
В облегченной системе Android Go действуют повышенные требования к предустановленным приложениям — размеру и используемой памяти. Перед нами встала задача в эти требования уложиться. Мы провели ряд оптимизаций и решили серьезно поменять архитектуру нашей графической оболочки — Яндекс.Лончера. Руководитель группы разработки прикладных мобильных решений Александр Старченко поделился этим опытом.
— Меня зовут Александр, я из Санкт-Петербурга, из команды, которая занимается разработкой Яндекс.Лончера и Яндекс.Телефона. Сегодня я расскажу, как мы оптимизировали память в Лончере. Сначала коротко объясню, что такое Лончер. Далее мы обсудим причины, зачем нам оптимизировать память. После этого рассмотрим, как корректно измерить память и из чего она состоит. Затем перейдем к практике. Я буду рассказывать, как мы оптимизировали память в Лончере и как пришли к радикальному решению вопроса. И под конец расскажу о том, как мы мониторим использование памяти, как мы держим ее под контролем.

«Лончер» или «Лаунчер» — не так важно. Мы в Яндексе привыкли называть его Лончером, и в докладе я буду использовать слово «Лончер».
Еще один важный пункт: Лончер достаточно широко распространяется через предустановки, то есть когда вы покупаете новый телефон, Яндекс.Лончер довольно часто может оказаться одним и единственным менеджером приложений, менеджером домашних столов в вашем телефоне.
Теперь к причинам, зачем нам оптимизировать память. Начну с нашей причины. Если коротко, это Android Go. А теперь более длинно. В конце 2017 года Google представил Android Oreo и его специальную версию — Android Oreo Go edition. Чем она специальная? Эта версия предназначена для low-end, для недорогих телефонов с объемом оперативной памяти до одного гигабайта. Чем еще она особенная? Для приложений, которые предустанавливаются на эту версию Android, Google выдвигает дополнительные требования. В частности — требования по потреблению оперативной памяти. Грубо говоря, некоторое время после запуска снимается память приложения, и размер не должен превышать для Лончера 30–50 мегабайт в зависимости от размера экрана телефона. 30 на самом маленьком, 50 на больших экранах.
Также следует заметить, что Google продолжает развивать это направление, и уже есть Android Pie Go edition.
Какие еще могут быть причины оптимизировать использование памяти? Во-первых, ваше приложение будет реже выгружаться. Во-вторых, оно будет быстрее работать, так как будет реже отрабатывать сборщик мусора и реже аллоцироваться память. Не будут создаваться лишние объекты, не будут инфлейиться лишние view, и т. д. Косвенно, судя по нашему опыту, это приведет к уменьшению размера apk вашего приложения. Все это вместе обеспечит вам большее количество установок и лучшие оценки в Google Play.
Отлично, теперь мы знаем, зачем оптимизировать память. Давайте посмотрим, с помощью каких средств ее измерять и из чего она состоит.
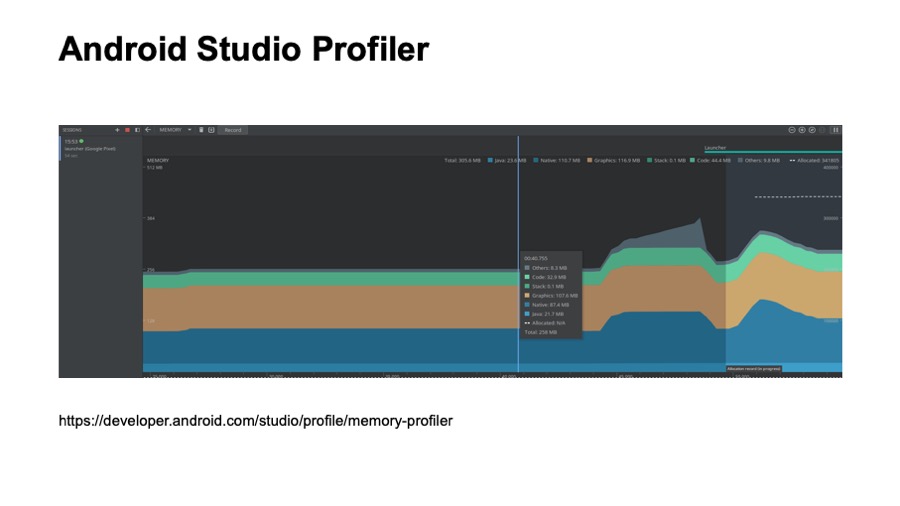
Наверное, многие из вас видели эту картинку. Это скриншот из Android Studio Profile, из просмотра памяти. Это средство достаточно подробно описано на developer.android.com. Наверное, многие из вас их пользовались. Кто не пользовался — попробуйте.
Что здесь хорошо? Оно всегда под рукой. Его удобно использовать в процессе разработки. Тем не менее, оно обладает некоторыми недостатками. Здесь видны не все аллокации вашего приложения. Например, здесь не видны загруженные шрифты. Также с помощью этого средства неудобно смотреть, какие классы загружены в память, и это средство вы не сможете использовать в автоматическом режиме, то есть вы не сможете настроить какой-то автоматический тест на основе Android Studio Profile.

