

Почти десять лет я провёл в довольно специализированной продуктовой компании, создавая высокопроизводительные системы I/O. Все мы видели быстрое и решительное развитие технологий хранения данных, так что работать с NVMe сейчас одно удовольствие.
В этом году я перешёл в более крупную компании с разработчиками из разных сфер с разным бэкграундом. И меня удивил один факт. Безусловно, каждый из них чрезвычайно умён, но большинство вообще не понимает, как наилучшим образом использовать высокую производительность современных систем хранения. Из-за этого они разрабатывают не самую оптимальную архитектуру.
Размышляя о причинах заблуждений, я подумал, что дело в недостатке бенчмарков. Люди просто не проверяют свои предположения на реальных данных.
Распространённые примеры заблуждений:
- «Я разрабатываю быструю систему. Поэтому данные должны быть в памяти».
- Если мы разделим это на несколько файлов, то выйдет медленно из-за рандомных чтений. Нужно оптимизировать данные для последовательного доступа и чтения из одного файла».
- «Ну, здесь можно прекрасно скопировать данные из памяти и выполнить дорогостоящее вычисление, ведь так мы сэкономим одну операцию ввода-вывода, которая ещё дороже».
- Прямой ввод-вывод очень медленный. Он работает только для очень специализированных приложений. Если нет кэша, вы обречены.
Тем не менее, беглый просмотр спецификаций современных NVMe показывает задержки в несколько микросекунд, пропускную способность в гигабайты/с, производительность в сотни тысяч случайных IOPS. Так в чём проблема?
В этой статье я покажу, что несмотря на огромный прогресс железа за последнее десятилетие, программные API практически не изменились. Они напичканы копированием памяти, распределением памяти, чрезмерно оптимистичным кэшированием чтения и всевозможными дорогостоящими операциями. Эти устаревшие API мешают максимально использовать современное оборудование.
В процессе написания статьи я получил доступ к одному из устройств Intel Optane следующего поколения. Хотя они ещё не распространились на рынке, но демонстрируют тренд к дальнейшему ускорению устройств. Здесь приведены бенчмарки именно с такого девайса.
Ради экономии места сосредоточимся на операциях чтения. У записи отдельный набор проблем — а также возможностей для улучшений, которые рассмотрим в следующей статье.
Типичные проблемы API
У обычных файловых API три основные проблемы:
- Они выполняют много ресурсоёмких операций, чтобы избежать «дорогого» I/O
Когда устаревшим API нужно считать данные не из кэша, они генерируют page fault. А когда данные готовы — прерывание. Наконец, для традиционного чтения на основе системных вызовов у вас создаётся дополнительная копия в пользовательском буфере, а для операций на основе mmap придётся обновить сопоставления виртуальной памяти.
Ни все эти операции — page fault, прерывание, копии или отображения виртуальной памяти — обходятся дороже, чем принято считать. Много лет назад они были примерно в 100 раз дешевле I/O, делая такой подход приемлемым. Сейчас это уже не так, поскольку задержка устройств упала до нескольких микросекунд, как у операций с памятью.
Приблизительные расчёты показывают, что задержка устройства занимает не больше половины всего времени операции. Это не считая всех отходов, что подводит нас ко второй проблеме:
- Лишние чтения
Опустим здесь некоторые детали (память для файловых дескрипторов, кэши метаданных в Linux). Итак, если современные NVMe поддерживают множество параллельных операций, то нет никаких оснований полагать, что чтение из нескольких файлов обходится дороже, чем из одного. Безусловно, имеет значение совокупный объём прочитанных данных.
Операционная система считывает данные постранично, то есть минимум по 4 КБ. Это означает, что если нужно прочитать 1 КБ в двух файлах по 512 байт, вы эффективно читаете 8 КБ, отбрасывая 87% прочитанных данных. На практике ОС также выполняет упреждающее чтение с настройкой по умолчанию 128 КБ. Если эти данные не пригодятся, то вы просто считали 256 КБ, чтобы получить 1 КБ, потратив впустую 99% объёма операции.
Так что чтение из нескольких файлов действительно может быть немного медленнее, чем чтение из одного файла, но только из-за того, что объём реально считываемых данных значительно увеличился.
Поскольку проблема заключается в системном кэше страниц, то почему просто не открыть файл напрямую при прочих равных? К сожалению, это тоже вряд ли ускорит процесс. Из-за третьей и последней проблемы:
- Традиционные API не используют параллелизм
Файл рассматривается как последовательный поток байтов. Независимо от того, находятся данные в памяти или нет, они прозрачны для чтения. Традиционные API будут ждать, пока вы не коснётесь данных, чтобы выполнить операцию ввода-вывода. Эта операция может прочитать больше данных, чем запросил пользователь, из-за упреждающего чтения, но всё равно это всего лишь одна операция.
