
Сегодня мы хотим поговорить о концепции Insight-Driven и о том, как ее реализовать на практике c помощью DataOps и ModelOps. Insight-Driven подход — это комплексная тема, про которую мы подробно рассказываем в нашей недавно созданной библиотеке полезных материалов про управление данными (ссылка будет ниже). В сегодняшнем хабратопике мы сконцентрируемся на ключевых этапах жизненного цикла моделей машинного обучения, т.к. это одна из основных тем в рамках концепции.

Многие специалисты достаточно давно говорят про важность Data-Driven, что в целом, конечно, абсолютно правильно, ведь этот поход предполагает принятие повышение эффективности управленческих решений за счет анализа данных, а не только интуиции и личного опыта руководства. Аналитики Forrester отмечают, что компании, опирающиеся в своей деятельности на анализ данных, растут в среднем на 30% быстрее конкурентов.
Но все мы понимаем, что компания двигается вперед не от наличия данных как такового, а от умения работать с ними — то есть находить инсайты, которые можно монетизировать, и ради которых стоит накапливать, обрабатывать и анализировать данные. Поэтому мы говорим именно об Insight-Driven подходе, как о более продвинутой версии Data-Driven.
Чаще всего, когда речь идет о работе с данными, большинство специалистов подразумевают в первую очередь структурированную информацию внутри компании, однако, не так давно мы рассказывали о том, почему около 80% потенциально доступных данных бизнес в подавляющем большинстве вообще не использует. Insight-Driven как раз создает основу для того, чтобы дополнить картину внешней неструктурированной информацией, а также результатами интерпретации данных для поиска неявных зависимостей между ними.
Обещанная ссылка на полную библиотеку материалов про управление данными, где есть и упомянутый ролик про неиспользуемые данные.
В основе Insight-Driven лежат практики DevOps, DataOps и ModelOps. Поговорим о том, почему сочетание именно этих практик способно обеспечить полноценную реализацию подхода.
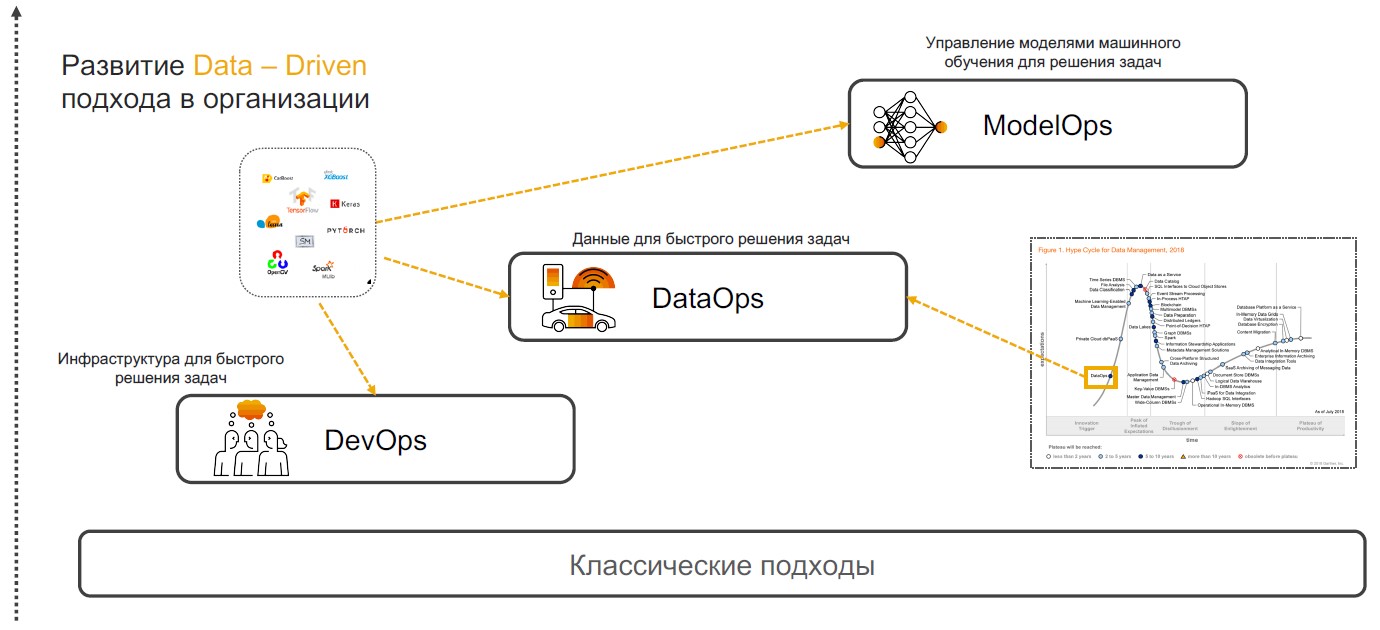
DevOps+DataOps. DevOps предполагает сокращение времени выхода продукта, его обновлений и минимизацию затрат на дальнейшую поддержку за счет использования инструментов для контроля версии, непрерывной интеграции, тестирования и мониторинга, управления релизами. Если к этим практиками добавить понимание того, какие данные есть внутри компании, как управлять их форматом и структурой, тэгировать, отслеживать качество, трансформацию, агрегацию и иметь возможность быстрого анализа и визуализации, то мы получаем DataOps. Фокус этого подхода — реализация сценариев с помощью моделей машинного обучения, которые обеспечивают поддержку принятия решений, поиск инсайтов и прогнозирование.
