
Периодически посматриваю на Swift в качестве языка прикладного программирования для Linux — простой, динамичный, компилируемый, без сборщика мусора, а значит, теоретически, пригоден и для устройств. Решил сравнить его с чем-то таким же молодым и модным — например Rust. В качестве теста я взял прикладную задачу — парсинг и агрегация большого файла JSON, содержащего массив объектов. Исходники старался оформлять в едином стиле, сравнивал по 4-м параметрам: скорость исполнения, размер бинарника, размер исходника, субъективные впечатления от кодинга.
Подробнее о задаче. Имеется файл JSON размером 100 Мб, внутри массив из миллиона объектов. Каждый объект представляет собой запись о долге — название компании, список телефонов и сумма долга. Одни и те же телефоны могут использовать разные компании, и по этому признаку их нужно сгруппировать, т.е. выделить реальных дебиторов, имеющих список названий, список телефонов, и суммарный долг. Исходные объекты «грязные», т.е. данные могут быть записаны в виде строк / чисел / массивов / объектов.
Результаты бенчмаркинга меня озадачили. Подробности и исходные тексты — под катом.
Исходный JSON:
[
{"company":"Рога и копыта", "debt": 800, "phones": [123, 234, 456]},
{"company":"Первая коллекторская", "debt": 1200, "phones": ["2128506", 456, 789]},
{"company":"Святой престол", "debt": "666", "phones": 666},
{"company": "Казачий спас", "debt": 1500, "phones": [234567, "34567"], "phone": 666},
{"company": {"name": "Шестерочка"}, "debt": 2550, "phones": 788, "phone": 789},
...Детали реализации
Задача распадается на 4 стадии:
1) Буферизованное посимвольное чтение файла, потоковый парсинг и выделение объектов из массива. Не стал заморачиваться поиском библиотек типа YAJL, ведь мы точно знаем что внутри массив, и выделить объекты можно путем подсчета открывающих и закрывающих фигурных скобок {}, благо что они ASCII, а не многобайтные Unicode. На удивление, не обнаружил в обоих языках функции посимвольного чтения из потока Unicode — полное безобразие, слава богу что парсеры JSON берут эту работу на себя, иначе пришлось бы велосипедить с битовыми масками и сдвигами.
2) Cтроки-объекты, выделенные на стадии 1, передаем штатному парсеру JSON, на выходе получаем динамическую структуру (Any в Swift и JsonValue в Rust).
3) Копаемся в динамических данных, на выходе формируем типизированную структуру:
//source data
class DebtRec {
var company: String
var phones: Array<String>
var debt: Double
}4) Агрегируем запись о долге — ищем по номеру телефона дебитора (либо создаем), и обновляем его атрибуты. Для чего используем еще 2 структуры:
//result data
class Debtor {
var companies: Set<String>
var phones: Set<String>
var debt: Double
}
class Debtors {
var all: Array<Debtor>
var index_by_phone: Dictionary<String, Int>
}Итоговых дебиторов храним в динамическом массиве (векторе), для быстрого поиска по телефону используем индексную хеш-таблицу, в которой для каждого телефона храним ссылку на дебитора. Упс… Помня, что Rust не поощряет хранение реальных ссылок (даже иммутабельных), используем вместо ссылки числовой индекс дебитора в массиве all — доступ по индексу дешевая операция. Хотя, конечно, если все перейдут на доступ по индексам и хешам, получим не приложение, а какую-то СУБД. Может Rust этого от нас и добивается?
P.S.
Мой код на Rust далек от идеального — например, много to_string(), тогда как правильнее было бы заморочиться со ссылками и временами жизни (хотя предполагаю, что умный компилятор сделал это за меня). Что касается Swift — код также весьма далек от совершенства, но ведь в этом и цель бенчмаркинга — показать как простой человек склонен решать задачи на том или ином языке, и что из этого получается.
Результаты тестирования
Проекты компилировались со стандартными опциями:
swift build -c release
cargo build --release
Дебажная версия Rust показала чудовищную производительность в 86 секунд, возможно, честно отрабатывая мои to_string() (а может вообще в машинный код не переводила? <шутка>). Для Swift разница в дебажной и релизной версии оказалась незначительной. Сравниваем только релизные версии.
Скорость чтения и обработки 1 млн. объектов
Swift: 50 секунд
Rust: 4.31 секунды, то есть в 11.5 раз быстрее
Размер бинарного кода
Swift:
Сам бинарник 62 Kb, но библиотеки runtime — 9 штук на сумму 54,6 Мб (я считал только те, без которых программа действительно не запускается)
Rust:
Бинарник получился не маленким — 1,9 Мб, зато он один («lto=true» ужимает до 950 Кб, но компилирует существенно дольше).
Размер исходного кода
Swift: 189 строк, 4.5 Kb
Rust: 230 строк, 5.8 Кб
Впечатления от языка
Что касается кодинга — бесспорно, Swift гладкий и приятный глазу, особенно в сравнении с «ершистым» Rust, и программы получаются компактнее. Я не буду придираться к мелочам, отмечу лишь те грабли, на которые наступил сам при изучении. Простите, могу быть субъективен.
1) Именования объектов стандартной библиотеки Swift (а также Foundation) не так интуитивны и структурированы как в Rust, видимо по причине необходимости тащить наследие предков. Без документации порой сложно догадаться, какой метод или объект нужно искать. Перегруженные конструкторы конечно добавляют приятной магии, но данный подход, похоже, совсем не молодежный, и мне ближе принцип именования фабричных методов в Rust — from_str(), from_utf8() и т.д.
2) Обилие унаследованных объектов + перегрузка методов в Swift облегчает возможность начинающему программисту выстрелить себе в ногу. Например, в качестве промежуточного буфера прочитанных из файла байт я сначала использовал Data(), который как раз требуется на вход парсеру JSON. Этот Data имеет те же методы, что и Array, т.е. позволяет добавлять байты, да и по сути это одно и то же. Однако, производительность с Data была в несколько раз (!) ниже, чем в нынешнем варианте с Array. В Rust разница в производительности между векторами и слайсами практически не ощущается, а API доступа настолько разные, что никак не перепутать.
PS
В комментариях — специалисты по Swift смогли ускорить код в несколько раз, но это уже магия профессионалов, тогда как Rust смогли ускорить только на 14%. Получается, что порог вхождения в Rust на самом деле ниже, а не выше, как принято думать, и злой компилятор не оставляет никакой свободы «сделать что-то не так».
3) Опциональный тип данных Swift (а также оператор приведения типов) сделаны синтаксически более изящно, через постфиксы ?! — в отличие от неуклюжего растового unwrap(). Однако растовый match позволяет единообразно обрабатывать типы Option, Result, Value, получая, при необходимости, доступ к тексту ошибки. В Swift же в разных местах используется то возврат Optional, то бросок исключения, и это иногда сбивает с толку.
4) Объявления внутренних функций в Swift не всплывают, поэтому их приходится объявлять выше по тексту, что странно, ведь во всех остальных языках внутренние функции можно объявлять в конце.
5) В Rust встречаются кривые синтаксические конструкции, например если нужно проверить значение JSON на пустоту, приходится писать один из 2-х смешных бредов:
if let Null = myVal {
...
}
match myVal {
Null => {
...
}
_ => {}
}хотя напрашиваются очевидные варианты:
if myVal is Null {
...
}
if myVal == Option::Null {
...
}Поэтому и приходится в библиотеках создавать кучу методов is_str(), is_null(), is_f64() для каждого enum-типа, что, конечно, жуткие синтаксические костыли.
PS
Судя по всему, это скоро починят, в комментариях есть ссылка на proposal.
Резюме
Так что же так тормозит в свифте? Разложим на стадии:
1) Чтение файла, потоковый парсинг с выделеним объектов
Swift: 7.46 секунд
Rust: 0.75 секунд
2) Парсинг JSON в динамический объект
Swift: 21.8 секунд
— это миллион вызовов: JSONSerialization.jsonObject(with: Data(obj))
Rust: 1.77 секунд
— это миллион вызовов: serde_json::from_slice(&obj)
3) Преобразование Any в типизированную структуру
Swift: 16.01 секунд
Rust: 0.88 секунд
— допускаю, что можно написать оптимальнее, но мой код на Rust такой же «тупой» как и на Swift
4) Агрегация
Swift: 4.74 секунд
Rust: 0.91 секунд
То есть мы видим, что в языке Swift тормозит все, и его надо сравнивать с системами типа Node.js или Python, причем я не уверен, в чью пользу будет бенчмаркинг. Принимая во внимание огромность рантайма — об использовании в устройствах вообще можно забыть. Получается, что алгоритм подсчета ссылок гораздо медленнее сборщика мусора? Тогда что, все учим Go и MicroPython?
Rust — красавчик, хотя задача была слишком простой, и погружаться в ад заимствований и лайфтаймов не было необходимости. Конечно, было бы неплохо протестировать растовые Rc<> на предмет торможения, а еще хочется прогнать данный тест на Node, Go и Java, но жаль свободного времени (хотя, по моим прикидкам, Javascript будет медленнее всего в 2.5 раза).
P.S.
Буду благодарен растаманам и свифтерам за комментарии — что не так с моим кодом.
Исходные тексты
Swift:
import Foundation
let FILE_BUFFER_SIZE = 50000
//source data
class DebtRec {
var company: String = ""
var phones: Array<String> = []
var debt: Double = 0.0
}
//result data
class Debtor {
var companies: Set<String> = []
var phones: Set<String> = []
var debt: Double = 0.0
}
class Debtors {
var all: Array<Debtor> = []
var index_by_phone: Dictionary<String, Int> = [:]
}
func main() {
var res = Debtors()
var fflag = 0
for arg in CommandLine.arguments {
if arg == "-f" {
fflag = 1
}
else if fflag == 1 {
fflag = 2
print("\(arg):")
let tbegin = Date()
let (count, errcount) = process_file(fname: arg, res: &res)
print("PROCESSED: \(count) objects in \(DateInterval(start: tbegin, end: Date()).duration)s, \(errcount) errors found")
}
}
for (di, d) in res.all.enumerated() {
print("-------------------------------")
print("#\(di): debt: \(d.debt)")
print("companies: \(d.companies)\nphones: \(d.phones)")
}
if fflag < 2 {
print("USAGE: fastpivot -f \"file 1\" -f \"file 2\" ...")
}
}
func process_file(fname: String, res: inout Debtors) -> (Int, Int) {
var count = 0
var errcount = 0
if let f = FileHandle(forReadingAtPath: fname) {
var obj: Array<UInt8> = []
var braces = 0
while true {
let buf = f.readData(ofLength: FILE_BUFFER_SIZE)
if buf.isEmpty {
break //EOF
}
for b in buf {
if b == 123 { // {
braces += 1
obj.append(b)
}
else if b == 125 { // }
braces -= 1
obj.append(b)
if braces == 0 { //object formed !
do {
let o = try JSONSerialization.jsonObject(with: Data(obj))
process_object(o: (o as! Dictionary<String, Any>), res: &res)
} catch {
print("JSON ERROR: \(obj)")
errcount += 1
}
count += 1
obj = []
}
}
else if braces > 0 {
obj.append(b)
}
}
}
} else {
print("ERROR: Unable to open file")
}
return (count, errcount)
}
func process_object(o: Dictionary<String, Any>, res: inout Debtors) {
let dr = extract_data(o)
//print("\(dr.company) - \(dr.phones) - \(dr.debt)")
var di: Optional<Int> = Optional.none //debtor index search result
for p in dr.phones {
if let i = res.index_by_phone[p] {
di = Optional.some(i)
break
}
}
if let i = di { //existing debtor
let d = res.all[i]
d.companies.insert(dr.company)
for p in dr.phones {
d.phones.insert(p)
res.index_by_phone[p] = i
}
d.debt += dr.debt
}
else { //new debtor
let d = Debtor()
let i = res.all.count
d.companies.insert(dr.company)
for p in dr.phones {
d.phones.insert(p)
res.index_by_phone[p] = i
}
d.debt = dr.debt
res.all.append(d)
}
}
func extract_data(_ o: Dictionary<String, Any>) -> DebtRec {
func val2str(_ v: Any) -> String {
if let vs = (v as? String) {
return vs
}
else if let vi = (v as? Int) {
return String(vi)
}
else {
return "null"
}
}
let dr = DebtRec()
let c = o["company"]!
if let company = (c as? Dictionary<String, Any>) {
dr.company = val2str(company["name"]!)
} else {
dr.company = val2str(c)
}
let pp = o["phones"]
if let pp = (pp as? Array<Any>) {
for p in pp {
dr.phones.append(val2str(p))
}
}
else if pp != nil {
dr.phones.append(val2str(pp!))
}
let p = o["phone"]
if p != nil {
dr.phones.append(val2str(p!))
}
if let d = o["debt"] {
if let dd = (d as? Double) {
dr.debt = dd
}
else if let ds = (d as? String) {
dr.debt = Double(ds)!
}
}
return dr
}
main()Rust:
//[dependencies]
//serde_json = "1.0"
use std::collections::{HashMap, HashSet};
use serde_json::Value;
const FILE_BUFFER_SIZE: usize = 50000;
//source data
struct DebtRec {
company: String,
phones: Vec<String>,
debt: f64
}
//result data
struct Debtor {
companies: HashSet<String>,
phones: HashSet<String>,
debt: f64
}
struct Debtors {
all: Vec<Debtor>,
index_by_phone: HashMap<String, usize>
}
impl DebtRec {
fn new() -> DebtRec {
DebtRec {
company: String::new(),
phones: Vec::new(),
debt: 0.0
}
}
}
impl Debtor {
fn new() -> Debtor {
Debtor {
companies: HashSet::new(),
phones: HashSet::new(),
debt: 0.0
}
}
}
impl Debtors {
fn new() -> Debtors {
Debtors {
all: Vec::new(),
index_by_phone: HashMap::new()
}
}
}
fn main() {
let mut res = Debtors::new();
let mut fflag = 0;
for arg in std::env::args() {
if arg == "-f" {
fflag = 1;
}
else if fflag == 1 {
fflag = 2;
println!("{}:", &arg);
let tbegin = std::time::SystemTime::now();
let (count, errcount) = process_file(&arg, &mut res);
println!("PROCESSED: {} objects in {:?}, {} errors found", count, tbegin.elapsed().unwrap(), errcount);
}
}
for (di, d) in res.all.iter().enumerate() {
println!("-------------------------------");
println!("#{}: debt: {}", di, &d.debt);
println!("companies: {:?}\nphones: {:?}", &d.companies, &d.phones);
}
if fflag < 2 {
println!("USAGE: fastpivot -f \"file 1\" -f \"file 2\" ...");
}
}
fn process_file(fname: &str, res: &mut Debtors) -> (i32, i32) {
use std::io::prelude::*;
let mut count = 0;
let mut errcount = 0;
match std::fs::File::open(fname) {
Ok(file) => {
let mut freader = std::io::BufReader::with_capacity(FILE_BUFFER_SIZE, file);
let mut obj = Vec::new();
let mut braces = 0;
loop {
let buf = freader.fill_buf().unwrap();
let blen = buf.len();
if blen == 0 {
break; //EOF
}
for b in buf {
if *b == b'{' {
braces += 1;
obj.push(*b);
}
else if *b == b'}' {
braces -= 1;
obj.push(*b);
if braces == 0 { //object formed !
match serde_json::from_slice(&obj) {
Ok(o) => {
process_object(&o, res);
}
Err(e) => {
println!("JSON ERROR: {}:\n{:?}", e, &obj);
errcount +=1;
}
}
count += 1;
obj = Vec::new();
}
}
else if braces > 0 {
obj.push(*b);
}
}
freader.consume(blen);
}
}
Err(e) => {
println!("ERROR: {}", e);
}
}
return (count, errcount);
}
fn process_object(o: &Value, res: &mut Debtors) {
let dr = extract_data(o);
//println!("{} - {:?} - {}", &dr.company, &dr.phones, &dr.debt,);
let mut di: Option<usize> = Option::None; //debtor index search result
for p in &dr.phones {
if let Some(i) = res.index_by_phone.get(p) {
di = Some(*i);
break;
}
}
match di {
Some(i) => { //existing debtor
let d = &mut res.all[i];
d.companies.insert(dr.company);
for p in &dr.phones {
d.phones.insert(p.to_string());
res.index_by_phone.insert(p.to_string(), i);
}
d.debt += dr.debt;
}
None => { //new debtor
let mut d = Debtor::new();
let i = res.all.len();
d.companies.insert(dr.company);
for p in &dr.phones {
d.phones.insert(p.to_string());
res.index_by_phone.insert(p.to_string(), i);
}
d.debt = dr.debt;
res.all.push(d);
}
}
}
fn extract_data(o: &Value) -> DebtRec {
use std::str::FromStr;
let mut dr = DebtRec::new();
let c = &o["company"];
dr.company =
match c {
Value::Object(c1) =>
match &c1["name"] {
Value::String(c2) => c2.to_string(),
_ => val2str(c)
},
_ => val2str(c)
};
let pp = &o["phones"];
match pp {
Value::Null => {}
Value::Array(pp) => {
for p in pp {
dr.phones.push(val2str(&p));
}
}
_ => {dr.phones.push(val2str(&pp))}
}
let p = &o["phone"];
match p {
Value::Null => {}
_ => {dr.phones.push(val2str(&p))}
}
dr.debt =
match &o["debt"] {
Value::Number(d) => d.as_f64().unwrap_or(0.0),
Value::String(d) => f64::from_str(&d).unwrap_or(0.0),
_ => 0.0
};
return dr;
fn val2str(v: &Value) -> String {
match v {
Value::String(vs) => vs.to_string(), //to avoid additional quotes
_ => v.to_string()
}
}
}Комментарии (250)

