
В мире PHP хорошо известны инструменты миграций структуры БД — Doctrine, Phinx от CakePHP, от Laravel, от Yii — это то первое, что пришло в голову. Наверняка, есть еще с десяток. И большинство из них работают с миграциями — командами для внесения инкрементных изменений в схему базы данных.
Я не буду описывать зачем это, на хабре много постов на эту тему. Например:
- Версионная миграция структуры базы данных: основные подходы — хоть и старая статья, но принципы не стареют
- Эволюционный дизайн баз данных — перевод статьи Мартина Фаулера, хорошее описание [инкрементного подхода]
- Опыт 1440 миграций баз данных — практичный пост по работе с PostgesSQL
Далее, развитие моего опыта работы в команде с постоянным изменением структуры БД в разных ветках.
raw SQL vs PHP api
Мы пишем миграции на чистом SQL. Многие инструменты предоставляют PHP-api для написания инструкций транслируемых в SQL-код. Теперь я вообще не понимаю зачем это? Такой инструмент всегда будет ограничен своими возможностями. Специфические инструкции для конкретного движка они не позволяют написать, приходится все равно использовать чистый SQL. Я уже не говорю про написание процедур и вьюх.
Кто-то жаловался, что не хочет учить синтаксис ALTER-команд… Ну, не знаю, открыл справочник и написал, примеров гора, в большом проекте особенно.
Миграции данных (INSERT, UPDATE), тоже всегда пишутся на SQL. Потому что никогда нельзя положиться на текущую версию ОРМ и Моделей. В одной ревизии они есть, в другой уже нет.
Например:
Rollback
Country::delete()->where(....)->execute();
Хотите откатить состояние базы. А этого PHP-класса уже нет в репо. Нужно искать последний коммит, где он был и откатываться от-туда. Бррр…
Поэтому SQL — все просто и надежно:
--TRANSACTION
--UP
ALTER TABLE authors ADD COLUMN code INT;
ALTER TABLE posts ADD COLUMN slug TEXT;
UPDATE authors SET ...
--DOWN
ALTER TABLE authors DROP COLUMN code;
ALTER TABLE posts DROP COLUMN slug;
Транзакции в DDL
С переходом на PostgreSQL забыл о сломанных миграциях как страшный сон — миграция упала в середине, что-то накатилось, что-то нет, сиди и правь ручками… Это вынуждало писать атомарные однострочные команды и запускать их по одной. С транзакциями все просто: если что-то сломалось — все откатывается назад (ну почти все ))). Просто чинишь и запускаешь заново. Автоматическая сборка работает на ура, если что и упало, то быстро исправляется и поднимается.
Вьюхи (представления) и функции
Здесь проблема в том, что они не могут быть обновлены инкрементно, как ALTER в таблицах. Нужно DROP и CREATE. Т.е. по дифу (тексту миграции) совсем не понятно, что же поменялось в итоге. Особенно когда логика накручена, это довольно неудобно. Например:
--UP
DROP VIEW ...
CREATE VIEW mvstock AS
SELECT (now() - '7 days'::interval) AS refreshed_at,
o.pid,
COALESCE(sum(o.debit), 0)::integer AS debit,
COALESCE(sum(o.credit) FILTER (WHERE d.type <> 104), 0)::integer AS credit,
COALESCE(sum(o.debit), 0) - COALESCE(sum(o.credit), 0)::integer AS total
FROM operations o
JOIN docs d ON d.id = o.doc_id AND d.deleted_at IS NULL
WHERE d.closed_at < (now() - '7 days'::interval) AND d.type <> 500
GROUP BY o.pid
WITH DATA;
--DOWN
DROP VIEW ...
CREATE VIEW mvstock AS
SELECT (now() - '10 days'::interval) AS refreshed_at,
o.pid,
COALESCE(sum(o.debit), 0)::integer AS debit,
COALESCE(sum(o.credit) FILTER (WHERE d.type <> 104), 0)::integer AS credit,
COALESCE(sum(o.debit), 0) - COALESCE(sum(o.credit), 0)::integer AS total
FROM operations o
JOIN docs d ON d.id = o.doc_id AND d.deleted_at IS NULL
WHERE d.closed_at < (now() - '10 days'::interval) AND d.type <> 500
GROUP BY o.pid
WITH DATA;
Вот что здесь изменилось?
Остановились на том, что рядом с миграциями лежит папочка, где хранится текущий код вьюх и процедур, который обновляется и копипастится в rollback миграции.
И теперь дифф становится похож на:

Еще в Авито сделали интересное решение для версионирования кода хранимых процедур
В целом, этот кейс поднимает хорошую проблему — как посмотреть историю изменений конкретного объекта структуры БД. По каждой таблице хочется посмотреть историю изменений в связи с решением конкретных задач.

