
— Jack Ganssle, «The Art of Designing Embedded Systems»
Привет, Хабр!
Как ни странно, но в абсолютном большинстве виденных мной «учебников для начинающих» по STM32 в частности и микроконтроллерам вообще нет, как правило, вообще ничего про такую вещь, как распределение памяти, размещение стека и, главное, недопущение переполнения памяти — в результате которого одна область перетирает другую и всё рушится, обычно с феерическими эффектами.
Отчасти это объясняется простотой учебных проектов, выполняемых при этом на отладочных платах с относительно жирными микроконтроллерами, на которых влететь в нехватку памяти, мигая светодиодом, довольно сложно — однако в последнее время даже у начинающих любителей мне всё чаще встречаются упоминания, например, контроллеров типа STM32F030F4P6, простых в монтаже, стоящих копейки, но и памяти имеющих единицы килобайт.
Такие контроллеры позволяют делать вполне себе серьёзные штуки (ну вот у нас, например, такая вполне себе годная измериловка сделана на STM32F042K6T6 с 6 КБ ОЗУ, от которых свободными остаются чуть больше 100 байт), но при обращении с памятью при работе с ними нужна определённая аккуратность.
Об этой аккуратности и хочу поговорить. Статья будет короткая, профессионалы ничего нового не узнают — но начинающим эти знания очень рекомендуется иметь.
В типовом проекте на микроконтроллере на ядре Cortex-M оперативная память имеет условное разделение на четыре секции:
- data — данные, инициализируемые конкретным значением
- bss — данные, инициализируемые нулём
- heap — куча (динамическая область, из которой память выделяется явным образом с помощью malloc)
- stack — стек (динамическая область, из которой память выделяется компилятором неявным образом)
Изредка может также встречаться область noinit (неинициализируемые переменные — они удобны тем, что сохраняют значение между перезагрузками), ещё реже — какие-то иные области, выделенные под конкретные задачи.
Расположены они в физической памяти довольно специфическим образом — дело в том, что стек в микроконтроллерах на ядрах ARM растёт сверху вниз. Поэтому он располагается отдельно от остальных блоков памяти, в конце ОЗУ:
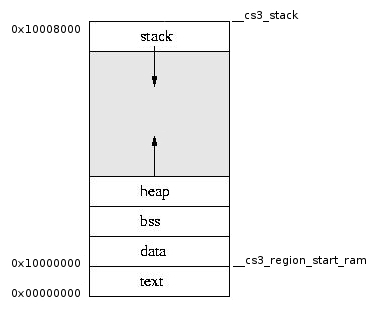
По умолчанию его адрес обычно равен самому последнему адресу ОЗУ, и оттуда он по мере роста опускается вниз — и из этого растёт одна крайне неприятная особенность стека: он может дотянуться до bss и перезаписать его верхушку, причём никаким явным образом вы про это не узнаете.
Статические и динамические области памяти
Вся память делится на две категории — статически выделяемая, т.е. память, общий объём который очевиден из текста программы и не зависит от порядка её выполнения, и динамически выделяемая, потребный объём которой зависит от хода выполнения программы.
К последней относятся куча (из которой мы берём куски с помощью malloc и возвращаем с помощью free) и стек, который растёт и уменьшается «сам по себе».
Вообще говоря, использовать malloc на микроконтроллерах настоятельно не рекомендуется, если вы не знаете абсолютно точно, что вы делаете. Основной привносимой им проблемой является фрагментация памяти — если вы выделите 10 кусочков по 10 байт, а потом освободите каждый второй, то вы не получите свободных 50 байт. Вы получите 5 свободных кусков по 10 байт.
Кроме того, на этапе компиляции программы компилятор не сможет автоматически определить, сколько памяти потребует ваш malloc (тем более — с учётом фрагментации, которая зависит не просто от размера запрошенных кусков, а от последовательности их выделения и освобождения), и потому не сможет вас предупредить, если памяти в итоге не хватит.
Методы обхода этой проблемы есть — специальные реализации malloc, которые работают в рамках статически выделенной области, а не всего ОЗУ, аккуратное употребление malloc с учётом возможной фрагментации на уровне логики программы и т.п. — но в общем и целом malloc лучше не трогать.
Все области памяти с границами и адресами прописаны в файле с расширением LD, на который ориентируется линковщик при сборке проекта.
Статически выделяемая память
Итак, из статически выделяемой памяти у нас есть две области — bss и data, отличающиеся только формально. При инициализации системы блок data копируется из флэша, где для него сохранены нужные значения инициализации, блок bss просто заполняется нулями (по крайней мере, заполнить его нулями считается хорошим тоном).
Обе вещи — копирование из флэша и заполнение нулями — делаются в коде программы в явном виде, но не в вашем main(), а в отдельном файле, который выполняется первым, пишется один раз и просто таскается из проекта в проект.
Впрочем, интересует нас сейчас не это — а то, как мы поймём, влезают ли вообще наши данные в ОЗУ нашего контроллера.
Это узнаётся очень просто — утилитой arm-none-eabi-size с единственным параметром — скомпилированным ELF-файлом нашей программы (часто её вызов вставляют в конец Makefile, потому что удобно):

Здесь text — это объём данных программы, лежащих во флэше, а bss и data — наши статически выделенные области в ОЗУ. Последние две колонки нас не волнуют — это сумма первых трёх, она не имеет практического смысла.
Итого, статически в ОЗУ нам нужны bss + data байт, в данном случае — 5324 байта. У контроллера есть 6144 байта ОЗУ, malloc мы не используем, остаётся 820 байт.
Которых нам должно хватить на стек.
Но хватит ли? Потому что если нет — наш стек дорастёт до наших же данных, и далее сначала он затрёт данные, потом данные затрут его, а потом всё рухнет. Причём между первым и вторым пунктами программа может продолжать работать, не осознавая, что в обрабатываемых ей данных — мусор. В худшем случае это будут данные, которые вы записали, когда со стеком было всё в порядке, а теперь только читаете — например, калибровочные параметры какого-нибудь датчика — и тогда у вас вообще нет очевидного способа понять, что с ними всё плохо, при этом программа продолжит выполняться, как ни в чём не бывало, выдавая вам на выходе мусор.
Динамически выделяемая память
И вот тут начинается самое интересное — если сократить сказку до одной фразы, то заранее определить размер стека практически невозможно.
Чисто теоретически, вы можете попросить компилятор выдать вам размер стека, используемый каждой отдельной функцией, потом попросить его же выдать дерево выполнения вашей программы, и для каждой ветви в нём просчитать сумму стеков всех присутствующих в этом дереве функций. Одно это для любой более-менее сложной программы займёт у вас крайне немалое время.
Потом вы вспомните, что в любой момент может случиться прерывание, обработчику которого тоже нужна память.
Потом — что могут случиться два или три вложенных прерывания, обработчикам которых…
В общем, вы поняли. Попробовать посчитать стек для конкретной программы — занятие увлекательное и в целом полезное, но часто вы это делать не будете.
Поэтому на практике используется один приём, позволяющий хоть как-то понять, всё ли у нас в жизни складывается хорошо — так называемая «окраска памяти» (memory painting).
Что удобно в этом методе — так это то, что он никак не зависит от используемых вами средств отладки, и при наличии у системы хоть каких-то средств вывода информации позволяет обойтись без средств отладки вообще.
Суть его в том, что мы заливаем весь массив от конца bss до начала стека где-то на самой ранней стадии выполнения программы, когда стек ещё точно маленький, одним и тем же значением.
Далее, проверяя, на каком адресе это значение уже пропало, мы понимаем, куда опускался стек. Так как однажды стёртая окраска сама не восстановится, то проверку можно делать эпизодически — она покажет максимальный достигавшийся размер стека.
