

Еще с 1990-х годов меня поражало, что проектирование всей мировой цифровой микроэлектроники контролируется двумя конторами в Калифорнии, которые находятся в 10 минутах езды друг от друга — Synopsys и Cadence. В те времена четверть мирового проектирования делалось в Японии (континентальный Китай тогда находился в примитивном состоянии), и все эти Sony, Hitachi, Fujitsu и другие гиганты ездили на поклон в Америку и платили несчетные миллионы долларов за программы, которые потом использовали японские проектировщики. Сейчас это продолжается с Samsung, Huawei и даже с российскими конторами, которые проектируют микросхемы для космоса.
Русская земля умудрилась вырастить Yandex супротив Гугла, так почему бы и не попробовать создать какие-нибудь программы для проектирования микросхем? Начать можно с малого: популяризовать конкурсы и хакатоны по разработке алгоритмов автоматизации проектирования (Electronic Design Automation — EDA). Эти алгоритмы удобны тем, что у них много уровней сложности: простейшую программу Place & Route может написать студент за выходные, но вот на продвинутую потребуются десятилетия работы сотен людей и миллиарды долларов на R&D.
Сейчас в Иннополисе возле Казани делают мероприятие для студентов в формате «две недели подготовки + хакатон». Одной из тем стала традиционная задача EDA — размещение и трассировка графа электронной схемы на ряды стандартных ячеек. Будет интересно увидеть, что за это короткое время сможет осуществить небольшая команда студентов-программистов с базовым пониманием C++/Java/Python, методов парсирования текста, алгоритмов работы с графами и навыками визуализации структур данных с помощью GUI.
Итак — постановка задачи:

Задача состоит из трех подзадач, которыми могут заниматься разные студенты:
- Парсирование текстового представления графа цифровой схемы.
- Размещение графа на рядах стандартных ячеек микросхемы и соединение этих ячеек дорожками (трассировка).
- Визуализация результатов — вывод на экран схемы дорожек и соединений.
Входом для программы является текстовый файл на очень ограниченном подмножестве языка описания аппаратуры Verilog. В этом файле описаны входы и выходы для схемы (input, output), внутренние соединения (wire) и приведен список логических элементов в формате «тип имя-экземпляра (список соединений)». Файл можно парсировать на C/C++ с помощью Lex+Yacc или аналогичных программ.

Результатом парсирования текста должно быть представление графа из элементов в памяти. Это представление будет использовано алгоритмом размещения и трассировки, которые потом создаст другую структуру. Если в команде хакатона будет достаточно участников, то результат начального парсирования можно визуализировать во время хакатона в качестве дополнительного задания. Примерно в таком духе, пусть даже не так красиво:

