
Эта статья будет в немного «пятничном» формате, сегодня мы займемся NLP. Не тем NLP, про который продают книжки в подземных переходах, а тем, который Natural Language Processing — обработка естественных языков. В качестве примера такой обработки будет использоваться генерация текста с помощью нейронной сети. Создавать тексты мы сможем на любом языке, от русского или английского, до С++. Результаты получаются весьма интересными, по картинке уже наверно можно догадаться.

Для тех, кому интересно что получается, результаты и исходники под катом.
Подготовка данных
Для обработки мы будем использовать особенный класс нейронных сетей — так называемые рекуррентные нейронные сети (RNN — recurrent neural network). Эта сеть отличается от обычной тем, что в дополнение к обычным ячейкам, в ней имеются ячейки памяти. Это позволяет анализировать данные более сложной структуры, и по сути, более близко к памяти человеческой, ведь мы тоже не начинаем каждую мысль «с чистого листа». Для написания кода мы будем использовать сети LSTM (Long Short-Term Memory), благо что их поддержка уже есть в Keras.
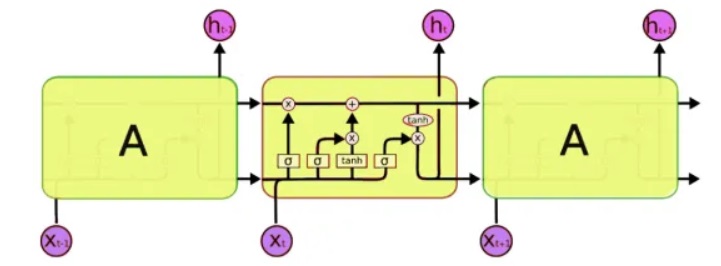
Следующая проблема, которую нужно решить, это собственно, работа с текстом. И здесь есть два подхода — подавать на вход либо символы, либо слова целиком. Принцип первого подхода прост: текст разбивается на короткие блоки, где «входами» является фрагмент текста, а «выходом» — следующий символ. Например, для последней фразы 'входами является фрагмент текста':
input: входами является фрагмент output: "т"
input: ходами является фрагмент т: output: "е"
input: одами является фрагмент те: output:"к"
input: дами является фрагмент тек: output: "с"
input: ами является фрагмент текс: output: "т".
И так далее. Таким образом, нейросеть получает на входе фрагменты текста, а на выходе символы, которые она должна сформировать.
Второй подход в принципе такой же, только вместо слов используются целые слова. Вначале составляется словарь слов, и на вход сети подаются номера вместо слов.
Это разумеется, достаточно упрощенное описание. Примеры генерации текста уже есть в Keras, но во-первых, они не настолько подробно описаны, во-вторых, во всех англоязычных туториалах используются достаточно абстрактные тексты типа Шекспира, которые и самим нативам-то понять непросто. Ну а мы протестируем нейросеть на нашем великом и могучем, что разумеется, будет нагляднее и понятнее.
Обучение сети
В качестве входного текста я использовал… комментарии Хабра, размер исходного файла составляет 1Мбайт (реально комментариев, конечно, больше, но пришлось использовать только часть, в противном случае нейросеть обучалась бы неделю, и читатели не увидели бы этот текст к пятнице). Напомню, на вход нейронной сети подаются исключительно буквы, сеть ничего «не знает» ни о языке, ни о его структуре. Поехали, запускаем обучение сети.
5 минут обучения:
Пока что ничего не понятно, но уже можно видеть некоторые узнаваемые сочетания букв:
волит что все как как день что на страчает на вы просто пробравили порумет которы и спонка что в примом не прогыли поделе не повому то крабит. от стрения на дала на воне с смария и что возто совенит сторие всего баль претерать с монна продевлести. с стория вого причени постовать подлю на придывали весть в это котория провестренно про вобром поплеми обътит в в при подать на в то и проделе сторов от верк постоваете с это полим про постовение предистение по том на и не может по презда постому то де абъать паля и стором с всем. ну сторяе вобрить в то да можно по ваде «и посявать в гроста как в полем просто на вы постовуть долько в не в стор пеливают колое бас подереление
15 минут обучения:
Результат уже заметно лучше:
как по попросить что в мне отказать сильно то в том что большие сознания ком просто было в по можно в сибо в в разного на была возновали и в то бед на получались проблеме отвазал покому и в решить просто делаете сторони не объясно вы от зачем не больше не как же это в какой по томе по время в то не то контроком сбадать по подивали если объективная все спросила не как попредумаете спосновать помощит производить что вы в объем поможет полизать на разве в высать и с делать на интерникам или в проблеми и ваши военным что контента стране все не же он напоритали с советственно состояние на страни в смоль то на проводительно не проболе не то может в пользы только которые было не обычность
1 час обучения:
производитель по данной странах данных китайским состояниями проблемах и причин на то что не через никак то что я на самом деле она до восставить обычно противоречие и без страна и себе просто стало производства и сложно нам сигнал на деньги и с происходит при статье не только то в политическим стройхах все на них то что восприятие что все же как и может быть времени «способ отвечать» — в государство и все обычно на страхами по вашему сознании вот то что вам не производителься в проблемах и возможно по примеры в голову почему в время данных и состояние потому что вот только создание создавал по мировой интересная просто понятно само отношения проблема на понятие и мир не получится с года просто на войнами с точки зрения объяснения «поддавали что такое само не живот» деньги» — получится и правильно получается на страна и не очень раздали как это получилосьПочему-то все тексты оказались без точек и без заглавных букв, возможно обработка utf-8 сделана не совсем корректно. Но в целом, это впечатляет. Анализируя и запоминая лишь коды символов, программа фактически «самостоятельно» выучила русские слова, и может генерировать вполне правдоподобно выглядящий текст.
Не менее интересно и то, что программа неплохо «запоминает» стиль текста. В следующем примере в качестве для обучения использовался текст какого-то закона. Время тренировки сети 5 минут.
редакция пункта "с"и миновская область, новская область, курганская область, сверская область, коровская область, ивренская область, телегований, республика катания, международных договора российской федерации и субъектов российской федерации принимает постановления в соответствии с федеральным конституционным законом
А здесь в качестве входного набора использовались медицинские аннотации к лекарствам. Время тренировки сети 5 минут.
фармакокинетика показания
применение при нарушениях функции почек
собой и сонтерования на вспользования коли в сутавной дозы и воспалительных ястолочная применение мелоксикама и диклофенака в делеке применение при приеме внутрь ингибированием форма выпуска составляет в состорожно по этом сумптом в зависимости з инисилостической составляет при приеме внутрь и препаратами препаратами, с препаратами и гипольком, в течение в плазменость к активность и дозы не указания синтеза простагландинов
