

Уверен, что заголовок вызвал здоровую реакцию — “ну опять началось…” Но позвольте завладеть вашим вниманием на 5-10 минут, и я постараюсь не обмануть ожидания.
Структура статьи будет такова: берется стереотипное утверждение и раскрывается “природа” возникновения этого стереотипа. Надеюсь, это позволит взглянуть на выбор парадигмы обмена данными в ваших проектах под новым углом.
Для того, чтобы была ясность в том, что такое RPC, предлагаю рассматривать стандарт JSON-RPC 2.0. C REST ясности нет. И не должно быть. Все, что нужно знать о REST — он неотличим от HTTP.
RPC запросы быстрее и эффективнее, потому, что позволяют делать batch-запросы.
Речь идет о том, что в RPC можно в одном запросе выполнить вызов сразу нескольких процедур. Например, создать пользователя, добавить ему аватар и в том же запросе подписать его на какие-то топики. Всего один запрос, а сколько пользы!
Действительно, если у вас будет всего одна нода backend, это будет казаться быстрее при batch-запросе. Потому, что три REST запроса потребуют в три раза больше ресурсов от одной ноды на установку соединений.
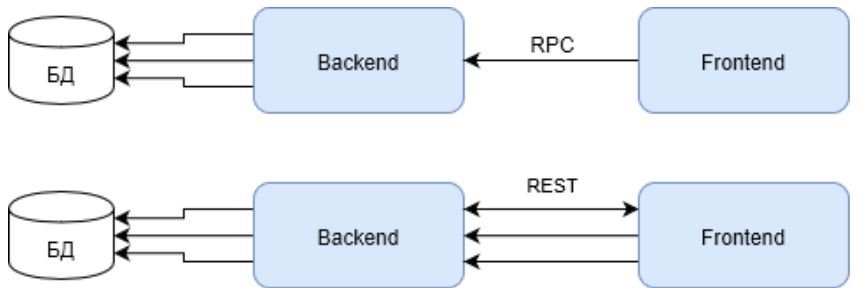
Обратите внимание, что первый запрос в случае с REST должен вернуть идентификатор пользователя, для выполнения последующих запросов. Что также негативно влияет на общий результат.
Но такие инфраструктуры можно встретить, разве что, в in-house решениях и Enterprise. В крайнем случае, в небольших WEB проектах. А вот полноценные WEB решения, да еще и именуемые HighLoad так строить не стоит. Их инфраструктура должна отвечать критериям высокой доступности и нагруженности. И картина меняется.
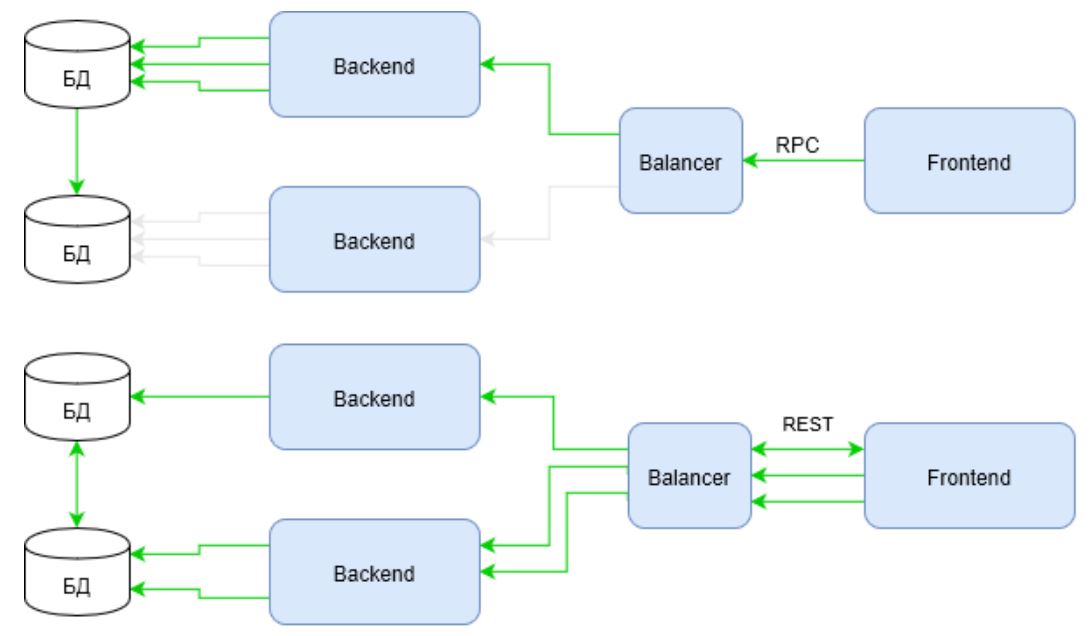
Зеленым отмечены каналы активности инфраструктуры при том же сценарии. Обратите внимание, как ведет себя RPC теперь. Запрос использует инфраструктуру только по одному плечу от балансировщика к backend. В то время, как REST все также проигрывает в первом запросе, но наверстывает упущенное используя всю инфраструктуру.