Если участников во время хакатона будет не хватать, то визуализацию промежуточного, неразмещенного графа стоит оставить на потом, а во время хакатона выводить на экран только окончательное размещение.
Вообще задачу парсирования можно ставить с несколькими уровнями сложности:
- В простейшем случаи все узлы графа — это двух-входовые логические элементы AND и OR, а также одновходовые элементы NOT. На окончательном размещении они реализуются стандартными ячейками одинаковой ширины.
- Если для хакатона хватит времени, задачу можно усложнить:
- ввести трех- и четырех-входовые ячейки AND3, OR4 и т.д.;
- расширить набор типов узлов добавлением NAND, XOR, D-триггеров (D-Flip-Flop) с разными опциями (reset, enable) и т.д.;
- сделать дополнительный текстовый файл, в котором задать ширину и другие параметры ячеек.
- После хакатона задачу можно привязать к реальному миру, и именно парсировать не абстрактные AND и OR, а файл в таком же формате, но с ячейками из реальных библиотек стандартных ячеек ASIC на 28, 14 или 7 нанометров, которые поставляют разработчикам EDA программ и проектировщикам фабрики типа TSMC (Taiwan Semiconductor Manufacturing Company).
Что такое стандартная ячейка? Это ячейка стандартной высоты для данной ASIC library, то есть библиотеки примитивов для изготовления микросхемы на фабрике по некоторой технологии. ASIC — Application Specific Integrated Circuit. Сейчас большинство микросхем, например в смартфонах — это ASIC. Ячейки в библиотеке ASIC имеют стандартную высоту, чтобы их было удобно выстраивать в ряды для подвода к ним питания и облегчения алгоритмов трассировки. Разные ячейки в библиотеке могут реализовывать не только примитивы типа AND и OR, но и более сложные конструкции — мультиплексоры, защелки, комбинации из двух-трех логических элементов (AND-OR) и т.д.
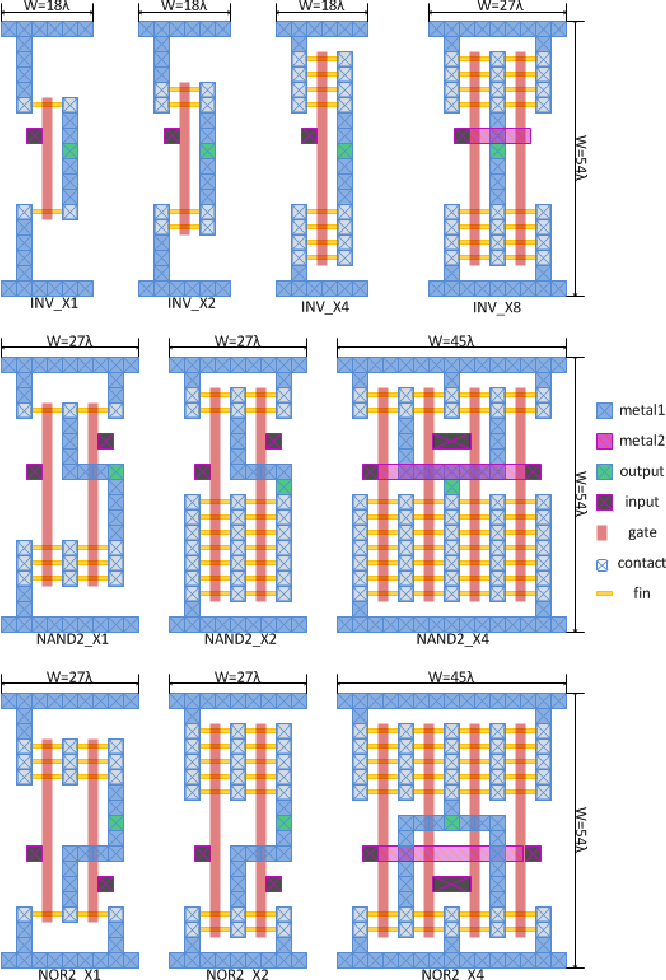
Ячейки на микросхеме выстраиваются в ряды (слайд из лекций Чарльза Данчека):

Между рядами есть каналы (routing channels), в которых проходят соединения. Ширину каналов можно менять, если в соединениях образуются заторы (congestion). В рядах можно делать просветы между ячейками:
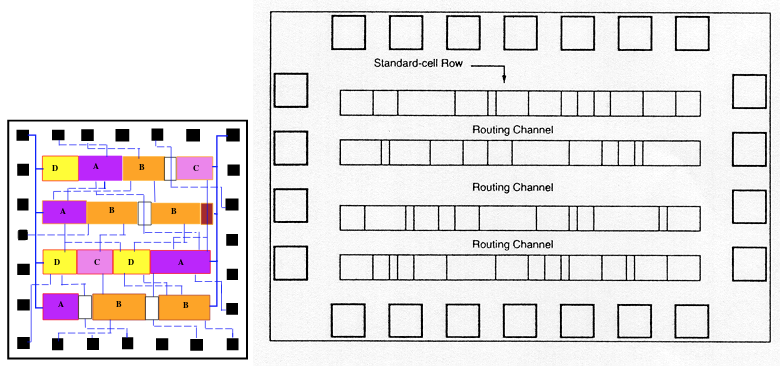
Для хакатона задачу можно упростить до уровня сферического коня в вакууме:
- Ограничить типы ячеек. Для начала можно вообще размещать просто граф из двухвходовых NAND.
- Считать все ячейки имеющими одинаковую ширину.
- Игнорировать все аспекты физической природы ячеек, в том числе задержку прохождения сигнала и энергопотребление.
Здесь «игнорировать» — означает, что в учебном упражнении можно не учитывать физику ячейки при оценке качества размещения и трассировки. Для начала достаточно учитывать только геометрию, например минимизировать общую длину соединений и количество слоев, на которых делаются соединения. Необходимость в новом слое возникает когда невозможно разместить два проводника без их пересечения.
На хакатоне достаточно рассматривать стандартные ячейки как «черные ящики» и выводить их на экран как на рисунках сверху. Или с изображениями логических элементов, как на слайде из лекций Игоря Маркова:

