определить будущие возможности, которые сулят новый золотой век в области компьютерной архитектуры в следующем десятилетии. Такой же, как в 1980-е, когда мы проводили свои исследования по улучшению в стоимости, энергоэффективности, безопасности и производительности процессоров, за что и получили эту почётную награду.
Ключевые идеи
- Прогресс программного обеспечения может стимулировать архитектурные инновации
- Повышение уровня программно-аппаратных интерфейсов создаёт возможности для инноваций архитектуры
- Рынок в конечном итоге определяет победителя в споре архитектур
Программное обеспечение «разговаривает» с оборудованием через словарь, который называется «архитектура набора команд» (ISA). К началу 1960-х у IBM было четыре несовместимые серии компьютеров, каждая со своей ISA, программным стеком, системой ввода-вывода и рыночной нишей — ориентированные на малый бизнес, крупный бизнес, научное применение и системы реального времени, соответственно. Инженеры IBM, в том числе лауреат премии Тьюринга Фредерик Брукс — младший, решили создать единую ISA, которая эффективно объединит все четыре.
Им нужно было техническое решение, как обеспечить одинаково быструю ISA для компьютеров и с 8-битной, и с 64-битной шиной. В каком-то смысле шины являются «мускулами» компьютеров: они выполняют работу, но относительно легко «сжимаются» и «расширяются». Тогда и сейчас самым большим вызовом для конструкторов является «мозг» процессора — аппаратура управления. Вдохновлённый программированием, пионер вычислительной техники и лауреат премии Тьюринга Морис Уилкс предложил варианты упрощения этой системы. Элемент управления был представлен как двумерный массив, который он назвал «управляющая память» (control store). Каждый столбец массива соответствовал одной линии управления, каждая строка была микроинструкцией, а запись микроинструкций называлась микропрограммированием. Управляющая память содержит интерпретатор ISA, написанный микроинструкциями, поэтому выполнение обычной инструкции занимает несколько микроинструкций. Управляющая память реализована, собственно, в памяти, а она намного дешевле логических элементов.
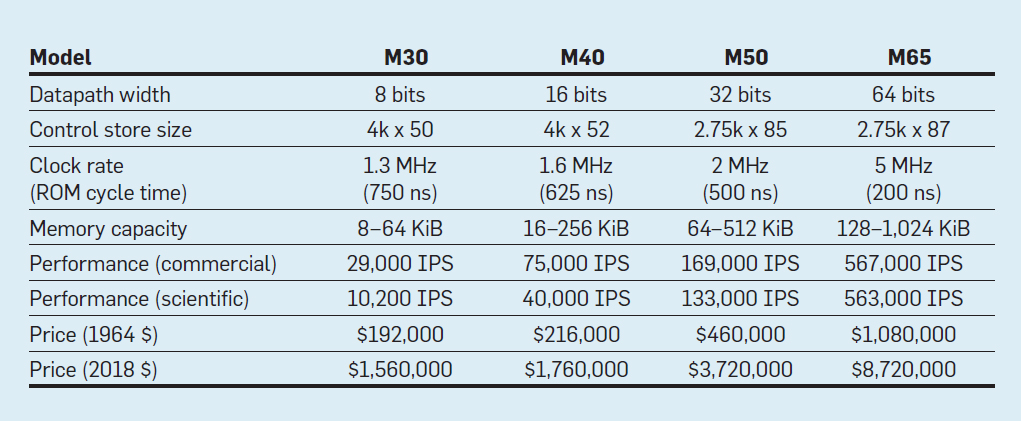
Характеристики четырёх моделей семейства IBM System/360; IPS означает количество операций в секунду
В таблице указаны четыре модели новой ISA в System/360 от IBM, представленной 7 апреля 1964 года. Шины отличаются в 8 раз, объём памяти — в 16, тактовая частота — почти в 4, производительность — в 50, а стоимость — почти в 6. В самых дорогих компьютерах наиболее обширная управляющая память, потому что более сложные шины данных использовали больше линий управления. В самых дешёвых компьютерах меньше управляющая память из-за более простого оборудования, но они нуждались в большем количестве микроинструкций, так как для выполнения инструкции System/360 им требовалось больше тактовых циклов.
Благодаря микропрограммированию IBM сделала ставку, что новая ISA революционизирует вычислительную промышленность — и выиграла пари. IBM доминировала на своих рынках, а потомки старых мейнфреймов IBM 55-летней давности по-прежнему приносят $10 млрд дохода в год.
Как неоднократно отмечалось, хотя рынок — неидеальный арбитр в качестве технологий, но учитывая тесные связи между архитектурой и коммерческими компьютерами, он в конечном итоге определяет успех архитектурных инноваций, которые часто требуют значительных инженерных инвестиций.
Интегральные схемы, CISC, 432, 8086, IBM PC
Когда компьютеры перешли на интегральные схемы, закон Мура означал, что управляющая память может стать намного больше. В свою очередь, это позволило гораздо более сложные ISA. Например, управляющая память VAX-11/780 от Digital Equipment Corp. в 1977 году составляла 5120 слов по 96 бит, в то время как его предшественник использовал только 256 слов по 56 бит.
Некоторые производители разрешили микропрограммирование избранным клиентам, которые могли добавить свои пользовательские функции. Это назвали «управляющая память с перезаписью» (writable control store, WCS). Самым известным компьютером WCS стал Alto, который лауреаты премии Тьюринга Чак Такер и Батлер Лэмпсон с коллегами создали для исследовательского центра Xerox Palo Alto в 1973 году. Это был действительно первый персональный компьютер: тут первый дисплей с поэлементным формированием изображений и первая локальная сеть Ethernet. Контроллеры для инновационных дисплея и сетевой карты были микропрограммами, которые хранятся в WCS объёмом 4096 слов по 32 бита.
В 70-е годы процессоры ещё оставались 8-битными (например, Intel 8080) и программировались в основном на ассемблере. Конкуренты добавляли новые инструкции, чтобы превзойти друг друга, показывая свои достижения на примерах ассемблера.
Гордон Мур верил, что следующая ISA от Intel сохранится для компании навсегда, поэтому нанял много умных докторов наук в области информатики и отправил их на новый объект в Портленде, чтобы изобретать следующую великую ISA. Процессор 8800, как Intel первоначально назвала его, стал абсолютно амбициозным проектом компьютерной архитектуры для любой эпохи, безусловно, это был самый агрессивный проект 80-х гг. Он предусматривал 32-битную мандатную адресацию (capability-based addressing), объектно-ориентированную архитектуру, инструкции переменной длины и собственную операционную систему на новом языке программирования Ada.
К сожалению, этот амбициозный проект потребовал несколько лет разработки, что заставило Intel запустить экстренный резервный проект в Санта-Кларе, чтобы быстро выпустить 16-битный процессор в 1979 году. Intel дала новой команде 52 недели на разработку новой ISA «8086», проектирование и сборку чипа. Учитывая плотный график, проектирование ISA заняло всего 10 человеко-недель в течение трёх обычных календарных недель, в основном за счет расширения 8-разрядных регистров и набора инструкций 8080 до 16 бит. Команда завершила 8086 по графику, но этот аварийно сделанный процессор объявили без особых фанфар.
Intel очень повезло, что IBM разрабатывала персональный компьютер для конкуренции с Apple II и нуждалась в 16-битном микропроцессоре. IBM присматривалась к Motorola 68000 с ISA, похожей на IBM 360, но та отставала от агрессивного графика IBM. Вместо этого IBM переключилась на 8-разрядную версию шины 8086. Когда IBM анонсировала PC 12 августа 1981 года, то надеялась продать 250 000 компьютеров к 1986 году. Вместо этого компания продала 100 миллионов по всему миру, подарив очень перспективное будущее экстренно сделанной ISA от Intel.
Оригинальный проект Intel 8800 переименовали в iAPX-432. Наконец, его анонсировали в 1981 году, но он требовал нескольких микросхем и имел серьёзные проблемы с производительностью. Его завершили в 1986 году, через год после того, как Intel расширила 16-битную ISA 8086 до 80386, увеличив регистры с 16 бит до 32 бит. Таким образом, предсказание Мура в отношении ISA оказалось правильным, но рынок выбрал сделанный впопыпах 8086, а не «помазанника» iAPX-432. Как поняли архитекторы процессоров Motorola 68000 и iAPX-432, рынок редко умеет проявить терпение.
От сложного к сокращённому набору команд
В начале 1980-х было проведено несколько исследований компьютеров с набором сложных инструкций (CISC): у них большие микропрограммы в большой управляющей памяти. Когда Unix продемонстрировала, что даже операционную систему можно написать на языке высокого уровня, то главным стал вопрос: «Какие инструкции будут генерировать компиляторы?» вместо прежнего «Какой ассемблер будут использовать программисты?» Значительное повышение уровня аппаратно-программного интерфейса создало возможность для инноваций в архитектуре.
Лауреат премии Тьюринга Джон Кокк и его коллеги разработали более простые ISA и компиляторы для миникомпьютеров. В качестве эксперимента они переориентировали свои исследовательские компиляторы на использование в IBM 360 ISA только простых операций между регистрами и загрузки с запоминанием, избегая более сложных инструкций. Они заметили, что программы работают в три раза быстрее, если используют простое подмножество. Эмер и Кларк обнаружили, что 20% инструкций VAX занимают 60% микрокода и занимают всего 0,2% времени выполнения. Один автор этой статьи (Паттерсон) провёл творческий отпуск в DEC, помогая уменьшить количество ошибок в микрокоде VAX. Если производители микропроцессоров собирались в больших компьютерах следовать конструкции ISA с набором сложных команд CISC, то предполагали большое количество ошибок микрокода и хотели найти способ их исправлять. Он написал такую статью, но журнал Computer её отклонил. Рецензенты высказали мнение, что ужасная идея строить микропроцессоры с ISA настолько сложной, что их нужно ремонтировать в полевых условиях. Этот отказ поставил под сомнение ценность CISC для микропроцессоров. По иронии судьбы, современные микропроцессоры CISC действительно включают механизмы восстановления микрокода, но отказ от публикации статьи вдохновил автора на разработку менее сложной ISA для микропроцессоров — компьютеров с сокращённым набором команд (RISC).
Эти замечания и переход на языки высокого уровня позволили перейти от CISC к RISC. Во-первых, инструкции RISC упрощены, так что нет необходимости в интерпретаторе. Инструкции RISC обычно просты как микроинструкции и могут выполняться непосредственно аппаратным обеспечением. Во-вторых, быстрая память, ранее использовавшаяся для интерпретатора микрокода CISC, была перепрофилирована в кэш инструкций RISC (кэш — это небольшая, быстрая память, которая буферизует недавно выполненные инструкции, поскольку такие инструкции, вероятно, будут повторно использованы в ближайшее время). В-третьих, распределители регистров на основе схемы окрашивания графа Грегори Чайтина значительно облегчили компиляторам эффективное использование регистров, от чего выиграли эти ISA с операциями регистр-регистр. Наконец, закон Мура привёл к тому, что в 1980-х годах транзисторов на чипе стало достаточно, чтобы разместить на одном чипе полную 32-битную шину, вместе с кэшами для инструкций и данных.
Например, на рис. 1 показаны микропроцессоры RISC-I и MIPS, разработанные в Калифорнийском университете в Беркли и Стэнфордском университете в 1982 и 1983 годах, которые продемонстрировали преимущества RISC. В итоге, в 1984 году эти процессоры были представлены на ведущей конференции по схемотехнике, IEEE International Solid-State Circuits Conference (1, 2). Это был замечательный момент, когда несколько аспирантов в Беркли и Стэнфорде создали микропроцессоры, превосходившие возможности промышленности той эпохи.

Рис. 1. Процессоры RISC-I от Калифорнийского университета в Беркли и MIPS от Стэнфордского университета
Те академические чипы вдохновили многие компании на создание микропроцессоров RISC, которые были самыми быстрыми на протяжении следующих 15 лет. Объяснение связано со следующей формулой производительности процессора:
Время/Программа = (Инструкции / Программа) ? (тактов / Инструкция) ? (Время / такт)
Инженеры DEC позже показали, что для одной программы более сложные CISC требуют 75% от количества инструкций RISC (первый член в формуле), но в схожей технологии (третий член) каждая инструкция CISC занимает на 5-6 тактов больше (второй член), что делает микропроцессоры RISC примерно в 4 раза быстрее.
Таких формул не было в компьютерной литературе 80-х годов, что заставило нас в 1989 году написать книгу Computer Architecture: A Quantitective Approach. Подзаголовок объясняет тему книги: использовать измерения и бенчмарки для количественной оценки компромиссов вместо того, чтобы полагаться на интуицию и опыт конструктора, как в прошлом. Наш количественный подход также был вдохновлен тем, что сделала для алгоритмов книга лауреата Тьюринга Дональда Кнута.