ModelOps. Как только компания начинает активно использовать модели машинного обучения — появляется необходимость ими управлять, отслеживать метрики качества, переобучать, сравнивать, обновлять и версионировать. ModOps — это набор практик и подходов, упрощающих управление жизненным циклом таких моделей. Его используют компании, которые имеют дело с большим количеством моделей в различных областях бизнеса, например стриминговые сервисы.
Внедрение Insight-Driven подхода в компании — нетривиальная задача. Но для тех, кто все-таки хотел бы начать работу с ним, мы расскажем, как это можно сделать.
Внедрение Insight-Driven практик начинают с поиска и подготовки данных. Позже их анализируют и используют для построения моделей МО, но предварительно определяют кейсы, в которых интеллектуальные алгоритмы могут быть полезны.
Определение задач. На этом этапе компания устанавливает бизнес-цели, например, рост прибыли на рынке. Далее определяют бизнес-метрики для их достижения вроде роста количества новых клиентов, размера среднего чека и процента конверсии. Так появляются сценарии, в рамках которых уже можно искать релевантные данные.
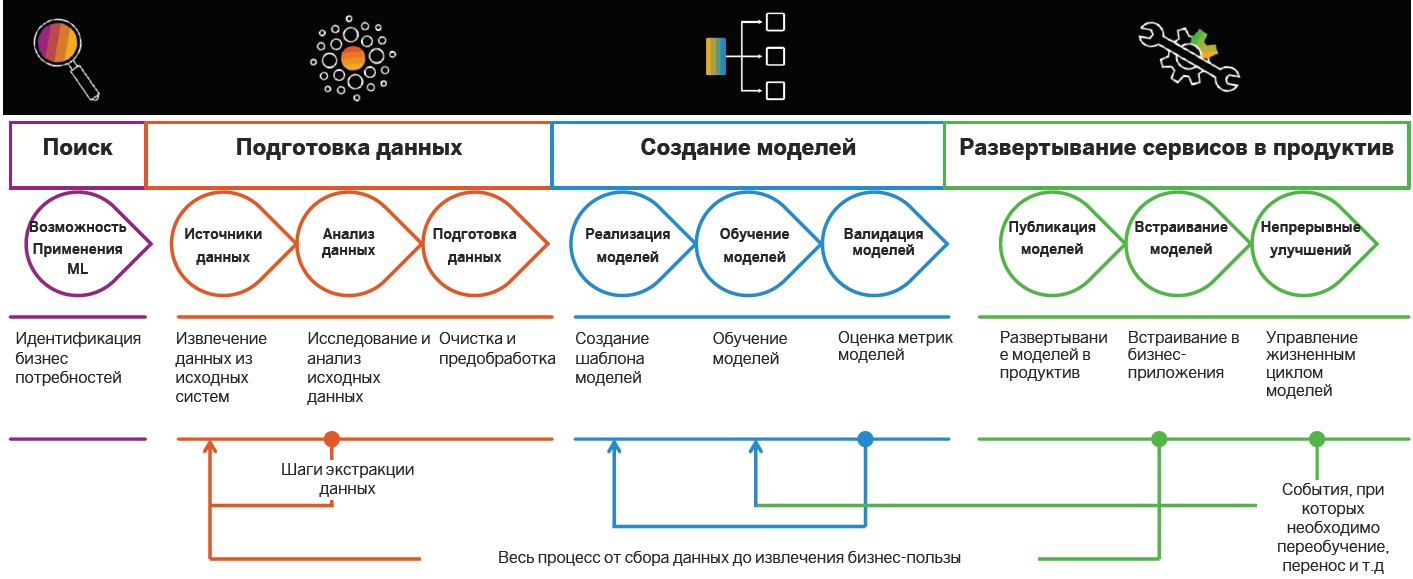
Поиск источников и анализ данных. Когда цели и направления для поиска данных определены, наступает время анализа источников. На этот и последующий этапы разработки интеллектуальных сценариев, которые касаются подготовки уходит 70–80% бюджетов компаний при реализации. Дело в том, что качество дата-сета влияет на точность проектируемых моделей машинного обучения. Но необходимая информация часто бывает «разбросана» по различным системам — может лежать в реляционных базах данных, таких как MS SQL, Oracle, PostgreSQL, на платформе Hadoop и многих других источниках. И на этом этапе необходимо понять, где есть релевантные данные и как их собрать.