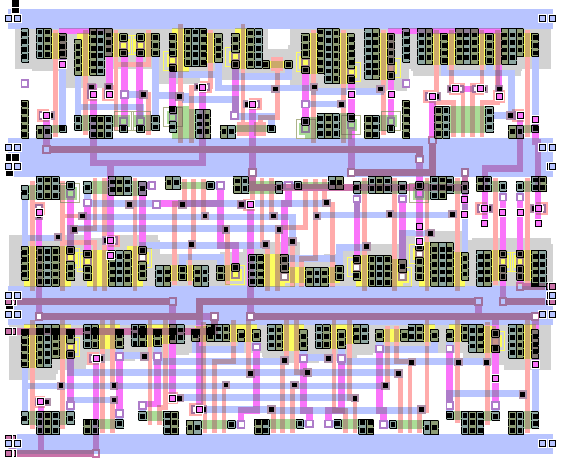
Хотя если выводить с внутренностями ячеек, то картинки получаются более декоративными. Слайд из лекций Чарльза Данчека:

Еще картинка из интернета с размещением и трассировкой + изображением внутренностей ячеек:
А как размещать ячейки в ряды, расширять и сужать каналы между рядами, строить соединения, вводить новые слои, оценивать оптимальность результатов и перебирать варианты? Ну это чисто алгоритмически-программистские задачки, в Иннополисе наверное такому учат, посему я не буду растекаться мыслию или мысью по древу. В качестве начального вдохновения для трассировки можно использовать древний метод волновой трассировки, который описан в третьей части курса для школьников от РОСНАНО. Хотя этот метод не для стандартных ячеек выстроенных в ряды, а для менее упорядоченного случая с небольшим числом компонент:
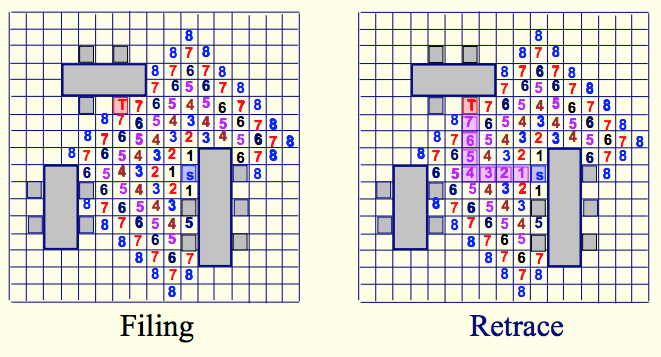
2.10. Как это делается: Алгоритм волновой трассировки.
Один из классических алгоритмов, которые применяли ранние программы трассировки — это волновая трассировка, которую описал в статье 1961 года Честер Ли (C. Y. Lee), исследователь из Bell Labs. По английски алгоритм Ли называют «maze routing», что дословно переводится как «лабиринтовая трассировка». Такое название связано с тем, что помимо программ для проектирования электроники, алгоритм Ли применяли в игровых программах для нахождения кратчайшего пути в лабиринте.
Алгоритм Ли представляет блоки, которые нужно соединить, в виде фигур на ограниченной плоскости, размеченной «в клеточку». Чтобы найти кратчайший путь от вывода одного блока к выводу другого блока, алгоритм Ли использует два прохода:
- Первый проход называется «распостранение волн». Помечаем все «клеточки» или ячейка у первого вывода единицей. После этого для каждой ячейки, помеченной числом N, помечаем все соседние свободные непомеченные ячейки числом N + 1. Повторяем разметку до тех пор, пока мы либо не дойдем к выводу второго блока, либо больше не будет возможности распостранять «волну».
- Второй проход называется «восстановление пути». Если ячейка у второго блока помечена, выберем среди ее соседей ячейку, которая помечена на 1 меньше, чем число в текущей ячейке. Добавляем соседнюю ячейку в путь, переходим в нее и начинаем смотреть на ее соседей, которые помечены еще на 1 меньше. Повторям это, пока мы не прийдем к выводу первого блока.
Сначала алгоритм Ли применяли в программах для проектирования печатных плат, потом его стали использовать и для проектирования микросхем. Однако когда размер микросхем вырос, применять алгоритм Ли в его первоначальном виде стало невозможно, так как он требует большого количества памяти для хранения массива данных, а также большого количества времени для многочисленных проходов через этот массив. Несмотря на то, что современные программы автоматической трассировки используют другие алгоритмы, алгоритм Ли остается отличным упражнением для тех, кто недавно освоил программирование и хочет написать небольшую программу трассировки сам.