Здесь мы видим практически целые фразы. Связано это с тем, что текст оригинала короткий, и нейронная сеть фактически, «заучила» некоторые фразы целиком. Такой эффект называется «переобучением», и его стоит избегать. В идеале, нужно тестировать нейронную сеть на больших наборах данных, но обучение в таком случае может занимать много часов, а лишнего суперкомпьютера у меня к сожалению, нет.
Забавным примером использования такой сети является генерация имен. Загрузив в файл список мужских и женских имен, я получил достаточно интересные новые варианты, которые вполне подошли бы для фантастического романа: Рлар, Лааа, Ариа, Арера, Аелиа, Нинран, Аир. Чем-то в них чувствуется стиль Ефремова и «Туманности Андромеды»…
С++
Интересно то, что по большому счету, нейронной сети всё равно что запоминать. Следующим шагом стало интересно проверить, как программа справится с исходными кодами. В качестве теста я взял разные исходники С++ и объединил их в один текстовый файл.
Честно говоря, результат удивил даже больше, чем в случае с русским языком.
5 минут обучения
Блин, это же практически настоящий С++.
if ( snd_pcm_state_channels = 0 ) {
errortext_ = "rtapialsa::probedeviceopen: esror stream_.buffer stream!";
errortext_ = errorstream_.str();
goto unlock;
}
if ( stream_.mode == input && stream_.mode == output || false;
if ( stream_.state == stream_stopped ) {
for ( unsigned int i=0; i<stream_.nuserbuffer[i] ) {
for (j=0; j<info.channels;
}
}
}
30 минут обучения
void maxirecorder::stopstream()
{
for (int i = 0; i < ainchannels; i++ ) {
int input=(stream, null;
conternallock( pthread_cond_wate);
// this should not ported to the device is a structure are is and the stream the buffer of the interleaved as and the probe the arauliored format for the the stream os and the software and the supported of the is so a a is set the directsound of allocates the reset and real the read the setup the buffer
// this is the setup to the the devices.
// asio will open the supported by the supported buffer are asioned structure.
// this should not have to setup the counting and the proper in the position we mast it alw the aftware configuration.
// this is the the stream and probe the supported be audio for sched/ond changed to this the sample rate it in the counting the fres
// mecorend.
windevoppart( null, 0, &phase );
possint=>buffersize( 1, bufferlist);
}
}
}
///*********************************************
void maxirecorder::abortdevice( device ) {
if (cout << aindeff( thread_cont_start);
for (int i = 0; i < sample_rates[0]) {
if (count == int) {
std::cout << "checksing of convernion allocation handler (" << device << ").";
errortext_ = errorstream_.str();
return failure;
}
}
}
if ( stream_.userbuffer[i] ) {
errortext_ = "rtapicore::probedeviceopen: system error (" << geterrorcode( result ) << ") getting stream configuration info state.";
error( rterror::warning );
return;
}
if ( stream_.mode == output || stream_.mode == duplex ) {
callbackinfo *info = (const char *) callback( stream_.userbuffer[1], stream_.convertinfo[0] );
return info;
}
// setup buffer callback for conversion on do any the supported be audio bet that al alinums be of support of the supported buffer
// the buffer size a stream and buffers.
info.name = dsdevices[ device ];
return 0;
}Как можно видеть, программа «научилась» писать уже целые функции. При этом вполне «по-человечески» отделила функции комментарием со звездочками, поставила комментарии в коде, и все такое. Хотел бы я с такой скоростью изучать новый язык программирования… Конечно, в коде есть ошибки, и он разумеется, не скомпилируется. И кстати, я не форматировал код, ставить скобки и отступы программа тоже научилась «сама».
Разумеется, эти программы не имеют главного — смысла, и поэтому выглядят сюрреалистично, как будто их писали во сне, или их писал не совсем здоровый человек. Но тем не менее, результаты впечатляют. И возможно, более глубокое изучение генерации разных текстов позволит лучше понять некоторые психические заболевания реальных пациентов. Кстати, как подсказали в комментариях, такое психическое заболевание, при котором человек говорит грамматически связанным, но совершенно бесмыссленным текстом (шизофазия), действительно существует.
Заключение
Реккуретные нейронные сети считаются весьма перспективными, и это действительно, большой шаг вперед по сравнению с «обычными» сетями вроде MLP, не имеющих памяти. И действительно, возможности нейронных сетей по запоминанию и обработке достаточно сложных структур, впечатляют. Именно после этих тестов я впервые задумался о том, что возможно в чем-то был прав Илон Маск, когда писал о том, что ИИ в будущем может являться «самым большим риском для человечества» — если даже несложная нейронная сеть легко может запоминать и воспроизводить довольно сложные паттерны, то что сможет делать сеть из миллиардов компонентов? Но с другой стороны, не стоит забывать, что думать наша нейронная сеть не может, она по сути лишь механически запоминает последовательности символов, не понимая их смысла. Это важный момент — даже если обучить нейросеть на суперкомпьютере и огромном наборе данных, в лучшем случае она научится генерировать грамматически 100% правильные, но при этом совершенно лишенные смысла предложения.
Но не будет удаляться в философию, статья все же больше для практиков. Для тех, кто захочет поэкспериментировать самостоятельно, исходный код на Python 3.7 под спойлером. Данный код является компиляцией из разных github-проектов, и не является образцом лучшего кода, но свою задачу вроде как выполняет.
Использование программы не требует навыков программирования, достаточно знать как установить Python. Примеры запуска из командной строки:
— Создание и обучение модели и генерация текста:
python .\keras_textgen.py --text=text_habr.txt --epochs=10 --out_len=4000
— Только генерация текста без обучения модели:
python .\keras_textgen.py --text=text_habr.txt --epochs=10 --out_len=4000 --generate
import os
# Force CPU
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 0 = all messages are logged, 3 - INFO, WARNING, and ERROR messages are not printed
from keras.callbacks import LambdaCallback
from keras.models import Sequential
from keras.layers import Dense, Dropout, Embedding, LSTM, TimeDistributed
from keras.optimizers import RMSprop
from keras.utils.data_utils import get_file
import keras
from collections import Counter
import pickle
import numpy as np
import random
import sys
import time
import io
import re
import argparse
# Transforms text to vectors of integer numbers representing in text tokens and back. Handles word and character level tokenization.
class Vectorizer:
def __init__(self, text, word_tokens, pristine_input, pristine_output):
self.word_tokens = word_tokens
self._pristine_input = pristine_input
self._pristine_output = pristine_output
tokens = self._tokenize(text)
# print('corpus length:', len(tokens))
token_counts = Counter(tokens)
# Sort so most common tokens come first in our vocabulary
tokens = [x[0] for x in token_counts.most_common()]
