
Привет! Мы участники программы Tinkoff Internship, и в этой статье хотим рассказать об отборе, внутренней обстановке, задачах и наших впечатлениях. Надеемся, это будет полезно и будущим интернам, и тем, кому просто интересна компания.

Отбор на программу Tinkoff Internship проходил в два этапа.
Первая часть — онлайн-экзамены. В зависимости от направления предлагается несколько алгоритмических задач, тест на знание SQL или олимпиадные задачи по математике, а также тестовое приложение для тех ребят, кто подается на мобильную разработку. Вступительные испытания не совсем стандартны и требуют некоторой подготовки. По истечении срока сдачи экзаменов условия задач выкладываются в группу во Вконтакте, где их можно попробовать решить и обсудить.
Всех тех, кто успешно справился с онлайн-этапом, приглашают на собеседование в офис. Дата стажировки может пересекаться с экзаменами в университете, поэтому организаторы по просьбе могут поменять время или даже день встречи.
Собеседования проходили в разных форматах: давали задачки на логику, язык программирования, спрашивали о предпочтениях в технологиях и обо всем том, что тебя интересует в мире ИТ.
Спустя некоторое время тем, кто был принят на программу, пришло приглашение с условиями работы. И речь не только о деньгах. Стажеры бесплатно обедают в Тинькофф Кафе и ходят в фитнес-зал в офисе.
Как и всем сотрудникам, стажерам предоставляются корпоративные скидки и предложения от партнеров компании.
В отборе участвовали 1299 человек, из которых 412 были приглашены на собеседование, 98 получили приглашения на программу. Итоговый конкурс — более 13 человек на место.
В первый рабочий день организаторы проводят ознакомительную лекцию, после которой стажеры расходятся по своим командам.

На рабочем месте их уже ждет ноутбук, монитор, мышь и внутренний телефон. При желании можно запросить любое нужное оборудование.
Мы, например, просили дополнительный монитор, коврик для мыши, наушники и гарнитуру.
Как только вы обосновались на новом рабочем месте, кураторы рассказывают о своих командах и проектах. Кстати, стажерам сразу дают «боевые» задачи.
Каждый из соавторов статьи недавно завершил свое участие в программе Tinkoff Internship и расскажет о своем опыте.
Я работал над улучшением ценообразования страховых полисов.
У ментора возникла идея, что, проанализировав рынок, мы сможем ввести в модель цены новый параметр, который позволит в конечном счете повысить прибыль. Для этого нужно было собрать имеющиеся данные, получить информацию о рынке, провести конечную аналитику и выяснить, полезен ли новый параметр.
В начале самым сложным было освоиться с SQL и библиотекой для работы с данными Pandas, так как до этого я мало их использовал. Целую неделю я писал скрипты для получения и складирования данных о рынке.
Параллельно работал тест эластичности, где мы меняли наши цены и смотрели на конверсию — вероятность покупки полиса. Используя данные этого теста, мы смогли построить модель, предсказывающую конверсию по нашей цене и полям полиса, а новый параметр увеличил качество работы модели.
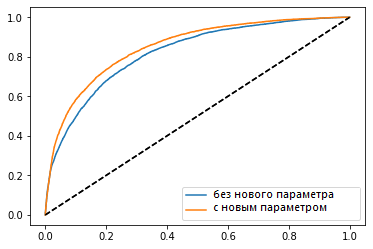
ROC-кривая модели. Чем больше площадь под графиком, тем лучше модель
Получать данные о рынке при каждом обращении пользователя слишком долго, поэтому мы попытались предсказывать новый параметр — и поначалу нам удавалось хорошо это делать. Но с какого-то момента модель на обновленных данных стала обучаться хуже и ошибаться сильнее.
Оказалось, что причина тому — резкая «просадка» курса рубля к основным валютам, поэтому по одному набору параметров она должна была выдавать различные ответы, чего модель, конечно же, делать не могла. Логичным решением стало добавление курса валюты в модель.