Несмотря на всю быстроту современных устройств, они всё равно медленнее CPU. Пока ожидается результат операции I/O, процессор простаивает.
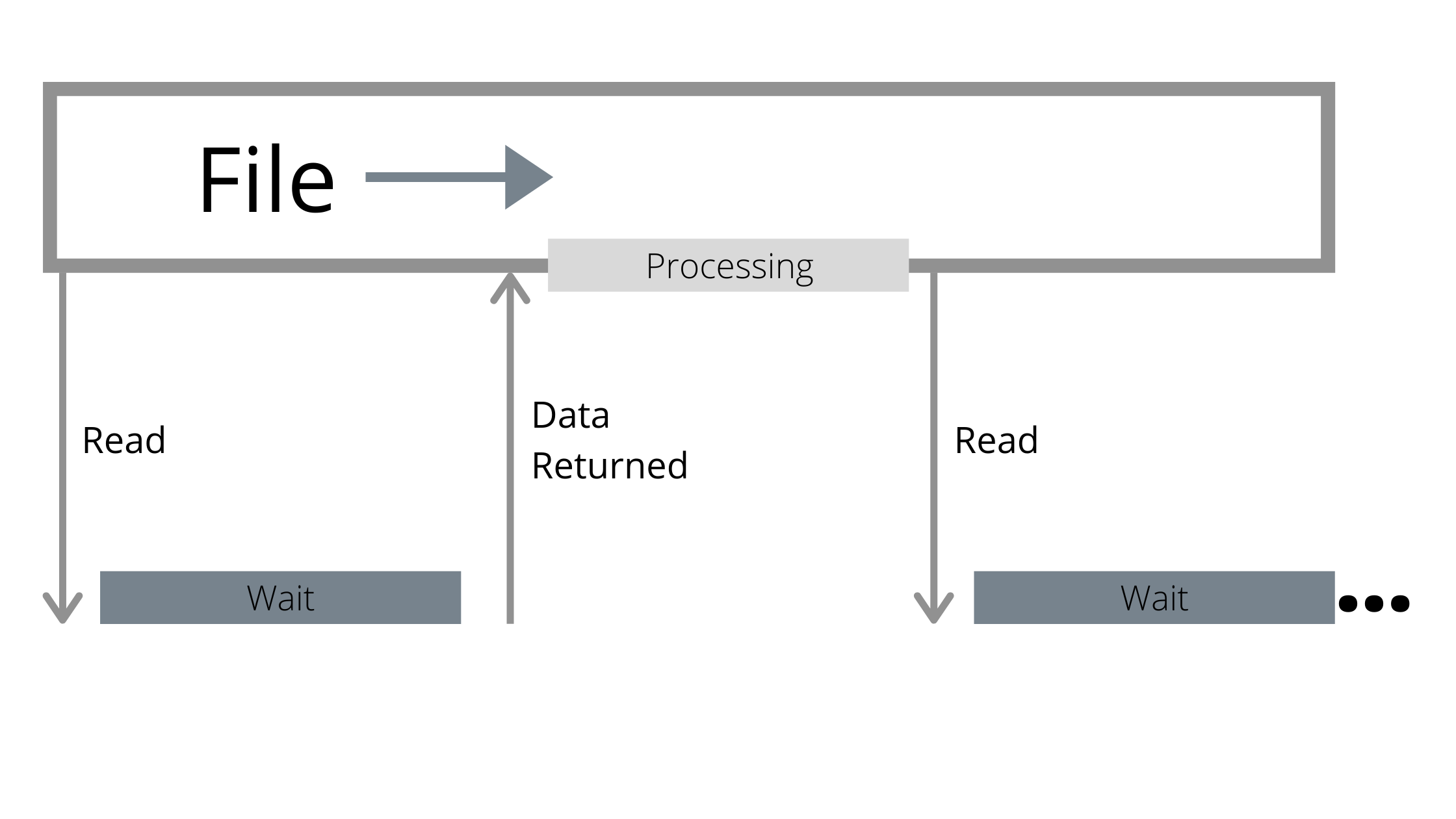
Отсутствие параллелизма в традиционных API приводит к тому, что CPU простаивают в ожидании возврата ввода-вывода
Использование нескольких файлов — шаг в правильном направлении, поскольку позволяет более эффективно распараллелить процесс. Пока один процесс ждёт результат операции, другой может продолжать. Но если не соблюдать осторожность, вы просто усугубите одну из предыдущих проблем:
- Несколько файлов означает несколько буферов упреждающего чтения, что увеличивает коэффициент потерь для случайного ввода-вывода.