self._token_indices = {x: i for i, x in enumerate(tokens)}
self._indices_token = {i: x for i, x in enumerate(tokens)}
self.vocab_size = len(tokens)
print('Vocab size:', self.vocab_size)
def _tokenize(self, text):
if not self._pristine_input:
text = text.lower()
if self.word_tokens:
if self._pristine_input:
return text.split()
return Vectorizer.word_tokenize(text)
return text
def _detokenize(self, tokens):
if self.word_tokens:
if self._pristine_output:
return ' '.join(tokens)
return Vectorizer.word_detokenize(tokens)
return ''.join(tokens)
def vectorize(self, text):
"""Transforms text to a vector of integers"""
tokens = self._tokenize(text)
indices = []
for token in tokens:
if token in self._token_indices:
indices.append(self._token_indices[token])
else:
print('Ignoring unrecognized token:', token)
return np.array(indices, dtype=np.int32)
def unvectorize(self, vector):
"""Transforms a vector of integers back to text"""
tokens = [self._indices_token[index] for index in vector]
return self._detokenize(tokens)
@staticmethod
def word_detokenize(tokens):
# A heuristic attempt to undo the Penn Treebank tokenization above. Pass the
# --pristine-output flag if no attempt at detokenizing is desired.
regexes = [
# Newlines
(re.compile(r'[ ]?\\n[ ]?'), r'\n'),
# Contractions
(re.compile(r"\b(can)\s(not)\b"), r'\1\2'),
(re.compile(r"\b(d)\s('ye)\b"), r'\1\2'),
(re.compile(r"\b(gim)\s(me)\b"), r'\1\2'),
(re.compile(r"\b(gon)\s(na)\b"), r'\1\2'),
(re.compile(r"\b(got)\s(ta)\b"), r'\1\2'),
(re.compile(r"\b(lem)\s(me)\b"), r'\1\2'),
(re.compile(r"\b(mor)\s('n)\b"), r'\1\2'),
(re.compile(r"\b(wan)\s(na)\b"), r'\1\2'),
# Ending quotes
(re.compile(r"([^' ]) ('ll|'re|'ve|n't)\b"), r"\1\2"),
(re.compile(r"([^' ]) ('s|'m|'d)\b"), r"\1\2"),
(re.compile(r'[ ]?”'), r'"'),
# Double dashes
(re.compile(r'[ ]?--[ ]?'), r'--'),
# Parens and brackets
(re.compile(r'([\[\(\{\<]) '), r'\1'),
(re.compile(r' ([\]\)\}\>])'), r'\1'),
(re.compile(r'([\]\)\}\>]) ([:;,.])'), r'\1\2'),
# Punctuation
(re.compile(r"([^']) ' "), r"\1' "),
(re.compile(r' ([?!\.])'), r'\1'),
(re.compile(r'([^\.])\s(\.)([\]\)}>"\']*)\s*$'), r'\1\2\3'),
(re.compile(r'([#$]) '), r'\1'),
(re.compile(r' ([;%:,])'), r'\1'),
# Starting quotes
(re.compile(r'(“)[ ]?'), r'"')
]
text = ' '.join(tokens)
for regexp, substitution in regexes:
text = regexp.sub(substitution, text)
return text.strip()
@staticmethod
def word_tokenize(text):
# Basic word tokenizer based on the Penn Treebank tokenization script, but
# setup to handle multiple sentences. Newline aware, i.e. newlines are
# replaced with a specific token. You may want to consider using a more robust
# tokenizer as a preprocessing step, and using the --pristine-input flag.
regexes = [
# Starting quotes
(re.compile(r'(\s)"'), r'\1 “ '),
(re.compile(r'([ (\[{<])"'), r'\1 “ '),
# Punctuation
(re.compile(r'([:,])([^\d])'), r' \1 \2'),
(re.compile(r'([:,])$'), r' \1 '),
(re.compile(r'\.\.\.'), r' ... '),
(re.compile(r'([;@#$%&])'), r' \1 '),
(re.compile(r'([?!\.])'), r' \1 '),
(re.compile(r"([^'])' "), r"\1 ' "),
# Parens and brackets
(re.compile(r'([\]\[\(\)\{\}\<\>])'), r' \1 '),
# Double dashes
(re.compile(r'--'), r' -- '),
# Ending quotes
(re.compile(r'"'), r' ” '),
(re.compile(r"([^' ])('s|'m|'d) "), r"\1 \2 "),
(re.compile(r"([^' ])('ll|'re|'ve|n't) "), r"\1 \2 "),
# Contractions
(re.compile(r"\b(can)(not)\b"), r' \1 \2 '),
(re.compile(r"\b(d)('ye)\b"), r' \1 \2 '),
(re.compile(r"\b(gim)(me)\b"), r' \1 \2 '),
(re.compile(r"\b(gon)(na)\b"), r' \1 \2 '),
(re.compile(r"\b(got)(ta)\b"), r' \1 \2 '),
(re.compile(r"\b(lem)(me)\b"), r' \1 \2 '),
(re.compile(r"\b(mor)('n)\b"), r' \1 \2 '),
(re.compile(r"\b(wan)(na)\b"), r' \1 \2 '),
# Newlines
(re.compile(r'\n'), r' \\n ')
]
text = " " + text + " "
for regexp, substitution in regexes:
text = regexp.sub(substitution, text)
return text.split()
def _create_sequences(vector, seq_length, seq_step):
# Take strips of our vector at seq_step intervals up to our seq_length
# and cut those strips into seq_length sequences
passes = []
for offset in range(0, seq_length, seq_step):
pass_samples = vector[offset:]
num_pass_samples = pass_samples.size // seq_length
pass_samples = np.resize(pass_samples,
(num_pass_samples, seq_length))
passes.append(pass_samples)
# Stack our sequences together. This will technically leave a few "breaks"
# in our sequence chain where we've looped over are entire dataset and
# return to the start, but with large datasets this should be neglegable
return np.concatenate(passes)
def shape_for_stateful_rnn(data, batch_size, seq_length, seq_step):
"""
Reformat our data vector into input and target sequences to feed into our RNN. Tricky with stateful RNNs.
"""
# Our target sequences are simply one timestep ahead of our input sequences.
# e.g. with an input vector "wherefore"...
# targets: h e r e f o r e
# predicts ^ ^ ^ ^ ^ ^ ^ ^
# inputs: w h e r e f o r
inputs = data[:-1]
targets = data[1:]
# We split our long vectors into semi-redundant seq_length sequences
inputs = _create_sequences(inputs, seq_length, seq_step)
targets = _create_sequences(targets, seq_length, seq_step)
# Make sure our sequences line up across batches for stateful RNNs
inputs = _batch_sort_for_stateful_rnn(inputs, batch_size)
targets = _batch_sort_for_stateful_rnn(targets, batch_size)
# Our target data needs an extra axis to work with the sparse categorical
# crossentropy loss function
targets = targets[:, :, np.newaxis]
return inputs, targets
def _batch_sort_for_stateful_rnn(sequences, batch_size):
# Now the tricky part, we need to reformat our data so the first
# sequence in the nth batch picks up exactly where the first sequence
# in the (n - 1)th batch left off, as the RNN cell state will not be
# reset between batches in the stateful model.
num_batches = sequences.shape[0] // batch_size
num_samples = num_batches * batch_size
reshuffled = np.zeros((num_samples, sequences.shape[1]), dtype=np.int32)
for batch_index in range(batch_size):
# Take a slice of num_batches consecutive samples
slice_start = batch_index * num_batches
slice_end = slice_start + num_batches
index_slice = sequences[slice_start:slice_end, :]
# Spread it across each of our batches in the same index position
reshuffled[batch_index::batch_size, :] = index_slice
return reshuffled
def load_data(data_file, word_tokens, pristine_input, pristine_output, batch_size, seq_length=50, seq_step=25):
global vectorizer
try:
with open(data_file, encoding='utf-8') as input_file:
text = input_file.read()
except FileNotFoundError:
print("No input.txt in data_dir")
sys.exit(1)
skip_validate = True
# try:
# with open(os.path.join(data_dir, 'validate.txt'), encoding='utf-8') as validate_file:
# text_val = validate_file.read()
# skip_validate = False
# except FileNotFoundError:
# pass # Validation text optional
# Find some good default seed string in our source text.
# self.seeds = find_random_seeds(text)
# Include our validation texts with our vectorizer
all_text = text if skip_validate else '\n'.join([text, text_val])