Уже казалось, что мы имеем хорошую конверсионную модель. Зафиксировав остальные параметры для конкретного полиса, мы можем изменять нашу цену и, используя предсказанную конверсию, получать точку максимальной ожидаемой прибыли. Но тут оказалось, что модель плохо отображает динамику изменения конверсии от изменения цены и, как следствие, наиболее выигрышной стратегией становится повышение цены настолько, насколько это возможно. Думаю, если провести более тонкие тесты изменения цены, мы сможем избавиться от этой проблемы и внедрить эту модель ценообразования.
В будущем мы хотим создать полноценный RL-агент, который сможет адаптироваться под изменяющиеся условия окружающей среды и максимизировать прибыль. Для знакомства с SQL рекомендую решать задачки по SQL и параллельно смотреть необходимую теорию. Что касается библиотеки Pandas — есть замечательный пример использования Pandas в House Prices. Для хорошего изучения ML подходит курс Воронцова в ШАДе.
Я занимался разработкой мобильной CRM-системы, позволяющей владельцам малого и среднего бизнеса более эффективно вести свой продукт.
Мне повезло с командой: была полная свобода действий, а разработка полна экспериментами и необычными решениями. С каждым днем я все глубже погружался в проект и уже через месяц после фиксов небольших багов и написания автотестов приступил к разработке фичей. Помимо этого мне давали участвовать почти во всех процессах развития продукта: я присутствовал на встречах с клиентами, слушал их пожелания и предложения. Каждый из членов команды мог вносить что-то новое в проект, предлагать свои идеи.
Мне удалось решить несколько важных технических задач, в числе которых была навигация по приложению. Мы не хотели завязываться на библиотеках, поэтому было принято решение написать свой роутер. «Под капотом» он содержит несколько оптимизаций, которые позволяют более эффективно по времени и памяти выполнять транзакции на фрагментах.
Также однажды мы заметили довольно большую утечку памяти, которая приводила к падению приложения на слабых устройствах. Посмотрев логи в LeakCanary, мы увидели, что во всем виноват стандартный гугловский Snackbar. Решили переписать его и немного улучшить, в итоге никаких утечек больше не возникало.
Еще одной проблемой для нас был вес приложения: мы заметили, что в какой-то момент оно стало весить чуть ли не в три раза больше. Проанализировав apk через
Android-приложение мы писали, используя собственную архитектуру, что сначала было для меня совсем непривычным, однако через некоторое время я освоился, и даже принял ее как свою основную, ведь она показалась мне наиболее естественной для написания ПО.
Все это время со мной на связи был мой куратор, он же тимлид, который в режиме 24/7 отвечал на все мои вопросы и нещадно ревьювил мои пулл-реквесты :).
Во время стажировки я смог внести некоторый вклад в развитие Финтех-школы — помогал выстраивать процесс записи прогонов лекций, чтобы в будущем это было легче масштабировать и лекторы из других городов могли понять, о чем была презентация. Также я помогал с донесением информации до студентов, так как понимал, в чем у них могут быть сложности с восприятием.
Стоит учесть, что на момент стажировки у меня уже был некоторый опыт разработки. Однако здесь ценится не только опыт, но и умение быстро разбираться в сложных вещах. Для этого, мне кажется, стоит уделять время алгоритмическим задачам, которые развивают абстрактное мышление. Задачки настоятельно рекомендую решать на leetcode.
Также не стоит забывать про техническую литературу и вообще быть в курсе того, что происходит в мире мобильной разработки. Для этого есть шикарный ресурс с тысячами полезных статей о том, как можно писать код.
