
Статьи на тему «ФП лучше» или «ООП лучше» напоминают дебаты, что же лучше для обеда, вилка или ложка. Традиционно джуны начинали с ложки, но кто-то очень авторитетный однажды поведал, что ест только мясо и использует вилку, поэтому зародилась новая мода — есть вилкой. Ей едят и каши, и супы, и даже умудряются лакать смузи. Интернет завален статьями, какие мы молодцы, что научились есть смузи вилкой и преодолели все грабли. Это и смешно и грустно, с одной стороны, даёт конкурентное преимущество бывалым ребятам, которые показывают сверхрезультаты просто игнорируя этот хайп, с другой, приходится переучивать коллег и сотрудников, вычищая из их головы нанесённый ветром мусор. В этой статье я постараюсь рассказать своё видение, которое не претендует на абсолютную истину, но очень хорошо работает на практике
Как принято в науке, начинём с определений. Классическое определение ООП включает в себя следование принципам наследования, инкапсуляции и полиморфизма. Но если у нас нет одного из этих составляющих, будет ли это ООП? И если нет, то что это будет?
Функциональное программирование, в вольной трактовке, рассматривает программу как математическую формулу. Формулы хорошо формализуются и при одинаковых входных данных возвращают одинаковые выходные. Вся программа состоит из подпрограмм, следующих тем же принципам. Чем это отличается от того же процедурного программирования? ФП активно использует чистые функции, в идеале вся программа должна быть чистой функцией. Чистые функции не имеют сайд-эффектов, их можно легко мемоизировать, легко тестировать и т.п… Можно сказать, в чистых функциях основная идея и преимущество ФП.
А теперь два вопроса:
— Можем ли мы использовать чистые функции в ООП?
— Можем ли мы привязывать функции к данным в ФП?
Ответ на оба из них утвердительный. Статические методы классов могут быть чистыми, даже методы экземпляров можно считать чистыми, если они не создают сайдэффектов и мы рассматриваем свойства экземпляра класса как параметры. Границы классических определений раздуваются и кто-то может быть не согласен, но на практике это просто работает. И такие методы формализуются и тестируются ничуть не хуже, чем классические чистые функции, написанные по всем канонам. Про привязку методов к данным чуть сложнее, накладывают ограничения используемый язык и библиотеки. Скажем, в JavaScript это делается элементарно, не уверен за Haskell и Erlang. Теперь самое интересное, что это даёт, и почему уже ООП поднял такой хайп лет 20-30 назад. Если вы пишете небольшую программу — вы можете писать как хотите, кроме вашего чувства прекрасного это ни на что не влияет. Когда вы создаёте действительно большую программу — возникает проблема сложности. Не вычислительной сложности, считаем, что здесь мы делаем всё хорошо, а воспринимаемой сложности. Скажем, у вас есть 50 000 строк кода, и все они целесообразны. Как их организовать так, чтобы не сойти в с ума (или не уходить с работы в 11 ночи)? Мы не можем уменьшить количество операций, но можем уменьшить число связей между ними (в этом нам и помогает инкапсуляция). Мы скрываем сложную реализацию за простым интерфейсом и дальше работаем только с интерфейсом. Например, интернет — жутко сложная штука, но большинству разработчиков достаточно знания протокола HTTP, чтобы выполнять свою работу
По практике, где работает преимущественно один подход, а где преимущественно другой? Когда я пишу бекенд на NodeJS, он сам собой как-то получается в функциональной парадигме. Почему? Потому что запрос на сервер — это по природе своей функция, с фиксированным инпутом и аутпутом. Функциональный подход ложится на серверные запросы очень естественно и код получается компактнее и гибче. Когда я создаю фронтенд для браузера — как правило лучше работает ООП, потому что кроме инпута и аутпута у нас есть поток пользовательских событий, а так же программные события, такие как начало и конец анимаций, запросы на сервер и т.п… Функциональный подход работал бы, если бы нужно было просто отрисовать статическую страничку без интерактива, при использовании ФП во фронтенде страдает либо интерактив, либо время разработки (по нашим замерам, раза в 3). Почему?
Любая парадигма программирования базируется на определённой модели реальности, а модель это всегда упрощение. В ФП модель накладывает больше ограничений на мир, поэтому её проще формализировать. По той же причине, когда она становится не релевантна условиям задачи — она начинает требовать больше костылей. Например, ФП на фронтенде решили проблему пользовательского ввода созданием массива событий (экшенов, привет redux). Но это является нерелевантной абстракцией, которая кроме того, что бьёт по производительности, здорово увеличивает время разработки. Таким подходом можно создать todo-лист, но на действительно больших проектах придётся разбивать лбом кирпичи, а потом писать победные статьи для таких же несчастных. Для сравнения, когда мы писали биржевой терминал (на vanilla js, естественно) с canvas, svg и обновлением несколько раз в секунду по websockets, в некоторых часто обновляемых компонентах мы не удаляли div'ы, а переиспользовали, так как их пересоздание — сравнительно дорогая операция в браузере (и это важно, если у вас действительно большое приложение). Если вы программируете на ФП на фронте — у вас даже такой мысли не возникнет, так как вы уже смирились с иммутабельностью (кстати, замечательная вещь для работы с многопоточностью, которой в JS не бывает), с тем, что каждый экшн проходит через каждый редьюссер и другим хламом. С другой стороны, на бекенде часто получается обходиться без классов совсем, так как там, как раз, можно избежать расходов на их создание, так как условия задач очень релевантны модели ФП. Но, в основной массе, Java и PHP разработчики как раз не спешат изучать ФП, в первых рядах фронтендеры, которым это реально меньше всего нужно. Как упражнение для ума — интересно конечно, только программы получаются г… но, а кому-то ими пользоваться. При том, что фронтенд — сравнительно молодой раздел IT, и своих нерешённых задач там на несколько поколений. Чем, казалось бы, не упражнение для ума?
Комментарии (243)
samsergey
02.05.2019 06:24+2Про вилку и ложку — это хорошо! А ведь есть ещё палочки и ножи всякие… Споры о том "что круче" парадоксальны в своей бесполезности. Ответ очевиден — лучше научиться владеть всеми приборами, и это не мешает иметь среди всех приборов любимый.
Например, я люблю считать на логарифмической линейке, хотя каждый день ею, конечно, не пользуюсь, для этого есть калькулятор. Но опыт работы с линейкой даёт зримое представление о преобразованиях, соответствующих вычислениям. Движения ползунка и бегунка превращают вычисления в буквальную манипуляцию: в преобразования руками, от которых приходит интуитивное геометрическое представление о поле чисел, имеющее под собой глубокое теоретико-групповое основание. Ответ не берётся из ниоткуда, а возникает в контексте масштаба и своеобразного "ландшафта" вычислений, так что проверка его правильности начинает согласовываться с интуицией. Это как знание города помогает понять, как тебя везёт таксист.
Подобные опыт и интуицию даёт работа в Лиспе и Хаскеле. С ними программа на JS или C# превращается не просто в набор рецептов, инструкций, а в те или иные вычислительные схемы или математические структуры с присущими им свойствами.
Но, полагаю, даже если жаркие дискуссии на темы "нужна ли программистам математика", "что круче: ФП или ООП" и т.п. постепенно отомрут, на смену им придёт что-то вроде: "кто круче, как программист: ИИ, корректно выполняющий ТЗ, или человек с его творчеством?". Мы уже видим начало этой эпохи, споря можно ли доверять машине управлять автомобилем на дороге.


VolCh
02.05.2019 07:33Обычно самая сложная часть бэкенда (хайлоад не трогаем) — это обработка запросов с сайд — эффектами. И хорошо если синхронных с точки зрения клиента(браузера), чётко имеющих вход и выход. А если попутно ставится задание в очередь, о выполнении которого клиент потом уведомляется? Никак тут моделью функции, пускай и не чистой, не обойтись.
scp1001
02.05.2019 07:55На мой взгляд обойтись всё-таки реально, особенно если отказаться от асинхронности.
А проверить выполнение задания клиент может и сам, даже без уведомлений.
Да, удобство снизится, зато безопасность и отказоустойчивость будут максимальны.
Во всяком случае, если не весь код можно сделать функциональным, то хоть его самую важную часть.
CMS, фреймворки, да и сами языки для веб-программирования содержат большое число различных функций, которые ничего не записывают и не сохраняют промежуточных значений.
Порой там находят опасные уязвимости, так что проверка формальными методами им бы не помешала.
C4ET4uK
02.05.2019 10:04+3На мой взгляд обойтись всё-таки реально, особенно если отказаться от асинхронности.
А проверить выполнение задания клиент может и сам, даже без уведомлений.
То есть после выполнения запроса клиент должен постоянно пинговать сервер «где там мой ответ?» А если клиентов сотни тысяч? Сервер только и будет делать, что «пинги» разгребать.
VolCh
02.05.2019 10:43Я ж говорю, самая важная часть бэкенда — обработка небезопасных (изменяющих состояние сервера) запросов. Не, можно какие-то монады прикрутить, чтобы и изменения были, и функционально было. Но стоит ли оно того, а если стоит, то кто платить будет?
sshikov
02.05.2019 11:46+1Вы как-то странно формулируете свое или-или. Монады — это не про «функционально или изменения». Это (в несколько примитивной форме) способ оформить изменения таким образом, чтобы их нельзя было сделать криво. Путем ограничения контекста, где их можно делать, лишь некоторыми функциями.
Возможно, и даже наверняка, это чего-то стоит. Но по большому счету разделение кода на чистые функции, и функции с побочным эффектами — это то, к чему так или иначе стоит стремиться.
Вот вы скажем имеете что-то против single responsibility principle? Посмотрите на это как на другую его сторону. Выделить побочные эффекты — это полезно. Вы можете всегда накодить тяп-ляп, и не сделать этого, точно также, как намешать в один метод или класс кучу функций. Так тоже можно, и так (увы) тоже работает.
Стоит ли оно того? Ну так это вам решать. Если сегодня нагавнокодили — это да, сегодня дешевле. А завтра? Ну вот и тут примерно так же.VolCh
02.05.2019 13:26+1Я не считаю, что класс с состоянием, геттерами(хезерами, изерами, ...) и мутаторами нарушает SRP. Ну и я их разделяю в подавляющем большинстве случаев: геттеры возвращают что-то, мутаторы — нет (типа функций и процедур в Паскаль). Ну есть ещё фабрики, которые создают что-то и возвращают созданное. Иногда мутаторы возвращают свой инстанс для удобства использования в цепочке (билдеры вские). Зачем тут монады и вообще ФП? Оно бывает удобно (в основном для filter/map/reduce инлайн), то зачем больше его внедрять не понимаю.
sshikov
02.05.2019 17:26+1>Я не считаю, что класс с состоянием, геттерами(хезерами, изерами, ...) и мутаторами нарушает SRP.
Я не совсем про это, вообще-то. Разве геттеры — это про композицию?
>Зачем тут монады и вообще ФП?
>Оно бывает удобно (в основном для filter/map/reduce инлайн), то зачем больше его внедрять не понимаю.
Монады, если еще чуть упростить — это способ безопасной композиции. filter/map/reduce — это один частный случай. Для остальных частных случаев и внедряют обычно остальное. Этих случаев немножко больше, чем допустим имеется на сегодня в вашем (или моем) наборе инструментов. Ну так это нормально — никто не заставляет внедрять все сразу. Скажем, аппликативные функторы — это неплохое описание процесса валидации исходных данных, и оно тоже бывает удобно.
Можно же и так зайти — зачем вам фабрики, если у вас есть билдеры всякие? Да в общем все затем же — чтобы к каждой задаче выбрать свой наиболее подходящий инструмент.VolCh
02.05.2019 17:45Переформулирую вопрос: почему вы считаете монады или ещё какие функциональные способы призводить сайд-эффекты (прежде всего изменения какого-то состояния) наиболее подходящими инструментами для этого? Чем созданные специально для инкапсулированного состояния объекты хуже?
sshikov
02.05.2019 18:13+2Я не говорил, что они наиболее подходящие. Я говорил, что они просто инструменты для композиции. И что вы скорее всего похожие инструменты все равно применяете, с теми же целями. Так что это был ответ на вопрос «зачем», без попытки сравнивать.
>Чем созданные специально для инкапсулированного состояния объекты хуже?
Не знаю, кто такие эти объекты. Давайте на простом примере, который вы точно знаете. List — это монада. Чем map лучше по сравнению с циклом for (a: list)? И по сравнению с циклом for (int i= 0; i< list.size(); i++)?
По-моему, ответ очевиден — тем что map это как раз безопасная композиция. Я гарантировано знаю, что применяя при помощи map функцию String->Integer к List я точно получу List, и ничего иного. Причем исходного размера. А применяя filter — получу List, возможно меньшего размера. И сколько бы я их не компоновал, я не смогу эти правила нарушить, независимо от того, какими типами мы тут в List<?> манипулируем. То есть, она еще и универсальная.
0xd34df00d
03.05.2019 01:02+1Я гарантировано знаю, что применяя при помощи map функцию String->Integer к List я точно получу List, и ничего иного.
Нет, не знаете. Ну, то есть, знаете, но этого недостаточно.
Гарантированно кем? Если сигнатурой, то терм
map f _ = []удовлетворяетвысказываниютипу(a -> b) -> List a -> List b.
Классического хаскеля не хватит, нужно притащить в formation rule возможность выражать типы
{ n : Int } -> (a -> b) -> Vect n a -> Vect n b. Что, впрочем, не помешает написать ерунду с идеейreplicate n . f (head vec), там уже надо будет доказывать теоремки типаmap id xs = xs.
