

SEO — это рутина. Иногда приходится делать совсем тоскливые операции вроде удаления «плюсиков» в ключевых словах. Иногда — что-то более продвинутое вроде парсинга мета-тегов или консолидации данных из разных таблиц. В любом случае все это съедает тонны времени.
Но мы не любим рутину. Предлагаем 16 полезных функций Google Sheets, которые упростят работу с данными и помогут вам высвободить несколько рабочих часов или даже дней. (Уверены, о существовании некоторых функций вы не догадывались).
2. IFERROR — присваиваем свое значение в случае ошибки
3. ARRAYFORMULA — протягиваем формулу вниз в один клик
4. LEN — считаем количество символов в ячейке
5. TRIM — удаляем пробелы в начале и конце фразы
6. SUBSTITUTE — меняем/удаляем пробелы и спецсимволы
7. LOWER — переводим буквы из верхнего регистра в нижний
8. UNIQUE — выводим данные без дублирующихся ячеек
9. SEARCH — находим данные в строке
10. SPLIT — разбиваем фразы на отдельные слова
11. CONCATENATE — объединяем данные в ячейках
12. VLOOKUP — ищем значения в другом диапазоне данных
13. IMPORTRANGE — импортируем данные из других таблиц
14. IMPORTXML — парсим данные с веб-страниц
15. GOOGLETRANSLATE — переводим ключевики и другие данные
16. REGEXEXTRACT — извлекаем нужный текст из ячеек
1. IF — базовая логическая функция
Это одна из базовых функций, знакомых вам по Excel. Она помогает при решении разных SEO-задач. Формула IF выводит одно значение, если логическое выражение истинное, и другое — если оно ложное.
Синтаксис:
=IF(логическое_выражение;"значение_истина";"значение_ложь")Пример. Есть список ключей с частотностями. Наша цель — занять ТОП-3. При этом мы хотим выбрать только такие ключи, каждый из которых приведет нам минимум 300 посетителей в месяц.
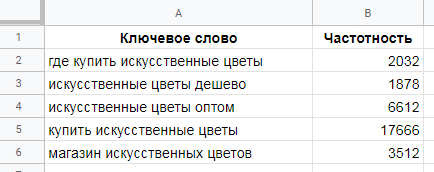
Определяем, какая доля трафика приходится на третью позицию в органике. Для этого идем в этот сервис и видим, что третья позиция приводит около 10% трафика из органики (конечно, эта цифра неточная, но это лучше, чем ничего).
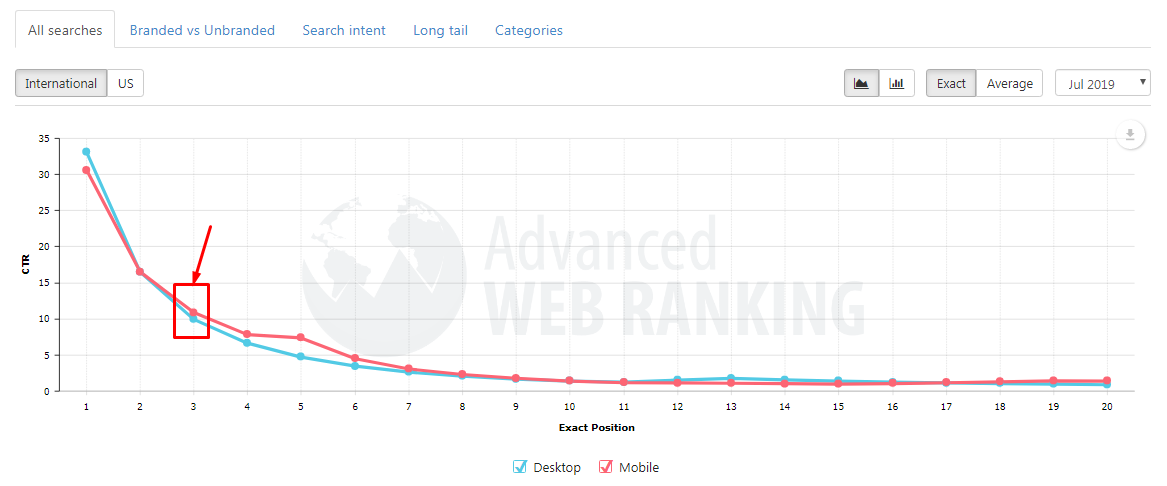
Составляем выражение IF, которое будет возвращать значение 1 для ключей, который приведут минимум 300 посетителей, и 0 — для остальных ключей:
=IF(B2*0.1>=300;"1";"0")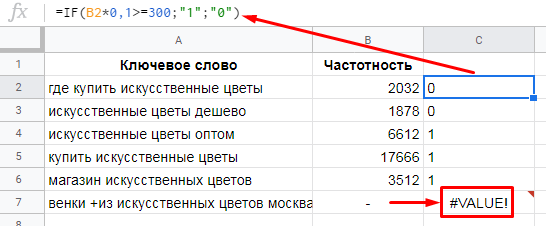
Обратите внимание, в строке 7 формула выдала ошибку, поскольку значение частотности задано в неверном формате. Для подобных ситуаций есть продвинутая версия функции IF — IFERROR.