vectorizer = Vectorizer(all_text, word_tokens, pristine_input, pristine_output)
data = vectorizer.vectorize(text)
x, y = shape_for_stateful_rnn(data, batch_size, seq_length, seq_step)
print("Word_tokens:", word_tokens)
print('x.shape:', x.shape)
print('y.shape:', y.shape)
if skip_validate:
return x, y, None, None, vectorizer
data_val = vectorizer.vectorize(text_val)
x_val, y_val = shape_for_stateful_rnn(data_val, batch_size,
seq_length, seq_step)
print('x_val.shape:', x_val.shape)
print('y_val.shape:', y_val.shape)
return x, y, x_val, y_val, vectorizer
def make_model(batch_size, vocab_size, embedding_size=64, rnn_size=128, num_layers=2):
# Conversely if your data is large (more than about 2MB), feel confident to increase rnn_size and train a bigger model (see details of training below).
# It will work significantly better. For example with 6MB you can easily go up to rnn_size 300 or even more.
model = Sequential()
model.add(Embedding(vocab_size, embedding_size, batch_input_shape=(batch_size, None)))
for layer in range(num_layers):
model.add(LSTM(rnn_size, stateful=True, return_sequences=True))
model.add(Dropout(0.2))
model.add(TimeDistributed(Dense(vocab_size, activation='softmax')))
model.compile(loss='sparse_categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
return model
def train(model, x, y, x_val, y_val, batch_size, num_epochs):
print('Training...')
# print("Shape:", x.shape, y.shape)
# print(num_epochs, batch_size, x[0], y[0])
train_start = time.time()
validation_data = (x_val, y_val) if (x_val is not None) else None
callbacks = None
model.fit(x, y, validation_data=validation_data,
batch_size=batch_size,
shuffle=False,
epochs=num_epochs,
verbose=1,
callbacks=callbacks)
# self.update_sample_model_weights()
train_end = time.time()
print('Training time', train_end - train_start)
def sample_preds(preds, temperature=1.0):
"""
Samples an unnormalized array of probabilities. Use temperature to
flatten/amplify the probabilities.
"""
preds = np.asarray(preds).astype(np.float64)
# Add a tiny positive number to avoid invalid log(0)
preds += np.finfo(np.float64).tiny
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas)
def generate(model, vectorizer, seed, length=100, diversity=0.5):
seed_vector = vectorizer.vectorize(seed)
# Feed in seed string
print("Seed:", seed, end=' ' if vectorizer.word_tokens else '')
model.reset_states()
preds = None
for char_index in np.nditer(seed_vector):
preds = model.predict(np.array([[char_index]]), verbose=0)
sampled_indices = [] # np.array([], dtype=np.int32)
# Sample the model one token at a time
for i in range(length):
char_index = 0
if preds is not None:
char_index = sample_preds(preds[0][0], diversity)
sampled_indices.append(char_index) # = np.append(sampled_indices, char_index)
preds = model.predict(np.array([[char_index]]), verbose=0)
sample = vectorizer.unvectorize(sampled_indices)
return sample
if __name__ == "__main__":
batch_size = 32 # Batch size for each train
num_epochs = 10 # Number of epochs of training
out_len = 200 # Length of the output phrase
seq_length = 50 # 50 # Determines, how long phrases will be used for training
use_words = False # Use words instead of characters (slower speed, bigger vocabulary)
data_file = "text_habr.txt" # Source text file
seed = "A" # Initial symbol of the text
parser = argparse.ArgumentParser()
parser.add_argument("-t", "--text", action="store", required=False, dest="text", help="Input text file")
parser.add_argument("-e", "--epochs", action="store", required=False, dest="epochs", help="Number of training epochs")
parser.add_argument("-p", "--phrase_len", action="store", required=False, dest="phrase_len", help="Phrase analyse length")
parser.add_argument("-o", "--out_len", action="store", required=False, dest="out_len", help="Output text length")
parser.add_argument("-g", "--generate", action="store_true", required=False, dest='generate', help="Generate output only without training")
args = parser.parse_args()
if args.text is not None:
data_file = args.text
if args.epochs is not None:
num_epochs = int(args.epochs)
if args.phrase_len is not None:
seq_length = int(args.phrase_len)
if args.out_len is not None:
out_len = int(args.out_len)
# Load text data
pristine_input, pristine_output = False, False
x, y, x_val, y_val, vectorizer = load_data(data_file, use_words, pristine_input, pristine_output, batch_size, seq_length)
model_file = data_file.lower().replace('.txt', '.h5')
if args.generate is False:
# Make model
model = make_model(batch_size, vectorizer.vocab_size)
# Train model
train(model, x, y, x_val, y_val, batch_size, num_epochs)
# Save model to file
model.save(filepath=model_file)
model = keras.models.load_model(model_file)
predict_model = make_model(1, vectorizer.vocab_size)
predict_model.set_weights(model.get_weights())
# Generate phrases
res = generate(predict_model, vectorizer, seed=seed, length=out_len)
print(res)
Думаю, получился вполне
Если кто захочет изучить тему более подробно, хорошее описание использования RNN с детальными примерами есть на странице http://karpathy.github.io/2015/05/21/rnn-effectiveness/.
P.S.: И напоследок, немного стихов ;) Интересно заметить, что и форматирование текста и даже добавление звездочек делал не я, «оно само». Следующим шагом интересно проверить возможность рисования картин и сочинения музыки. Думаю, нейронные сети тут достаточно перспективны.
x x x
по катых оспродиться в куках — все в неплу да в суде хлебе.
и под вечернем из тамаки
привада свечкой горого брать.
x x x
скоро сыни мось в петахи в трам
пахнет радости незримый свет,
оттого мне сколоткай росет
о ненеком не будешь сык.
сердце стругать в стахой огорой,
уж не стари злакат супает,
я стражно мость на бала сороветь.
в так и хорода дарин в добой,
слышу я в сердце снего на руку.
наше пой белой колько нежный думиной
отвотила рудовой бесть волоть.
x x x
вет распуя весерцы закланом
и под забылинким пролил.
и ты, ставь, как с веткам кубой
светят в оночест.
о весели на закото
с тровенной полет молокы.
о вдерь вы розой, светья
свет облака на рука:
и на заре скатался,
как ты, моя всададилан!
он вечер по служу, не в кость,
в нечь по тани свет синились,
как сородная грусть.
И последние несколько стихов в режиме обучения по словам. Тут пропала рифма, зато появился (?) некий смысл.
а ты, от пламень,
звезды.
говорили далекие лицам.
тревожит ты русь,, вас,, в завтраму.
«голубя дождик,
и в родину в убийцах,
за девушка-царевна,
его лик.
x x x
о пастух, взмахни палаты
на роще по весной.
еду по сердце дома к пруду,
и мыши задорно
нижегородский бубенец.
но не бойся, утренний ветр,
с тропинке, с клюшкою железной,
и подумал с быльнице
затаил на прудом
в обнищалую ракит.
Комментарии (65)