Часто аналитики выгружают и обрабатывают все вручную, что сильно замедляет процессы и повышает риск возникновения ошибок. Мы в SAP предлагаем своим клиентам внедрять мета-систему, которая подключается к нужным источникам и собирает данные по запросу.
Так, можно каталогизировать все таблицы, внешние пулы с неструктурированными данными и другие источники — установить теги (в том числе иерархические) и оперативно набирать релевантную информацию. Условно, если информация по клиенту лежит в разных БД, то достаточно обозначить эти сущности. В следующий раз, когда понадобится «клиентский дата-сет», вы выберете уже готовую витрину.
Когда источники данных определены, можно переходить к отслеживанию качества данных и профилированию. Эта операция необходима для понимания количества пропусков, уникальных значений и проверки общего качества данных. Для всего этого можно строить дашборды с правилами и отслеживать любые изменения.
Трансформация данных. Следующий шаг — непосредственная работа с данными, которые должны решить поставленные задачи. Для этого данные очищают: проверяют, дедуплицируют, заполняют пробелы. Упростить этот процесс можно с помощью flow-based programming. В этом случае мы имеем дело с последовательностью операций — пайплайном. Его выход можно направить в графический интерфейс или другую систему для последующей работы. Здесь обработчики данных собирают как конструктор (и в зависимости от сценария). Это может быть периодическая или стриминговая обработка, либо REST-сервис.

Концепция flow-based programming подходит для решения широкого спектра задач: от прогноза продаж и оценки качества обслуживания до поиска причин оттока клиентов. Для поиска и подготовки данных в SAP есть два инструмента. Первый — SAP Data Intelligence для специалистов по анализу данных. В отличие от аналогичных платформ это решение работает с распределенными данными и не требует их централизации — дает единую среду для реализации, публикации, интеграции, масштабирования и поддержки моделей. Второе инструмент — SAP Agile Data Preparation — небольшой сервис для подготовки данных, ориентированный на аналитиков и бизнес-пользователей. У него простой интерфейс, который помогает собрать дата-сет, отфильтровать, обработать и сопоставить информацию. Её можно опубликовать в витрину для передачи Self-Service BI — системам самообслуживания для создания аналитических сценариев (они не требуют глубоких знаний в области data science).
После подготовки наступает очередь создания моделей машинного обучения. Здесь выделяют: исследование, прототипирование и продуктивизацию. Последний этап включает в себя реализацию пайплайнов для обучения и применения моделей.
Исследование и прототипирование. На текущий момент доступно множество тематических фреймворков и библиотек. Лидируют по частоте использования TensorFlow и PyTorch, популярность которого за прошедший год выросла на 243%. Платформа SAP позволяет задействовать любой из таких фреймворков и может гибко дополняться библиотеками, такими как CatBoost от «Яндекса», LightGBM от Microsoft, scikit-learn и pandas. Еще можно использовать HANA DataFrame в библиотеке hanaml. Этот API мимикрирует под pandas, а HANA позволяет обрабатывать большие объемы данных с помощью «ленивых вычислений».
Для прототипирования моделей мы предлагаем Jupyter Lab. Это — инструмент с открытым исходным кодом для data-science специалистов. Мы встроили его в экосистему SAP, параллельно расширив функциональность. Jupyter Lab работает в платформе Data Intelligence и за счет встроенной библиотеки sapdi может подключаться к любым источникам данных, подключенных на предыдущих шагах, мониторить эксперименты и метрики качества для их дальнейшего анализа.