Определим цвет краски — конкретное значение неважно, ниже я просто настучал двумя пальцами левой руки. Главное — не выбирать 0 и FF:
#define STACK_CANARY_WORD (0xCACACACAUL)В самом-самом начале программы, вот прямо в стартап-файле, зальём всю свободную память этой краской:
volatile unsigned *top, *start;
__asm__ volatile ("mov %[top], sp" : [top] "=r" (top) : : );
start = &_ebss;
while (start < top) {
*(start++) = STACK_CANARY_WORD;
}Что мы тут сделали? Ассемблерная вставка присвоила переменной top значение, равное текущему адресу стека — чтобы его случайно не затереть; в переменной start — адрес конца блока bss (переменную, в которой он хранится, я подсмотрел в скрипте линковщика *.ld — в данном случае он от библиотеки libopencm3). Далее мы просто заливаем всё от конца bss до начала стека одним и тем же значением.
После этого мы в любой момент можем сделать так:
unsigned check_stack_size(void) {
/* top of data section */
unsigned *addr = &_ebss;
/* look for the canary word till the end of RAM */
while ((addr < &_stack) && (*addr == STACK_CANARY_WORD)) {
addr++;
}
return ((unsigned)&_stack - (unsigned)addr);
}Здесь переменная _ebss нам уже знакома, а переменная _stack — из того же скрипта линковщика, в нём она означает верхний адрес стека, то есть, в данном случае, просто конец ОЗУ.
Вернёт эта функция максимальный зафиксированный размера стека в байтах.
Дальнейшая логика достаточно проста — где-нибудь в теле программы периодически вызываем check_stack_size() и выводим его выхлоп в консоль, на экран или куда нам удобно его вывести, и запускаем устройство в боевую эксплуатацию на период, который считаем достаточно продолжительным.
Периодически смотрим на размер стека.
В данном случае различными хаотическими действиями с устройством его удаётся довести до 712 байт — то есть из имевшихся изначально 6 Кбайт ОЗУ у нас остаётся запас ещё в целых 108 байт.
Word of caution
Экспериментальный метод определения размера стека — простой, эффективный, но не 100-% надёжный. Всегда может сложиться ситуация, когда очень редкое стечение обстоятельств, наблюдаемое, например, раз в год, приведёт к незапланированному повышению этого размера. Впрочем, в общем случае и при грамотно написанной прошивке можно считать, что вряд ли у вас случится что-то, перехлёстывающие зафиксированный размер более чем на 10-20 %, так что мы с нашими 108 байтами запаса с высокой степенью уверенности находимся в безопасности.
В большинстве же случаев такое квазипрофилирование, легко и просто выполняемое практически на любой системе и независимо от используемых средств разработки, позволяет с высокой достоверностью определить эффективность использования памяти и поймать проблему со стеком на ранних стадиях, особенно при работе на младших контроллерах с ОЗУ размером в единицы килобайт.
P.S. В многозадачных системах на RTOS стеков в большинстве случаев много — помимо главного стека MSP, растущего от верхнего края ОЗУ вниз, есть отдельные стеки процессов PSP. Размер их явно задаётся программистом, что не уберегает процесс от выхода за их границы — поэтому методы контроля в них используются такие же.
Комментарии (102)

IgorPie
09.03.2019 01:21Сократить число прерываний, избавиться от готовых библиотек работы со стрингами и поведение стека становится более предсказуемым.

ittakir
09.03.2019 09:01Еще можно запустить программу под отладчиком и поставить breakpoint в какой-нибудь самой-самой вложенной функции. Там посмотреть либо сам стек целиком, либо хотя бы Stack Pointer.
Чтобы узнать, сколько свободной памяти у нас есть, нужно включить создание Linker Map File и посмотреть сколько занимают глобальные переменные. Неиспользованный остаток можно отдать на стек.
Если ваш микроконтроллер совсем имеет совсем крошечный объем памяти, например какой-нибудь AVR Tiny, не используйте стандартные функции работы со строками sprintf, printf. Они очень неслабо жрут память, т.к. универсальные по своей природе. Напишите свои функции, узко заточенные именно под ваши нужды, например, только под вывод unsigned char.
Costic
09.03.2019 15:28Абсолютно согласен с вами. Отладчик и MAP-файл позволяют решить эти проблемы. Ну, и конечно же минимизировать вложенные функции, кол-во аргументов сделать поменьше. А динамическая память и рекурсия вообще противопоказаны. Компилятор даже кое-что показывает: linking…
Program Size: data=119.5 xdata=2323 const=303 code=15011
(у меня не ARM, но суть та же).

amartology
09.03.2019 11:37+3Где-то в конце статьи должна быть приписка, что если вы делаете не домашний термометр, а автопилот или систему управления АЭС, то надо пользоваться не этим методом, а
гальванической развязкойчем-то более продвинутым и, желательно, стандартизованным.
olartamonov Автор
09.03.2019 11:59Например, чем?..
amartology
09.03.2019 15:31+2Не знаю( Вы же специалист, а не я. Я серьезно сейчас, если что.
Но мне кажется, что для ответственных применений должно существовать что-то более надежное, хотя, конечно, вы правы в том, что этот метод покрывает подавляющее большинство возможных проблем.olartamonov Автор
09.03.2019 18:58+1Так и я серьёзно. И Ганссл серьзно.
Инструментов, которые достоверно при статическом анализе кода определят размер нужного стека, вообще нет.
Инструменты, которые позволят в рантайме поймать переполнение надёжнее, чем окраска памяти — есть, но не во всех контроллерах.
eup
11.03.2019 14:33На ум сразу приходит статический анализ кода для оценки потребления программой стека, но он если и возможен, то только в рамках чистых функций без side-effect-ов (т.е. не взаимодействующих с внешним миром), иначе проблема сводится к решению (нерешаемой) проблемы останова.
olartamonov Автор
11.03.2019 14:40+1Даже безотносительно внешнего мира — два прерывания от разных таймеров с разным приоритетом для анализатора будут непреодолимой проблемой, потому как потребуют от него знания внутренней архитектуры контроллера, анализа времени выполнения каждого из прерываний и т.п.
Оценка здесь возможна только сверху — из обработчиков с одним приоритетом выбираем самый жирный, далее складываем полученное для разных приоритетов и добавляем к каждой из веток кода.
Ну и молимся, чтобы приоритет прерываний в рантайме не менялся.
P.S. И ещё анализаторы при построении структуры программы могут обламываться на вызове функций через указатели.
vZakhar
09.03.2019 18:56+1Например стандартизованными методиками IEC61508, сертифицированными тестами, проверяющими состояние буферной области стека, грамотно определенными безопасным состоянием системы и границами применимости.

Jef239
09.03.2019 22:23Как вариант — четыре процессора, каждая пара сравнивает результаты после каждого такта (аппаратно), при сбое — управление переходит на вторую пару.
Второй вариант — написание двух прошивок разными командами разработчиков, при отказе одной прошивки работает вторая.
Третий вариант — троирование с мажоритарной логикой.
Четвертый вариант — вторая прошивка с сильно упрощенным алгоритмом.
Надеюсь сами вспомните, где какой вариант применяется?olartamonov Автор
09.03.2019 23:05+1Я серьёзно надеюсь, что вы не пишете софт для АЭС и автопилотов.
двух прошивок разными командами разработчиков, при отказе одной прошивки работает вторая
И как именно вы определите, какая из двух прошивок ошиблась?
Третий вариант — троирование с мажоритарной логикой
Не хочу вас расстраивать, но компьютер — вполне себе детерминированная система. Три экземпляра с одним и тем же кодом внутри и одними и теми же сигналами на входе при наличии в этом коде ошибки свалятся совершенно синхронно.
Четвертый вариант — вторая прошивка с сильно упрощенным алгоритмом
У вас правда в голове нет никаких идей, почему в системах с мажоритарной логикой не используются два дублирующихся экземпляра?..Jef239
10.03.2019 00:45Я серьёзно надеюсь, что вы не пишете софт для АЭС и автопилотов.
Для автопилотов как раз пишем. Но автопилот комбайна — очень простая штука. Мелкое дополнение к сложной сиcтеме RTK-навигации.
