

В этой статье мы описываем опыт применения технологии анализа изображений для улучшения алгоритма сопутствующих товаров. Читать ее можно двумя способами: те, кто не интересуется техническими деталями использования нейронных сетей, могут пропустить главы про формирование датасета и реализацию решений и перейти сразу к AB-тестам и их результатам. А тем, кто имеет базовое представление о таких понятиях как эмбендинги, слой нейронной сети и т.д., будет интересен весь материал целиком.
Deep Learning в контексте анализа изображений
В нашем технологическом стеке для решения некоторых задач довольно успешно используется глубинное обучение (Deep Learning). Какое-то время мы не решались применять его в контексте анализа изображений, но недавно появился ряд предпосылок, которые изменили наше мнение:
- возрос общий интерес сообщества к анализу изображений с помощью методов глубинного обучения;
- определился круг «зрелых» фреймворков и предобученных нейронных сетей, с которых можно было довольно быстро и просто начать;
- анализ изображений в рекомендательных системах стал часто использоваться как маркетинговая фича, которая гарантирует «невиданные» улучшения;
- стали появляться продуктовые потребности в такого рода исследованиях.
В контексте пересечения рекомендательных систем и анализа изображений может быть множество применений глубинного обучения, однако мы на первом этапе выделили для себя три основных пути развития этого направления:
- Общее улучшение качества рекомендаций, например сопутствующие товары к платью более качественно подходят по цвету и фасону.
- Нахождение товаров в товарной базе магазина по фотографии (In Shop Retrieval) — механизм, позволяющий находить товары в базе магазина по загруженной фотографии.
- Определение свойств/атрибутов товара по фотографии (Attribute Tagging), когда по фотографии определяются значимые атрибуты, например тип товара — футболка, куртка, брюки и прочее.
Самое приоритетное и перспективное для нас направление — это первый вариант, его мы и решили исследовать.
Почему выбрали алгоритм сопутствующих товаров
У любой рекомендательной системы существует два базовых статичных товарных алгоритма: альтернативы и сопутствующие товары. И если с альтернативами все понятно — это похожие на исходную модель товары (например, разные виды рубашек) то с сопутствующими товарами все гораздо сложнее. Здесь важно не ошибиться с соответствием базового и рекомендуемого товаров, например зарядное устройство по разъему должно подходить к телефону, цвет платья к туфлям и т.д.; нужно учесть обратную связь, например, к зарядному устройству не рекомендовать телефон, несмотря на то, что они покупаются вместе; и продумать кучу других нюансов, которые возникают на практике. Во многом из-за наличия различных нюансов наш выбор пал именно на сопутствующие товары. Кроме, только в сопутствующих товарах есть возможность сформировать полноценный look, если говорить о fashion сегменте.
Главную исследовательскую цель мы сформулировали как «Понять, можно ли с использованием методов глубинного обучения для анализа изображений значимо улучшить текущий алгоритм сопутствующих товаров»
Отмечу, что до этого мы совсем не использовали информацию об изображении при расчете товарных рекомендаций и вот почему:
- За время существования платформы Retail Rocket мы накопили большую экспертизу в области работы товарных рекомендаций. И главный вывод, который мы получили за это время — правильное использование пользовательского поведения обеспечивает практически 90% результата. Да, существует проблема холодного старта, когда именно контентные вещи, например информация об изображении, могут уточнить или улучшить рекомендации, но на практике этот эффект намного меньше, чем о нем говорят в теории. Поэтому, мы не делаем особой ставки на контентные источники информации.
- Для построения товарных рекомендаций в виде контентной информации мы используем такие элементы как цена, категория, описание и другие свойства, которые передает нам магазин. Эти свойства независимы от сферы и качественно валидируются при интеграции нашего сервиса. Ценность изображения, напротив, возникает фактически только в сегменте fashion товаров.
- Поддержание сервиса работы с картинками, валидации их качества и соответствия товарам — это довольно сложный процесс и серьезный технический долг, который не хотелось брать на себя без подтверждения необходимости.
И все же мы решили дать шанс картинкам и посмотреть, насколько они повлияют на эффективность построения рекомендаций. Наш подход не является идеальным, наверняка кто-то решил бы проблему по-другому. Задача этой статьи представить наш подход с описанием доводов на каждом шаге и изложить результаты перед читателем.
Формирование концепции
Мы начали с того, что пересекли три составляющие любого продукта: доступные технологии, имеющиеся ресурсы и потребности клиентов. Концепция «улучшения рекомендаций за счет информации об изображении сопутствующих товаров» сложилась сама собой. «Идеальная» реализация этого продукта сформировалась как выдача, составленная по образу подобранного look. Причем такого рода рекомендации должны не только выглядеть отлично, но и работать с точки зрения основных e-commerce метрик (Conversion, RPV, AOV) не хуже нашего базового алгоритма.
Look — это подобранный стилистами образ, который включает в себя набор сочетающихся между собой различных вещей, например платье, жакет, сумка, пояс и т.д. На стороне наших клиентов такой работой, как правило, занимаются специально выделенные люди, работа которых плохо автоматизируется. Ведь иметь чувство вкуса может иметь не каждая нейронная сеть.

