

Подходы к реализации поиска в мобильном приложении
- Поиск как фильтр данных
Обычно это выглядит как строка поиска над каким-нибудь списком. То есть мы просто фильтруем уже готовые данные. - Серверный поиск
В этом случае мы отдаём всю реализацию на откуп серверу, а приложение выступает в роли тонкого клиента, от которого требуется лишь показать данные в нужном виде. - Комплексный поиск
- приложение содержит в себе большое количество данных разного типа;
- приложение работает оффлайн;
- поиск нужен как единая точка доступа к разделам/контенту приложения.
В последнем случае на помощь приходит встроенный в SQLite полнотекстовый поиск (Full-text search). С его помощью можно очень быстро находить совпадения в большом объёме информации, что позволяет нам делать несколько запросов в разные таблицы без снижения производительности.
Рассмотрим реализацию такого поиска на конкретном примере.
Подготовка данных
Допустим, нам необходимо реализовать приложение, которое показывает список фильмов с сайта themoviedb.org. Для упрощения (чтобы не ходить в сеть), возьмём список фильмов и сформируем из него JSON-файл, положим его в assets и локально будем наполнять нашу базу данных.
Пример структуры JSON-файла:
[
{
"id": 278,
"title": "Побег из Шоушенка",
"overview": "Фильм удостоен шести..."
},
{
"id": 238,
"title": "Крестный отец",
"overview": "Криминальная сага, повествующая..."
},
{
"id": 424,
"title": "Список Шиндлера",
"overview": "Лента рассказывает реальную историю..."
}
]Наполнение базы данных
Для реализации полнотекстового поиска в SQLite используются виртуальные таблицы. Внешне они выглядят как обычные таблицы SQLite, но при любом обращении к ним выполняется некая закулисная работа.
Виртуальные таблицы позволяют нам ускорить поиск. Но, помимо преимуществ, у них есть и недостатки:
- нельзя создать триггер на виртуальной таблице;
- нельзя выполнять команды ALTER TABLE и ADD COLUMN для виртуальной таблицы;
- каждый столбец в виртуальной таблице индексируется, а это значит, что могут впустую тратиться ресурсы на индексацию столбцов, которые не должны участвовать в поиске.
Для решения последней проблемы можно использовать дополнительные таблицы, которые будут содержать часть информации, а в виртуальной таблице хранить ссылки на элементы обычной таблицы.
Создание таблицы немного отличается от стандартного, у нас появились ключевые слова
VIRTUAL и fts4: CREATE VIRTUAL TABLE movies USING fts4(id, title, overview);Наполнение же ничем не отличается от обычного:
fun populate(context: Context) {
val movies: MutableList<Movie> = mutableListOf()
context.assets.open("movies.json").use {
val typeToken = object : TypeToken<List<Movie>>() {}.type
movies.addAll(Gson().fromJson(InputStreamReader(it), typeToken))
}
try {
writableDatabase.beginTransaction()
movies.forEach { movie ->
val values = ContentValues().apply {
put("id", movie.id)
put("title", movie.title)
put("overview", movie.overview)
}
writableDatabase.insert("movies", null, values)
}
writableDatabase.setTransactionSuccessful()
} finally {
writableDatabase.endTransaction()
}
}Базовый вариант
При выполнении запроса используется ключевое слово
MATCH вместо LIKE:fun firstSearch(searchString: String): List<Movie> {
val query = "SELECT * FROM movies WHERE movies MATCH '$searchString'"
val cursor = readableDatabase.rawQuery(query, null)
val result = mutableListOf<Movie>()
cursor?.use {
if (!cursor.moveToFirst()) return result
while (!cursor.isAfterLast) {
val id = cursor.getInt("id")
val title = cursor.getString("title")
val overview = cursor.getString("overview")
result.add(Movie(id, title, overview))
cursor.moveToNext()
}
}
return result
}Для реализация обработки ввода текста в интерфейсе будем использовать
RxJava:RxTextView.afterTextChangeEvents(findViewById(R.id.editText))
.debounce(500, TimeUnit.MILLISECONDS)
.map { it.editable().toString() }
.filter { it.isNotEmpty() && it.length > 2 }
.map(dbHelper::firstSearch)
.subscribeOn(Schedulers.computation())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(movieAdapter::updateMovies)Получился базовый вариант поиска. В первом элементе нужное слово нашлось в описании, а во втором элементе — и в заголовке, и в описании. Очевидно, что в таком виде не совсем понятно, что мы нашли. Давайте это исправим.