И как именно вы определите, какая из двух прошивок ошиблась?
Если не путаю, это на Апполоне было сделано. Америкацы тупые, да?
Три экземпляра с одним и тем же кодом внутри и одними и теми же сигналами на входе при наличии в этом коде ошибки свалятся совершенно синхронно.
А это уже русские, Аргон-16.За четверть века эксплуатации на космических кораблях “Союз”, транспортных кораблях “Прогресс”, орбитальных станциях “Салют”, “Алмаз”, “Мир”, “Меч-К” не было отмечено ни одного отказа комплекса в составе системы управления.Русские тупые, да? Не знали, что вся беда в ошибка и защищались от ТЗЧ и иных аппаратных сбоев.
Не хочу вас расстраивать, но компьютер — вполне себе детерминированная система.
Да ну??? А доказать можете? Ну скажем на год поставить 10 незащищенных от ТЗЧ систем. Сколько из них сбойнут? Почитайте лучше про вероятность сбоя. И на Земле и в космосе. Потому 9ая приемка — 9ой приемкой, а защищаться от сбоев лучше дополнительно.
Четвертый вариант — вторая прошивка с сильно упрощенным алгоритмом
Для полноты картины — это системы управления газом всех современных автомобилей.
почему в системах с мажоритарной логикой не используются два дублирующихся экземпляра?..
Потому что используются. Например двухголовый simatic S7–400H это отказоустойчивая система, а двухголовый simatic S7-400F — отказобезопасная. Логика отказобезопасной простая — или два процессора совпали, или все выходы — в безопасное состояние. Если нужно и то и то — четырехголовый S7-400FH.
Впрочем, с вашей точки зрения, небось немцы тоже тупые.

augorelov
10.03.2019 11:20Для полноты картины — это системы управления газом всех современных автомобилей.
На современных автомобилях возможно и так, в чем я крайне не уверен. Но на ряде инжекторных автомобилях — это работает не так. При выходе из строя ЭБУ машина глохнет, даже на ходу. А вот при выходе одного из датчиков двигателя, кроме датчика коленвала, ЭБУ переходит на упрощенный алгоритм управления двигателем. При выходе из строя датчика коленвала ЭБУ останавливает работу двигателя.Jef239
10.03.2019 21:10При выходе из строя ЭБУ машина глохнет, даже на ходу.
А почему глохнет, а не ускоряется до предела? Какое же устройство при любом выходе из строя притягивает выход к нулю? В комментарии на хабре мне писали, что как раз второй процессор.
Cама стратегия работы DBW — это вообще космос! Там два микропроцессора и каждый непрерывно проверяет достоверность работы другого и правильность расчета положения — при этом каждый при определении проблемы, может независимо от другого, снять питание выходных каскадов драйвера привода заслонки.
Собственно зову в тред emmibox. При всех наших с ним спорах он действительно разбирается в чип-тюнинге авто.
Ну а я умываю руки.Максимум, что я могу — это спросить у коллеги из одного их производителей автоэлектроники (включая ЭБУ), так это в их решении или не так. Но я контактирую с разработчиками бортового компа, фактически — замены приборной панели, тонкости ЭБУ он может не знать.augorelov
11.03.2019 08:41Вы представляете, что такое заглохнуть на ходу? Судя по ответу не очень.
Системы с двойным, тройным резервированием, в которых каждый блок работает в горячем резерве, существуют и нашли реальное применение, но и стоимость таких систем соответствующая. В изделиях для народного хозяйства я пока не встречал систем с горячем резервированием.emmibox
11.03.2019 09:53Вы представляете, что такое заглохнуть на ходу?
Если вы поняли, что у вас что то пошло не так — заглохнуть на ходу самый оптимальный вариант! (на самом деле дроссель становится в limp-home позицию и можно куда то ехать с черепашьей скоростью)… И он значительно лучше, чем скажем неконтролируемо разогнаться до максимальной скорости и впечататься в столб.
Резервирования там нет никакого… Там есть 100%-й контроль корректности работы в условиях абсолютного недоверия как ПО так и железу, для одновременно двух микроконтроллеров. С идеей основанной на том, что любой вдруг возникший ранее не известный дефект не может одинаково воспроизвестись в двух фундаментально разных микропроцессорных архитектурах, созданных на разных заводах, по разным технологиям, разными производителями… (хотя в последних версиях 2й микроконтроллер упростили и заменили на asic только контролирующую работу первого).augorelov
11.03.2019 10:26Резервирования там нет никакого…
Про горячее резервирование в автомобильных ЭБУ речи не шло.
Если вы поняли, что у вас что то пошло не так — заглохнуть на ходу самый оптимальный вариант!.. И он значительно лучше, чем скажем неконтролируемо разогнаться до максимальной скорости и впечататься в столб.
С этим не поспоришь.
на самом деле дроссель становится в limp-home позицию и можно куда то ехать с черепашьей скоростью
Все зависит от датчиков двигателя, вышедших из строя.
augorelov
11.03.2019 10:48Приведите пример автомобильно ЭБУ, в котором применяются:
1. два микроконтроллера (для резервирования);
2. два микроконтроллера с разной архитектурой.emmibox
11.03.2019 12:32Про резервирование речь не шла! Что касаемо двух с разной архитектурой то это, например вся линейка линейка ME7.
Основной МК — С167 с внешней памятью или ST10 с флеш.
МК монитора — 68HС05. (в массе) масочный ST10-С167 (в редких исполнениях).
(впрочем если про резервирование — первые АБС это 2 масочных 80с51 с арбитражем)
olartamonov Автор
10.03.2019 11:49+1Если не путаю, это на Апполоне было сделано. Америкацы тупые, да?
Вы на вопрос ответьте, пожалуйста. Сами. Без ссылок на американцев.
Да ну??? А доказать можете? Ну скажем на год поставить 10 незащищенных от ТЗЧ систем.
У меня всё сильнее ощущение, что вы беседуете с радио, очень громко играющим у вас в голове. К теме защиты от переполнения стека в результате ошибки софта вот эта ваша фраза какое вообще отношение имеет?
Про комбайны — печально, конечно. С такой кашей в голове и ещё что-то проектировать…Jef239
10.03.2019 15:19Вы на вопрос ответьте, пожалуйста. Сами. Без ссылок на американцев.
Да ноль проблем, я не понимаю, какие у вас трудности.
Чем плох watchdog? Тем что он спасает только от зацикливания. А от отсутствия решения (или неверного решения) не спасает. Да, можно выкручиваться, но мы сильно ограничены временем watchdog. которое обычно секунды.
Из того, что обсуждалось. Два блока, инерциальной и спутниковй навигации. При отсутствии достоверного решения от одного блока в течение N секунд другой блок ресетит отказавший.
Аналогично можно действовать и в случае двух функционально идентичных блоков. При отсутствии решения на чужом блоке или его низком качестве и наличии решения у нас — отключаем или перезапускаем чужой блок.
Качество решения (обычно в виде СКО) в навигации всегда считается вместе с решением. Например — по остаткам псведодальностей и псевдофазы. Или по дрожанию решения. Так что закомплексировать два RTK-приемника или RTK c PPP — это запросто можно.
Ну а задачи бортового компьтера космического корабля — близки к навигационным.
К теме защиты от переполнения стека в результате ошибки софта вот эта ваша фраза какое вообще отношение имеет?
А задача защиты от переполнения не является самостоятельной задачей. Реальная задача — обеспечить наработку на отказ.
И рассмотрение системы как 100% детерменированной — это неверный подход. есть шумы ошифровки, есть ошибки на портах и шинах передачи (и перпосылки), есть нестабильности тактовых генераторов.
99.999% детерменированности обычно есть. Но сбои, изредка приводящие к переполнению стека надо рассматривать как недетерменированные. Получили сбой по порту, запустили перепосылку — стека поели больше. Пришла импульсная помеха — получили пачку лишних прерываний — опять стека поели больше.