Обратите внимание: использование в формуле запятой или точки для десятичных дробей определено в настройках ваших таблиц.
2. IFERROR — присваиваем свое значение в случае ошибки
Функция позволяет вывести заданное значение в ячейку, если выдается ошибка.
Синтаксис:
=IFERROR(ваша формула;"значение в случае ошибки")Используем эту функцию в примере, описанном выше. Зададим значение в случае ошибки «нет данных».
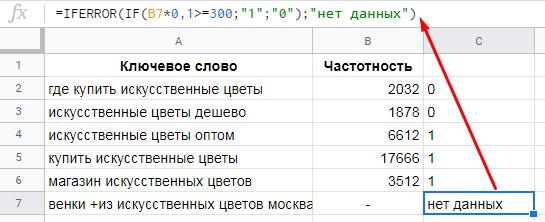
Как видите, значение #VALUE! изменило вид на понятное нам «нет данных».
3. ARRAYFORMULA — протягиваем формулу вниз в один клик
В работе с данными практически каждый раз приходится прописывать формулу для всех ячеек в столбце. «Тянуть» ее, зажав левую кнопку мыши, или копипастить — это прошлый век.
Достаточно заключить исходную функцию в функцию ARRAYFORMULA, и формула применится ко всем ячейкам ниже. Причем при удалении добавлении строк формула все равно будет работать — без пробелов в расчетах.
Синтаксис:
=ARRAYFORMULA(исходная формула)Пример. Сделаем автоматическое применение формулы, описанной выше, для всех ячеек диапазона. Для этого заключаем исходную формулу в ARRAYFORMULA:
=ARRAYFORMULA(IFERROR(IF(B2:B*0,1>=300;"1";"0");"нет данных"))Обратите внимание, что мы вместо ячейки B2 указали диапазон, для которого применяем формулу (B2:B — это весь столбец B, начиная со второй строки). Если указать одну ячейку, формула не сработает.
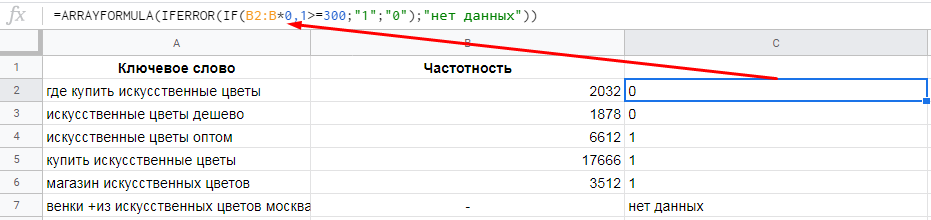
Лайфхак. Нажмите сочетание клавиш CTRL+SHIFT+ENTER после ввода основной формулы, и функция ARRAYFORMULA применится автоматически.
ARRAYFORMULA работает не со всеми функциями. Например, она не совместима с GOOGLETRANSLATE и IMPORTXML, о которых мы расскажем ниже.
4. LEN — считаем количество символов в ячейке
Эта функция особенно полезна при составлении объявлений контекстной рекламы — когда важно не заступать за отведенное количество символов для заголовков, описаний, отображаемых URL, быстрых ссылок и уточнений.

В SEO функция LEN применяется, например, при составлении мета-тегов title и description. Символы функция считает с пробелами.