VLIW, EPIC, Itanium
Предполагалось, что следующая инновационная ISA превзойдёт успех и RISC, и CISC. Архитектура очень длинных машинных команд VLIW и её двоюродный брат EPIC (вычисление с явным параллелизмом машинных команд) от Intel и Hewlett-Packard использовали длинные инструкции, каждая из которых состояла из нескольких независимых операций, связанных вместе. Сторонники VLIW и EPIC в то время считали, что если бы одна инструкция могла указать, скажем, шесть независимых операций — две передачи данных, две целочисленные операции и две операции с плавающей запятой — и технология компилятора могла бы эффективно назначать операции в шесть слотов инструкций, то оборудование можно упростить. Подобно подходу RISC, VLIW и EPIC перенесли работу с аппаратного обеспечения на компилятор.
Работая вместе, Intel и Hewlett-Packard разработали 64-разрядный процессор на идеях EPIC для замены 32-разрядной архитектуры x86. Большие надежды возлагались на первый процессор EPIC под названием Itanium, но реальность не соответствовала ранним заявлениям разработчиков. Хотя подход EPIC хорошо работал для высокоструктурированных программ с плавающей запятой, он никак не мог достичь высокой производительности для целочисленных программ с менее предсказуемыми ветвлениями и кэш-промахами. Как позже отметил Дональд Кнут: «Предполагалось, что подход Itanium… будет потрясающим — пока не оказалось, что желаемые компиляторы в принципе невозможно написать». Критики отметили задержки в выпуске Itanium и окрестили его «Итаником» в честь злополучного пассажирского корабля «Титаник». Рынок же опять не смог проявить терпение и принял в качестве преемника 64-разрядную версию x86, а не Itanium.
Хорошая новость в том, что VLIW по-прежнему подходит для более специализированных приложений, где работают небольшие программы с более простыми ветвями без кэш-промахов, включая обработку цифровых сигналов.
RISC против CISC в эпоху ПК и пост-ПК
AMD и Intel понадобились проектные группы по 500 человек и превосходная полупроводниковая технология, чтобы сократить разрыв в производительности между x86 и RISC. Опять же, ради производительности, которая достигается благодаря конвейеризации, декодер инструкций на лету переводит сложные инструкции x86 во внутренние RISC-подобные микроинструкции. AMD и Intel затем строят конвейер их выполнения. Любые идеи, которые дизайнеры RISC использовали для повышения производительности — отдельные кэши инструкций и данных, кэши второго уровня на чипе, глубокий конвейер (deep pipeline), а также одновременное получение и выполнение нескольких инструкций — затем включили в x86. На пике эры персональных компьютеров в 2011 году AMD и Intel ежегодно поставляли около 350 миллионов x86-микропроцессоров. Высокие объёмы и низкая маржа индустрии также означали более низкие цены, чем у компьютеров RISC.
С сотнями миллионов ежегодно продаваемых компьютеров гигантским рынком стало программное обеспечение. В то время как поставщикам ПО для Unix приходилось выпускать разные версии ПО для разных архитектур RISC — Alpha, HP-PA, MIPS, Power и SPARC — у персональных компьютеров была одна ISA, поэтому разработчики выпускали «ужатый» софт, бинарно совместимый только с архитектурой x86. Из-за гораздо большей программной базы, аналогичной производительности и более низких цен к 2000 году архитектура x86 доминировала на рынках настольных компьютеров и малых серверов.
Apple помогла открыть эпоху пост-ПК с выпуском iPhone в 2007 году. Вместо закупок микропроцессоров смартфонные компании делали собственные системы-на-чипе (SoC), используя чужие наработки, в том числе процессоры RISC от ARM. Здесь конструкторам важна не только производительность, но ещё энергопотребление и площадь кристалла, что поставило в невыгодное положение архитектуры CISC. Кроме того, Интернет вещей значительно увеличил как количество процессоров, так и необходимые компромиссы в размерах чипа, мощности, стоимости и производительности. Эта тенденция повысила важность времени и стоимости проектирования, что ещё больше ухудшило положение процессоров CISC. В сегодняшнюю эпоху пост-ПК годовые поставки x86 упали почти на 10% с пикового 2011 года, в то время как чипы RISC взлетели до 20 миллиардов. Сегодня 99% 32- и 64-разрядных процессоров в мире — это RISC.
Завершая этот исторический обзор, мы можем сказать, что рынок урегулировал спор RISC и CISC. Хотя CISC выиграл более поздние этапы эпохи ПК, но RISC выигрывает сейчас, когда наступила эпоха пост-ПК. Новых ISA на CISC не создавалось в течение десятилетий. К нашему удивлению, общее мнение по лучшим принципам ISA для процессоров общего назначения сегодня по-прежнему склоняется в пользу RISC, спустя 35 лет после его изобретения.
Современные вызовы для процессорной архитектуры
«Если у проблемы не существует решения, возможно, это не проблема, а данность, с которой следует научиться жить» — Шимон Перес
Хотя в предыдущем разделе основное внимание уделялось разработке архитектуры набора команд (ISA), большинство конструкторов в индустрии не разрабатывают новые ISA, а внедряют существующие ISA в существующую технологию производства. С конца 70-х превалирующей технологией были интегральные схемы на МОП-структурах (MOS), сначала n-типа (nMOS), а затем комплементарного (CMOS). Ошеломляющие темпы совершенствования технологии MOS — зафиксированные в предсказаниях Гордона Мура — стали движущей силой, которая позволяла конструкторам разрабатывать более агрессивные методы достижения производительности для данной ISA. Первоначальное предсказание Мура в 1965 году предусматривало ежегодное удвоение плотности транзисторов; в 1975 году он пересмотрел его, прогнозируя удвоение каждые два года. В конце концов этот прогноз стали называть законом Мура. Поскольку плотность транзисторов растёт квадратично, а скорость — линейно, с помощью большего количества транзисторов можно повышать производительность.
Конец закона Мура и закона масштабирования Деннарда
Хотя закон Мура действовал в течение многих десятилетий (см. рис. 2), где-то в районе 2000 года он начал замедляться, а к 2018 году разрыв между предсказанием Мура и текущими возможностями вырос до 15-кратного. В 2003 году Мур высказал мнение, что такое было неизбежно. В настоящее время ожидается, что разрыв будет и дальше увеличиваться по мере приближения технологии CMOS к фундаментальным пределам.
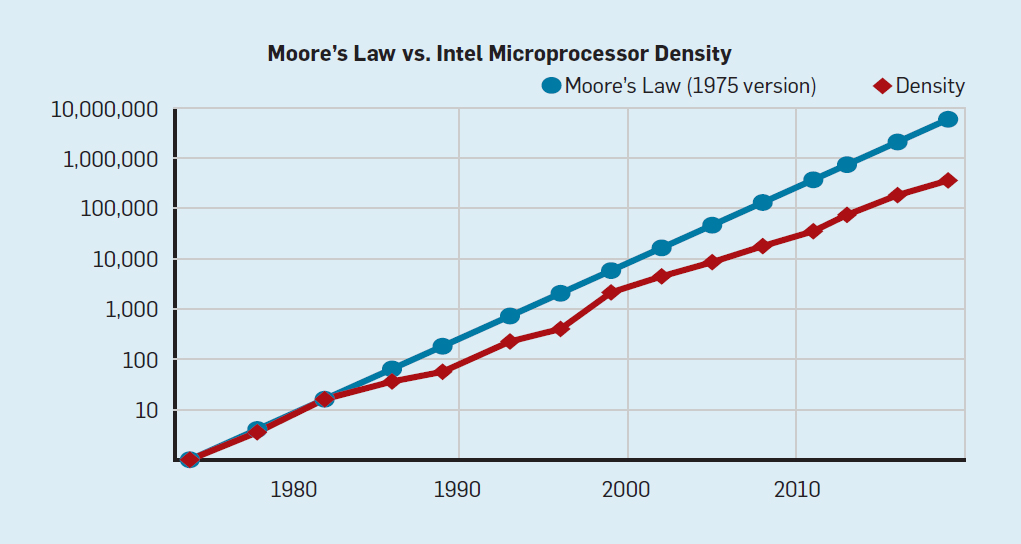
Рис. 2. Количество транзисторов на чипе Intel по сравнению с законом Мура
Закон Мура сопровождала проекция, сделанная Робертом Деннардом под названием «масштабирование Деннарда», что по мере увеличения плотности транзисторов потребление энергии на транзистор будет падать, поэтому потребление на мм? кремния будет почти постоянным. Поскольку вычислительные возможности кремниевого миллиметра росли с каждым новым поколением технологий, компьютеры становились более энергоэффективными. Масштабирование Деннарда начало значительно замедляться в 2007 году, а к 2012 году практически сошло на нет (см. рис. 3).
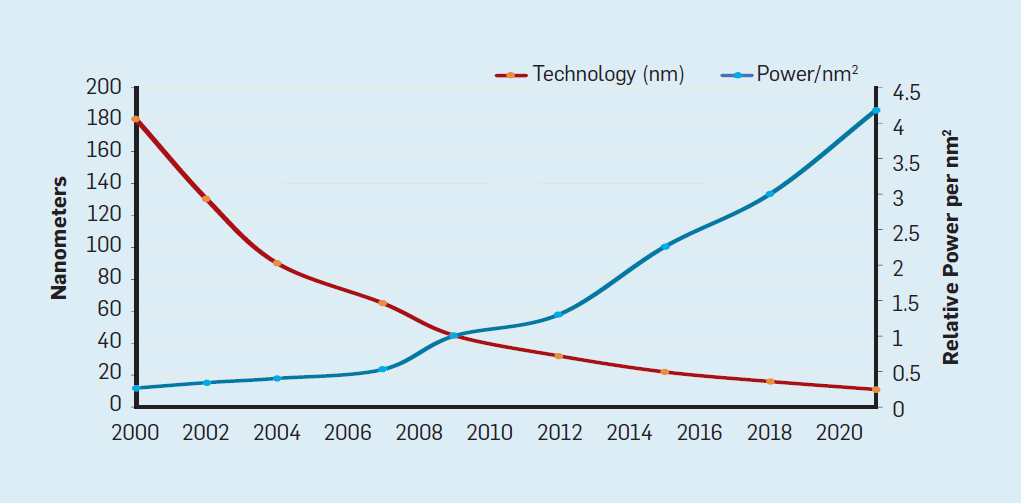
Рис. 3. Количество транзисторов на чип и потребление энергии на мм?
С 1986 по 2002 год параллелизм на уровне инструкций (ILP) был основным архитектурным методом повышения производительности. Наряду с повышением скорости транзисторов, это давало ежегодное увеличение производительности примерно на 50%. Конец масштабирования Деннарда означал, что архитекторам пришлось найти более эффективные способы использования параллелизма.
Чтобы понять, почему увеличение ILP снижало эффективность, рассмотрим ядро современных процессоров ARM, Intel и AMD. Предположим, что у него 15-этапный конвейер и четыре инструкции на такт. Таким образом, в любой момент времени на конвейере находится до 60 инструкций, в том числе примерно 15 веток, поскольку они составляют примерно 25% выполненных инструкций. Чтобы заполнить конвейер, ветви прогнозируются, а код спекулятивно помещается в конвейер для выполнения. Спекулятивынй прогноз — одновременно источник и производительности ILP, и неэффективности. Когда предсказание ветвлений является идеальным, спекуляция повышает производительность и совсем немного повышает энергопотребление — и даже может экономить энергию — но когда ветви предсказываются неправильно, процессор должен выбросить неправильные вычисления, а вся работа и энергия затрачена впустую. Внутреннее состояние процессора также придётся восстановить до состояния, существовавшего до неправильно понятой ветви, с затратой дополнительного времени и энергии.
Чтобы понять, насколько сложной является такая конструкция, представьте сложность правильного прогнозирования результатов 15 ветвей. Если конструктор процессора ставит лимит в 10% потерь, процессор должен правильно предсказать каждую ветвь с точностью 99,3%. Существует не так много программ общего назначения с ветвями, которые можно предсказать так точно.
Чтобы оценить, из чего состоит эта потраченная впустую работа, рассмотрим данные на рис. 4, показывающие долю инструкций, которые эффективно выполняются, но оказываются потраченными впустую, потому что процессор неправильно предсказал ветвление. В тестах SPEC на Intel Core i7 впустую тратятся в среднем 19% инструкций. Однако количество потраченной энергии больше, так как процессор должен использовать дополнительную энергию для восстановления состояния, когда он неправильно спрогнозировал.
