
Наверное, каждой команде знакома эта боль — неактуальная документация. Как бы команда ни старалась, в современных проектах мы релизимся так часто, что описывать все изменения практически нереально. Наша команда тестирования совместно с системными аналитиками решили попробовать оживить нашу проектную документацию.

На web-проектах Альфа-Банка используется фреймворк для автоматизации тестирования Akita, который использует для BDD-сценарии. К настоящему моменту фреймворк набрал большую популярность благодаря низкому порогу входа, удобству использования и возможности тестировать верстку. Но мы решили пойти дальше — на основе описанных тестовых сценариев формировать документацию, тем самым сильно сокращая время которое аналитики тратят на на извечную проблему актуализации документации.
По сути, вместе с Akita уже использовался плагин по генерации документации, который проходил по шагам в сценариях и выгружал их в формат html, но для того, чтобы сделать этот документ востребованным, нам нужно было добавить:
Мы посмотрели на наш существующий плагин, который был, по сути, статическим анализатором и формировал документацию на основе описанных в .feature-файлах сценариев. Решили добавить динамики, и для того, чтобы не городить плагин над плагином, приняли решение написать свой собственный.
Для начала мы решили узнать, как мы можем собирать из feature-файлов скриншоты и значения переменных, используемых в тестовых сценариях. Все оказалось достаточно просто. Cucumber при выполнении тестов для каждого feature файла создает отдельный cucumber.json.
Внутри этого файла содержатся следующие объекты:
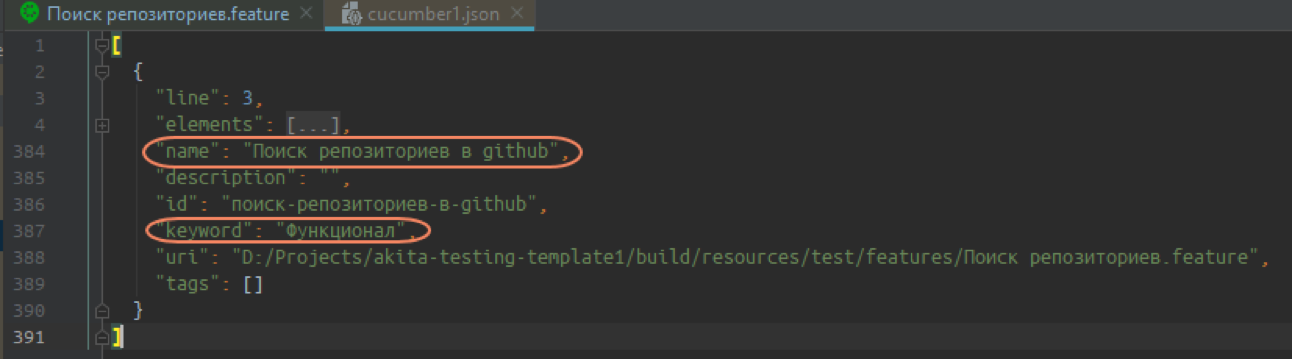
Имя тестового набора и ключевое слово:
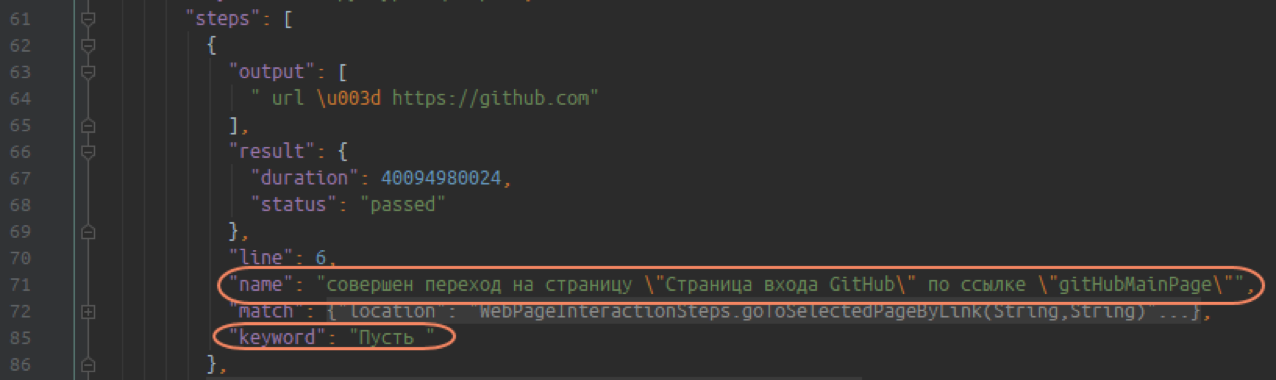
Массивы элементов — сами сценарии и шаги:
В поле output содержится дополнительная информация, например, переменные — адреса, ссылки, учетные записи пользователей и т.д.:

В embeddings находятся скриншоты, которые делает selenium во время прохождения тестов:

Таким образом, нам необходимо всего лишь пройти по cucumber.json-файлам, собрать названия тестовых наборов, тестовых сценариев, вытащить шаги, собрать дополнительную информацию и скриншоты.
Для того чтобы в документации отображались запросы, которые происходят в фоне или по определенному действию, нам пришлось обратиться за помощью к нашим фронт-разработчикам. С помощью proxy мы смогли отловить traceId, который генерируют фронтовые запросы к сервисам. По этому же traceId пишутся логи в elastic, откуда мы подтягиваем все необходимые параметры запросов в отчет о тестировании и документацию.
В результате у нас получился файл в формате Asciidoc — удобный формат файлов, немного сложнее аналога markdown, но имеет гораздо больше возможностей по форматированию (можно вставить изображение или таблицу, чего в markdown сделать нельзя).
Чтобы конвертировать полученный Asciidoc в другие форматы, используем Ascii doctorj, который является официальной версией для Java-инструмента AsciiDoctor. В результате у нас получается готовая документация в формате html, которую можно загрузить в confluence, отправить коллеге или положить в репозиторий.