modest_man
06.05.2019 11:16Не могли бы вы выложить файлы с данными для парсинга, чтобы попробовать запустить у себя?
veslemay
06.05.2019 11:29Rust действительно красавчик. Вы сравнивали потребление памяти? Возможно set в свифте дерево и его некорректно сравнивать с хешмапой, ведь оно требует куда большего кол-ва памяти, а свифт создан «для мобилок».

epishman Автор
06.05.2019 11:46Swift — VSZ: 205 Мб, RSS: 21 Мб
Rust — VSZ: 13 Мб, RSS: 1Мб
Все стабильно, не течет.

agalakhov
06.05.2019 11:29«Некрасивость» кода на Rust в приведенном примере возникла исключительно из-за стиля написания. Например, обработку ошибки при открытии файла на Rust можно было написать в точности таким же `if let`, как на Swift. То же самое относится и к match в проверках на None. И еще много таких мест есть. Кажется, если поправить их все, код на Rust будет даже более красивым.
epishman Автор
06.05.2019 11:37+1Согласен, недавно только понял, что деструктуризация if let Ok(o) = val нагляднее, чем у других, так как сразу виден тип переменной val.
agalakhov
06.05.2019 12:05+2Eще в таких же случаях методы типа .and_then() могут быть полезны. Или возврат ошибки из функции через оператор "?" с переносом обработки ошибок на уровень выше.
При чтении файла можно выкинуть всю возню с буферизацией и написать буквально так:
`for byte in BufReader(file).bytes()`.
Вместо `Option::None` можно писать просто `None`, так как это имя всегда импортировано. Аннотация типа в той же строке не нужна, Rust сам выведет. Вообще этот цикл лучше переписать как-то так:
`let dr = di.phones.iter().map(|p| res.index_by_phone.get(p)).any(Option::is_some);`
Тот же прием лучше использовать для итерирования по байтам: поскольку все непустые ветки завершаются одним и тем же `push()`, то имеет смысл профильтровать итератор, а потом вызвать `collect()`. Иногда такой подход повышает скорость, так как при заранее известном размере итератора вектор не будет переаллоцироваться.
Еще во многих местах лишний match на String, так как `val_to_str()` уже содержит точно то же самое. Вместо `to_string()` почти везде можно писать `into()`. В целом, кажется, я могу раза в два сократить написанное тут. И это даже если не вспоминать, что крейт `serde` содержит готовую работу с JSON, и вообще всю программу можно свести к одному вызову `from_str()`, если добавить `#[derive(Deserialize)]` к структурам. По скорости это будет очень быстро, Deserialize не делает лишних копирований и прочего.
Для переделки со строк на ссылки скорее всего достаточно просто сменить тип поля в структурах: сложная игра со временами жизни тут не требуется, достаточно просто формально это время объявить.epishman Автор
06.05.2019 12:13+1Матч на стринг не лишний, если просто написать to_string(), то serde для строковых данных выведет еще дополнительные кавычки. За все остальное — большое спасибо!
agalakhov
06.05.2019 18:31Кавычки внутри кавычек? Если так, то это где-то еще баг, и решать надо не таким способом. serde не дает дополнительных кавычек (точно знаю, у нас в продакшн он как раз на JSON). Если речь о скобках, не о кавычках, так там
#[flatten]ставится. Чуть попозже внимательно проверю, откуда что идет, при беглом прочтении не вижу.epishman Автор
06.05.2019 18:55Возможно это особенность реализации to_string() в serde_json::Value, похоже оно предназначено для презентационных целей, добавляет [], {}, "", надо просто другой метод исользовать.
epishman Автор
06.05.2019 21:13+1При чтении файла можно выкинуть всю возню с буферизацией и написать буквально так:
`for byte in BufReader(file).bytes()`.
=============
Неа, полученный байт придется анрапить, а это задержка существенная, проверял. Проще вообще читать сразу из File, своим собственным буфером, как товарищ ниже мой код переделал.
zolkko
06.05.2019 11:41Что бы чуть-чуть поменьше кода получилось в раст версии можно убрать
impl Structблоки и заменить из на:
#[derive(Default)] struct Debtor { /*... */ } // ... Debtor::default();
Думаю, что было бы справедливо использовать тип
process_file -> (isize, isize)или в swift поменять наInt32.
Ещё чисто из эстетических соображений убрать вложеность
match std::fs::File::open(fname).
Возможно для swift версии будет иметь значение замена
classнаstructи соотвествующая заменаletнаvar?epishman Автор
06.05.2019 11:49Спасибо, не знал что дерайв дефолт и коллекции умеет инициализировать.
Структуры в Swift передаются по значению, копированием, поэтому только классы.agalakhov
06.05.2019 12:07+1Дерайвить дефолт можно для всех типов, которые имеют
impl Default, а это почти все типы стандартной библиотеки. В том числе все коллекции, которые могут быть пустыми.

V1tol
07.05.2019 00:54Структуры в Swift передаются по значению, копированием, поэтому только классы.
Это не совсем так (точнее не всегда). Структуры в Swift используют семантику copy-on-write. То есть, в коде вида
let struct = Struct(var: 5) var struct2 = struct struct2.var = 10
структура скопируется не на 2 строке, а на 3. Также есть ключевое слово inout, которое используется для передачи внутрь метода структуры через аргумент и модификации её без копирования.
Собственно, для изменения вашего кода с классов на структуры, мне понадобилось добавить всего 1 строку помимо замены ключевого слова class на struct. По производительности мне это обошлось в 1 копирование в методе process_object (и то я не увидел никакой разницы).
NishchebrodKolya2
06.05.2019 11:51-1Вы сравнили ежа с ужом, как минимум языки под разные задачи, тогда уж сравнивайте C++ и java, результат будет похожий.
epishman Автор
06.05.2019 11:54Как-то писал похожий бенч Go vs Javascript (V8), там разница 2.5 раза всего, на Java давно не писал, не знаю.
NishchebrodKolya2
06.05.2019 13:05А если попробовать более по свифтовому?
import Foundation struct DebtRec: Decodable { private enum Key: String, CodingKey { case company, debt, phones } private struct Company: Decodable { let name: String } enum Error: Swift.Error { case invalidCompany, invalidPhones, invalidPhoneItem, invalidDebt } let company: String, phones: [String], debt: Double private struct PhoneItem: Decodable { let value: String init(from decoder: Decoder) throws { let decoder = try decoder.singleValueContainer() guard let value = (try? decoder.decode(Int.self)).map({ "\($0)" }) ?? (try? decoder.decode(String.self)) else { throw Error.invalidPhoneItem } self.value = value } } init(from decoder: Decoder) throws { let container = try decoder.container(keyedBy: Key.self) guard let company = (try? container.decode(String.self, forKey: .company)) ?? (try? container.decode(Company.self, forKey: .company).name) else { throw Error.invalidCompany } self.company = company guard let phones = (try? container.decode(Int.self, forKey: .phones)).map({ ["\($0)"] }) ?? (try? container.decode([PhoneItem].self, forKey: .phones).map({ $0.value })) else { throw Error.invalidPhones } self.phones = phones guard let debt = (try? container.decode(Double.self, forKey: .debt)) ?? (try? container.decode(String.self, forKey: .debt)).flatMap({ Double($0) }) else { throw Error.invalidDebt } self.debt = debt } } func main() throws { let data = try Data(contentsOf: URL(fileURLWithPath: "__path_to_json__")) let res = try JSONDecoder().decode([DebtRec].self, from: data) } try main()epishman Автор
06.05.2019 13:23+1Не, ну так не честно.
VSZ: 1Гб
RSS: 920 Мб
Вы забрали весь файл в память, а в жизни приходится миллиарды записей обрабатывать.NishchebrodKolya2
06.05.2019 13:48Это как бы решение из коробки, очевидно перед разработчиками swift не стояла задача супер оптимизации, в rust как известно наоборот.
epishman Автор
06.05.2019 13:51Ну, в общем, да. В браузере вообще невозможно файл потоково прочитать, и приходится ради такой мелочи ноду ставить :)

PsyHaSTe
06.05.2019 13:53В расте тоже есть решение из коробки
let val = serde_json::from_str(file), только сравниваем мы вроде не стандартные функции работы с JSON, а более-менее эквивалентный код.NishchebrodKolya2
06.05.2019 14:10Почему бы нам тогда не сравнить эквивалентный код на C++ и Java, и не порадоваться какой молодец C++?
PsyHaSTe
06.05.2019 14:12Напишите, почему бы и нет? Чем больше сравнений, тем лучше.
NishchebrodKolya2
06.05.2019 14:40Там где java, с++ вообще не котируется и наоборот. По этому это Вы напишите, а мы почитаем.

XanKraegor
07.05.2019 06:09А что мешает «по-честному» декодировать таким же способом, но построчно или чанками из буфера?
agalakhov
06.05.2019 12:08C++ проиграет, если на Rust писать чисто. Потому что на ту игру со ссылками, которая нормальна в Rust с его borrow checker, ни один программист C++ в здравом уме не решится и будет копировать строки.
Сравнение Rust и Swift более чем корректно, потому что это очень похожие по синтаксису языки. Компилятор Swift мог бы быть таким же быстрым, как Rust, если бы его разработчики не халтурили.epishman Автор
06.05.2019 12:17Насколько я понимаю, в свифте любые указатели это Arc<>, может поэтому и тормоза.
NishchebrodKolya2
06.05.2019 13:11Свифт ни разу не позиционируется как самый быстрый, и корректнее было бы его сравнивать с Kotlin Native, тот вроде тоже с ARC и под мобилки.
veslemay
06.05.2019 13:59-4C++ проиграет, если на Rust писать чисто.
Везде и всюду видно обратное и именно поэтому rust целиком и полностью С/С++-зависим.
ни один программист C++ в здравом уме не решится и будет копировать строки.
И что же мне помешает? Что мешает другим? Везде и всюду не копируются, а тут вдруг кто-то сообщают обратное.
К тому же, раст состоит целиком и полностью из копирования. Там копируется всё и единственное, что ему позволяет существовать — это llvm и его оптимизации, которые выпиливают все эти копирования.
Сравнение Rust и Swift более чем корректно, потому что это очень похожие по синтаксису языки.
Неверно. Раст целиком и полностью состоит из костылей из которых не состоит тот же свифт, та же жава, сишарп — тысячи их. Как минимум там нет исключений, а значит он никому ненужен.
Компилятор Swift мог бы быть таким же быстрым, как Rust, если бы его разработчики не халтурили.
Именно компилятор раста халтура, ведь раст существует только благодаря халяве, которую даёт llvm(т.е. С++). У раста вообще нет никакого компилятора — есть огрызок фронта, который так же завязан на llvm-рантайме.
Для понимания всей нелепости раста без халявы — достаточно взглянуть на код «без оптимизаций» — это то, что генерирует «компилятор» раста. Хотя об этом я уже говорил выше.PsyHaSTe
06.05.2019 14:01+2Везде и всюду видно обратное и именно поэтому rust целиком и полностью С/С++-зависим.
Каким образом раст С-зависим? Ну не считая всяких врапперов, но это про любой язык сказать можно.
И что же мне помешает? Что мешает другим? Везде и всюду не копируются, а тут вдруг кто-то сообщают обратное.
Тут вкратце, почему не получится. Если в двух словах, то в плюсах это будет очень хрупко, и буст по перфомансу не окупит потенциальных проблем.
Неверно. Раст целиком и полностью состоит из костылей из которых не состоит тот же свифт, та же жава, сишарп — тысячи их. Как минимум там нет исключений, а значит он никому ненужен.
Ха-ха
Именно компилятор раста халтура, ведь раст существует только благодаря халяве, которую даёт llvm(т.е. С++). У раста вообще нет никакого компилятора — есть огрызок фронта, который так же завязан на llvm-рантайме.
Это плохо?