- В потоковом API несколько файлов означает несколько потоков, что увеличивает объём работы на одну операцию ввода-вывода.
Не говоря уже о том, что во многих ситуациях это не то, что нам нужно. Начать с того, что у нас может быть не так много файлов.
К лучшим API
Я уже писал о революционном интерфейсе io_uring в Linux. Но это низкоуровневый интерфейс, и его недостаточно для решения всех проблем с API. Вот почему:
- Если ввод-вывод через io_uring использует буферизованные файлы, то он по-прежнему страдает от большинства проблем, перечисленных ранее.
- В прямых операциях I/O много подводных камней, а io_uring как интерфейс низкого уровня даже не пытается (и не должен) скрыть их: например, нужно правильно выровнять память, а также позиции, с которых происходит чтение.
- Для получения выгоды от использования этого интерфейса, нужно накапливать операции ввода-вывода и отправлять их партиями. Это требует установления правил и определённого цикла событий (event loop), так что он лучше работает с фреймворком, который обеспечивает необходимые механизмы.
Для решения перечисленных проблем API я написал библиотеку Rust под названием Glommio (ранее была известна как Scipio) для распараллеливания потоков прямого ввода-вывода. Glommio опирается на io_uring и поддерживает многие расширенные функции, такие как registered buffers и завершения на опросах (poll-based, без прерываний), чтобы операции прямого ввода-вывода просто летали. Для удобства Glommio поддерживает буферизованные файлы с кэшем страниц Linux примерно как в стандартных API Rust, но она всё-таки ориентирована именно на прямой ввод-вывод.
В Glommio два класса файлов: файлы произвольного доступа (random access files) и потоки (streams).
Файлы произвольного доступа выступают аргументом, то есть не нужно поддерживать курсор поиска. Но что ещё более важно, они не принимают буфер в качестве параметра. Вместо этого они используют предварительно зарегистрированную буферную область io_uring для выделения буфера и возврата пользователю. Никакого отображения памяти, никакого копирования в пользовательский буфер, только копирование с устройства в буфер Glommio — и пользователь получает ссылку на указатель. И поскольку это случайный ввод-вывод, то не нужно читать больше данных, чем было запрошено.
pub async fn read_at<'_>(&'_ self, pos: u64, size: usize) -> Result<ReadResult>С другой стороны, потоки предполагают чтение всего файла, поэтому используют больший размер блока и коэффициент упреждающего чтения.
Потоки максимально похожи на дефолтный AsyncRead в Rust, поэтому реализуют трейт AsyncRead и всё равно считывают данные в пользовательский буфер. Все преимущества прямого ввода-вывода сохраняются, но существует копия между внутренними буферами упреждающего чтения и пользовательским буфером. Это своеобразный налог на удобство использования стандартного API.
Если вам нужна дополнительная производительность, Glommio предоставляет доступ API в поток, который тоже предоставляет необработанные буферы, сохраняя дополнительную копию.
pub async fn get_buffer_aligned<'_>(
&'_ mut self,
len: u64
) -> Result<ReadResult>Тесты
Есть пример программы, которая выдаёт ввод-вывод с различными настройками, используя все эти API (с буферизацией, прямой ввод-вывод, случайный, последовательный) и оценивает их производительность.
Начнём с файла примерно в 2,5 раза больше объёма оперативной памяти. Для начала проведём простое последовательное чтение как обычный буферизованный файл:
Buffered I/O: Scanned 53GB in 56s, 945.14 MB/s
Неплохо для файла, который не помещается в памяти. Но по сути все лавры достаются нереальной производительности Intel Optane и бэкенду io_uring, который по-прежнему эффективно распараллеливает поток ввода-вывода (parallelism of one). И хотя размер системной страницы 4 КБ, упреждающее чтение позволяет нам эффективно увеличить размер ввода-вывода.
И в самом деле, если эмулировать подобные параметры с помощью API прямого ввода-вывода (буферы 4 КБ, parallelism of one), результаты окажутся разочаровывающими, «подтверждая» наше подозрение, что прямой ввод-вывод действительно намного медленнее.
Direct I/O: Scanned 53GB in 115s, 463.23 MB/s
Но мы уже обсуждали, что потоки Glommio могут принимать явный параметр упреждающего чтения. Библиотека выдаёт упреждающие запросы I/O, чтобы задействовать параллелизм устройства.
Упреждающее чтение Glommio работает иначе, чем на уровне ОС: наша цель — использовать параллелизм, а не просто увеличить объём ввода-вывода. Вместо того, чтобы потребить весь буфер упреждающего чтения и только затем запрашивать новый пакет, Glommio всегда пытаться сохранить фиксированное количество активных буферов, как показано на рисунке.