Для более серьезных алгоритмов вы можете поискать идеи в материалах Игоря Маркова. Но круче всего было бы проявить творчество — вдруг вы придумаете что-нибудь, что не придумали тысячи математически-подкованных алгоритмистов-программистов, которые каждое утро стоят в пробках на 101-м, 880-м и 237-м фривеям в офисы Synopsys и Cadence в городах Сан-Хосе, Саннивейл и Маунтин-Вью, Калифорния.
Список литературы (от простого к сложному):
- Вводные лекции по основам цифрового проектирования в Иннополисе: 1, 2.
- Вводный курс в цифровую электронику и EDA для продвинутых школьников олимпиадного типа. От РОСНАНО: 1, 2, 3.
- Учебник Харрис & Харрис.
- Слайды лекций Чарльза Данчека.
- Курс Игоря Маркова из университета Мичигана. Этот курс он прочитал в МГУ.
Выражаю надежду, что почин Иннополиса по алгоритмическим соревнованиям расширится. Область EDA математически интересна и хорошо оплачивается. Synopsys открыл отделение в Армении и превратился там в одного из ведущих работодателей: «Today, Synopsys is one of the largest IT employers in Armenia with more than 650 employees (including more than 600 engineers).» Замечу, что Россия крупнее Армении и наверное может создать свой Synopsys. В конце-концов, программистов в России много, математиков тоже, а текущая рыночная капитализация Synopsys + Cadence примерно равна затратам на сочинскую олимпиаду.
Комментарии (28)

andy_p
01.10.2019 12:18Как это делается: Алгоритм волновой трассировки.
Не вводите людей в заблуждение. Для трассировки рядов стандартных ячеек используется канальная трассировка.

YuriPanchul Автор
01.10.2019 18:17+1Вы просто не прочитали внимательно. Я два раза написал, что этот алгоритм «для вдохновения», а не для трассировки standard cells. Вот перечитайте мой пост:
«Хотя этот метод не для стандартных ячеек выстроенных в ряды, а для менее упорядоченного случая с небольшим числом компонент»
«Несмотря на то, что современные программы автоматической трассировки используют другие алгоритмы, алгоритм Ли остается отличным упражнением для тех, кто недавно освоил программирование и хочет написать небольшую программу трассировки сам.»
Далее, в сценарии роснановского курса, который я цитирую, есть и про канальную трассировку:
2.9. Трассировка
Трассировка — это создание геометрических чертежей расположения соединений между элементами микросхемы. Современные алгоритмы трассировки приспособлены к современной организации микросхем, на основе рядов из стандартных ячеек одинаковой высоты. Эта организация позволяет упростить задачу трассировки для очень больших микросхем за счет разбиения ее на подзадачи: сначала делается глобальная трассировка на уровне всего чипа (global routing), потом локальные трассировки внутри каждого канала (channel routing). Кроме этого есть подзадача трассировки областей так называемых коробок переключений (switchbox), которые находятся на пересечении каналов, расположенных в перпендикулярных направлениях.
Алгоритмы трассировки, как и алгоритмы размещения, пробуют ортимизировать общую длину соединений и задержки сигналов на критическом пути. Не все соединения проходят только между двумя выводами стандартных ячеек. Часть соединяет три, четыре или более выводов.
Алгоритмы трассировки следят за соблюдений правил проектирования (design rules). Эти правила программы проектирования берут из набора файлов под названием Process design kit (PDK), который разрабатывает полупроводниковая фабрика. К правилам проектирования относятся минимальные расстояния между соединениями и частями транзистора в разных ситуациях. Также алгоритмы трассировки смотрят, чтобы не возникали проблемы с электрическими помехами, которые возникают, когда соединения находятся слишком близко друг к другу (по-английски это называется crosstalk).
Одно из направлений развития программ трассировки — это трассировка трехмерных чипов. Уже сейчас трассировка учитывает соединения в нескольких слоях, то есть не является чисто двухмерной задачей. Но одновременно возникают и экспериментальные чипы с транзисторами и памятью на разных слоях, либо в «этажерке» из нескольких кристаллов, либо в монолитном трехмерном чипе. Для таких структур нужны новые методы трассировки.

