
Одна из больших проблем в Яндекс.Вертикалях были логи — 18 ТБ в день и 250 000 логов в секунду, все пишется в файлы. Логи разнородные, потому что много языков: Scala, Java, Python, Go. Потом их собирает Fluent Bit, пишет в Kafka, на одной железной машине работают обработчики, собирают из Kafka и пишут всё на диск. При этом это уже вторая версия логов.

Как следствие, возникает проблема долгого поиска. По этим логам поиск идет с помощью grep. На некоторых сервисах grep может достигать часов. Если у вас есть проблемы в продакшн, вы не будете часами искать свои логи. Чтобы решить проблему, в Яндекс решили написать свой велосипед доставки логов для поиска. Что из этого получилось, расскажет Алексей Данилов (danevge) — разработчик команды инфраструктуры в Яндекс.Вертикалях. Разрабатывает, пишет и поддерживает проекты auto.ru и Яндекс.Недвижимость.
Дисклеймер. Статья рассказывает о современной разработке и подходит для микросервисной архитектуры. Здесь представлены различные продукты — это инструменты, которые используют в Яндекс.Вертикалях. Под другие условия возможны аналоги удачнее, но они выполняют практически те же функции.
Примечание. Статья — расширенная версия доклада Алексея Данилова «Логи не нужны» на РИТ++ 2019 DevOps Conf, которая стилистически изменена и дополнена новым материалом. Видеозапись выступления Алексея вы можете найти по ссылке на нашем YouTube-канале.
В команде Яндекс.Вертикали 300 человек, примерно 100 из них — разработчики. В разработке мы ничем не отличаемся от большинства компаний, которые создают собственные продуктовые решения. Микросервисы, все живет в Docker, в темном углу пылится монолит на PHP, деплоим посредством Hashicorp Nomad и держим зоопарк языков: Scala, Java, Go, Node.js, Python.
Одна из больших проблем инфраструктуры в Яндекс.Вертикалях — логи приложений. Когда мы серьезно подошли к этой проблеме, то использовали уже третью версию их сбора и обработки. Упрощенно это работало так:
- приложения писали в файлы;
- Fluent Bit читал файлы и построчно отправлял в Kafka filebeat;
- на выделенной железной машине стояло приложение, которое читало топик Kafka и писало в файлы на диск.
В горячее время у нас было 18 ТБ логов в день или 250 000 строк в секунду. Это очень большой объем, который усложняет работу с этими данными. Единственный способ анализа — это grep, так как все хранится в файлах. Для больших приложений анализ мог длиться часами. При проблемах в продакшн у вас нет этого времени.
Готовые решения не подходили по цене, ресурсам или скорости. Они не могли приемлемо обработать наш поток. Сложно даже подсчитать количество попыток приготовить Elasticsearch. Предполагаю, что мы не умеем его готовить. Но это и не то, что нам нужно, если для его использования, как хранилища логов, требуются особые способности (скилы).
В такой ситуации мы решили реализовать собственную систему сбора и анализа логов.
Велосипед

Примечание: Если очередной велосипед не интересен, то переходите сразу к разделу «Типизация».
Формат
Мы используем несколько ЯП и любим микросервисы. Чтобы работать с логами однообразно сформировали собственный JSON-формат. Он закрывает большинство потребностей в дальнейшей работе с логами.
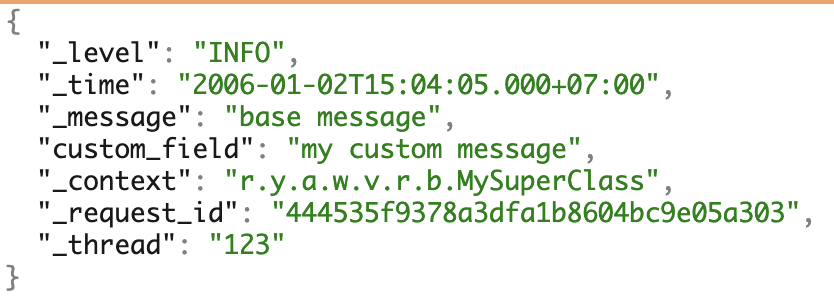
Пример логов со всеми возможными полями.
Docker log driver
Для сбора логов мы написали собственный docker log driver — приложение на Go. Оно собирается специальным образом, доставляется командами docker plugin, хранится в registry и работает в единственном экземпляре под управлением Docker.
Так как любые проблемы с log driver могут негативно повлиять на всю работу, мы старались написать минимальную реализацию. Наш драйвер слушает stdout контейнера и сразу же передает логи в приложение, которое стоит рядом. Уже оно занимается более сложной частью доставки.
Проблемы
Отдельно упомяну проблемы обновления версии docker log driver.