Добавляем акценты
Для улучшения очевидности поиска воспользуемся вспомогательной функцией
SNIPPET. Она используется для отображения отформатированного фрагмента текста, в котором найдено совпадение.snippet(movies, '<b>', '</b>', '...', 1, 15)- movies — название таблицы;
- <b> и </b> — эти аргументы используются для того, чтобы выделить участок текста, по которому был выполнен поиск;
- … — для оформления текста, если результатом стало неполное значение;
- 1 — номер столбца таблицы, из которого будут выделяться куски текста;
- 15 — примерное количество слов, включаемых в возвращаемое текстовое значение.
Код идентичен первому, не считая запроса:
SELECT
id,
snippet(movies, '<b>', '</b>', '...', 1, 15) title,
snippet(movies, '<b>', '</b>', '...', 2, 15) overview
FROM movies
WHERE movies
MATCH 'фильм'Пробуем ёще раз:
Получилось нагляднее, чем в предыдущем варианте. Но это ещё не конец. Давайте сделаем наш поиск более «полным». Воспользуемся лексическим анализом и выделим значимые части нашего поискового запроса.
Финишное улучшение
В SQLite есть встроенные токенизаторы, позволяющие выполнить лексический анализ и преобразовать исходный поисковый запрос. Если при создании таблицы мы не указывали конкретный токенизатор, то будет выбран «простой». По сути он всего лишь преобразует наши данные в нижний регистр и откидывает нечитаемые символы. Нам это не совсем подходит.
Для качественного улучшения поиска нам необходимо использовать стемминг — процесс нахождения основы слова для заданного исходного слова.
В SQLite есть дополнительный встроенный токенизатор, который использует алгоритм стемминга «Стеммер Портера». Этот алгоритм последовательно применяет ряд определённых правил, выделяя значимые части слова путем отсечения окончаний и суффиксов. Например, при поиске «ключей», мы сможем получить выдачу, где содержатся слова «ключом», «ключами» и «ключа». Ссылку на подробное описание алгоритма я оставлю в конце.
К сожалению, встроенный в SQLite токенизатор работает только с английским языком, поэтому для русского языка необходимо написать свою реализацию или воспользоваться уже готовыми наработками. Мы возьмём готовую реализацию с сайта algorithmist.ru.
Преобразуем наш поисковый запрос в необходимый вид:
- Убрать лишние символы.
- Разбить фразу на слова.
- Пропустить через стеммер.
- Собрать в поисковый запрос.
object Porter {
private val PERFECTIVEGROUND = Pattern.compile("((ив|ивши|ившись|ыв|ывши|ывшись)|((<=[ая])(в|вши|вшись)))$")
private val REFLEXIVE = Pattern.compile("(с[яь])$")
private val ADJECTIVE = Pattern.compile("(ее|ие|ые|ое|ими|ыми|ей|ий|ый|ой|ем|им|ым|ом|его|ого|ему|ому|их|ых|ую|юю|ая|яя|ою|ею)$")
private val PARTICIPLE = Pattern.compile("((ивш|ывш|ующ)|((?<=[ая])(ем|нн|вш|ющ|щ)))$")
private val VERB = Pattern.compile("((ила|ыла|ена|ейте|уйте|ите|или|ыли|ей|уй|ил|ыл|им|ым|ен|ило|ыло|ено|ят|ует|уют|ит|ыт|ены|ить|ыть|ишь|ую|ю)|((?<=[ая])(ла|на|ете|йте|ли|й|л|ем|н|ло|но|ет|ют|ны|ть|ешь|нно)))$")
private val NOUN = Pattern.compile("(а|ев|ов|ие|ье|е|иями|ями|ами|еи|ии|и|ией|ей|ой|ий|й|иям|ям|ием|ем|ам|ом|о|у|ах|иях|ях|ы|ь|ию|ью|ю|ия|ья|я)$")
private val RVRE = Pattern.compile("^(.*?[аеиоуыэюя])(.*)$")
private val DERIVATIONAL = Pattern.compile(".*[^аеиоуыэюя]+[аеиоуыэюя].*ость?$")
private val DER = Pattern.compile("ость?$")
private val SUPERLATIVE = Pattern.compile("(ейше|ейш)$")
private val I = Pattern.compile("и$")
private val P = Pattern.compile("ь$")
private val NN = Pattern.compile("нн$")
fun stem(words: String): String {
var word = words
word = word.toLowerCase()
word = word.replace('ё', 'е')
val m = RVRE.matcher(word)
if (m.matches()) {
val pre = m.group(1)
var rv = m.group(2)
var temp = PERFECTIVEGROUND.matcher(rv).replaceFirst("")
if (temp == rv) {
rv = REFLEXIVE.matcher(rv).replaceFirst("")
temp = ADJECTIVE.matcher(rv).replaceFirst("")
if (temp != rv) {
rv = temp
rv = PARTICIPLE.matcher(rv).replaceFirst("")
} else {
temp = VERB.matcher(rv).replaceFirst("")
if (temp == rv) {
rv = NOUN.matcher(rv).replaceFirst("")
} else {
rv = temp
}
}
} else {
rv = temp
}
rv = I.matcher(rv).replaceFirst("")
if (DERIVATIONAL.matcher(rv).matches()) {
rv = DER.matcher(rv).replaceFirst("")
}
temp = P.matcher(rv).replaceFirst("")
if (temp == rv) {
rv = SUPERLATIVE.matcher(rv).replaceFirst("")
rv = NN.matcher(rv).replaceFirst("н")
} else {
rv = temp
}
word = pre + rv
}
return word
}
}val words = searchString
.replace("\"(\\[\"]|.*)?\"".toRegex(), " ")
.split("[^\\p{Alpha}]+".toRegex())
.filter { it.isNotBlank() }
.map(Porter::stem)
.filter { it.length > 2 }
.joinToString(separator = " OR ", transform = { "$it*" })После этого преобразования фраза «дворы и призраки» выглядит как «двор* OR призрак*».