Синтаксис:
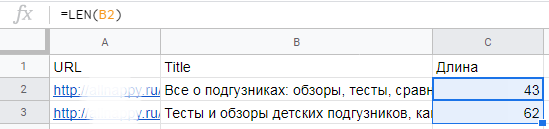
=LEN(ячейка с текстом)Пример. Нам нужно составить тайтлы для всех страниц сайта. Мы знаем, что в результатах поиска отображается около 55 символов. Наша задача — составить тайтлы так, чтобы самая важная информация была в первых 55 символах. Прописываем формулу LEN для заполняемых ячеек. Теперь мы точно знаем, когда приближаемся к отображаемым 55 символам.
5. TRIM — удаляем пробелы в начале и конце фразы
Когда парсишь семантику из разных источников, часто она содержит «мусорные» элементы — пробелы, плюсики, спецсимволы. Рассмотрим функции, которые помогают быстро почистить ядро. Одна из них — TRIM.
Эта функция удаляет пробелы в начале и конце фразы, указанной в ячейке.
Синтаксис:
=TRIM(ячейка, в которой нужно удалить пробелы до и после фразы)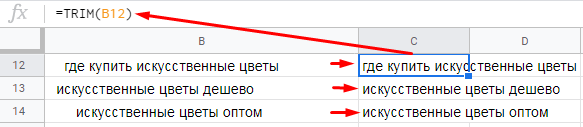
Функция удаляет все пробелы до и после фразы — сколько бы их там ни было.
6. SUBSTITUTE — меняем/удаляем пробелы и спецсимволы
Универсальная функция замены/удаления символов в ячейках.
Синтаксис:
=SUBSTITUTE(где искать;"что искать";"на что менять";номер соответствия)Номер соответствия — порядковый номер встреченного значения на замену, например, первое встреченное заменить, остальные оставить. Опциональный параметр.
Пример. У нас есть выгрузка ключевых фраз из Яндекс.Вордстат. Многие ключи содержат плюсики. Нам нужно их удалить.
Формула будет иметь вид:
=SUBSTITUTE(B12;"+";"";)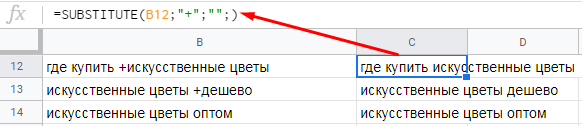
Что мы сделали:
- где искать — указали ячейку с данными;
- «что искать» — указали плюсик, который нужно удалить;
- «на что менять» — поскольку символ нужно удалить, мы указали кавычки без символов внутри; если бы нам нужна была замена, здесь бы мы прописали текст, на который нужно заменить плюсик;
- номер соответствия — здесь мы ничего не указали, и функция удалит все плюсы в фразе; если бы мы указали 1, то функция удаляла бы только первый плюсик, если 2 — второй и т. д.
7. LOWER — переводим буквы из верхнего регистра в нижний
При составлении ключей и парсинге из разных источников (например, из мета-тегов конкурентов) может так получиться, что они будут иметь буквы в верхнем регистре. Для приведения ключей в унифицированный вид нужно перевести все буквы в нижний регистр. Для этого используется функция LOWER.
Синтаксис:
=LOWER(ячейка, текст в которой нужно перевести в нижний регистр)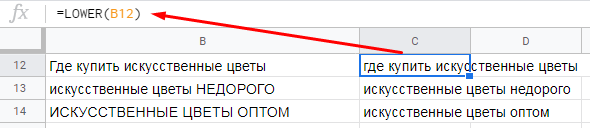
8. UNIQUE — выводим данные без дублирующихся ячеек
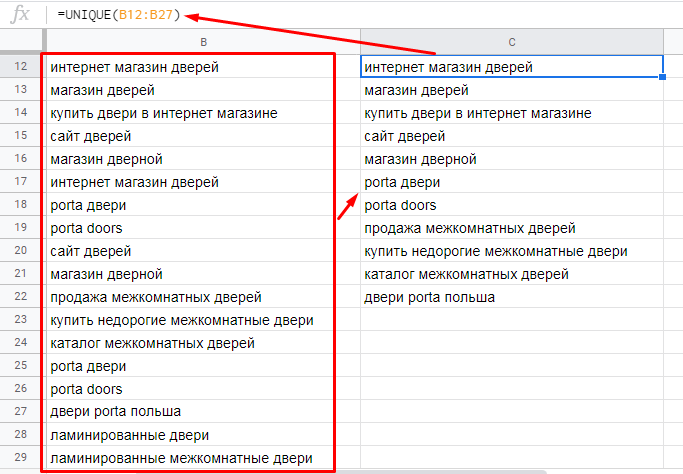
Функция анализирует выделенный диапазон на предмет полных дублей и выводит только уникальные строки — в том же порядке, что и в исходном диапазоне.