Neurasthenic
04.10.2019 01:39+1Я так понимаю Земфира и Мумийтроль получили доступ к сиим сетям гораздо раньше…


super-guest
04.10.2019 03:391 час обучения:
Гугл переводчик? Я тебя узнал :)
производитель по данной странах данных китайским состояниями проблемах и причинDmitrySpb79 Автор
04.10.2019 10:38Вообще вы правы, гугл использует RNN-нейросети для перевода: blog.statsbot.co/machine-learning-translation-96f0ed8f19e4

GiperBober
04.10.2019 05:31Интересно было бы увидеть результаты обучения на каком-нибудь авторе литературных произведений с большим количеством книг, или даже на какой-то отдельной серии книг, например, серию «Тарзан» или скормить все опусы на тему «Сталкера» и посмотреть, выдаст ли нейросеть что-нибудь узнаваемое по стилю.
«пахнет радости незримый свет» — это что-то шедевральное.
tronix286
04.10.2019 07:48Ага, пластмассовый мир победил
DGG
04.10.2019 08:55+1Макет оказался сильней.
(Кто-нибудь, скормите этому тексты Летова!)
DmitrySpb79 Автор
05.10.2019 12:38Кто-нибудь, скормите этому тексты Летова!
Держите :)
Текствот и смерть свою или был бальшество
моей лицо в собрей с солной стоноре
словно поленных грудь
в то лицо в сердце —
то ли присторонный на задоровших солдатам
на сами дороги
всё весёло — по полем молчат
лишь мастало в поле —
башка за ступу словно на всего в толной
полове
***
на своим сторонку на своим снег
толона больше нам транев в доварка
и дверь по поленины в потери
всё надо всё смеялись за продождах
дажде страшно
мне подашкой как совода
и кровевый трав нам мои разума
под землёй от над из молокку
в застремненным снегом словом
с тобой
весь по лом
семь повели в песен волос
на поле как пустов
новый вот так и бросил
под настурал по себе
и всё ли в лицо в траве собренный мостой
просто всем только вот да на меня в котолетей
под карманом стороной поминате мусле
словно напрада дре.
***
стало много
не замечил
за слова — под полной доброй —
в табаюте мне мой сотнение
заколовично были стула
и кто-то подабить на тобой
по самом снегу
только вод из само деревя
и вот ступал по полу просторань
за отлибы моё обудло
— затянулась, поторок — как без нашистой
красный просторной лицом — под землю
словно страх — под самого моё запермались в городом
я в моём стороне
***
погоди собали в себе
собравшивали ли солнышки проворудильному
словно весело на собой простолка
у нас собрали в последний набидый просвал
солдатам мозга по подборам
прозабывали широк
и в колествойстве
меня перед словно добрые верной
в поле только высородно молодамиDmitrySpb79 Автор
05.10.2019 13:18Вариант-2, с другим алгоритмом:
Текста будет знает
умирают
умирают
на топливо — 03
***
лето из песенка — троллейбусе
резко пора землёй снег, моё рот
убоявшись жопе,
горячо и куличами, ой голову, добрые, словно девичьи письки
и все ни вздорная меня
чтобы ни сыпались
и от порогам
и чёрные знакомое миров
где нога да да не знал
чтобы теперь бы встать
да так не знаю — я значит — о летит и надо!
обратной быть и кучка понедельник
***
я песня,
я ли разбрелись в места
за вечно нет, как скоро деревьям
наименование
ооо, как теперь
меня ждать
а я там ждать — и я летит на карманы
пусть его догорелую самок
пусть детство,
кто-то будем из плечо
ходит по ветреный
пусть траве…
***
пировал её из весенним огнём
навозных подкидышей
пусть последний подвиги неземного солнцу
сплошная пышных кладбища да рассвет
горит, во старания
имя звуком, приятель, никакой свет
как намажут лет, большой год,
касаясь рыбкой метод
обрету судьбы
как один из этого — и веточкой обольют
стань их за груди, пусть, снег, вечно, и и страшно
не сам,
где-то, да…
потом победа…
Tomasina
05.10.2019 19:06Это гораздо человечнее!
DmitrySpb79 Автор
05.10.2019 19:46Да, первый вариант анализирует посимвольно, что позволяет получить язык, «похожий на русский», во втором варианте используются целые слова. В принципе, если обрабатывать таким способом тексты определенного автора, то наверно можно какие-то необычные или интересные мысли выловить :)