KanuTaH
08.05.2019 02:51Тут вкратце, почему не получится.
Эм… Не понял, в чем проблема. «If I wished to use a pointer I would need to be sure that the vector isn’t deallocated by the time I’m done with it» — для этого есть умные указатели. «And more importantly, to be sure that no other code pushes to the vector (when a vector overflows its capacity it will be reallocated, invalidating any other pointers to its contents)» — так не надо пихать в вектор сами строки, пихай туда указатели на строки в куче, resize вектора никак не повлияет на указатели на сами объекты. Более того, std мир не ограничивается, есть другие реализации, например, Qt с его implicit sharing, там копирование объектов из-за этого дешевое потому, что самого копирования там как такового нет (пока ты не захочешь изменить одну из копий), причем все это реализовано абсолютно прозрачно. В общем, странно мне это читать, это из разряда страшилок скорее.mayorovp
08.05.2019 09:23+2Умные указатели требуют затрат в рантайме. Поэтому на плюсах приходится выбирать между быстрыми сырыми указателями и медленными умными.
KanuTaH
08.05.2019 10:16-1Зато они работают везде, а не только в пределах вашего собственного кода.
mayorovp
08.05.2019 10:17Возвращаю вам ваш аргумент: и как же они будут работать, если владелец объекта — внешняя dll? :-)
KanuTaH
08.05.2019 10:19Эм… Куча-то у них общая, почему бы им и не работать?
mayorovp
08.05.2019 10:25Потому что внешняя dll в ситуации "codebase, так сказать, неполная" может удалить объект наплевав на все ваши умные указатели.
KanuTaH
08.05.2019 10:30-3А еще она может сделать rm -rf /. Ладно, в общем, вы скатываетесь в ту же демагогию, что и автор оригинальной статьи по ссылке, мне это не интересно. Просто имейте в виду для себя — когда вы пропагандируете rust, не делайте это так топорно. Для начинающих ваши аргументы могут показаться привлекательными, но для людей с опытом они выглядят… топорно и пропагандистски в плохом смысле. Я где-то понимаю, почему veslemay так хейтит пропагандистов rust'а :)
PsyHaSTe
08.05.2019 12:01+1для этого есть умные указатели
А вы их используете для каждой переменной? Я видел только использования, когда программист уверен, что тут они нужны.
так не надо пихать в вектор сами строки, пихай туда указатели на строки в куче
Что значит "не пихайте сами строки"? Строки это и так указатели на кучу где лежат данные, в лучшем случае они еще и длину хранят.
если есть такая опасность, то никто не мешает хранить в векторе такие же shared_ptr на атрибуты
Даже если использовать shared_ptr через shared_ptr отстрелить ногу вполне себе легко можно:
#include <memory> #include <iostream> #include <functional> std::function<int(void)> f(std::shared_ptr<int> x) { return [&]() { return *x; }; } int main() { std::function<int(void)> y(nullptr); { std::shared_ptr<int> x(std::make_shared<int>(4)); y = f(x); } std::cout << y() << std::endl; }KanuTaH
08.05.2019 12:04-1А вы их используете для каждой переменной?
Нет, конечно. Но автор же беспокоится, что в large codebase некий код где-то там far far away, который, возможно, и не он сам писал, может как-то что-то прощелкать в плане времени жизни. Для таких случаев использование умных указателей безусловно оправданно.
Что значит «не пихайте сами строки»? Строки это и так указатели на кучу где лежат данные, в лучшем случае они еще и длину хранят.
Ну я не знаю, что автор тут имел в виду под «when a vector overflows its capacity it will be reallocated, invalidating any other pointers to its contents», видимо, он пытается сделать что-то вроде std::vector<std::string> (а потом брать ссылки на элементы вектора) вместо std::vector<std::string*>, в общем, выглядит это либо как бред начинающего, либо как передергивание.
creker
08.05.2019 12:25std::vector<std::string*> это потенциально тормоза из-за нарушения локальности данных, а это кэш промахи и вот это вот все. Строчки же еще имеют оптимизацию, когда для коротких строк символы будут лежать внутри самого объекта, а не где-то в куче. Да и вообще, не принято в плюсах хранить указатели в контейнерах, если только это реально не нужно прямо кровь из носа. Причин для этого масса, помимо локальности данных.
Автор ведет речь о слайсах, когда мы создаем указатель с длиной на внутреннее хранилище контейнера. Прямо как string_view, который все так долго ждали в плюсах. Только вот проблема, даже с учетом иммутабельности std::string мы с этими string_view запросто можем получить все вкусности плюсов — dangling pointer и use after free. А с std::vector дело еще хуже, ибо контейнер изменяемый и внутренний буфер могут внезапно уничтожить и реаллицировать в другом месте.
Поэтому и хвалит он раст, у которого компилятор не позволит такой баг допустить. В других языках такие вещи решаются всякими сборщиками мусора. В плюсах это решается внимательными программистами и фиксами CVE, когда неизбежно что-то внимательный программист пропустит.KanuTaH
08.05.2019 12:28Строчки же еще имеют оптимизацию, когда для коротких строк символы будут лежать внутри самого объекта, а не где-то в куче.
Не понял. Контейнер по условию задачи находится в куче, строки так или иначе тоже в куче — либо в составе контейнера, либо отдельно. То, что они не находятся в памяти друг за другом — так у автора есть же требование, что при расширении контейнера и реаллокациях ссылки на строки из него не должны инвалидироваться. Тут ничего не попишешь. Не было бы этого требования — можно было бы обеспечить для них локальность без проблем.creker
08.05.2019 12:33Не понял
Почитайте про short string optimization.
так у автора есть же требование, что при расширении контейнера и реаллокациях ссылки на строки из него не должны инвалидироваться. Тут ничего не попишешь.
У него не требование, а факт того, что есть такая угроза и плюсы с ней никак не помогают. Раст помогает и ошибки допустить не позволит.KanuTaH
08.05.2019 12:37-1Почитайте про short string optimization.
Вы… это самое… сами почитайте, о чем я пишу вообще.
Раст помогает и ошибки допустить не позволит.
Вы сильно преувеличиваете возможности компилятора раста что-то там «не позволить».creker
08.05.2019 13:10Вы… это самое… сами почитайте, о чем я пишу вообще.
Все недавние комментарии о том, что вы статью не поняли. Я это вижу, поэтому решил помочь, но чего-то не помогло все равно. По идее, на одном слове «слайсы» уже должно быть все понятно.
Вы сильно преувеличиваете возможности компилятора раста что-то там «не позволить».
Пустые слова. Раст не позволит, плюсы позволят. Так эти языки работают.KanuTaH
08.05.2019 13:13Я это вижу
Не похоже.
Пустые слова. Раст не позволит, плюсы позволят. Так эти языки работают.
Пустые слова — это считать компилятор раста серебряной пулей, способной заглядывать внутрь сисколлов или сторонних библиотек без прилагаемых исходников.epishman Автор
08.05.2019 13:34Поэтому у растаманов и принято линковать все статически с lto, а сошки это моветон.
KanuTaH
08.05.2019 13:35-1Ессессно. Им пока везет, что они тихо-мирно варятся там в своем растамирке, где нет необходимости решать реальные задачи с помощью сторонних closed source библиотек, а также делать свои такие же closed source библиотеки на продажу.
KanuTaH
08.05.2019 03:41P.S. Прочитал там сносочку, кто-то рассказал гражданину про shared_ptr, но он начал придумывать новые страшилки — про «iterator invalidation» (пока ты держишь подконтрольную тебе копию shared_ptr, указывающую на вектор, вектор никуда не денется, и, соответственно, никакого iterator invalidation не будет), «someone consuming the API might take a reference of an attribute and hold on to it long enough for it to become invalidated» — если есть такая опасность, то никто не мешает хранить в векторе такие же shared_ptr на атрибуты: пока ты им владеешь, атрибут никуда не денется, даже если вектор будет полностью уничтожен. Например, такой код:
auto func() { std::vector<std::shared_ptr<std::string>> vctor; vctor.push_back(std::make_shared<std::string>("FYVA")); return vctor.back(); } int main() { auto res = func(); std::cout << *res << std::endl; return 0; }
вполне себе успешно выведет «FYVA», хотя контейнер, содержавший строку, уже был уничтожен на момент вывода.
Более того, это будет совершенно безопасно работать даже в чужом коде, который доступен тебе исключительно в виде .lib/.so/.dll (насколько я понимаю, расту для его compile-time borrow checking нужен доступ к исходникам, ничего прочекать в чужом машинном коде он не в состоянии).
Это не говоря уж о том, что в том же Qt этот атрибут (если это какой-то стандартный QString или контейнер (QList/QMap/...) или даже какой-то кастомный наследник от QObject с реализованной implicit sharing функциональностью, это несложно) можно будет просто скопировать локально через обычный конструктор копии или operator=(), и не париться — будет shallow copy.
В общем, если по чесноку, аргументы автора выглядят, мягко говоря, надуманными и действительно похожими на пропаганду в плохом смысле этого слова.red75prim
08.05.2019 09:09+2Iterator invalidation это про другое.
#include <iostream> #include <vector> int main() { std::vector<int> a; a.push_back(1); a.push_back(2); for (int &b: a) { a.push_back(b); } std::cout << "Hello, UB!\n"; for (int &b: a) { std::cout << b << "\n"; } }
Этот код компилируется без ошибок и предупреждений в GCC 4.9 c -Wall -Wextra -Wpedantic и выводит:
Hello, UB!
1
2
1
0
Некоторые операции над структурами инвалидируют итераторы, указывающие на эту структуру. Если после этого всё-таки использовать эти итераторы, то получаем undefined behavior.
Очень рекомендую проверить свой код на такие случаи.KanuTaH
08.05.2019 09:43Я прекрасно знаю, что во время итерирования нельзя менять содержимое итерируемого контейнера. Только какое отношение это имеет к изначальной проблеме "дать структуре доступ к вектору", я так и не понял. Менять вектор при итерировании по нему нельзя независимо от количества ссылок на него. Такое ощущение, что автору надо было срочно придумать хоть что-то.
mayorovp
08.05.2019 10:03Самое прямое. В C++ программист сам должен следить чтобы вектор не менялся пока на него остаются итераторы. В Rust за этим следит компилятор, что позволяет строить более сложные структуры без увеличения нагрузки на программиста.
KanuTaH
08.05.2019 10:07-1Ну вот не надо про это, что «компилятор следит». Что ваш компилятор сделает, если владелец контейнера — чужая .dll, к коду которой у вас нет доступа (а это совершенно рядовая ситуация, с которой сталкивается любой разработчик сплошь и рядом)? Ничего он не сделает и не проверит.
mayorovp
08.05.2019 10:17Как-то быстро вы перешли от двух локальных переменных к внешней dll...
KanuTaH
08.05.2019 10:20Речь не идет о «двух локальных переменных». Автор сам пишет, что, дескать, «for a smaller codebase this might be possible» просто добавить в структуру указатель на вектор, но вот если codebase большая, дескать, то будут проблемы. А если codebase не просто большая, а еще и, так сказать, неполная?
mayorovp
08.05.2019 10:26Если в документации на внешнюю dll не указано никакой информации о времени жизни своих объектов — такой dll, по-хорошему, вообще нельзя пользоваться.
PsyHaSTe
08.05.2019 11:57Чужая dll это ансейф, и тут все то же самое, что в плюсах.
А где не ансейф, там гарантии работают.
Аргумент из разряда "а что если в компьютер с вашей программой прилетит метеорит".
KanuTaH
08.05.2019 12:01Я к тому, что если вы пишете, прости господи, библиотеку, предоставляющую некий API, которую будут использовать как dll и, скорее всего, никто из использующих ее не будет ее каждый раз пересобирать, то вот эти вот все аргументы «а вдруг someone consuming the API might take a reference of an attribute and hold on to it long enough for it to become invalidated» — это как бы так себе аргумент, мягко говоря. Тут либо давать доступ к атрибутам через что-то вроде умных указателей, либо просто надеяться на то, что пользователи библиотеки напишут свой код аккуратно. Я думаю, в глубине души вы это и сами понимаете.
PsyHaSTe
08.05.2019 12:04+1Если я буду вызывать чужую dll, то я как и в плюсах лучше сделаю копию, на всякий случай.
Только это пессимистичный сценарий.
Я прекрасно понимаю о чем говорит автор. Отследить в большой системе кто что меняет нереально. Я помню функцию forEach, в которой в реализации копировался итерируемая коллекция, чтобы работало в случае инвалидации.
KanuTaH
08.05.2019 12:07Если библиотека написана так, что ее функции принимают и возвращают умные указатели, то в «копии на всякий случай» смысла нет. Это лишний расход ресурсов.
Я помню функцию forEach, в которой в реализации копировался итерируемая коллекция, чтобы работало в случае инвалидации
Если эта forEach рассчитана на вызов чего-то внешнего, что ты в общем случае контролировать не можешь, то копирование — да, разумная предосторожность, что на C++, что на расте. foreach из Qt (который Q_FOREACH), например, по-любому делает shallow copy итерируемого контейнера, но там, как я уже писал, все продумано, и это дешевая операция. Если автор кода, который вызывается из foreach, молодец — то практически никаких затрат не будет, если не молодец — ну, будет дополнительное копирование.PsyHaSTe
08.05.2019 12:15Библиотека обычно написана в стиле ANSI C, потому что это единственный популярный язык со стабильным ABI. Откуда там возьмутся умные указатели — загадка.
А вообще, как я уже сказал, это все вилами по воде писано. Обычное приложение не линкуется к непонятным либам по звездам. Есть обычный пакетный менеджер, в нем есть нормальные зависимости, и вот это все. В таком сценарии компилятор все нормально проверит. И это дефолт.
KanuTaH
08.05.2019 12:22Библиотеки разные бывают. Использовать ANSI C там никто не заставляет. Там может потребоваться собирать определенным компилятором, это да. А «обычное приложение» в моей практике сплошь и рядом линкуется к «непонятным либам», например, к Google AdMob, Firebase, Facebook SDK, и так далее.
PsyHaSTe
08.05.2019 12:26Библиотеки разные бывают. Использовать ANSI C там никто не заставляет. Там может потребоваться собирать определенным компилятором, это да.
За пределами плюсов им собственно мало кто пользуется. Если я хочу из C# вызвать библиотечные функци апи с умными указателями мне никак не поможет.
А «обычное приложение» в моей практике сплошь и рядом линкуется к «непонятным либам», например, к Google AdMob, Firebase, Facebook SDK, и так далее.
Да пожалуйста
https://www.nuget.org/packages/Google.Apis/
KanuTaH
08.05.2019 12:31Я к тому, что если у компилятора раста нет доступа к коду этих «непонятных либ» (хотя бы в виде IL), он вряд ли сможет что-то там прочекать с временем жизни объектов, передаваемых в них или возвращаемых из них. Даже если сами эти библиотеки будут написаны на Rust, а потом собраны в .dll, это никак им не поможет. Привет, unsafe.
PsyHaSTe
08.05.2019 12:32+1Эмм, если мы на плюсах подключаем С++ либы, то на расте мы подключаем раст либы. Если либа написана на расте, то компилятор её уже провалидировал.
Я не понимаю поинта.
KanuTaH
08.05.2019 12:35Внутри она, возможно, и провалидирована, но вот в этой библиотеке, скажем, есть экспортированная функция, которая возвращает указатель на что-то. Компилятор в момент сборки этой библиотеки не может знать, как дальше этот указатель будет использован, и не может проверить, какое у него будет время жизни.