Отдельно стоит отметить, что блокноты, датасеты, пайплайны обучения и инференса, а также сервисы для деплоя моделей должны быть консистентны. Для объединения всех этих объектов используют ML-сценарий (версионируемый объект).
Обучение моделей. Существует два варианта работы с ML-сценариями. Есть модели, которые вообще не нужно обучать. Например, в SAP Data Intelligence мы предлагаем системы распознавания лиц, автоматического перевода, OCR (optical character recognition) и другие. Все они работают «из коробки». С другой стороны — есть те модели, которые необходимо обучать и продуктивизировать. Это обучение может происходить как в самом кластере Data Intelligence, так и на внешних вычислительных ресурсах, которые подключаются только на время вычислений.
«Под капотом» в SAP Data Intelligence — платформа Kubernetes, поэтому все операторы привязаны к docker-контейнерам. Для работы с моделью достаточно описать docker-файл и привязать к нему тэги для используемых библиотек и версий.
Другой способ создания моделей — с помощью AutoML. Это автоматизированные системы МО. Такие инструменты разрабатывают H2O, Microsoft, Google и др. В этом направлении работают и в MIT. Но инженеры университета не фокусируются на встраивании и продуктивизации. В SAP также есть AutoML-система, которая делает упор на быстрый результат. Она работает в HANA и имеет прямой доступ к данным — их не нужно куда-то перемещать и модифицировать. Сейчас мы разрабатываем решение, которое фокусируется на качестве моделей — о релизе объявим позже.
Управление жизненным циклом. Условия меняются, информация устаревает, поэтому точность моделей МО со временем снижается. Соответственно, накопив новые данные, можно переобучить модель и уточнить результаты. Например, один крупный производитель напитков использует информацию о предпочтениях потребителей в 200 разных странах для переобучения интеллектуальных систем. Компания учитывает вкусы людей, количество сахара, калорийность напитков и даже продукцию, которую предлагают конкурирующие бренды на целевых рынках. Модели МО автоматически определяют, какой из сотен продуктов компании лучше всего примут в том или ином регионе.

Переиспользование компонентов на базе операторов в SAP Data Hub
Но версионировать и обновлять модели нужно еще и по мере выхода свежих алгоритмов и обновлений аппаратных компонентов. Их внедрение может повысить точность и качество используемых в работе моделей.
Описанный выше подход к управлению этапами жизненного цикла моделей машинного обучения — это, по сути, универсальный фреймворк, позволяющий компании стать Insight-Driven и использовать работу с данными в качестве ключевого драйвера для роста бизнеса. Организации, воплощающие эту концепцию, знают больше, растут быстрее, ну и, на наш взгляд, работают гораздо интереснее на этом переднем крае технологий!
Узнайте больше о построении концепции Insight-Driven в нашей библиотеке полезных материалов по управлению данными, куда мы собрали видео, полезные брошюры и триал-доступы к системам SAP.
В чем суть Insight-Driven подхода
Многие специалисты достаточно давно говорят про важность Data-Driven, что в целом, конечно, абсолютно правильно, ведь этот поход предполагает принятие повышение эффективности управленческих решений за счет анализа данных, а не только интуиции и личного опыта руководства. Аналитики Forrester отмечают, что компании, опирающиеся в своей деятельности на анализ данных, растут в среднем на 30% быстрее конкурентов.
Но все мы понимаем, что компания двигается вперед не от наличия данных как такового, а от умения работать с ними — то есть находить инсайты, которые можно монетизировать, и ради которых стоит накапливать, обрабатывать и анализировать данные. Поэтому мы говорим именно об Insight-Driven подходе, как о более продвинутой версии Data-Driven.
Чаще всего, когда речь идет о работе с данными, большинство специалистов подразумевают в первую очередь структурированную информацию внутри компании, однако, не так давно мы рассказывали о том, почему около 80% потенциально доступных данных бизнес в подавляющем большинстве вообще не использует. Insight-Driven как раз создает основу для того, чтобы дополнить картину внешней неструктурированной информацией, а также результатами интерпретации данных для поиска неявных зависимостей между ними.
Обещанная ссылка на полную библиотеку материалов про управление данными, где есть и упомянутый ролик про неиспользуемые данные.
DevOps + DataOps + ModelOps
В основе Insight-Driven лежат практики DevOps, DataOps и ModelOps. Поговорим о том, почему сочетание именно этих практик способно обеспечить полноценную реализацию подхода.