Ребятам, изучающим Android, хотелось бы посоветовать прочесть следующие книги:
Чтение книг и нарешивание задач принесут пользу только в том случае, когда вы каждый день применяете новые знания на практике. Поэтому я рекомендую придумать какую-нибудь идею для своего проекта — например, написать простенький мессенджер, музыкальный плеер, галерею для просмотра фото — и начать все это дело реализовывать. Верьте в себя, много читайте, пишите код каждый день — и тогда у вас все получится!
Я два раза проходила стажировку в Tinkoff в команде Process Mining, которая занимается анализом бизнес-процессов в компании. Анализ бизнес-процессов позволяет увидеть, как на самом деле работает процесс, насколько он близок к «идеалу» и где его узкие места.
Так как коллектив компании молодой, было достаточно легко найти общий язык. Все обращаются друг к другу на ты, иерархия сотрудников никак не проявляется в общении. Первый раз в моей команде было трое стажеров, все мы занимались разными задачами с разными наставниками. Также была возможность поменять задачу в течение программы. Но моя мне понравилась с самого начала.
В основном я занималась анализом процесса обработки запросов от сотрудников и клиентов Tinkoff.ru. Всю мою работу можно разделить на две части: подготовка требуемой модели данных с помощью SQL (основные команды и правила языка можно посмотреть на этом ресурсе) и построение аналитики на основе этих данных.
Первая стажировка была с частичной занятостью, 20 часов в неделю. Моя основная задача состояла в том, чтобы добавить информацию о соблюдении SLA — соглашения об уровне обслуживания — к существующему варианту анализа процесса. Некоторое время ушло на знакомство с инфраструктурой компании и инструментами, с помощью которых выгружались и обрабатывались данные. В итоге в текущий анализ бизнес-процесса я добавила два новых дашборда с аналитикой.
Во второй раз передо мной стояла более сложная задача — собрать неиспользуемые ранее данные из хранилища в определенной форме и сделать по ним новую аналитику. Кстати, в книге В. Савельева «Статистика и котики» простым языком описаны основные статистические характеристики и методы их применения.
Несколько раз я ходила на встречу с заказчиком, где мы обсуждали требования и текущие наработки. Изначально планировалось, что результатом моей работы станут три дополнительные страницы с аналитикой, но в ходе обсуждений мы пришли к выводу, что нужно сделать абсолютно новую версию отчета. Когда все данные были собраны и дашборды готовы, я запустила новый проект на тестовую группу. Спустя неделю собрала от них фидбек и внесла некоторые доработки. В конце стажировки проект был доступен сотрудникам компании.
В рамках Tinkoff Internship я попал в команду речевых технологий.
Еще на собеседовании я познакомился с Настей, будущим куратором, и Вадимом — нашим менеджером по продукту. Настя дала несколько алгоритмических задачек, а Вадим рассказал о работе над голосовым помощником, роботами и аналитикой колл-центров. Вопреки расхожему мнению, мы работаем не только над голосом и ушами голосового помощника Олега, но и над множеством других интересных задач по интеграции голосовых технологий для различных клиентов. Наша команда активно растет и ищет как профессионалов, так и мотивированных новичков.
Во время стажировки я занимался оптимизацией инференса. Дело в том, инференс нейронных сетей довольно часто сводится к операциям с плотными матрицами. При этом для авторегрессионных моделей, например для WaveNet, его выгоднее выполнять на CPU, чтобы можно было поддерживать больше одновременных потоков инференса.
Однако производительность «наивной» реализации матричного умножения с автоматической оптимизацией средствами компилятора редко достигает 10% от максимально возможной для отдельно взятого CPU. Для большей производительности необходимо использовать более тонкую оптимизацию. Существует много различных подходов к оптимизации матричных умножений для инференса нейросетей на CPU. У Насти были серьезные наработки по данному вопросу, мне же предстояло собрать их всех в единую библиотеку GEMM на C++. Такие библиотеки используются в популярных фреймворках: в TensorFlow это Eigen, в PyTorch — FBGEMM.