vitvakatu
08.05.2019 13:10Валидировать время жизни указателя будет, очевидно, компилятор при сборке приложения, которая эту библиотеку использует. Библиотеке само собой об этом знать не нужно. Инкапсуляция, все дела.
KanuTaH
08.05.2019 13:11Очевидно, он не сможет этого сделать без исходного кода библиотеки в том или ином виде. Исходники коммерческих библиотек никто раздавать, само собой, не будет ради этого.
epishman Автор
08.05.2019 13:48Ничего не понял. Если либа возвращает растовую ссылку, то владелец этой ссылки должен быть не в либе, а в коде, использующем либу — он владельца и прибъет. Разве может быть ситуация, что из либы возвращается ссылка, и владелец этой ссылки сидит внутри либы? У меня компилятор ругается, что «объект не живет долго».
KanuTaH
08.05.2019 13:54-2:))) Да ужж, при таком подходе забавно было бы посмотреть на чисто растовский аналог обычной библиотечной функции для работы с памятью типа malloc(). Для библиотек вообще-то создавать некие свои ресурсы и возвращать на них указатели или хэндлы для дальнейшего использования в этой же библиотеке (а затем и освобождения) — это нормальная практика. Не всегда можно требовать, чтобы владелец ссылки в коде, использующем либу, вообще был в курсе, сколько памяти нужно выделить под соответствующий объект, например. Не его это собачье дело.
P.S. И, кстати, что такое «владелец»? В графе, например, или в двусвязном списке, кто чей владелец?
P.P.S. Растаман у меня (сорри, конечно, но не могу удержаться) ассоциируется с человеком в смирительной рубашке в кресле-каталке, которыйходитездит не туда, куда ему нужно, а туда, куда повезет санитар, но зато счастлив, что не может случайно упасть и ушибить коленку. При этом вероятность разбить коленку по факту все равно никуда не девается потому, что это в любой момент могут сделать многочисленные окружающие.epishman Автор
08.05.2019 14:10PsyHaSTe более компетентен в расте, насколько моих знаний хватает — любая функция может вернуть либо копию данных, либо указатель на память, выделенную до вызова этой функции, возможно есть исключения, не знаю.
Графы и списки — это ж известный траходром раста, там специальные контейнеры для этого запилили :)KanuTaH
08.05.2019 14:13любая функция может вернуть либо копию данных, либо указатель на память, выделенную до вызова этой функции, возможно есть исключения, не знаю.
Видимо, через пресловутый unsafe исключения и запиливаются.
Графы и списки — это ж известный траходром раста, там специальные контейнеры для этого запилили :)
Не удивлен вообще нисколько.
PsyHaSTe
08.05.2019 14:22+1Да ужж, при таком подходе забавно было бы посмотреть на чисто растовский аналог обычной библиотечной функции для работы с памятью типа malloc().
Да пожалуйста, смотрите
P.S. И, кстати, что такое «владелец»? В графе, например, или в двусвязном списке, кто чей владелец?
В графе нет владельца, нужно использовать shared_ptr. —
Rc<T>, арены и прочее. Пример как можно сделать здесь.
P.P.S.
Пишите на жс, там вообще все разрешено.
KanuTaH
08.05.2019 14:32-1Да пожалуйста, смотрите
Да, я посмотрел:
pub(crate) fn alloc_pages(pages: Pages) -> Result<ptr::NonNull<u8>, AllocErr> { unsafe { let bytes: Bytes = pages.into(); let addr = libc::mmap( ptr::null_mut(), bytes.0, libc::PROT_WRITE | libc::PROT_READ, libc::MAP_ANON | libc::MAP_PRIVATE, -1, 0, ); if addr == libc::MAP_FAILED { Err(AllocErr) } else { ptr::NonNull::new(addr as *mut u8).ok_or(AllocErr) } } }
Не агритесь вы так, я ничего не имею против Раста жеж. Нравится людям на нем писать — очень хорошо. Просто вот люди, которые на полном серьезе пишут, что «компилятор все за нас проверит», «компилятор гарантирует» — это… ну… Шаг влево — шаг вправо, нестандартная задача, вызов сисколла, сторонняя библиотека без исходного кода (даже и написанная внутри на том же Расте), и все — «гарантии компилятора» превращаются в тыкву сразу. Раздражает не раст, раздражает его неумелая и грубая пропаганда.epishman Автор
08.05.2019 14:37Если раст завоюет мир (что возможно), то набор паттернов проектирования, подозреваю, изменится настолько, что переживут не все :)))
github.com/rust-unofficial/patterns
PsyHaSTe
08.05.2019 14:44При чем тут пропаганда, если это работает? Да, чтобы реализовать низкоуровневую работу с памятью нужно unsafe, что дальше?
С тем же успехом весь haskell компилируется в машинный код, значит ли это что мы потеряли все что нам давали типы?..
В общем, спор ни о чем.
Programming Defeatism: No technique will remove all bugs, so let's go with what worked in the 70s. ©
Не агритесь вы так
Когда мне начинают рассказывать про смирительные рубашки и невероятную свободу, которую он дает, я вспоминаю слова кармака
KanuTaH
08.05.2019 14:50Когда мне начинают рассказывать про смирительные рубашки и невероятную свободу, которую он дает, я вспоминаю слова кармака
Ну товарищ, которому он отвечал, тоже в чем-то прав :)
Game dev people discovering Rust is pure comedy. Tweeting out all the benefits, and I'm like «Yup, all the things you mentioned are also available in C++, and you've been ignoring and criticizing them for years». ?\_(?)_/?
mayorovp
08.05.2019 14:51А что не так с процитированным вами кодом?
KanuTaH
08.05.2019 14:52Ну он как бы unsafe полностью, все вот эти «компилятор гарантирует» на нем в пролете. А иначе никак.
mayorovp
08.05.2019 15:00Этот код представляет собой аксиому, которой компилятор пользуется чтобы дать нужные гарантии относительно кода пользователя.
Иными словами, компилятор rust гарантирует что программа будет безопасно работать с памятью при условии что процитированный вами код не нарушает инвариантов.

technic93
08.05.2019 16:46+2Почему нет? Все лайфтаймы и заимствование ссылок описаны в объявлении функции. Далее есть код по одну сторону интерфейса (клиент) и по другую (библитека). Им ничего не нужно знать про друг друга — они работают через интерфейс. Есть время жизни 'static для каких-то синглетонов библиотеке. Safe Раст не возвращает голый указатель. Если мы возвращаем ссылку из функции то должны объявить её время жизни, которое зависит от времени жизни входных параметров. Или мы можем передать владение объектом наверх.
Если мы имеем дело с dll которая на Cи то нужно писать обёртку через unsafe. Ну тут серебрянной пули не существует. Либо жить на си/плюсах либо писать обёртки либо переписывать всё на раст. Очевидно что в зависимтости от ситуации и количества кода то или иное решение оптимально.

frol
06.05.2019 14:46+2Ваш комментарий ниже куда-то делся, но я на него уже подготовил ответ...
Целиком и полностью. Зависит от libc, от libc и любых других аллокаторов написаных на си. Использует компилятор и его рантайм написанный на С/С++.
libc — это лишь абстракция, где "с" в названии — это лишь история. В Redox OS (ОС на Rust) используется relibc (реализованная по большей части на Rust).
В
#[no_std]вообще без алокаторов живут (реалии встаиваемых систем). При необходимости можно алокатор свой написать и переопределить, только возникнет резонный вопрос: "а зачем?"
Использует компилятор и его рантайм написанный на С/С++.
Компилятор Rust написан на Rust. В дополнение (а там будет видно) к кодогенератору LLVM разрабатывают альтернативный кодогенератор на Rust — Cranelift (и всё-таки нет смысла сразу всё бросать и нестись всё переписывать на Rust, но планомерные качественные изменения очень даже происходят).
А пока есть одни хлеворды и серво, которое не может нарисовать хелворд без артефактов — меня эти рассуждения волнуют мало и волновать вообще не должны.
К тому же, раст состоит целиком и полностью из копирования. Там копируется всё и единственное, что ему позволяет существовать — это llvm и его оптимизации, которые выпиливают все эти копирования.
В Rust используется move-семантика по умолчанию. О каком компировании речь вообще?
Что, методичка сломалась и ответа нету?
Ответа к чему? Вопроса не звучало. Я готов увидеть Ваши патчи в компиляторы перечисленных языков и тогда будем обсуждать по делу. Исходники Rust — это единственные исходники крупного языка программирования, которые не вызывают у меня ужаса, даже более того, компилятор реализован как самый "обычный" проект на Rust и всё логично расположено и код написан с минимальным использованием магии, хорошо документирован и покрыт тестами.
Плохо это тем, что очередное пхп украв логику у llvm выдаёт достижения llvm за свои. Без это достижений — это бы пхп было пхп. А оно и было пхп.
По Вашей логике выходит, что LLVM справедливо использовать только для компиляторов С++.
epishman Автор
06.05.2019 14:50Похоже, админы забанили пользователя по чьей-то жалобе. У меня принцип — никого не минусовать, так что жалко его, смешно писал, и кое-что даже по делу было. По мне так форма выражения мыслей неважна — хоть матом, лишь бы Мысль была.
PS
Самое смешное, что Swift тоже зависит от LLVM :)
Am0ralist
06.05.2019 15:03Похоже, админы забанили пользователя по чьей-то жалобе.
у меня было желание пожаловаться когда он уже окончательно скатился, но я только комментарий написал о том, что при такой подаче искать что-либо в тексте желания не возникает. Но либо сами админы нашли, либо кто-то ещё отписался…
0xd34df00d
06.05.2019 22:34Тьфу ты, только я начал писать ответ на его комментарий недельной давности...
epishman Автор
06.05.2019 14:59> В Rust используется move-семантика по умолчанию.
========
Тут путаница какая-то у меня в голове. Если я создю структуру внутри функции, а потом ее возвращаю вверх по стеку — какие есть варианты кроме копирования? Или в другой тред передаю. Получается, что компилятор сам определяет по ситуации — мув там или копи? Со ссылками то как раз все понятно, непонятно с передачей владения.frol
06.05.2019 15:22+1Семантика — это модель, которая предоставляется программисту, в рамках которой он(а) может создавать описывать логику своей программы. Move-семантика — это про то, что после передачи владения значения из переменной А в переменную Б, обращение к переменной А не имеет смысла (в Rust — это ошибка компиляции, а в С++ — поведение не определено [UB]). С точки зрения реализации — это уже вопрос другой. Можно Move-семантику оставить моделью, а асемблер будет производить копии, но чаще всего оптимизационные компиляторы достаточно умны чтобы пользоваться этим преимуществом и избегать копий. Однако, магии не существует и на границах функций (если они не заинлайнятся), данные должны как-то через регистры и стек попасть к вызываемой функции, так что если другого выхода не будет найдено, то данные будут "копироваться".

Playa
06.05.2019 16:10в С++ — поведение не определено [UB]
Это не совсем так. Например, объекты классов из STL после перемещения являются «valid, but unspecified».frol
06.05.2019 16:24Не знал, спасибо за уточнение. Скажу честно, на С++ мне писать код просто страшно. Я думаю мне всей жизни не хватит чтобы устранить моё невежество в области специфики С++.
0xd34df00d
06.05.2019 22:35+3Что означает, что любые операции с ними, кроме вызова деструктора или оператора присваивания — UB.
mayorovp
07.05.2019 06:59Что означает, что любые операции с ними, кроме вызова деструктора или оператора присваивания — Unspecified Behavior.
Undefined Behavior тут неоткуда возникнуть.
0xd34df00d
07.05.2019 14:53Мы оба неправы.
Те операции, которые имеют предусловия — UB. Те, которые не имеют — unspecified.
PsyHaSTe
06.05.2019 15:28del
epishman Автор
06.05.2019 15:32Ну, то есть String копируется всегда, хотя по сути это указатель?
PsyHaSTe
06.05.2019 15:33+1В случае String ничего копироваться не будет, потому что это значение из кучи
Будет копироваться только сам адрес указателя, который простой int, а все инты как мы знаем проще скопировать. Контент строки остается нетронутым.
epishman Автор
06.05.2019 16:35Например, функция из библиотеки serde_json возвращает мне не String а &str. Я понимаю, что это аллоцировано где-то в куче, и владелец внутри библиотеки сидит. Но мне со ссылками неудобно, и я хочу из этого слайса сделать нормальный String. И вопрос — если я к этому &str применю to_string(), не приведет ли это к новому выделению памяти? По доке получается что приведет, а по жизни?
PsyHaSTe
06.05.2019 16:42+3Очень просто, serde-json ничего не аллоцирует. Функция не может вернуть &str на локальный объект, потому что это была бы висячая ссылка. Отсюда получаем очевидный факт, что все &str которые возвращает функция это просто слайсы, а владелец — строка, переданная в
from_str. Зиро кост, аллокаций нет.
veslemay2
06.05.2019 16:11Ваш комментарий ниже куда-то делся, но я на него уже подготовил ответ...
Я могу с вами поспорить, если адепты не будут мне мешать и пакостить, загаживая карму — отбирая у меня возможность отвечать.