Пример образа (look).
Сразу появились ограничения использования информации об изображении — по факту применение нашлось только в сегменте fashion.
Инфраструктура и датасет
Первым делом мы подняли тестовый стенд для экспериментов и прототипирования. Тут все довольно стандартно GPU + Python + Keras, поэтому не будем вдаваться в детали. Мы нашли качественный датасет, который был предназначен для решения сразу нескольких задач, начиная с предсказания атрибутов по изображению и заканчивая генерацией новых текстур одежды. Что было особенно важным для нас, он включал в себя фотографии, которые составляли фактически единый look. Также датасет включал в себя фотографии моделей одежды с разных ракурсов, что мы и попытались использовать на первом этапе.

Пример look из датасета.

Примеры изображений одной и той же модели одежды с разных ракурсов.
Первые шаги
Первая идея реализации финального продукта с помощью датасета была достаточно проста: «Давайте сведем проблему к задаче распознавания одежды по изображению. Таким, образом, при формировании рекомендаций будем “поднимать наверх” те рекомендации, которые похожи на базовый товар». Соответственно, предполагалось найти функцию «близости» товаров и по ходу решить проблему удаления альтернатив в выдаче.
Сразу скажу, что такого рода задача могла быть решена и с использованием обычной предобученной нейронной сети, например ResNet-50. Действительно: убираем последний слой, получаем эмбендинги, ну а потом косинус, как мера “близости”. Однако, немного поэкспериментировав с таким подходом мы решили оставить его в основном по трем причинам.
- Не очень понятно, как правильно интерпретировать полученную близость. Что такое скажем cosine = 0.7 в домене футболок, где как правило все сильно похоже друг на друга и что такое cosine = 0.5 в домене курток, где отличия более существенны. Такого рода интерпретация нам была нужна, чтобы попутно удалять совсем близкие товары — альтернативы.
- Такой подход нас немного ограничивал с точки зрения дообучения под наши конкретные задачи. Например, важные черты, которые формируют целостный образ, не всегда одинаковы от домена к домену. Где-то более важны цвет и форма, а где-то материал и его текстура. Дополнительно нам хотелось дообучить сеть совершать меньше гендерных ошибок, когда к мужской одежде рекомендуется женская. Такая ошибка сразу бросается в глаза и должна встречаться как можно реже. С простым использованием предобученных нейронных сетей казалось, что мы немного ограничены отсутствием возможности подавать примеры, которые хорошо “похожи” с точки зрения образа.
- Использование более подходящих под эти задачи Cиамских нейронных сетей (Siamese Networks) казалось более естественным и хорошо изученным вариантом.
Немного о Сиамской нейронной сети
Широкое применение Сиамские нейронные сети получили при решении задач, связанных с распознаванием лиц. На входе подается изображение лица, на выходе — имя человека из база данных, которому оно принадлежит. Такая задача может быть решена и напрямую, если использовать на последнем слое нейронной сети softmax и количество классов, равное количеству распознаваемых людей. Однако такой подход имеет ряд ограничений:
- нужно иметь достаточно большое количество изображений на каждый класс, что на практике невозможно.
- такую нейронную сеть придется переобучать каждый раз, когда добавляется новый человек в базу данных, что совсем неудобно.
Логичным решением в такой ситуации будет получение функции “похожести” двух фотографий, чтобы в любой момент ответить, принадлежат ли две фотографии — подаваемая на вход нейронной сети и референсная из базы данных — одному и тому же человеку, и соответственно решить проблему распознавания лиц. Это в большей степени соответствует тому, как ведет себя человек. Например, охранник смотрит на лицо человека и фотографию на бейдже и отвечает на вопрос, одно это лицо или нет. Сиамская нейронная сеть реализует похожую концепцию.
Основной компонент Сиамской нейронной сети — это backbone нейронная сеть, которая на выходе дает эмбендинг изображения. Этот эмбендинг может использоваться для определения степени схожести двух картинок. В архитектуре Сиамской нейронной сети backbone-компонент используется два раза, каждый раз для получения эмбендинга изображения. Исследователю остается показывать на выходе значения 0 или 1 в зависимости от того, одному или разным людям принадлежат фотографии, и подстраивать backbone нейронную сеть.