Символ "*" означает, что поиск будет вестись по вхождению данного слова в другие слова. Оператор "OR" означает, что будут показаны результаты, которые содержат хотя бы одно слово из поисковой фразы. Смотрим:
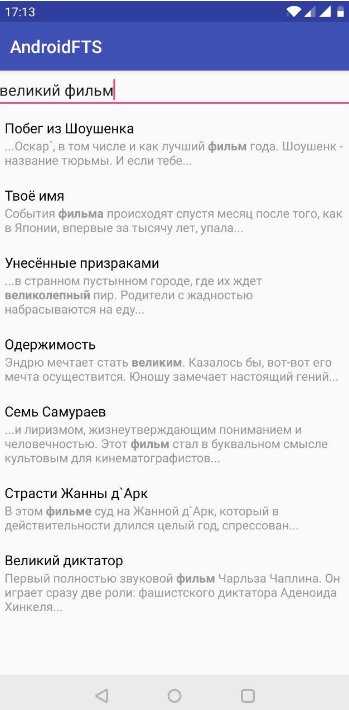
Резюме
Полнотекстовый поиск не такой сложный, как может показаться с первого взгляда. Мы разобрали конкретный пример, который вы быстро и легко сможете реализовать у себя в проекте. Если вам нужно что-то сложнее, то стоит обратиться к документации, благо она есть и довольно хорошо написана.
Ссылки:
Комментарии (8)

qw1
11.09.2019 13:55val query = «SELECT * FROM movies WHERE movies MATCH '$searchString'»
SQL-инъекция?
vitkidd Автор
11.09.2019 16:29Хорошее замечание. Возможно стоило оставить небольшую заметку про возможность инъекции. Но раскрывать тему SQL-инъекций в рамках данной статьи не вижу смысла, так как на хабре есть несколько интересных статей на эту тему.
qw1
11.09.2019 20:02Имхо, проще ничего не раскрывать, а отредактировать пример, чтобы использовались параметризованные запросы. Это увеличит размер кода на 1 строку. Всё-таки, публиковать примеры с дырами в корпоративном блоге банка — опасная для репутации затея )))
uncle_doc
12.09.2019 18:21А смысл делать инъекциию? Если клиент можно просто достать базу данных и посмотреть. (: Разве только для того что-бы приложение не упало.
qw1
12.09.2019 19:37А ничего, что по этой статье начинающие программисты учиться будут, и код копипастить, как образец наилучших практик.
uncle_doc
12.09.2019 21:33Начинающие программисты и полнотекстовый поиск? Ну ладно (: А автору кстати можно поправить код и добавить вызов вот этой функции и если введут всякие кавычки и прочее то ничего не упадет developer.android.com/reference/android/database/DatabaseUtils.html#sqlEscapeString(java.lang.String)
agent10
Если список уже в памяти, то зачем делать запросы к БД, это же будет дольше?
Room уже вроде начал поддерживать FTS из коробки и всё должно быть проще?
vitkidd Автор
Наполнение базы данных из ассетов сделано для примера. В реальном проекте данные будут загружаться с сервера, а между наполнением базы данных и поиском может пройти значительное время (причем поиск будет происходить без наличия интернета).
По поводу Room я с вами согласен, реально удобнее, но, по тем или иным причинам, не все используют Room. Единственный момент, что с поддержкой русского языка так и не разобрались (если я не прав — поправьте пожалуйста).