Следующее средство существует со времен Android-разработки в Eclipse, это Memory Analyzer, MAT, если коротко. Оно предоставляется как standalone-приложение и совместимо с дампами памяти, которые вы можете сохранить из Android Studio.
Для этого вам понадобится использовать небольшую утилиту, проф-конвертер. Она идет вместе с Android Go edition и обладает рядом преимуществ. Например, оно умеет строить Paths to gs roots. Нам оно очень сильно помогло увидеть, какие именно классы грузятся Лончером и когда они грузятся. Мы не могли этого делать с помощью Android Studio Profiler.
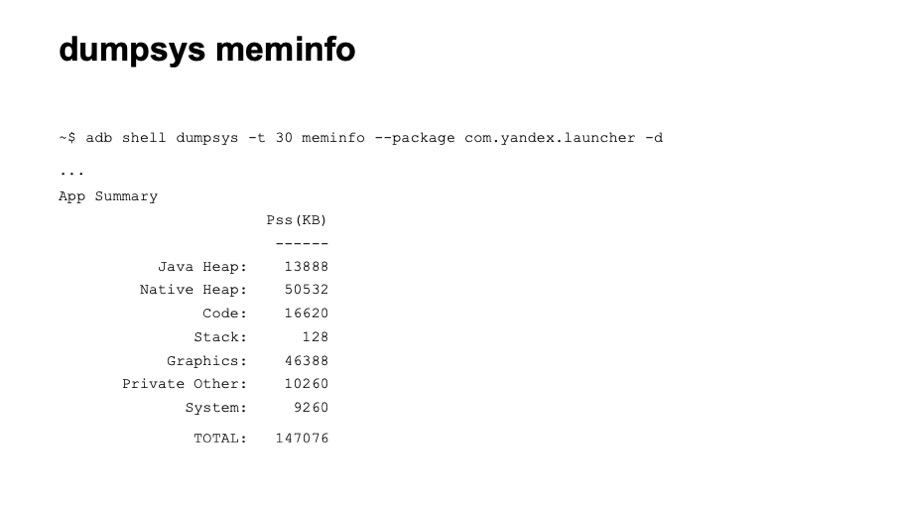
Следующее средство — утилита dumpsys, а конкретно dumpsys meminfo. Здесь вы видите часть вывода этой команды. Она дает достаточно высокоуровневые знания о расходе памяти. Тем не менее, она обладает и определенными преимуществами. Ее удобно использовать в автоматическом режиме. Вы легко можете настроить тесты, которые просто будут вызывать эту команду. Также оно показывает память сразу по всем процессам. И показывает все локации. Насколько нам известно, Google в процессе тестов использует значение памяти именно из этого средства.
Давайте на примере вывода я коротко расскажу, из чего состоит память приложения. Первое — Java Heap, все локации вашего Java- и Kotlin-кода. Обычно эта секция достаточно большая. Следующее — Native Heap. Здесь находятся аллокации из нативного кода. Даже если вы явно не используете нативный код в своем приложении, аллокации здесь будут присутствовать, так как многие объекты Android — те же view — аллоцируют нативную память. Следующий раздел — Code. Сюда попадает всё, что связано с кодом: байт-код, шрифты. Code тоже может быть достаточно большим, если вы используете много сторонних, неоптимизированных библиотек. Следующее — программный стек Java- и нативного кода, обычно небольшой. Далее идет графическая память. Сюда попадают Surface, текстуры, то есть та память, которая стелется между CPU и GPU, используется для отрисовки. Далее — раздел Private Other. Сюда попадает все, что не попало в перечисленные разделы, все, что система не смогла по ним раскидать. Обычно это какие-то нативные аллокации. Далее — раздел System, это часть системной памяти, которая атрибутируется вашему приложению.
И в конце мы имеем TOTAL, это сумма всех перечисленных разделов. Ее мы и хотим уменьшить.