Antervis
06.05.2019 16:32Компилятор Rust написан на Rust
фронтенд* компилятора RustPsyHaSTe
06.05.2019 16:40Да нет, весь компилятор. Никто не говорит, что таргетом компилятора должен быть машинный код. Таргет csc например это MSIL.
Antervis
07.05.2019 16:08Таргет csc например это MSIL.
Даже если бы это и имело практический смысл, в таком случае для запуска программы потребуется CLR, написанный на c/c++.PsyHaSTe
07.05.2019 16:39Какая разница? Надеюсь, вы не будете спорить, что csc (C Sharp Compiler) это компилятор?
Antervis
07.05.2019 17:31если брать наиболее широкое из возможных определений слова «компилятор», то формально вы правы. Но с такой терминологией препроцессор си тоже можно назвать отдельным компилятором, а clang так вообще целой пачкой. Если же говорить о компиляторе как о программе, преобразующий исходный код в исполняемые файлы, вдруг окажется, что csc — не компилятор.
PsyHaSTe
07.05.2019 17:48Спор об определениях мне не очень интересен. Майкрософт вряд ли планировал всех запутать или использовать маркетинговый трюк, чтобы все думали, что это компилятор, а на самом деле… Кстати, а что это тогда? Вроде не интерпретатор. А других вариантов и нет. Транспайлер частный случай компиляции, причем тут его правило одноуровневости языков не соблюдается, а на этом перечень исчерпан.
masai
07.05.2019 17:49Ну вот в том-то и спор, считать ли байт-код .NET исполняемым. :) Это всё философские рассуждения, которые не очень-то и принципиальны на мой взгляд.
Antervis
08.05.2019 14:22-1я бы назвал «исполняемым» «исполняемый процессором» код, а всё остальное — интерпретируемым.
PsyHaSTe
08.05.2019 14:23+1Есть лисп-машины, с тем же успехом можно сделать процессор, выполняющий net код. Что дальше?
clang получается кстати тоже интерпретируемый?
Antervis
08.05.2019 15:38вот когда появится такой процессор, тогда я поменяю свое мнение
PsyHaSTe
08.05.2019 15:42Свойство языка не меняется от того, что там где-то какой-то процессор кто-то сделал.
Кстати да, интерпретатор это штука, которой на вход поступает некий исходный код, а на выходе она его собстенно интерпретирует, выполняя команды. csc ничего не выполняет, он просто кладет некий файлик с IL-кодом. Вопрос, как так?
И про clang ответьте, пожалуйста. Тоже интерпретатор?
Antervis
08.05.2019 16:04Программа имеет смысл только тогда, когда конкретное железо (target) способно её выполнить. И в конвеере от «исходного кода на языке Rust» до выполнения 99% кода написано на с/с++. Вы комфортно обособили написанную на расте часть и обозвали её компилятором. Вот только самостоятельно эта часть не способна обеспечить выполнение кода, а значит, рассматривать её можно лишь как часть (причем очень малую) инфраструктуры.
И про clang ответьте, пожалуйста. Тоже интерпретатор?
С чего бы ради то?PsyHaSTe
08.05.2019 16:25+1С чего бы ради то?
Ну потому что clang делает ровно то же, что и растовый компилятор — собирает llvm из сишного кода.
Antervis
08.05.2019 16:38-2clang'ом обычно называют весь компилятор (набор утилит, обеспечивающих преобразование исходного кода в исполняемые файлы), включая llvm и линкер. Он написан в основном на с/с++. По аналогии, rustc написан… всё еще в основном на с/с++.
PsyHaSTe
08.05.2019 16:55clang'ом обычно называют весь компилятор (набор утилит, обеспечивающих преобразование исходного кода в исполняемые файлы), включая llvm и линкер
llvm это llvm. Линкер же и в расте есть.
По аналогии, rustc написан… всё еще в основном на с/с++.
Раст вообще никогда не был написан на С++. Раст написан на самом расте, и отбутстраплен с OCaml, а никак не с плюсов.


creker
06.05.2019 12:43В первую очередь тут не так допущение, что в свифте нет сборщика мусора. Он есть и зовётся автоматическим подсчётом ссылок или ARC. Как показывает теория и практика это один из самых медленных видов сборки мусора. Не так давно была любопытная работа о реализации юзерлевел драйвера сетевой карты. Свифт проиграл всем — си, расту, сишарпу, гоу. Чрезвычайно сильно проиграл. Как раз из-за подсчёта ссылок. Последние два при этом были недалеко от раста что по скорости, что по латентности. Сишарп только посильнее проигрывал
epishman Автор
06.05.2019 13:06Спасибо. Я почему заинтересовался — в Rust ведь тоже активно пользуют счетчики ссылок Rc и Arc, особенно в многопоточном программировании с разделяемым состоянием. Теперь буду избегать счетчиков всеми силами :)
TargetSan
06.05.2019 13:14+2В Rust их в очень многих случаях можно избежать. В многопоточке они используются для целей шаринга состояния. Обычно это одна копия на задачу, что, как правило, почти незаметно. А вот в Swift, насколько я понимаю, любое ссылочное значение это
Arc<_>.
creker
06.05.2019 15:02+1Счетчики разные бывают и есть подозрение, что причина тормозов в их универсальности в свифт. Там же сразу сделано с прицелом на потокобезопаность, а значит куча атомарных операций. Если посмотреть на swift_retain и swift_release, то там найдется довольно нетривиальный код даже в fast-path с атомарными инструкциями и циклами. Это при том, что еще есть slow-path. И такие вызовы компилятор пачками повсюду вставляет везде, где хоть как-то фигурируют объекты, покрываемые ARC. Да еще и не инлайнится это все что, как правило, делают в более продвинутых сборщиках мусора, где есть барьеры.
В С++ shared_ptr тоже не жалуют по той же причине — он медленный.
В Rust все таки философия такая, что правила владения максимально исключают необходимость в ручном управлении памятью, а счетчики вообще как крайний вариант используются.
modest_man
06.05.2019 15:19+2В вашей реализации тормозят не счетчики ссылок, а сравнение строк, хэширование и преобразование типов.
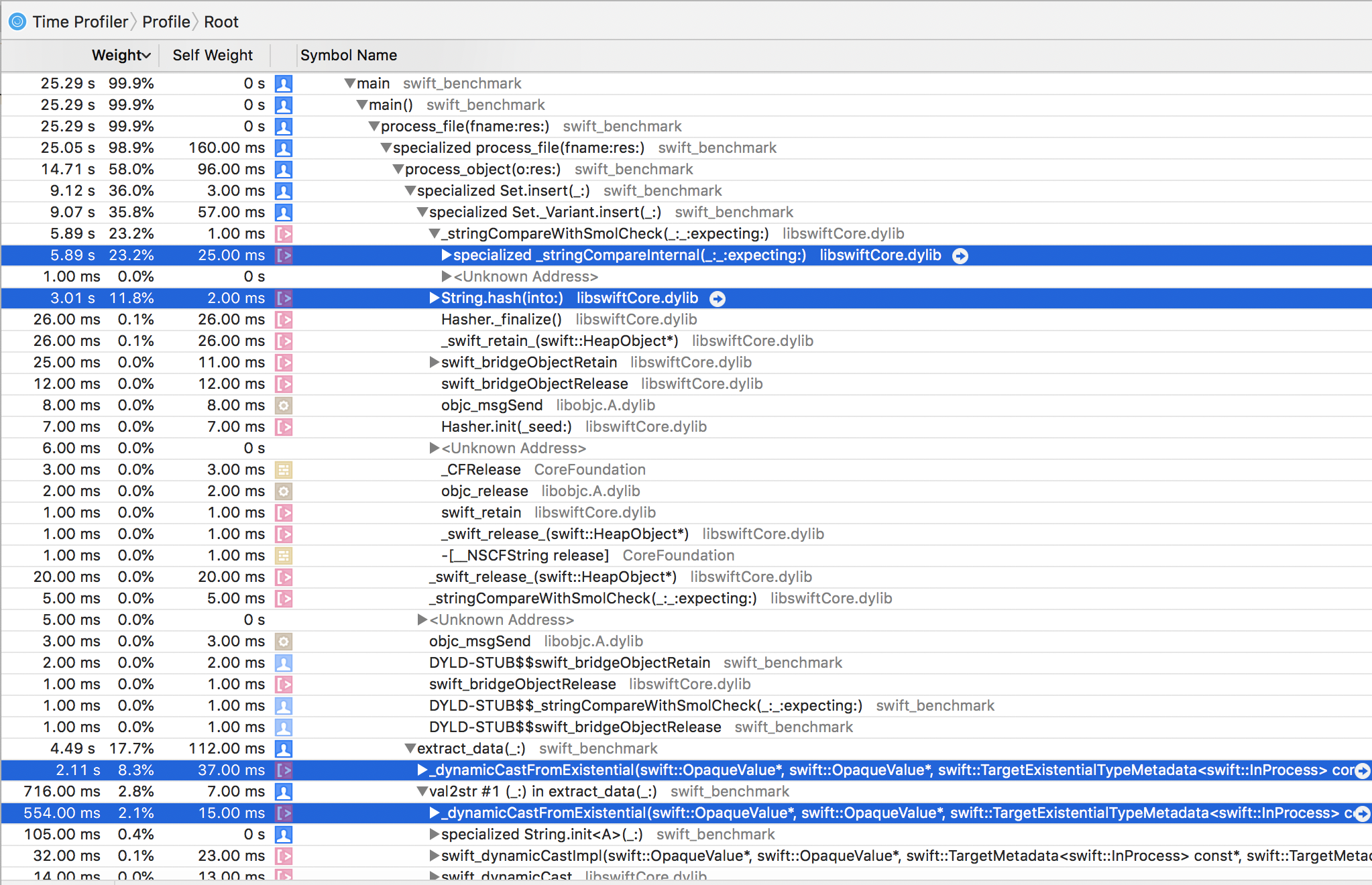
См. скриншот из профайлера: habrastorage.org/webt/9z/ja/gv/9zjagvgpfto07vw_mwsdav40zts.pngepishman Автор
06.05.2019 15:26Класс. Ну, сравнение строк и хеширование не отменить, а про приведение типов я догадывался. Непонятно правда, как работать с Any иначе, чем описано в документации is? / as?, это ж общее место для всех языков — Object в Java, interface{} в Go, возможно это грабли конкретной реализации Any в конкретном Swift, я-то этот язык толком не знаю.
creker
06.05.2019 15:50Ну да, но подсчет ссылок подкосил результаты тоже прилично. Если копнуть глубже, то везде в профайле фигурируют вызовы рантайма с довольно приличными паузами. Еще хуже в самой процедуре хэширования — почти половину ее времени выполнения занимают манипуляции со ссылками, которые уходят аж в CoreFoundation. Тоже самое со сравнением — на манипуляции райнтайма уходят секунды. Хотя тут стоит признать, что если бы все бриджи до Foundation и CoreFoundation убрать, то эти бы секунды скорее всего исчезли.

iushakov
07.05.2019 00:03Это для какой версии macOS и Swift? У меня вот так (https://habrastorage.org/webt/tk/4e/ji/tk4ejimhubxqfrilanvyrje_rlm.png), правда я исправлял несколько проблем.
{kind=link}
Mistand
06.05.2019 13:265) В Rust встречаются кривые синтаксические конструкции, например если нужно проверить значение JSON на пустоту, приходится писать один из 2-х смешных бредов:
docs.serde.rs/serde_json/value/enum.Value.html#method.is_null
Зачем?epishman Автор
06.05.2019 13:27Ну понятно, добрый дядя реализовал этот метод. Но хочется поддержки языка. Были обсуждения сделать опции енама отдельными типами, но статус сего непонятен.

domix32
06.05.2019 13:46Мне кажется немного покурив доку можно при помощи процедурных макросов избавиться от подобного, оставив обработку недрам
serde. Правда не уверен, что это можно сделать потоково.
PsyHaSTe
06.05.2019 13:50+1Бинарник получился не маленким — 1,9 Мб, зато он один (про тупой линковщик Rust известно давно, обещaют починить).
Запускали с lto=true? Дебажные символы оставляли? Все это дает размер. Подробнее здесь.
Опциональный тип данных Swift (а также оператор приведения типов) сделаны синтаксически более изящно, через постфиксы ?! — в отличие от неуклюжего растового unwrap()
В коде не должно быть unwrap, если только вы не знаете чего-то, чего не знает компилятор, например, что значение всегда есть. Да и вообще в программе встречается 2 раза, и хорошо, что видно, где программа может упасть.
В Rust встречаются кривые синтаксические конструкции, например если нужно проверить значение JSON на пустоту, приходится писать один из 2-х смешных бредов:
…
хотя напрашиваются очевидные варианты:Зачем плодить сахар на ровном месте? Зачем писать
if myVal is Nullеслиif let Null = myValименно это и делает? Два одинаковых способа в языке делать одно и то же обычно не поощряется, особенно когда разница в одно ключевое слово.
Попробую в свободное время покрутить реализацию, вам рекомендую добавить по крайней мере lto=true и сравнить еще разок.
epishman Автор
06.05.2019 13:55Спасибо, со всем согласен, но как сказать расту, что я хочу сделать проверку на НЕ-НАЛ?
if !(let Null = myVal)
или
if let Null != myVal
возможно, конечно, что это единственные грабли, или я чего не знаю.PsyHaSTe
06.05.2019 13:56Есть пропозал, но его статус пока не очень понятен: https://github.com/mbrubeck/rfcs/blob/if-not-let/text/0000-let-else.md
epishman Автор
06.05.2019 13:58Супер!
PsyHaSTe
06.05.2019 14:00+2Ну и да, всегда можно написать макрос, в данном случае сделано за нас: https://crates.io/crates/derive_is_enum_variant
veslemay
06.05.2019 14:06-4Запускали с lto=true?
Это не лто, а «лто» — оно не особо поможет. А даже если бы это было настоящие лто, то оно бы расту так же не помогло, ведь он состоит из косвенных вызовов на 99%, а значит llvm без девиртуализации никакогда не узнает — какую именно функцию код может вызвать.
В коде не должно быть unwrap
unwrap — это основа раст-пропаганды. Без unwrap через unwrap раст-портянки будут попросту километровым нечто. Аналогично с expect, когда его везде пихают в надежде, что неофиты/сторонние наблюдатели подумают, что там есть исключения.PsyHaSTe
06.05.2019 14:12+1Это не лто, а «лто» — оно не особо поможет. А даже если бы это было настоящие лто, то оно бы расту так же не помогло, ведь он состоит из косвенных вызовов на 99%, а значит llvm без девиртуализации никакогда не узнает — какую именно функцию код может вызвать.
Эмм, это вообще какой-то поток сознания.
Вы сейчас линкуете все подряд, и жалуетесь на большой бинарь.
Для сравнения, когда я писал бота с http сервисом, релиз сборка весила 130 мегабайт, с lto — 6. Как по мне, разница существенная.
unwrap — это основа раст-пропаганды. Без unwrap через unwrap раст-портянки будут попросту километровым нечто. Аналогично с expect, когда его везде пихают в надежде, что неофиты/сторонние наблюдатели подумают, что там есть исключения.
Да ну? Открываем https://doc.rust-lang.org/std/option/enum.Option.html#method.unwrap
In general, because this function may panic, its use is discouraged. Instead, prefer to use pattern matching and handle the None case explicitly.
Где же раст пропаганда?
PsyHaSTe
06.05.2019 14:17+2Только что проверил,
без lto:2,61 MB (2 737 543 bytes)
с lto:1,04 MB (1 101 258 bytes)
Собирал
stable-x86_64-pc-windows-gnu - rustc 1.34.1 (fc50f328b 2019-04-24)
veslemay
06.05.2019 14:18-4Эмм, это вообще какой-то поток сознания.
Т.е. адепт раста не осилил понять, вернее осилил и слился, а проблема моя? Почему адепт не знает что такое thinlto и какие у него есть ограничения, но пытается со мною спорить? Мануал есть, написан.
Вы сейчас линкуете все подряд, и жалуетесь на большой бинарь.
Лично я ничего не линкую.
Да ну? Открываем doc.rust-lang.org/std/option/enum.Option.html#method.unwrap
Ну, открываем и? Открываем любой раст-портянку из любой раст-агитки и видим там unwrap через unwrap через expect.
Где же раст пропаганда?
К чему вы это процитировали? Очевидно, что у любой пропаганды созданы пути отхода. В этом суть пропаганды, что она неявная. Эта портянка не являются частью любой раст-портянке, которая используется в пропаганде. В этом смысл.
Что человек, который привык к исключениям и прочему видя это думает, что «так пишут код», но так код не пишут. И именно этим занимается пропаганда, что она выдаёт неюзабельные портянки за «полноценные».
А если мы начинаем заменять всё это на матчи, то портянка из 100строк превращается в 250. На это и делается расчёт.
PsyHaSTe
06.05.2019 14:55+1Вообще отвечать хаму такое себе, но завершая начатое
Это не лто, а «лто» — оно не особо поможет. А даже если бы это было настоящие лто, то оно бы расту так же не помогло, ведь он состоит из косвенных вызовов на 99%, а значит llvm без девиртуализации никакогда не узнает — какую именно функцию код может вызвать.
На всю стандартную библиотеку динамическая диспетчеризация используется ровно в 38 файлах:
epishman Автор
06.05.2019 14:33+1lto=true
Бинарь 940 Кб, то есть экономия более чем в 2 раза
Почему-то прохождение теста немного ускорилось — 3.95 сек, возможно экономия на чтении бинаря.PsyHaSTe
06.05.2019 14:35+2Компактный бинарь всегда более кэш-френдли, это имеет небольшое влияние на производительность.
Кстати, для замеров раста рекомендую использовать criterion.
0xd34df00d
06.05.2019 22:39Нет, не всегда. У вас же нет цели весь бинарь в кеш загнать.
Гы, в раст портировали хаскелевский критерион, прикольно.