Из того, что ловили 30 лет назад. Исходная причина — незащищенный стек между двумя инструкциями ассемблера. При приходе таймерного прерывания (50 герц) портилась память в стеке.
Исходная частота ошибки — примерно раз в трое суток. Вначале мучались математики, потом прикладники, потом системщики. В итоге исключением кусков программы удалось довести частоту сбоя до 1 раз в 10 минут, после чего уже нашли чтением кода. Увы, заслуга не моя, а моего шефа.
Но факт есть факт — пока ошибку искали как детерминированную — её не могли найти. Как только стали искать как недетерменированную — нашли.
Возвращаясь к теме. Симптомы, указывающие на редкое переполнение стека, нельзя рассматривать отдельно от шансов сбоев от ЭМИ, ТЗЧ и так далее. Если есть нужное оборудование — можно даже начать исследование с них. То есть увеличить частоту сбоев предельным тепловым режимом, максимальными помехами, ухудшенным качеством питания. Вполне может быть, что этим вы редчайшее событие превратите в редкое.olartamonov Автор
10.03.2019 15:40+1Аналогично можно действовать и в случае двух функционально идентичных блоков. При отсутствии решения на чужом блоке или его низком качестве и наличии решения у нас — отключаем или перезапускаем чужой блок.
Вы продолжаете нести многословную чушь.
Что такое «отсутствие решения»? Блок 1 и блок 2 одновременно выдают координаты вашего комбайна, причём разные.
У какого из блоков «отсутствует решение»?
А задача защиты от переполнения не является самостоятельной задачей. Реальная задача — обеспечить наработку на отказ.
Ваша проблема в том, что сначала вы начинаете нести отсебятину, причём щедро приправленную чушью, в ответ на вполне конкретный и узкий вопрос, а потом — оправдываться, что на самом деле вопрос был и не такой уж конкретный и не такой уж узкий.
В то время как вопрос был именно таким, каким он был. Конкретным и узким.
Симптомы, указывающие на редкое переполнение стека, нельзя рассматривать отдельно от шансов сбоев от ЭМИ, ТЗЧ и так далее
Бред. Можно и нужно, потому что котлеты — отдельно, а мухи — отдельно.Jef239
10.03.2019 16:04Что такое «отсутствие решения»? Блок 1 и блок 2 одновременно выдают координаты вашего комбайна, причём разные.
Так выдается же не только решение, но и его СКО, полученное из остатков. То есть нашли координаты, просчитали теоретически расстояние до спутников, вычли измерения — получили остатки. И эти остатки могу отличаться в десятки раз.
У какого из блоков «отсутствует решение»?
В реальности у нас 3 антенны и 3 приемника и проверяемся по вычисленному из решений расстоянию между приемниками. Если между приемниками 1 и 2 расстояние в норме, а между 3 и 1 и между 3 и 2 — не в норме, то надо перезапустить решение на приемнике 3.
На самом деле мы считаемся на одном и том же SoC, но логика у нас ровно такая.
А измерения без оценки СКО — это какой-то школьный уровень. Ну не стоит так делать в профессиональной аппаратуре.
на самом деле вопрос был и не такой уж конкретный и не такой уж узкий.
Это правда. При переносе вопросов на личный опыт получается не конкретно и не узко.
Нехватки стека я видел. Но они или срабатывают сразу или носят не детерменированнный характер. То есть может проработать сутки, а может свалиться через 10 минут. Потому что условием ошибки является редкая и не детерменированная ситуация в данных.olartamonov Автор
10.03.2019 16:43Так выдается же не только решение, но и его СКО, полученное из остатков
В реальности у нас 3 антенны и 3 приемника
Мне нравится, как вы сначала делаете обобщение вида «при отказе одной прошивки работает вторая», а на вопрос, как вы определяете, какая конкретно прошивка отказала, мгновенно сводите всё к тому, что у вас и не две, и не прошивки, а вообще всё по-другому.
Вы не могли бы громкость играющего у вас в голове радио всё же немного уменьшить — а то не очень понятно, стоит ли вообще с вами дискутировать, если вы в любой момент тему беседы меняете произвольным образом?
Но они или срабатывают сразу или носят не детерменированнный характер
Опять чушь — ну или банальное незнание и непонимание вами, что такое детерминированная система.
Ваш контроллер по определению является детерминированной машиной Тьюринга, и тот факт, что сочетание входных данных, приводящее к конкретному результату, случается крайне редко, никак не делает поведение недетерминированным.
Недетерминированное поведение — это поведение, при котором одни и те же входные данные могут приводить к разным результатам.Jef239
11.03.2019 02:27Недетерминированное поведение — это поведение, при котором одни и те же входные данные могут приводить к разным результатам.
Да, именно так. Один и тот же сигнал, снятый с одной и той же антенны приводит к разным измерениям. Один и тот же пинг, посланный одному и тому же серверу, дает разное время пинга.
Отучайтесь от привычки работать исключительно с ученическими системами. Не детерминированность или неполная детермированность — неотъемлимое свойство сложных систем.
Ваш контроллер по определению является детерминированной машиной Тьюринга,
Это так лишь для школьничков. Уже на уровне студентов такое определение вредно и вызывает куча ошибок типа гонка.
В понимаете, что в многонитевой программе переключение между нитями может произойти в произвольный момент? Или веруете, что оно детерменировано?
Вы понимаете. что в младших битах значения от АЦП дробный шум? Или веруете в стабильность любых измерений, не взирая на температурный дрейф и прочие эффекты?
Вы понимаете, что сбои по ком-порту бывают примерно с частой 1E-6 в не детерминированных местах?
Короче, оставьте этот бред для школьников. Да, на уровне «hello world» все детермировано. А на уровне реальных систем — нет.
Поэтому дико бесят недоучки, не принимающие мер к детерминизации. То есть они работают только по реальному сигналу, а потом удивляются — ой, странный сбой, ой, не воспроизводится.
Да, подсистемы. позволяющие записать сигналы, а потом — воспроизвести поведение системы по записанным файлам — не дешевое удовольствие. Зато по файлам, на windows, в однонитевой программе — все детерминировано. И 98% процентов проблем отлаживается именно так.
И первый шаг к надежному коду — признать, что реальный SoC с плывующей частотой кварца, шумящим АЦП, прерываниям и прочими прелестями — слабо детерменирован.
Теперь к первому вопросу.
Мне нравится, как вы сначала делаете обобщение вида «при отказе одной прошивки работает вторая», а на вопрос, как вы определяете, какая конкретно прошивка отказала, мгновенно сводите всё к тому, что у вас и не две, и не прошивки, а вообще всё по-другому.
Давайте вы научитесь правильно задавать вопросы? А то думаете одно, пишете другое, а потом удивляетесь, что вам ответили на тот вопрос, который вы задали, а не на тот, о котором вы думали.
а на вопрос, как вы определяете, какая конкретно прошивка отказала,
Мы определяем? Именно мы?! Я вам рассказал про решение, которое применило НАСА в одном из кораблей. Вроде в Апполоне.
Мы не являемся сотрудниками НАСА. И не отвечаем за решением примененное НАСА более 50 лет назад.
Я могу рассказать про свои системы. Но мы не НАСА, поэтому программирование одного алгоритма двумя независимыми командами разработчиков не применяем. А что применяем — я рассказал.
Или вам нужны фантазии, что бы я сделал на месте НАСА? Это несложно. Принцип ровно тот же — не только считать не только результаты расчетов, но и показатели их достоверности и точности (СКО, КВО, etc). Это все давным давно описано в учебниках. Собственно любая система выше школьного уровня погрешности считает.
Ну и второе -это время решения. Все расчеты — итеративные, сходятся итерации быстро или медленно — зависит от данных и методики расчета. Насколько мне помнится, в те годы сильно боялись зацикливаний. Так что нету решения N секунд — считаем, что у нас отказ. Такой вот взаимный контроль.