Что еще важно знать об измерении памяти? В первую очередь, наше приложение не полностью контролирует все аллокации. То есть мы как разработчики не имеем полного контроля над тем, какой код будет загружен.
Следующее. Память приложения может сильно «скакать». В процессе измерения вы можете наблюдать сильные различия в показаниях. Это может быть связано как со временем снятия показаний, так и с различными сценариями. В связи с этим, когда мы оптимизируем память, анализируем ее, очень важно делать это при одних и тех же условиях. В идеале — на одном и том же устройстве. Еще лучше, если у вас есть возможность вызвать Garbage Collector.
Отлично. Мы знаем, зачем нам оптимизировать память, как ее корректно измерить, из чего она состоит. Давайте перейдем к практике, и я расскажу, как мы оптимизировали память в Лончере.

Так обстояли дела сначала. У нас было три процесса, которые в сумме аллоцировали порядка 120 мегабайт. Это почти в четыре раза больше, чем мы бы хотели получить.

Относительно аллокации основного процесса здесь был большой участок Java Heap, достаточно много графики, большой код и достаточно большой Native Heap.

Сначала мы подошли к решению проблемы достаточно наивно и решили следовать каким-то рекомендациям от Google с каких-то ресурсов, постараться решить проблему быстро. Мы обратили внимание на синтетические методы, которые генерятся в процессе компиляции. У нас их было больше 2 тысяч. За пару часов мы их все удалили, сняли память.

И получили выигрыш около одного-двух мегабайт в разделе кода. Отлично.
Далее мы обратили внимание на enum. Как известно, enum — это класс. И как Google в конце концов признал, enum не очень эффективны в плане памяти. Все enum мы перевели в InDef и в StringDef. Тут вы мне можете возразить, что здесь поможет ProgArt. Но на самом деле ProgArt не все enum заменит на примитивные типы. Лучше это сделать самому. К слову, enum у нас было больше 90, достаточно много.

Эта оптимизация уже заняла дни, так как большую часть пришлось делать вручную, и мы выиграли порядка трех-шести мегабайт в разделе Java heap.
Далее мы обратили внимание на коллекции. Мы использовали достаточно стандартные Java-коллекции, такие как HashMap. У нас их было больше 150, и все они создавались при старте Лончера. Их мы заменили на SparseArray, SimpleArrayMap и ArrayMap и стали создавать коллекции с заранее известным размером, чтобы не аллоцировались пустые слоты. То есть мы передаем размер коллекции в конструктор.

Это тоже дало определенный выигрыш, и на эту оптимизацию у нас также ушли дни, большую часть мы сделали вручную.
Затем мы предприняли более специфичный шаг. Мы увидели, что у нас три процесса. Как мы знаем, даже пустой процесс в Android занимает порядка 8–10 мегабайт памяти, достаточно много.
Подробно о процессах рассказывал мой коллега Артур Василов. Не так давно на конференции Mosdroid был его доклад, тоже про Android Go.

Что мы имели после этих оптимизаций? На основном тестовом устройстве мы наблюдали потребление памяти в районе 80–100 мегабайт, достаточно неплохо, но все еще недостаточно. Мы стали измерять память и на других устройствах. Мы обнаружили, что на более быстрых устройствах потребление памяти было гораздо больше. Оказалось, что у нас было много различных отложенных инициализаций. Через некоторое время Лончер инфлейтил какие-то view, инициировал какие-то библиотеки и т. д.