Disasm
01.10.2019 12:36И ни одного упоминания в статье таких инструментов, как graywolf и qrouter. Как так?

Lerk
01.10.2019 16:46А зачем? Это явно не те инструменты, с которых надо брать пример.
Разного рода мелких задачек в полноценном маршруте, которые можно улучшить — вагон и маленькая тележка. Например, «Standard Cell Pin Access and Physical Design in Advanced Lithography», чтобы далеко от задач роутинга не ходить.Disasm
01.10.2019 17:33+2Это открытые инструменты, которые можно взять за основу, а не делать всё с нуля.
YuriPanchul Автор
01.10.2019 18:19Для первоначального изучения алгоритмов полезно наделать кучу мелких программок с нуля. А вот потом можно ковыряться в программах побольше. Лично для меня такой комбинированный способ обучения более эффективен.

atrosinenko
01.10.2019 17:36Ещё некий Verilog to Routing (VTR) на Гитхабе периодически проскакивает — это не аналогичный проект?
Disasm
01.10.2019 17:54Это больше про FPGA, но в целом задачи схожие. Если говорить про FPGA, то сюда можно набросить ещё yosys и arachne-pnr/nextpnr.

Alyoshka1976
01.10.2019 14:05В такой простейшей постановке задача трассировки весьма подходит для применения Q-learning (нахождение оптимальной траектории + достижение конечной цели). Как водится, штраф за 1 ход + бонус за достижение конечной точки. И для разнообразия — штраф за изменение направления — тогда агент будет стараться избегать поворотов.
Ну почти как здесь, только надо запретить по диагонали ходить:

faoriu
01.10.2019 14:15Как я понимаю, главная фишка продвинутых EDA — это точная симуляция характеристик для заданной физической технологии, а алгоритмы 60-х любой студент может скопипастить, только в Huawei и Samsung его не позовут.
YuriPanchul Автор
01.10.2019 18:24Сразу не позовут, но с каких-нибудь алгоритмов нужно начинать. Вот в МГУ студенты даже выиграли международное соревнование по EDA алгоритмам — www.msu.ru/news/komanda-vmk-pobeditel-2015-cad-contest-at-iccad.html С таким достижением и в Samsung, и в Huawei позовут.
acex101
01.10.2019 18:24+1Какой тонкий троллинг от американского инженера:
1.«Уничтожить монополию Америки в ЕDA.»
2."… простейшую программу Place & Route может написать студент за выходные, но вот на продвинутую потребуются десятилетия работы сотен людей и миллиарды долларов на R&D."
3."… Россия крупнее Армении и наверное может создать свой Synopsys. В конце-концов, программистов в России много, математиков тоже, а текущая рыночная капитализация Synopsys + Cadence примерно равна затратам на сочинскую олимпиаду."YuriPanchul Автор
01.10.2019 18:27-1Вы можете рассматривать это как троллинг, но это и правда тоже. Замечу, что я в свое время продал свои патент и интеллектуальную собственность созданного мною EDA стартапа Synopsys-у — см. en.wikipedia.org/wiki/C_Level_Design

maxim_ge
02.10.2019 14:21Это просто замечательно. А не поделитесь немного информацией про то, как получать патенты в США?
YuriPanchul Автор
02.10.2019 18:20Я нанимал патентного адвоката на деньги инвесторов — обошлось более чем в 20 тысяч долларов. Процесс довольно нетривиальный, в двух словах не описать. Некоторые делают без адвоката — если идея простая, с малым числом claims. В крупных компаниях делание патентов работниками поставлено на поток — их обслуживает корпоративный юрист.
qwr124
02.10.2019 18:17На практике обычно над таким продуктом работает команда человек 20-40 в течение пары лет. Дальше идет поддержка тем же составом по мере роста базы кастомеров. Потом команда усыхает и продукт переходит в састейн мод.
Другое дело, что для покрытия e2e процессов надо иметь полное портфолио тулов — и тут да, несколько тысяч людей, десятки купленных стартапов, миллиарды долларов.
В результате сейчас _весь_мир_ может позволить себе содержать только Кейденс, Синопсис и Ментор Сименс бизнес. В существенной части это результат того, что производство микросхем тоже сконцентрировано сейчас до предела.