Пример Сиамской нейронной сети. Эмбендинги верхнего и нижнего изображения получаются из backbone нейронной сети. Изображение взято из курса Andrey Ng “Convolutional Neural Networks”.
Базовое решение
Таким образом, после некоторого экспериментирования первая версия алгоритма сложилась следующим образом:
- Берем любую предобученную нейронную сеть в качестве backbone. Мы экспериментировали с ResNet-50 и InceptionV3. Выбирали по принципу баланса размера сети и точности предсказаний. Ориентировались на данные, представленные в официальной документации по Keras раздел “Documentation for individual models”.
- Создаем на ее основе Сиамскую сеть и используем для обучения триплет лосс (Triplet Loss).
- В качестве позитивных примеров подаем то же изображение, но в другом ракурсе. В качестве негативного примера подаем другой товар.
- Имея обученную модель, получаем метрику близости для любой пары товаров аналогично тому как считается Triplet Loss.

Код расчета Triplet Loss.
Дело с Triplet Loss на реальном проекте имели в первый раз, что создало ряд трудностей. Сначала долго боролись с тем, что полученные эмбендинги все сводились в одну точку. Тут был целый ряд причин: мы не делали нормализации эмбендингов перед расчетом лосса; margin параметр alpha был слишком маленьким, а примеры слишком трудными. Добавили нормализацию и эмбендинги стали различаться. Второй проблемой неожиданно стал Gradient Exploding. Благо, что Keras позволял довольно просто решить эту проблему — добавили clipnorm=1.0 в оптимизатор, что не позволяло разрастаться градиентам при обучении.
Работа была итеративная: обучали модель, понижали лосс, смотрели финальный результат и экспертно принимали решение, в каком направлении идем. В какой-то момент стало понятно, что мы сразу подаем довольно сложные примеры и сложность не меняется в процессе обучения, что негативно сказывается на финальном результате. К счастью, датасет с которым мы работали имел хорошую древовидную структуру, которая отражала сам товар, например Men -> Pants, Men -> Sweaters и тд. Это позволило нам переделать генератор и мы стали первые несколько эпох подавать «легкие» примеры, потом более сложные и так далее. Самые сложные примеры — это товары той же товарной категории, например Pants, в качестве негативных.
В итоге мы получили модель, которая отличалась по производимому результату от “наивной” методики использования ResNet-50. Однако качество финальных рекомендаций нас не полностью устраивало. Во-первых, оставалась проблема с гендерными ошибками, но было понимание как ее можно было решить. Так как датасет разделял одежду на мужскую и женскую, можно было легко собрать негативные примеры для обучения. Во-вторых, обучая на датасете финальный результат, мы визуально проверяли на наших клиентах — сразу стало понятно, что придется дообучаться именно на их примерах, так как на некоторых алгоритм работал совсем плохо, если товары слабо пересекались с тем, что было показано при обучении. Наконец, качество было зачастую плохим, потому что изображение при обучении зачастую была шумным и содержало, например, не только джинсы, но и майку.