Скриншот с внутренней Grafana.
Слева — отношение установленных версий на машины. Сейчас три версии установлены на всё железо — нигде не потеряны машины и нет лишних установок. Справа — это количество контейнеров, которые используют ту или иную версию.
Docker-драйвер нельзя пойти и сразу обновить. Для этого пришлось бы перезапустить все контейнеры и все сервисы, что могло вылиться в проблемы. Поэтому, чтобы установить новую версию, мы просто ждем, когда все контейнеры обновятся сами.
Общая схема
Рассмотрим общую схему новой системы сбора и доставки логов. Остальные подробности не так интересны.
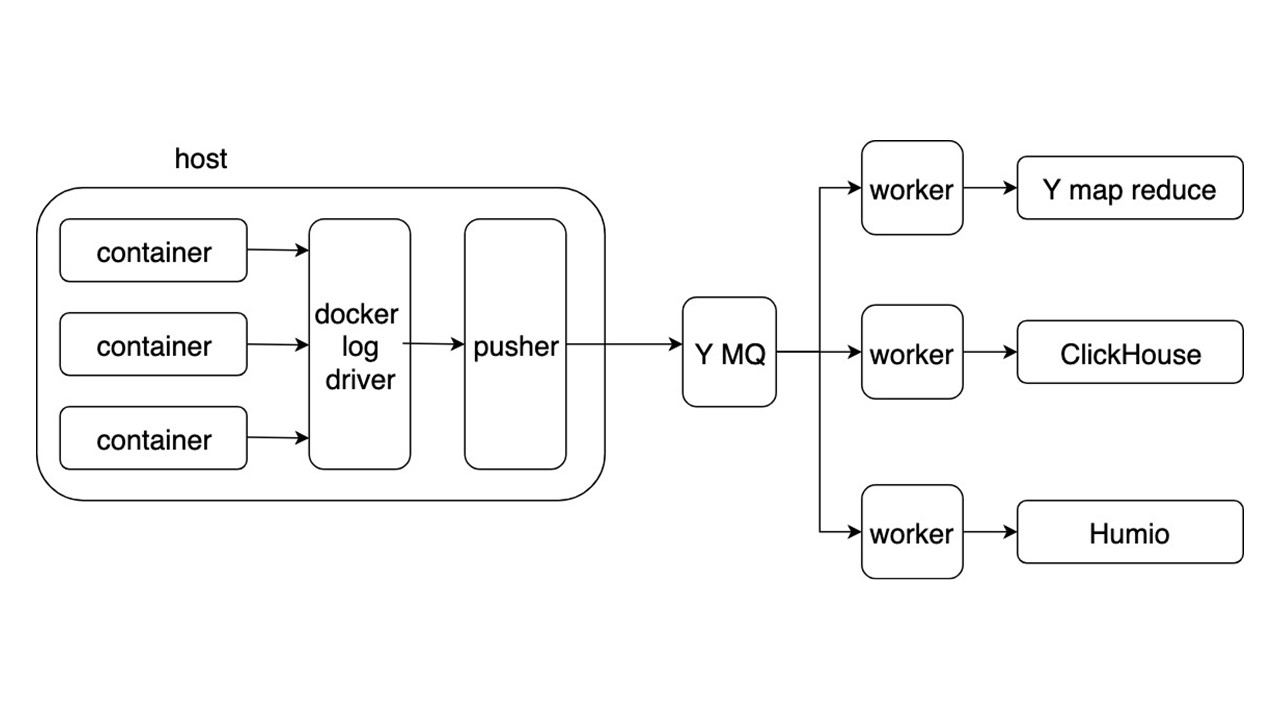
Приложения пишут логи в JSON-формате в stdout. Docker слушает pipe из контейнера и перенаправляет его Docker-драйверу. Docker-драйвер читает и аcинхронно переплавляет все в Pusher.
Pusher стоит на каждой железной машине. Он готовит, насыщает, батчует и пушит логи в яндексовую Message Queue. Поток логов из MQ разбирается тремя типами воркеров и пишется в хранилища.
Хранилищ для записи логов три.
- Яндексовый mapReduce для хранения и анализа логов за длительный период времени. Это аналог Hadoop.
- ClickHouse для хранения логов в течении последних суток.
- Humio (как эксперимент) для хранения логов за последние сутки.
Профит
Общий формат позволяет одинаково писать логи и обрабатывать. Сбор логов автоматический, без использования диска, а доставка — в районе пары секунд. Ключевые поисковые запросы от 2 секунд до 5 секунд. Хранение и поиск за большой период времени.
Для объемов поменьше рассмотрите альтернативные варианты: Humio, Splunk и Elastic. У двух последних есть официальные Docker-драйвера. Если вы вы живете в AWS, то есть Amazon CloudWatch.
Amazon CloudWatch
Amazon CloudWatch обрабатывает метрики, события и логи. Последние он не ищет, не дает суперпоисковых штуко и обрабатывает не в привычном виде. Amazon CloudWatch обрабатывает логи, анализирует, фильтрует и показывает на графиках.
Amazon CloudWatch преобразует логи в метрики и графики.
Что делать с логами?
Вернемся к нашему велосипеду — удовлетворяет ли он все кейсы? Нет, наше решение позволяет найти логи, но от них требуется куда большая разнородность информации и ее типов. Логи используются в гораздо большем количестве кейсов.
Как только вы соберете логи, то следующее предложение будет: «Давайте что-нибудь распарсим, как-нибудь обработаем, где-нибудь запишем и начнем выводить на графиках, на дашбордах». Это путь в ад. Особенно, если мы говорим об общих инструментах.
Если представлять логи как определенный хаос или журнал событий любых данных, то они не будут работать.
Это будет большое месиво информации, которое не получится обработать. Начнется игра в формализование логов: «Давайте мы вот эти строчки будем писать в особом формате, чтобы потом их было удобно парсить!». Так тоже не работает. Поверьте, мы пробовали.
Типизация
Если разбивать логи по типам и обрабатывать их отдельно, то можно найти инструменты, которые позволят легче работать с ними. Работать уже не как с логами, а как с полезными данными — такая работа прозрачнее и удобнее. Некоторые типы логов можно вообще выбросить.
Just in case
Это тип логов «чтобы были» — мой любимый. Если нельзя четко ответить зачем нужна та или иная строка, то это они. Еще этот тип можно назвать «логи на всякий случай».
// validate customer
func Validate(customer Customer) {
// ???
log.debug(“Validate customer %v”, customer)
…
log.Error(“Customer not valid %v. Reason: %s”, ...)
….
}Логи — это не комментарии, которые можно удалить. Это часть кода, который сложнее изменять, поддерживать и тем более удалять.
В лучшем случае такой лог может превратиться в debug или trace. Этот тип захламляет код. Из-за необдуманного логирования в него могу попасть личные данные, пароли и куки пользователей.
Правильный путь — выбросить их и забыть. Но тогда мы сталкиваемся с новой проблемой. Как разобрать ситуацию при ошибке?
Fatal/Critical error
Для начала рассмотрим только критические ошибки. Это ошибки из-за которых страдают пользователи и разработчики. Первые — когда не могут совершить операцию. Вторые — когда нужно вносить исправления руками.
Почему не подходят логи?
Нет быстрой реакции. Если об ошибке команда разработки узнает от пользователей через поддержку или из Twitter, то пора что-то менять.
Нет контекста. Отдельная строка лога с ошибкой бесполезна. Приходится собирать контекст по крупицам. Даже в таком случае его может быть не достаточно, так как это контекст процесса, а не ошибки.
Нет общей картины. Нет ответа на вопросы:
- как часто возникает такая ошибка;
- она произошла на остальных репликах сервиса;
- была ли раньше?
Чтобы исправить эти проблемы, используйте подходящий инструмент, например, sentry.io. Он позволяет работать с репрезентативной, полной (содержащей контекст) информацией об ошибке с настраиваемыми
alerting rule. На сайте sentry описаны различия логов от использования sentry.io.Not critical error
Мы выбросили фатальные и критические ошибки и теперь они пишутся в Sentry. Но остались внутренние ошибки — различные библиотеки или ответы от сторонних сервисов.
Хороший пример — успешный retry. Допустим, сервис А обратился к сервису В, но, из-за проблем с сетью, не смог получить ответ. После ошибки сервис А повторно обратился к сервису В и получил валидный ответ. Ошибка при первом обращении критическая? Нет. В данном случае процесс завершился успешно, а пользователь смог воспользоваться сервисом.