Синтаксис:
=UNIQUE(диапазон данных)Пример. Мы собрали ключи из Яндекс.Вордстат, поисковых подсказок, парсили слова конкурентов. Естественно, в этом массиве ключей у нас будут дубли. Нам они не нужны. Убираем их с помощью UNIQUE.
Если вы хотите «одним махом» очистить ядро от мусора, используйте бесплатный нормализатор слов. Он убирает дублирующиеся фразы (с учетом перестановок), меняет регистры, удаляет пробелы и спецсимволы. По сути, он делает то же самое, что и функции TRIM, SUBSTITUTE, LOWER и UNIQUE вместе взятые — только в один клик.
9. SEARCH — находим данные в строке
С помощью этой функции вы быстро найдете необходимые вам строки с большом массиве данных.
Синтаксис:
=SEARCH(«что искать»;где искать)Функция используется в разных ситуациях:
- выделить ключевые фразы с необходимым интентом (например, брендированные или связанные с определенной тематикой, товаром или услугой);
- найти определенные символы в URL (например, UTM-параметры или знак вопроса);
- найти URL для целей линкбилдинга — например, содержащие слова «guest-post»).
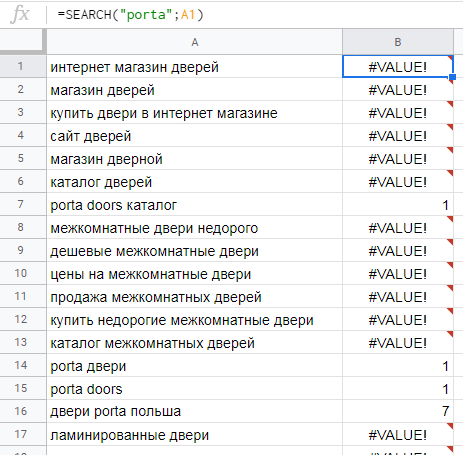
Пример. У нас есть список ключей для интернет-магазина дверей. Мы хотим найти все брендированные запросы и отметить их в таблице. Для этого используем формулу:
=SEARCH("porta";A1)Но в таком виде формула при отсутствии слова «porta» в ключе выведет нам #VALUE!.. Кроме того, при наличии этого слова в искомой ячейке функция будет проставлять номер символа, с которого начинается это слово. Выглядит результат так:
Для получения результата поиска в удобной для нас форме используем дополнительно функции IF и IFERROR:
=IFERROR(IF(SEARCH("porta";A1)>0;"бренд";"0"))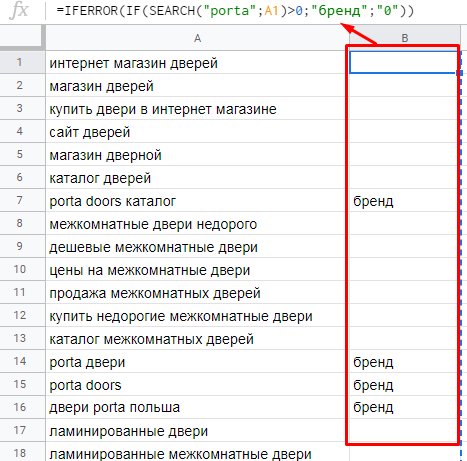
10. SPLIT — разбиваем фразы на отдельные слова
Функция делит строки на фрагменты, используя заданный разделитель.
Синтаксис:
=SPLIT(ячейка;"разделитель")Стоит иметь в виду, что вторая половина разделенного текста займет следующую колонку. Так что если у вас плотная таблица, перед применением формулы нужно добавить пустую колонку.
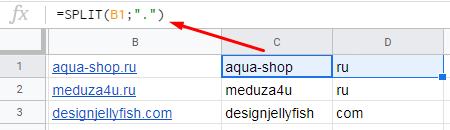
Пример. У нас есть список доменов. Нам нужно разделить их на названия доменов и расширения. В функции SPLIT в качестве разделителя указываем точку и получаем результат:
11. CONCATENATE — объединяем данные в ячейках
Эта функция, в отличие от предыдущей, объединяет данные из нескольких ячеек.