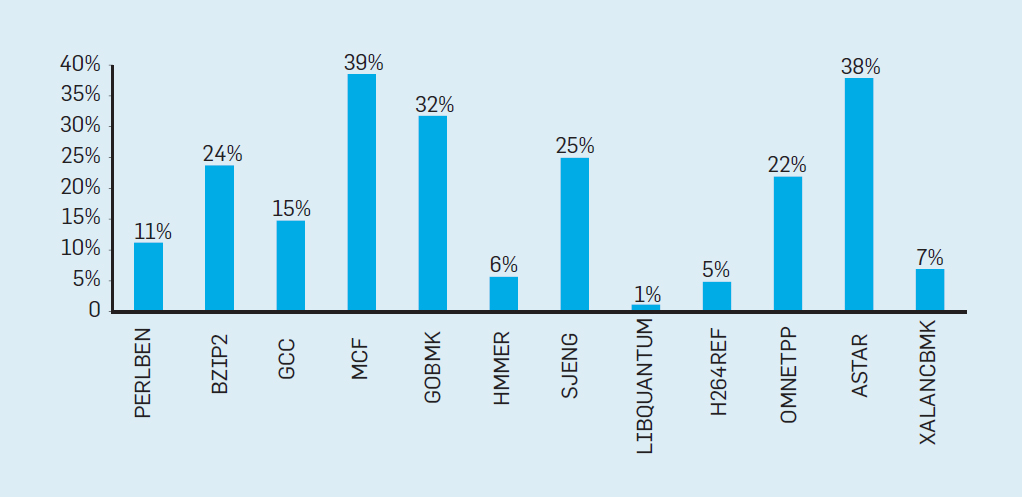
Рис.4. Потраченные впустую инструкции в процентах от всех инструкций, выполненных на Intel Core i7 для различных целочисленных тестов SPEC
Подобные измерения привели многих к выводу, что нужно искать иной подход для достижения лучшей производительности. Так родилась многоядерная эпоха.
В этой концепции ответственность за выявление параллелизма и принятие решения о том, как его использовать, перекладывается на программиста и языковую систему. Многоядерность не решает проблему энергоэффективных вычислений, которая усугубилась к концу масштабирования Деннарда. Каждое активное ядро потребляет энергию независимо от того, участвует ли оно в эффективных вычиcлениях. Основным препятствием является старое наблюдение, называемое законом Амдаля. Оно говорит, что выгода от параллельных вычислений ограничена долей последовательных вычислений. Чтобы оценить важность этого наблюдения, рассмотрим рисунок 5. Он показывает, насколько быстрее приложение работает с 64 ядрами по сравнению с одним ядром, предположив разную долю последовательных вычислений, когда активен только один процессор. Например, если 1% времени вычисление выполняется последовательно, то преимущество 64-процессорной конфигурации составляет всего 35%. К сожалению, потребляемая мощность пропорциональна 64 процессорам, поэтому примерно 45% энергии тратится впустую.
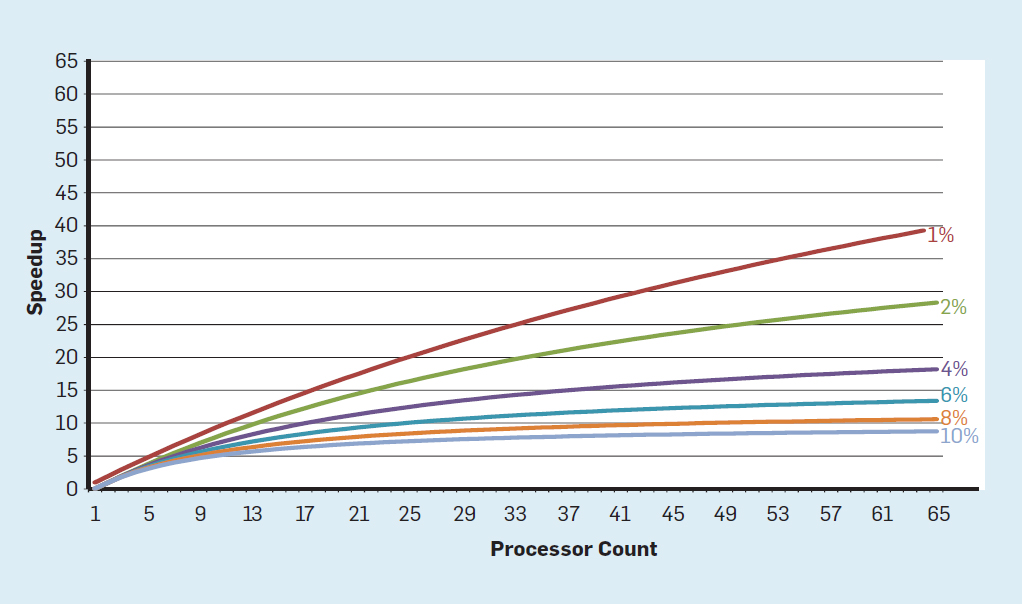
Рис. 5. Влияние закона Амдала на увеличение скорости с учётом доли тактов в последовательном режиме
Конечно, у реальных программ более сложная структура. Есть фрагменты, которые позволяют использовать разное количество процессоров в любой момент времени. Тем не менее, необходимость периодически взаимодействовать и синхронизировать их означает, что у большинства приложений есть некоторые части, которые могут эффективно использовать только часть процессоров. Хотя закону Амдаля уже более 50 лет, он остаётся трудным препятствием.
С окончанием масштабирования Деннарда увеличение количества ядер на чипе означало, что мощность также увеличивается почти с той же скоростью. К сожалению, подводимое к процессору напряжение затем следует ещё удалить как тепло. Таким образом, многоядерные процессоры ограничены тепловой выходной мощностью (TDP) или средним количеством мощности, которое способны удалить корпус и система охлаждения. Хотя некоторые высококлассные дата-центры используют более продвинутые технологии охлаждения, ни один пользователь не захочет ставить на стол небольшой теплообменник или носить на спине радиатор, чтобы охладить мобильный телефон. Предел TDP привёл к эпохе «тёмного кремния» (dark silicon), когда процессоры замедляют тактовую частоту и отключают простаивающие ядра, чтобы предотвратить перегрев. Другой способ рассмотреть этот подход заключается в том, что некоторые микросхемы могут перераспределить свою драгоценную мощность от бездействующих ядер к активным.
Эпоха без масштабирования Деннарда, наряду с сокращением закона Мура и закона Амдаля, означает, что неэффективность ограничивает улучшение производительности лишь несколькими процентами в год (см. рис. 6).
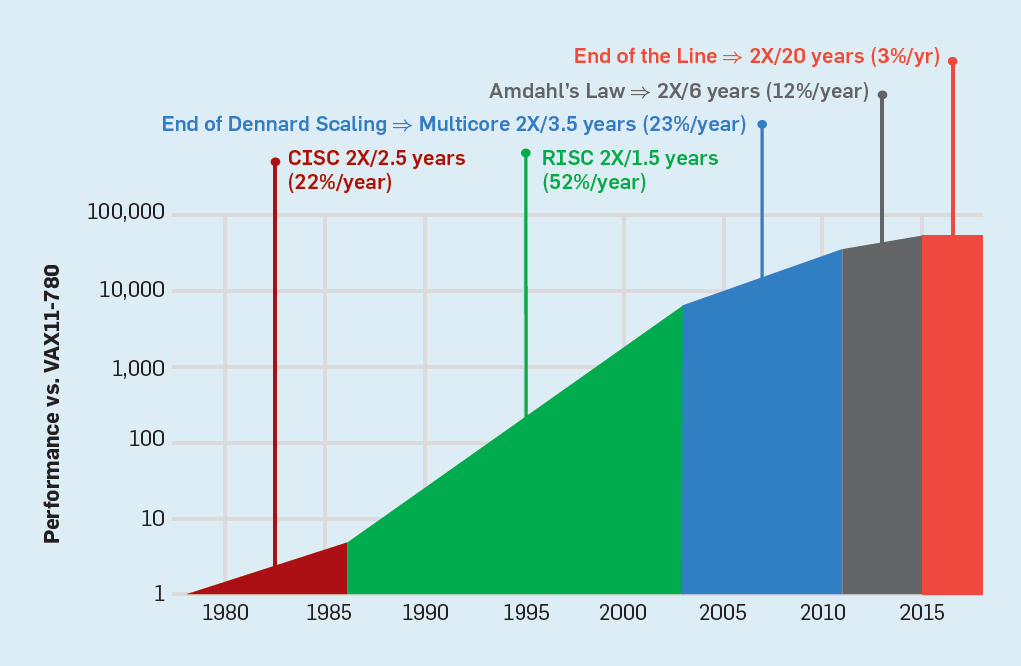
Рис. 6. Рост компьютерной производительности по целочисленным тестам (SPECintCPU)
Достижение более высоких темпов повышения производительности — как это было отмечено в 80-е и 90-е годы — требует новых архитектурных подходов, которые гораздо более эффективно используют возможности интегральных схем. Мы вернёмся к обсуждению потенциально эффективных подходов, упомянув ещё один серьезный недостаток современных компьютеров — безопасность.
Забытая безопасность
В 70-е годы разработчики процессоров старательно обеспечивали компьютерную безопасность с помощью разных концепций, начиная от защитных колец и заканчивая специальными функциями. Они хорошо понимали, что большинство ошибок будет в программном обеспечении, но верили, что архитектурная поддержка может помочь. Эти функции в основном не использовались операционными системами, которые работали в предположительно безопасном окружении (как персональные компьютеры). Поэтому функции, связанные со значительными накладными расходами, были устранены. В программном сообществе многие считали, что формальная проверка и методы вроде использования микроядра обеспечат эффективные механизмы для создания высокозащищённого программного обеспечения. К сожалению, масштаб наших общих программных систем и стремление к производительности означали, что такие методы не могли идти в ногу с производительностью. В результате большие программные системы по-прежнему имеют много недостатков в безопасности, причём эффект усиливается из-за огромного и растущего количества личной информации в интернете и использования облачных вычислений, где пользователи делят одно физическое оборудование с потенциальным злоумышленником.
Хотя конструкторы процессоров и другие, возможно, не сразу осознали растущее значение безопасности, они начали включать аппаратную поддержку виртуальных машин и шифрование. К сожалению, предсказание ветвлений внедрило во многие процессоры неизвестный, но существенный недостаток безопасности. В частности, уязвимости Meltdown и Spectre используют особенности микроархитектуры, допуская утечку защищённой информации. Они обе применяют так называемые атаки по сторонним каналам, когда информация просачивается по разнице во времени, затрачиваемом на задачу. В 2018 году исследователи показали, как использовать один из вариантов Spectre для извлечения информации по сети без загрузки кода на целевой процессор. Хотя эта атака под названием NetSpectre передаёт информацию медленно, но сам факт, что она позволяет атаковать любую машину в той же локальной сети (или в том же кластере в облаке), создаёт много новых векторов атаки. Впоследствии сообщалось ещё о двух уязвимостях в архитектуре виртуальных машин (1, 2). Одна из них под названием Foreshadow позволяет проникать в механизмы безопасности Intel SGX, предназначенные для защиты самых ценных данных (таких как ключи шифрования). Новые уязвимости находят ежемесячно.
Атаки по сторонним каналам не новы, но в большинстве случаев раньше виной были баги в ПО. В Meltdown, Spectre и других атаках это недостаток в аппаратной реализации. Существует фундаментальная трудность в том, как процессорные архитекторы определяют, что является правильной реализацией ISA, потому что стандартное определение ничего не говорит об эффектах производительности выполнения последовательности инструкций, только о видимом ISA архитектурном состоянии выполнения. Архитекторы должны пересмотреть своё определение правильной реализации ISA, чтобы предотвратить такие недостатки безопасности. В то же время они должны переосмыслить то внимание, которое они уделяют компьютерной безопасности, и то, как архитекторы могут работать с разработчиками ПО для реализации более безопасных систем. Архитекторы (и все остальные) не должны воспринимать безопасность никак иначе как первостепенную необходимость.
Будущие возможности в компьютерной архитектуре
«Перед нами открываются потрясающие возможности, замаскированные под неразрешимые проблемы» — Джон Гарднер, 1965
Присущая процессорам общего назначения неэффективность, будь то технологии ILP или многоядерные процессоры, в сочетании с завершением масштабирования Деннарда и законом Мура делают маловероятным, что архитекторы и разработчики процессоров смогут поддерживать значительные темпы повышения производительности процессоров общего назначения. Учитывая важность повышения производительности для ПО, мы должны задать вопрос: какие ещё есть перспективные подходы?
Есть две явные возможности, а также третья, созданная путём объединения этих двух. Во-первых, существующие методы разработки ПО широко используют высокоуровневые языки с динамической типизацией. К сожалению, такие языки обычно интерпретируются и выполняются крайне неэффективно. Для иллюстрации этой неэффективности Лейсерсон с коллегами привели небольшой пример: перемножение матриц.