Во время опустошения одного буфера уже запрашивается другой. Это улучшает параллелизм и поддерживает его на высоком уровне
Как только мы включаем правильный параллелизм, установив коэффициент упреждающего чтения, прямой ввод-вывод не только догоняет по производительности буферизованный ввод-вывод, но и намного опережает его.
Direct I/O, read ahead: Scanned 53GB in 22s, 2.35 GB/s
Эта версия по-прежнему использует интерфейсы AsyncReadExt из Rust, которые делают дополнительное копирование из буферов Glommio в пользовательские буферы.
Интерфейсы get_buffer_aligned дают прямой доступ к буферу, который позволяет избежать этого последнего копирования памяти. Если задействовать данные API в нашем тесте, то производительность увеличивается на 4%:
Direct I/O, glommio API: Scanned 53GB in 21s, 2.45 GB/s
Последний шаг — увеличить размер буфера. Поскольку это последовательное сканирование, нет необходимости ограничивать буфер размером 4 КБ, разве что для сравнения с системным кэшем.
На этом этапе давайте объединим в одном тесте всё, что делают под капотом Glommio и io_uring:
- каждый запрос ввода-вывода на 512 КБ;
- 5 одновременных запросов для параллелизма;
- память предварительно выделена и предварительно зарегистрирована;
- нет дополнительного копирования в пользовательский буфер;
- io_uring установлен в режим опроса (poll mode), то есть никакого копирования памяти, никаких прерываний, никаких переключений контекста.
Результаты?
Direct I/O, glommio API, large buffer: Scanned 53GB in 7s, 7.29 GB/s
Это более чем в семь раз быстрее стандартного подхода с буферами. А использование памяти никогда не поднимается выше того, что установлено в качестве коэффициента упреждающего чтения, умноженного на размер буфера. В данном примере это 2,5 МБ.
Случайное чтение
Как известно, сканирование пагубно влияет на системный кэш. А что насчёт операций случайного чтения? Для проверки прочитаем столько, сколько сможем за 20 секунд, сначала ограничимся первыми 10% доступной памяти (1,65 ГБ).
Buffered I/O: size span of 1.65 GB, for 20s, 693870 IOPS
Для прямого ввода-вывода:
Direct I/O: size span of 1.65 GB, for 20s, 551547 IOPS
Прямой ввод-вывод на 20% медленнее, чем буферизованное чтение. Ничего удивительного, что чтения полностью из памяти всё ещё быстрее, но разница не такая большая, как можно было бы ожидать. При этом учтите, что буферизованная версия выделяет 1,65 ГБ оперативной памяти для работы, в то время как прямой ввод-вывод использует только 80 КБ (20 буферов по 4 КБ). Так что второй вариант даже предпочтительнее для определённого класса приложений, которые не хотят занимать много памяти.
Как скажет вам любой инженер по производительности, хороший тест чтения должен считывать данные на достаточной скорости для записи на носитель. В конце концов, «накопители медленные». В такой ситуации наша буферизованная производительность резко падает на 65%.
Buffered I/O: size span of 53.69 GB, for 20s, 237858 IOPS
А в прямом вводе-выводе не меняется ни производительность, но объём занимаемой памяти — эти показатели не зависят от объёма прочитанных данных.
Direct I/O: size span of 53.69 GB, for 20s, 547479 IOPS
Если для сравнения взять крупные сканы, то прямой ввод-вывод происходит в 2,3 раза быстрее, чем через буферы.
Вывод
Современные устройства NVMe заставляют иначе подходить к оптимизации ввода-вывода в stateful-приложениях. Эта тенденция сохраняется уже некоторое время. Но большинство API, особенно более высокого уровня, до сих пор не эволюционировали в соответствии с изменениями NVMe и уровней ядра Linux. При правильном выборе API прямой ввод-вывод становится новым королём.
Новые устройства, такие как новейшее поколение Intel Optane, просто закрепляют статус-кво. Не существует сценария, в котором стандартный буферизованный ввод-вывод бесспорно лучше, чем прямой ввод-вывод.
При сканировании производительность хорошо адаптированных API на основе прямого ввода-вывода просто намного выше. Да, стандартные API буферизованного ввода-вывода на 20% быстрее для случайных считываний, которые полностью помещаются в память. Но это происходит за счёт увеличения использования памяти в 200 раз, что делает выбор не таким очевидным.
Приложения, которые действительно нуждаются в дополнительной производительности, всё равно захотят кэшировать некоторые результаты. В будущем Glommio обеспечит простую интеграцию специализированных кэшей с прямым вводом-выводом. Работаю над этим.