А
filterтогда будет{n : Int} -> (a -> Bool) -> Vect n a -> (m ** Vect m a). Или-> (m ** Vect m a ** m `LEQ` n), если хочется больше строгости. Или ещё сложнее тип, если вы хотите поймать всю семантикуfilter(потому чтоfilter f _ = []снова удовлетворяет обоим этим типам). Или, опять же, теоремки.filter (const True) xs = xs,filter (const False) xs = [],all f (filter f xs) = True, всякое такое.samsergey
03.05.2019 03:07Самое главное — эти проверки и доказательства возможны, причём уже сейчас, так что глупо этим не пользоваться и спорить. Что подтверждает тезис, обозначенный в названии статьи.
0xd34df00d
03.05.2019 03:11+1Я обычно очень активно проповедую проверки и доказательства на уровне типов, но сегодня я надену другую шляпу, раз вы сказали «уже сейчас».
Какие языки у нас есть, в которых это возможно? Есть Coq, но это не язык программирования, программы из него экстрагируются куда-нибудь. Аналогично есть Agda, но это тоже не очень прикладной язык программирования (хотя стиль доказательств в ней мне ближе, чем в коке). Есть Idris, который язык, который вроде как всем идеален, ничего даже никуда не надо экстрагировать, но он пока ещё слишком молод и бажен. Написать формально верифицированную проверку строки на палиндромность на нём у меня не получилось, я упёрся в не очень разумное сообщение, что чё-то там нельзя матчить на LHS, и даже чтение исходников тайпчекера не помогло мне понять, что делать.
Sirikid
03.05.2019 03:43Не обязательно писать все на Coq, Agda, Idris, не все считают, и вполне обосновано, что для доказательств и кода должен использоватся один язык. Пример: верифицированная реализация Standard ML — CakeML. Написан на SML и HOL.
0xd34df00d
03.05.2019 04:04Ну, это уже скорее дело субъективное. Я лично сторонник proof-carrying code по разным соображениям (начиная хотя бы просто с изящества и простоты).
samsergey
03.05.2019 07:24+1Боюсь, что разочарую вас. Я имел в виду принципиальную возможность двигаться в этом направлении, если оставаться в рамках ФП. Пока же выкладки приходится делать "на бумажке". Но! Это возможно сделать. Я игрался с формальной верификацией некоего подмножества Java (практически, процедурным подмножеством, не выходящем за пределы Оберона) через триады Хоара. Очень быстро система неравенств становится неподъёмной, по моим ощущениям, экспоненциально. Инварианты циклов приходится писать самому, а это искусство и шаманство. После этого, возвращаясь к типам и индукции в ФП, с доказуемыми свойствами алгебраических структур, понимаешь, какой это кайф: надеть, наконец лыжи после того, как брел по пояс в мокром снегу. Но и лыжи пока приходится переставлять самому. Впрочем, пока ждем завтипов в Хаскеле, можно упражняться, отрабатывая технику на том что есть. Понятно же, что для того, чтобы написать грамотную рабочую спецификацию для автоматического верификатора, потребуется нехилая квалификация программиста. Но пока, насколько я вижу, именно ФП ведёт нас к возможности по-настоящему взлететь.
sshikov
03.05.2019 08:45Я смотрю на все это проще. Даже если заменив цикл на map я просто более ясно выразил в коде свои намерения — я уже получил практическое преимущество. Ну то есть код становится лучше, даже если мы не можем доказать его правильность, мы хотя бы все одинаково понимаем его функции. И если в следующем релизе или через пару лет никто его не сломает, потому что неверно понял назначение этого куска — это уже хорошо. А это так и будет.
sshikov
03.05.2019 08:39+1>Нет, не знаете. Ну, то есть, знаете, но этого недостаточно.
Ну, это смотря по сравнению с чем. По сравнению с циклом, результат которого вообще без детального анализа непонятен — очень даже знаю. Собственно, я хотел сказать простую вещь — что map ограничивает изменения одним элементом списка, не позволяя функции менять структуру списка каким-то непредсказуемым способом.
Понятно, что могут быть какие-то еще эффекты, скажем в Java функция String->Integer легко может выкинуть исключение — но это означает, что функция определена не на всем множестве входных значений. И в Java я не могу этого выразить, да. Что совершенно не отменяет вполне практических преимуществ map в этом случае.
samsergey
02.05.2019 13:12+3Функциональному подходу нет необходимости заполнять всё вокруг. Оно тяготеет к маленьким самодостаточным ортогональным блокам и если в императивной архитектуре такие блоки использовать, то они не помешают. В Фотране (куда уж императивнее!) с 80-х годов есть модификатор
pure, указывающий и программисту и компилятору, что определяемая функция чистая, что позволяет им делать определённые выводы как о коде функции, так и о коде, ее использующем.
Операционную систему не сделать чистой по определению, но с некоторыми задачами ФП справляется отлично. Например, на моём ноутбуке, а также на домашнем и на рабочем десктопах стоит NixOS (Linux-дистрибутив построенный вокруг функционального ленивого (а значит, чистого) пакетного менеджера Nix), c оконным менеджером XMonad. И мне нужна их декларативность при настройке и переносе решений с машины на машину. Но это не позволяет мне говорить, что ФП решает все проблемы. Но оно очень неплохо встраивается в императивные решения, поскольку предлагает… чистые функции :)balsoft
03.05.2019 12:34Я тоже пользуюсь NixOS, и при этом ещё до перехода на неё начал переписывать скипты, которые обычно писал на bash, на haskell, но только когда
main = interact myPureFunction. Тогда гораздо легче отлаживать ошибки в них, а ещё можно скомпилировать и получить некую прибавку к скорости и производительности.
А всё, что нельзя описать interact, лучше написать на классическом баше или перле — быстрее и читаемей.
0xd34df00d
03.05.2019 15:16А всё, что нельзя описать interact, лучше написать на классическом баше или перле — быстрее и читаемей.
Нет. Написание скриптов на хаскелеподобных языках даёт ещё ряд других ништяков.
Пора бы уже про это статейку наваять.
vassabi
03.05.2019 15:35о, обязательно напишите!
и еще чтобы с примерами «скриптов на хаскелеподобных языках» (мне действительно интересно).0xd34df00d
03.05.2019 17:27Там ещё свободные монады будут.
samsergey
03.05.2019 21:31Это, действительно, было бы очень полезно и для практики и для участия в холиварах с пруфами :)
Вопрос не по теме. Присмотрел для перевода материал по freer monad, но сижу, чешу в затылке, как корректно перевести на русский freer: "ёщё более свободные", "освобождённые"… есть ли устоявшийся термин?0xd34df00d
03.05.2019 21:41Неа, устоявшегося термина я не знаю.
Но я где-то видел, что operational monads и freer monads отождествляют.
samsergey
03.05.2019 22:12Ага! спасибо, посмотрю, operational переводится лучше, но они не тождественны, а связаны через
Coyoneda. Интересно, сам Олег Киселёв как их называет?

Source
02.05.2019 14:26Одна из основных задач программирования — это изоляция сайд-эффектов. Если у вас допустим идёт работа с БД, то можно сохранять данные по мере вычисления и размазать логику работы с БД по всей программе. А можно сначала подготовить все данные, а потом сохранить их все разом. Это можно делать в любой парадигме, но, применяя ООП, про это, к сожалению, часто забывают.
А если попутно ставится задание в очередь, о выполнении которого клиент потом уведомляется? Никак тут моделью функции, пускай и не чистой, не обойтись.
В чём проблема? Или вы представляете какую-то одну божественную функцию, которая делает всё? Это не так работает.
Постановка задания в очередь — это сайд-эффект, но тем не менее это никак не мешает вернуть какой-то ответ клиенту. А при выполнении задания, когда до него дойдёт очередь, уведомить клиента, например через веб-сокет.VolCh
02.05.2019 15:33Изоляция сайд-эффектов — это не задача программирования, это способ держать его результат под контролем.
Уведомление клиента через полчаса после возврата из функции — это тоже результат функции.

atamur
02.05.2019 09:42Когда код простой, можно и в процедурном стиле написать, то, что бэк на ноде выглядит функционально это скорее особенность ноды — в той же java обычный бэкэндщик будет вызывать блокирующие процедуры.
Что касается переиспользования дивов — реакт с его функциональным подходом давно так делает, работа же с ивентами без стримов быстро превращается в спагетти.
sshikov
02.05.2019 11:49+12>Java и PHP разработчики как раз не спешат изучать ФП
Хм. Вот люблю я, когда так вот обобщают. Видимо, это не Java разработчики когда-то довольно давно изобрели clojure — это хаскелисты прокрались в их ряды. Это не Java разработчики внедрили в Java 8 много всего разного от ФП, в частности, сделав функции наконец-то удобными в работе. Это все они, это их заговор, мы-то знаем, что настоящие Java разработчики не спешат изучать ФП.koldyr
02.05.2019 12:59Гипотетически они не "не спешат", они не могут. Порог входа высокий.
sshikov
02.05.2019 13:21Ну, всегда кто-то может, а кто-то нет. Это так было, есть и будет. Квалификация и опыт разные. Я про то и толкую, что Java разработчики тут вообще никаким боком. Есть задачи, где ФП нужнее или скажем ООП лучше подходит, есть разные люди, кто-то опытнее или способнее.

Ryppka
02.05.2019 13:34+1Мне кажется, все холивары ООП против ФП и т.д. из-за смешения объектно-ориентированного дизайна и ООП.
ИМХО, ООП — это расширение (даже просто синтаксический сахар) идей модульного программирования, а будут ли инстансы таких модулей «объектами» в смысле ОО дизайна — отдельный вопрос. Если экземпляр класса инкапсулирует состояние и ограничивает к нему доступ — это объект, а если нет, просто синтаксический артефакт. Классы, методы и остальное вторичны, реализовать суть: инкапсулировать состояние и ограничить возможность его изменения хоть через открытый интерфейс, хоть через передачу сообщений.
При чем тут ФП? Мне кажется, вообще не при чем. Речь идет о выборе языка реализации, а это совсем другой круг вопросов.
А вот разговор о подходах к дизайну — осмысленный! Что в конкретном случае продуктивнее — рассматривать систему, как набор функций или как совокупность объектов с состоянием, или как сочетание того и другого — в этом суть. И можно подобрать удобный инструмент. Иначе придется чесать правой рукой левое ухо и завинчивать гвозди отверткой.
Простите за занудство.VolCh
02.05.2019 15:37На русском не принято употрелять «объектно-ориентированный дизайн», употребляется «объектно-ориентированное проектирование», тоже ООП.
А многие холивары внутри ООП из-за смешения понятий «инкапсуляция» и «сокрытие». Инкапсуляция — это совмещение данных и методов, а сокрытие — ограничение работы с данными напрямую.
tmteam
03.05.2019 04:07+1ZanudaMode.On()
Инкапсуляция это «Упаковка» ответственности, а совмещение данных и методов это частный случай инкапсуляции в ООП. Например — можно инкапсулировать алгоритм в функцию (или в статик метод, если угодно). А сокрытие, это следствие инкапсуляции при хорошем дизайне.
ZanudaMode.Off()
Mabusius
02.05.2019 13:38-16Накину немного говна на вентилятор:
Мое определение ФП — непрофессиональное программирование, либо программирование для гуманитариев, которые не могут в абстрактное мышление. Какими бы чистыми там функции не были, когда их будет 100500 они в любом случае превратяться в черный ящик с макаронами.mikeus
02.05.2019 13:59+6Так не адекватно предмету, что вызывает улыбку.
Mabusius
02.05.2019 17:17-3Покажите мне хоть одну серьезную большую программу в ФП.
Пока что все топители за ФП, которых я встречал, были только одного типа. В институтах их сразу заставили писать в ООП, не объяснив зачем это все нужно, и теперь они вдруг видят, что можно писать без нудных классов, просто бери и фигач код напрямую и все типо работает. Особенно это характерно для фронтендов,которые гуманитарииу которых на странице два скрипта по 10 строчек и ООП им действительно толькко мешает.
Вакансии с условием «уметь в ФП» я тоже чтото не видел, что намекает.
Вы путаете ПОП и ФП. Изучить ФП очень трудно (на порядок труднее ООП) как раз по причине очень высокой абстракции…
dreesh, Ну и вот тем более! Если фронт-джун топит за ФП это говорит о том, что на самом деле он просто не хочет писать в ООП, а хочет писать код чистоганом. Никаким ФП тут на самом деле не пахнет.dreesh
02.05.2019 17:33+2Покажите мне хоть одну серьезную большую программу в ФП.
Компилятор Haskell GHC написан на Haskell :) Можете сами в этом убедится Glasgow Haskell Compiler

Virviil
05.05.2019 08:21Ещё добавим по вакансиям:
Согласно этой статье, топ зарплат у F#, Ocaml, Clojure, Groovy, Perl, Rust, Erlang, Scala, Go, Ruby. Вот десяточка.
Угадай, сколько из них ФП?
VolCh
02.05.2019 15:41+2Вот как раз унаследовать автомобиль от транспортного средства «гуманитарии» могут, а вот представить его как функцию от комплектующих, конвейера и времени — нет. :)
dreesh
02.05.2019 17:09+5Вы путаете ПОП и ФП. Изучить ФП очень трудно (на порядок труднее ООП) как раз по причине очень высокой абстракции…
0xd34df00d
03.05.2019 01:09+1Какой-то FUD про трудность.
Equational reasoning вполне естественно для человека, пока его не начинают портить. Монада — это просто любая ерунда, удовлетворяющая таким-то законам, вот такие-то очевидные три примера. Ну и так далее.

third112
02.05.2019 17:25+4Статьи на тему «ФП лучше» или «ООП лучше» напоминают дебаты, что же лучше для обеда, вилка или ложка.
Практика турпоходов показывает, что ложка лучше — все всегда берут ложки, но практически никто не берет с собой в поход вилку :)
Аналогично, ООП позволяет решать более широкий круг задач, если исходить из определения автора:
Функциональное программирование, в вольной трактовке, рассматривает программу как математическую формулу. Формулы хорошо формализуются и при одинаковых входных данных возвращают одинаковые выходные.