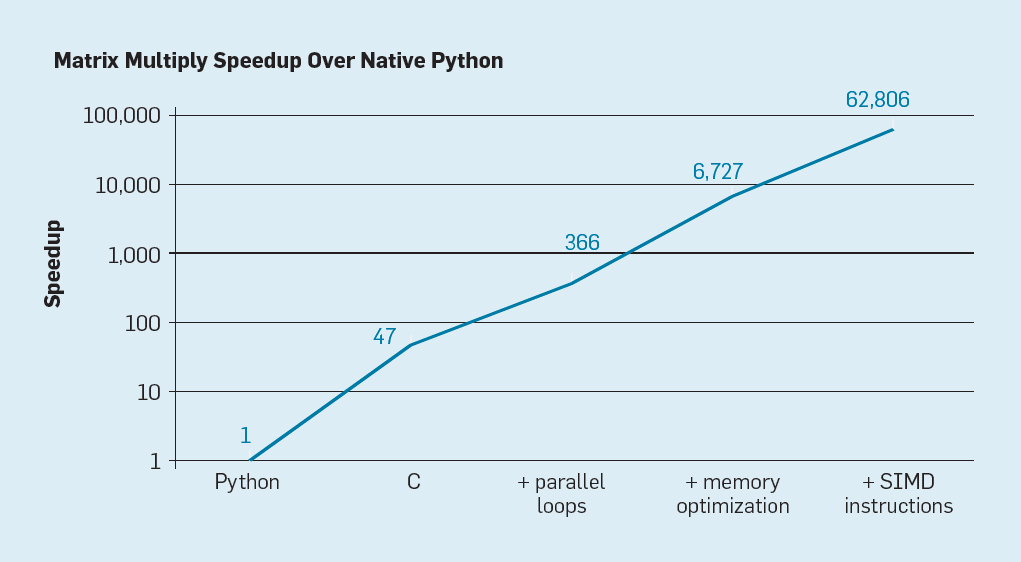
Рис. 7. Потенциальное ускорение перемножения матриц Python после четырёх оптимизаций
Как показано на рис. 7, простое переписывание кода с Python на C повышает производительность в 47 раз. Использование параллельных циклов на многих ядрах даёт дополнительный коэффициент примерно 7. Оптимизация структуры памяти для использования кэшей дает коэффициент 20, и последний фактор 9 происходит от использования аппаратных расширений для выполнения параллельных операций SIMD, которые способны выполнять 16 32-разрядных операций в инструкции. После этого финальная, сильно оптимизированная версия выполняется на многоядерном процессоре Intel в 62 806 раз быстрее, чем первоначальная Python-версия. Это, конечно, небольшой пример. Можно предположить, что программисты будут использовать оптимизированную библиотеку. Хотя здесь преувеличен разрыв в производительности, но существует, вероятно, много программ, которые можно оптимизировать в 100-1000 раз.
Интересным направлением исследований является вопрос о том, можно ли устранить некоторые пробелы в производительности с помощью новой технологии компилятора, возможно, с помощью архитектурных усовершенствований. Хотя сложно эффективно транслировать и компилировать скриптовые языки высокого уровня, такие как Python, но потенциальный выигрыш огромен. Даже небольшая оптимизация может привести к тому, что программы Python будут работать в десятки-сотни раз быстрее. Этот простой пример показывает, насколько велик разрыв между современными языками, ориентированными на эффективность работы программиста, и традиционными подходами, подчёркивающими производительность.
Специализированные архитектуры
Более аппаратно-ориентированный подход — проектирование архитектур, адаптированных к конкретной предметной области, где они демонстрируют значительную эффективность. Это специализированные или предметно-ориентированные архитектуры (domain-specific architectures, DSA). Это обычно программируемые и тьюринг-полные процессоры, но с учётом конкретного класса задач. В этом смысле они отличаются от специализированных интегральных схем (application-specific integrated circuits, ASIC), которые часто используются для одной функции с кодом, который редко изменяется. DSA часто называют ускорителями, так как они ускоряют некоторые приложения по сравнению с выполнением всего приложения на CPU общего назначения. Кроме того, DSA могут обеспечить более высокую производительность, поскольку они более точно адаптированы к потребностям приложения. Примеры DSA включают графические процессоры (GPU), процессоры нейронных сетей, используемые для глубокого обучения, и процессоры для программно-определяемых сетей (SDN). DSA достигают более высокой производительности и большей энергоэффективности по четырём основным причинам.
Во-первых, DSA используют более эффективную форму параллелизма для конкретной предметной области. Например, SIMD (одиночный поток команд, множественный поток данных) более эффективен, чем MIMD (множественный поток команд, множественный поток данных). Хотя SIMD менее гибок, он хорошо подходит для многих DSA. Специализированные процессоры могут также использовать подходы VLIW к ILP, вместо плохо работающих спекулятивных механизмов. Как упоминалось ранее, процессоры VLIW плохо подходят для кода общего назначения, но для узких областей гораздо более эффективны, поскольку механизмы управления проще. В частности, самые топовые процессоры общего назначения чрезмерно многоконвейерны, что требует сложной логики управления и для начала, и для завершения инструкций. Напротив, VLIW выполняет необходимый анализ и планирование во время компиляции, что может хорошо работать для явно параллельной программы.
Во-вторых, службы DSA более эффективно используют иерархию памяти. Доступ к памяти стал гораздо дороже, чем арифметические вычисления, как отметил Горовиц. Например, доступ к блоку в 32-килобайтном кэше требует примерно в 200 раз больше энергии, чем сложение 32-разрядных целых чисел. Такая огромная разница делает оптимизацию доступа к памяти критически важной для достижения высокой энергоэффективности. Процессоры общего назначения выполняют код, в котором доступы к памяти обычно демонстрируют пространственную и временну?ю локальность, но в остальном не очень предсказуемы во время компиляции. Поэтому для увеличения пропускной способности CPU используют многоуровневые кэши и скрывают задержку в относительно медленных DRAM за пределами кристалла. Эти многоуровневые кэши часто потребляют около половины энергии процессора, зато предотвращают почти все обращения к DRAM, на что уходит примерно в 10 раз больше энергии, чем на доступ к кэшу последнего уровня.
У кэшей два заметных недостатка.
Когда наборы данных очень большие. Кэши просто плохо работают, когда наборы данных очень велики, имеют низкую временну?ю или пространственную локальность.
Когда кэши работают хорошо. Когда кэши работают хорошо, локальность очень высока, то есть, по определению, бoльшая часть кэша простаивает большую часть времени.
В приложениях, где шаблоны доступа к памяти хорошо определены и понятны во время компиляции, что верно для типичных предметно-ориентированных языков (DSL), программисты и компиляторы могут оптимизировать использование памяти лучше, чем динамически выделяемые кэши. Таким образом, DSA обычно используют иерархию памяти с перемещением, которое явно контролируется программным обеспечением, подобно тому, как работают векторные процессоры. В соответствующих приложениях «ручной» контроль памяти пользователем позволяет тратить гораздо меньше энергии, чем стандартный кэш.
В-третьих, DSA может снижать точность вычислений, если высокая точность не нужна. CPU общего назначения обычно поддерживают 32-и 64-разрядные целочисленные вычисления, а также данные с плавающей запятой (FP). Для многих приложений в машинном обучении и графике это избыточная точность. Например, в глубоких нейросетях при расчёте часто используются 4-, 8- или 16-разрядные числа, улучшая и пропускную способность данных, и вычислительную мощность. Аналогично, для обучения нейросетей полезны вычисления с плавающей запятой, но достаточно 32 бит, а часто и 16 бит.
Наконец, DSA выигрывают от программ, написанных на предметно-ориентированных языках, которые допускают больше параллелизма, улучшают структуру, представление доступа к памяти и упрощают эффективное наложение программы на специализированный процессор.
Предметно-ориентированные языки
DSA требуют приспособления высокоуровневых операций к архитектуре процессора, но это очень сложно сделать на языке общего назначения, таком как Python, Java, C или Fortran. Предметно-ориентированные языки (DSL) помогают в этом и позволяют эффективно программировать DSA. Например, DSL могут сделать явными векторные, плотные матричные и разреженные матричные операции, что позволит компилятору DSL эффективно сопоставлять операции с процессором. Среди предметно-ориентированных языков — Matlab, язык для работы с матрицами, TensorFlow для программирования нейросетей, Р4 для программирования программно-определяемых сетей, и Halide для обработки изображений с указанием преобразований высокого уровня.
Проблема DSL заключается в том, как сохранить достаточную архитектурную независимость, чтобы программное обеспечение на нём можно было портировать на различные архитектуры, при этом достичь высокой эффективности при сопоставлении программного обеспечения с базовым DSA. Например, система XLA транслирует код Tensorflow на гетерогенные системы с Nvidia GPU или тензорными процессорами (TPU). Балансировка переносимости между DSA с сохранением эффективности — интересная исследовательская задача для разработчиков языков, компиляторов и самих DSA.
Пример DSA: TPU v1
В качестве примера DSA рассмотрим Google TPU v1, который разработан для ускорения работы нейросети (1, 2). Этот TPU производится с 2015 года, на нём работают многие приложения: от поисковых запросов до перевода текстов и распознавания изображений в AlphaGo и AlphaZero, программах DeepMind для игры в го и шахматы. Цель состояла в том, чтобы повысить производительность и энергоэффективность глубоких нейронных сетей в 10 раз.
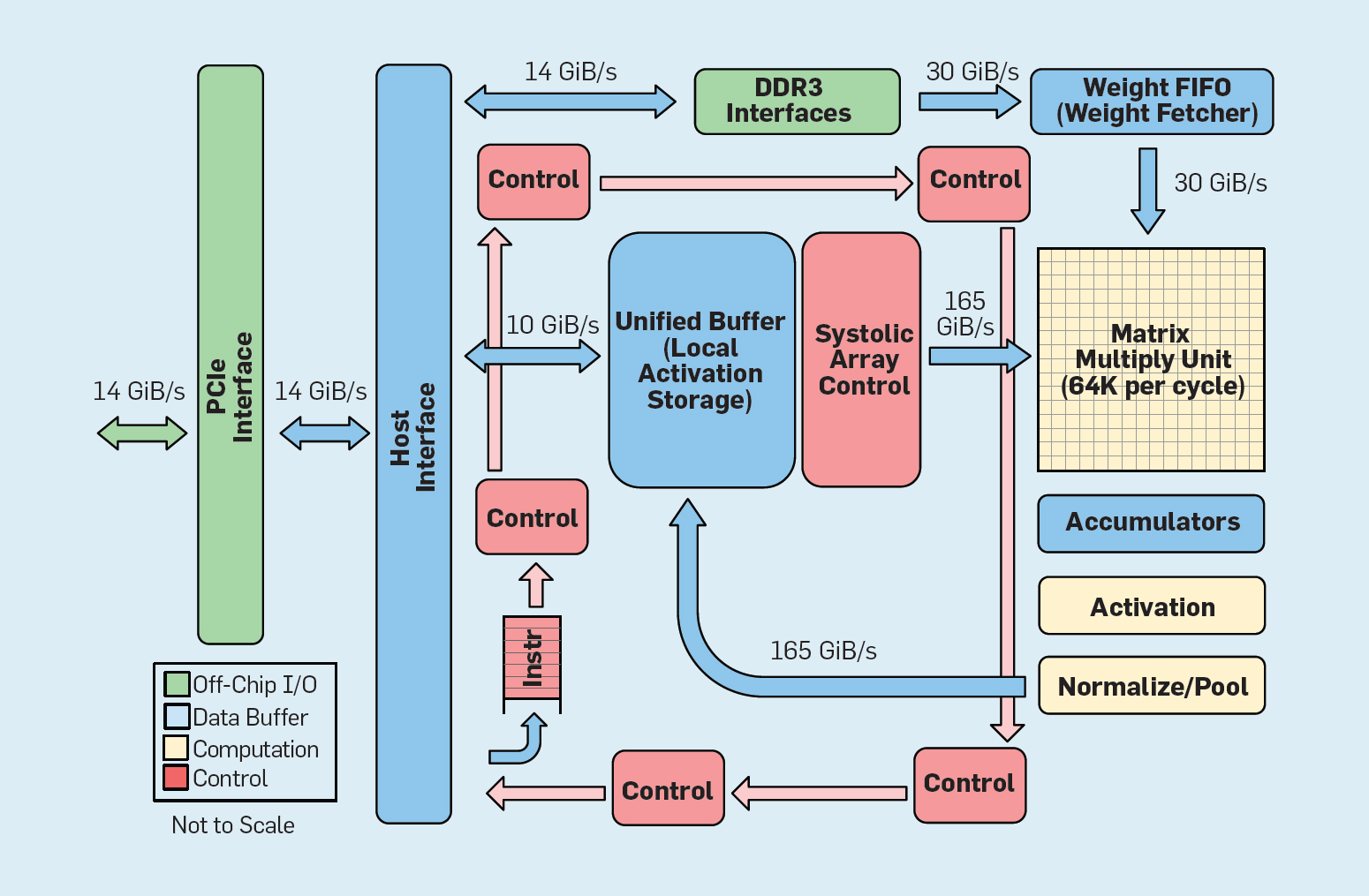
Рис. 8. Функциональная организация Google Tensor Processing Unit (TPU v1)
Как показано на рисунке 8, организация TPU радикально отличается от процессора общего назначения. Основным вычислительным блоком является матричный блок, структура систолических массивов, которая каждый такт производит умножения 256?256 с накоплением (multiply-accumulate). Сочетание 8-разрядной точности, высокоэффективная систолическая структура, управление SIMD и выделение под эту функцию значительной части чипа помогают выполнять за один такт примерно в 100 раз больше операций умножения с накоплением, чем ядро CPU общего назначения. Вместо кэшей TPU использует локальную память 24 МБ, что примерно вдвое больше, чем кэши CPU общего назначения 2015 года с тем же TDP. Наконец, и память активации нейронов и память весов нейросети (включая структуру FIFO, которая хранит веса) соединяются через высокоскоростные каналы, контролируемые пользователем. Средневзвешенная производительность TPU по шести типичным проблемам логического вывода нейросетей в дата-центрах Google в 29 раз выше, чем у процессоров общего назначения. Поскольку TPU требует меньше половины мощности, то его энергоэффективность для этой рабочей нагрузки более чем в 80 раз превосходит процессоры общего назначения.