Sergey_Kovalenko
01.10.2019 22:25+2Простите, где там будет проходить следующий межгалактический шахматный турнир?
YuriPanchul Автор
01.10.2019 22:34+1Если не организовывать шахматные кружки, то точно нигде, а с кружками может появится хоть что-то

Blackfin
02.10.2019 18:18Из open-source есть http://opencircuitdesign.com/qflow/ и насколько я понимаю уже весь toolchain есть для FPGA/ASIC http://www.clifford.at/yosys/. Verilator успешно использовали в Tesla для их FSD чипа: Used Verilator, 50x faster than commercial simulators
Также помимо EDA тулов наверное есть смысл делать эмуляторы на FPGA и софт к ним. Как я понимаю без эмулирования дизайна на условном Synopsys ZeBu чип не выпустить. Юрий, у вас нет планов рассказать про эмуляцию и тестирование уже готового чипа ?atrosinenko
02.10.2019 18:32Эмуляторы на FPGA — это, что ли вроде FireSim? Кстати, а чем это отличается просто от синтеза под FPGA? Или это синтез под одну FPGA, будто это другая FPGA с другими скоростными характеристиками?
Lerk
02.10.2019 19:48А вы правда думаете, что кому то есть дело до скорости симулятора верилога?)) Это, право, смешно. Любой коммерческий чип упирается в моделирование на транзисторном уровне. Для FastSpice обычно используют XA от Synopsys, для более точного Spice — Spectre от Cadence.
Для понимания масштаба, последний Spectre X умеет разворачиваться в амазоновском облаке и запускаться на большом количестве мультсокетных машин. При этом моделирование может идти от нескольких часов до десятков дней.
На этом фоне скорость цифрового моделирования не интересует вообще никого.YuriPanchul Автор
03.10.2019 01:33Скорость симулятора верилога для компаний с большими CPU и GPU дизайнами очень важна. Говорю как бывший инженер в команде Synopsys VCS и текущий инженер MIPS.
Когда тест на VCS работает в 60 раз быстрее чем на Icarus Verilog, это сильно меняет дело. Так как в первом случае regression идет overnight, а во втором случае это бы заняло 1 месяц. Ночь или месяц — большая разница.Lerk
03.10.2019 01:57Это, конечно, здорово, что вам на работе разрешают тестить икарус)) Однако, сравнение его с vcs это запредельная лесть для икаруса. Если мы говорим про коммерческую разработку, то речь явно не о икарусе. И бутылочным горлышком event-driven моделирование явно не является.
Ну и если все же рассуждать про большие дизайны, то значит про UVM. Как дела у икаруса с этим делом? Подозреваю, что примерно никак, потому что UVM нынче в основном бегает на SV, а поддержки SV(SystemVerilog) у него нету.
Лист недочётов икаруса для коммерческой разработки можно продолжать бесконечно, но совершенно бесмысслено. Равно как и сильно вкладываться в движки для цифры, когда аналог моделируется на порядки дольше, а этого самого аналога нынче в самом захудалом SoC — вагон.
Lerk
02.10.2019 20:40Что касается эмуляции, то тут все очень плохо. Не в плане аппаратных решений, а в плане их доступности. Не говоря уже о том, что большая часть компаний не осиливает даже топ-левел смешанное моделирование до тейпаута…
Ну и упреждая возможный вопрос про моделирование на GPU — пока никто не хочет в это вкладываться, потому что фермы с CPU уже у всех больших компаний есть, а тратится на фермы GPU для какого-то одного конкретного тула экономически невыгодно.
Ну и общий тренд на моделирование в облаке сильно упрощает жизнь всяким стартапам, значительно снижая капитальные инвестиции и затраты на обслуживание. А мощностей в облаке, как водится, больше нужного.
schulzr
Коллеги из Казани, конечно, в курсе забегов ispd? http://www.ispd.cc/?page=contests
Можно сравниваться с международными командами. Плюс брать инфроструктуру.
YuriPanchul Автор
Да, вот в МГУ студенты даже выиграли международное соревнование по EDA алгоритмам — www.msu.ru/news/komanda-vmk-pobeditel-2015-cad-contest-at-iccad.html