Синтаксис:
=CONCATENATE(ячейка 1;ячейка 2;...)Важно: в формулу можно вставлять не только значения ячеек, но и символы (в прямых кавычках).
Пример. В примере с функцией SPLIT мы разделили домены. Сделаем обратную операцию с помощью CONCATENATE (указываем объединяемые ячейки и между ними указываем разделитель — точку):

12. VLOOKUP — ищем значения в другом диапазоне данных
Функция выполняет поиск ключа в первом столбце диапазона и возвращает значение указанной ячейки в найденной строке.
Синтаксис:
=VLOOKUP(запрос;диапазон;номер_столбца;[сортировка])Пример 1. Есть два массива ключевых фраз, полученных из разных источников. Нужно найти ключи в первом массиве, которые не встречаются во втором массиве. Для этого используем формулу:
=VLOOKUP(A2:A;B2:B;1;false)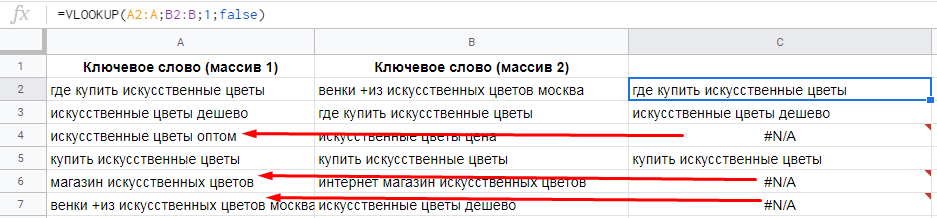
Что мы сделали:
- задали диапазон A2:A, из которого берем ключи для сравнения;
- задали диапазон B2:B, с которым сравниваем ключи из столбца А;
- задали номер столбца (1), из которого подтягиваем ключи при совпадениях;
- false — указали, что сортировка нам не нужна.
Функция VLOOKUP часто используется при поиске данных на разных листах или в разных документах.
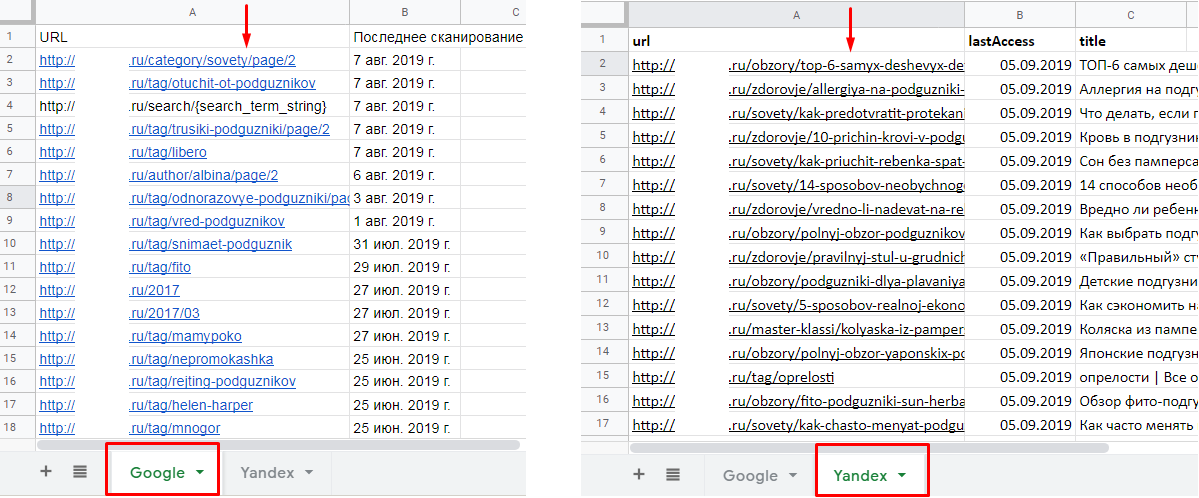
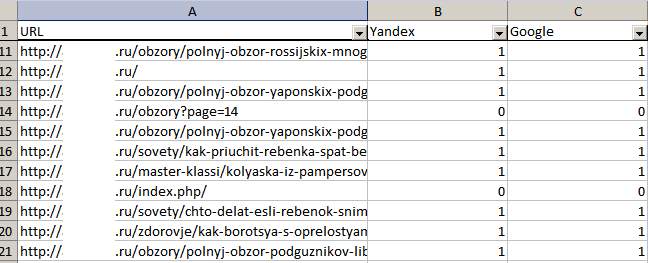
Пример 2. Мы выгрузили данные из Яндекс.Вебмастера и Google Search Console об индексации страниц сайта. Наша задача — сопоставить данные и определить, какие страницы индексируются в одном поисковике, но не индексируются в другом.