Если для работы сервиса подобные ошибки не критические и они не влияют на пользователя при редком повторении, то это вовсе не ошибки. Это деградация сервиса, хоть ответ пользователю и пришел на 50 мс позднее. Такой тип логов относится к предупреждениям — Warning.
Warning
Предупреждения — это информация о деградации сервиса.
Здесь мы увидим те же проблемы, что присущи критическим ошибкам, но с оговоркой. Реакция на отдельное событие не важна — важно их количество во времени.
Рассмотрим пример, когда сервис не может достать запись из кэша и обращается к холодному хранилищу. Если это происходит раз в минуту, то это вполне можно принять за нормальную работу сервиса. Редкие выбросы не важны.
Но одновременно с этим нужно иметь инструмент для просмотра общей картины, нужен анализ в реальном времени. Чтобы проследить за изменениями за длительный интервал времени было бы неплохо иметь также ретроспективный анализ. Деградации выше определенного уровня (thresholds) могут негативно сказаться на пользователях — нужна реакция при сильной деградации.
Нужны не логи с пометкой Warning, а метрики деградации.
Популярнейший инструмента для сбора метрик — Prometheus, а для визуализации можно использовать Grafana. Если требуется большой контекст (такой же, как у ошибки), то подойдет тот же Sentry, но с выключенными оповещениями. Однако, в большинстве случаев будет достаточно контекста. Он будет использоваться для графиков — Prometheus labels.
Примеры.
| label |
example 1 |
example 2 |
example 3 |
| context |
db |
internal_service |
cache |
| module |
user_service |
user_service |
user_service |
| reason |
long_query |
retry |
miss_cache |
| other |
get_user |
service_b |
user_permisson |
В условном
user_service произошли три события. Они влияют на работу сервиса: долгий запрос к БД, повторное обращение к API сервиса service_b и не были найдены права пользователя в кэше. Графики и алерты будут настроены так, как это важно разработчикам сервиса, благодаря контексту.Tracing
Это первое с чего бы пришлось начать, если бы мы выбрали путь, где нужно парсить логи. Сама по себе эта информация в логах бесполезна, потому что нужно строить цепочки вызовов, видеть данные внутри запросов, ошибки в цепочках вызовов, времена ответов, количество RPS.
Для трассировки есть отличные инструменты — Jaeger или Zipkin. Советую использовать OpenTracing, который они оба поддерживают.
Собирать трейсинг можно из трех источников.
- Если используете общие балансеры — парсите логи с них и отправляйте в Jaeger.
- Сами сервисы, если они получают адреса через Service Discovery и ходят напрямую. В данном случае трассировка из сервисов отправляется напрямую в Jaeger.
- Умный service mesh. Он умеет сам собирать и отправлять трассировку, например, Istio.
Initial information
Это информация о вызовах API сервиса, запуске Cron, запросах в БД или вызовах других сервисов.
{
"_message": "Request: ...; request_id: ...,... ",
"_level": "INFO",
"_time": "2019-03-08T12:04:05.000+07:00",
"_context": "r.y.a.w.v.c.Handler",
"_tread": "785534"
}Эта информация относится к блоку «Just in case», но стоит отдельно, потому что встречается чаще. Эта информация нужна для разбора ошибки и ее можно выбросить.
Если же информация о вызовах внутренних методов критично важна и без нее нельзя обойтись, даже с собранным контекстом при ошибке, то стоит инструментировать вызовы методов как трассировку.
Execution time
Это информация о времени выполнении методов, API, запросах БД или других сервисов.
{
"_message": "Get customer 12ms",
"_level": "INFO",
"_time": "2019-03-08T12:04:05.000+07:00",
"_context": "r.y.a.w.v.c.CustomerRepository",
"_tread": "785534"
}В логах от нее нет ценности, потому что нужно эту информацию анализировать, отображать на графиках, настраивать thresholds. Этот тип логов нужно заменить на метрики, например, в Prometheus.
Business info
Это информация требуется для бизнес аналитики, анализа поведения клиентов, финансовых расчетов. В этом месте мы исторически использовали обратный подход — парсили логи. Но это хороший пример того, во что могут выродиться логи приложения если с ними работать подобным образом.
Для логов с бизнес-данными были сформированы соглашения с фиксированными полями в формате TSKV, которые необходимы для аналитики. Приложения писали бизнес-логи в выделенный файл. Дальше логи читались и построчно отправлялись в MQ, а отдельное приложение их обрабатывало и записывало в БД. Это пример того во что превращается любой парсинг.
Не получится парсить весь поток логов в надежде, что данные сойдутся.
Появляются конвенции, форматы, правила, требования к надежности. Это уже мало похоже на логи приложения. В данном случае лог становится очередью поставки данных со всеми вытекающими требованиями к MQ. Заметно, что middleware в виде лога здесь лишний.
Хорошее решение — прямая отправка этих данных в MQ. Уже там они будут обработаны, сохранены в соответствующее хранилище и использованы командой аналитики. Например, для отображения мы используем Tableau.
Performance
Это тип логов редко встречается в логах приложений и чаще собирается как метрика. Отдельно добавлю, что для сбора базовых метрик, которые специфичны для языка, достаточно использовать библиотеку Prometheus. Она по умолчанию соберет все до чего дотянется. Цена добавления этих метрик небольшая.