Что мы сделали? В первую очередь, мы прошлись по view, по всем лэйаутам. Удалили все view, которые инфлейтились с visibility gone. Внесли их в отдельные лэйауты, стали их инфлейтить программно. Те, которые нам не были нужны, мы вообще перестали инфлейтить до того момента, как они понадобятся пользователю. Мы обратили внимание на оптимизацию картинок. Перестали грузить картинки, которые пользователь сейчас не видит. В случае Лончера это были картинки-иконки приложений в полном списке приложений. До его открытия мы их не грузим. Это дало нам очень хороший выигрыш в разделе графики.
Также мы проверили наши кэши картинок в памяти. Оказалось, что не все они были оптимальные, хранили в памяти не все картинки, соответствующие экрану телефона, на котором запущен Лончер.
После этого мы стали анализировать раздел кода и обратили внимание, что у нас откуда-то возникло много достаточно тяжелых классов. Оказалось, что это в основном библиотечные классы. В некоторых библиотеках мы нашли достаточно странные вещи. Одна из библиотек создавала HashMap и в статическом инициализаторе забивала его достаточно большим количеством объектов.

Другая библиотека также в статическом блоке грузила аудиофайлы, которые занимали порядка 700 килобайт памяти.

Такие библиотеки мы перестали инициализировать, стали с ними работать, только когда данные функции реально нужны пользователям. На все перечисленные оптимизации ушло несколько недель. Мы много тестировали, проверяли, что не внесли дополнительных проблем. Но также мы получили достаточно хороший выигрыш, порядка 25 из 40 мегабайт в разделах Native, Heap, Code и Java Heap.
Но и этого было недостаточно. Потребление памяти все еще не опустилось до 30 мегабайт. Казалось, что мы исчерпали все варианты каких-то простых автоматических и безопасных оптимизаций.
Мы решили рассмотреть радикальные решения. Тут мы увидели два варианта — создание отдельного lite-приложения либо переработка архитектуры Лончера и переход на модульную архитектуру с возможностью делать сборки Лончера без дополнительных модулей. Первый вариант достаточно долгий и дорогой. Скорее всего, создание такого приложения выльется для вас в полноценное отдельное приложение, которое надо будет полноценно поддерживать и разрабатывать. С другой стороны, вариант с модульной архитектурой тоже достаточно дорогой, достаточно рискованный, но все-таки он быстрее, так как вы работаете уже с известной кодовой базой, у вас уже есть набор как автоматических unit-тестов, интеграционных тестов, так и ручных тест-кейсов.
Следует заметить, что какой бы вариант вы не выбрали, вам так или иначе придется отказаться от части фич вашего приложения в версии для Android Go. Это нормально. Google в своих приложениях для Go делает так же.
В итоге, реализовав модульную архитектуру, мы достаточно надежно решили наши проблемы с памятью и стали проходить тесты даже на девайсах с маленьким экраном, то есть уменьшили потребление памяти до 30 мегабайт.