Теперь, чтобы генерировать фронтовую документацию по своему проекту, необходимо всего лишь подключить к нему documentation plugin и после прогона всех тестов выполнить команду
На web-проектах Альфа-Банка используется фреймворк для автоматизации тестирования Akita, который использует для BDD-сценарии. К настоящему моменту фреймворк набрал большую популярность благодаря низкому порогу входа, удобству использования и возможности тестировать верстку. Но мы решили пойти дальше — на основе описанных тестовых сценариев формировать документацию, тем самым сильно сокращая время которое аналитики тратят на на извечную проблему актуализации документации.
По сути, вместе с Akita уже использовался плагин по генерации документации, который проходил по шагам в сценариях и выгружал их в формат html, но для того, чтобы сделать этот документ востребованным, нам нужно было добавить:
- скриншоты;
- значения переменных (config File, учетные записи пользователей и т.д.);
- статусы и параметры запросов.
Мы посмотрели на наш существующий плагин, который был, по сути, статическим анализатором и формировал документацию на основе описанных в .feature-файлах сценариев. Решили добавить динамики, и для того, чтобы не городить плагин над плагином, приняли решение написать свой собственный.
Для начала мы решили узнать, как мы можем собирать из feature-файлов скриншоты и значения переменных, используемых в тестовых сценариях. Все оказалось достаточно просто. Cucumber при выполнении тестов для каждого feature файла создает отдельный cucumber.json.
Внутри этого файла содержатся следующие объекты:
Имя тестового набора и ключевое слово:
Массивы элементов — сами сценарии и шаги:
В поле output содержится дополнительная информация, например, переменные — адреса, ссылки, учетные записи пользователей и т.д.:
В embeddings находятся скриншоты, которые делает selenium во время прохождения тестов:
Таким образом, нам необходимо всего лишь пройти по cucumber.json-файлам, собрать названия тестовых наборов, тестовых сценариев, вытащить шаги, собрать дополнительную информацию и скриншоты.
Для того чтобы в документации отображались запросы, которые происходят в фоне или по определенному действию, нам пришлось обратиться за помощью к нашим фронт-разработчикам. С помощью proxy мы смогли отловить traceId, который генерируют фронтовые запросы к сервисам. По этому же traceId пишутся логи в elastic, откуда мы подтягиваем все необходимые параметры запросов в отчет о тестировании и документацию.
В результате у нас получился файл в формате Asciidoc — удобный формат файлов, немного сложнее аналога markdown, но имеет гораздо больше возможностей по форматированию (можно вставить изображение или таблицу, чего в markdown сделать нельзя).
Чтобы конвертировать полученный Asciidoc в другие форматы, используем Ascii doctorj, который является официальной версией для Java-инструмента AsciiDoctor. В результате у нас получается готовая документация в формате html, которую можно загрузить в confluence, отправить коллеге или положить в репозиторий.
Как подключить?
Теперь, чтобы генерировать фронтовую документацию по своему проекту, необходимо всего лишь подключить к нему documentation plugin и после прогона всех тестов выполнить команду
adoc.Что хотим улучшить?
- Добавить конфигурируемые технические шаги.
В текущей версии плагина присутствуют шаги « И сделан скриншот...». Такого рода шаги не несут смысловой нагрузки для документации, и мы хотим их скрывать. Сейчас мы их зашили внутрь плагина, и они пропускаются, но есть недостаток — каждое добавление подобного шага приводит к тому, что нам нужно собирать новую версию плагина. Чтобы уйти от этого, мы планируем вынести подобные шаги в конфигурационный файл и туда прописывать те шаги, которые не хотим видеть в сценариях. - Сделать плагин open sourse.
Каким командам подойдет наша реализация?
- используют Cucumber (или подобный фреймворк);
- хотят иметь актуальную документацию для фронта и базы знаний;
- хотят привлечь аналитиков в тестирование.
Результат:
Пилот на нескольких командах показал, что с помощью плагина нам удается держать в актуальном состоянии документацию, аналитикам не нужно больше тратить свое время на ее поддержание. Кроме того, реализация этой возможности заставила нас задуматься о том, чтобы продолжить внедрять полноценный BDD внутри команд. На сегодняшний день у нас ведется эксперимент — аналитики формулируют позитивный путь клиента, указывают бизнес ограничения с помощью BDD-шагов Akita, тестировщики, в свою очередь, пишут кастомные шаги и дополнительные проверки к этим сценариям.Кстати, насчет холивара, нужен ли BDD или нет, уже в понедельник мы проведем специальный митап.