Итог типизации
Разобрав логи по типам мы можем подобрать более мощные инструменты для работы с ними. Здесь нет сложных систем или космических технологий как у Amazon, нет того, что нельзя поднять уже завтра. Вероятно, часть из этих систем или аналоги у вас уже есть: где-то пылится Sentry, где-то работает Prometheus.

Проблема не в технологиях, а в когнитивной ловушке, когда мы доверяем логам как средству надежного представления состояния нашей системы. Это не так, логи — это набор хаотичных событий.
Есть исключение — Debug-логи, которые можно применять в редких случаях.
Debug log
Debug-логи должны представлять из себя развернутую информацию. Они не должны дублировать то, что уже отправляется в системы, которые мы описали выше. Этот тип существует для разбора особых случаев. Например, на продакшн происходит непонятный баг, а в моменте по метриками непонятно, что происходит.
Debug-логи включайте на горячую, без перезапуска сервиса. Так как мы говорим о нескольких сервисах, то их не будет много. Сложная инфраструктура не нужна. Достаточно ELK стека без сложного «приготовления». Также имеет смысл добавить алерт в Sentry со всем необходимым контекстом.
Debug-логи можно использовать для разработки. Но их отлично заменяет debugging.
Подведем итоги
Мы написали свой велосипед доставки логов для поиска. Клиентов сервиса мы не удовлетворили — они все приходят к нам, чтобы эти логи парсить, собирать и где-то агрегировать. Этого можно избежать — сложные системы обработки логов не нужны.
Логи в сыром виде бесполезны, но их можно превратить в полезные метрики.
Достаточно создать инфраструктуру доставки полезных метрик и данных вокруг сервисов. В результате появятся полезные метрики, которые говорят о сервисах, и прозрачно показывают все, что с ними происходит.
Ошибки должны содержать контекст самой ошибки.
Это поможет справиться с ней и сразу исправить. Ошибки и деградация должны побуждать к действию, чтобы разработчики мгновенно узнавали о проблемах и исправляли их еще до гневных обращений пользователей.
Правильные инструменты сделают работу с вашими сервисами приятнее и прозрачнее. Debug имеет место быть, но с ним надо быть строгим.
На HighLoad++ 2019 в ноябре будет секция DevOps — 13 докладов о нагрузках в AWS, системе мониторинга в Lamoda, конвейерах для поставки моделей, жизни без Kubernetes и многом другом. Полный список тем и тезисов смотрите на отдельной странице «Доклады». А на DevOpsConf встретимся весной — подписывайтесь на рассылку, сообщим, когда определим даты и локацию.
Комментарии (36)