Резюме
Мы рассмотрели два различных подхода к повышению производительности программ за счёт повышения эффективности использования аппаратных технологий. Во-первых, за счёт повышения производительности современных языков высокого уровня, которые обычно интерпретируются. Во-вторых, за счёт создания архитектур для конкретных предметных областей, которые значительно улучшают производительность и эффективность по сравнению с процессорами общего назначения. Предметно-ориентированные языки — ещё один пример того, как улучшить аппаратно-программный интерфейс, который позволяет внедрять архитектурные инновации, такие как DSA. Для достижения значительных успехов с помощью таких подходов потребуется вертикально интегрированная проектная группа, которая разбирается в приложениях, предметно-ориентированных языках и связанных с ними технологиях компиляции, компьютерной архитектуре, а также в базовой технологии реализации. Необходимость вертикальной интеграции и принятия проектных решений на разных уровнях абстракции была характерна для большинства ранних работ в области вычислительной техники до того, как отрасль стала горизонтально структурированной. В эту новую эпоху вертикальная интеграция стала более важной. Преимущества получат команды, которые могут найти и принять сложные компромиссы и оптимизации.
Эта возможность уже привела к всплеску архитектурных инноваций, привлекая множество конкурирующих архитектурных философий:
GPU. Графические процессоры Nvidia используют множество ядер, каждое с большими файлами регистров, множеством аппаратных потоков и кэшей.
TPU. TPU от Google полагаются на большие двухмерные систолические массивы и программно-управляемую память на чипе.
FPGA. Корпорация Microsoft в своих дата-центрах внедряет программируемые пользователем вентильные матрицы (FPGA), которые применяет в приложениях нейросетей.
CPU. Intel предлагает процессоры со многими ядрами, большим многоуровневым кэшем и одномерными инструкциями SIMD, в своём роде как FPGA от Microsoft, а новый нейропроцессор ближе к TPU, чем к CPU.
Помимо этих крупных игроков, собственные идеи реализуют десятки стартапов. Чтобы удовлетворить растущий спрос, конструкторы объединяют сотни и тысячи чипов для создания нейросетевых суперкомпьютеров.
Эта лавина архитектур нейросетей говорит о наступлении интересного времени в истории компьютерной архитектуры. В 2019 году трудно предсказать, какое из этих многих направлений выиграет (если кто-то вообще выиграет), но рынок обязательно определит результат, так же, как он урегулировал архитектурные дебаты прошлого.
Открытые архитектуры
По примеру успешного программного обеспечения open source, альтернативную возможность в компьютерной архитектуре представляют открытые ISA. Они нужны, чтобы создать эдакий «Linux для процессоров», чтобы сообщество могло создавать ядра с открытым исходным кодом в дополнение к отдельным компаниям, владеющим проприетарными ядрами. Если многие организации разрабатывают процессоры с использованием одного и того же ISA, то большая конкуренция может привести к еще более быстрым инновациям. Цель — обеспечить архитектуру для процессоров стоимостью от нескольких центов до $100.
Первый пример — RISC-V (RISC Five), пятая архитектура RISC, разработанная в Калифорнийском университете в Беркли. Её поддерживает сообщество под руководством Фонда RISC-V. Открытость архитектуры позволяет эволюции ISA происходить на виду общественности, с привлечением экспертов до принятия окончательного решения. Дополнительным преимуществом открытого фонда является то, что ISA вряд ли будет расширяться в первую очередь по маркетинговым причинам, ведь иногда это единственное объяснение расширений собственных наборов инструкций.
RISC-V — это модульный набор инструкций. Небольшая база инструкций запускает полный стек программного обеспечения с открытым исходным кодом, за которым следуют дополнительные стандартные расширения, которые конструкторы могут включать или отключать в зависимости от потребностей. Эта база содержит 32-разрядные и 64-разрядные версии адресов. RISC-V может расти только через необязательные расширения; программный стек всё равно будет отлично работать, даже если архитекторы не принимают новые расширения. Проприетарные архитектуры обычно требуют «восходящей» совместимости на уровне двоичных кодов: это значит, что если процессорная компания добавляет новую функцию, все будущие процессоры также должны включать её. У RISC-V не так, здесь все усовершенствования являются необязательными и могут быть удалены, если они не нужны приложению. Вот стандартные расширения на данный момент, с указанием первых букв полного названия::
- M. Умножение/деление целого числа.
- A. Атомарные операции с памятью.
- F/D. Операции над числами с плавающей запятой одинарной/двойной точности.
- С. Сжатые инструкции.
Третьей отличительной чертой RISC-V является простота ISA. Хотя этот показатель не поддаётся количественной оценке, вот два сравнения с архитектурой ARMv8, которую параллельно разработала компания ARM:
- Меньше инструкций. У RISC-V гораздо меньше инструкций. В базе 50 штук, и они удивительно похожи по количеству и характеру на оригинальный RISC-I. Остальные стандартные расширения (M, A, F и D) добавляют 53 инструкции, плюс C добавляет ещё 34, так что общее число составляет 137. Для сравнения, в ARMv8 более 500 инструкций.
- Меньше форматов инструкций. У RISC-V гораздо меньше форматов инструкций: шесть, тогда как у ARMv8 по крайней мере 14.
Простота упрощает и проектирование дизайна процессоров, и проверку их корректности. Поскольку RISC-V нацелен на всё: от дата-центров до устройств IoT, то проверка дизайна может быть значительной частью затрат на разработку.
В-четвёртых, RISC-V — это дизайн с чистого листа спустя 25 лет, где архитекторы учатся на ошибках своих предшественников. В отличие от архитектуры RISC первого поколения, он позволяет избежать микроархитектуры или функций, которые зависят от технологии (таких как отложенные ветви и отложенные загрузки) или инноваций (как регистровые окна), коих вытеснили достижения компиляторов.
Наконец, RISC-V поддерживает DSA, резервируя обширное пространство опкодов для пользовательских ускорителей.
Помимо RISC-V, Nvidia также анонсировала (в 2017 году) бесплатную и открытую архитектуру, она называет её Nvidia Deep Learning Accelerator (NVDLA). Это масштабируемый, настраиваемый DSA для логического вывода в машинном обучении. Параметры конфигурации включают тип данных (int8, int16 или fp16) и размер двумерной матрицы умножения. Маштабы кремниевой подложки варьируются от 0,5 мм? до 3 мм?, а потребление энергии от 20 мВт до 300 мВт. ISA, программный стек и реализация открыты.
Открытые простые архитектуры хорошо сочетаются с безопасностью. Во-первых, эксперты по безопасности не верят в безопасность через неясность, поэтому открытые реализации привлекательны, а открытые реализации требуют открытой архитектуры. Не менее важно увеличение числа людей и организаций, которые могут внедрять инновации в области безопасных архитектур. Проприетарные архитектуры ограничивают участие сотрудников, но открытые архитектуры позволяют самым лучшим умам в академических кругах и индустрии помочь с безопасностью. Наконец, простота RISC-V упрощает проверку его реализаций. Кроме того, открытые архитектуры, реализации и программные стеки, а также пластичность FPGA означают, что архитекторы могут развёртывать и оценивать новые решения онлайн с еженедельными, а не ежегодными циклами релизов. Хотя FPGA в 10 раз медленнее, чем кастомные чипы, но их производительности хватает для работы в онлайне и экспонирования инноваций безопасности перед реальными злоумышленниками для проверки. Мы ожидаем, что открытые архитектуры станут примером совместного проектирования аппаратного и программного обеспечения архитекторами и экспертами по безопасности.
Гибкая разработка аппаратного обеспечения
Манифест гибкой разработки программного обеспечения (2001) Бека и др. произвёл революцию в софтверной разработке, устранив проблемы традиционной системы водопада, основанной на планировании и документации. Небольшие команды программистов быстро создают рабочие, но неполные прототипы, и получают отзывы клиентов перед началом следующей итерации. Скрам-версия Agile собирает команды из пяти-десяти программистов, выполняющих спринты по две-четыре недели за итерацию.
Снова позаимствовав идею у разработки ПО, есть возможность организовать гибкую разработку аппаратного обеспечения. Хорошая новость в том, что современные инструменты электронного автоматизированного проектирования (ECAD) повысили уровень абстракции, допуская гибкую разработку. Этот более высокий уровень абстракции также увеличивает уровень повторного использования работы между разными дизайнами.
Четырёхнедельные спринты кажется неправдоподобными для процессоров, учитывая месяцы между тем, когда созданием дизайна и производством чипа. На рис. 9 показано, как может работать гибкий метод путём изменения прототипа на соответствующем уровне.
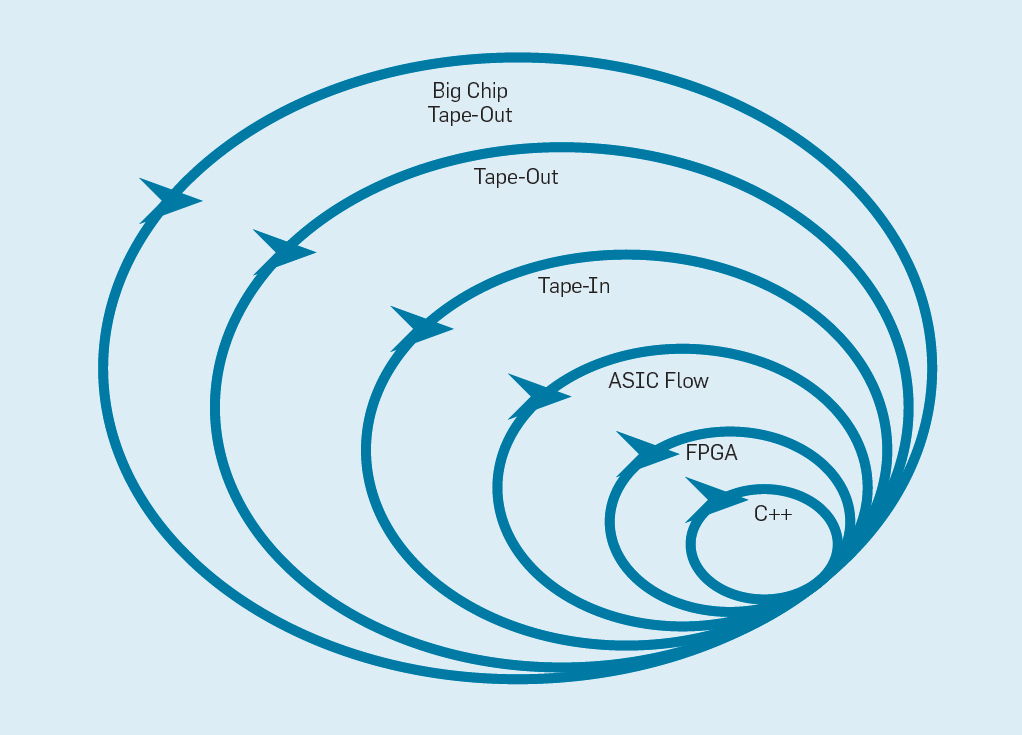
Рис. 9. Гибкая методология разработки оборудования
Самый внутренний уровень — это программный симулятор, самое простое и быстрое место для внесения изменений. Следующий уровень — чипы FPGA, которые могут работать в сотни раз быстрее, чем подробный программный симулятор. FPGA могут работать с операционными системами и полными бенчмарками, такими как Standard Performance Evaluation Corporation (SPEC), что позволяет гораздо более точно оценивать прототипы. Amazon Web Services предлагает FPGA в облаке, поэтому архитекторы могут использовать FPGA без необходимости сначала покупать оборудование и создавать лабораторию. Следующий уровень использует инструменты ECAD, чтобы сгенерировать схему чипа, задокументировать размеры и энергопотребление. Даже после работы инструментов необходимо выполнить некоторые ручные шаги для уточнения результатов, прежде чем отправить новый процессор в производство. Разработчики процессоров называют этот следующий уровень tape in. Эти первые четыре уровня поддерживают четырёхнедельные спринты.