Заносим результаты выгрузок в файл Google Sheets. На одном листе — URL из Google, на втором — из Яндекса.
В ячейке C2 прописываем функцию VLOOKUP. Сразу заключаем в функцию в ARRAYFORMULA для автоматического протягивания вниз:
=ARRAYFORMULA(VLOOKUP(A2:A;Yandex!A2:A;1;false))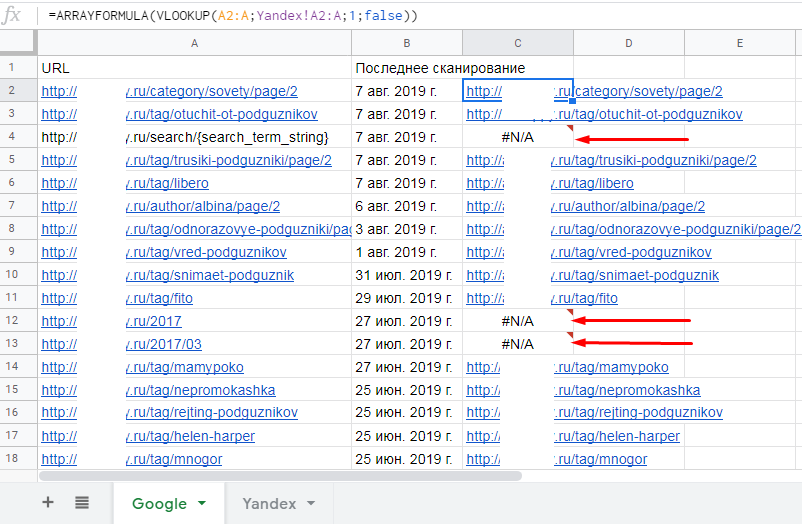
Теперь мы сразу видим, какие страницы проиндексированы в Google, но не проиндексированы в Яндексе.
Что мы сделали:
- задали диапазон A2:A текущего листа, из которого берем значение для сравнения;
- задали диапазон Yandex!A2:A листа с выгрузкой из Яндекса, с которым будем сравнивать значения URL из Google;
- указали номер столбца листа с выгрузкой из Яндекса, значения из которого подтягиваем при совпадении значений из сравниваемых диапазонов;
- false — указали, что сортировка нам не нужна.
Если же вам нужно проверить одновременно индексацию конкретных страниц в Яндексе и Google, воспользуйтесь инструментом от PromoPult. Загрузите список URL и запустите проверку. Если страница проиндексирована в поисковике, в столбце будет цифра 1, если нет — 0.
Каким пользоваться этим инструментом и в каких ситуациях он полезен, читайте в этом гайде.
13. IMPORTRANGE — импортируем данные из других таблиц
Функция позволяет вставить в текущий файл данные из других таблиц.
Синтаксис:
=IMPORTRANGE("ссылка на документ";"ссылка на диапазон данных")Пример:
=IMPORTRANGE("https://docs.google.com/spreadsheets/d/ХХХХХХХХ/","имя листа!A2:A25")Пример. Вы продвигаете сайт клиента. Над проектом работает три специалиста: линкбилдер, SEO-специалист и копирайтер. Каждый ведет свой отчет. Клиент заинтересован отслеживать процесс в режиме онлайн. Вы формируете для него один отчет с вкладками: «Ссылки», «Позиции», «Тексты». На эти вкладки с помощью функции IMPORTRANGE подтягиваются данные по каждому направлению.

Преимущество функции в том, что вы открываете доступ только к конкретным листам. При этом внутренние части отчетов специалистов остаются недоступны для клиентов.
14. IMPORTXML — парсим данные с веб-страниц
«Развесистая» функция для парсинга данных с веб-страниц с помощью XPath.