fougasse
23.10.2019 17:01Не очень понял про Just in case логирование.
Фразой «выбросить и забыть» автор предлагает вообще не использовать дебажные логи?
Интересно как рещается проблема «отладки» нового функционала или предполагается, что скилл разработчиков настолько высок, что все проблемы решаются без наличия настолько низкоуровневых логов, в принципе?
Раздел про tracing интересен, но я не уверен, что все проблемы можно обработать сторонними сервисами.
Или я что-то упускаю?
dimkss
23.10.2019 17:30-1Мне кажется тут надо-бы сделать разделение. Когда сервис только разрабатывается/создается «Just in case» логирование очень хорошо помогает найти ошибки, а вот когда сервис уже устаканился и работает, оно в принципе уже не очень нужно.
fougasse
23.10.2019 17:35+2А если нужно расширять функицонал сервиса?
Или подход, что новая бизнес-логика после какого-то уровня сложности обязана реализовываться в другом сервисе?
По опыту когда сервис устаканился и работает находят баги, соответственно, нужно дебажить, зачастую, логами. Не правильнее ли грамотно настроить систему логирования, а не ограничиваться только сообщениями об ошибках в коде, ведь и сама логика работы в сервисе может быть довольно сложной даже без учета ошибок и всякого мониторинга?dimkss
24.10.2019 13:07Не правильнее ли грамотно настроить систему логирования…
Эта мысль похожа на фразу «Не правильнее ли сразу написать систему без ошибок», но я с вами согласен. Вот только как найти баланс между размерами логов (гигабайты логов каждый день?) и их будущей полезностью (каждую команду логгировать?) — вопрос довольно сложный.