Для исследовательских целей мы могли бы остановиться на четвёртом уровне, поскольку оценки площади, энергии и производительности очень точны. Но это словно бегун пробежал марафон и остановился за 5 метров до финиша, потому что и так понятно его финишное время. Несмотря на тяжёлую подготовку к марафону, он пропустит острые ощущения и удовольствие от фактического пересечения финишной черты. Одно из преимуществ аппаратных инженеров над инженерами программного обеспечения в том, что они создают физические вещи. Получить микросхемы с завода: измерить, запустить реальные программы, показать их друзьям и семье — большая радость для проектировщика.
Многие исследователи полагают, что они должны остановиться, потому что изготовление чипов слишком недоступно по цене. Но если конструкция мала, она удивительно недорога. Инженеры могут заказать 100 микросхем 1 мм? всего за $14 000. При 28 нм чип 1 мм? содержит миллионы транзисторов: этого достаточно и для процессора RISC-V, и для ускорителя ускорителя NVLDA. Самый внешний уровень стоит дорого, если дизайнер намерен создать большую микросхему, но много новых идей можно продемонстрировать и на небольших чипах.
Заключение
«Самый тёмный час — перед самым рассветом» — Томас Фуллер, 1650
Чтобы извлечь пользу из уроков истории, создатели процессоров должны понимать, что многое можно перенять из программной индустрии, что повышение уровня абстракции аппаратного/программного интерфейса даёт возможности для инноваций и что рынок в конечном итоге определит победителя. iAPX-432 и Itanium демонстрируют, как вложения в архитектуру могут ничего не дать, в то время как S/360, 8086 и ARM десятилетиями обеспечивают высокий результат, и конца не видно.
Завершение закона Мура и масштабирования Деннарда, а также замедление роста производительности стандартных микропроцессоров — это не проблемы, которые следует решить, а данность, которая, как известно, предлагает захватывающие возможности. Высокоуровневые предметно-ориентированные языки и архитектуры, освобождающие от цепочек проприетарных наборов инструкций, наряду с требованием общественности к повышению безопасности, откроют новый золотой век для компьютерной архитектуры. В экосистемах с открытым исходным кодом искусно разработанные чипы убедительно продемонстрируют достижения и тем самым ускорят коммерческое внедрение. Философией процессоров общего назначения в этих чипах, скорее всего, будет RISC, который выдержал испытание временем. Ожидайте таких же стремительных инноваций, как и во время прошлого золотого века, но на этот раз с точки зрения стоимости, энергии и безопасности, а не только производительности.
В следующем десятилетии произойдет кембрийский взрыв новых компьютерных архитектур, означающий захватывающие времена для компьютерных архитекторов в академических кругах и в индустрии.
Комментарии (86)

Sdima1357
19.02.2019 00:43Первые IBM — PC были на базе 8088, а не на 8086, насколько мне известно…
IBM выбирала между 68000 и 8086, но тут появился 8088 с внешней 8 битной шиной, что позволило значительно удешевить материнскую плату и IBM остановила свой выбор на 8088.

amartology
19.02.2019 01:17В части открытых архитектур (а эта статья по большому счету — реклама RISC-V) интересно, как будут сосуществовать RISC-V и MIPS, который, став открытым, сразу же предлагает доступ к hi-end ядрам, а также как они вместе или по отдельности будут пытаться украсть у ARM полноценный кусок пирога, а не крошки.
P.S. Ну и VLIW красиво походя пнули. Что ответят корифеям фанаты Эльбруса?
sergeperovsky
19.02.2019 20:20Что можно ответить? «Компиляторы невозможно создать» оказалось просто «мы не смогли создать». Что касается эффективности, то все очень сильно зависит от решаемых задач.
Были архитектуры очень экзотические и очень эффективные, но для ограниченного круга задач. Например Сетунь с троичной системой. Или баллистический вычислитель с представлением чисел в виде набора остатков от деления на простые числа. Все это было оттеснено массовостью универсальных процессоров.
Если бы понятие серверов данных, файлов и приложений появились до создания архитектуры массовых процессоров, под них были бы созданы различные высокоэффективные архитектуры, со своими системами команд.
FForth
19.02.2019 04:55Про одного Мура упомянуто в статье, а про другого и его MISC процессоры забыли. :)
Статья (на английском) «Chuck Moore: Part 2: From Space to GreenArrays»
www.cpushack.com/2013/03/02/chuck-moore-part-2-from-space-to-greenarrays
P.S. Неплохо, для ретро-сравнения и данные этой статьи включить.
А, вот что делалось в те времена и в СССР
«Стековые процессоры, или новое — это хорошо забытое новое»
www.kit-e.ru/articles/cpu/2003_09_98.php
www.kit-e.ru/articles/elcomp/2004_1_102.php (продолжение)
www.kit-e.ru/articles/elcomp/2004_2_130.php (заключение)
Чужие: странная архитектура инопланетных компьютеров
www.ferra.ru/review/techlife/philae-computer.htm
Не всем процессорам и их архитектурам посчастливилось найти своего «массового» потребителя.
F21 in a Mouse www.ultratechnology.com/scope.htm
prospero78su
19.02.2019 09:32Спасибо за перевод. Жаль авторы ничего не упомянули про разработку Никлауса Вирта (Oberon + Lola + программно определяемая архитектура).
Lex4art
19.02.2019 13:03Чтобы оценить важность этого наблюдения, рассмотрим рисунок 5. Он показывает, насколько быстрее приложение работает с 64 ядрами по сравнению с одним ядром, предположив разную долю последовательных вычислений, когда активен только один процессор. Например, если 1% времени вычисление выполняется последовательно, то преимущество 64-процессорной конфигурации составляет всего 35%.
Не 35% а в 35 раз…

potan
19.02.2019 13:39«Рынок в конечном итоге определяет победителя в споре архитектур» — к сожалению, это не так. На рынке, особенно связаном с крупными капиталовложениями, очень сильны положительные обратные связи. Преимущество получает тот, кто раньше вышел на рынок, даже если его решения технически хуже.
amartology
19.02.2019 13:57Так определяется рынком не технически лучшая архитектура, а наиболее коммерчески успешная. Так что все сходится.
vvmtutby
20.02.2019 21:28+1рынок выбрал сделанный впопыпах 8086, а не «помазанника» iAPX-432
Такие «истории успеха» весьма показательны.
Правы «зелёные»: «подводной лодке» под названием «планета Земля» дикий размах «экономической самоуправляемости» просто «не по карману».
( Кстати, на вышеупомянутом CPU для ADA вирусы/эксплоиты просто невозможны )
Hardcoin
19.02.2019 15:01в 62 806 раз быстрее, чем первоначальная Python-версия
Прям обидно, как питон подставили. Для перемножения матриц есть специальные алгоритмы. А они, подозреваю, цикл со сложностью О(n^3) сделали. Разумеется, эти алгоритмы реализованы в виде библиотек на си и фартране, но всё же можно не терять ни капли эффективности работы программиста и при этом получать все плюшки скорости.
sergeperovsky
19.02.2019 20:25Нормальный компилятор «понимает» цикл по массивам и матрицам и пользуется инкрементом указателя вместо вычисления по индексу. Ну или позволяет ассемблерные вставки.
Если питон этого не умеет, при чем тут «подставили»?Hardcoin
19.02.2019 20:39Нужна не ассемблерная вставка, а, например, алгоритм Штрассена. Несомненно, на питоне тот же самый алгоритм будет медленнее, но на практике вы никогда не будете его реализовывать, независимо от того, на питоне вы пишите или на си. То есть независимо от того, какой язык вы выберете, скорость будет одинакова.
Кстати, если вы на си будете перемножать матрицы наивным циклом, это будет медленнее, чем использование питона + numpy.
То есть на практике, если вы захотите получить ускорение и для этого возьмёте си — вы ускорения не получите. Именно это я и имел ввиду, говоря "подставили". Типа, если нужна скорость, берите си. Но для данной задачи (перемножение матриц) это неверно.
sergeperovsky
19.02.2019 22:40+1Мухи отдельно, котлеты отдельно.
Есть правильный выбор алгоритма. Он от языка не зависит и тут не рассматривается.
Рассматривается только насколько эффективно команды языка высокого уровня превращаются в машинный код. Это зависит от качества компилятора. И от возможностей «понять» смысл кода. Если отказаться от понятия массива в пользу более общей абстракции списка, то доступ к конкретному элементу возможен только стандартным способом и прямая адресация памяти невозможна. Значит компилятор не может заменить обращение к функции получения элемента по номеру на инкремент адреса. Вот и разница больше, чем на порядок.
DaylightIsBurning
19.02.2019 15:49Дональд Кнут: «Предполагалось, что подход Itanium… будет потрясающим — пока не оказалось, что желаемые компиляторы в принципе невозможно написать».
А почему? В чём оказалась проблема?Brak0del
19.02.2019 17:27Боюсь сильно упростить, но попробую сформулировать: вроде как они не смогли выжать должного параллелизма уровня команд, т.е. написать такие компиляторы, которые смогут заполнить слоты команд EPIC/VLIW процессора эффективно с учётом ветвлений, кэшей и прочего, т.е. загрузить железо на полную. А тот уровень, который получился в результате, не слишком отличался от обычных процессоров, в то же время ценник отличался существенно.
DaylightIsBurning
19.02.2019 18:35Так по идее же ценник VLIW должен быть ниже CISC. Как я понимаю, основное отличие VLIW от CISC в том, что планировщик выкидывается из процессора и переносится в компилятор. Если при этом производительность процессора не меняется — шикарно, компиляция, конечно, дольше, но это не так важно.
amartology
19.02.2019 19:02Ну вот практика показала, что производительность падает, потому что компиляторы раз за разом оказываются недостаточно хороши, а алгоритмы далеко не все поддаются удобной упаковке для VLIW.
DaylightIsBurning
19.02.2019 19:06Так а почему? Чем компилятор уступает встроенному планировщику?
Sdima1357
19.02.2019 19:24+1Поток данных не всегда предсказуем априори. Встроенный адаптируется под конкретные сиюминутные данные.
DaylightIsBurning
19.02.2019 20:08Но это тоже можно закодировать в компиляторе в виде дерева решений. Получится фактически софтовая реализация хардварного планировщика, который будет для каждого конкретного участка кода гораздо проще чем обобщенный хардварный, но зато софтовый предсказатель будет разным в разных местах программы.
Для меня совершенно не очевидно, почему такая реализация принципиально хуже аппаратного планировщика, как пишет Кнут. Под программным планировщиком я понимаю это код, генерируемый компилятором. Что такое есть в аппаратном планировщике, что нельзя эффективно заменить на программную реализацию в компиляторе? Компилятор может решать, когда логика планировки может быть упрощена или вообще не нужна, если код branching-free.Sdima1357
19.02.2019 20:26Может, но не всегда. Представьте себе программу управляемую потоком данных с заведомо неизвестным распределением, например интерпретатор, код для которого приходит последовательно из сети например.
Вы не можете предсказать следующую команду и соответственно оптимизировать переходы. Предсказатель переходов работает на актуальной для данного времени статистике, а компилятор ее знать заведомо не может и соответственно не может спланировать бранчи.DaylightIsBurning
19.02.2019 22:39В случае сетевого кода и хардварный предсказатель будет бессилен, в этом смысле они окажутся равно неэффективными.
Предсказатель переходов работает на актуальной для данного времени статистике, а компилятор ее знать заведомо не может
Но может рассмотреть варианты точно так же как это делает хардварный предсказатель. Код хардварного предсказателя можно записать программно.
Brak0del
19.02.2019 20:29+2Компилятор принимает пессимистичные решения, т.к. с одной стороны у него нет достаточной инфы по вопросам промахов кэша, ветвлений, некоторых зависимостей по данным (типа алиасов), а с другой при всех его махинациях надо гарантировать корректность состояния программы, в т.ч. корректность состояния на прерываниях. Компилятору «видны» не все возможности паралеллизма, которые «видны» аппаратному. Ну и не стоит забывать, что в обычных процессорах аппаратный планировщик дополняется компилятором, а не исключает его.
DaylightIsBurning
19.02.2019 23:01Что мешает процессору узнать, есть ли следующая переменная в кэше, а компилятору вставить разные ветки кода на оба случая? То же самое с алиасами. Что есть такого в аппаратном планировщике, что это нельзя полностью перенести в компилятор?