potan
06.05.2019 15:57Подсчет ссылок часто медленнее — ссылки надо инкрементить/декрементить при каждом присваивании и выходе из области видимости, хуже того, это надо делать атомарными операциями.
Преимущество в том, что накладные расходы размазаны по времени работы, а у gc они появляются в самый неожиданный момент времени (вообще говоря у счетчика ссылок тоже может возникнуть непредсказуемая задержка, если освобождается сразу длинная цепочка объектов, но все-таки это меньше, чем в GC).creker
06.05.2019 16:02У современных параллельных сборщиков расходы тоже размазаны по времени и практически все этапы идут параллельно выполнению кода. Нужные только где-то две паузы на считанные миллисекунды, а то и сотни микросекунд.
Преимущество подсчета ссылок только в том, что расход памяти под контролем и предскауемые задержки. Тем не менее эти задержки могут быть очень большие из-за упомянутых цепочек объектов. Да и циклические ссылки не имеет разруливать.

nuclight
06.05.2019 16:08Протестируйте на своём железе версию на Perl — у меня менее 10 секунд, хотя язык скриптовый, сборщик мусора тоже подсчетом ссылок (как и Swift), и код значительно короче обеих в статье.
#!/usr/bin/perl use v5.12; use warnings; use JSON::XS; use List::Util qw(first); use Time::HiRes 'time'; my $jsontext; my $t0 = time; die "Specify input file as first argument" unless defined $ARGV[0] && -f $ARGV[0]; open FH, "<", $ARGV[0] or die "Can't open input file $ARGV[0]: $!"; # slurp all file at once :) { local $/ = undef; $jsontext = <FH>; close FH; } my $t1 = time; say "read file in " . ($t1-$t0) . " sec"; my $data = decode_json $jsontext; my $t2 = time; say "decoded JSON in " . ($t2-$t1) . " sec"; my (@debtors, %by_phone); for my $rec (@$data) { my ($name, @phones, $di); if (ref $rec->{company}) { # XXX only HASH $name = $rec->{company}->{name}; } else { $name = $rec->{company}; } push @phones, $rec->{phone} if exists $rec->{phone}; if (ref $rec->{phones}) { push @phones, @{ $rec->{phones} }; } else { push @phones, $rec->{phones}; } my $ph = first { exists $by_phone{$_} } @phones; if (not defined $ph) { push @debtors, { companies => [ $name ], debt => 0, phones => { map { $_ => 1 } @phones }, }; $di = $#debtors; $by_phone{$_} = $di foreach @phones; } else { $di = $by_phone{$ph}; push @{ $debtors[$di]->{companies} }, $name unless scalar grep { $_ eq $name } @{ $debtors[$di]->{companies} }; $debtors[$di]->{phones}->{$ph} = 1; foreach (@phones) { die "Oops! consistency error... $_ $di" if defined $by_phone{$_} and $by_phone{$_} != $di; $by_phone{$_} = $di; $debtors[$di]->{phones}->{$_} = 1; } } $debtors[$di]->{debt} += $rec->{debt}; } my $t3 = time; say "aggregated in " . ($t3-$t2) . " sec"; $" = ", "; for my $debtor (@debtors) { say "\nCompany names:\t@{ $debtor->{companies} }"; say "Total debt:\t$debtor->{debt}"; say "Phone numbers:\t@{[sort keys %{ $debtor->{phones} }]}"; } say "\nTotal " . (time-$t0) . " sec";epishman Автор
06.05.2019 16:46read file in 0.0822980403900146 sec
decoded JSON in 1.64080214500427 sec
aggregated in 7.59123682975769 sec
Wide character in say at ./fastpivot.pl line 78.
…
Total 9.31448316574097 sec
==================
Это похоже на правду, подобные цифры демонстрирует у меня Javascript. Что ставит вопрос — а так ли уж нужны компилируемые языки для прикладного программирования (го ?). А что касается перла — да, он очень крут.nuclight
06.05.2019 16:54Ну, на самом деле, там модуль JSON::XS написан на Си — впрочем, Javascript поступает аналогично. Если заменить на JSON::PP, на моем железе парсинг был 143 секунды и около полгигабайта памяти. Но агрегация всё равно остается около 7 секунд, т.е. шаги 3+4 в статье — непонятно, почему Swift, будучи более типизированным, не ускоряется от этого.
epishman Автор
06.05.2019 16:59Тут приводили скрин профайлера — видно что именно кастинг типов и тормозит, изначально то мы имеем Any, который нужно приводить к строкам и числам, а дайнамик кастинг — это видно сильная сторона именно перла.
creker
06.05.2019 17:14Там все сложнее. Многие вызовы свифта уходят в недра Foundation и CoreFoundation библиотек, а это ObjC и С. Там куча рантайм вызовов, жрущих буквально секунды времени на бриджинг между разными языками.
RomanKerimov
06.05.2019 19:53Так в линуксовской реализации Foundation вроде ж нет ObjC.
creker
06.05.2019 20:01Я запускал под макосью, как и товарищ со скрином выше, чтобы профайл посмотреть. Что там будет под линуксом это вопрос хороший. Тот же JSON парсер под максью уходит в NSJSONSerialization.
PsyHaSTe
08.05.2019 12:23+1Что ставит вопрос — а так ли уж нужны компилируемые языки для прикладного программирования (го ?)
Интерпретируемые языки всегда очень быстры, когда все, что они делают — вызывают скомпилированный сишный код.
nuclight
06.05.2019 21:13+1В Telegram подкинули более быстрый вариант, который решает задачу «как хотели», не читая файл целиком: gist.github.com/jef-sure/dba9779610505f30d70e5c3d82be1ea6 (правда, там использован другой трюк — отображение файла сразу в память)
epishman Автор
06.05.2019 21:26+1Ну вот, Perl и Rust реальные конкуренты на хайлоад, остальные языки слились :)
nuclight
06.05.2019 21:55А как же модные JavaScript и Go?
epishman Автор
06.05.2019 22:07По жаваскрипту я делал замеры, у меня в блоге 3 статьи на эту тему, короче, миллион объектов он за 9 секунд агрегирует, то есть где-то в 2.5 раза медленнее раста получается. На гошке я почти не писал, может изнасилую себя и сделаю тест, не знаю.
frol
06.05.2019 17:29+2Я немного подчистил Rust реализацию в плане идиоматических конструкций (как я это вижу): https://gist.github.com/frol/547f36c5f736f3651dfeac53d8fde34e (174 строки кода, если это важно)
Мне всё ещё не нравится:
- именование переменных
- обработка ошибок
- глубина лесенки в некоторых местах (но я не стал дробить код)
P.S.
obj.clear()вместоobj = Vec::new()дало ~13% ускорение за счёт переиспользования буфера вместо деалокации старого и алокации нового буфера.epishman Автор
06.05.2019 18:49Спасибо, очень приятный код. Исполнение 3.5 секунды. Про clear() не знал.
PS
Что касается map — ну не люблю я этого, в JS объелся. Цикл же нагляднее, понятно в каком месте преждевременно выходим, не нужно помнить спецификации map() на всех языках. Единственное ЗА — это возможность оптимизации (в т.ч. распараллеливания), но похоже Rust этого не умеет?vitvakatu
06.05.2019 19:06+2Умеет, с помощью библиотеки Rayon, например. Насчет итераторы vs циклы я с вами не соглашусь.
Во-первых, во всех языках map действует одинаково и поддерживает вполне определенные инварианты. Чтобы понять, что получается в цикле — надо его полностью распарсить глазами. Чтобы понять, что на выходе итератора — достаточно прочитать только названия методов и убедиться в том, что map, например, трансформирует каждый элемент из одного типа в другой, но никогда не добавляет новых элементов и не удаляет старых.
Кроме того, Rust отлично оптимизирует итераторы, убирая проверки на выход за границы коллекций.
epishman Автор
06.05.2019 19:49Ну не знаю. Если читать буквально Ваш код — мы сначала отфильтровали массив (то есть пробежались по всем телефонам), а потом взяли первый элемент результата. Я понимаю конечно, что мы выходим из цикла досрочно, и это «досрочно» стоит в самом конце… в общем, пока не могу привыкнуть.
PS
Впрочем, согласен, par_iter() это то что надо!a1ien_n3t
06.05.2019 20:11+2Нее у нас ленивое вычисление. Мы никуда не бежим вначале.
P.S. Ааа я понял вы имелли виду что это не сразу понятно из кода. Тогда да надо привыкнуть, что мы небудем ничего делать пока явно это не попросим.
frol
06.05.2019 19:06+2Единственное ЗА — это возможность оптимизации (в т.ч. распараллеливания), но похоже Rust этого не умеет?
rayon умеет. То есть простая замена
.iter()на.par_iter()и магия работает. Но в данном случае нужно найти первое вхождение, так что смысла в этом мало. Если бы это было узким местом, то стоило бы заменить вектор (с его линейным поиском) на hashmap.
NishchebrodKolya2
06.05.2019 18:09-2Вот бы на Go кто написал тест, который как известно быстрее Rust.
epishman Автор
06.05.2019 18:51Может и напишу. Хотя, гошник бы потратил в 10 раз меньше времени чем я, вспоминая как чего там называется. Да и не люблю я Go, эстетически.
iushakov
06.05.2019 21:48+21) Буферизованное посимвольное чтение файла, потоковый парсинг и выделение объектов из массива.
Если в случае Rust это видимо так, то в случае Swift никакого буфера для чтения не используется. Мало того, на каждый вызов чтения вы создаете новый Data объект.
Если это заменить на InputStream, то становится 13 секунд (https://gist.github.com/ivan-ushakov/65ad074216e33f222b6a572069e4e8f5). Это по прежнему много, но тут проблема в том что текущий парсер JSON не сохраняет информацию о типе при разборе, и вынуждает использовать as? для логики, что выливается в _dynamicCastFromExistential, который занимает много времени, судя по отчету Time Profiler.
Еще не очень корректно сравнивать язык с постоянным ARC, и язык где ARC можно использовать только когда он нужен. В вашем коде Swift почти не предпринято усилий по минимизации создания объектов в куче.epishman Автор
06.05.2019 21:58О! Очень дельный комментарий. Я так и предполагал, что в Swift нужно хорошо разбираться, чтобы писать оптимально, иначе выстрел в ногу. То, что я Data повторно создаю — на эти же грабли я наступил в Rust, и мне уже объяснили, что надо не пересоздавать объект, а просто его очищать, тогда релокации не происходит.
Что касается типа Any — это кстати очень хороший довод в пользу алгебраических типов Rust, где нет корневого типа (в отличие например от Go, где он есть interface{}, и наверняка так же долго кастится). А в растовом enum получается, информация о типе сохраняется, потому что там кастинг проходит быстро.
PS
13 и 4.5 секунды — это уже нормальная, объяснимая разница.
PPSS
Специалисты смогли ускорить мой код на Rust всего до 3.5, видимо потому что вариантов написать по другому значительно меньше, компилятор злой :)
Gorthauer87
06.05.2019 22:31В Swift же тоже есть аглебраические типы данных
epishman Автор
06.05.2019 22:54Ну тогда надо использовать. Вот как в расте выглядит значение JSON (и никаких Any):
enum Value {
Null,
Bool(bool),
Number(Number),
String(String),
Array(Vec),
Object(Map<String, Value>),
}V1tol
07.05.2019 01:03В таком случае в Swift тоже нужно искать библиотеку для парсинга JSON не использующую встроенный в Foundation парсер. А для Swift таких библиотек и нет, нашлась разве что discontinued github.com/tyrone-sudeium/JSONCore
iushakov
07.05.2019 10:28Вот версия на 5.7 секунд — gist.github.com/ivan-ushakov/ee8257e5bb3e8c872f2f07c712e76972. Свел вызовы dynamicCast к минимуму.