Изображение джинс на котором по факту изображены еще и майка, и ботинки.
Первый опыт послужил основой для последующего решения, хотя мы и не сразу приступили к реализации улучшенной модели.

Пример рекомендаций, построенных на основе базового решения. Есть гендерные ошибки, так же всплывают альтернативы.
Улучшенная модель
Начали с того, что дообучили ResNet-50 на данных нашего датасета. В датасете имеется информация о том, что изображено на картинке. Она извлекается из структуры датасета Men -> Pants, Women -> Cardigans и прочее. Данную процедуру сделали по двум причинам: во-первых, хотели “направить” backbone — нейронную сеть на домен одежды; во-вторых, так как одежда разделяется еще и по полу, надеялись избавиться от проблемы гендерных ошибок, которые встречались в первой версии.
На втором этапе мы попытались одновременно убрать шум из входных изображений и получить позитивные пары сопутствующих товаров для последующего обучения. Используемый нами датасет также предназначен для решения проблемы обнаружения объектов на картинке. Другими словами для каждого изображения имеются: координаты прямоугольника, который описывает объект и его класс. Для решения такого рода задачи мы воспользовались уже готовым проектом. В данном проекте используется архитектура нейронной сети RetinaNet с использованием особого фокального лосса. Суть этого лосса больше фокусироваться не на фоне изображения, который есть практически в каждой картинке, а на объекте который надо детектировать. В качестве backbone нейронной сети при обучении мы использовали нашу дообученную сеть ResNet-50.
В итоге на каждом изображении из датасета детектируется три класса объектов: “верх”, “низ” и “общий вид”. После определения классов “верх” и “низ” мы просто разрезаем картинку на две отдельные картинки, которые будут использоваться впоследствие как пара положительных примеров для подсчета Triplet Loss. Качество детектирования объектов получилось довольно высоким, единственной претензией было то, что не всегда удавалось найти класс на изображении. Это не было для нас проблемой, так как мы могли легко увеличить количество изображений для предсказаний.

Пример обнаружения классов “верх” и “низ” и разрезания изображения.
Имея такого рода сплиттер картинок, мы получили возможность взять любой look из интернета и разделить его на составляющие с целью использования при обучении. Чтобы увеличить обучающую выборку и победить проблему с недостаточным покрытием примеров, которая возникла при проработке базового решения, мы расширили датасет за счет “разрезанных” образов одного из наших клиентов. Единственной проблемой оставалось то, что мы не выделяли такие объекты как “аксессуар”, “головной убор”, “обувь” и прочее. Это создавало некоторые ограничения, но вполне годилось для проверки концепта. Мы планировали после получения положительных результатов расширить модель и на описанные выше классы.
Получив расширенный датасет, мы воспользовались уже проверенной методикой построения Сиамской сети из базового решения, хотя и было несколько отличий. Во-первых, в качестве backbone нейронной сети мы использовали теперь дообученную сеть ResNet-50, описанную выше. Во-вторых, теперь в качестве позитивных примеров мы подавали пары верх-низ и наоборот, давая выучить по факту нейронной сети именно “соответствие” образа. Ну и собственно десяток эпох спустя у нас появился механизм, который давал на выходе возможность оценить “соответствие” товаров единому образу.

Пример рекомендаций, построенных на основе использования нейронной сети. К базовому товару — шорты, рекомендуются майки.
Финальный результат нас порадовал: рекомендации получились визуально неплохого качества и, что особенно хорошо, их построение не требовало совершенно никакой истории взаимодействий пользователя. Однако оставались проблемы, основной из них было наличие альтернатив в выдаче. Так попадались выдачи в которых к “низу” рекомендовался “низ”, аналогично происходило и с категорией “верх”. Это заставило нас задуматься и доработать решение для удаления альтернатив.
Удаление альтернатив
Решить проблему наличия альтернатив выдаче удалось довольно быстро. Помогли первоначальные опыты с “ванильным” ResNet-50. Такая нейронная сеть выдавала в качестве “похожих” товаров те, которые в наибольшей степени совпадали по изображению — фактически альтернативы. То есть ее можно было использовать для определения альтернатив.