Ну может оно сложновато для того школьного уровня, к которому вы привыкли. Ну так реальные системы сильно отличаются от того «hello world», который вы преподаете. Ничего страшного, не век же вам со студентами общаться? Привыкайте к общению со специалистами.olartamonov Автор
11.03.2019 07:49Не детерминированность или неполная детермированность — неотъемлимое свойство сложных систем.
Вы сейчас занимаетесь тем, что выдумываете свои собственные определения, чтобы скрыть вашу же собственную профнепригодность как разработчика.
Ну или в силу своей вопиющей некомпетентности искренне не различаете случайные физические процессы с недетерминированностью вычислительной системы.
Остальную простыню не читал.
amartology
10.03.2019 13:46+1Зачем вы сейчас приплетаете одиночные сбои к разговору про сбой процессора в результате ошибки в программе? Если есть ошибка в программе, то все три копии действительно откажут синхронно и одинаково (там, разумеется, есть нюансы про прерывания, но это сейчас не важно).
Но кстати да, дублирование в реальности довольно часто применяется, хотя мажоритарная логика тут ни при чем, конечно же. Это как с помехоустойчивым кодированием — есть коды, которые ошибки исправляют, а есть коды, которые их только обнаруживают. Вторые дают меньше накладных расходов в штатной эксплуатации, но больше — во время сбоя.Jef239
10.03.2019 15:50Если есть ошибка в программе, то все три копии действительно откажут синхронно и одинаково (там, разумеется, есть нюансы про прерывания, но это сейчас не важно).
Попробуйте доказать этот тезис.
Ну как пример. Есть чтение ком-порта, при приеме бывают сбои. Подаем информацию с одного датчика на две системы. Вы уверены, что два ком-порта на разных SoC дадут сбой синхроннно?
Ошибки на главном ходу алгоритма вычищаются быстро. А ошибки на редко используемых ветках намного больше завязаны на не детерменированные события.
Можете сделать эксперимент. Берете два GPS-приемника, сажаете их на общую антенну и общее питание. Корпус — общий или одинаковый, чтобы температурный режим не влиял.
Какие шансы, что два приемника в таком режиме (режим называется нуль-база) дадут одинаковые измерения псевдодальности и псевдофазы? НУЛЕВЫЕ. Всегда будет шум измерений. У хороших приемников — поменьше, у плохих — побольше. Но он есть всегда.
И дело не только в тепловом шуме. Бывают слипы, бывают систематики. Даже тактовые генераторы прилично расходятся. Один дает коррекцию на 1/16 мкс раз в 15 секунд, другой- на каждой секунде. Что будет в измерениях? Систематика там будет.
Так что сказок про детерменированность — не надо. Детерменированность у нас (высокоточная навигация) — редкий подарок.olartamonov Автор
10.03.2019 16:47+1Ну как пример. Есть чтение ком-порта, при приеме бывают сбои. Подаем информацию с одного датчика на две системы. Вы уверены, что два ком-порта на разных SoC дадут сбой синхроннно?
Вы вообще пробовали прочитать вопрос, который вам задали, и ваш ответ на него?
Или вы искренне считаете, что какая-либо корреляция между вопросом и ответом совершенно не обязательна — и в дискуссии можно просто на все исходные тезисы спокойно забить, на ходу придумав новый пример?
Впрочем, из вашего примера про то, как вы «исправляли» клавиатуру, в принципе дальнейший ход ваших мыслей вполне понятен.
В то время как у любых нормальных разработчиков решение проблемы начинается с её максимальной декомпозиции и дальнейшего поштучного исключения кандидатов на причину, то вы действуете ровно наоборот — яростно замешиваете в одну кучу все возможные причины, а потом, вместо поиска и устранения единственной истинной причины, пытаетесь подпереть получившееся костылём, который вроде бы в данном месте не даёт получившейся конструкции обрушиться.Jef239
11.03.2019 04:21То есть вы не поняли, что вопрос "Зачем вы приплетаете" риторический и хотите получить на него ответ????!
Ну ОК, отвечу. Да затем, что исправление «одиночных сбоев» занимает 90% времени. Затем что хотя каждая отдельная ситуация редкая, хоть какая-нибудь из них происходит часто. Затем, что учет редких ситуаций дает нам точность в 4 раза лучше конкурентов (при том же приемнике).
Никогда не видели, как дешевый навигатор показывает, что вы едете сквозь дома? Это вот как раз и есть — отсутствие учета редких ситуаций.
Иногда даже понятно, каких именно.Включите навигатор в 2:30 в ночь с субботы на воскресенье — есть шансы, что в 3:00 решение улетит метров на 100 от реального расположения. Как минимум на одной модели мы такое видели. Исправляется оно через 6-7 минут. Кстати, это один из немногих хорошо детерменированных ляпов.olartamonov Автор
11.03.2019 07:50Господи, какой невероятный стыд вы несёте.
Да никакие вы проблемы не решаете и решать не умеете — вы умеете подпирать дырки костылями, маскируя эти уродливые конструкции гигантскими нагромождениями слов, которые с вашей точки зрения, видимо, имеют отношение к решению проблем.
amartology
11.03.2019 12:30Ну ОК, отвечу. Да затем, что исправление «одиночных сбоев» занимает 90% времени.
Если у вас при проектировании автопилота комбайна 90% времени занимает работа по предотвращению одиночных сбоев от космических частиц, то вы явно что-то делаете не так; даже если применяете самые правильные методы, проверенные еще NASA на «Аполлонах».
Jef239
10.03.2019 03:31Да, для понимания надежности комбайнового автопилота. Прием GPS-сигнала идет на уровне в 100 меньше фонового шума. Поэтому куска мокрого брезента, брошенного на антенны — хватает для вывода системы из строя. Любой системы. Хоть нашей, хоть американской.
Поэтому надежность не так важна. Важнее — достоверность. Те самые 2см отклонения от заданной траектории.
Если картошку сажать ровно в грядки, её вырастает на 30% больше, чем при равномерной посадке. Но требуемая долговременная стабильность — меньше 5 см на орудии. Это, правда, не про комбайны, а про трактора.
Ещё один важный критерий — доступность. Один спутник сломался, второй — на плановом ТО, остальные — разлетелись и низко висят… Вот тут как раз хочется минимум пять девяток.
А надежность… Сезон отработал — можно полгода чиниться. Так что надежность решается путем доступности запасных блоков — ну скажем 1 на 100 комбайнов хватит с запасом.
Вот такая вот специфика.augorelov
10.03.2019 12:17Поэтому надежность не так важна. Важнее — достоверность
Вот здесь Вы в корне ошибаетесь. Надежность важна всегда и не важно на земле, под землей, в воздухе, на воде или под водой нашло применение разрабатываемое вами устройство. Бывают случаи когда устройство разрабатываемое для стационарных наземных систем, находит свое применение на подводных лодках.Jef239
10.03.2019 14:21Ну только если это будет летающая подводная лодка. Пары милллиметров воды достаточно, чтобы заглушить прием GPS.
Нет смысла делать супернадежную обработку GPS, когда у нас сам прием GPS блокируется куском мокрого брезента. Есть смысл бороться за точность и долговременную стабильность.
Надежность важна всегда
Расскажите об этом производителям лампочек накаливания. Можно было (и делали) очень надежные лампочки. Только они выходили в разы дороже. Есть спрос на надежные лампочки накаливания по десятерной цене? Увы, нету.
amartology
10.03.2019 14:26На LED-лампы с ценой х10 от ламп накаливания и сроком службы х10 спрос есть и он растет (даже не говоря о том, что они значительно меньше электричества потребляют).
Jef239
11.03.2019 03:02Ну так это всего лишь 10х срока службы за 10х цену. А сколько будет стоит выпуск столетних лампочек? Угу, углеродная нить не перогорает из-за пусковых токов. Но цена…
augorelov
10.03.2019 18:11Ну только если это будет летающая подводная лодка. Пары милллиметров воды достаточно, чтобы заглушить прием GPS.