Достаточно в сценарий ввести не два запроса на обогащение, а, скажем, пять или десять… и ответ на вопрос “кто выигрывает теперь?” становится неочевиден.
Предлагаю глянуть еще шире на проблему. На схеме видно, как используются каналы инфраструктуры, но инфраструктура не ограничивается каналами. Важной составляющей высоконагруженной инфраструктуры являются кэши. Давайте теперь получим какой-то артефакт пользователя. Несколько раз. Скажем 32 раза.
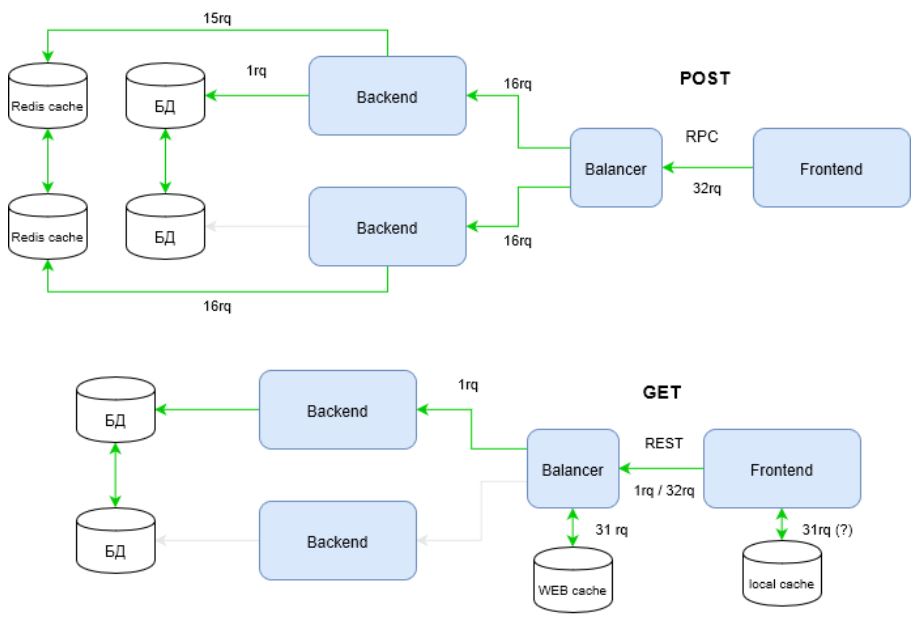
Посмотрите, как заметно “поправилась” инфраструктура на RPC для того, чтобы отвечать требованиям высокой нагрузки. Все дело в том, что REST использует всю мощь HTTP протокола в отличие от RPC. На приведенной схеме эта мощь реализуется через метод запроса — GET.
У HTTP методов, помимо прочего, есть стратегии кеширования. Познакомиться с ними можно в документации на HTTP. Для RPC используются POST запросы, которые не считаются идемпотентными, то есть многократное повторение одних и тех же запросов POST может возвращать разные результаты (например, после каждой отправки комментария будет появляться очередная копия этого комментария) (источник).
Следовательно, RPC не в состоянии эффективно использовать инфраструктурные кэши. Это приводит к тому, что приходится “завозить” софтовые кэши. На схеме в этой роли представлен Redis. Софтовый кэш, в свою очередь, требует от разработчика дополнительный кодовый слой и заметные изменения в архитектуре.
Давайте теперь посчитаем, сколько же запросов “родил” REST и RPC в рассматриваемой инфраструктуре?
| Запросы | Входящие | к backend | к СУБД | к софт-кэшу (Redis) | ИТОГО |
|---|---|---|---|---|---|
| REST | 1/32* | 1 | 1 | 0 | 3 / 35 |
| RPC | 32 | 32 | 1 | 31 | 96 |
[*] в лучшем случае (если локальный кэш используется) 1 запрос (один!), в худшем 32 входящих запроса.
В сравнении с первой схемой разница разительная. Теперь становится очевидным выигрыш REST. Но предлагаю не останавливаться на достигнутом. Развитая инфраструктура включает в себя CDN. Часто он же решает вопрос противодействия DDoS и DoS атакам. Получим:

Тут для RPC все становится совсем плачевно. RPC просто не в состоянии делегировать работу с нагрузкой CDN. Остается надеяться только на системы противодействия атакам.