Немного о мониторингах памяти, о том, как мы держим использование памяти под контролем. В первую очередь, мы настроили статические анализаторы, тот же Lint на ошибке в случаях, когда мы используем enum, создаем синтетические методы или используем неоптимизированные коллекции.
Дальше сложнее. Мы настроили автоматические интеграционные тесты, которые запускают Лончер на эмуляторах и через некоторое время снимают расход памяти. Если он сильно отличается от предыдущего билда, у нас срабатывают warnings и alerts. Тогда мы начинаем исследовать проблему и не публикуем изменения, которые увеличивают использование памяти Лончера.
Подведем итоги. Есть различные средства мониторинга памяти, измерения памяти для быстрой и эффективной работы. Лучше использовать их все, так как они обладают своими плюсами и минусами.
Радикальные решения с модульной архитектурой для нас оказались более надежными и эффективными. Мы жалеем, что не предприняли их сразу. Но те шаги, о которых я рассказывал в самом начале доклада, были не зря. Мы заметили, что основная версия приложения стала оптимально использовать память, работать быстрее. Спасибо.
— Меня зовут Александр, я из Санкт-Петербурга, из команды, которая занимается разработкой Яндекс.Лончера и Яндекс.Телефона. Сегодня я расскажу, как мы оптимизировали память в Лончере. Сначала коротко объясню, что такое Лончер. Далее мы обсудим причины, зачем нам оптимизировать память. После этого рассмотрим, как корректно измерить память и из чего она состоит. Затем перейдем к практике. Я буду рассказывать, как мы оптимизировали память в Лончере и как пришли к радикальному решению вопроса. И под конец расскажу о том, как мы мониторим использование памяти, как мы держим ее под контролем.
«Лончер» или «Лаунчер» — не так важно. Мы в Яндексе привыкли называть его Лончером, и в докладе я буду использовать слово «Лончер».
Еще один важный пункт: Лончер достаточно широко распространяется через предустановки, то есть когда вы покупаете новый телефон, Яндекс.Лончер довольно часто может оказаться одним и единственным менеджером приложений, менеджером домашних столов в вашем телефоне.
Теперь к причинам, зачем нам оптимизировать память. Начну с нашей причины. Если коротко, это Android Go. А теперь более длинно. В конце 2017 года Google представил Android Oreo и его специальную версию — Android Oreo Go edition. Чем она специальная? Эта версия предназначена для low-end, для недорогих телефонов с объемом оперативной памяти до одного гигабайта. Чем еще она особенная? Для приложений, которые предустанавливаются на эту версию Android, Google выдвигает дополнительные требования. В частности — требования по потреблению оперативной памяти. Грубо говоря, некоторое время после запуска снимается память приложения, и размер не должен превышать для Лончера 30–50 мегабайт в зависимости от размера экрана телефона. 30 на самом маленьком, 50 на больших экранах.
Также следует заметить, что Google продолжает развивать это направление, и уже есть Android Pie Go edition.
Какие еще могут быть причины оптимизировать использование памяти? Во-первых, ваше приложение будет реже выгружаться. Во-вторых, оно будет быстрее работать, так как будет реже отрабатывать сборщик мусора и реже аллоцироваться память. Не будут создаваться лишние объекты, не будут инфлейиться лишние view, и т. д. Косвенно, судя по нашему опыту, это приведет к уменьшению размера apk вашего приложения. Все это вместе обеспечит вам большее количество установок и лучшие оценки в Google Play.
Отлично, теперь мы знаем, зачем оптимизировать память. Давайте посмотрим, с помощью каких средств ее измерять и из чего она состоит.
Ссылка со слайда
Наверное, многие из вас видели эту картинку. Это скриншот из Android Studio Profile, из просмотра памяти. Это средство достаточно подробно описано на developer.android.com. Наверное, многие из вас их пользовались. Кто не пользовался — попробуйте.
Что здесь хорошо? Оно всегда под рукой. Его удобно использовать в процессе разработки. Тем не менее, оно обладает некоторыми недостатками. Здесь видны не все аллокации вашего приложения. Например, здесь не видны загруженные шрифты. Также с помощью этого средства неудобно смотреть, какие классы загружены в память, и это средство вы не сможете использовать в автоматическом режиме, то есть вы не сможете настроить какой-то автоматический тест на основе Android Studio Profile.
Ссылки со слайда: первая, вторая
Следующее средство существует со времен Android-разработки в Eclipse, это Memory Analyzer, MAT, если коротко. Оно предоставляется как standalone-приложение и совместимо с дампами памяти, которые вы можете сохранить из Android Studio.
Для этого вам понадобится использовать небольшую утилиту, проф-конвертер. Она идет вместе с Android Go edition и обладает рядом преимуществ. Например, оно умеет строить Paths to gs roots. Нам оно очень сильно помогло увидеть, какие именно классы грузятся Лончером и когда они грузятся. Мы не могли этого делать с помощью Android Studio Profiler.