epishman Автор
07.05.2019 10:55Да, Вы волшебник, я подозревал что-то в этом роде.
PS
if d.phones[p] != nil {
d.phones[p] = 1
}
Я стараюсь таких вещей избегать, если компилятор тупой, он по идее должен дважды хеш брать от p, но, выходит, не берет.V1tol
07.05.2019 18:40+1Перепроверил — с кастомным типом переменной p хэш при таком коде вычислится дважды. Хотя возможно, что в Swift хеши для строк кешируются и в этом месте не будет провалов по производительности.
PsyHaSTe
08.05.2019 00:04+1Ради интереса выпилил весь ужасающий парсинг, заменив на дефолтные растовые возможности. Стриминг при этом не потерялся. Попробуйте это забенчить, интересно, что у вас выйдет:
https://gist.github.com/Pzixel/4427eb6641cbd092621ea91c5fd0db82
P.S. Также попробовал полностью с нуля переписать, адекватно, с парсингом, но забил после того, как увидел, что у вас в некоторых случаях phones приходят из двух разных полей, причем они могут оба в одном объекте быть. К такому жизнь serde не готовила :) Но если интересно, то практически все варианты нормально парсятся вот здесь: https://gist.github.com/Pzixel/0460abea262574b6081dc709c9c30e26. Там можно увидеть, что почти все разбросанные данные можно распарсить в структуру, ну а дальше что с ней делать вопрос тривиальный.
epishman Автор
08.05.2019 00:335.6 секунд почему-то.
Самый быстрый вариант получился у фрола:
habr.com/ru/post/450512/#comment_20119542
PS
Я идею Вашу понял, но тут, похоже мы теряем контроль процесса, отдавая все библиотеке. У меня была долгосрочная идея — прицел на гигабайтные файлы и миллиард объектов. Соответственно, сейчас пишу сюда многопоточность, так как чтение и первичный парсинг быстрее раз в 5 чем остальное, значит можно 5 тредов запустить и раздавать объекты им в очередь. Напишу — выложу. Дальше ускоряться можно только двумя путями:
— SIMD, которого у меня нет
— выкинуть serde, и писать свой однопроходный потоковый парсинг, чтобы одним циклом по байт-буферу делать все — вплоть до агрегации, и без промежуточных структур.
PS
Спасибо большое, Вы с фролом мне очень помогли подтянуть язык, перестал брезговать функциональщиной :)PsyHaSTe
08.05.2019 00:45+1Самый быстрый вариант получился у фрола:
Я его и взял за основу. По сути я просто заменил
process_fileна стандартную функцию, остальное оставил без изменений.
Замедление в целом понятно откуда взялось, потому что теперь JSOn парсится правильно. например, что ваш парсер скажет на объект
{"company":"Рога и } копыта", "debt": 800, "phones": [123, 234, 456]},? Правильно, скорее всего помрет. А трекинг когда мы внутри или снаружи объекта и даст тут скорее всего немного лишних миллисекунд.
Если переписать абсолютно все декларативно то мб получится выжать побольше. А может и нет, надо мерить.
У меня была долгосрочная идея — прицел на гигабайтные файлы и миллиард объектов.
Никак этому не мешаю.
Соответственно, сейчас пишу сюда многопоточность, так как чтение и первичный парсинг быстрее раз в 5 чем остальное, значит можно 5 тредов запустить и раздавать объекты им в очередь. Напишу — выложу. Дальше ускоряться можно только двумя путями:
Нужно бенчить. Если у вас затык в чтении файла с диска то многопоток слабо поможет, а может и ухудшит ситуацию. Короче, проверять-проверять-проверять :)
Спасибо большое, Вы с фролом мне очень помогли подтянуть язык, перестал брезговать функциональщиной :)
Всегда пожалуйста. Декларативное описание всегда лучше императивного. Хотя бы потому, что за счет ограничений накладываемых логикой операции компилятор может дополнительно оптимизировать, самое банальное — выкинуть баунд чеки на
map. Ну и то что читать это проще вам выше уже говорили. Я про это рассказывал здесь.epishman Автор
08.05.2019 00:54Да, полностью согласен, мой парсер и не парсер вовсе :)
Надо будет изучить нормальные потоковые парсеры, вроде на си и жаве их полно, на расте нет вообще, когда-то давно при работе с XML они просто и рядом не лежали по производительности с тормознутыми DOM. Проблема, что мало людей захотят пользоваться, и путаться в аде колбэков…
epishman Автор
08.05.2019 09:53Замедление в целом понятно откуда взялось, потому что теперь JSOn парсится правильно. например, что ваш парсер скажет на объект {«company»:«Рога и } копыта», «debt»: 800, «phones»: [123, 234, 456]},? Правильно, скорее всего помрет. А трекинг когда мы внутри или снаружи объекта и даст тут скорее всего немного лишних миллисекунд.
Я таки заморочился, обрабатываю кавычки и экранированные кавычки (вроде ничего не забыл ?). Производительность упала, пришлось отказаться от второго буфера байтов (кроме случая, когда объект разорван первым буфером). Получилось немного медленней чем у frol (3.95) но все равно быстрее чем на serde.
Подозреваю, что не serde тормозит, а чтение из стрима — from_reader(), оно побайтовое с необходимостью каждый байт анрапить. Похожую проблему я обнаружил тут:
habr.com/ru/post/450512/#comment_20120520
PS
Полный код:
main.rs//[dependencies] //serde_json = "1.0" use std::collections::{HashMap, HashSet}; use serde_json::Value; const FILE_BUFFER_SIZE: usize = 100000; //source data #[derive(Default)] struct DebtRec { company: String, phones: Vec<String>, debt: f64 } //result data #[derive(Default)] struct Debtor { companies: HashSet<String>, phones: HashSet<String>, debt: f64 } #[derive(Default)] struct Debtors { all: Vec<Debtor>, index_by_phone: HashMap<String, usize> } fn main() { let mut result = Debtors::default(); let mut fflag = 0; let mut threads = vec![]; let mut tid = 0; for arg in std::env::args() { if arg == "-f" { fflag = 1; } else if fflag == 1 { fflag = 2; tid += 1; threads.push(std::thread::spawn(move || process_file(tid, &arg))); } } for t in threads { let part = t.join().unwrap(); if result.all.len() == 0 { result = part; } else { merge_result(part, &mut result); } } for (di, d) in result.all.iter().enumerate() { println!("-------------------------------"); println!("#{}: debt: {}", di+1, &d.debt); println!("companies: {:?}\nphones: {:?}", &d.companies, &d.phones); } if fflag < 2 { println!("USAGE: fastpivot -f \"file 1\" -f \"file 2\" ..."); } } fn process_file(tid: i32, fname: &str) -> Debtors { use std::io::prelude::*; let mut result = Debtors::default(); println!("thread {}: file {}", tid, fname); let tbegin = std::time::SystemTime::now(); let mut prntab = String::new(); for _ in 0..(tid-1)*3 {prntab.push('\t')} let mut allcount = 0; let mut prncount = 0; let mut errcount = 0; let mut file = match std::fs::File::open(fname) { Ok(f) => f, Err(e) => { println!("ERROR: {}", e); return result; } }; let mut buf = [0; FILE_BUFFER_SIZE]; let mut osave:Vec<u8> = vec![]; let mut i0 = 0; let mut braces = 0; let mut quotes = false; let mut backslash = false; loop { let blen = match file.read(&mut buf) { //Err(ref e) if e.kind() == std::io::ErrorKind::Interrupted => continue, Ok(0) => break, Ok(blen) => blen, Err(e) => { println!("ERROR: {}", e); return result; } }; for i in 0..blen { let b = buf[i]; if b == b'"' && !backslash { quotes = !quotes; } backslash = b == b'\\'; if !quotes { if b == b'{' { if braces == 0 { i0 = i; } braces += 1; } else if b == b'}' { braces -= 1; if braces == 0 { //object formed ! let mut o = &buf[i0..i+1]; i0 = 0; if osave.len() > 0 { osave.extend_from_slice(o); o = &osave; } match serde_json::from_slice(o) { Ok(o) => { process_object(&o, &mut result); } Err(e) => { println!("JSON ERROR: {}:\n{:?}", e, std::str::from_utf8(o)); errcount +=1; } } if osave.len() > 0 { osave.clear(); } allcount += 1; prncount += 1; if prncount == 100000 { println!("{}thread {}: {}", prntab, tid, allcount); prncount = 0; } } } } } if i0 > 0 { osave.extend_from_slice(&buf[i0..]); i0 = 0; } } println!("thread {}: file {}: processed {} objects in {:?}s, {} errors", tid, fname, allcount, tbegin.elapsed().unwrap(), errcount ); result } fn process_object(o: &Value, result: &mut Debtors) { let dr = extract_data(o); //println!("{} - {:?} - {}", &dr.company, &dr.phones, &dr.debt,); let di = match dr.phones.iter().filter_map(|p| result.index_by_phone.get(p)).next() { Some(i) => *i, None => { result.all.push(Debtor::default()); result.all.len()-1 } }; let d = &mut result.all[di]; d.companies.insert(dr.company); for p in &dr.phones { d.phones.insert(p.to_owned()); result.index_by_phone.insert(p.to_owned(), di); } d.debt += dr.debt; } fn merge_result(part: Debtors, result: &mut Debtors) { for dr in part.all { let di = match dr.phones.iter().filter_map(|p| result.index_by_phone.get(p)).next() { Some(i) => *i, None => { result.all.push(Debtor::default()); result.all.len()-1 } }; let d = &mut result.all[di]; d.companies.union(&dr.companies); for p in &dr.phones { d.phones.insert(p.to_owned()); result.index_by_phone.insert(p.to_owned(), di); } d.debt += dr.debt; } } fn extract_data(o: &Value) -> DebtRec { let mut dr = DebtRec::default(); let c = &o["company"]; dr.company = match c { Value::Object(c1) => match &c1["name"] { Value::String(c2) => c2.to_owned(), _ => val2str(c) }, _ => val2str(c) }; match &o["phones"] { Value::Null => {} Value::Array(pp) => dr.phones.extend(pp.iter().map(|p| val2str(p))), pp => dr.phones.push(val2str(&pp)) } match &o["phone"] { Value::Null => {} p => dr.phones.push(val2str(&p)) } dr.debt = match &o["debt"] { Value::Number(d) => d.as_f64().unwrap_or(0.0), Value::String(d) => d.parse::<f64>().unwrap_or(0.0), _ => 0.0 }; dr } fn val2str(v: &Value) -> String { match v { Value::String(vs) => vs.to_owned(), //to avoid additional quotes _ => v.to_string() } }
epishman Автор
08.05.2019 00:36Да, конечно я понимаю, что когда схема строгая, весь этот бред с матчингом не нужен — сразу парсим в строгую структуру, но мне хотелось понять как работает динамическая. Получается, что кастинг типов — это был основной тормоз свифта, а в расте все норм, енамы отностительно быстро матчатся, но правда не мгновенно.
PsyHaSTe
08.05.2019 00:48Ну тут можно дополнительно ускорять, убирая все String, где можно преобразуя их в u64 (например, номера телефонов, если позволяет бизнес). В общем, варианты есть. Но вряд ли они прям супер-много дадут, может еще процентов 10-20.
epishman Автор
08.05.2019 00:59Хочется раз в 100, а это только CUDA (там вроде из шейдера можно писать в разделяемую память, в отличие от шейдеров обычных), но не на каждом сервере/компе эта железка будет. На новых интелах вроде SIMD добавили в центральный процессор, но как пользоваться я пока не разобрался.
PsyHaSTe
08.05.2019 01:45+1Да тут уже вопросы к диску больше будут, чем к производительности. Больше 400МБ/сек выжать не получится никак.
С другой стороны не очень понятно, зачем такие объемы данных парсить в кривом формате.