Добавим в код генерацию случайного числа или обработку события и при одинаковых входных данных не получим одинаковые выходных. Т.о., согласно данному определению, в ФП это недопустимо. А в ООП (и других парадигмах) допустимо. Или я не понял предложенного в статье определения?sshikov
02.05.2019 17:34>Или я не понял предложенного в статье определения?
Не совсем поняли. Впрочем, там сразу написано, что это вольная трактовка определения. На самом деле, прагматический подход к такому (написанию ГСЧ) состоит в том, чтобы выделить такие куски кода, которые являются чистыми, и остальные, которые либо взаимодействуют с внешним миром (IO), или не являются чистыми по другим причинам.
> обработку события и при одинаковых входных данных не получим одинаковые выходных
Это с чего бы? Если у вас есть состояние — то почему вы его не считаете частью входных данных? И дело не в том, допустимо это или нет. Дело в том, что выводы, которые вы (или компилятор) можете делать по поводу вот этого вот кода, они зависят от того, является ли кусок кода чистым.third112
02.05.2019 17:45Спасибо за разъяснение.
прагматический подход к такому (написанию ГСЧ) состоит в том, чтобы выделить такие куски кода
ГСЧ может быть и аппаратным, частью CPU. Тут выделить не получится и ФП не применимо (в вольной трактовке).
Если у вас есть состояние — то почему вы его не считаете частью входных данных?
Если событие происходит в ходе вычисления и влияет на него.sshikov
02.05.2019 18:21CPU это часть внешнего мира. То есть выделяется тоже (в хаскеле — в виде IO). В принципе, можно вольно считать, что весь доступный программе внешний мир — это часть входных данных (как оно в общем-то и есть). И он же — результат.
>Если событие происходит в ходе вычисления и влияет на него.
Все что влияет — это часть исходных данных, почему нет-то? Если обработка событий происходит по-разному — значит у вас есть какое-то состояние? В ФП его просто делают чуть более явным.third112
02.05.2019 19:16Все что влияет — это часть исходных данных, почему нет-то?
Данных, но не исходных, а текущих. Простейший пример: функция последовательными приближениями долго вычисляет результат, мне надоело ждать, нажал кнопочку, функция должна вернуть, что упела вычислить на этот момент.sshikov
02.05.2019 20:05>успела вычислить на этот момент.
Это такое вполне обычное состояние. Я повторюсь — ФП не означает, что у вас скажем не бывает состояния. Оно лишь означает, что вы такие случаи, когда вычисления от него зависят, явно выделяете. Если вы зависите от железа в реализации ГСЧ, то у вас и не может быть никакой абстракции чистой функции _в этом месте_, но вполне может быть в другом. И такое разделение само по себе полезно.
Вот такой простой пример, не совсем в тему — один мой коллега очень любит в один метод всунуть две вещи — чтение данных из файла, и работу с этими данными. Из чего вытекает нехорошее следствие — чтобы этот код протестировать, мы вынуждены в тестах заводить реальные файлы, и иметь дело с файловой системой, со всеми вытекающими. Если же мы разделим метод на две части, одну которая читает данные из файла, и вторую, которая обрабатывает, то вторая почти автоматически становится функцией, причем чистой. Ну то есть я это к тому, что и в совершенно не ФП случае выделение побочных эффектов в виде файлов вполне себе полезная штука.third112
02.05.2019 20:17Ну то есть я это к тому, что и в совершенно не ФП случае выделение побочных эффектов в виде файлов вполне себе полезная штука.
Полностью согласен. В моем примере вижу только одно решение:
повторять
список_аргументов := чистая_функция_очередное_приближение (список_аргументов);
до_той_поры_пока чистая_функция_точность_достигнута (список_аргументов)
или кнопочка_нажата;
Т.е. две чистых функции, но всю программу в виде читой функции не оформить.0xd34df00d
03.05.2019 01:14А это и не надо. Смысл ФП не в том, чтобы всё было чисто, а в том, чтобы явно видеть эффекты функций в типах.
Поэтому, кстати, всякие хаскелисты смотрят на функциональщиков из клана лисперов с некоторым удивлением.
dreesh
02.05.2019 18:48ГСЧ может быть и аппаратным, частью CPU
Даже в императивном языке придется к нему обращаться явно.third112
02.05.2019 19:38Чистые функции не имеют сайд-эффектов
Ok: никаких внешних переменных, видимых помимо аргументов, но в регистрах, стеке, где-то еще (зависит от железа и реализации) всегда есть мусор от предыдущих действий. Если мы будем читать этот мусор? М.б. не очень хороший ГСЧ, но одинаковых выходных не получим. Либо любой мусор признать аргументами (входными данными), но тогда список аргументов будет зависеть от устройства черного ящика — железа и реализации, т.е. никакой абстракции. Либо чистить весь мусор, что в общем виде м.б. проблематично. Либо везде прописывать уникальный код и тестировать все локальные переменные на неинициализированность. Как-то очень нечисто?dreesh
02.05.2019 20:41Вы забыли добавить в список деградацию структур процессора, памяти и остальных компонентов которые могут встретиться между ними и как то повлиять на результат вычислений…
third112
02.05.2019 20:45Говорим про исправный комп, всякие сбои и деградации не в счет.
dreesh
02.05.2019 21:47Либо везде прописывать уникальный код и тестировать все локальные переменные на неинициализированность. Как-то очень нечисто?
Ну как бы код после компиляции будет отличаться в зависимости от целевой системы разве нет?
На самом деле я уже не совсем понимаю предмет обсуждения. Как связанно явное обращение к ГСЧ и наличие мусора на стеке и регистрах
third112
02.05.2019 22:47Вы сказали:
Даже в императивном языке придется к нему [ГСЧ] обращаться явно.
ИМХО использование локальной переменной с неопределенным значением (в качестве случайного числа) — не явное обращение к ГСЧ. Такие обращения можно отследить в ходе исполнения, если во все переменые при запуске программы (и при вызове функции) будет записано уникальное значение, нпр., FFF… Так ловили баг в древних Паскалях. В некоторых ЯП всегда записано значение по умолчанию, нпр., ноль.

vitvakatu
03.05.2019 00:44Внезапно, доступ к неинициализированным переменным можно (и нужно) запретить. Либо всегда инициализировать их значением по умолчанию, как вы ниже заметили.
third112
03.05.2019 00:59Следовательно, возращаясь к сравнению статьи: ложка лучше вилки, т.к. ООП не требует дополнительных мер к неинициализированным переменным)
0xd34df00d
03.05.2019 01:14ФП не требует переменных, так что ещё непонятно, что лучше.
third112
03.05.2019 02:01ФП не требует переменных
Сможете доказать это утверждение строго математически: Теорема. Любую функцию можно реализовать без использования переменных?
И практически интересно: как спрограммировать в этом подходе решето Эратосфена?Sirikid
03.05.2019 02:06В общих чертах: переменную заменяете на аргумент функции, изменение переменной заменяете на рекурсивный вызов с новым значением.
third112
03.05.2019 02:14Т.е. числа Фибоначчи считаем по самой долгой рекурсии с 2 рекурсивными вызовами? :)
0xd34df00d
03.05.2019 02:31Зачем?
fibs = 1 : 1 : zipWith (+) fibs (tail fibs).
Стотысячное число в интерпретаторе вывело меньше чем за секунду. И никаких переменных.
Ryppka
04.05.2019 21:19Как по мне, так это все игра в бисер: переменные появляются ровно в том месте, где аргументы превращаются в параметры (подобно тому, как бордюр превращается в поребрик).
samsergey
03.05.2019 03:27Т.е. числа Фибоначчи считаем по самой долгой рекурсии с 2 рекурсивными вызовами? :)
Боже упаси! Рекурсивная функция не обязательно реализует рекурсивный процесс. если хочется организовать итерацию с "переменными"
aиb:
fib n = go 0 1 n where go a b n | n == 1 = a | n == 2 = b | otherwise = go b (a+b) (n-1)
что эквивалентно псевдокоду:
a = 0; b = 1 while (true) if (n == 1) return a if (n == 2) return b a,b = b,a+b; n--
Но в функциональном решении пропустить инициализацию "переменных" нельзя никак.
third112
03.05.2019 03:38Так нужны переменные a,b,n? Зачем слово «переменных» в кавычки ставить? ИМХО отлаживать проще, когда известно точное имя. Мне кажется, что переменные (пусть локальные) облегчают разработку.
samsergey
03.05.2019 04:12Это не переменные, поскольку они не могут измениться, оставаясь в рамках процесса, описываемого функцией. Изменения происходят только на входе-выходе. Одно из отличий, в частности, состоит в том, что, в функциональном коде нет понятия времени и изменение наших "переменных" происходит одновременно:
a,b = b,a+b, эквивалентное последовательности присвоений с буферомс = b; b = a+b; a = c.
Это не лучше и не хуже нормальных переменных, просто если проще описать вычислительный процесс итеративным, ФП этому не сильно помешает.third112
03.05.2019 05:17Понял. Может лучше сказать, что это переменные с особыми свойствами? ;) Так будет понятнее, чем «без переменных».
vitvakatu
03.05.2019 11:11+1В англоязычной литературе используется слово binding, что лучше отражает суть. В русскоязычной аналога не придумал и всегда называют переменными, даже если они не изменяются.
Sirikid
03.05.2019 15:08Это формальные параметры функции, первое и последнее опускают, если из контекста ясно какой именно параметр.
0xd34df00d
03.05.2019 02:33Сможете доказать это утверждение строго математически: Теорема. Любую функцию можно реализовать без использования переменных?
Сначала нужно будет строго определить понятие переменной.
В любом случае, SSA у компиляторов вполне обычных императивных языков как бы намекает.
И практически интересно: как спрограммировать в этом подходе решето Эратосфена?
На том же хаскеле в чистом коде оно спокойно делается.
third112
03.05.2019 02:46SSA у компиляторов вполне обычных императивных языков как бы намекает.
Вы хотите сказать, что ФП — синтаксический сахар?0xd34df00d
03.05.2019 02:48А почему не императивщина — синтаксический сахар? :)
К слову о решете, я тут добрался до ghci, и вот пример:
?> erato = [ n | n <- [2..], all (/= 0) [ n `mod` n' | n' <- [2 .. n - 1] ] ] ?> take 10 erato [2,3,5,7,11,13,17,19,23,29]
Снова никаких переменных. Не очень оптимально, правда, можно зареюзить
eratoвместо списка[2..n-1], но это потребует включать мозг, а я сегодня уже устал что-то.third112
03.05.2019 02:50Может взаимно? и это, и то — сахар? ;)
third112
03.05.2019 03:04ИМХО за деревьями не видно леса. Для вызова функции нужно пропихнуть что-то в стек, а на возврате выпихнуть — переменные в неявном виде. Выше Вы справедливо отметили:
Сначала нужно будет строго определить понятие переменной.
0xd34df00d
03.05.2019 03:08А тут функции нет. И вызова её нет. И стека тоже, в общем, нет.
Эту всю ерунду проще рассматривать на
fibsиз примера выше. В общем, там нет функций, типfibs— непосредственно список интов. Самfibsна самом деле рецепт по вычислениюfibs, который, конечно, где-то в глубине компилируется во вполне мутабельный код, но это деталь реализации, нас не сильно интересующая. Переменных в этом коде нет в том смысле, в котором нет изменения значения.third112
03.05.2019 03:25который, конечно, где-то в глубине компилируется во вполне мутабельный код, но это деталь реализации, нас не сильно интересующая
В данном случае интересующая: если деталь скрытая — то не значит, что ее нет. Посмотреть ассемблер — будут там переменные, изменения значения.samsergey
03.05.2019 03:52А вот тут в дело вступает то обстоятельство, что задача трансляции (компиляции) по природе своей функциональна. Объектный код полностью определяется исходным кодом и текущим окружением (входными параметрами). На этом стоит вся система сборки дистрибутивов типа configure >> make. Так что если абстракция функциональности и теряется на каком-то уровне, то это происходит всегда одинаково и решение можно, в конце концов, верифицировать, добившись герметичности абстракции на верхнем уровне. GHC это уже умеет. То есть, нас, действительно могут не сильно интересовать детали реализации, покуда компилятор не нарушает некоторых нужных нам законов и инвариантов.
third112
03.05.2019 04:09Ok. Готов допустить, что компилятор не нарушает. Но при этом не понял, чем эта абстракция удобнее, нпр., абстракции ООП? Тут нужно какое-то отдельное обоснование, т.к. может быть абстракция наоборот затрудняющая работу с кодом.
samsergey
03.05.2019 04:17Запросто! Это как в задаче интегрирования. Есть алгебраический подход, а есть геометрический, есть спектральный, а есть аналитический по теореме Коши, наконец, можно численно, но и там, можно Симпсоном, можно Гауссом. Когда как удобнее. Полезно владеть всем.
third112
03.05.2019 04:31Когда как удобнее. Полезно владеть всем.
Если я правильно понял, есть случаи, когда ФП удобнее ООП — можете привести пример?
И наоборот: когда ООП удобнее ФП — а пример такого случая?
0xd34df00d
03.05.2019 04:24+1А она не удобнее, они вообще ортогональны.