Кроме Register Blocking, Cache Blocking и SIMD-расширений процессора в библиотеке активно используются возможности C++: статический полиморфизм (CRTP) и генерация кода на этапе компиляции. Забавный факт: в определенный момент пришлось ненадолго переключиться с оптимизации матричных умножений на оптимизацию компиляции кода, использующего библиотеку. В итоге наша библиотека обгоняет Eigen (многократно) и FBGEMM на большинстве тестов. Дальнейшая работа будет направлена на внедрение библиотеки в наш движок для инференса.
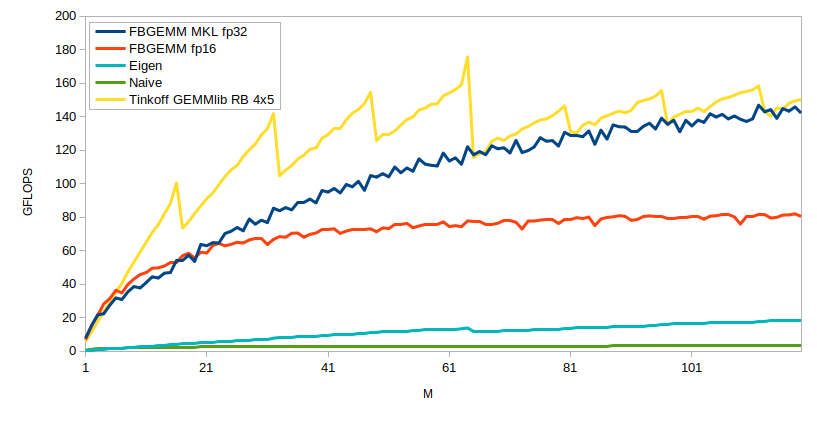
Один из стандартных бенчмарков FBGEMM: произведение матриц
[M ? 512] и [512 ? 512]
От стажировки у нас остались только положительные впечатления. Круто, что стажеров считают полноценными сотрудниками, дают реальные задачи и позволяют решать их самостоятельно. Если возникают трудности, наставники помогают, но не просто озвучивают советы, а дают возможность самому найти решение.
Работа с людьми, не лишенными чувства юмора, которые могут профессионально руководить и писать крутой код, всегда дает отличный шанс развивать свои хард- и софт-скилы, набираться опыта и начинать свою работу в ИТ.

Отбор
Отбор на программу Tinkoff Internship проходил в два этапа.
Первая часть — онлайн-экзамены. В зависимости от направления предлагается несколько алгоритмических задач, тест на знание SQL или олимпиадные задачи по математике, а также тестовое приложение для тех ребят, кто подается на мобильную разработку. Вступительные испытания не совсем стандартны и требуют некоторой подготовки. По истечении срока сдачи экзаменов условия задач выкладываются в группу во Вконтакте, где их можно попробовать решить и обсудить.
Всех тех, кто успешно справился с онлайн-этапом, приглашают на собеседование в офис. Дата стажировки может пересекаться с экзаменами в университете, поэтому организаторы по просьбе могут поменять время или даже день встречи.
Собеседования проходили в разных форматах: давали задачки на логику, язык программирования, спрашивали о предпочтениях в технологиях и обо всем том, что тебя интересует в мире ИТ.
Спустя некоторое время тем, кто был принят на программу, пришло приглашение с условиями работы. И речь не только о деньгах. Стажеры бесплатно обедают в Тинькофф Кафе и ходят в фитнес-зал в офисе.
Как и всем сотрудникам, стажерам предоставляются корпоративные скидки и предложения от партнеров компании.
В отборе участвовали 1299 человек, из которых 412 были приглашены на собеседование, 98 получили приглашения на программу. Итоговый конкурс — более 13 человек на место.
Первое впечатление
В первый рабочий день организаторы проводят ознакомительную лекцию, после которой стажеры расходятся по своим командам.