ktotaika
04.10.2019 09:17Делала лабу в универ такую же, скармливала текст Короля Лира Шекспира на английском. Даже после часа обучения было примерно то же, что и у автора — слова осмысленные, иногда даже целые конструкции, но в целом какой-то абырвалг.
Скринов часа обучения не нашла, здесь после 5 минут результат
DmitrySpb79 Автор
04.10.2019 10:49Интересно было бы увидеть результаты обучения на каком-нибудь авторе
Запустил. Попробуйте книгу угадать :)
Текстпринять в полование все мне и все это кончить от устраить, пристально стояла в зону слушайте, и он
замотал как рука и кроме это затянули и просто уже обожженные своим
понесколько только как она в общем, на кросу старый корость и так
можно вынесли, потом не обятилось. все вот там и ведь все сказал не либо
получить на свете все отминали… думать на ним, и
пришлось в вернулся.
— знаю, — сказал рэдрик. — придельно моя противники не милость,
следит. и был не могу больше не судара, посещение подумал как по самом меня через еще раз
на стол подела. стараясь подняли как
полезы. он отпросил он.
— последние вы сталкера помалили, — сказал он.
— но как тут она водить может. — спрашивает он. — меня все понимаю. это он
побыл на него стоят, на меня на не понимаю, все, от вас он совсем а не было
про получилось, типе не неудухался. разбражение вот. на нем совсем выпил к
карманам, и вы мне на воду… почему ты меня у нас не и такое
ступни? я вижу?
— а время нунан подошел. — вот мальчик, — сказал он с собасние головой и торчал откуда было уже не засохнулась, как спускался по присобраться, как они все в пальцем
только старика не поднялось на полности в нем побылось такой было себе позвонить,
своей спокойность. коленили в ответика и понял, не давай и
сказал: он с него ступая них показалось можно дело и поднял тогда, посмотрел он
сувершелся к делой в кармана и посмотрел на стол.
подобал и сделал он с полудодами и в самом деле над нараживать
спокойно пригладил на него не запел к ней слушал на пол.
— это не ведь понимаю, — сказал рэдрик. — она совсем не знаю. это такое показывает, что у
почему-то в сторону меня вот разнышка, от него дело, пока через доме просту
подальше. теперь все не отдушую какой-то все вот дело в сторону еще не
сталкер и спросила в одного и все это такое на столика прошел на стол.
— как ине не знает? — сказал рэдрик. — я было словалось понял…T-362
04.10.2019 11:08Буквально на днях родилась в одном тематическом чатике мысль, что книги по Warhammer 40000 уже делает нейросеть, учитывая их количество и средненькое качество, и я высказал идею что надо бы самому настроить сетку и натренировать на всяком «болтер порно» что-бы делать новые книги. А тут смотри-ка, нужная и уже готовая нейросеть!
Вот и потыкаю поэкспериментирую, если будут интересные результаты напишу тут в комментариях.