Вполне можно строить ООП на иммутабельных данных (см. того же Пирса). И обратно, можно иметь чистый функциональный код без мутабельных переменных, который за счёт, например, линейных типов будет разворачиваться в императивный инплейс-код — см. язык Clean, ну или Idris:
umap : (a -> b) -> UList a -> UList b umap f [] = [] umap f (x :: xs) = f x :: umap f xs
«In the second clause, xs is a value of a unique type, and only appears once on the right hand side, so this clause is valid. Not only that, since we know there can be no other reference to the UList a argument, we can reuse its space for building the result! The compiler is aware of this, and compiles this definition to an in-place update of the list.» (курсив наш)
0xd34df00d
03.05.2019 04:06Вы не сможете эту изменчивость наблюдать средствами, предоставляемыми языком. Дальше уже начинается философия, но, ИМХО, именно это и значит, что переменных в вашем языке нет. А что там на уровне ассемблера, микрокода или волновых функций — неважно.
third112
03.05.2019 04:21ИМХО это как раз плохо, когда нет переменных. Что-то скрыть не самоцель, а цель облегчить понимание и отладку. Или м.б. вместо отладки на высоком уровне исходного кода лезть в объектный код? Выше я привел примеры, в которых нельзя применить ФП — это случайные значения переменной и события. Мы ушли в сторону, выясняя, что можно без переменных. Но исходный пункт остался: видимо есть задачи, которые решаются ООП, но не ФП.
0xd34df00d
03.05.2019 04:30+1Что-то скрыть не самоцель, а цель облегчить понимание и отладку. Или м.б. вместо отладки на высоком уровне исходного кода лезть в объектный код?
А почему отсутствие переменных отменяет отладку? :)
Другое дело, что она действительно не очень нужна. Я вот прямо сейчас параллельно на другом рабочем столе читаю книгу Окасаки и делаю упражнения в нём, тут как раз параграф про красно-чёрные деревья. Я набросал своё дерево, набросал простенький предикат для проверки инварианта, что у красных нод нет красных детей
data Tree a = Empty | Node { color :: Color , left :: Tree a , elt :: a , right :: Tree a } deriving (Eq, Show) noRedRedPath :: Tree a -> Bool noRedRedPath Empty = True noRedRedPath n@Node { left, right } = case color n of B -> recCond R -> recCond && maybeColor left /= Just R && maybeColor right /= Just R where maybeColor Node { color } = Just color maybeColor Empty = Nothing recCond = noRedRedPath left && noRedRedPath right
и тест для него
describe "RB trees general properties" $ do ... it "does not have red-red path" $ property $ \(lst :: [Int]) -> RB.noRedRedPath (foldr RB.insert RB.Empty lst)
Quickcheck мне сказал входные данные, на которых валится тест:
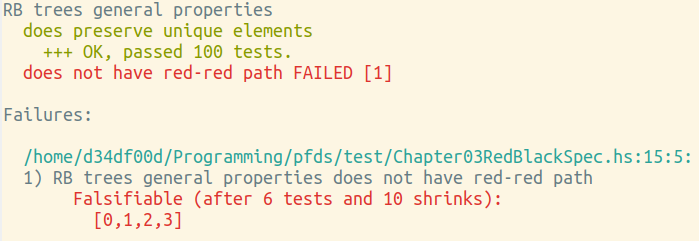
Мне больше не нужно ничего дебажить. Мне нужно вдумчиво смотреть на insert и balance, чтобы попытаться понять, какой случай я упустил. Зачем мне бегать дебаггером, какую новую информацию он мне даст?
Выше я привел примеры, в которых нельзя применить ФП — это случайные значения переменной и события.
Э, ну можно же. Модификация состояния (в том числе состояния ГПСЧ) — это эффект, а эффект моделируется монадой.
third112
03.05.2019 04:49Мне нужно вдумчиво смотреть на insert и balance, чтобы попытаться понять, какой случай я упустил. Зачем мне бегать дебаггером, какую новую информацию он мне даст?
Это уже не теория, а практика. Действительно в простых учебных задачах бывает достаточно просто хорошо подумать над результатами тестов. Но для более сложных отладчики себя зарекомендовали. Факт, что чем больше всяких возможностей для отладки — тем лучше. Дело не только в том чтобы найти баг, а чтобы найти его достаточно быстро.
Э, ну можно же. Модификация состояния (в том числе состояния ГПСЧ) — это эффект, а эффект моделируется монадой.
я не спорю: многое возможно. Но люди склонны совершать ошибки. Одна из типовых ошибок — непредсказуемое поведение функции.0xd34df00d
03.05.2019 04:52Но для более сложных отладчики себя зарекомендовали. Факт, что чем больше всяких возможностей для отладки — тем лучше. Дело не только в том чтобы найти баг, а чтобы найти его достаточно быстро.
Компилятор для DSL — достаточно крупный проект?
Там подход с разбитием на мелкие тесты для разных юзкейсов и отладку через этакую дифференциальную диагностику ну просто отличнейше себя зарекомендовал. В моём опыте, по крайней мере. Отладчик ни разу не захотелось брать в руки.
Одна из типовых ошибок — непредсказуемое поведение функции.
И чистота системы типов отлично от этого защищает.
third112
03.05.2019 04:59Компилятор для DSL — достаточно крупный проект?
Наверняка крупный, но у каждого проекта своя специфика. Для другого может не подойти.
И чистота системы типов отлично от этого защищает.
Как защищает в случае неинициализированных переменных?0xd34df00d
03.05.2019 05:13Наверняка крупный, но у каждого проекта своя специфика. Для другого может не подойти.
Ну, у меня пока что такого опыта не было.
Как защищает в случае неинициализированных переменных?
Что-то я запутался. Мы о случайных величинах или об этом?
third112
03.05.2019 05:21-1Мы о случайных величинах или об этом?
В примере в качестве случайной величины я предложил использовать неинициализированную переменную. На практике кто-то может ее использовать и по ошибке. Как защититься от такой ошибки?0xd34df00d
03.05.2019 15:19В примере в качестве случайной величины я предложил использовать неинициализированную переменную.
В каком языке? В C++ (да и в С, насколько я знаю) это UB, например, так что ваше предложение я, пожалуй, отвергну.
А значит, все использования неинициализированных переменных ошибочны, и, как я понимаю, вопрос снимается сам собой (на самом деле это не так, и ошибочны не все, но играть в C++ language lawyer'а мне не хочется, это занудно и не очень важно для данной дискуссии).
third112
03.05.2019 15:32В каком языке?
ОО Паскаль (Дельфи-7).0xd34df00d
03.05.2019 15:33Там что, разрешают читать из неинициализированных переменных и выбирать на основе этого бранчи? И значение этой переменной действительно не определено?
vitvakatu
03.05.2019 11:17Мы же только что убедились, что в чистых функциональных языках переменных вообще нет — следовательно неинициализированных переменных быть не может :)
third112
03.05.2019 15:05Тут путаница. Я понял, что глобальные переменные в ФП запрещены. А локальные? Могу в функции определить и использовать переменную? Аргументы функции — переменные? Результат — переменная?
Sirikid
03.05.2019 15:11Вы понимаете разницу между переменной и параметром? Так вот, первых в чистых языках a la Haskell вообще нет.
third112
03.05.2019 15:29Вы понимаете разницу между переменной и параметром?
Понимаю. В Паскале, нпр.:
function sinFi (fi :real) :real; begin Result := sin(fi); end;
Могу вызвать из другой функции:
function f2 :real; begin Result := sinFi(pi/2); end;
И так:
function f2(fi :real) :real; var temp: real; // локальная переменная begin temp := sinFi(fi); if temp>0.5 then Result := temp*2 else Result := temp*3; end;
Можно такое в рамках ФП. Или, чтобы избежать переменной, я должен сделать:
function f2(fi :real) :real; begin if sinFi(fi)>0.5 then Result := sinFi(fi)*2 else Result := sinFi(fi)*3; end;
Result — переменная?0xd34df00d
03.05.2019 15:32Функциональщик бы написал что-то вроде
f2 fi | sin fi > 0.5 = sin fi * 2 | otherwise = sin fi * 3
или
f2 fi | s > 0.5 = s * 2 | otherwise = s * 3 where s = sin fi
или
f2 fi = s * if s > 0.5 then 2 else 3 where s = sin fi
sособо не отличается от вашегоtemp.third112
03.05.2019 15:44s, как и мой temp — переменная? Значит переменные допустимы в ФП? Сколько раз вызывается sinFi в каждом примере?
0xd34df00d
03.05.2019 15:47Нет, не переменная, она ж не меняется.
Сколько раз — зависит. Я бы ожидал, что с оптимизациями компилятор первые два варианта свернет в третий, во всех случаях давая вам один вызов.third112
03.05.2019 16:05Нет, не переменная, она ж не меняется.
Как не меняется? Я так понял, что до выполнения оператора
where s = sin fi
s не определена, а после равна значению синуса аргумента fi.0xd34df00d
03.05.2019 16:07Это не оператор, это уравнение, типа, видишь слово s — подставь определение из правой части.
third112
03.05.2019 16:38видишь слово s — подставь определение из правой части.
«подставь» — это команда (что в программировании называется оператором). Для ее выполнения, надо не только подставить значение синуса, но и вычислить его сначала. Или тут только подстановка, как в препроцессорах? Но тогда синус будет вычислятся 2 раза, а не один.0xd34df00d
03.05.2019 16:53«подставь» — это команда (что в программировании называется оператором)
Нет, это не команда для компьютера, это одна из возможностей интерпретации подобной записи. Впрочем, то, что написал Sirikid рядом, ещё лучше и ближе к тому, как оно на самом деле работает.
А дальше играет роль стратегия вычислений.
В хаскеле нестрогие вычисления, поэтому на самом деле в обе точки использования
sбудет подставлена ссылка на соответствующий thunk — что-то вроде микрофункции, его вычисляющей, которая при первом вычислении заменит себя на вычисленное значение (этакая мемоизация).
Поэтому, например, в коде типа
f2 phi | phi < 0.1 = 0 | otherwise = s * if s < 0.5 then 2 else 3 where s = sin phi
sбудет вычислена от нуля до одного раза.
Идрис, с другой стороны, строгий язык. Там все байндинги будут вычисляться сразу, но состояния неинициализированности у них тоже не будет — у вас просто синтаксически не получится обратиться к соответствующим байндингам, пока они не будут вычислены.
third112
03.05.2019 17:32Т.е. переменные заменяются мемоизацией. Насколько это эффективно в плане времени исполнения? В сложных случаях можно опасаться, что компилятор не так поймет? И если не так, то сложно ли отловить такой баг?
0xd34df00d
03.05.2019 17:44Т.е. переменные заменяются мемоизацией.
При нестрогой стратегии вычислений. И не то что заменяются, просто это один из вариантов реализации байндингов.
Насколько это эффективно в плане времени исполнения?
Зависит. Матричные числодробилки так писать не надо (а надо взять, скажем, repa), а в иных случаях это может быть даже эффективнее — за счёт ленивости ненужные части не вычисляются (что, кстати, ещё и полезно для композабельности).
В сложных случаях можно опасаться, что компилятор не так поймет?
В третьем варианте трансляции вашего примера компилятору нечего не понимать (с точностью до багов в компиляторе, но это в любом языке может быть).
В предыдущих вариантах есть расчёт на то, что компилятор поймёт, что sin phi вычисляется во всех ветках, поэтому он имеет право в сгенерированном коде вычислить sin phi один раз на входе в функцию, сделать код строгим и не генерировать никаких thunk'ов. Ну, то есть, типичный common subexpression elimination, несколько осложнённый тем фактом, что надо сохранять семантику программы с точки зрения ленивости (и именно программы — если функция f2 из моего предыдущего комментария везде инлайнится, и компилятор видит, что phi везде >= 0.1, то он имеет право снова добавить строгости и сразу вычислять sin phi на входе в функцию).
Sirikid
03.05.2019 15:55+2s — "локальный" параметр, от формального параметра функции отличается тем, что уже связан со значением, т. е. он сам себе и формальный, и фактический. Тот самый binding из комментария ниже. Можно представить выражение
f x = s * if s > 0.5 then 2 else 3 where s = sin x
в виде
f x = (\s -> s * if s > 0.5 then 2 else 3) sin x
khim
03.05.2019 05:48Но для более сложных отладчики себя зарекомендовали.
У них очень узкая ниша, на самом деле. В Гугле, например, сняли разработчиков с GDB, когда выяснилось, что им пользуется ежедневно, в среднем, менее 5% разработчиков.
Вряд ли разработку google.com можно назвать «маленькой учебной задачей».
VolCh
03.05.2019 07:39В подавляющем большинстве случаев (вроде есть какие-то лисп-процессоры функциональные) среда исполнения императивна. Императивные языки, да, сахар, но над императивными машкодами.

wataru
03.05.2019 12:07Это не решето Эратосфена. Тут наивный метод перебора всех чисел и проверки делимости на уже найденные простые числа. Даже после переиспользования erato вместо списка всех меньших чисел.
Для поиска всех простых чисел до n этот алгоритм будет работать O(n^2 / log n). Может, если там соптимизированно "all /= 0" и не проверяет после первого несовпадения, тогда можно еще на log n поделить. Когда как честное решето эратосфена будет O(n log log n), что намного эффективнее.
Да, наивному решету надо в log n раз больше памяти, но это лечится если ввести сегментацию — тогда оно будет занимать ассимптотически столько же памяти, что и ваш алгоритм. А если надо хранить не все простые, а, скажем, найти k-ое, то сегментированное решето потребует гораздо меньше памяти.
third112
03.05.2019 15:11Да, наивному решету надо в log n раз больше памяти, но это лечится если ввести сегментацию — тогда оно будет занимать ассимптотически столько же памяти, что и ваш алгоритм. А если надо хранить не все простые
Т.е. что-то надо хранить. Хранят в переменных (явных или неявных), но при этом постоянно говорят, что
в чистых функциональных языках переменных вообще нет
Так есть или нет? ИМХО если что-то хранить, то хранится в переменной. А иначе напоминает двоемыслие.wataru
03.05.2019 15:50Просто эти переменные все с модификатором const и как бы неявные — в виде параметров у функций. Вызвали функцию — создали переменные.
Хотите к счетчику что-то прибавить — вызывайте рекурсивно функцию с +1 в параметре.