Где Вы в моем комментарии видели про GPS под водой?! Не надо читать между строк, то чего нет.
Вы не понимаете, что такое надежность, если привели пример про лампы накаливая.
Вот Вам не больший ликбез из ГОСТ 27.002-2015: «Надежность: Свойство объекта сохранять во времени способность выполнять требуемые функции в заданных режимах и условиях применения, технического обслуживания, хранения и транспортирования.»Jef239
10.03.2019 20:04Где Вы в моем комментарии видели про GPS под водой?!
Ну вот же:под водой нашло применение разрабатываемое вами устройство.и тутБывают случаи когда устройство разрабатываемое для стационарных наземных систем, находит свое применение на подводных лодках.
Мы занимаемся высокоточным GPS (точнее GNSS, то есть GPS, ГЛОНАСС, GALILEO и так далее).
Так что подводная лодка нам светит только летающая (в степях Украины, видимо).
А для корабельных систем — другое устройство, тоже RTK, но работающее по иным принципам.augorelov
11.03.2019 08:32Это было не конкретно про Ваше устройства, а пример из жизни. Но Вам видимо важно придраться к словам, а не понять что надёжность одина из важнейших характеристик разрабатываемых и серийновыпускаемых устройств.
acesn
09.03.2019 14:37+3Маркировка стека и есть фактически стандартизованный способ, он используется в различных SDK и RTOS.
Есть ещё автоматизированные инструменты для расчёта дерева вызовов, но они сильно ограничены в применении так как не могут учесть наложение прерываний, о чём автор собственно написал.
Andy_Big
09.03.2019 15:53+2Статья явно не для тех, кому квалификация позволяет делать автопилот или систему управления АЭС :)
amartology
09.03.2019 18:31+1К сожалению, недостаточная квалификация ещё никого не останавливала от того, чтобы делать что-то, потенциально опасное для жизни. Особенно если нет понимания, что квалификация недостаточная, зато есть горящие глаза и нулевой раунд инвестиций.
Andy_Big
09.03.2019 18:41Одних горящих глаз явно недостаточно чтобы начать производство и продажи таких дорогих и сложных вещей как автопилоты или САУ для АЭС :)
А тем разработчикам, которые все же дошли до таких сложных и ответственных вещей, но не научились качественному тестированию — им никакие приписки в статьях уже не помогут начать это делать.Jef239
09.03.2019 22:36С чего вы решили, что автопилот — это сложная штука? Это для автомобиля он сложен. А для самолета или комбайна — довольно прост.
Andy_Big
10.03.2019 01:16И сколько самолетов летают или комбайнов ездят на Ваших автопилотах? :)
Jef239
10.03.2019 01:58Самолетам не занимаемся, а комбайны прошли этап госиспытаний опытного образца. Впрочем, как и у конкурентов из Ебурга. А западные системы лет 15 есть, просто дорогие слишком.
Кстати, то, что автопилот для самолета был сделан в 1912 году намекает, что ничего сложного там нет. Ну то есть не сложнее PID-регулятора.
Сложное — это управление цементной печью. Там люди диссертации пишут на основе опыта живых операторов. Ну просто потому, что математически она не рассчитывается. Там нечеткая логика и экспертные системы. Ну то есть явно не 1912ого года технологии.
evgus
09.03.2019 11:55+1Судя по фрагменту кода:
while (start < top) {
создаётся впечатление, что перед публикацией его не показывали компилятору.
*(star++) = STACK_CANARY_WORD;
}
Sergey78
09.03.2019 11:59+1Попробовал этот способ, и обнаружил интересное поведение.
Заполнение памяти я добавил прямо в startup, который использую из CMSIS.
изменения в startupReset_Handler:
ldr sp, =_estack /* set stack pointer */
ldr r0, =_ebss
ldr r1, =_estack
ldr r2, =0x6B6B6B6B
Clear_Heap:
str r2, [r0, #0]
add r0, #4
cmp r0, r1
bne Clear_Heap
olartamonov Автор
09.03.2019 12:07Насколько я понял, несмотря на то, что я не использую динамическое выделение памяти и _Min_Heap_Size у меня стоит 0, линкер располагает секцию _user_heap_stack
Да, printf/scanf/etc. могут, в зависимости от конкретной реализации, использовать или не использовать кучу, равно как и куча, в зависимости от конкретной реализации, можно быть сделана по-разному.
Например, newlib, собранный по умолчанию, и newlib, собранный со specs=nano.specs, имеют радикально разные футпринты printf, а во FreeRTOS сразу пять реализаций кучи разной функциональности.IgorPie
09.03.2019 16:39Все равно, они едят память как не в себя и лучше заменять все самописными. По крайней мере, на f0.
И компиляторы keil и gcc компилируют сильно по-разному
acesn
09.03.2019 12:38+2Вообще говоря, использовать malloc на микроконтроллерах настоятельно не рекомендуется, если вы не знаете абсолютно точно, что вы делаете. Основной привносимой им проблемой является фрагментация памяти
Знать что делаешь надо в любом случае, а не только с malloc. Сам malloc не приводит к дефрагментации, причина дефрагментации — free. Использовать malloc очень удобно на стадии инициализации, и достаточно безопасно, так как легко проверяется тестами. А вот в runtime злоупотреблять malloc действительно не стоит.
poison85
09.03.2019 14:57+2
zloe_morkoffko
09.03.2019 15:23Просто взять побольше не получится, нужно все равно как-то проанализировать потребности программы. Хоть через раскрашивание стека, хоть любым другим способом из этой статьи или из комментов к ней.
Amomum
09.03.2019 15:25+2С большим — а насколько большим? 20 Кб? 40? Мегабайт? Если никак не профилировать и не оценивать потребление стека, то как узнать, сколько вам хватит? Или сразу Малину ставить предложите?
poison85
09.03.2019 15:45+1Я не против профилирования. Но если памяти хватает уже в притирку, и есть опасения, что стек достанет данные, то лучше брать МК с запасом на случай расширения объема программы в следующих версиях. У меня уже возникла ситуация с нехваткой памяти. Пришлось вместо STM32F030C8T6 с 8кБ взять STM32F030CCT6 с 32кБ, по распиновке совместимый.
IgorPie
10.03.2019 00:15Это закупщики не сказали своё фи и паяльщики, которые привыкли TSSOP20 паять, значит это f030f4p6 и tqfp48, значит это f103cbt6.
olartamonov Автор
09.03.2019 19:08+1Ну, где-то на партии от 10 тыс. штук жизнь этого чувака и правда оказывается дешевле, чем разница в стоимости между двумя контроллерами…

Sun-ami
09.03.2019 20:29Дешево же Вы оценили его жизнь — на партии 10 тыс. штук разница между STM32F030F4 и STM32F070F6P6 — $1480, между STM32F407VET6 и STM32F427VGT6 — $11890 (цены взяты с сайта ST). Такая разница оправдывает трудозатраты на оптимизацию, но уже даже замену программиста на более квалифицированного — сама по себе как правило нет.
Sun-ami
09.03.2019 18:45+2После определения фактически используемого объёма стека окрашиванием полезно поставить на наибольшую глубину стека точку останова по обращению к ячейке памяти. Это позволит увидеть, в какой ветке программы стек используется максимально. Это нужно потому, что в случае, если программа попадает в эту ветку редко, совпадение времени нахождения в ней, и всех возможных прерываний может случаться очень редко, и за время тестирования может не случиться ни разу. Поэтому в случае, если останов на этой точке останова произошел не в прерывании, или не в том прерывании, которое использует максимальное количество стека, или если возможны вложенные прерывания — к полученному размеру стека нужно добавить соответствующий его размер, используемый в прерываниях. Также возможен случай, когда у функции, в которой наблюдается максимальное использование стека, есть совсем редкий вариант исполнения, который использует ещё больше стека — определив эту функцию его не сложно выявить простым анализом, и зарезервировать под него дополнительный объём стека. Вариант «просто добавить 10%» срабатывает не всегда, фактически 10% нужно резервировать просто на всякий случай, уже после резервирования под максимально возможную вложенность прерываний.