DevOps+DataOps. DevOps предполагает сокращение времени выхода продукта, его обновлений и минимизацию затрат на дальнейшую поддержку за счет использования инструментов для контроля версии, непрерывной интеграции, тестирования и мониторинга, управления релизами. Если к этим практиками добавить понимание того, какие данные есть внутри компании, как управлять их форматом и структурой, тэгировать, отслеживать качество, трансформацию, агрегацию и иметь возможность быстрого анализа и визуализации, то мы получаем DataOps. Фокус этого подхода — реализация сценариев с помощью моделей машинного обучения, которые обеспечивают поддержку принятия решений, поиск инсайтов и прогнозирование.
ModelOps. Как только компания начинает активно использовать модели машинного обучения — появляется необходимость ими управлять, отслеживать метрики качества, переобучать, сравнивать, обновлять и версионировать. ModOps — это набор практик и подходов, упрощающих управление жизненным циклом таких моделей. Его используют компании, которые имеют дело с большим количеством моделей в различных областях бизнеса, например стриминговые сервисы.
Внедрение Insight-Driven подхода в компании — нетривиальная задача. Но для тех, кто все-таки хотел бы начать работу с ним, мы расскажем, как это можно сделать.
Поиск и подготовка данных
Внедрение Insight-Driven практик начинают с поиска и подготовки данных. Позже их анализируют и используют для построения моделей МО, но предварительно определяют кейсы, в которых интеллектуальные алгоритмы могут быть полезны.
Определение задач. На этом этапе компания устанавливает бизнес-цели, например, рост прибыли на рынке. Далее определяют бизнес-метрики для их достижения вроде роста количества новых клиентов, размера среднего чека и процента конверсии. Так появляются сценарии, в рамках которых уже можно искать релевантные данные.
Поиск источников и анализ данных. Когда цели и направления для поиска данных определены, наступает время анализа источников. На этот и последующий этапы разработки интеллектуальных сценариев, которые касаются подготовки уходит 70–80% бюджетов компаний при реализации. Дело в том, что качество дата-сета влияет на точность проектируемых моделей машинного обучения. Но необходимая информация часто бывает «разбросана» по различным системам — может лежать в реляционных базах данных, таких как MS SQL, Oracle, PostgreSQL, на платформе Hadoop и многих других источниках. И на этом этапе необходимо понять, где есть релевантные данные и как их собрать.
Часто аналитики выгружают и обрабатывают все вручную, что сильно замедляет процессы и повышает риск возникновения ошибок. Мы в SAP предлагаем своим клиентам внедрять мета-систему, которая подключается к нужным источникам и собирает данные по запросу.
Так, можно каталогизировать все таблицы, внешние пулы с неструктурированными данными и другие источники — установить теги (в том числе иерархические) и оперативно набирать релевантную информацию. Условно, если информация по клиенту лежит в разных БД, то достаточно обозначить эти сущности. В следующий раз, когда понадобится «клиентский дата-сет», вы выберете уже готовую витрину.
Когда источники данных определены, можно переходить к отслеживанию качества данных и профилированию. Эта операция необходима для понимания количества пропусков, уникальных значений и проверки общего качества данных. Для всего этого можно строить дашборды с правилами и отслеживать любые изменения.
Трансформация данных. Следующий шаг — непосредственная работа с данными, которые должны решить поставленные задачи. Для этого данные очищают: проверяют, дедуплицируют, заполняют пробелы. Упростить этот процесс можно с помощью flow-based programming. В этом случае мы имеем дело с последовательностью операций — пайплайном. Его выход можно направить в графический интерфейс или другую систему для последующей работы. Здесь обработчики данных собирают как конструктор (и в зависимости от сценария). Это может быть периодическая или стриминговая обработка, либо REST-сервис.
Концепция flow-based programming подходит для решения широкого спектра задач: от прогноза продаж и оценки качества обслуживания до поиска причин оттока клиентов. Для поиска и подготовки данных в SAP есть два инструмента. Первый — SAP Data Intelligence для специалистов по анализу данных. В отличие от аналогичных платформ это решение работает с распределенными данными и не требует их централизации — дает единую среду для реализации, публикации, интеграции, масштабирования и поддержки моделей. Второе инструмент — SAP Agile Data Preparation — небольшой сервис для подготовки данных, ориентированный на аналитиков и бизнес-пользователей. У него простой интерфейс, который помогает собрать дата-сет, отфильтровать, обработать и сопоставить информацию. Её можно опубликовать в витрину для передачи Self-Service BI — системам самообслуживания для создания аналитических сценариев (они не требуют глубоких знаний в области data science).