На рабочем месте их уже ждет ноутбук, монитор, мышь и внутренний телефон. При желании можно запросить любое нужное оборудование.
Мы, например, просили дополнительный монитор, коврик для мыши, наушники и гарнитуру.
Как только вы обосновались на новом рабочем месте, кураторы рассказывают о своих командах и проектах. Кстати, стажерам сразу дают «боевые» задачи.
Каждый из соавторов статьи недавно завершил свое участие в программе Tinkoff Internship и расскажет о своем опыте.
Витя. Направление — аналитика
Я работал над улучшением ценообразования страховых полисов.
У ментора возникла идея, что, проанализировав рынок, мы сможем ввести в модель цены новый параметр, который позволит в конечном счете повысить прибыль. Для этого нужно было собрать имеющиеся данные, получить информацию о рынке, провести конечную аналитику и выяснить, полезен ли новый параметр.
В начале самым сложным было освоиться с SQL и библиотекой для работы с данными Pandas, так как до этого я мало их использовал. Целую неделю я писал скрипты для получения и складирования данных о рынке.
Параллельно работал тест эластичности, где мы меняли наши цены и смотрели на конверсию — вероятность покупки полиса. Используя данные этого теста, мы смогли построить модель, предсказывающую конверсию по нашей цене и полям полиса, а новый параметр увеличил качество работы модели.
ROC-кривая модели. Чем больше площадь под графиком, тем лучше модель
Получать данные о рынке при каждом обращении пользователя слишком долго, поэтому мы попытались предсказывать новый параметр — и поначалу нам удавалось хорошо это делать. Но с какого-то момента модель на обновленных данных стала обучаться хуже и ошибаться сильнее.
Оказалось, что причина тому — резкая «просадка» курса рубля к основным валютам, поэтому по одному набору параметров она должна была выдавать различные ответы, чего модель, конечно же, делать не могла. Логичным решением стало добавление курса валюты в модель.
Уже казалось, что мы имеем хорошую конверсионную модель. Зафиксировав остальные параметры для конкретного полиса, мы можем изменять нашу цену и, используя предсказанную конверсию, получать точку максимальной ожидаемой прибыли. Но тут оказалось, что модель плохо отображает динамику изменения конверсии от изменения цены и, как следствие, наиболее выигрышной стратегией становится повышение цены настолько, насколько это возможно. Думаю, если провести более тонкие тесты изменения цены, мы сможем избавиться от этой проблемы и внедрить эту модель ценообразования.
В будущем мы хотим создать полноценный RL-агент, который сможет адаптироваться под изменяющиеся условия окружающей среды и максимизировать прибыль. Для знакомства с SQL рекомендую решать задачки по SQL и параллельно смотреть необходимую теорию. Что касается библиотеки Pandas — есть замечательный пример использования Pandas в House Prices. Для хорошего изучения ML подходит курс Воронцова в ШАДе.
Максим. Направление — Android-разработка
Я занимался разработкой мобильной CRM-системы, позволяющей владельцам малого и среднего бизнеса более эффективно вести свой продукт.
Мне повезло с командой: была полная свобода действий, а разработка полна экспериментами и необычными решениями. С каждым днем я все глубже погружался в проект и уже через месяц после фиксов небольших багов и написания автотестов приступил к разработке фичей. Помимо этого мне давали участвовать почти во всех процессах развития продукта: я присутствовал на встречах с клиентами, слушал их пожелания и предложения. Каждый из членов команды мог вносить что-то новое в проект, предлагать свои идеи.
Мне удалось решить несколько важных технических задач, в числе которых была навигация по приложению. Мы не хотели завязываться на библиотеках, поэтому было принято решение написать свой роутер. «Под капотом» он содержит несколько оптимизаций, которые позволяют более эффективно по времени и памяти выполнять транзакции на фрагментах.