Brak0del
20.02.2019 07:11+3Повторюсь, у компилятора недостаточно тактичекой инфы, этой тактической инфы достаточно у аппаратного планировщика, если бы эта инфа была доступна компилятору, то было бы всё ок. Но т.к. её нет, компилятор вынужден принимать безопасные, пессимистичные прогнозы и генерить менее быстрый код, закладываться на слишком много ситуаций и генерить лишний код для восстановления из них, а в результате и производительность упадёт. В вашем примере про ветки кода компилятор нагенерит лишнего кода, который попадёт в кэш (и сократит его эффективную ёмкость), который приведет к ветвлению (и ударит по конвейеру). Ещё один аргумент — когда «отстреливаются» неудачные предположения — в случае компилятора неправильные предсказания для тех же алиасов придется разруливать полноценными командами, в случае аппаратного планировщика их можно отстрелить на разных стадиях конвейера (когда выполнится только часть команды), установив poison bit или что-то в таком духе, т.е. ущерб от ошибочного предсказания или спекуляции ниже на железном уровне. Наконец, аппаратный планировщик способен передавать результаты (разрешать потенциальные зависимости) в ходе выполнения команд, т.е. 1-я команда готовится записать результат в регистр/память и до этой записи транслирует результат по шинам быстрого доступа командам 5 и 6, которые ждут этого операнда (разрешения зависимости по данным) на разных стадиях конвейера, т.е. разруливать зависимости в ходе выполнения команды не разгружая конвейер (см. алгоритм Томасуло)
DaylightIsBurning
20.02.2019 15:05у компилятора недостаточно тактичекой инфы
Но компилятор может сгенерировать код планировщика, который будет учитывать тактическую инфу.
компилятор вынужден принимать безопасные, пессимистичные прогнозы и генерить менее быстрый код,
Не обязательно, компилятор может генерировать несколько веток кода, программа может переключаться между ними в зависимости от обстоятельств.
закладываться на слишком много ситуаций
Аппаратный планировщик действует так же.
генерить лишний код для восстановления из них
Который будет лежать в RAM, которой много. Засорения кеша тоже будет, но не факт, что значительное.
компилятор нагенерит лишнего кода, который попадёт в кэш (и сократит его эффективную ёмкость)
Но не сильно. Емкость кеша не так сильно влияет на производительность, что видно по тому, что размеры кэша в современных процессорах с одинаковой IPC могут отличаться в разы, без роста производительности. То есть, что бы засорение кэша повлияло на ситуацию без возможности компенсировать простым увеличением его емкости, неэффективность должна отличаться хотя бы в 3 раза, а то и на порядок.
в случае аппаратного планировщика их можно отстрелить на разных стадиях конвейера (когда выполнится только часть команды),
А толку? Это может немного снизить энергопотребление, но не производительность, ведь спланировать новую полезную нагрузку скорее всего не получится. Да и программируемный планировщик тоже в принципе может такое, теоретически.
Наконец, аппаратный планировщик способен передавать результаты (разрешать потенциальные зависимости) в ходе выполнения команд
это то же самое, что и предыдущий пункт?Brak0del
20.02.2019 16:07Который будет лежать в RAM, которой много. Засорения кеша тоже будет, но не факт, что значительное.
Лишнему коду перед исполнением тоже надо будет попасть в кэш (это требует времени и места), значит часть полезного кода может вытесниться, повысится число промахов.
А толку? Это может немного снизить энергопотребление, но не производительность
Вы серьезно?) С программным планировщиком вам доступна гранулярность уровня команд, не меньше. С аппаратным — гранулярность уровня тактов, а тактов на команду может быть с десяток и на каждом можно отстрелить лишнее, освободить аппаратный ресурс и занять его другой командой (ну, в теории).
это то же самое, что и предыдущий пункт?
Обратите внимание на алгоритм Томасуло. Этот пункт значит, что разрешение зависимостей по данным в случае аппаратного планировщика может происходить гораздо раньше, чем это может позволить программный (потому что гранулярность снова у компилятора не позволяет добраться).DaylightIsBurning
20.02.2019 16:33повысится число промахов.
Но на сколько? А если увеличить кэш в два-три раза? Предположим, что число веток, которое рассматривает аппаратный планировщик не превышает 2-3 (поправьте, если не так). Значит и оверхед кода для программного планировщика тоже будет 2-3.
С аппаратным — гранулярность уровня тактов
В случае RISC, а тем более VLIW, команда=такт.
тактов на команду может быть с десяток
Эта проблема (и её героическое преодоление) существует только для CISC. В случае VLIW проблемы нет.
Обратите внимание на алгоритм Томасуло
Обратил, но не понял, какие существенные недостатки это демонстрирует в случае VLIW процессора, где команда=такт. Более того, на сегодняшний день CISC(Intel, AMD) — это RISC+транслятор CISC->RISC.RISC processors only use simple instructions that can be executed within one clock cycle.
Brak0del
20.02.2019 16:41В случае RISC, а тем более VLIW, команда=такт.
Не согласен, у вас там 5-6 тактов на команду, вряд ли меньше, точно не 1, всякие fetch, decode, read operands, execute, write. За один так не уложитесь. В вашей цитате написано про executed, это одна из тех стадий что я привёл, но не единственная.
Но на сколько?
Вот опять же не хочу сильно перескакивать, вы вводите дополнительный код, это приводит к увеличению числа промахов, но не только, это приводит к лишним командам, на которые требуется время выполнения, а также к промахам при предсказании ветвлений. Тут бы весь оверхед посчитать, а не только кэш.DaylightIsBurning
20.02.2019 16:46Не согласен, у вас там 5-6 тактов на команду, вряд ли меньше
Откуда Ваши данные? Ребята из Стэнфорда пишут, что RISC -> 1instruction=1cycle:RISC processors only use simple instructions that can be executed within one clock cycle.
это одна из тех стадий что я привёл, но не единственная.
Так а что в таком случае мешает программному планировщику задействовать алгоритм Томасуло?Brak0del
20.02.2019 16:49То, что гранулярность планировщика == 1 команда, а гранулярность алгоритма Томасуло — 1 стадия. 1 команда требует 5-6 стадий, из этих стадий 1 стадия называется execute.
DaylightIsBurning
20.02.2019 17:06Что такое стадия и что такое команда? Как они соотносятся с терминами такт, инструкция, cycle, instruction?
В RISC/VLIW 1 instruction=1cycle, соответственно программный планировщик может оперировать на уровне циклов.amartology
20.02.2019 17:12Очень люблю, когда о каких-то вещах с жаром спорят люди, которые даже не в курсе базовых понятий темы, на которую они спорят. Но точка зрения имеется, и готовность отстаивать ее с пеной у рта тоже. И то, что если многомиллиардная индустрия в лице Intel не справилась с задачей, то вероятно, задача как минимум очень сложная, никак не смущает.
В RISC/VLIW 1 instruction=1cycle
Повторяю: это не так. Ссылку на википедию про конвейер вам ниже дали.

Вот для простоты картинка.DaylightIsBurning
20.02.2019 17:24даже не в курсе базовых понятий темы, на которую они спорят
Это Вы про кого ;)?
Повторяю: это не так.
видимо, про себя. Наличие конвеера и многостадийность инструкций — вещи вообще никак не связанные. В RISC, в отличии от CISC инструкции однотактовые, но в обоих случаях есть конвеер. А вот у VLIW, о котором и разговор, как раз отличие от RISC в том, что конвеера нет. Вместе с 1цикловостью инструкций это теоретически даёт возможность делать программный планировщик с гранулярностью в 1 cycle.
если многомиллиардная индустрия в лице Intel не справилась с задачей, то вероятно, задача как минимум очень сложная
Я в курсе, потому и задал изначальный вопрос, ответ на который мне показался очень неочевидным. О тех аргументах, которые Вы приводите я тоже сначала подумал, но вынужден был их отбросить как несостоятельные, так как сам же нашел у них недостатки. Надеялся, что кто-то мне подскажет аргументы получше.
многомиллиардная индустрия в лице Intel не справилась с задачей
С какой задачей? Добиться распространения и коммерческого успеха? Не справилась. Но с технической подзадачей они справились, VLIW процессоры Itanium работали вполне себе неплохо.Brak0del
20.02.2019 17:34+1В RISC, в отличии от CISC инструкции однотактовые, но в обоих случаях есть конвеер.
Как вы себе представляете конвейер для инструкции в 1 такт? Что там конвейеризируется, в чём смысл? Более того, с железячной точки зрения любопытно как за один такт расшифровать инструкцию, запросить и получить операнды, выполнить инструкцию, записать результаты? С какой частотой такое будет работать в железе?DaylightIsBurning
20.02.2019 17:37Brak0del
20.02.2019 17:43но там же как раз 5 стадий, не одна
DaylightIsBurning
20.02.2019 19:16Вот что я имею ввиду:
While CISC instructions varied in length, RISC instructions are all the same length and can be fetched in a single operation. Ideally, each of the stages in a RISC processor pipeline should take 1 clock cycle so that the processor finishes an instruction each clock cycle and averages one cycle per instruction (CPI).
amartology
20.02.2019 19:22processor finishes an instruction each clock cycle
Вот на картинке ниже. Каждый такт processor finishes одну инструкцию. При этом выполнение каждой отдельно взятой инструкции занимает четыре такта. Это если без сбросов и простоев, с ними больше.
Так понятнее, что такое конвейер и почему «одна иструкция за такт» — это не то, о чем вы думаете?DaylightIsBurning
20.02.2019 19:23Это именно то, о чем я думаю, что в среднем выполняется одна инструкция за такт. Я (видимо ошибочно) считал, что у VLIW нет конвейера.
amartology
20.02.2019 19:331) У VLIW есть конвейер, и глубокий.
2) Разговор про одну инструкцию за такт начался с вопроса про разную гранулярность аппаратного и программного планировщика.
Аппаратный планировщик имеет гранулярность в один такт, то есть каждый такт смотрит, что происходит со всеми лежащими в конвейере командами, и может принимать решения соответственно.
Для программного планировщика промежуточные результаты выполнения недоступны, поэтому он может сбрасывать конвейер позже, чем смог бы аппаратный, что приводит к значительным потерям в производительности, особенно на сложных ветвящихся алгоритмах, управляемых входными данными.DaylightIsBurning
20.02.2019 20:08смотрит, что происходит со всеми лежащими в конвейере командами
В конверее или на подходе? Он может переставлять стадии уже на выполнении? То есть он может проанализировать ситуацию (составить статистику), принять решение (выбрать ветку), и поменять стадии в конвеере за один цикл?
он может сбрасывать конвейер позже, чем смог бы аппаратный
Но гранулярность такая же, для команд, выполнение которых ещё не началось. Переставлять программный планировщик так же может по одной стадии, только задержка между принятием решения и перестановкой операций = длина конвеера. Если процессор суперскалярный, то есть у нас фактически несколько параллельных конвееров, то на одном из конвееров может крутиться планировщик, если надо.

beeruser
20.02.2019 18:35+1В RISC, в отличии от CISC инструкции однотактовые, но в обоих случаях есть конвеер.
На «CISC» инструкции такие же «однотактовые» ещё с 486.
www.gamedev.net/articles/programming/general-and-gameplay-programming/a-journey-through-the-cpu-pipeline-r3115
А вот у VLIW, о котором и разговор, как раз отличие от RISC в том, что конвеера нет.
Вы вообще не понимаете о чём пишете.
Конвейер нужен для пресловутой «однотактовости» и разумеется у VLIW он точно такой же.DaylightIsBurning
20.02.2019 18:54Вы вообще не понимаете о чём пишете.
Развиваете ЧСВ? Я не «пишу», я спрашиваю. Если бы я всё понимал, я бы не спрашивал.
Конвейер нужен для пресловутой «однотактовости» и разумеется у VLIW он точно такой же.
Если так, то понятно.
DaylightIsBurning
20.02.2019 19:22Гранулярность программного планировщика тоже = 1 стадия. Другое дело, что latency в худшем случае равна длине конвейера, т.к. планировать он может то, что еще не в конвеере. Не знаю, может ли аппаратный планировщик переставлять стадии, которые уже в конвейере.
Brak0del
20.02.2019 19:59Гранулярность программного планировщика тоже = 1 стадия.
Не согласен, гранулярность выходит всё равно одна команда. Если считать как вы, получается, что за такт аппаратный планировщик может делать действия с примерно N командами, где N — глубина конвейера. Т.е. его разрешение всё равно выше.Не знаю, может ли аппаратный планировщик переставлять стадии, которые уже в конвейере.
Частичный ответ на этот вопрос есть всё в том же алгоритме Томасуло, обратите внимание на reservation stations.DaylightIsBurning
20.02.2019 20:02Т.е. его разрешение всё равно выше.
Разрешение не выше, одинаково, оно равно одной стадии. Разница только в том, что аппаратный планировщик может переставлять стадии, которые уже в конвеере, а программный — только те, что ещё не попали в него.