Пример рекомендаций, построенных на основе “ванильного” ResNet-50. Товары являются альтернативами.
Воспользовавшись этим полезным свойством ResNet-50 мы стали фильтровать из выдачи максимально близкие товары, убрав тем самым альтернативы. Были и минусы такого подхода — все та же непонятная ситуация с тем какой threshold для фильтрации выбрать. Иногда фильтровалось достаточно много товаров, несмотря на то, что внешне это были не альтернативы. Однако мы не стали заострять внимание на этой проблеме и продолжили работу дальше.
Подготовка AB-Тестов
Для финальной проверки фактически любого изменения в алгоритмах мы широко используем инструмент АБ-тестирования. Более того у нас действует только одно правило: “каким бы маленьким ни был лосс, какой бы ни была сложной и многослойной нейронная сеть, какими красивыми бы ни были рекомендации — это все не считается если нет результата на АБ-тесте”. Логика довольно простая: АБ-тест — это самый честный, понятный всем сторонам (особенно клиентам и бизнесу) и точный метод измерить результат. За время существования Retail Rocket мы провели огромное количество АБ-тестов и накопили колоссальную экспертизу в нюансах этого процесса (о чем можно подробнее прочитать в статье «Подводные камни A/Б-тестирования или почему 99% ваших сплит-тестов проводятся неверно?»). Поэтому вопрос о проведении АБ-теста для фиксации изменений стоял изначально.
В рамках работы над такого рода исследованиями мы проводим предварительные оффлайн тесты перед запуском реальных АБ-тестов. О том, как проводят у нас оффлайн тесты подробно рассказывал наш директор по аналитике на RecSys 2016. Оффлайн тест в первую очередь является для нас своего рода проверкой на баг в алгоритме. Например, если разработан новый алгоритм, который повышает диверсификацию выдачи, мы можем отыграть его на исторических логах и посмотреть, увеличилась ли средняя диверсификация выдачи или нет. Таким образом, мы проверяем какие-то свои априорные предположения, которые должны выполняться.
Изначально мы не планировали заменять все сопутствующие товары на выдачу, сформированную новым алгоритмом. Мы планировали заменить только ту часть в которой мы не уверены, то есть поведение отсутствует или его недостаточно. Тут во всей красе можно использовать информацию об изображении, так как это не требует истории. Мы выбрали предварительный пул партнеров для проведения АБ-теста и провели на них оффлайн тесты. Оказалось, что при всем количестве изменений, вносимых нашим новым алгоритмом, чтобы зафиксировать различия, проводить АБ-тест нам придется несколько месяцев. Мы в буквальном смысле попали в патовое положение: имея практически готовый продукт на руках мы были не способны фактически доказать его эффективность.
В теории АБ-тесты можно проводить неограниченное время, однако на практике это не так. Во-первых, если требуется несколько месяцев, чтобы зафиксировать изменение, то это уже индикатор того, что мы работаем в неправильном направлении. Во-вторых, сайт — это организм, который постоянно меняется, мы имеем долю тестов, которые не состоялись, потому что клиент может внести несовместимые с тестом правки. Например, на некоторое время убрать или подвинуть наши блоки. Соответственно, если тест длится несколько месяцев, вероятность того, что он будет “испорчен», стремится к единице.
Вариантов оставалось два:
- Начать расширять область применения алгоритма и расширить его не только на “верх” и “низ”, но и добавить туда всякого рода аксессуары, обувь, головные уборы, куртки и пр. Однако, предварительные результаты говорили о том, что это существенно не изменит ситуацию, да и работы пришлось бы сделать немало.
- Рискнуть и выставить наш новый алгоритм против поведения, а не только в качестве холодного старта. Так мы могли сделать proof-of-concept на доступной области применения, да и получение значимого результата не было проблемой.
Мы решили остановиться на втором варианте, где проверяем наш алгоритм сопутствующих товаров против текущего алгоритма, который в существенной степени опирается на поведение. Отметим, что внутри команды уже появилась внутренняя неуверенность в том, что информация из картинок может переиграть поведение.
Результаты AB-Тестов
В формате, описанном в предыдущем разделе, мы запустили АБ-тесты на четырех наших клиентах. Все клиенты — это магазины ориентированные на сегмент fashion. Блоки сопутствующих товаров в тесте были установлены в карточке товаров. Таким образом, пользователь имел возможность сразу видеть на одной странице доступный образ, который может быть сформирован с просматриваемым товаром. Гипотеза была в том, что если алгоритм работает, это положительно скажется на конверсии и среднем чеке.
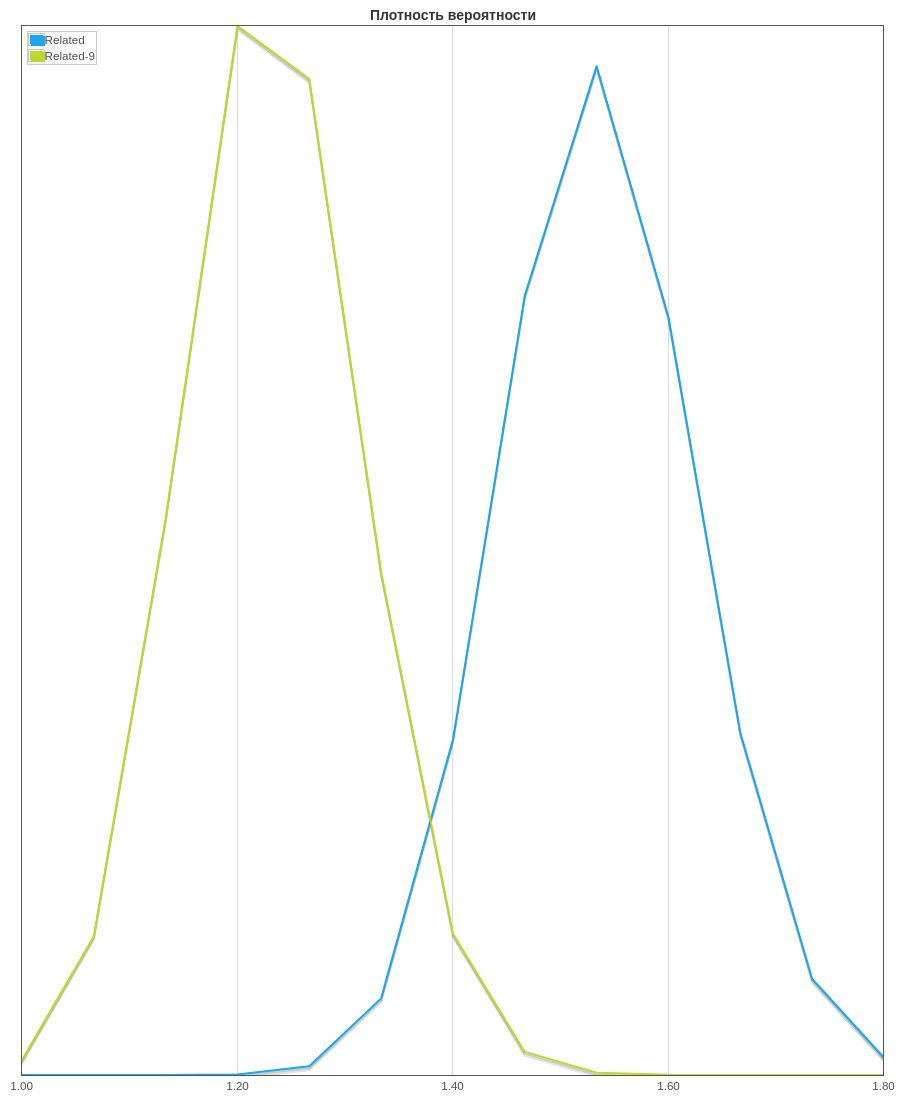
Результаты не заставили себя долго ждать. Первый тест был остановлен спустя 3 недели. Проигрыш новой версии алгоритма был зафиксирован как по конверсии, так и по среднему чеку на уровне значимости более 95%.