Также однажды мы заметили довольно большую утечку памяти, которая приводила к падению приложения на слабых устройствах. Посмотрев логи в LeakCanary, мы увидели, что во всем виноват стандартный гугловский Snackbar. Решили переписать его и немного улучшить, в итоге никаких утечек больше не возникало.
Еще одной проблемой для нас был вес приложения: мы заметили, что в какой-то момент оно стало весить чуть ли не в три раза больше. Проанализировав apk через
apkanalyzer, увидели, что все дело в нативных библиотеках: приложение собирается под все типы процессоров, из-за чего один .so-файл может увеличить вес приложения не на 2,5 Мб, а на 12 Мб. Чтобы этого избежать, решили разделить итоговый apk на каждый из типов процессоров. Таким образом мы получили четыре релизные сборки вместо одной, но весили они примерно в 2,5 раза меньше.Android-приложение мы писали, используя собственную архитектуру, что сначала было для меня совсем непривычным, однако через некоторое время я освоился, и даже принял ее как свою основную, ведь она показалась мне наиболее естественной для написания ПО.
Все это время со мной на связи был мой куратор, он же тимлид, который в режиме 24/7 отвечал на все мои вопросы и нещадно ревьювил мои пулл-реквесты :).
Во время стажировки я смог внести некоторый вклад в развитие Финтех-школы — помогал выстраивать процесс записи прогонов лекций, чтобы в будущем это было легче масштабировать и лекторы из других городов могли понять, о чем была презентация. Также я помогал с донесением информации до студентов, так как понимал, в чем у них могут быть сложности с восприятием.
Стоит учесть, что на момент стажировки у меня уже был некоторый опыт разработки. Однако здесь ценится не только опыт, но и умение быстро разбираться в сложных вещах. Для этого, мне кажется, стоит уделять время алгоритмическим задачам, которые развивают абстрактное мышление. Задачки настоятельно рекомендую решать на leetcode.
Также не стоит забывать про техническую литературу и вообще быть в курсе того, что происходит в мире мобильной разработки. Для этого есть шикарный ресурс с тысячами полезных статей о том, как можно писать код.
Ребятам, изучающим Android, хотелось бы посоветовать прочесть следующие книги:
- Kotlin in Action. Довольно простая, отлично написанная книга, прочитав которую можно очень быстро влиться в разработку на Kotlin.
- Effective Java. Мастхэв — сборник советов и приемов, которые должен знать любой Kotlin-/Java-разработчик.
- Efficient Android Threading. Отличная книга — умеренно глубоко рассказывает о том, как устроено многопоточное взаимодействие в Android.
Чтение книг и нарешивание задач принесут пользу только в том случае, когда вы каждый день применяете новые знания на практике. Поэтому я рекомендую придумать какую-нибудь идею для своего проекта — например, написать простенький мессенджер, музыкальный плеер, галерею для просмотра фото — и начать все это дело реализовывать. Верьте в себя, много читайте, пишите код каждый день — и тогда у вас все получится!
Маша. Направление — аналитика
Я два раза проходила стажировку в Tinkoff в команде Process Mining, которая занимается анализом бизнес-процессов в компании. Анализ бизнес-процессов позволяет увидеть, как на самом деле работает процесс, насколько он близок к «идеалу» и где его узкие места.
Так как коллектив компании молодой, было достаточно легко найти общий язык. Все обращаются друг к другу на ты, иерархия сотрудников никак не проявляется в общении. Первый раз в моей команде было трое стажеров, все мы занимались разными задачами с разными наставниками. Также была возможность поменять задачу в течение программы. Но моя мне понравилась с самого начала.
В основном я занималась анализом процесса обработки запросов от сотрудников и клиентов Tinkoff.ru. Всю мою работу можно разделить на две части: подготовка требуемой модели данных с помощью SQL (основные команды и правила языка можно посмотреть на этом ресурсе) и построение аналитики на основе этих данных.