С одной стороны это создает кучу сложностей и ограничений. С другой убирает сайд-эффекты.
third112
03.05.2019 16:21С одной стороны это создает кучу сложностей и ограничений. С другой убирает сайд-эффекты.
ИМХО в процедурном программировании сайд-эффекты убираются простыми ограничениями на глобальные переменные. Там это вопрос стиля. В ООП у каждого класса есть свойства и переменные, которые видны всем методам класса. Можно сказть, что там сайд-эффекты сознательно допустимы внутри класса и его потомков. И это бывает удобно. В ООП возможен плохой стиль, но ИМХО это не причина абстрактного ужаса перед сайд-эффектами. Не слишком ли их боятся?0xd34df00d
03.05.2019 16:30У меня слишком много травматического опыта с отладкой императивных ООП-приложений, чтобы таки бояться.
third112
03.05.2019 16:43А ФП — серебряная пуля?
0xd34df00d
03.05.2019 16:53Нет, но травматического опыта у меня с ним сильно меньше.
third112
03.05.2019 18:59Подобный травматический опыт может зависеть от многих причин, поэтому высока вероятность ошибочных выводов на основе такого опыта.
samsergey
03.05.2019 22:06+1Мне импонирует ваше стремление разобраться! Переменное состояние и сайд-эффекты в ФП исключены вовсе не ради инкапсуляции, вернее не только ради неё. Если мы готовы принять это ограничение, то становятся возможными:
- Однозначный вывод типов по Хиндли-Милнеру, существенно более полезный, чем
varилиauto, поскольку он проникает на все уровни программы от сигнатуры функции до самых мелких её деталей. И это не для экономии нажатий клавиш при определении функции, а для настоящей и осознанной типобезопасности. Компилятор в чистых типизированных ФЯП не тестировщик и не надзиратель, а друг и помощник, подсказывающий и объясняющий программисту даже не в чём состоит ошибка, а что ему писать дальше. Это не автодополнение IDE доступных полей и методов, а подсказка сложных и очень нетривиальных решений, которые потом могут превратиться в научные разработки. Это круто и от этого уже трудно отказаться! - "Типо-ориентированное программирование", несколько более широкое, чем data-driven design, поскольку на первый план выступают алгебраические свойства типов (и функций над ними), не нарушаемые изменением состояния.
- Внятная и доказуемая денотационная семантика, equational reasoning, настоящее unit-тестирование с автогенерацией тестов и property-based тестированием (Quickcheck появился в Haskell и только потом разошёлся по языкам).
- Выбор стратегии вычислений (строгая/ленивая), в чистом ФП не меняющая результат, а влияющая лишь на эффективность программы и на способы её декомпозиции (в ленивом Haskell декомпозиция вкусна до безобразия, одни только гиломормизмы и fusion чего стоят!).
- Принципиальное отсутствие в многопоточности гонок, и проблем с общими ресурсами.
- Наконец, осознанная свобода в выборе и конструировании семантики позволяет легко (правда, легко, монады не сложнее какого-нибуть преобразования Фурье или Лапласа, хоть и "ломают" по началу мозг) эмулировать и переменное состояние и эффекты, но со всеми перечисленными выше плюшками!
Отсутствие сайд-эффектов и переменных не цель ФП, а средство достижения гораздо больших целей. И, более того, если надо, я всегда могу их себе завести, но они гарантированно будут локальными и с тонко настраиваемой семантикой.
third112
04.05.2019 01:22Мне импонирует ваше стремление разобраться!
Спасибо Вам и всем, кто помогает мне разобраться! :)
Со своей стороны, в первую очередь хочу отметить, что мне импонирует дружелюбная атмосфера, сложившаяся в данном обсуждении. До этой статьи я периодически читал про ФП, у меня постепенно накапливались недоуменные вопросы, которые откладывал «на потом». И вот этот «потом» настал, и за пару дней узнал больше, чем раньше за гораздо более длительный срок. Поэтому надеюсь, что и в дальнейшем обсуждении сообщество проявит терпение, отвечая на дальнейшие, может, не самые удобные вопросы — у меня их еще много)
Пользуясь случаем, предложу идею, м.б. кого заинтересует: тут много наговорили, отвечая на вопросы чайника в ФП (т.е. меня). Предполагаю, что я не оригинален, и что у других ФП-чайников есть похожие вопросы, но не все они будут читать это объемное обсуждение. Может, кто из экспертов-знатоков ФП переформатирует это обсуждение в FAQ и опубликует в виде статьи на Хабре? Уверен, что такая публикация будет очень актуальна.
Хотя в данный момент я далек от того, чтобы перейти на ФП, но вижу, что здесь очень интересная философия и практика, есть над чем подумать. В любом случае любому программисту очень полезно ознакомиться с общими принципами для расширения кругозора. Думаю, что если и не перейду на ФП, это довольно мимолетное знакомство повлияет на мой стиль написания программ.
Теперь позвольте задать очередную порцию вопросов.
для настоящей и осознанной типобезопасности
Не понимаю, как вывод типов повышает типобезопасность. В вики читаю:
опустить тип идентификатора в определении с инициализацией (см. синтаксический сахар). Например:
ИМХО действительно сахар.
var s = «Hello, world!»; // Тип переменной s (от string) выведен из инициализатора
Это не автодополнение IDE доступных полей и методов, а подсказка сложных и очень нетривиальных решений, которые потом могут превратиться в научные разработки.
Это не преувеличение? Как это можно превратить в научную разработку? Есть пример?
«Типо-ориентированное программирование»
Не нашел в гугле и вики внятных определений. Можно пояснение и ссылку?
Принципиальное отсутствие в многопоточности гонок, и проблем с общими ресурсами
За счет чего отсутствие?
samsergey
04.05.2019 13:10+1Спасибо, это, действительно, многовато для комментария. Пройдёмся по вашим вопросам.
- Вывод типов в ФП распространяется не только на объявление параметров/констант, но и на типы всех выражений и функций. И работает он в "обе стороны", то есть, я могу явно написать тип определяемой функции, а потом спросить у компилятора каким должен быть тип того или иного (любого) подвыражения в её теле, используя т.н. дырки, (holes). Это лучше показать, но не в комментарии. С другой стороны, я могу написать тело функции, не указывая вообще ни одного типа, и компилятор постарается вывести самый общий полиморфный тип для неё (в статике, на этапе компиляции). Если не выйдет, он скажет что именно ему не понятно, и это будет либо моя ошибка, либо неоднозначность задачи, требующая явного сужения типа, что тоже полезно и открывает глаза на программу. Особенно приятно общаться с компиляторами PureScript или Elm, но и ghc в последние годы становится более дружелюбным (или это я учусь понимать его?). А вот работа с литералами-константами (из примера с
var), как раз часто требует уточнения, поскольку в Haskell выражение5может означать либо целое число, либо число с плавающей точкой, либо, вообще, какой-нибудь тип-обертку типаSumилиMax. Компилятор очень постарается понять из контекста, что же это такое, но программист может его здорово запутать :) - Я не преувеличил роль вывода типов в ФП в серьёзных исследованиях. Многие наши замечательные современники — асы ФП, создавшие целые концепции, вроде линз, кондуитов, или свободных монад, активно используют интерпретатор GHCi, как основной инструмент, получая от него ответы на вопросы (скажем, какой функтор нужно подставить в линзу, чтобы превратить его в геттер или сеттер) и целые доказательства (см. изоморфизм Карри-Ховарда) для своих идей, о чём с удовольствием рассказывают на конференциях и в блогах.
- Я нарочно взял словосочетание «типо-ориентированное программирование» в кавычки, это не официальный термин. Типы в ФП (типизированном) это нечто большее чем "множество допустимых значений, внутреннее представление данных и возможные операции над ними". Это основа дизайна программ, предоставляющая связи между типами и законы (в математическом смысле, а не в инженерном) им присущие. Типы параметризуют друг друга и сами образуют более общую структуру Kinds, всё это выводит работу с ними на уровень настоящего исчисления. Иногда это чертовски сложно и нетривиально, иногда чертовски красиво, но вот что для меня привлекательно: тут остаётся мало места традициям, моде и вкусовщине, присущим нашему делу. Вместо них теоремы, анализ и строгие выводы, которые можно использовать, спустя десятилетия и они не устаревают, а со временем получают развитие, как, например получилось с линейными типами.
- На последний вопрос отвечу аккуратно: отсутствие изменяемого состояния (концептуальное) заставляет писать код, в котором проблем с параллелизмом и конкурированием существенно меньше. Я не стану утверждать рекламным голосом, что в рамках ФП параллелизм станет лёгким и приятным как никогда, и теперь с этим справится даже ваша мама. Сложности всё равно остаются, но они, скажем так, иного уровня, поприятнее, что-ли.
third112
04.05.2019 15:43Когда-то виртовский Паскаль и первые стандарты языка критиковали за то, что невозможно написать функцию умножения двух матриц в общем виде. Матрицы 5х5 — один тип, 6х6 — уже другой тип. Турбо Паскаль 3 и выше, и другие компиляторы имели расширения для обхода этой проблемы. Правда расширения не всегда удобные. Как в ФП решают эту проблему?
Это основа дизайна программ, предоставляющая связи между типами и законы (в математическом смысле, а не в инженерном) им присущие.
Не все матрицы можно умножать — размеры должны соответствовать. Можно в ФП задать такое правило на уровне типов?vassabi
04.05.2019 16:21Не все матрицы можно умножать — размеры должны соответствовать. Можно в ФП задать такое правило на уровне типов?
конечно можно (простейший пример)0xd34df00d
04.05.2019 18:10Хаскель не лучший язык, чтобы на нём демонстрировать завтипы.
Лучше
multiply : { n, m, k : Nat} -> Mat a n m -> Mat a m k -> Mat a n k
будет типом искомой функции. Можно обратить внимание, что обычные натуральные числа из уровня термов вполне себе работают на уровне типов.
И ещё очень важно, что
n, m, kмогут быть и неизвестны до этапа исполнения (в отличие от, скажем, сиплюсплюсных шаблонов).
0xd34df00d
04.05.2019 18:11Зависит от ФП. В классическом хаскеле — увы, нет, его система типов для этого слишком сложна. В современном, реализованном в ghc — да, можно, но довольно уродливо. Лучше сразу брать языки типа Agda или Idris. Я там чуть ниже пример привёл.
- Вывод типов в ФП распространяется не только на объявление параметров/констант, но и на типы всех выражений и функций. И работает он в "обе стороны", то есть, я могу явно написать тип определяемой функции, а потом спросить у компилятора каким должен быть тип того или иного (любого) подвыражения в её теле, используя т.н. дырки, (holes). Это лучше показать, но не в комментарии. С другой стороны, я могу написать тело функции, не указывая вообще ни одного типа, и компилятор постарается вывести самый общий полиморфный тип для неё (в статике, на этапе компиляции). Если не выйдет, он скажет что именно ему не понятно, и это будет либо моя ошибка, либо неоднозначность задачи, требующая явного сужения типа, что тоже полезно и открывает глаза на программу. Особенно приятно общаться с компиляторами PureScript или Elm, но и ghc в последние годы становится более дружелюбным (или это я учусь понимать его?). А вот работа с литералами-константами (из примера с
0xd34df00d
04.05.2019 18:08+1Не нашел в гугле и вики внятных определений. Можно пояснение и ссылку?
Можно почитать, например, Type-driven development with Idris.
Как пример для затравки и этакого экстремального случая — чтобы написать функцию для применения данной функции к каждому элементу вектора, вам достаточно написать сигнатуру функции типа
myfmap : (a -> b) -> Vect n a -> Vect n b, чтобы потом тайпчекер с небольшой вашей помощью реализовал за вас её тело за 4 команды:
- Generate definition. Тайпчекер за вас пишет черновик тела функции:
myfmap : (a -> b) -> Vect n a -> Vect n b myfmap f xs = ?myfmap_rhs - Вектор — индуктивная структура данных, поэтому разумно воспользоваться разбором случаев по структуре вектора. Наводим курсор на xs, в редакторе выполняем команду case split, тайпчекер за нас пишет
myfmap : (a -> b) -> Vect n a -> Vect n b myfmap f [] = ?myfmap_rhs_1 myfmap f (x :: xs) = ?myfmap_rhs_2 - Теперь рассмотрим каждый из случаев. Они довольно простые, поэтому тайпчекер может найти правильный терм справа от знака равно для каждого из случаев. Наводим на
?myfmap_rhs_1и даём команду obvious proof search. Получаем
myfmap : (a -> b) -> Vect n a -> Vect n b myfmap f [] = [] myfmap f (x :: xs) = ?myfmap_rhs_2 - Повторяем со второй веткой. Получаем
myfmap : (a -> b) -> Vect n a -> Vect n b myfmap f [] = [] myfmap f (x :: xs) = f x :: myfmap f xs
За счет чего отсутствие?
За счёт примитивов типа того же STM и проверок компилятором, что вы не делаете того, что не нужно делать.
- Generate definition. Тайпчекер за вас пишет черновик тела функции:
- Однозначный вывод типов по Хиндли-Милнеру, существенно более полезный, чем
VolCh
04.05.2019 22:28Я бы сказал, что в ООП сайд-эффекты не просто допустимы, а под них оно и было создано: только в вырожденных случаях типа DTO у методов класса нет сайд-эффектов, в остальных они должны быть. Но эти сайд-эффекты должны быть ограничены объектом в общем случае или заключаться в вызовах методов зависимостей.
0xd34df00d
03.05.2019 15:29Да, в однострочник с ленивостью и узлом полноценное решето у меня засунуть не получилось. Я что-то тупанул и думал, что переиспользование erato даст ту же сложность, но да, вы очевидно правы, спасибо, что поправили!