Нашел на Хабре интересный подход для автоматизации фиксации изменений структуры базы данных.
Работа с ветками
Моя вечная боль — как переключиться между двумя А- и В-ветками, в каждой из которых есть правки по структуре БД.

Надо откатить миграции в А-ветке (надо еще помнить какие и сколько), потом переключиться в В-ветку и накатить новые миграции. Ладно еще, если наши правки совместимы и я могу просто переключиться на вторую ветку и накатить дополнительные миграции из B.
А если нет? А если у меня не одна такая ветка? А потом откатить все эти review-состояние? Всегда это ненавидел…
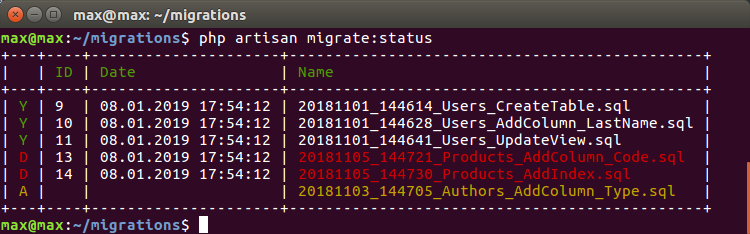
Теперь при переключении на чужую ветку я могу автоматически удалить чужие миграции и накатить текущие:
где:
D — А-миграции, которые были запущены в А-ветке, но их нет в текущей ветке, и их рекомендуется удалить
А — B-миграции, которые появились в новой ветке и их надо накатить
Это становится безумно удобно при тестировании и автосборке на одной базе. Когда нет смысла или возможности для каждой ветки создавать базу с нуля. Переключаешься на ветку и автоматом синхронизируется состояние БД.
Нумерация и очередность выполнения
Все известные мне инструменты нумеруют миграции таймстампом — хорошее решение. Если я пишу несколько миграций, то сохраняется необходимая очередность. У другого разработчика в другой ветке может стоять любая дата, даже моя — но это уже не важно в каком порядке мы с ним накатимся, наши изменения не зависят друг от друга. Даже, если мы работаем с одной и той же таблицей (добавляем по колонке), то все необходимые изменения пройдут в любом порядке. Главное, что соблюдается очередность моих зависимых правок.

Я не рассматриваю случаи, когда нам нужно править одно и тоже — эти моменты всегда согласуются. Ну, или будет фейл на этапе сборки и тестирования.
Вот интересный пример.
Мы делаем разные правки в одной вьюхе или процедуре, т.е. в тех структурах, которые обновляются через удаление. Т.е. я, например, добавил колонку col_A во вьюху, а мой коллега col_В. Соответственно, если его код выкатывается после моего, то в его версии не будет моей колонки:
CREATE VIEW vusers AS
SELECT
login,
name,
-- ....
| ветка-А | ветка-B |
|---|---|
|
|
Еще один интересный случай — исправления в миграциях.
Суть в том, что миграция, которая была применена, уже не будет применяться повторно, сколько бы изменений вы не вносили в нее (надо откатить сначала, а потом снова применить). Т.е. вы отдали Миграцию на тестирование, все норм, а потом спохватились и сделали небольшую правку. Но тестовый или другой сервер, где вы ее применили, об этом уже не узнает.
В этих случаях мы переименовываем файл миграции, прибавляя новый номер версии, чтобы мигратор начал интерпретировать это как 2 команды — откатить 1 и накатить 2,
например:

Rollback
Всегда писать ROLLBACK, даже если он не может вернуть базу к исходному состоянию. Например DROP TABLE, какой там может быть ROLLBACK?
В таких случаях мы пишем пустой CREATE TABLE. Суть в том, чтобы dev-система всегда могла легко переключиться между ветками. Для PROD управление необратимыми правками решается уже на другом уровне. Я могу сделать копию таблицы, или переименовать ее вместо удаления. Но сам принцип написания миграции — ролбек ОБЯЗАН вернуть СТРУКТУРУ базы в исходный уровень, а данные уже по мере возможности.
В боевом окружении ролбек я использовал всего 1-2 раза в своей жизни. А в dev постоянно. Поэтому всегда проверяю что ролбек все возвращает в нужное состояние.
Часто разработчики могут делать ошибки в ролбеке. Т.к. они в первую очередь концентрируются на новых правках, их тестируют и с ними работают. С ролбеком работают уже другие люди и процессы. Поэтому я всегда тестирую миграции UP — ROLLBACK — UP
Интересный момент появляется на постоянной тестовой базе (база не удаляется). Написали миграцию, ролбек отлично работает, отдали на тестирование, тестировщик нагенерил данных в новом формате, пытается откатить, а новые данные не дают. Классический пример
ALTER TABLE abc ALTER COLUMN code SET NULLПрекрасно! В базе после тестирования полно NULL значений. Делаем ROLLBACK:
ALTER TABLE abc ALTER COLUMN code SET NOT NULLи обратно уже никак :-(
Надо добавлять команду:
DELETE FROM abc WHERE code IS NULLСложность в том, что это нужно держать в голове и никак это не автоматизировать, если мы не говорим о пересоздании базы с нуля каждый раз.
Немного про удаление данных
Обычно мы стараемся НЕ удалять заполненные таблицы и колонки сразу. Лучше переименовать или сделать копию, а удалить уже по-позже, когда все уляжется и данные потеряют актуальность:
ALTER TABLE user_logs RENAME TO user_logs_20190223;
-- или
CREATE TABLE user_logs_20190223 AS TABLE user_logs;
Мигратор
Мы сейчас работаем с Laravel — у него есть стандартный, привычный движок управления миграциями. Хочешь, пиши даже на чистом SQL, правда все равно в PHP-классе. Но мои неоднократные попытки заставить его работать так, как нам надо вылились в отдельный репо:
- Решение состоит из 2 частей — lib и реализация под конкретную консоль (Laravel, Symfony). Можно интегрировать в любою консоль, или хоть в web-морду.
- Нет своего конфига и коннекта — зачем, когда он уже есть в вашем проекте. Цепляете свой коннект к интерфейсу и вперед.
- SQL ролбека хранится в базе. Это необходимо для переключения между ветками
- Проверено на Postgesql, Mysql (без транзакций). Подходит в принципе для любых баз и структур, потому что используется raw-формат.
Ссылки
— migrations-lib
— реализация под Laravel/Artisan
— реализация под Symfony/Console
Комментарии (21)

flancer
28.02.2019 10:20И большинство из них работают с миграциями — командами для внесения инкрементных изменений в схему базы данных.
Я не очень глубоко влазил в Doctrine по этому вопросу, но у меня сложилось впечатление, что Doctrine DBAL считывает текущую схему данных из базы, позволяет разработчику через PHP-код модифицировать её путем удаления/добавления таблиц/столбцов, затем сама генерирует набор SQL-запросов, переводящих структуру данных из начального состояния в желаемое.
Разумеется, что делает она это не настолько хорошо, как это может сделать сам разработчик на чистом SQL, заточенном под конкретную СУБД, но меня во всём этом привлекает идея создания моделей схемы данных — начальной и конечной. Doctrine создает модель в памяти из PHP-объектов, но можно модель описывать в виде XML/JSON/YAML/… В этом случае вся схема данных, допустим в XML, ложится под стандартный контроль версий (как и SQL-файлы).
Для двух различных моделей схем данных можно прогонять миграцию прямую и обратную (rollback). Два развития одной базовой модели от двух (и более) разных девелоперов можно прогнать через процедуру слияния (текст структурированный), либо вообще собирать конечную модель из отдельных фрагментов, где каждый девелопер сам развивает свой участок общей схемы данных.
Для таблиц такой структурированный подход уже работает (Magento 2.3). Для views/triggers/procedures/… более проблематично (здесь, скорее всего, пойдут вставки чистого SQL, что нивелирует преимущества структурирования информации).
Тем не менее, если не увлекаться DB-программированием (триггеры и SQL-процедуры), то можно достаточно успешно структурировать SELECT, который лежит в основе создания views. А tables & views — основа схемы данных. Т.е., если переводить XML/JSON/YAML-модель в Doctrine-модель, то далее Doctrine DBAL уже сама сможет выполнять миграцию.
Это не универсальное решение, оно однозначно не подойдёт для крупных проектов, где БД является центром Вселенной и доводиться вручную "до блеска". Но для проектов, типа Magento, где конечное приложение собирается из отдельных модулей (как следствие, конечная схема данных собирается из отдельных фрагментов) — может оказаться вполне удачным.