Sabubu
23.10.2019 17:54У них было 250 000 строк логов в секунду. Что вы собрались там отлаживать? Вы даже десятую часть из этого прочесть не сможете.
Отлаживать надо в dev-окружении, а на продакшене смотреть метрики, как я понимаю.

Veikedo
23.10.2019 17:57+2У нас доходит до 40тб логов за день (и кстати эластик с этим справляется) и при этом отлаживать по логам всё ещё помогает.
fougasse
23.10.2019 18:33+1Я собирался бы отлаживать бизне-логику, как обычно.
Зачастую, достаточно пары(десятков) секунд, чтобы локализовать проблему. Думаю, что даже самый просто греп справится с несколькими миллионами строк.
Конечно, я понимаю, что у крутых пацанов прод и дев ведут себя одинаково, и с боевых серверов только графики на презенташки экспортируют, но категоричность "дебаг логи в мусорник" хотелось бы услышать какой-то аргумент кроме "парсить долго, а проблему надо на проде решать срочно".
Veikedo
23.10.2019 17:37+2Тоже не совсем понял про just in case логи.
Зачастую они и дают понять контекст ошибок.
Что-то мне кажется, что Sentry не особо поможет прислав мне какой-нибудь InvalidOperationException, который возникает при определённых аргументах в методе, а по логам я как раз смогу увидеть/понять что предшествовало ошибке.
Или вы предлагаете заменить just in case логи на трейсинг?