Следующее средство — утилита dumpsys, а конкретно dumpsys meminfo. Здесь вы видите часть вывода этой команды. Она дает достаточно высокоуровневые знания о расходе памяти. Тем не менее, она обладает и определенными преимуществами. Ее удобно использовать в автоматическом режиме. Вы легко можете настроить тесты, которые просто будут вызывать эту команду. Также оно показывает память сразу по всем процессам. И показывает все локации. Насколько нам известно, Google в процессе тестов использует значение памяти именно из этого средства.
Давайте на примере вывода я коротко расскажу, из чего состоит память приложения. Первое — Java Heap, все локации вашего Java- и Kotlin-кода. Обычно эта секция достаточно большая. Следующее — Native Heap. Здесь находятся аллокации из нативного кода. Даже если вы явно не используете нативный код в своем приложении, аллокации здесь будут присутствовать, так как многие объекты Android — те же view — аллоцируют нативную память. Следующий раздел — Code. Сюда попадает всё, что связано с кодом: байт-код, шрифты. Code тоже может быть достаточно большим, если вы используете много сторонних, неоптимизированных библиотек. Следующее — программный стек Java- и нативного кода, обычно небольшой. Далее идет графическая память. Сюда попадают Surface, текстуры, то есть та память, которая стелется между CPU и GPU, используется для отрисовки. Далее — раздел Private Other. Сюда попадает все, что не попало в перечисленные разделы, все, что система не смогла по ним раскидать. Обычно это какие-то нативные аллокации. Далее — раздел System, это часть системной памяти, которая атрибутируется вашему приложению.
И в конце мы имеем TOTAL, это сумма всех перечисленных разделов. Ее мы и хотим уменьшить.
Что еще важно знать об измерении памяти? В первую очередь, наше приложение не полностью контролирует все аллокации. То есть мы как разработчики не имеем полного контроля над тем, какой код будет загружен.
Следующее. Память приложения может сильно «скакать». В процессе измерения вы можете наблюдать сильные различия в показаниях. Это может быть связано как со временем снятия показаний, так и с различными сценариями. В связи с этим, когда мы оптимизируем память, анализируем ее, очень важно делать это при одних и тех же условиях. В идеале — на одном и том же устройстве. Еще лучше, если у вас есть возможность вызвать Garbage Collector.
Отлично. Мы знаем, зачем нам оптимизировать память, как ее корректно измерить, из чего она состоит. Давайте перейдем к практике, и я расскажу, как мы оптимизировали память в Лончере.
Так обстояли дела сначала. У нас было три процесса, которые в сумме аллоцировали порядка 120 мегабайт. Это почти в четыре раза больше, чем мы бы хотели получить.
Относительно аллокации основного процесса здесь был большой участок Java Heap, достаточно много графики, большой код и достаточно большой Native Heap.
Сначала мы подошли к решению проблемы достаточно наивно и решили следовать каким-то рекомендациям от Google с каких-то ресурсов, постараться решить проблему быстро. Мы обратили внимание на синтетические методы, которые генерятся в процессе компиляции. У нас их было больше 2 тысяч. За пару часов мы их все удалили, сняли память.
И получили выигрыш около одного-двух мегабайт в разделе кода. Отлично.
Далее мы обратили внимание на enum. Как известно, enum — это класс. И как Google в конце концов признал, enum не очень эффективны в плане памяти. Все enum мы перевели в InDef и в StringDef. Тут вы мне можете возразить, что здесь поможет ProgArt. Но на самом деле ProgArt не все enum заменит на примитивные типы. Лучше это сделать самому. К слову, enum у нас было больше 90, достаточно много.
Эта оптимизация уже заняла дни, так как большую часть пришлось делать вручную, и мы выиграли порядка трех-шести мегабайт в разделе Java heap.
Далее мы обратили внимание на коллекции. Мы использовали достаточно стандартные Java-коллекции, такие как HashMap. У нас их было больше 150, и все они создавались при старте Лончера. Их мы заменили на SparseArray, SimpleArrayMap и ArrayMap и стали создавать коллекции с заранее известным размером, чтобы не аллоцировались пустые слоты. То есть мы передаем размер коллекции в конструктор.
Это тоже дало определенный выигрыш, и на эту оптимизацию у нас также ушли дни, большую часть мы сделали вручную.
Затем мы предприняли более специфичный шаг. Мы увидели, что у нас три процесса. Как мы знаем, даже пустой процесс в Android занимает порядка 8–10 мегабайт памяти, достаточно много.
Подробно о процессах рассказывал мой коллега Артур Василов. Не так давно на конференции Mosdroid был его доклад, тоже про Android Go.
Что мы имели после этих оптимизаций? На основном тестовом устройстве мы наблюдали потребление памяти в районе 80–100 мегабайт, достаточно неплохо, но все еще недостаточно. Мы стали измерять память и на других устройствах. Мы обнаружили, что на более быстрых устройствах потребление памяти было гораздо больше. Оказалось, что у нас было много различных отложенных инициализаций. Через некоторое время Лончер инфлейтил какие-то view, инициировал какие-то библиотеки и т. д.