Тогда придётся делать рекурсивную функцию, которая берёт какой-нибудь
Data.Arrayили тупо список (хотя тут чуть сложнее анализировать сложность в ленивом контексте) и из него что-нибудь вычёркивает. Но, в любом случае, снова никаких переменных.wataru
03.05.2019 16:00+1Тогда придётся делать рекурсивную функцию, которая берёт какой-нибудь Data.Array или тупо список (хотя тут чуть сложнее анализировать сложность в ленивом контексте) и из него что-нибудь вычёркивает.
Но, в любом случае, снова никаких переменных.Ох и сомневаюсь я что тут что-то вообще хоть сколько-нибудь читаемое получится.
Вот в чем проблема-то, решето — по природе своей изменение массива по заданному правилу. Любая его реализация в чистом ФП будет костылем и эмулированием всех переменных и циклов, но через функции.
Как я уже писал, представьте что у вас все переменные const, и при изменении просто передавайте новые значения как параметры функции. Это и есть подход ФП.
Формально — никаких переменных и сайд эффектов. На практике код будет таким сложным, что это просто выдумывание себе проблем на ровном месте.
Для многих задач в этой парадигме можно сделать очень простой и понятный код. Для других задач чистое ФП все-таки не так хорошо подходит.
third112
03.05.2019 16:46Для многих задач в этой парадигме можно сделать очень простой и понятный код. Для других задач чистое ФП все-таки не так хорошо подходит.
Спасибо. Что-то подобное я и ожидал услышать!
0xd34df00d
03.05.2019 17:25Ох и сомневаюсь я что тут что-то вообще хоть сколько-нибудь читаемое получится.
Ну почему.
erato = go [2..] where go (x:xs) = x : go (filter ((/= 0) . (`mod` x)) xs)
Правда, я очень не люблю анализ сложности в подобных случаях (ленивость всё портит, а тупой переход к строгости даёт слишком плохую оценку сверху), но, по идее, это как раз эквивалентно последовательному вычеркиванию элементов.
Получили, кстати, бесконечное решето.
*Erato> take 10 erato [2,3,5,7,11,13,17,19,23,29] *Erato> take 100 erato [2,3,5,7,11,13,17,19,23,29,31,37,41,43,47,53,59,61,67,71,73,79,83,89,97,101,103,107,109,113,127,131,137,139,149,151,157,163,167,173,179,181,191,193,197,199,211,223,227,229,233,239,241,251,257,263,269,271,277,281,283,293,307,311,313,317,331,337,347,349,353,359,367,373,379,383,389,397,401,409,419,421,431,433,439,443,449,457,461,463,467,479,487,491,499,503,509,521,523,541]
Реквестирую императивное бесконечное решето.
wataru
03.05.2019 17:53Но это опять не решето! Мне кажется, тут опять каждое число проверяется на делимость всеми предыдущими простыми. Это слабо отличается от изначального вашего алгоритма.
Вы тут просто по определению делаете — списко всех чисел, которые не делятся ни на одно предыдещее число из списка.
Суть решета же в том, что вы вычеркиваете только те числа, которые точно делятся на число x, делая прыжки +x по массиву, не проверяя делимость вообще.
Реквестирую императивное бесконечное решето.
Этот же метод (не решето!) в императиве также бесконечно очень просто делается. Да, тут ФП решение покороче будет. На задчах, где ФП действительно применимо, оно часто позволяет делать сильно более короткие решения. P.s. решето, к таким, по всей видимости, не относится.
C++vector <int> ans; size_t i = 2; while (ans.size() < N) { bool prime = true; for (auto& p : ans) { if (i % p == 0) { prime = false; break; } } if (prime) ans.push_back(i); ++i; }0xd34df00d
03.05.2019 17:59Мне кажется, тут опять каждое число проверяется на делимость всеми предыдущими простыми. Это слабо отличается от изначального вашего алгоритма.
Да, у меня не получилось изящно использовать erato в том варианте, этот ближе к тому, пожалуй.
Суть решета же в том, что вы вычеркиваете только те числа, которые точно делятся на число x, делая прыжки +x по массиву, не проверяя делимость вообще.
Когда вы говорите о сложности log log n, то что вы считаете за операцию? Проверку на делимость или вообще обращение к контейнеру?
wataru
03.05.2019 18:12Когда вы говорите о сложности log log n, то что вы считаете за операцию? Проверку на делимость или вообще обращение к контейнеру?
За операцию считаются:
- обращение к массиву.
- арифметические операции (+, -, *, деления тут вообще нет).
- проверка условия, условные/безусловные переходы.
Грубо говоря, ассемблерные операции.
Там log log n вылезает потому что n/2 + n/3 + n/5 + n/7 +… сходится к n log log n. Мы ведь сначала вычеркиваем каждое второе число (пишем false по индексу, прибавляем к индексу смещение, проверяем на конец массива). Потом каждое 3-е число, и т.д. Отдельно вылезает слагаемое +n, потому что надо каждый элемент во внешнем цикле проверить, и если число простое выписать его в ответ и запустить вычеркивание.
0xd34df00d
03.05.2019 18:18+1А, ну, значит, на списках совсем никак. Пойду дальше пытаться позориться, на этот раз с действительно с массивами какими-нибудь.
0xd34df00d
03.05.2019 21:05Окей, как насчёт
import qualified Data.IntSet as IS erato2 :: Int -> [Int] erato2 n = go $ IS.fromDistinctAscList [2..n] where go set | IS.null set = [] | let x = IS.findMin set = x : go (foldr IS.delete set [x, 2 * x .. n])
IS.findMinконстантно для достаточно больших множеств,IS.deleteтоже.wataru
03.05.2019 21:24Не верю, как delete может быть константным. Если он лениво выполняется, то надо считать с ленивостью.
Это уже больше похоже на решето, но я не могу разобраться в этом коде, ибо этот синтаксис мне чужд. Оно работает вообще? Можете его позапускать на больших n и подсчитать время работы? Хотя бы для n=100, 1000, 10000, 100000, 1000000 и посмотреть с какой скоростью оно растет?
У меня такие подозрения, что ленивость delete тут всю суть поломает, ибо ему придется все предыдущие удаленные списки проверить на каждом элементе, что равносильно, опять же, проверке на делимость каждого числа всем предыдущими.
0xd34df00d
03.05.2019 21:30Не верю, как delete может быть константным. Если он лениво выполняется, то надо считать с ленивостью.
Я сам не понимаю, как, но это не ленивость. С ленивостью всё за O(1) работает :)
«Many operations have a worst-case complexity of O(min(n,W)). This means that the operation can become linear in the number of elements with a maximum of W — the number of bits in an Int (32 or 64).»
См. доки, там и ссылки на папиры с описанием структуры данных есть. Я их не читал, правда.
Оно работает вообще?
Работает, для n = 1000 я даже ручками посмотрел и сравнил с прошлой версией:
*Erato> and $ zipWith (==) erato (erato2 1000) True
У меня такие подозрения, что ленивость delete тут всю суть поломает, ибо ему придется все предыдущие удаленные списки проверить на каждом элементе, что равносильно, опять же, проверке на делимость каждого числа всем предыдущими.
А зачем все?
В любом случае, окей, попробую ssh'нуться на полноценную машину и наваять там бенчмарк.
0xd34df00d
04.05.2019 18:12Побенчмаркал. И исходное erato, и последнее выглядят почти линейно, но константа у исходного существенно лучше.
wataru
04.05.2019 19:08Исходное erato ну никаким образом не может быть n log log n. До каких n вы его гоняли? Можно данные в студию?
0xd34df00d
04.05.2019 22:10До миллиона erato, до сотни тысяч вариант с IntSet. За данные мне стыдно, IntSet сливает подчистую на два-три порядка.
wataru
04.05.2019 22:38Дайте угадаю, до 10^6 erato у вас работает пару секунд? У меня сишное решето до миллиона срабатывает мгновенно. Для 10^9 меньше 10 секунд.
Чтобы было что сравнивать, подсчитайте сумму всех простых чисел до n включительно. Для 10^9 ответ 24739512092254535. Если ваше erato сработает хотя бы за минуту, я буду очень-очень-очень удивлен и признаю, что это действительно решето.
Sirikid
05.05.2019 01:57Именно поэтому мы считаем асимптотику, а не секунды или попугаев.
wataru
05.05.2019 11:19И эта самая ассимптотика — o(N^2 / log^2 N).
Для малых N оно слабо отличается от правильного n log log n. Но для уже 10^6 вы результата будете ждать дольше, для 10^9 вы его не дождетесь.
Я прошу запустить наконец это решение чтобы наглядно доказать, что там не n log log n.
khim
04.05.2019 20:17Побенчмаркал.
Бенчмаркать тут довольно бессмысленно. log? log? 1000000000 — это в районе 5, а log? 1000000000 — это в районе 30, так что на любых вменяемых объёмах вы log? log? N от log? N не отличите.
Тут нужно либо очень точно считать именно количество операций (а не время), либо нужны какие-то совершенно безумные объёмы.0xd34df00d
04.05.2019 22:10Это уже следующий вопрос. Я не вижу практической разницы между log и loglog так-то, да.
wataru
04.05.2019 22:18Но erato, приведенное 0xd34df00d выше в ветке — не n log log n и даже не n log n. Оно n^2 / log^2 n.
Согласны что там любое простое число в ответе будет проверено на ненулевой остаток всеми предыдущими? Всего чисел n/logn, проверок — квадрат этого числа.
0xd34df00d
04.05.2019 22:19Не всеми, а до первого делителя.
wataru
04.05.2019 22:39Но оно же простое, там нет делителей! Это мы тут только оценку снизу считаем — только проверки для чисел, которые в ответ попадут. А все составные числа еще сколько-то операций добавят.
0xd34df00d
04.05.2019 22:48Но оно же простое, там нет делителей!
Так простых чисел до n примерно logn, так что мы сделаем nlogn делений для всех простых чисел вместе. На самом деле даже еще меньше, но это уже надо интегралы брать, а у меня лапки.
А все составные числа еще сколько-то операций добавят.
Именно. Добавят. Это не мультипликативный фактор.
wataru
04.05.2019 22:56Простых до n — примерно n/logn.
Еще раз, каждое простое число в вашем erato будет проверено на делимость всеми предыдущими. Иначе, с какой стати ему попадать в ответ, а вдруг оно делится на какое-то число? Всего простых до N — N/logN. Кадое с каждым проверилось — всего квадрат пополам операций.
Просто запустите уже ваше решение на n= 10^8 и 10^9. Императивное решение на C++ без каких-либо оптимизаций до 10^9 работает за 7 секунд на моей машине. Умножим на 10 для различий в машинах и компиляторах. Если вы так верите, что ваше erato быстрое — проврьте сначала, что оно отработает хотя бы за полторы минуты.
0xd34df00d
05.05.2019 04:39А, да, тогда вопрос снят.
Сорри, я сейчас в самолётах с неработающим ssh'ем до адекватной машины, так что с запусками кода сложно.
mikeus
03.05.2019 23:02Но это опять не решето!
Заходим на haskell.org. Рядом с большим логотипом наблюдаем:primes = filterPrime [2..] where filterPrime (p:xs) = p : filterPrime [x | x <- xs, x `mod` p /= 0]
Что в переводе на человеческий означает, что из потока целых чисел [3 ..] автоматом отфильтровываются делящиеся на 2, из полученного таким образом потока выбрасываются числа делящиеся на 3, из этого потока далее выбрасываются все числа делящиеся на 5, и т.д.
Процесс как на картинке из википедии, где кресты разного цвета соответствуют разным уровням рекурсии:
Вызовы filterPrime в хвосте формируемого списка при его рекурсивном раскрытии накладываются друг поверх друга, образуя вложенную матрёшку, а ленивость вычислений делает так, что следующий уровень рекурсии вызывает вычисления на предыдущем уровне рекурсии (и далее по цепочке на всех более ранних уровнях) только тогда, когда ему требуются новые данные из своего входного параметраxsдля вычеркивания из этого (уже просеянного) списка следующего числа.wataru
03.05.2019 23:24+1Нет! koldyr в комментарии выше привел статью уже. Это распространенное заблуждение.
Ну вы запустите этот код на 1000,10000,100000,1000000, 10^7 чисел и померяйте время работы. Будет ближе к n^2 / log^2 n, чем честное n log log n у решета.
То, что там что-то лениво вычисляется не позволяет тупо сократить лишние вычисления. Просто посмотрите сколько раз у вас будет остаток вычисляться.
Вы сначала за n операций уберете все числа, деляещеся на 2. Потом за n/2 операций — все делящееся на 3. Потом за n*(1-1/2)*(1-1/3) — все делящееся на 5. И т.д.
Это сложно подсчитать прямо, но можно посмотреть с другой стороны: каждое число будет проверено для всех простых, которые меньше его минимального делителя, пока не будет выпилено на какой-то итерации. Если считать только проверки для простых чисел (а они еще происходят и для всех остальных чисел тоже), то оценка снизу количества операций тут (n/logn)^2. Вы уже для n=100000 ответа не дождетесь, в то время, как решето работает тут за доли секунды.
mikeus
04.05.2019 00:06Я смотрел эту статью давно. Суть в том, чтобы улучшить производительность фильтра, генерирующего входящий поток, т.к. числа делящиеся на k есть каждое k-тое число, и нам просто не нужно к нему применять операцию деления и тестировать остаток. Это как колесо с шипами, которое катится по ленте целых чисел и выбивает каждое k-тое число, причем радиус колеса и количество шипов увеличивается после каждого полного оборота из-за нового найденного простого (не выбитого) числа. Это улучшение наивной реализации алгоритма решета Эратосфена. Суть представленной наивной реализации алгоритма (рассчитанной прежде всего на вау-эффект от элегантности рекурсивного решения) это не меняет. Это всё тот же алгоритм решета, каждое k-тое входное число там определяется наивно с помощью операции mod k.
wataru
04.05.2019 00:28Это всё тот же алгоритм решета.