staticmain
23.10.2019 17:54+3В горячее время у нас было 18 ТБ логов в день или 250 000 строк в секунду
18 х 1024 х 1024 х 1024 х 1024 = 19 791 209 299 968 байт в день.
19 791 209 299 968?(60?60?24) = 229 064 922 байт в секунду
229 064 922 ? 250 000 000 = 0,916 байт на строку.
Кажется, что цифры с потолка.firk
23.10.2019 19:45+2Кажется кто-то перепутал 250000 и 250000000.
А ещё пятеро кто поставили плюсы — не удосужились прочесть содержание коммента перед его оценкой.
Впрочем кбайт на строку тоже не совсем обычно выглядит.staticmain
23.10.2019 19:46Каюсь, но тогда получается, что строки по килобайту. Все равно с потолка.
darkit
23.10.2019 20:33Не думаю, что с потолка. Тк например у нас сейчас строка лога в КликХаусе около 0.15Кб, в ЕластикСерча строка уже под 1Кб.

kisuxa
23.10.2019 21:32Не в первый раз вижу, когда log base metrics становятся основой получения данных и не могу понять причину предпочтения этого подхода.
Те же business info (количество запросов от одного юзера на конкретный сервис), application performance (скорость выполнения запроса), errors (количество errors за N время) данные вполне можно получать в виде метрик — выйдет гораздо дешевле, быстрее и более информативно, ввиду бОльшей гибкости за счет дешевизны метрик.
Я не отрицаю пользу логов, но почему не использовать то и другое, вместо затрат на парсинг логов?
Mishiko
23.10.2019 21:43а выделенной железной машине стояло приложение, которое читало топик Kafka и писало в файлы на диск.
…
Сложно даже подсчитать количество попыток приготовить Elasticsearch. Предполагаю, что мы не умеем его готовить. Но это и не то, что нам нужно, если для его использования, как хранилища логов, требуются особые способности (скилы).
— удивительно, мой велосипед, трудоемкостью в одну человеко-неделю, забирал лог сообщения из ActiveMQ (тут похоже на ваше решение) и клал их в Lucene (индексы создавались ежедневно). Как профит — все хранится также в ФС, плюс поиск по логам на основе запросов Lucene (в эластике они же) и отсутствие каких либо настроек. Правда под нагрузкой в 250 000 записей в секунду я его не тестил) В моем случае, наверное уперся бы в скорость записи на диск, а дальше переполнилась бы очередь в ActiveMQ

amarao
24.10.2019 08:05Во всей презентации нет ответа на очевидный вопрос: а эластик и логстэш? Не то, чтобы я большой фанат явы, но впечатляющие 18Гб логов в сутки это куда менее пугающие 200kb в секунду, которые прекрасно перевариваются даже однонодовой конфигурацией ELK.

Elufimov
24.10.2019 09:0818гб логов в сутки это капля в море для эластика. Мы храним террабайты логов и некоторые дневные индексы легко переваливают за сотни гб.

flancer
24.10.2019 08:40Логи позволяют понимать, как работает код, который ты (кто-то) написал. Если ты и так понимаешь, как работает твой (чей-то) код, то логи не нужны. Но чаще присутствует иллюзия понимания, чем само понимание.
18 ТБ логов в день...
Это с каким уровнем логирования? Как по мне, так на prod'е trace/debug (обычно) не нужны, а если "250К строк в секунду" это уровня warn/err, то — ой!
Вполне допускаю, что trace/debug могут использоваться для сбора каких-то метрик, но, как правильно отметил автор публикации, профилирование != логирование.

blind_oracle
24.10.2019 09:39+1Клиентские запросы логгировать например, по которым потенциально потом некие расследования вести.
flancer
24.10.2019 10:00Резонно. Возможно, есть смысл уровень "info" выделять в отдельный канал, либо сохранение запросов-ответов вынести в отдельную бизнес-функцию. В общем, это тема "на подумать".