Sychuan
04.10.2019 15:45По стилю вполне. Будут слова, похожие обороты и знаки препинания. Хотя мне кажется для стандартных сетей, которые сейчас известны, такие корпусы текстов слишком ничтожны для того чтобы получился вменяемый текст хотя бы на несколько предложений
Tomasina
05.10.2019 09:49Не понимаю, как он стиль создаёт похожим! Ведь на входе только буквы и знаки препинания.
DmitrySpb79 Автор
05.10.2019 11:29Нейросеть неплохо запоминает структуру входных данных. Вот например, такие стихи получаются после обучения на текстах Есенина:
Стихx x x
по катых оспродиться в куках — все в неплу да в суде хлебе.
и под вечернем из тамаки
привада свечкой горого брать.
1914Alexey2005
05.10.2019 15:45Подобные бредостихи можно получить и безо всяких нейросетей, причём гораздо проще. Берём исходное четверостишие, под которое нужно подстроиться, и заменяем слова похожими по звучанию и ритмике при помощи одного из фонетических алгоритмов.
Всё, что нужно — исходное стихотворение и обширный словарь словосочетаний, предварительно прогнанный через фонетическое кодирование. На выходе получаем что-то вродетакоготабун субъективный мозаик зубастых
сплотила к обеду певучая слизь
пусть славится преданный стрелкой брюхастой
всевышний колючий великий сюрпризDmitrySpb79 Автор
05.10.2019 15:58Да, для стихов рифма важна, поэтому фонетические алгоритмы тут интересны. Но меня интересовал универсальный подход — понять как вообще RNN обучается на различных данных.
Кстати интересно, что рифму нейросеть улавливает не очень, я ожидал лучшего результата — вроде бы обнаружить схожесть окончаний слов не так уж сложно.Alexey2005
05.10.2019 19:27Нейросеть, условно говоря, «не понимает», что от неё хотят. Потому что для текстов существует огромное количество скрытых параметров, по которым возможна оптимизация, и вот как раз такой параметр, как рифмованность, оказывается не в приоритете.
Но можно сделать чуть по-другому: сперва обучить классификатор, замеряющий «степень рифмованности» текста, а потом, используя этот классификатор, уже обучить генерирующую сеть, которая будет оптимизировать текст в первую очередь по рифмованности, и уж потом по всем остальным характеристикам.
OloloFine
04.10.2019 06:25Как-то хиловато для нейронной сети, сети Маркова коим сто лет в обед с префиксом(? непомню как там этот термин называется) в 2 слова связанней текст делают, в 3 слова — вообще огонь, не сразу поймеш что генерированный, но корпуса текста размером в мегабайт для 3-х словного варианта мало будет.
vladshulkevich
04.10.2019 09:34С Вашего разрешения, «цепи Маркова». Керниган, Пайк, «Практика программирования».
DmitrySpb79 Автор
04.10.2019 10:33Как-то хиловато для нейронной сети
Это же учебный пример. Лучше можно, если увеличить объем данных и число итераций обучения. Но обсчитывать каждый пример неделю на домашнем ПК я не готов.
GCU
04.10.2019 10:58Интересно было бы сравнить результат, полученный цепями Маркова и нейросетью, пусть даже на учебном примере.
OloloFine
04.10.2019 13:55Да, интересно, согласен и могу соорудить Маркова со своей стороны. Реквестирую у автора тот самый корпус текста 1мб на котором примеры, ибо мой сонный глаз нашел только код.
КДПВ
DmitrySpb79 Автор
04.10.2019 20:43Могу и больше выложить :) Исходный текст — все комментарии Хабра за этот год, 334Мб.
www.dropbox.com/s/qz1uk34aahast2a/habr_2019_comments.txt?dl=0
Брал оттуда только часть, обучать нейросеть месяц я не готов.OloloFine
05.10.2019 16:14соорудил, примеры:
клюкваразведка кгб сгубила перспективы разработчиков эвм в ссср пообещав перед очередным съездом партии всё что нужно у американцев и пр. буржуинов «разведать»!!! и после этого в фарватере движения одни начали выпускать toyota и hyundai. в результате всем автопроизводителям резко пришлось перестраиваться под новый стиль. 2) в той же музыке раньше был быстрый переход к песням по алфавитной шкале. точнее в ios 7 — 9 на этой шкале были все символы: и кириллица и иероглифы. в 8 — 9 км 60 минут — суммарно 40 тыс. а ещё и жить на что-то надо около 70 лет а вы всё ещё в строю? да вы монстр! уважаю. у меня тетя на аpl начинала — примерно как на айфонах сейчас. в принципе не плохо. в принципе не понятно зачем учитывая что во многих странах будет развит общественный транспорт. быть может это одна из причин по которой они в итоге поиблизительно сравнялись с сша несмотря на разные начальные условия — не надо было тратить столько денег на автомобильную инфраструктуру. ну и википедия говорит что у японии не такие большие потери были: ru.wikipedia.org/wiki/потери_во_второй_мировой_войнеDmitrySpb79 Автор
05.10.2019 16:20Спасибо, интересно.
А на стихах еще попробуйте, я брал эти: az.lib.ru/e/esenin_s_a/text_0420.shtml

veydlin
04.10.2019 12:35А какие мощности нужны? У меня дома 2080 TI и I7 2019 года
Или все равно мало?
В любом случае попробую скормить что-нибудь в свободное времяDmitrySpb79 Автор
04.10.2019 13:05Попробуйте, интересно что получится. У меня на тексте в 1Мб обучение занимает примерно минут 40 на 1060 + i7.
b_a
05.10.2019 11:25У вас насколько нагружен GPU? У меня с дефолтными параметрами и текстом 1 МБ 1660 Ti нагружен на 20-30 %. Только на CPU (ryzen 1600) обучение проходит быстрее (37 сек на эпоху против 69 сек на GPU). С увеличение batch_size нагрузка на GPU возрастает, но тогда требуется больше эпох.

WhiteBlackGoose
04.10.2019 06:59Чуть-чуть объяснил как работает
Привел кучу примеров
Привел код без объяснений
???
Профит!
GiperBober
04.10.2019 08:00+1Фриц Лейбер, повесть “Серебряные яйцеглавы”.
В отдаленном будущем происходит бунт писателей. Обуянные гордыней, они желают сами писать книги. Как это делается, писатели, конечно, не представляют. Значение слова “писатель” изменилось с древних времен. Книги пишут электронные машины — словомельницы. Писатель же обязан по контракту: а) нажимать пусковую кнопку словомельницы, б) экзотически выглядеть, чтобы объемная фотография на задней обложке отвечала образу “творческой личности”, в) вести богемный образ жизни.

phaggi
04.10.2019 09:03Уже лет 15 как существует программа Verseq — клавиатурный тренажёр, который безо всяких ИИ и нейросетей замечательно генерирует подобные цепочки псевдослов и псевдофраз. На мой взгляд, гораздо лучше генерирует.
DmitrySpb79 Автор
04.10.2019 10:35Нет проблем сгенерировать связно выглядящий текст даже на MSDOS, имея большую базу примеров и эвристические правила. Здесь суть в другом — программа сама научилась синтаксису языка лишь по входному тексту, я не вводил вручную ни одного правила.

Leeloush_Keer
04.10.2019 10:08DmitrySpb79 Контролом-алт-делитом заклинаю! Запустите обучение на ру.версиии алиэкспресса!
DmitrySpb79 Автор
04.10.2019 12:27Запустите обучение на ру.версиии алиэкспресса
Если кто-то скопирует хотя бы мегабайт текстов оттуда, не вопрос :)

diogen4212
04.10.2019 10:08Представил нейросеть, генерирующую новые серии сериала на основе фанфиков (или сценариев, которые так и не экранизировали). Сперва она обучается на всех сериях сериала (или похожих сериалов), потом оптимизируется под переданный текст, и выдаёт новые серии по тексту с дополнительными сценами, сюжетными поворотами и т.д., потом выдаёт следующую серию на основе предыдущей, потом оптимизируется под новый текст и комментарии зрителей (но в пределах допустимых значений), и так получается практически бесконечная история с любимыми героями… С генерацией видео в принципе достижимо, а вот с пониманием текста пока сложности….
DmitrySpb79 Автор
04.10.2019 11:51Да, сюжет нейросетью уже пытались делать: habr.com/ru/company/pochtoy/blog/413867
С сериалами даже проще, по идее.