Что мы сделали? В первую очередь, мы прошлись по view, по всем лэйаутам. Удалили все view, которые инфлейтились с visibility gone. Внесли их в отдельные лэйауты, стали их инфлейтить программно. Те, которые нам не были нужны, мы вообще перестали инфлейтить до того момента, как они понадобятся пользователю. Мы обратили внимание на оптимизацию картинок. Перестали грузить картинки, которые пользователь сейчас не видит. В случае Лончера это были картинки-иконки приложений в полном списке приложений. До его открытия мы их не грузим. Это дало нам очень хороший выигрыш в разделе графики.
Также мы проверили наши кэши картинок в памяти. Оказалось, что не все они были оптимальные, хранили в памяти не все картинки, соответствующие экрану телефона, на котором запущен Лончер.
После этого мы стали анализировать раздел кода и обратили внимание, что у нас откуда-то возникло много достаточно тяжелых классов. Оказалось, что это в основном библиотечные классы. В некоторых библиотеках мы нашли достаточно странные вещи. Одна из библиотек создавала HashMap и в статическом инициализаторе забивала его достаточно большим количеством объектов.
Другая библиотека также в статическом блоке грузила аудиофайлы, которые занимали порядка 700 килобайт памяти.
Такие библиотеки мы перестали инициализировать, стали с ними работать, только когда данные функции реально нужны пользователям. На все перечисленные оптимизации ушло несколько недель. Мы много тестировали, проверяли, что не внесли дополнительных проблем. Но также мы получили достаточно хороший выигрыш, порядка 25 из 40 мегабайт в разделах Native, Heap, Code и Java Heap.
Но и этого было недостаточно. Потребление памяти все еще не опустилось до 30 мегабайт. Казалось, что мы исчерпали все варианты каких-то простых автоматических и безопасных оптимизаций.
Мы решили рассмотреть радикальные решения. Тут мы увидели два варианта — создание отдельного lite-приложения либо переработка архитектуры Лончера и переход на модульную архитектуру с возможностью делать сборки Лончера без дополнительных модулей. Первый вариант достаточно долгий и дорогой. Скорее всего, создание такого приложения выльется для вас в полноценное отдельное приложение, которое надо будет полноценно поддерживать и разрабатывать. С другой стороны, вариант с модульной архитектурой тоже достаточно дорогой, достаточно рискованный, но все-таки он быстрее, так как вы работаете уже с известной кодовой базой, у вас уже есть набор как автоматических unit-тестов, интеграционных тестов, так и ручных тест-кейсов.
Следует заметить, что какой бы вариант вы не выбрали, вам так или иначе придется отказаться от части фич вашего приложения в версии для Android Go. Это нормально. Google в своих приложениях для Go делает так же.
В итоге, реализовав модульную архитектуру, мы достаточно надежно решили наши проблемы с памятью и стали проходить тесты даже на девайсах с маленьким экраном, то есть уменьшили потребление памяти до 30 мегабайт.
Немного о мониторингах памяти, о том, как мы держим использование памяти под контролем. В первую очередь, мы настроили статические анализаторы, тот же Lint на ошибке в случаях, когда мы используем enum, создаем синтетические методы или используем неоптимизированные коллекции.
Дальше сложнее. Мы настроили автоматические интеграционные тесты, которые запускают Лончер на эмуляторах и через некоторое время снимают расход памяти. Если он сильно отличается от предыдущего билда, у нас срабатывают warnings и alerts. Тогда мы начинаем исследовать проблему и не публикуем изменения, которые увеличивают использование памяти Лончера.
Подведем итоги. Есть различные средства мониторинга памяти, измерения памяти для быстрой и эффективной работы. Лучше использовать их все, так как они обладают своими плюсами и минусами.
Радикальные решения с модульной архитектурой для нас оказались более надежными и эффективными. Мы жалеем, что не предприняли их сразу. Но те шаги, о которых я рассказывал в самом начале доклада, были не зря. Мы заметили, что основная версия приложения стала оптимально использовать память, работать быстрее. Спасибо.
Комментарии (4)

inoyakaigor
22.04.2019 13:59Вот бы ещё Я.Карты такие оптимизации провели

lopatoid
22.04.2019 19:07Я в целом не понимаю необходимости отделять Яндекс.Карты от Яндекс.Навигатора, у них возможности на 99% пересекаются (и там и там есть навигация, пробки и т.д., только навигатор ещё голосом маршрут говорит, а МЯК для пешеходов умеет строить, вот и все различия). Лучше бы сделали один большой и толстый комбайн со всеми возможностями (так как сейчас приходится держать 2 разных приложения на телефоне), а для слабых телефонов лёгкую версию с максимально обрезанными функциями.
grvelvet
А что думаете о недавней разработке huawei ark compiler? Она как призвана оптимизировать архитектуру приложения.