Синтаксис:
=IMPORTXML("url";"xpath-запрос")Вот лишь несколько вариантов использования этой функции:
- извлечение метаданных из списка URL (title, description), а также заголовков h1-h6;
- сбор e-mail со страниц;
- парсинг адресов страниц в соцсетях.
Пример. Нам нужно собрать содержимое тегов title для списка URL. Запрос XPath, который мы используем для получения этого заголовка, выглядит так: «//title».
Формула будет такой:
=IMPORTXML(A2;"//title")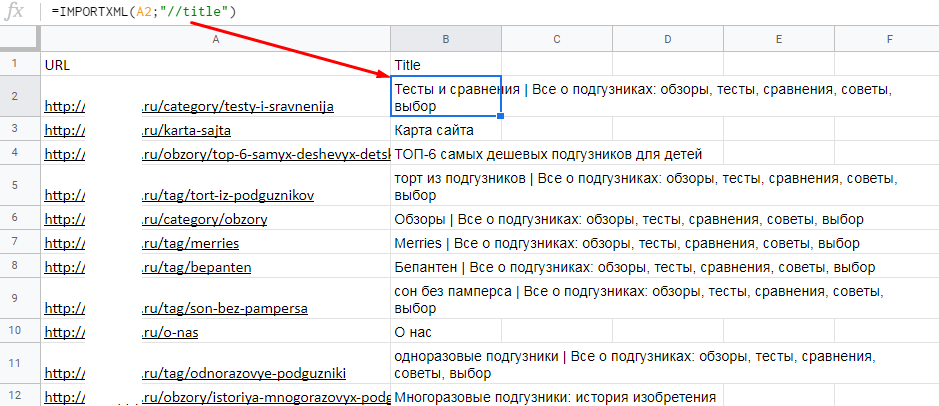
IMPORTXML не работает с ARRAYFORMULA, так что вручную копируем формулу во все ячейки.
Вот другие запросы XPath, которые вам будут полезны:
- выгрузить заголовки H1 (и по аналогии — h2-h6): //h1
- спарсить мета-теги description: //meta[@name='description']/@content
- спарсить мета-теги keywords: //meta[@name='keywords']/@content
- извлечь e-mail адреса: //a[contains(href, 'mailTo:') or contains(href, 'mailto:')]/@href
- извлечь ссылки на профили в соцсетях: //a[contains(href, 'vk.com/') or contains(href, 'twitter.com/') or contains(href, 'facebook.com/') or contains(href, 'instagram.com/') or contains(href, 'youtube.com/')]/@href
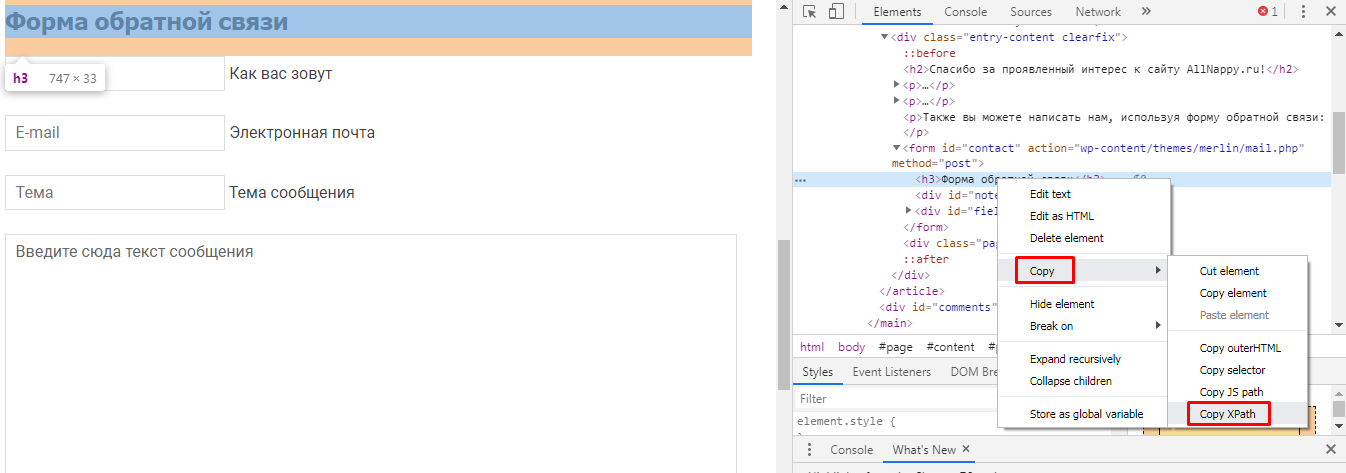
Если вам нужно узнать XPath-запрос для других элементов страницы, откройте ее в Google Chrome, перейдите в режим просмотра кода, найдите элемент, кликните по нему правой кнопкой и нажмите Copy / Copy XPath.