Различия по конверсии. Related-9 — новый алгоритм “стильных” сопутствующих товаров, Related — стандартный алгоритм сопутствующих товаров.
Различия по среднему чеку. Related-9 новый алгоритм “стильных” сопутствующих товаров. Как правило используем два теста перекрестно для фиксирования отличия: Mann-Whitney Test и Bootstrap. Оба фиксируют различия на уровне более 97%.
Далее в двух других тестах мы зафиксировали отсутствие отличий по целевым метрикам: конверсия и средний чек. При этом в одном из тестов, где не было различий, новый алгоритм, несмотря на свою “красоту” значимо просел по CTR. Мы, как правило, не ориентируемся на CTR при принятии решений, но обращаем внимание на значимые просадки. Последний АБ-тест мы не стали включать, так как где-то в середине его пришлось сначала перезапускать из-за внесения правок клиентом, а потом начались проблемы с расхождением параллельного АА-теста. Это скомпрометировало результаты этого теста, поэтому мы решили исключить его из рассмотрения.
Различия по CTR. При анализе используем байесовские методы. Распределение значения CTR для Related-9, нового алгоритм “стильных” сопутствующих товаров, (слева) и для Related — стандартной версии (справа). CTR нового алгоритма явно меньше (распределение находится левее) — значимость различия более 95%.
Как правило, не имея положительных результатов, но имея отрицательные, мы оставляем работу над исследованием, дожидаясь новых вводных. В остальных случаях мы пытаемся разобраться, что пошло не так и почему мы не получили результата, там где его ожидали. Здесь мы изначально имели априорную уверенность, что информация из картинок не победит поведение, так что решили пока остановиться на достигнутом результате. Более того экономическая обоснованность поддержки довольно дорогого процесса обработки картинок и механизма построения рекомендаций на их основе оказалась под вопросом.
Выводы
Не всегда то, что красиво выглядит в теории, работает на практике. В данном случае, мы считаем, что столкнулись именно с такой ситуацией. Красивая история с использованием глубинного обучения и извлечения информации из картинок поставила нас в тупик именно из-за практических нюансов. С одной стороны, если мы смешиваем два подхода — поведение и изображения — мы практически не можем доказать, что это эффективно. Тут оговоримся, что не можем доказать в нашей конкретной ситуации и на наших объемах. С другой стороны, если мы используем только изображения, то технология оказывается недостаточно зрелой, чтобы побеждать текущие механики Retail Rocket.
Как правило, при прочих равных, мы запускаем то, что проще и требует меньших усилий реализации, пусть даже это «не модно». Механизм извлечения информации из картинок на продуктовом уровне достаточно сложный процесс, поэтому мы решили на время оставить исследования в этом направлении пока не будет новых вводных. Например, изменится сильно доля холодного старта или появится другая важная информация.
Александр Анохин, аналитик Retail Rocket
Комментарии (6)