Sun-ami
09.03.2019 19:24+1А вообще — описан довольно экстремальный случай, хотя такое и случается. На практике, если после реализации всего функционала остаётся менее 30 % любого ресурса — памяти программ, данных, или вычислительной мощности — нужно в следующей ревизии устройства менять контроллер. Потому что это позволит немного доработать функционал и устранить баги и недоделки, выявленные уже в эксплуатации, обновлением прошивки. В этом случае половину неиспользуемой памяти в релизной версии можно отдать под стек, а в отладочной выделить под стек объём, близкий к минимальному — тогда все связанные с переполнением стека проблемы выявятся ещё на этапе отладки.
ittakir
09.03.2019 19:42Из своего опыта могу сказать, что важно не забывать о проверке стека, когда лезешь в какой-нибудь старый проект.
Обычно просят, добавь нам вот такой функционал. Ну добавляешь. И совсем забываешь, что программа то теперь требует чуть больше памяти и может упасть в самый неожиданный момент в тех местах, которые работали и протестированы на 10 раз.
zloe_morkoffko
Интересная статья про стек в Cortex-M habr.com/ru/post/425071 от Amomum
olartamonov Автор
Да, есть такой метод, с перемещением стека в начало ОЗУ.
Но по сути спасает только от неопределённого поведения при выходе стека за допустимый размер, заменяя его на хардфолт. При разработке хоть какое-то профилирование всё равно нужно.
olartamonov Автор
И, кстати, это только для MSP работает.
PSP — это просто куски памяти где-то в bss.
besitzeruf
PSP это не куски памяти, это такой же регистр как и MSP, только с одним исключением — его гарантировано не будут использовать прерывания. А на что каждый из регистров указывает, решать программисту.
olartamonov Автор
De facto это куски памяти в bss. Объявленные обычно просто как массивы в приложении. Особенного положения у стеков процессов нет и не будет просто в силу того, что стеков процессов — обычно несколько больше, чем возможно особенных положений.
besitzeruf
Всмысле «только» спасает? Также вам позволяет в микроконтроллере без MPU отловить проблемное место, войти в безопасный режим или вообще перезагрузится с сохранением состояния без ведома пользователея (все зависит от сложности програмы).
olartamonov Автор
Нет у вас никакого безопасного режима, у вас есть BusFault (или вообще сразу HardFault) по неизвестной вам причине. В этот момент вы уже ничего не знаете о том, живо ли там вообще какое-либо состояние.
И при «сложности программы» в основном стеке у вас с большой вероятностью будут крохи, потому что всё разбредётся по процессам.
Так что помогает это только в отладчике.
besitzeruf
Попадание в любое исключение уже указывает на проблему, что не мешает Вам ввести МК в «безопасный» режим. Этот режим и что это вообще такое, определяется проектом. Вы можете сделать дамп стека, регистров, записать лог… Оставить след в рам памяти. Сделать сброс, в стартапе проверив, не был ли сброс по причине ошибки. То что Вы не знаете как такое делается, не значит что такое невозможно.
olartamonov Автор
Какого стека? Того, который только что записался в никуда, вызвав хардфолт?
Ну началось.
Вообще-то с высокой степенью достоверности именно это и значит. Вы даже причину сбоя определить не сможете, так что какое вам счастье со знания, что перезагрузка была вызвана сбоем — сказать трудно.
besitzeruf
Что имеет смысл дампить, зависит от причины, которую (еще раз повторюсь) можно определить. Я перечислял возможности, а не указал последовательный список действий.
olartamonov Автор
Нет, нельзя. В рантайм-коде в общем случае нельзя определить причину, по которой система грохнулась в хардфолт.
Jef239
Для любого ответственного применения безопасный режим обязателен. То есть краны закрыть, все горящее — притушить, окна-двери — разблокировать. Ну в общем сделать так.чтобы если что — поменьше народу погибло. Безопасный режим желательно дублировать на разных слоях аппаратуры. Притяжки к 0 и 1 вне SoC — это первый слой, на случай, если нет питания на плате. Притяжки в STM32Cube — второй слой, но они отрабатывают не сразу после старта. поэтому для быстрых процессов делается третий слой — притяжки при вылете HardFault ему подобным.
В общем случае нельзя, а в частных — можно. Ту же окраску памяти при помощи 0xDEADBEAF проверить.Логика тут такая. Получив полный ламп, программист за месяц найдет причину с вероятностью 99.99%. Далее ничего не мешает написать код, который бы выявлял признаки именно этой ситуации. И так — со всеми ситуациями, которых на отлаженной программе — немного.
Ну как пример. 25 лет назад у меня при включении холодильника дважды перезапускался процессор клавиатуры. Сначала первый перезапуск, а следом — второй. Поэтому последовательность инициализации выдавалась в полуторном размере, а BIOS такого не понимал.
Случай был настолько вырожденный (всего одна причина слета), что я просто написал резидента к MS-DOS для исправления влияния холодильника.
Так что в общем случае нельзя, а в частных — делаем вероятностно на известные причины.
olartamonov Автор
Вы правда для ответственных применений пользуетесь простынками, сгенерированными кубом?..
Это, конечно, чушь.
Во-первых, до того, как у вас инициализировалась периферия и ножки программно переключились в нужные режимы, они находятся в режиме входа, то есть — работают внешние подтяжки.
Во-вторых, обработчик hard fault вам с этими подтяжками никак не поможет, потому как из него вам таки надо будет перезагрузиться, в результате чего все ваши ножки мгновенно встанут в режим входа, см. выше.
В-третьих, есть всего две вещи, в которых вам может помочь обработчик hard fault, и ни одну из них вы не упомянули. Это либо немедленно перезагрузиться, либо, наоборот, выставить ножки в состояние по умолчанию и навсегда уйти в while (1) — то есть повиснуть до вмешательства оператора.
Но второе не дружит с вотчдогом, который всё равно перезагрузит систему, поэтому при включённом вотдоге не имеет смысла. Кроме того, во втором случае надо не забыть не просто выставить ножки в нужное состояние, а с нуля переинициализировать всю периферию GPIO, но это уже детали.
Опять чушь.
Во-первых, то, что у вас окраска затёрта, могло случиться по тысяче причин, и переполнение стека — лишь одна из них. Вовремя не остановившийся while легко вытрет вам всю память вообще, пока либо не грохнет вам стек, либо не дойдёт до дырки в адресах. Никак в рантайме определить, что именно случилось, вы не сможете.
Во-вторых, ничем вам это всё равно не поможет. На момент hard fault у вас система в неопределённом состоянии и продолжать работу не может, путь у вас один — перезагрузка.
Вы уверены, что это — про рантайм?
Подпёрли дырку костылём то есть.
Jef239
Если делаете что-то отказоустойчивое, не путайте «должны находиться» с «находятся». Да, должны, но опыт STM32H7 показал, что не всегда RESET сбрасывает все. Ну и errata никто не отменял.
И что??? Вам нужна теоретическая надежность в семь девяток? Или реальная помощь персоналу по замене неисправного блока? Если второе, то 80% надежность при диагностике «сдох БП», «сдох процессорный блок», «сдохло УСО» вполне помогает сократить время ремонта.
Путей, вообще-то 4:
Угу. Приходилось. Вплоть до отладки драйверов через лампочки передней панели на больших машинах. Ну и через gdb при hardfault на той же STM32.
Менять холодильник или покупать ИБП было сильно дороже. не говоря уж о том, чтобы перепрограммировать процессор серийной клавиатуры. 1993 год, вообще-то был. С деньгами очень негусто было.
amartology
Jef239
А можно сценарий хоть одного инцидента именно из-за автопилота комбайна? А что-то ничего в голову не приходит.