SamDark
28.02.2019 10:53Мы пишем миграции на чистом SQL. Многие инструменты предоставляют PHP-api для написания инструкций транслируемых в SQL-код. Теперь я вообще не понимаю зачем это?
Есть такие штуки, как продукты, которые должны работать с любыми SQL-базами. CMS, например. Это не про модели и константы, которые да, меняются. Это про DSL в самих миграциях.

eefadeev
28.02.2019 11:00как посмотреть историю изменений конкретного объекта структуры БД. По каждой таблице хочется посмотреть историю изменений в связи с решением конкретных задач.
Для этого нужно вести не только миграции, но и полноценное версионированное описание схемы. Больше того — это описание первично по отношению к миграциям (которые всего лишь описывают один из бесконечного числа возможных путей перевода БД из состояния А в состояние Б).Partizan Автор
28.02.2019 11:13А как вы это делаете?
eefadeev
28.02.2019 12:38+1Пока, в основном, в мечтах :)
Но в комментариях к одной из приведённых статей звучали термины state-driven deployment и change-driven deployment.
Общая идея, в целом, достаточно проста: у вас должны быть скрипты, описывающие состояние схемы. Из них можно в любой момент собрать любую версию БД «с нуля» (и по ним же посмотреть кто, что и когда изменил). А миграции — это отдельная часть проекта (вторичная по отношению к схеме), причём имея в системе контроля версий состояния вы всегда можете убедиться в том, что ваша миграция делает именно то, что вы хотели (собрав с нуля схему версии N, а рядом версии N-1 + накат на неё миграции и сравнив их между собой).
Это если вкратце.
ashtokalo
28.02.2019 17:46У нас для этого есть две консольные команды, условно export и import. Соотвественно, первая — умеет делать дамп схемы, хранимых процедур и данных из заранее указанных таблиц — словари, миграции и т.п. Вторая команда умеет создавать базу из такого дампа и загружать данные в нужные таблицы. Собранные дампы добавлены в систему контроля версий. При создании новой миграции, после её применения, мы запускаем первую команду. Это обновляет дампы и даёт возможность отслеживать изменения с помощью системы контроля версий, без анализа самих миграций. Эти команды так же используются для разворачивания проекта и автоматического тестирования. Что позволяет избегать запуска сотен миграций. Всё это замечательно работает на базе Yii уже много лет.
Partizan Автор
28.02.2019 17:48Интересно, сможете показать исходники export?
ashtokalo
28.02.2019 18:53Тут нечего показывать. В проекте только MySQL. Родной дамп оказался быстрее и проще. Для схемы используется банальный mysqldump:
Аналогично для выборки данных из нужных таблиц. Данные из таблиц храним в отдельных файлах, так с ними удобнее работать.mysqldump --add-drop-table --no-data --routines $DBNAME > $SCHEMA
Импорт чуть более сложен, но только из-за добавленой интерактивности. Схема разбивается на части и выполняется по частям. Это позволяет видеть процесс по каждой таблице и сразу загружать её данные. Данные так же грузим частями, чтобы был виден прогресс и чтобы не спотыкаться на размере буфера. У нас в схеме больше сотни таблиц, некоторые словари имеют десятки тысяч записей и занимают несколько мегабайт. Без такой разбивки процесс импорта весьма скучен :)
Пример кода для импорта, чтобы было чуть более понятно// search for all tables in the schema if (preg_match_all('%\s*DROP\s+TABLE\s+(?:IF\s+EXISTS\s+)?(?# )\`([a-z_A-Z]+)\`.+(?=DROP\s+TABLE|\/\*\!\d+\s+DROP\s+FUNCTION(?# )|\/\*\!\d+\s+DROP\s+PROCEDURE)%sU', $sSchema, $aMatches)) { $sSql = ''; foreach ($aMatches[1] as $i => $sTable) { $this->write(sprintf(' > create table %s ...', $sTable)); $sSql = $aMatches[0][$i]; // apply global settings from sql dump header if ($i === 0) { $sSql = substr($sSchema, 0, strpos($sSchema, $sSql)) . $sSql; } $iTime = microtime(true); // clear auto increment value $sSql = preg_replace('/AUTO_INCREMENT=\d+/', '', $sSql); Yii::app()->db->createCommand($sSql)->execute(); $this->write(sprintf(' done (time: %.3fs)' . PHP_EOL, microtime(true) - $iTime)); $this->loadTableData($sTable); } // leave only routines in schema $sSchema = substr($sSchema, strpos($sSchema, $sSql) + strlen($sSql)); } // and then routines if (preg_match_all('%(?:/\*!\d+\s+)?DROP\s+(FUNCTION|PROCEDURE)\s+(?# )(?:IF\s+EXISTS\s+)?`([a-z_A-Z]+)`.+\sDELIMITER\s\;\;(.+)\;\;(?# )\s+DELIMITER\s\;\s%Ums', $sSchema, $aMatches)) { foreach ($aMatches[2] as $i => $sName) { $this->write(sprintf(' > create %s %s ...', strtolower($aMatches[1][$i]), $sName)); $sDropSql = preg_replace('/;.+$/Ss', '', $aMatches[0][$i]); $iTime = microtime(true); // drop function or procedure if exists Yii::app()->db->createCommand($sDropSql)->execute(); Yii::app()->db->createCommand($aMatches[3][$i])->execute(); $this->write(sprintf(' done (time: %.3fs)' . PHP_EOL, microtime(true) - $iTime)); } }
Akdmeh
28.02.2019 14:53Когда в MySQL нужно накатить дополнительный индекс или добавить колонку в таблицу с 50 миллионами записей — в своем большинстве эти инструменты никак не подходят.
Впервые об этом я узнал, когда по неопытности локнул таблицу на 4 часа…
После чего приходится использовать percona-toolkit, которая создает временную таблицу с новой структурой, а на старую цепляет триггеры. Это позволяет делать редактирование таблиц без простоев.
Как я понимаю, эта проблема актуальна не для всех баз, но подобная ошибка может быстро отучить от использования миграций на больших таблицах.
Придумали ли какое-то решение для этого сценария?Partizan Автор
28.02.2019 17:51Обычно делаем CREATE INDEX CONCURRENTLY — PG создает индекс без блокировки таблицы в реалтайме. Ну и медленнее он работает конечно.
Partizan Автор
28.02.2019 17:53А про добавление колонок на больших таблицах — здесь хорошо описано:
Опыт 1440 миграций баз данных — habr.com/company/wrike/blog/414441
Колонка добавляется как nullable ну и дальше аккуратно заполняется.