RetailRocket Автор
25.02.2019 15:26Да, все верно. Все исследования не могут заканчиваться удачно и рассказать о неудаче в лубом случае кажется правильным. Во первых, может мы ошиблись совсем на «чуть-чуть» и кто-то подскажет, где ошибка и как сделать лучше. Во вторых, это создает рабочую дискуссию по поводу применимости методов анализа изображений в сегменте fashion. Так, если кто-то шел другим — более удачным — путем может поделиться опытом.
stepansokolov
25.02.2019 17:51алгоритм подойдет в случае неформализованных входных данных:
не к конкретному productId порекомендуй другие productId,
а к фотографии меня в этих штанах порекомендуй конкретные productId из этого магазина для завершения лука.
актуально для fashion с развитым мобильным приложением и большим ассортиментомRetailRocket Автор
25.02.2019 18:32Да, параллельно прорабатывали такой сценарий использования. Тут действительно нет пользовательской истории, чтобы что-то сделать. Один из коллег в качестве демо как раз делал бота, который выполнял эту функцию в приложении. Присылаешь свое фото, а он тебе рекомендации из магазина. Но не нашли подходящий спрос на эту фичу.
vassabi
о, круто!
Я правильно понимаю, что (1)вы попробовали новый подход, (2) словили и порешали гору неочевидных «на берегу» граблей, (3) новый подход не оказался таким замечательным, как хотелось, поэтому (4) вы остались с новым опытом, но на старом берегу? И главное (5) — вы не побоялись обо всем этом написать?
rzykov
В точку!
chizh_andrey
еще это краткий ответ на вопрос: «а почему вы по картинкам рекомендации не делаете?» )