Создание моделей
После подготовки наступает очередь создания моделей машинного обучения. Здесь выделяют: исследование, прототипирование и продуктивизацию. Последний этап включает в себя реализацию пайплайнов для обучения и применения моделей.
Исследование и прототипирование. На текущий момент доступно множество тематических фреймворков и библиотек. Лидируют по частоте использования TensorFlow и PyTorch, популярность которого за прошедший год выросла на 243%. Платформа SAP позволяет задействовать любой из таких фреймворков и может гибко дополняться библиотеками, такими как CatBoost от «Яндекса», LightGBM от Microsoft, scikit-learn и pandas. Еще можно использовать HANA DataFrame в библиотеке hanaml. Этот API мимикрирует под pandas, а HANA позволяет обрабатывать большие объемы данных с помощью «ленивых вычислений».
Для прототипирования моделей мы предлагаем Jupyter Lab. Это — инструмент с открытым исходным кодом для data-science специалистов. Мы встроили его в экосистему SAP, параллельно расширив функциональность. Jupyter Lab работает в платформе Data Intelligence и за счет встроенной библиотеки sapdi может подключаться к любым источникам данных, подключенных на предыдущих шагах, мониторить эксперименты и метрики качества для их дальнейшего анализа.
Отдельно стоит отметить, что блокноты, датасеты, пайплайны обучения и инференса, а также сервисы для деплоя моделей должны быть консистентны. Для объединения всех этих объектов используют ML-сценарий (версионируемый объект).
Обучение моделей. Существует два варианта работы с ML-сценариями. Есть модели, которые вообще не нужно обучать. Например, в SAP Data Intelligence мы предлагаем системы распознавания лиц, автоматического перевода, OCR (optical character recognition) и другие. Все они работают «из коробки». С другой стороны — есть те модели, которые необходимо обучать и продуктивизировать. Это обучение может происходить как в самом кластере Data Intelligence, так и на внешних вычислительных ресурсах, которые подключаются только на время вычислений.
«Под капотом» в SAP Data Intelligence — платформа Kubernetes, поэтому все операторы привязаны к docker-контейнерам. Для работы с моделью достаточно описать docker-файл и привязать к нему тэги для используемых библиотек и версий.
Другой способ создания моделей — с помощью AutoML. Это автоматизированные системы МО. Такие инструменты разрабатывают H2O, Microsoft, Google и др. В этом направлении работают и в MIT. Но инженеры университета не фокусируются на встраивании и продуктивизации. В SAP также есть AutoML-система, которая делает упор на быстрый результат. Она работает в HANA и имеет прямой доступ к данным — их не нужно куда-то перемещать и модифицировать. Сейчас мы разрабатываем решение, которое фокусируется на качестве моделей — о релизе объявим позже.
Управление жизненным циклом. Условия меняются, информация устаревает, поэтому точность моделей МО со временем снижается. Соответственно, накопив новые данные, можно переобучить модель и уточнить результаты. Например, один крупный производитель напитков использует информацию о предпочтениях потребителей в 200 разных странах для переобучения интеллектуальных систем. Компания учитывает вкусы людей, количество сахара, калорийность напитков и даже продукцию, которую предлагают конкурирующие бренды на целевых рынках. Модели МО автоматически определяют, какой из сотен продуктов компании лучше всего примут в том или ином регионе.
Переиспользование компонентов на базе операторов в SAP Data Hub
Но версионировать и обновлять модели нужно еще и по мере выхода свежих алгоритмов и обновлений аппаратных компонентов. Их внедрение может повысить точность и качество используемых в работе моделей.
Insight-Driven для роста бизнеса
Описанный выше подход к управлению этапами жизненного цикла моделей машинного обучения — это, по сути, универсальный фреймворк, позволяющий компании стать Insight-Driven и использовать работу с данными в качестве ключевого драйвера для роста бизнеса. Организации, воплощающие эту концепцию, знают больше, растут быстрее, ну и, на наш взгляд, работают гораздо интереснее на этом переднем крае технологий!
Узнайте больше о построении концепции Insight-Driven в нашей библиотеке полезных материалов по управлению данными, куда мы собрали видео, полезные брошюры и триал-доступы к системам SAP.