evgwed
28.02.2019 17:23как посмотреть историю изменений конкретного объекта структуры БД. По каждой таблице хочется посмотреть историю изменений в связи с решением конкретных задач.
Вот тут и тут рассказывалось об очень удобной тулзе RedGate SQL Compare. Использовали на проекте одном, вполне годная для версионирования изменений в базе данных, но конфликты она решать не умеет (например при добавлении not null поля в существующую таблицу с данными).
Также в Phalcon Framework видел хорошее решение подобной проблемы, но там тоже не нативный SQL, а DSL описание бд (тут).
peresada
ORM в миграциях нужна не столько для «удобства», сколько для потенциальной возможности смены СУБД, при чистом SQL придется его переписывать, с ORM — нет. Конечно при специфичных моментах в диалектах это не поможет, но переписывать в любом случае придется меньше. + превратить orm код в чистый sql легко, в отличие от обратного
Почему только Postgress? К чему этот пункт? Разве есть современные субд, которые не поддерживают транзакции?
flancer
MyISAM
peresada
Под современным я имел ввиду все-таки те, которым меньше 10 лет. А с Mysql 5.5 этот движок уже не являлся основным
Partizan Автор
В миграциях этого точно не нужно — они одноразовые.
НЕ все базы поддерживают транзакции на уровне запросов по изменению структуры БД.
Долго работал и мучался с MySQL, у которой этого не было. Как там сейчас уже не в теме.
ghrb
> В миграциях этого точно не нужно — они одноразовые.
А как же кейс когда приходит новый разработчик и разворачивает проект имея пустую базу? Ему дампом структуру базы выдают?
Partizan Автор
Когда проекту больше 5 лет и миграций за тысячу — как-то по другому надо
happyproff
Хранить начальную структуру в какому-нибудь
initial.sql, рядом миграции. Раз в пару-тройку месяцев снимать актуальную структуру вinitial.sql, при этом удаляя миграции.Immortal_pony
Да. И?