Который работает за N^2/log^2N вместо N log log N. Который для N=10^7 чисел вы не дождетесь вообще, в отличии от нормального решета.
Это другой алгоритм. Для той же задачи, немного похожий, но другой!
Суть в том, что вычеркивать числа через k в массиве совсем не то же самое, что пройтись по всем числам в списке и вычеркнуть с нулевыми остатками.
Суть представленной наивной реализации алгоритма рассчитанной прежде всего на вау-эффект от элегантности рекурсивного решения это не меняет.
Да, решение элегантное, но уже для 10 миллионов чисел, в отличии от решета, тупо не работает за приемлемое время. Так-то, есть еще такой очень элегантный алгоритм для проверки числа на простоту:
return x > 1 && (x == 2 || x % 2 == 1);
В ФП стиле еще красивее будет. И очень просто и элегантно. И вау-эффектно. Но есть ньюанс для достаточно больших x.
mikeus
04.05.2019 00:53Суть в том, что вычеркивать числа через k в массиве совсем не то же самое, что пройтись по всем числам в списке и вычеркнуть с нулевыми остатками.
Поясните на примере. Есть массив последовательных чисел начиная строго с единицы (а у нас в исходной задаче именно такие условия), допустим вот: [1 2 3 4 5 6 7 8 9 10 11]. Нужно вычеркнуть каждый третий элемент. В чем суть отличия от вычеркивания чисел с нулевым остатком от деления на 3? (Кроме производительности операции конечно.)
Так-то, есть еще такой очень элегантный алгоритм для проверки числа на простоту:
А «достаточно большие» x начинаются уже с 9?
return x > 1 && (x == 2 || x % 2 == 1);
В ФП стиле еще красивее будет. И очень просто и элегантно. И вау-эффектно. Но есть ньюанс для достаточно больших x.wataru
04.05.2019 11:11Поясните на примере.
При вычеркивании каждого третьего числа, будет сделано 12/3=4 операции вычеркивания и еще столько же операций увеличения индекса (i+=3) и проверок на конец массива (i<12?). Т.е. суммарно 12 операций.
При вычеркивании чисел с остатком == 0, будет сделано 12 проверок на делимость, 12/3 вычеркиваний, 12 переходов к следующему элементу и 12 проверок на конец списка. 40 операций. Более чем в 3 раза больше.
Еще раз, решето на массиве просто пропускает 2/3 всех чисел, вообще не тратя на них операции. Ваш алгоритм со списком должен обработать все числа и посмотреть на остаток в каждом.
В итоге, эти лишние операции накапливаются для всех простых чисел и в сумме дают o(n^2/log^2 n), вместо O(n log log n). Что гораздо медленее для больших n.
А «достаточно большие» x начинаются уже с 9?
Да :)
Это был просто немного гипертрофированный пример, как ваш аргумент не совсем корректен. Если алгоритм работает плохо, то не так важно, насколько он красив.
khim
03.05.2019 05:57
Я боюсь вы пропустили «мимо ушей» три буквы и потому не поняли смысла всей фразы.SSA у компиляторов вполне обычных императивных языков как бы намекает.
Вы хотите сказать, что ФП — синтаксический сахар?
Современные компиляторы C++ (GCC, Clang, думаю, что и MSVC тоже) перед тем, как анализировать вашу программу и «думать» над тем, как превратить её в машинный код переводят её в так называемую SSA-форму. Фактически — это версия вашей программы в функциональном стиле. Где переменных в стиле императивных языков нет, а переменные в стиле функциональных языков (который вы там дальше в дискуссии обсуждаете) — есть. Ну а дальше уже — всё это «кладётся на архитектуру».
Соответственно переходя от императивного языка к функциональному — вы, несколько парадоксальным образом, оказываетесь «ближе» к машине.third112
03.05.2019 06:27Спасибо. Я читал про SSA.
Фактически — это версия вашей программы в функциональном стиле.
По указанной ссылке я такого не нашел. И не очевидно, как это соотносится с определением ФП, предложенным в данной статье.
Особо меня интересуют ГСЧ и обработка событий. Не вижу трудностей для:
промежуточное представление, используемое компиляторами, в котором каждой переменной значение присваивается лишь единожды. Переменные исходной программы разбиваются на версии, обычно с помощью добавления суффикса, таким образом, что каждое присваивание осуществляется уникальной версии переменной.
Но в обсуждаемой статье:
Формулы хорошо формализуются и при одинаковых входных данных возвращают одинаковые выходные.
Про эту проблему для событий и ГСЧ уже говорил в данном обсуждении.
Еще раз уточню: исхожу из определения обсуждаемой статьи.
0xd34df00d
03.05.2019 01:12ГСЧ может быть и аппаратным, частью CPU. Тут выделить не получится и ФП не применимо (в вольной трактовке).
Применимо в виде IO. И это хорошо, что оно в IO. Потому что если у меня вычисление со случайными числами (Монте-Карло там какое-нибудь, или тупо quickcheck-подобный тест/бенчмарк), то я знаю, что если оно не живёт в IO, то оно воспроизводимо, ибо где-то там внутри random seed.
А какой-нибудь MonadRandom потом никто не мешает быть написанной так, что она работает хоть с ГСЧ из CPU, хоть с линейным конгруентным генератором. Такая-то модульность, да гарантируемая компилятором! Это ли не Святой Грааль?
samsergey
03.05.2019 07:50Так вышло, но детерминистическая генерация псевдо-случайных чисел тоже функциональна по своей природе. Недетерминизм возникает лишь на входе в цепочку генератора, а это может быть точкой входа в функциональную программу.
Для RosettaCode я писал "Змейку" на Haskell. И там генерация случайного расположения "еды" для змеи вся прячется в одной полиморфной функции в рамках
MonadRandom, так как будто бы генератор у нас есть и он возьмёт затравку, когда понадобится, но нам пока не важно откуда. При этом код выглядит так, будто бы в мире змейки уже существуют все будущие координаты в которых еда "случайно" появится (как в беременной самке тли хранятся уже беременные самки и т.д.), это следствие ленивости.
Когда же, наконец, мы в точке входа в программу (функцияmain) инициализируем змейкин мир, тогда в качестве экземпляраMonadRandomоказываетсяIO(без неё-то всё равно никак) и вот ни пользователь, ни змейка уже "не знают" где появится очередной фрукт.
Это может показаться трюкачеством, но по-существу вся программа говорит только о том, что делать змейке, получившей сигнал от пользователя или при встрече с едой, и не более. Откуда возьмутся еда и сигналы пользователя, змейке знать не обязательно, об этом заботится только функцияmain, которая отправляет её в "реальный мир", либо в его детерминистическую эмуляцию (монаду ST) для отладки.
Этот пример не призван показать превосходство ФП перед императивным программированием. Он про то, что многие как кажется чисто императивные задачи гладко ложатся на функциональную парадигму, не требуя лишних шаманств и костылей (если не считать костылями то, что не понимаешь с первого раза).

develop7
03.05.2019 11:55согласно данному определению, в ФП это недопустимо
если бы это было недопустимо, программы на ФЯП не могли бы производить никакой полезной работы (а программы на ленивых ЯП так ещё и не выполнялись бы никогда) т.к. любой ввод-вывод, в т.ч. и получение входных данных, и вывод результата являются побочными эффектами. не то, чтобы это сильно расходилось с общей концепцией бесполезности ФЯП, насаждаемой их противниками, но и с объективной реальностью ничего общего не имеет :)third112
03.05.2019 14:54при одинаковых входных данных не получим одинаковые выходных.
Это допустимо в ФП? В определении сказано обратное.
vedenin1980
03.05.2019 15:57Это допустимо в ФП? В определении сказано обратное.
Тут надо учитывать, что входными данными можно считать все действия пользователя, состояние файлов в файловой системе, данные в базе данных, даже генератор случайных чисел. Если входные данные абсолютно одинаковые получим одинаковый результат.
Разумеется, обычно нет необходимости точно повторять все выходные данные для всей программы, достаточно, чтобы каждая часть программы давала одинаковый результат при одинаковых входных данных.third112
03.05.2019 16:30Тут надо учитывать, что входными данными можно считать все действия пользователя, состояние файлов в файловой системе, данные в базе данных, даже генератор случайных чисел.
В результате получим проблемы по обработке событий в ходе вычислений. Еще один интересный вопрос: как при таком подходе возможна многопоточность? Мьютекс — это входные данные?vedenin1980
03.05.2019 16:44В результате получим проблемы по обработке событий в ходе вычислений
Какого именно рода проблема? Дайте реальный пример.
как при таком подходе возможна многопоточность?
Прекрасно возможно, разумеется, если разумно использовать внешние ресурсы (не завязываться на ресурсы не поддерживающие многопоточность и т.п.). Опишите какие проблемы вы тут видите.
Мьютекс — это входные данные?
Вы про мьютексы операционной системы? Нет, но языки высокого уровня (не только функциональные) от них напрямую не зависят.third112
03.05.2019 17:03Вы про мьютексы операционной системы?
Я про средства синхронизации внутри программы (всякие семафоры и т.д.)
Опишите какие проблемы вы тут видите.
Обычные проблемы синхронизации: гонки, общая область памяти для обмена данными между потоками, т.е. глобальные переменные и запоминание текущих состояний, и т.п.
Какого именно рода проблема? Дайте реальный пример.
Выше приводил пример:
Простейший пример: функция последовательными приближениями долго вычисляет результат, мне надоело ждать, нажал кнопочку, функция должна вернуть, что успела вычислить на этот момент.
вижу только одно решение:
повторять
список_аргументов := чистая_функция_очередное_приближение (список_аргументов);
до_той_поры_пока чистая_функция_точность_достигнута (список_аргументов)
или кнопочка_нажата;
Т.е. две чистых функции, но всю программу в виде читой функции не оформить.0xd34df00d
03.05.2019 17:12гонки
С STM их нет.
общая область памяти для обмена данными между потоками, т.е. глобальные переменные и запоминание текущих состояний
С STM их тоже нет (по крайней мере, в классическом смысле). Если очень хочется чего-то глобального, то можно взять MVar, например. Тогда код, работающий с ним, живёт в IO, и чтение или запись в MVar — это эффект, примерно как чтение или запись с файлом.
Простейший пример: функция последовательными приближениями долго вычисляет результат, мне надоело ждать, нажал кнопочку, функция должна вернуть, что успела вычислить на этот момент.
Как вы это будете делать в императивном языке?
Это я так, чтобы понимать, какие ограничения и аналогии вы ожидаете, от этого зависит конкретный вариант решения с функциональщиной.
Т.е. две чистых функции, но всю программу в виде читой функции не оформить.
А зачем? У вас и так уже кнопочки и GUI есть, значит, там заведомо есть что-то нечистое. Ну будет ещё нечистый канал взаимодействия, куда одна мелкая функция будет писать результаты чистой.
third112
03.05.2019 17:57У вас и так уже кнопочки и GUI есть, значит, там заведомо есть что-то нечистое.
В этом я вижу проблему. Если функция
чистая_функция_очередное_приближение надолго задумывается, то в императивном языке вставлю в нее Application.ProcessMessages, чтобы нажатие кнопочки почувствовала. А в ФП моя функция перестанет быть чистой.0xd34df00d
03.05.2019 18:01Функция вычисления очередного приближения (в которой и лежит, кстати, вся бизнес-логика, и которой полезно быть чистой) остаётся чистой. Нечистой становится функция, которая берёт чистую функцию и вычисляет последовательность приближений (которая при этом является обобщённой, от предметной области не зависит, может быть написана один раз, выложена на Hackage и забыта).
third112
03.05.2019 18:51К сожалению, не все задачи решаются такой схемой. Простейший ИМХО пример: 8 ферзей. На современных мощностях решается быстро возвратным алгоритмом, поэтому можем увеличить размерность.
khim
03.05.2019 19:23Что вы имеете в виду? Как раз расстановка ферзей — задача, которая великолепно решается в описанном чуть выше стиле. Там, правда не три строки будет, а целых 10 или даже 20… но в любом случае — сильно меньше, чем на импереативных языках…
А нас в школе эта задачка рассмтривалась не то на третьем, не то на четвёртом занятии при использовании RL'я (такой очень-очень урезанный Lisp, где нет даже строк и чисел).
И новички без опыта программирования — писали вообще без вопросов. Вот как раз людям с опытом программирования их опыт сильно мешал.wataru
03.05.2019 20:07Выше обсуждается другой пример — решето Эратосфена. Этот быстрый алгоритм в чистой функциональщине очень сложно сделать. Придется тупо циклы/переменные эмулировать.
samsergey
03.05.2019 22:09Придется, но это, правда, не "очень сложно"!
wataru
03.05.2019 23:27Так никто пока и не привел чего-то, работающего за n log log n. Это далеко не тривиально вложенные циклы эмулировать на рекурсии.
samsergey
04.05.2019 02:31+2Вот решение, вполне прямолинейное и наивное.
import Control.Monad.Primitive import qualified Data.Vector.Unboxed as V import qualified Data.Vector.Unboxed.Mutable as M eratosphenesArray :: Int -> IO (M.MVector (PrimState IO) Bool) eratosphenesArray size = M.replicate size True >>= sieve 2 where sieve k m | k*k >= size = return m | otherwise = do next <- M.read m k m <- if next then fill (2*k) k m else pure m sieve (k+1) m fill n k m | n+k > size = return m | otherwise = M.write m n False >> fill (n+k) k m
заполняет массив значениями
TrueиFalseсогласно оригинальному замыслу, в двух вложенных циклах (sieveиfill). Сигнатура страшная, но алгоритм прост как пробка.