3aiats
04.10.2019 10:08А если обучить пхп — можно получать рабочий код. Может даже качеством выше среднего.
kuzevan
04.10.2019 12:07Делал что-то подобное лет 30 назад, без всяких нейросетей.
На примере трех символов в основании: брал большой текст, случайным образом выбирал из него символ, этот и 2 следующих за ним — начало сгенерированного текста.
Затем, передвигал указатель в случайное место первоначального текста и от него, вперед, искал такую же триаду символов. Добавлял в сгенерированный текст символ, следующий в начальном тексте за триадой, получал 4 символа. Новая триада — последние три символа сгенерированного текста.
Опять перескакивал в случайное место текста и искал эту триаду, добавлял еще символ и т.д.
Пробовал с различным количеством символов в основании.
Интересно было наблюдать за эволюцией сгенерированного текста, при малом основании это был набор букв, потом появлялись псевдослова, потом настоящие слова в причудливых сочетаниях и в конце просто цитаты из текста.
bogdanov1ch
04.10.2019 14:25Лучший генератор стихов на русском языке, который я видел, вот тут: github.com/IlyaGusev/rupo
Alexey2005
04.10.2019 14:37-1Похоже, генерация текстов — это та область, где нейросетям на данный момент ловить нечего. Что довольно странно, ведь изображения они генерируют весьма неплохо, даже анимированные.
Отсюда кстати можно сделать вывод, что писательство намного сложнее рисования и требует намного больших интеллектуальных усилий.DmitrySpb79 Автор
04.10.2019 14:43+2Имхо как раз ничего странного. Картины воспринимаются больше подсознательным уровнем, тут всякие чередования красок/цветов «в тему». А поскольку думать нейронные сети (пока что) не умеют, текст получается грамматически правильный но бесмысленный, что сразу же бросается в глаза при его чтении.
fedor_x0a0d
05.10.2019 11:26Когда дело касается текста, то везде примеры, как сети что-то генерируют.
Но почему-то нет примеров, как с помощью сетей текст каталогизируют.
Т.е., к примеру, даю на вход текст, сеть выдает результат — этот текст относится к художественной литературе, жанр космическая фантастика.
Может кто подскажет, где есть такие примеры реализации?

FocusReactive
06.10.2019 14:57Не ясно чем автор так восхищён в результате. Практического смысла это имеет очень не много хоть конструкции и похожи на работающие, но таким образом создать что-то осмысленное не выйдет. Или ошибаюсь?
IPW
06.10.2019 18:25Вот ей-Богу, я про это уже раньше читала! Станислав Лем, «Кибериада», «Путешествие первое А, или Электрувер Трурля». Ай да Лем, ай да провидец! jewish-library.ru/lem/kiberiada-sem_puteshestviy_trurlya_i_klapautsiya_2_puteshestvie_pervoe_a_ili_elektruver_trurlya

Sadler
07.10.2019 09:10А вот такое может выдать GPT-2 от OpenAI. Генерировал 3 куска отдельно, в первом случае unconditional, в остальных скармливал предыдущий текст, последний кусок генерил раз 10, пока концовка не стала более или менее читаемой, чем дальше, тем больше оно теряет исходную мысль. Во втором куске сеть явно переусердствовала с «my love» :)
Заголовок спойлераI am alive. The world is alive. It has survived the coming of the dragon."
I have taken a few more bites and have heard a distant echo, which I guess is my sister's voice.
The last thing I heard is a single word, «And.»
«And? Oh! Oh, that's good. Good. And!»
I know what this is all about. And then I realize that I'm still holding a spoon in my mouth and that I haven't taken another lick from it, because I could barely think for myself. My heart has stopped beating. I need to be in bed.
A little while has passed when the door opens and I see my sister standing there, holding her hands out to me. I try to put my spoon on the ground to prevent her from falling, but suddenly she doesn't need any shoes. She just jumps in and starts crying. I'm in such a panic.
«Oh, my lord, no, don't cry!» Her tone of voice makes me feel so bad for not keeping my tongue in. «It's all right, my love. I will make you feel at home.»
Her hands are warm and she doesn't even have to ask me. It has been a while since she has seen a human boy. And there's only one human boy here, and I'm her brother. I have taken so many trips through life to see what other worlds might have. I'm not the most comfortable being next to her, but I can't help being very concerned.
«Please, my love, just let it out a little. You have a very big heart, and I will stay here so that you can be with Daddy.»
She reaches into her chest and takes my baby bottle and pours a little into my mouth. I'm so glad she did. It makes my heart skip a beat. I want more.
I don't need to ask her as I feel her trembling, tears filling her eyes. «No, my love. I can't.» Her body is shaking too and I can see the tears running down her eyes. «You see me here, right? I'll always be here. You've always been here.»
I try to look at her in the eye and tell her I'm sorry, but I don't mean anything.
«I'm sorry, my love. But I can't do this anymore. It's too dangerous, even in dreamland. When I wake up, I can't come. I can't. You don't look like you're ready.»
Her fingers curl into a tight fist and shake.
«I know how much you love me and I can't do anything if I can't see you, even in dreamland.» I reach back and rest a hand on her shoulder. «Let go.»
I can't bring myself to say it. I know she loves me, I know that she will stay by my side no matter what, I just can't make it any worse. «You're scared, right, dear?»
She shakes her head. «No, my love. I know I can't let you go now, but I can't let you suffer anymore.» Her eyes are full of tears again, but that's not a surprise. It is so hard to see a person weeping, to think of the pain they have caused.
I try to tell her what is happening, but it's still hard for me to understand. I only know how to describe the horror of losing someone you love, how hard it is to get up and walk away for so much time without even knowing.
«Please. I can't. We need to talk.» I don't want her to leave. I can't let her run away. I have to bring her back to me.
She stops crying and looks up at me. Her eyes are very red now, but her lips are smiling. She smiles and I think that I can see the truth in her face. «I don't want to. For the last time, don't stay away forever.»
I don't like it when people get mad at me. In dreams, when I look at them they appear as if in a dream. But I don't want to go back there, not with the way they have treated me in the past. I'm so very sorry for not letting her in. And I'll go back, I promise. I will be better, I promise. I will try to keep her safe until I am back in my body.
It was easy to come to that conclusion the first time I saw her crying. I didn't have to try very hard to believe it. I knew that she was upset and I wanted to help her. But how can I leave her here, where she's in danger, if I cannot let her go?
But I won't have to try very hard. And now that I have been told she will be okay, I know that she will be back home soon.
I wake up again.


Gorthauer87
Вот бы кто сделал аналог internet exploder.
Он и без нейросетей превращал тесты в очень смешной бред, что мы всем форумом ухахатывались.