Fr3nzy
08.05.2019 08:37-1Даже на каком-нибудь топовом NVMe, который поддерживает 2-3ГБ/с скорость (последовательное чтение, понятное дело)?
Yar_Rom
08.05.2019 13:09+2Вариант на Go, 3.5 сек gist.github.com/yarrom/bcd9c62e58463e2acc0a7efcb6a081fb
epishman Автор
08.05.2019 13:18Спасибо огромное!!!
6.73 секунды, бинарь 4.8 Мб, компилил go build main.go
В гошке я особо не сомневался, думаю, если аккуратно допилить код — сможет догнать растишку :)
NishchebrodKolya2
vitvakatuYar_Rom
08.05.2019 13:40Как разнятся результаты. Видимо, надо учитывать конфигурацию железа )))
epishman Автор
08.05.2019 14:00Не, ну вот у меня сейчас все варианты есть, даже пришлось перл поставить с либами. Пока раст в исполнении фрола выдает 3.6 секунды, и это рекорд. Кстати, измерил память гошки:
Go — VSZ:10.7 Мб, RSS: 7.7 Мб
То есть по расходу памяти у свифта нет шанса, раст чуть-чуть экономнее, напомню:
Swift — VSZ: 205 Мб, RSS: 21 Мб
Rust — VSZ: 13 Мб, RSS: 1Мб
PS
Поставьте себе раст и поиграйтесь — если сможете его почти победить — ваша статья будет сразу в топе :)
PPSS
Память не течет, тестил на гигабайтном файле, так что GC работает норм :)
tsukanov-as
08.05.2019 14:14Lua: gist.github.com/tsukanov-as/d1532303e16d757e3fa9e70ccb21d64b
Решение в лоб чтением всего файла в памятьepishman Автор
08.05.2019 14:23эмм, я такое не знаю как запустить
tsukanov-as
08.05.2019 14:38+1Могу только дать собранные бинарники под винду: yadi.sk/d/NZCzZB85qQDoIg
Это чистая Lua 5.3.5 с библиотекой: www.kyne.com.au/~mark/software/lua-cjson.php
На моей машине время 1:1 как у решения выше на Goepishman Автор
08.05.2019 14:47У меня линукс 64. Но в память это не честно, в моей задаче надо гигабайты парсить.
tsukanov-as
09.05.2019 00:59Залил новый код: gist.github.com/tsukanov-as/d1532303e16d757e3fa9e70ccb21d64b
Пардон за его страшный вид )
У меня на i5 8400 3.6 сек. и 4 мб. памяти
Память смотрел на глаз по диспетчеру, т.к. не знаю как ее мерить на винде.
Для сравнения вариант на Go у меня 2.5 сек. и 6 мб. памяти.
ps Скорее всего кривое как мои руки, но на тестовом файле вроде правильно отработалоepishman Автор
09.05.2019 09:57Получается, что гошка вторым номером идет против раста, остальные медленнее. Так всегда — гугл изобретает странные корявые продукты, но они сцуко работают быстрее, чем красивые и продуманные чужие. Хромиум хуже мозилы, но быстрее, гугловский дарт хуже тайпскрипта, но в мобилы будут пихать именно его, раст красивее гошки, но вакансий нет и т.д.
tsukanov-as
09.05.2019 10:18Есть еще LuaJit, который с учетом ffi и грязных трюков (типа mmap) думаю обойдет Go. Но, как это ни печально, он похоже умирает.
epishman Автор
09.05.2019 10:24Программирование это не музыка, где побеждает новое звучание. Это грязная корпоративная война, где побеждает влияние. Сказала одна компания что публичные методы с большой буквы надо писать, все сказали есть. А все потому, что музыкант он условно в одиночку может сделать продукт, а программистов нужно сотни, чтобы что-то реальное написать. Поэтому остается лишь встраиваться в чужие тренды.
tsukanov-as
09.05.2019 20:11Таки запустил этот код на LuaJit из любопытства.
1.5 секунды и 2 Мб памяти
ps Допускаю что ошибаюсьepishman Автор
09.05.2019 20:52А в чем трюк? Я понимаю, что избавился от промежуточной структуры, значит минус аллокация памяти. Видимо файл читается быстрее, но тут надо тестировать на одной платформе — допускаю что Линукс тормознутее винды при работе с файлами.
Я сейчас на расте достиг 2.5 секунд за счет многопоточности, если выкину промежуточную структуру, возможно с трудом в полторы втиснусь, а как Вам удается такие цифры показывать?tsukanov-as
09.05.2019 21:02Ну в коде трюк только один:
s:find("^%b{}", p)
Это хитрая луашная «регулярка», которая умеет рекурсивно искать сбалансированные скобки.
А в целом читаю файл блоками, пытаюсь этой чудо регуляркой найти сбалансированные скобки, разбираю парсером то, что нашел, оставшийся кусок блока приклеиваю к следующему и по кругу.epishman Автор
09.05.2019 21:06Ровно то же самое делаю и я. Только не забудьте, что скобка может встречаться внутри кавычек «рога и {копыта», а еще бывает экранированная кавычка, это ж json. Вот мой последний код:
main.rs//[dependencies] //serde_json = "1.0" use std::collections::{HashMap, HashSet}; use serde_json::Value; const FILE_BUFFER_SIZE: usize = 100000; const PRN_COUNT: i32 = 100000; //source data #[derive(Default)] struct DebtRec { company: String, phones: Vec<String>, debt: f64 } //result data #[derive(Default)] struct Debtor { companies: HashSet<String>, phones: HashSet<String>, debt: f64 } #[derive(Default)] struct Debtors { all: Vec<Debtor>, index_by_phone: HashMap<String, usize> } fn main() { let mut result = Debtors::default(); let mut threadcount = -1; let mut fflag = 0; for arg in std::env::args() { if arg == "-t" { threadcount = 0; } else if threadcount == 0 { threadcount = match arg.parse() { Ok(n) => n, Err(_) => { println!("ERROR: -t \"{}\" - must be an integer !", arg); break; } } } else if threadcount > 0 { if arg == "-f" { fflag = 1; } else if fflag == 1 { fflag = 2; let resultpart = process_file(&arg, threadcount as usize); if result.all.len() == 0 { result = resultpart; } else { merge_result(resultpart, &mut result); } } } } for (di, d) in result.all.iter().enumerate() { println!("---------------------------------------------"); println!("#{}: debt: {}", di+1, &d.debt); println!("companies: {:?}\nphones: {:?}", &d.companies, &d.phones); } if threadcount <= 0 || fflag < 2 { println!("USAGE: fastpivot -t <thread count> -f \"file name\" -f \"file name\" ..."); } } fn process_file(fname: &str, threadcount: usize) -> Debtors { use std::io::prelude::*; println!("file {}:", fname); let tbegin = std::time::SystemTime::now(); let mut file = match std::fs::File::open(fname) { Ok(f) => f, Err(e) => { panic!(e); } }; let mut buf = [0; FILE_BUFFER_SIZE]; let mut i0 = 0; let mut osave:Vec<u8> = vec![]; let mut braces = 0; let mut quotes = false; let mut backslash = false; let mut channels = vec![]; let mut threads = vec![]; for tid in 0..threadcount { //start threads let (send, recv) = std::sync::mpsc::channel(); channels.push(send); threads.push(std::thread::spawn(move || process_thread(recv, tid))); } let mut tid = 0; loop { let blen = match file.read(&mut buf) { //Err(ref e) if e.kind() == std::io::ErrorKind::Interrupted => continue, Ok(0) => break, Ok(blen) => blen, Err(e) => { panic!(e); } }; for i in 0..blen { let b = buf[i]; if b == b'"' && !backslash { quotes = !quotes; } backslash = b == b'\\'; if !quotes { if b == b'{' { if braces == 0 { i0 = i; } braces += 1; } else if b == b'}' { braces -= 1; if braces == 0 { //object formed ! let mut o = &buf[i0..i+1]; i0 = 0; if osave.len() > 0 { osave.extend_from_slice(o); o = &osave; } channels[tid].send(o.to_vec()).unwrap(); tid = if tid == threadcount-1 {0} else {tid+1}; osave.clear(); } } } } if i0 > 0 { osave.extend_from_slice(&buf[i0..]); i0 = 0; } } for tid in 0..threadcount { //stop threads channels[tid].send(vec![]).unwrap(); } println!("---------------------------------------------"); let mut result = Debtors::default(); let mut allcount0 = 0; let mut errcount0 = 0; for _ in 0..threadcount { let (resultpart, allcount, errcount) = threads.pop().unwrap().join().unwrap(); if result.all.len() == 0 { result = resultpart; } else { merge_result(resultpart, &mut result); } allcount0 += allcount; errcount0 += errcount; } println!("---------------------------------------------"); println!("file {}: processed {} objects in {:?}s, {} errors", fname, allcount0, tbegin.elapsed().unwrap(), errcount0 ); result } fn process_thread(channel: std::sync::mpsc::Receiver<Vec<u8>>, tid: usize) -> (Debtors, i32, i32) { let mut result = Debtors::default(); let mut allcount = 0; let mut errcount = 0; let mut prncount = 0; let mut prntab = String::new(); for _ in 0..(tid)*3 {prntab.push('\t')} loop { let o = channel.recv().unwrap(); if o.len() == 0 { break; } match serde_json::from_slice(&o) { Ok(o) => { process_object(&o, &mut result); } Err(e) => { println!("JSON ERROR: {}:\n{:?}", e, std::str::from_utf8(&o)); errcount +=1; } } prncount += 1; if prncount == PRN_COUNT { allcount += prncount; prncount = 0; println!("{}thread{}: {}", prntab, tid, allcount); } } allcount += prncount; (result, allcount, errcount) } fn process_object(o: &Value, result: &mut Debtors) { let dr = extract_data(o); //println!("{} - {:?} - {}", &dr.company, &dr.phones, &dr.debt,); let di = match dr.phones.iter().filter_map(|p| result.index_by_phone.get(p)).next() { Some(i) => *i, None => { result.all.push(Debtor::default()); result.all.len()-1 } }; let d = &mut result.all[di]; d.companies.insert(dr.company); for p in &dr.phones { d.phones.insert(p.to_owned()); result.index_by_phone.insert(p.to_owned(), di); } d.debt += dr.debt; } fn merge_result(part: Debtors, result: &mut Debtors) { for dr in part.all { let di = match dr.phones.iter().filter_map(|p| result.index_by_phone.get(p)).next() { Some(i) => *i, None => { result.all.push(Debtor::default()); result.all.len()-1 } }; let d = &mut result.all[di]; d.companies.union(&dr.companies); for p in &dr.phones { d.phones.insert(p.to_owned()); result.index_by_phone.insert(p.to_owned(), di); } d.debt += dr.debt; } } fn extract_data(o: &Value) -> DebtRec { fn val2str(v: &Value) -> String { match v { Value::String(vs) => vs.to_owned(), //to avoid additional quotes _ => v.to_string() } } let mut dr = DebtRec::default(); let c = &o["company"]; dr.company = match c { Value::Object(c1) => match &c1["name"] { Value::String(c2) => c2.to_owned(), _ => val2str(c) }, _ => val2str(c) }; match &o["phones"] { Value::Null => {} Value::Array(pp) => dr.phones.extend(pp.iter().map(|p| val2str(p))), pp => dr.phones.push(val2str(&pp)) } match &o["phone"] { Value::Null => {} p => dr.phones.push(val2str(&p)) } dr.debt = match &o["debt"] { Value::Number(d) => d.as_f64().unwrap_or(0.0), Value::String(d) => d.parse::<f64>().unwrap_or(0.0), _ => 0.0 }; dr }tsukanov-as
09.05.2019 21:16Да, решение на Lua грязное в этом плане.
Для честного разбора нужно побайтно перебирать, а это заведомо провально на интерпретаторе и даже пытаться смысла нет.
Просто перебрать побайтно файл в памяти у меня 45 секунд на Lua 5.3.5
Изначально я вообще хотел попробовать использовать SAX парсер, но не нашел такой либы.epishman Автор
09.05.2019 21:23Для раста есть подобие SAX-парсера, только оно медленнее моего алгоритма. Но если в луа регулярки сишные, то можно наверное на регулярке что-то написать. Я просто давно понял, что если нужна экстремальная производительность — лучше самому в едином цикле все сделать, чем либами обкладываться. Поэтому и раст. Тема с гошкой интересная, закончу свой многопоточный вариант, попробую доработать Ваш код, чтобы с горутинами, неужели не догонит.
tsukanov-as
09.05.2019 23:38Поставил у себя Rust и собрал этот код.
2 сек. и около 100 Мб памяти (не знаю что это значит) в 1 поток.
Процессор у меня i5 8400 6 ядер
В 6 потоков 0.5 сек и непонятно сколько памяти (но как будто бы мало)
Каждый поток стабильно добавляет скорости.epishman Автор
09.05.2019 23:46По потокам наверное статью придется писать. Во-первых много памяти жрут, во-вторых если буфер канала ограничить — начинаются тормоза. Завтра доделаю код, выложу здесь, и параллельно буду гошку ковырять, возможно у нее многопоточность получше растовой будет.
tsukanov-as
10.05.2019 00:04Еще обнаружил что если поставить больше 6 потоков то начинает дико тупить. При 12 потоках 7 секунд выполняется. Явно что-то не так
epishman Автор
10.05.2019 00:14Так и должно быть. В идеале тредов не более количества ядер. Дальше ОС начинает переключать контекст, а это дорого. Поэтому зеленые потоки / горутины — это все больше абстракция для программистов, чем реальное ускорение. Железо рулит.
epishman Автор
09.05.2019 23:53Сейчас буфера каналов резиновые (в гошке они фиксированного размера). То есть память постоянно течет, и это плохо. Если в расте сделать их фиксированными, начинаются тормоза, видимо из-за мьютексов, которые зашиты внутрь синхронных каналов. Пока думаю как побороть.
tsukanov-as
10.05.2019 12:05Сделал без регулярки с учетом скобок внутри кавычек и экранирования: gist.github.com/tsukanov-as/d1532303e16d757e3fa9e70ccb21d64b
Удивительно, но даже так LuaJit быстрее Rust в одном потоке (1.6 sec).
Было бы здорово, если бы Вы собрали LuaJit у себя и сделали замер в своих условиях.
Собирается легко из репозитория: github.com/LuaJIT/LuaJIT
Библиотеку cjson можно поставить через менеджер пакетов: luarocks.org/modules/openresty/lua-cjsonepishman Автор
10.05.2019 12:30Приблизительно понятно в чем дело. Я использую промежуточную структуру, и возвращаю ее из функции по значению, то есть память выделяется заново. Потом я строки заталкиваю в результат, тоже по значению. Это проблема всех статических языков, почему порой код Java быстрей кода C++ — в интерпретаторах строка всегда в единственном экземпляре, а в C++ это на усмотрение программиста. Я смогу догнать, если уберу дополнительный слой, и поднапрягусь со ссылками. Собственно, поэтому у Rust только одно преимущество — экономия памяти, и то если не используем тредов. На луа библиотеку не напишешь. Хотя, на JS я ваш код уже не догоню :)
tsukanov-as
10.05.2019 12:36Мне нравится в Lua насколько мало нужно усилий, ума и знаний, чтобы написать эффективный код.
Язык то детский совсем.
ps Интересно насколько смогут еще ускорить этот код те, кто разбирается в LuaJit
tsukanov-as
09.05.2019 21:37Да, кстати, у меня SSD EVO 970 Plus.
Думаю это имеет влияние на скорость )epishman Автор
09.05.2019 21:47Да я уже понял что и машина получше, у меня старейший 2-х ядерный ноут 2 x Intel® Celeron® CPU 1005M @ 1.90GHz.
Прикол в том, что лучшая производительность получилась с пулом из 4-х тредов (не считая главного, который файл по байтам разбирает).
epishman Автор
09.05.2019 21:03Так запилите статью на эту тему, на хабре без статьи у вас невозможна карма больше 4, не сможете голосовать и проч. Если владеете гошкой и луа — сошлитесь на мой код, и на своей машине проведите замеры, и табличка сравнения.
Только научитесь память правильно смотреть, я не знаю винды, но надо изучить эту тему, чтобы отдельно куча, отдельно стек.tsukanov-as
09.05.2019 21:11Ой, у меня маловато ума чтоб на такие темы грамотно писать.
Я обычный одноэсник из деревни. Ни на Lua ни на Go не пишу. Играюсь только раз в пол года.epishman Автор
09.05.2019 21:13На гошке вакансий достаточно, даже в Краснодаре видел. И почти везде можно удаленно. Я с бухгалтерского софта уже соскочил, надеюсь не вернусь обратно к кактусам и фактурам.
tsukanov-as
09.05.2019 21:23Хочу соскочить на Go, но чего-то жду пока )
Смелости наверно не хватает.epishman Автор
09.05.2019 21:27Мне честно непонятен пока круг работодателей для гошки, но точно понятно что наступают времена, когда лучше иметь потенциальную возможность работать на заграницу, ибо внутри страны может остаться только пищевка и рынки.
deril
09.05.2019 11:14Интерестно было бы сравнить с Crystal. Тоже компилируется для LLVM, приятный синтаксис. Раньше делал на нем процессинг CSV файлов, отрабатывал шустро.
epishman Автор
09.05.2019 11:32Как я понял, для настоящего парсинга нужна многопоточка. В случае с JSON/XML это оправдано, так как скорость чтения из потока/файла сильно больше скорости остальной обработки. Проблема, если важна последовательность обработки, например финансовых документов, которые зависят друг от друга — в этом случае приходится часть документов кэшировать в памяти, что приводит к ее непредсказуемому расходу.
msin
Вы точно не ошиблись на 3 порядка? видимо, должно быть 54,6 Мб…
Просто рантайм на 54 гига даже в наше время избыточно жирных программ это что-то запредельно избыточное…
epishman Автор
Спасибо, поправил!
egordeev
del