TerraV
24.10.2019 12:14+1Это не должно быть в логах, это должно быть в базе. А в общем случае, подобная информация в логах — это дыра в безопасности. Сколько уже было историй когда логи использовались для взлома (чисто за счет того что к логам более безалаберное отношение)
blind_oracle
24.10.2019 12:51Смотря какая информация туда пишется.
Я в свое время писал миллиарды RADIUS-запросов в логи, по которым потом дебажил если что-то не так. Никакой ценной информации там не было.
Потом начал писать их же в InfluxDB в более структурированном виде — стало быстрее и удобнее.
inf
24.10.2019 08:49Тоже давно кажется что логи не нужны. Экономический эффект уходит в минуса с растущими объёмами и сложностью обработки. Самое время пилить ИИ для анализа логов))
Veikedo
24.10.2019 10:54У эластика есть ИИ для анализа логов.
Вообще было бы интересно почитать историии про его использование
dididididi
24.10.2019 14:40а зачем там ИИ если они сдантартизированы?

strang3r
24.10.2019 17:19Ну прям ИИ это громко сказано. У кибаны есть ml для поиска аномалий в логах: www.elastic.co/videos/automated-anomaly-detection-with-elasticsearch-using-machine-learning
dididididi
24.10.2019 14:48Принципиально неверное решение задачи)))
Перед тем как писать этот мерзкий велосипед(а любой велосипед мерзкий), нужно посмотреть, как часто и зачем логами пользуются. И на основе этого, что-то писать или не писать ничего вообще. А так вы сделали какие-то свои предположения.
Перед тем как говорить, что я там пишу какую то метрику, надо узнать, а как эта метрика будет использоваться и какие решения можно на основе ее принять.
Karl_Marx
24.10.2019 15:16+1TL;DR: Мы в Яндексе создали подразделение, которое слепило из логов других подразделений огромный комок грязи, из-за чего пришлось изобретать велосипеды для его обработки, а другие команды теперь ходят на поклон за тридевять земель, чтобы получить информацию из собственных логов и пофиксить баг.
Paskin
24.10.2019 15:40Очень полезно иметь уникальный ID для каждого вызова логгера — сильно упрощает фильтрацию, маршрутизацию и поиск в логах. На прошлом месте работы написали пре-коммит скрипт, заменявший NEXT_LOG_ID (определенный по дефолту как -1, чтобы компилировалось) на следующий свободный идентификатор. Он же (скрипт) проверял количество вызовов логгера в модуле — чтобы не копипастили ID из других мест в коде (проверка не 100% но зато довольно быстрая).

vintage
24.10.2019 19:39Чтобы работать с логами однообразно сформировали собственный JSON-формат. Он закрывает большинство потребностей в дальнейшей работе с логами.
Не хотите глянуть на формат tree? Тут я о нём рассказывал: https://youtu.be/vBqJWQzPB3Y?t=5652
Если вкратце сравнить с JSON:
- Не тратится время на экранирование и разэкранирование строк.
- Компактный как минифицированный JSON.
- Наглядный как YAML.
- Крайне простой, что позволяет быструю его обработку.
Ваш пример лога мог бы выглядеть так:
info time \2006-01-02T15:04:05.000+07:00 message \base message + custom_field \my custom \multiline message context \r.y.a.w.r.b.MySuperClass request_id \7328467235678463578634578678456783647 thread \123
maxim_ge
Хороший анализ ситуации. Не очень понятно, что такое «Business info» и почему «оно» было в логах. Поясните, пожалуйста…