Первая стажировка была с частичной занятостью, 20 часов в неделю. Моя основная задача состояла в том, чтобы добавить информацию о соблюдении SLA — соглашения об уровне обслуживания — к существующему варианту анализа процесса. Некоторое время ушло на знакомство с инфраструктурой компании и инструментами, с помощью которых выгружались и обрабатывались данные. В итоге в текущий анализ бизнес-процесса я добавила два новых дашборда с аналитикой.
Во второй раз передо мной стояла более сложная задача — собрать неиспользуемые ранее данные из хранилища в определенной форме и сделать по ним новую аналитику. Кстати, в книге В. Савельева «Статистика и котики» простым языком описаны основные статистические характеристики и методы их применения.
Несколько раз я ходила на встречу с заказчиком, где мы обсуждали требования и текущие наработки. Изначально планировалось, что результатом моей работы станут три дополнительные страницы с аналитикой, но в ходе обсуждений мы пришли к выводу, что нужно сделать абсолютно новую версию отчета. Когда все данные были собраны и дашборды готовы, я запустила новый проект на тестовую группу. Спустя неделю собрала от них фидбек и внесла некоторые доработки. В конце стажировки проект был доступен сотрудникам компании.
Коля. Направление — ML
В рамках Tinkoff Internship я попал в команду речевых технологий.
Еще на собеседовании я познакомился с Настей, будущим куратором, и Вадимом — нашим менеджером по продукту. Настя дала несколько алгоритмических задачек, а Вадим рассказал о работе над голосовым помощником, роботами и аналитикой колл-центров. Вопреки расхожему мнению, мы работаем не только над голосом и ушами голосового помощника Олега, но и над множеством других интересных задач по интеграции голосовых технологий для различных клиентов. Наша команда активно растет и ищет как профессионалов, так и мотивированных новичков.
Во время стажировки я занимался оптимизацией инференса. Дело в том, инференс нейронных сетей довольно часто сводится к операциям с плотными матрицами. При этом для авторегрессионных моделей, например для WaveNet, его выгоднее выполнять на CPU, чтобы можно было поддерживать больше одновременных потоков инференса.
Однако производительность «наивной» реализации матричного умножения с автоматической оптимизацией средствами компилятора редко достигает 10% от максимально возможной для отдельно взятого CPU. Для большей производительности необходимо использовать более тонкую оптимизацию. Существует много различных подходов к оптимизации матричных умножений для инференса нейросетей на CPU. У Насти были серьезные наработки по данному вопросу, мне же предстояло собрать их всех в единую библиотеку GEMM на C++. Такие библиотеки используются в популярных фреймворках: в TensorFlow это Eigen, в PyTorch — FBGEMM.
Кроме Register Blocking, Cache Blocking и SIMD-расширений процессора в библиотеке активно используются возможности C++: статический полиморфизм (CRTP) и генерация кода на этапе компиляции. Забавный факт: в определенный момент пришлось ненадолго переключиться с оптимизации матричных умножений на оптимизацию компиляции кода, использующего библиотеку. В итоге наша библиотека обгоняет Eigen (многократно) и FBGEMM на большинстве тестов. Дальнейшая работа будет направлена на внедрение библиотеки в наш движок для инференса.
Один из стандартных бенчмарков FBGEMM: произведение матриц
[M ? 512] и [512 ? 512]
Итоги
От стажировки у нас остались только положительные впечатления. Круто, что стажеров считают полноценными сотрудниками, дают реальные задачи и позволяют решать их самостоятельно. Если возникают трудности, наставники помогают, но не просто озвучивают советы, а дают возможность самому найти решение.
Работа с людьми, не лишенными чувства юмора, которые могут профессионально руководить и писать крутой код, всегда дает отличный шанс развивать свои хард- и софт-скилы, набираться опыта и начинать свою работу в ИТ.
HanryCase
Перед онлайн экзаменами сотрудники тинкофа проверяют, рост, вес, разрез глаз и цвет кожи.