Автопилот комбайна, как и автопилот самолета — это устройство, обеспечивающее ведение по заданной траектории. Водителя оно не заменяет, скоростным режимом не управляет.
На самолетах было всего несколько случаев, когда неверный монтаж автопилота вызвал раскачку. Причиной катастрофы было то, что летчики не поняли, что причина именно в автопилоте. Ибо реальных причин в самолете может быть много. Но хождение комбайна по синусоиде очень легко диагностируется, а сам автопилот отключается движением руля.
augorelov
Некорректное сравнение автопилотов самолета и комбайна, следовательно, Вы не до конца представляете, как работает автопилот на современном самолете.
olartamonov Автор
А вы вообще замечаете, что с логикой беседы у вас — ну, так себе? Вы каждый раз уверенно отвечаете не на тот вопрос, который вам задавали.
В ответ на вопрос о надёжных способах профилирования памяти — рассказ о мажоритарном троировании, о диагностике в рантайме — рассказ о программисте, месяц ковыряющем дамп памяти, о том, какое отношение этот дамп имеет к диагностике рантайму — уже пошли какие-то лампочки и «gdb при hardfault» (который, очевидно, опять — не диагностика в рантайме).
При этом вы ещё практически в каждом вашем тезисе умудряетесь и откровенной чуши добавить.
Jef239
Извините, штатный телепат в отпуске. Я не обязан догадываться, что было у вас в голове, когда вы писали свои вопросы.Это пусть ваши школьники гадают на кофейной гуще, какой ответ вы хотели получить.
Пардон, где этот вопрос? Вы не перепутали, кому его задавали? Приучаемся к взрослым методам ведения дискуссии — или признаете, что подобный вопрос мне не задавали или даете пруф.А вопрос был "Например, чем?". И относился он не к профилированию памяти, а к методам создания надежных систем.
Что вы называете диагностикой в рантайме? Выяснение причин вылета рантайма или диагностики, выполняемые в рантайме? Я писал про первое.
Если речь про второе, то есть богатый опыт, но с ПК, а не с микропроцессорами. Когда-нибудь допишу статью. Система проработала 15 лет без сбоев. Точнее без видимых пользователю сбоев, ибо внутренние сбои устранялись самой системой. Кстати, как раз с дублированием — два одинаковых сервера.
Диагностика строилась на постоянном использовании try-блоков. То есть в каждом методе — try...except… finally. Защита была многослойной — метод-объект-подсистема-тред-сервер. Впрочем, во многих случаях подсистема была эквивалентна треду. Каждый слой старался обработать исключение сам, если не мог — передавал вышестоящему слою. Для исключения долбежки применялись счетчики — 3 раза упали в одном месте — значит неверно восстанавливаемся, надо передать исключение выше.
Теперь о том. что вас больше всего интересует. Сервера работали по схеме мастер-слейв с теплым резервированием. Смена ролей шла двумя путями. Во-первых мастер, столкнувшись с неисправимой на уровне перезапуска тредов проблемой, сообщал слейву «я перезагружаться, побудь мастером», ну и уводил сервер в ребут. Во-вторых, слейв постоянно мониторил, жив ли мастер. Если мастер не подавал признаков жизни слейв брал его роль на себя.
Для надежности, отношение между таймаутом и частотой подачи сигналов от мастера было порядка сотни. Да, конечно, был риск, что перерубят обе сети, соединяющие сервера и они оба встанут мастерами. Ну в реальности двух независимо проложенных сетей хватило.
Сервера менялись ролями примерно раз в 2-3 месяца — в основном из-за отключения питания во время ППР (планово-предупредительный ремонт стана). Сбои, приводящие к переключению — порядка раз в год.
Так что с прямыми руками — вполне пишется надежная система с дублированием. Увы, 20 лет прошло, забыл я о ней. Ну ОК, спасибо, что напомнили.
olartamonov Автор
Практически везде, начиная с поста, под которым вы пишете ваши комментарии.
Вы издеваетесь — или у вас русский язык совсем не родной? Диагностикой в рантайме называется диагностика, проводимая в рантайме. Которую тут обсуждали до вас, пока вы не пришли со своими бесконечными рассказами про то, как у вас GPS работает, не имеющими к этой теме никакого отношения вообще.
Остальную вашу простыню не читал.
ne555
Не обращайте внимание на пользователя olartam..., у него что-то «не то»
Он такие комментарии много где оставляет.
Jef239
Ну он привык общаться со студентами, поэтому и сам мыслит ближе к уровню полных чайников и учебных проектов.
Ну это примерно как учителя детям во втором классе объясняют, что 3 (коробки) на 4 пирожка — будет 12 пирожков. А если наоборот, это будет 4 (пирожка) на 3 коробки — 12 коробок, то есть неверный ответ.
Взрослые шизеют и воют в LJ, но на уровне второклашек — оно действительно так. Потому что они используют умножение как быструю замену сложения, а у сложения — одна размерность.
Вы можете сколько угодно объяснять учителю, что 12 — это все равно 12, но он все равно не примет ответ, ибо коробки — это не пирожки. А законы умножения -это третий класс, а не второй, потому не катят.
Ну и у olartamonov та же болезнь.
ne555
Просто «репорт» отпраляйте администрации.
Этот инфальтильный чувак гадости пишет не стесняясь.
У него явно проблемы со здоровьем.
Jef239
У меня аналогичная деформация — много воспитывал подростков. Поэтому потерплю.
А администрация ему уже один аккаунт банила, насколько я помню.
olartamonov Автор
Очень люблю читать посвящённую мне мифологию.
Jef239
Помнится, когда вас забанили, вы писали с ника с ArbeitMachtFrei Вспоминаете такое?
olartamonov Автор
Честно говоря, не очень — хотя бы потому, что если бы у меня был запасной аккаунт, мне не составило бы особой проблемы загнать его карму в приличные +20-30, а не как у вас, кхе-кхе.
Что ещё расскажете?
(до чувака, который ходил и всем рассказывал, что меня уволили из «Компьютерры» за джинсу, вы пока довольно сильно не дотягиваете; не говоря уж про создавшего целиком посвящённый мне сайт)
Jef239
Ничего страшного, другие увидят. Ваше хамство — оно всегда с вами.
ne555
Вам пишут, что ваше поведение токсичное (по вашим комментариям к другим статьям), что вас уже банили здесь за ваш выходки, а вы отвечаете, про какой-то там сайт, который никому не интересен и не известен.
Amomum
Мне в комментарии советовали потрогать DebugMon, который, по идее, позволит отделить хардфолт от переполнения стека, но сходу у меня это не заработало и дальше я пока не копал.
Может у вас получится?
olartamonov Автор
DWT — это опциональные системные регистры; они, с одной стороны, определены ARM'ом, а не конкретным производителем, с другой — их наличие и функциональность в конкретном продукте отданы на откуп производителю.
Может не быть вообще, может быть не быть конкретно точек останова — надо смотреть документацию на конкретный контроллер.
Amomum
Это да, но ваша статья-то про STM32; там эта функциональность вроде как присутствует.
olartamonov Автор
Там целая пачка нюансов.
Во-первых, надо смотреть в конкретной серии процессоров, ибо ARM нам сообщает, что «The DWT unit can include between 0 and 15 comparators» — т.е. само по себе наличие DWT не означает, что он имеет конкретную функциональность. Во-вторых, с DWT также есть засада — он настраивается на конкретный адрес, и если сбоящая функция этот адрес «перешагнёт», то DWT ничего не заметит. В-третьих, DWT асинхронный и он сам не останавливает текущую операцию, т.е. проблема с тем, что ошибку-то мы заметили, а дальше нам остаётся только перезагружаться, потому что система находится уже в неопределённом состоянии, никуда не исчезает.
Sun-ami
Вообще-то в некоторых из STM32 есть MPU, и его тоже можно для этого использовать.
besitzeruf
К чему этот комментарий? Я знаю о существовании MPU, в статье же указаны микроконтроллеры без него, и даже без него есть варианты того, что можно сделать.