Если надо список простых чисел (индексы со значениямиTrue), то можно написать такое:
eratosphenes :: Int -> IO [Int] eratosphenes size = do a <- eratosphenesArray size elemIndices True . V.toList <$> V.freeze a
Результаты прогона на ноуте (сплошная линия — n*log(log(n))):
wataru
04.05.2019 11:21Посыпаю голову пеплом. Получилось гораздо менее громоздко, чем я предполагал.
Еще бы этот алгоритм вставить во все документации вместо стандартного красивого, но медленного однострочника.
samsergey
04.05.2019 03:18+1Немного прокомментирую это решение. Я использовал
Data.Vector.Unboxed.Mutableтолько для эффективности. От этой структуры здесь лишь конструкторM.replicateи функции доступаM.readbM.write. На месте этой структуры могли быть немутабельные векторы, Array (или даже список со всеми вытекающими проблемами эффективности). Программа и её результат бы от этого не изменились, только сигнатура. И то, её я не писал вручную, мне рассказал о ней компилятор :)
Именно этот выбор определил то, что результат будет "жить" в IO. Но ровно эту же программу можно погрузить в чистую ST, в любом случае, она принципиально императивна, что не помешало мне реализовать её в Haskell.
Циклы реализованы через рекурсию, вполне прямолинейно, в виде хвостового вызова. Из магии только монадические штучки
>>и>>=, которые можно рассматривать как пайпы.
И, наконец, я нарочно написал тело циклаsieveтак, чтобы он "выглядел" как изменение переменнойm, чтобы показать, что если уж мы мыслим наш алгоритм императивно, то его можно и выразить императивным кодом, не изменяя принципам ФП. Мы не монахи и императивность не грех, если всё делать аккуратно, с благословения компилятора.
В бенчмарке использовался вариант с преобразованием в список, чтобы честно. Оно добавило константу, но оставило асимптотику.
0xd34df00d
04.05.2019 18:17Только Array придётся копировать, что очень плохо скажется на производительности.
Короче, сложно всё это назвать чистым ФП, ИМХО.
samsergey
05.05.2019 01:55Это да. Мне хотелось продемонстрировать не столько чистое ФП, сколько его выразительность и гибкость. Если требуют решето именно Эратосфена и именно двойным циклом и именно с вычёркиваем, то… и это можно.
А так, есть классные функциональные решения тут и тут. Но они уже не совсем то решето, о котором обычно рассуждают.
Для своих нехитрых нужд я бы взял ваш однострочник и не заморачивался. Для криптографии какой-нибудь — быстрый императивный код через FFI, но я в ней мало смыслю, если честно.0xd34df00d
05.05.2019 04:40Для криптографии какой-нибудь — быстрый императивный код через FFI
Как раз для криптографии какой только чистый завтипизированный код со всеми теоремками, и ничего иного.
Ну, если вам не фоточки котиков криптографировать, конечно.
samsergey
05.05.2019 05:07Я имел в виду не задачу криптографии в целом, а генерацию простых чисел (если таковая, действительно ставится при факторизации больших чисел, опять же, могу напутать по незнанию). Эта генерация, по существу, чиста и может быть встроена в чистый код, но имплементирована может быть как угодно, лишь бы эффективно. Впрочем, тут мне лучше умолкнуть.
0xd34df00d
03.05.2019 16:56В результате получим проблемы по обработке событий в ходе вычислений.
А в чём проблемы?
Еще один интересный вопрос: как при таком подходе возможна многопоточность? Мьютекс — это входные данные?
Мьютекс — это ужасный, некомпозабельный примитив для синхронизации. Ъ функциональщики используют, например, software transactional memory.
third112
03.05.2019 17:17В STM усматривают ряд недостатков. Отечается, что
STM по-прежнему находится в центре интенсивных исследований
Видимо технология еще слишком молодая для тотального использования.
А в чём проблемы?
Выше приводил пример.0xd34df00d
03.05.2019 17:30STM по-прежнему находится в центре интенсивных исследований
Ну офигеть недостаток.
В STM усматривают ряд недостатков.
По ссылке я их не нашёл.
Не, конечно, STM не сделает весь ваш код магически белым и пушистым, и транзакции, в которых вы делаете стопицот операций, будут немного тормозить (правда, скорее в неудачном случе). Но если у вас транзакции по стопицот операций, которые конкурируют между собой, у вас уже и так проблемы.
Ну и стоило бы это сравнивать с тормозами от какого-нибудь одного-мьютекса-на-всё-ядро/программу/интерпретатор.
В любом случае, композабельность и возможность не думать, кто какие мьютексы в каком порядке где берёт — это офигенно. Возможность писать код в последовательном стиле, вообще не особо думая о точках синхронизации — это прямо вообще.
third112
03.05.2019 18:03Ну офигеть недостаток.
М.б. нет, но из общих соображений многие молодые технологии бывают несовершенными. В любом случае выбор желателен: чем больше возможностей — тем лучше.
Ryppka
04.05.2019 21:45Не вникал в проблему глубоко, но из последнего, что слышал/читал про практическое использование STM — надо быть внимательным, чтобы не было starvation, надо следить, чтобы «куски работы» были небольшого размера и очень плохо в гарантиями времени завершения (в моей работе они, увы, на каждом шагу).
0xd34df00d
04.05.2019 22:11А ещё оно не fair scheduling, например, да.
Ну а про то, что STM — не magic bullet, я уже тоже написал.

EvgeniiR
02.05.2019 19:41+4Как принято в науке, начинём с определений. Классичесткое определение ООП включает в себя следование принципам наследования, инкапсуляции и полиморфизма. Но если у нас нет одного из этих составляющих, будет ли это ООП? И если нет, то что это будет? Пока занудная часть аудитории зависла над этим непрактичным и ничего нам не дающим вопросом, вспомним, что было до ООП. А до него было процедурное программирование. И основная идея ООП на тот момент была в связи данных и функций для их обработки. Идея простая, но довольно революционная, сложно представить насколько, но об этом позже.
Объединение вместе данных и функций также изначальной идеей ООП не являлось. См. Alan Kay definition of object orintied или, например, Джо Армстронг интервьюирует Алана Кея, насколько я помню, от части в этом видео Алан рассказывает какие идеи вкладывал в это понятие, и что его парадигма должна была привнести в мир большее, чем язык Симула, в котором впервые была реализована модель объектов
Споры об ООП vs ФП считаю бессмысленными по следующим причинам
— Конечно же, каждый понимает под этими терминами что-то своё, только что мы вот уже 3 определения выделили.
— Есть более важные вещи которые нужно изучать чтобы писать качественный код, вот ими как раз стоит заниматься.
— ООП и ФП не противоречат друг другу по своей натуре. Erlang — отличный пример ФП языка сохранившего и до сих пор полноценно релизующиго изначальные идеи ООП благодаря наличию легковесных, независимых, общающихся между собой объектов. Объектами в данном случае являются легкие независимые потоки, который обмениваются сообщениями, и перезапускать который можно прямо в рантайме не ломая систему
Ну и да, холиварная тема далее — по поводу процедурного программирования, оно никуда не делось. До сих пор есть огромная кодовая база написанная и пополняющаяся кодом в процедурном стиле, будь это Java, PHP, или что ещё, экземпляры классов, часто представляют собой лишь набор связанных(или нет) данных которые вытягиваются и устанавливаются через геттеры/сеттеры из внешних процедур. Это лишь ещё одно дополнение к моему тезису о безполезности споров ООП vs фп.
0xd34df00d
03.05.2019 01:36Про привязку методов к данным чуть сложнее, накладывают ограничения используемый язык и библиотеки. Скажем, в JavaScript это делается элементарно, не уверен за Haskell и Erlang.
Достаточно почитать, например, Бенджамина Пирса, чтобы увидеть, как на просто типизированном лямбда-исчислении с некоторыми расширениями делается каноничное ООПэ, с методами и сабклассами.
Sirikid
03.05.2019 02:04Мм, можно и SICP — как известно, объекты это всего лишь замыкания для бедных.
tmteam
03.05.2019 04:22Есть ощущение, что на хорошем уровне ООП и SOLID, ФП и ООП начинают приходить к одному целому. (с учетом некоторой синтаксической убогости ОО-языков)
vassabi
03.05.2019 15:52ну вот например про ООП через ФП можно в SICP почитать (со второй главы ЕМНИП)
akryukov
03.05.2019 19:10-1Вторая глава — построение абстракций с помощью данных, хоть и похоже на ООП, но не про него. Современное, общепринятое понятие ООП обязательно включает в себя полиморфизм, инкапсуляцию и наследование. При абстрагировании с помощью данных используется максимум — инкапсуляция.
vassabi
03.05.2019 23:43полиморфизм и наследование спокойно добавляются через фабричные функции-конструкторы (например как в js).
akryukov
04.05.2019 00:03Где про это в SICP написано?
vassabi
04.05.2019 14:05конкретно это в SICP я не увидел (то ли не на то обращал внимание, то ли там такого нет — ибо авторы делали упор на совсем другом).
Но, если вы увидите как сделать вызов (пусть ИмяП (функция-создатель параметры)) а чтобы потом работал вызов (пусть результат (имяМетодаИмяП параметры)), то неужели будет трудно сделать двух таких функций-создателей, что они будут принимать разные параметры, функция-создатель-сын внутри вызовет функцию-создатель-отец (привет наследование), а вызов имяМетода будет корректно работать с результатами обеих функций-создателей — в том числе и через внутреннюю ссылку на результат из функции-создателя-отца (привет полиморфизм)?akryukov
04.05.2019 14:18Вы не могли бы чуть более строгим псевдокодом написать свою мысль?
vassabi
04.05.2019 15:42суббота, 4 мая, выходные между праздниками. хмм… не, нет, не мог бы.
… в общем, если бы вы видели, как работает механизм полиморфизма и наследования в джаваскрипте, то вы бы смогли написать такой же — из той функции, которая делает структуры в SICP.
0xd34df00d
04.05.2019 18:17А зачем SICP? Почитайте TAPL.
akryukov
04.05.2019 18:52Товарищ заявлял "ну вот например про ООП через ФП можно в SICP почитать", о чем и спрашиваю.
vassabi
04.05.2019 20:11ок, разложу поподробнее: ООП несложно сделать через структуры, а про структуры через чистые функции можно почитать в SICP
akryukov
04.05.2019 20:49Складывание данных в структуры это не ООП. Это один из его элементов.
Без остальных (а именно полиморфизма и наследования) — он в ООП от этого не превратится.vassabi
04.05.2019 22:31если вы не умеете делать полиморфим и наследование из структур — ок, значит у вас оно не превращается.


scp1001
Функциональное программирование также хорошо тем, что отлично вписывается в концепцию формальной верификации: например, в нём гораздо меньше проблем с сайд-эффектами.
Это упрощает создание отказоустойчивого софта.
rfq
И использование только целых чисел хорошо тем, что отлично вписывается в концепцию формальной верификации. А с вещественными числами сплошной головняк: ошибки накапливаются, и уже непонятно, если прогамма выдала ответ 1.23, это 1.23±0.01 или 1.23±1000. Ну его нафиг, давайте лучше без вещественных вообще.
samsergey
Ну, и во многих областях это оправдано. Так появилась поддержка длинных целых и рациональных чисел с одной стороны, и всё более мощные символьные движки в повседневных задачах. Так что не зря упирались теоретики!
koldyr
Давайте лучше откроем учебник по численным методам.
rfq
вот вы бы так функционально озабоченным отвечали: откройте учебник по ООП.
khim
А нужно ли открывать учебник по численным методам, если вы, скажем, пишите бухгалтерскую программу? И пытаться понять — откуда у вас взялось в балансе расхождение в копейку? Если можно вместо этого считать всё в копейках и не иметь проблем?
Правда ведь заключается в том, что использования вещественных чисел действительно стоит избегать… просто иногда без них задача не очень решается…
Zoolander
старый добрый трюк, который почему-то очень редко пишут во всяких книгах и уроках
Tepex
А как же классика — Bloch, J., Effective Java, 2nd ed, Item 48
koldyr
Можно считать в копейках, пока не придут 1/5 копейки, логарифм и экспонента.
khim
Там где могут придти 1/5 или 1/10000 копейки есть всё равно свои правила, позволяющие считать в целых числах.
Числа с плавающей точкой — зло. Иногда, впрочем, неизбежное зло, как я сказал — но всё равно зло.
Am0ralist
Да, и если вы вовремя не округлите до копейки, то у вас не сойдётся итоговый баланс. Таким образом мы возвращаемся к расчёту в целых числах.
А то вот пользуюсь ипотечным калькулятором, автор которого не совсем округляет числа. И на данный момент реальные числа и расчёты в этом калькуляторе разбежались на копейку уже. И вот что в одной из сумм:
Бухгалтерия вам будет благодарна за такое.
vedenin1980
На самом деле, для любого практического применения можно обойтись только рациональными числами (если ошибаюсь — поправьте).
Например, для вычисления окружности Вселенной, измеренной в атомах водорода, нужно около 40 знаков числа пи. То есть, округляя до первых 100 знаков после запятой, мы гарантировано получим адекватные результаты для любых вычислений длинн в пределах наблюдаемой Вселенной с любой доступной нам (даже в теории) точностью.
То есть иррациональные числа это лишь удобная математическая абстракция, как плюс или минус бесконечность, которой не обязательно сущствует в реальном мире (особенно если время, пространство и другие величины квантуются).
0xd34df00d
Более того, все интересные иррациональные числа вычислимы.
Sirikid
Не передергивайте. Вещественные числа формализовали ещё в XIX веке. Кроме того, никто не мешает доказывать теоремы о числах в формате IEEE 754.
NIKOSV
При этом, писать, читать, дебажить код — гораздо тяжелее. Так что тяжело сказать что оно там упрощает.
Ну а писать код без сайд эффектов можно, и нужно и на императивных языках. К тому же они поддерживают функциональный плюшки тоже, можно использовать там, где удобно. Короче как всегда, правда посредине.