15. GOOGLETRANSLATE — переводим ключевики и другие данные
В мультиязычных проектах часто приходится переводить ключевые фразы. Удобнее всего это сделать с помощью функции GOOGLETRANSLATE прямо в таблице.
Синтаксис:
=GOOGLETRANSLATE(«текст»; [язык_оригинала]; [язык_перевода])Например, если нам нужно перевести ключи с русского на английский, формула будет такой:
=GOOGLETRANSLATE(A1;"ru";"en")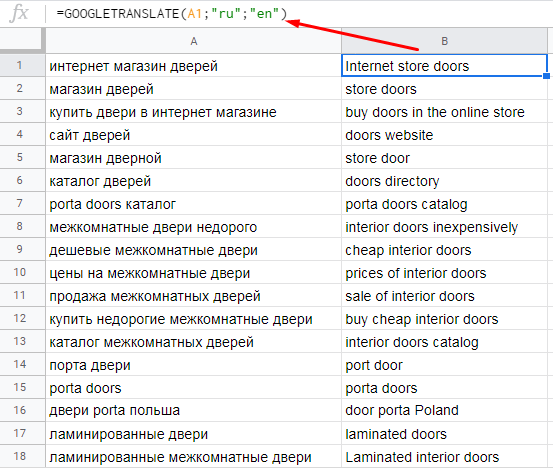
Если бы мы переводили с английского на русский, то нужно было бы изменить порядок языков:
=GOOGLETRANSLATE(A1;"en";"ru")GOOGLETRANSLATE не работает с ARRAYFORMULA, так что, как и в случае с IMPORTXML, протягиваем формулу вручную.
16. REGEXEXTRACT — извлекаем нужный текст из ячеек
Эта функция позволяет извлечь из строки с данными текст, описанный с помощью регулярных выражений RE2, поддерживаемых Google. Синтаксис регулярных выражений достаточно сложный, больше примеров вы найдете в справке Google.
Синтаксис:
=REGEXEXTRACT(где искать;”регулярное выражение”)Пример 1. У нас есть список URL. Нужно извлечь домены. Здесь нам поможет регулярное выражение:
^(?:https?:\/\/)?(?:[^@\n]+@)?(?:www\.)?([^:\/\n]+)
Пример 2. В списке ключевых фраз нужно найти брендированные ключи со словами «porta» и «порта». Для поиска фраз с вхождением любого из этих слов используем регулярное выражение:
(?i)(\W|^)(porta|порта)(\W|$)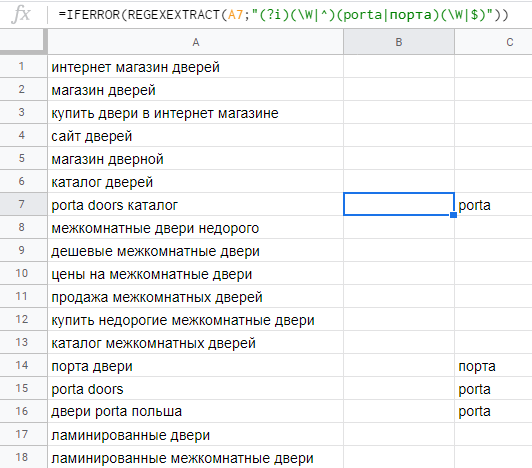
Как видите, в таблицах можно кроить и резать данные так, как вам будет нужно, достаточно разобраться в формулах.
Комментарии (3)

trapwalker
24.09.2019 18:04Для тех кто и так плотно этим пользовался и понимает принцип и возможности эта статья мало полезна. А вот положить в закладки и скидывать любопытным и сообразительным, но молодым и неопытным «падаванам» — это дорогого стоит.
Спасибо что оформили это в удобном виде.

dron88
Гугл транслейт стал для меня открытием. Остальное знал и частично использовал.