аппаратный планировщик может делать действия с примерно N командами, где N — глубина конвейера
Программный и аппаратный планировщики могут выполнять действия с любым числом стадий, если эти стадии ещё не на конвейере. Если на конвейере — только аппаратный, видимо.Brak0del
20.02.2019 20:11Ну нет же, смотрите, аппаратный планировщик может за стадию разрешить несколько конфликтов по данным, передав операнд на 2,3,4 ждущие команды. Программному для достижения этого придется дождаться завершения текущей команды (чтобы записать операнд в регистр), а затем заполнения конвейера командами 2,3,4, которые дождались своего операнда. Т.е. пройдет N+3 тактов до завершения выполнения команды 4 от момента завершения команды 1. Для аппаратного пройдет 4 такта.
DaylightIsBurning
20.02.2019 20:21затем заполнения конвейера командами 2,3,4, которые дождались своего операнда
Это можно сделать за 1 такт, раз аппаратный может. На самом деле там будет иначе. Компилятор запланирует две похожих последовательности команд по разным адресам, а далее одной командой переключит поток с одной последовательности на другую, в зависимости от результатов предыдущей операции.Brak0del
20.02.2019 20:26Компилятор запланирует две последовательности команд по разным адресам, а далее одной командой переключит поток с одной последовательности на другую, в зависимости от результатов предыдущей операции.
И результат будет получен через N+ тактов, ведь эти последовательности команд (ту последовательность, которую выбрали) надо будет загрузить в конвейер и выполнить, а это как раз N+ тактов.DaylightIsBurning
20.02.2019 20:30И результат будет получен через N+ тактов
Согласен, то есть нужно планировать так, что бы смена ветвей была реже чем длина конвейера, что бы конвейеру было чем заняться, пока идёт переключение веток.
надо будет загрузить в конвейер и выполнить
не в конвейер, а в поток исполнения, то есть «перед» конвейером.Brak0del
20.02.2019 20:53Всё же выше я немного обсчитался, но тенденция верна: когда аппаратный планировщик будет находиться на стадии execute команды 1, он уже будет иметь возможность разослать её результат ждущим этого результата в конвейере командам, а затем перейти на стадию write res. На стадии write res он запишет результат в регистр, в этот момент команда 2 уже будет на стадии execute. Программный планировщик (в паре с компилятором) сможет «передать» результат (точнее результат станет доступным в регистре) командам только после завершения стадии write res. Т.е. после этой стадии команда 2 сможет получить свой операнд при условии, что компилятор положил её так что она дошла в этот момент до стадии чтения операндов (пройдя последовательно и fetch, и decode), потом ей надо пройти execute и write res, сравните это со случаем аппаратного планировщика. И нет, по-моему тут второй поток команд будет лишним, одним быстрее, если потока команд будет 2, то конвейер точно придется разгружать.
amartology
20.02.2019 21:58то есть нужно планировать так, что бы смена ветвей была реже чем длина конвейера
Вот где-то в этот момент компиляторы и начинают проигрывать. Реальные алгоритмы не всегда можно вот так разобрать, особенно для VLIW, который постоянно хочет очень много данных. Такая концепция только для числодробилок хорошо работает.
DaylightIsBurning
20.02.2019 17:37это приводит к лишним командам, на которые требуется время выполнения
Но они и так выполняются, просто скрытно, на аппаратном планировщике.Brak0del
20.02.2019 17:48Нет, ваш программный планировщик вводит настоящие лишние команды, много, которые надо выполнять. Которые тоже должны будут пройти эти стадии. В аппаратном планировщике эти операции происходят одновременно с какой-либо из стадий, например read operands и т.д., т.е. оверхеда по времени нет.
DaylightIsBurning
20.02.2019 18:59Эти «лишние» комманды все равно выполняются, просто невидимо для пользователя. Если сделать команды планирования явными (генерируемыми компилятором), то, они будут слабо зависимы от команд основного потока, а значит их можно будет лучше распихивать для более полной загрузки конвейера.
amartology
20.02.2019 16:43В случае RISC, а тем более VLIW, команда=такт.
Вы в курсе, как конвейер работает?
RISC processors only use simple instructions that can be executed within one clock cycle.
Это просто неправда. Большинство реализаций RISC-процессоров конвейерные, как минимум с тремя, а чаще с пятью-семью ступенями.
Каждый такт заканчивается выполнение новой команды — это обычно так. Но каждая команда выполняется несколько тактов.DaylightIsBurning
20.02.2019 16:48Это просто неправда
Мопед не мой, Стэнфордский. Где можно прочитать другую точку зрения?Brak0del
20.02.2019 16:52Вики устроит? Кстати по вашей ссылке это косвенно тоже можно понять, они там тоже про конвейер упоминают и акцентируются на времени выполнения стадии execute равном в 1 такт.
DaylightIsBurning
20.02.2019 17:09так там сразу и написано:
Each of these classic scalar RISC designs fetched and tried to execute one instruction per cycle.
В случае VLIW конвеера не предполагается — «non-pipelined scalar architecture», а значит, можно в любой момент выкинуть инструкцию из потока и заменить другой, на уровне каждого цикла.amartology
20.02.2019 17:18Each of these classic scalar RISC designs fetched and tried to execute one instruction per cycle.
Еще раз, чтобы вы точно поняли: то, что каждый такт заканчивается выполнение новой инструкции, не означает, что выполнение каждой инструкции длится один такт.
Прочитайте уже, как конвейер устроен, прямо в следующем предложении той статьи в википедии.
amartology
20.02.2019 17:22Для справки: самый популярный из VLIW, Itanium, имеет девятистадийный конвейер — более глубокий, чем у большинства современных RISC-прроцессоров.
Sdima1357
19.02.2019 20:37Другой пример. У Вас есть сапоги и ботинки. Вы не можете заранее спланировать что одеть. А в каждый конкретный день, посмотрев в окно одеваете сапоги если дождь идет и ботинки если дождя нет. Погода тут входные данные. Процессор с предсказанием ветвлений одевает ботинки если вчера дождя не было и сапоги если он был и угадывает достаточно часто.
DaylightIsBurning
19.02.2019 22:57Чем это отличается от программного планировщика, сгенерированного компилятором?
Пример кода:
for (day=0; day<3; ++day) { rain=is_raining(day); if (rain) wear_waders(); else wear_sneakers(); }
Допустимis_raining(0)=false, Аппаратный предсказатель будет «опережая» выполнять wear_sneakers(). Что мешает компилятору сделать такой машинный код:
rain0=is_raining(0); if (rain0) { for (day=0; day<3; ++day) { wear_sneakers(); rain=is_raining(day); if (not rain) { unwear_sneakers(); wear_waders();} } else { ... }
Частоту считать можно точно так же.Sdima1357
19.02.2019 23:52+1Сброс неудачной ветки стоит ресурсов, причем иногда очень значительных а компилятор ну никак не может проанализировать данные которых у него просто нет…
DaylightIsBurning
20.02.2019 02:26сброс ветки стоит ресурсов независимо от ISA, как я понимаю. Компилятор не может проанализировать данные, но он может предусмотреть программный код для анализа этих данных. Я уже привел такой код выше. Программный аналог аппаратного планировщика.
Brak0del
20.02.2019 07:33+2У аппаратного планировщика может быть результат от аппаратного предсказания ветвлений, т.е. он с большей вероятностью угадает переход и сбрасывать не придётся, т.е. для N вызовов этого кода сброс ветки-таки будет стоить меньше в аппаратном случае. Кроме того, эти введенные ветки занимают место в кэше и требуют времени загрузки в кэш, т.е. уже вносят оверхед.
DaylightIsBurning
20.02.2019 15:12может быть результат от аппаратного предсказания ветвлений, т.е. он с большей вероятностью угадает переход
Почему? Чем программный предсказатель хуже? Всю тактическую информацию он точно так же может учитывать (алиасинг, кэш...).
введенные ветки занимают место в кэше и требуют времени загрузки в кэш, т.е. уже вносят оверхед.
Но много ли? Объем кэша x86 CPU сейчас может различаться в разы без особого роста производительности. То есть при необходимости, в каких-то пределах его можно добавить, если надо.Brak0del
20.02.2019 16:23+1Почему? Чем программный предсказатель хуже?
Ну хотя бы тем, что аппаратный предсказатель работает с текущей ситуацией (например с историей N последних вызовов данного кода), а программный предсказатель использует инфу на этапе компиляции.Всю тактическую информацию он точно так же может учитывать (алиасинг, кэш...).
Ценой введения кучи дополнительных инструкций, которые ударят по производительности (ну серьезно, вы предлагаете ввести много лишнего кода, который надо будет исполнить, почему это должно работать быстро?)DaylightIsBurning
20.02.2019 16:40программный предсказатель использует инфу на этапе компиляции.
Это не программный предсказатель, это просто компилятор. Программный предсказать выполняется как обычный код, то есть точно так же как и аппаратный предсказатель может динамически считать и учитывать статистику. Отличие в том, что аппаратный предсказатель выполняется на отдельном харде, параллельном ядру и не может менять свою логику, а программный предсказатель выполняется на том же ядре, что и сам полезный код и его логика может меняться на ходу и генерируется компилятором, в соответствии с контекстом, и потому может быть более специальным и эффективным, чем супер-универсальный аппаратный предсказатель.amartology
20.02.2019 16:46аппаратный предсказатель выполняется на отдельном харде, параллельном ядру и не может менять свою логику
Почему не может?DaylightIsBurning
20.02.2019 17:05Потому что она задается проектировщиками процессора и после изготовления не может быть изменена.
amartology
20.02.2019 17:14Что значит не может быть изменена? А что мешает сделать логику, управляемую состоянием внутренней памяти планировщика? Или, обоже, нейросеть?
DaylightIsBurning
20.02.2019 17:31Конечно, планировщик имеет внутреннюю память, при чём тут изменяемость логики его работы? «Код» планировщика не меняется, он может быть сложным, с ветвлениями, но не меняется.
Brak0del
20.02.2019 16:55Вы знаете, тут спорить не буду, это больше вопрос определений, то, что назвал я тоже называется программным предсказателем, только наверно мне стоило уточнить, что это статический программный предсказатель (например как здесь).
DaylightIsBurning
20.02.2019 17:16Ну такой предсказатель и для CISC и для VLIW может работать. Изначальный вопрос был в том, почему невозможно сделать компилятор, который под VLIW будет генерировать код, исполняемый со скоростью CISC.
vvmtutby
20.02.2019 21:09А почему? В чём оказалась проблема?
VLIW — фирменная «фишка» Эльбрус-2. Далее сплошные «странные» корреляции: лихие девяностые — внезапно появляется IA64, создатель Эльбрусов — лучший почетный работник Intel и т.п.
Поток книг по советскому суперкомпьютеру ( хотя это 1989+ ).
Настал 2008 — «не смогли написать компилятор», эра эвтаназии Itanium.
Совпадения? Не знаю…
dzsysop
19.02.2019 17:42Может скажу глупость, но мне кажется есть вариант улучшения «предсказаний» для многопоточных процессоров с использованием машинного обучения. Возможно сегодня это не входит в программу развития, но почему бы не обучить процессор «правильному» угадыванию. Как раньше к процессору пристраивали сопроцессор или графический процессор, так и сегодня можно встроить отдельный блок, который будет мониторить «трафик» инструкций входящих в процессор и обучать нейросеть. Готовые обученные датасеты могут поставляться вместе с процом как некая прошивка с каким-нибудь индексом к модели. Например под Python отдельно, под Javascript отдельно или под какую-то ОС. А потом проц все равно продолжит (или не продолжит) свое самообучение исходя из типичных инструкций которые он получает в реальности и сам может дообучиться и оптимизироваться на лету повышая свою точность в предугадывании инструкций которые следует выполнять или где не стоит тратить на это ресурсы. И через неделю или месяц эксплуатации эффективность угадывания может быть намного выше чем в первый день работы проца.
Я далек от разработки чипов, так что прошу сильно ногами не бить.
Просто глядя на историю развития процессоров за 30-40 лет, и скорость развития нейросетей и машинного обучения в последние годы, мне кажется это вполне возможным направлением для исследования.Brak0del
19.02.2019 17:54А как быстро (за сколько тактов или сколько операций и т.д.) можно получить предсказание от нейронной сети? Сейчас в процессорах вроде механизмы предсказания на основе набора из пары тысяч простейших счетчиков (локальных и глобальных), они при своей простоте быстры и достаточно точны.
amartology
19.02.2019 18:08+1так и сегодня можно встроить отдельный блок, который будет мониторить «трафик» инструкций входящих в процессор и обучать нейросеть
Так предсказатели ветвлений на нейросетях уже несколько лет как серийно применяются. Samsung Exynos 8890 тому пример, прямо в вашем мобильнике.dzsysop
19.02.2019 18:34Спасибо за наводку. Действительно нашел en.wikichip.org/wiki/samsung/microarchitectures/m1
beeruser
20.02.2019 10:24Так же он есть и в AMD Jaguar.
www.realworldtech.com/jaguar/2
Собственно Самсунг и переманил создателей Jaguar к себе.
greatkir
Удивительная статья, рациональный и охватывающий много факторов взгляд на проблему производительности. Спасибо за перевод!