Можно ли на этом закончить? И опять, нет. Методы HTTP, как выше уже говорилось, имеют свою “магию”. И неспроста метод GET является тотально используемым в Internet. Обратите внимание на то, что этот метод способен обращаться к части контента, способен ставить условия, которые смогут интерпретировать инфраструктурные элементы еще до передачи управления вашему коду и т.д. Все это позволяет создавать гибкие, управляемые инфраструктуры, способные переваривать действительно большие потоки запросов. А в RPC этот метод… игнорируется.
Так почему так устойчив миф о том, что batch запросы (RPC) быстрее? Лично мне кажется, что большинство проектов просто не достигают такого уровня развития, когда REST способен показать свою силу. Более того, в небольших проектах, он охотнее показывает свою слабость.
Выбор REST или RPC это не волевой выбор отдельного человека в проекте. Этот выбор должен отвечать требованиям проекта. Если проект способен выжать из REST все то, что он действительно может, и это действительно нужно, то REST будет отличным выбором.
Но если на то, чтобы получить все профиты REST, нужно будет нанять в проект девопсов, для оперативного масштабирования инфраструктуры, админов для управления инфраструктурой, архитектора для проектирования всех слоев WEB сервиса… а проект, при этом, продает три пачки маргарина в день… я бы остановился на RPC, т.к. этот протокол более утилитарный. Он не потребует глубоких знаний работы кэшей и инфраструктуры, а сфокусирует разработчика на простых и понятных вызовах нужных ему процедур. Бизнес будет доволен.
RPC запросы надежнее, потому, что могут выполнять batch-запросы в рамках одной транзакции
Это свойство RPC является несомненным плюсом, т.к. легко удерживать БД в консистентном состоянии. А вот с REST выходит все сложнее. Запросы могут приходить непоследовательно на разные ноды backend.
Этот “недостаток” REST является обратной стороной его преимущества описанного выше — способность эффективно использовать все ресурсы инфраструктуры. Если инфраструктура спроектирована плохо, а тем более, если спроектирована плохо архитектура проекта и БД в частности, то это действительно большая боль.
Но так ли надежны batch-запросы как кажутся? Давайте рассмотрим кейс: создаем пользователя, обогащаем его профиль каким-то описанием и отсылаем ему SMS с секретом для завершения регистрации. Т.е. три вызова в одном batch-запросе.
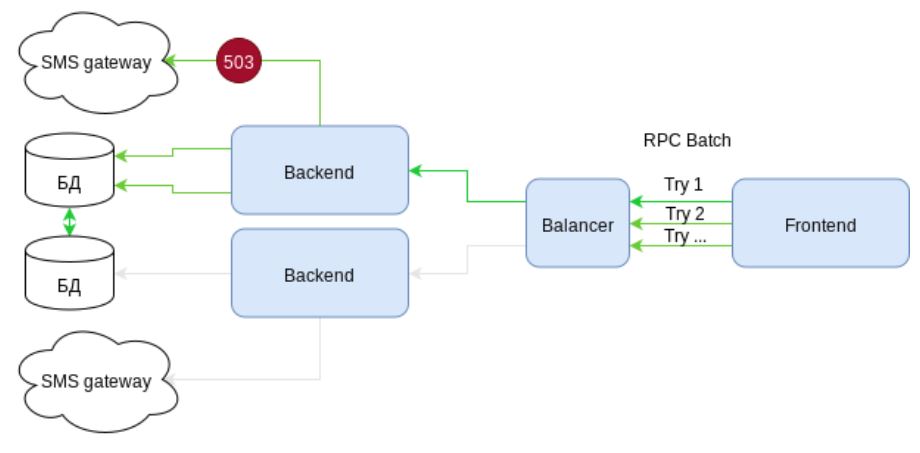
Рассмотрим схему. На ней представлена инфраструктура с элементами высокой доступности. Есть два независимых канала связи с SMS шлюзами. Но… что мы видим? При отправке SMS возникает ошибка 503 — сервис временно недоступен. Т.к. отправка SMS упакована в batch-запрос, то весь запрос должен откатиться. Действия в СУБД аннулируются. Клиент получает ошибку.
Следующая попытка — лотерея. Либо запрос опять попадет на ту же ноду и опять вернет ошибку, либо повезет, и он выполнится. Но главное, что как минимум один раз наша инфраструктура уже потрудилась зря. Нагрузка была, а профита нет.
Хорошо, давайте представим, что мы напряглись (!) и продумали вариант, когда запрос может успешно выполниться частично. А остаток, мы вновь попытаемся выполнить через какой-то интервал времени (Какой? Решает фронт?). Но лотерея так и осталась. Запрос на отправку SMS с вероятностью 50/50 вновь провалится.
Согласитесь, со стороны клиента, сервис не кажется таким надежным как хотелось бы… а что REST?

REST опять использует “магию” HTTP, но теперь с кодами ответов. При возникновении ошибки 503 на SMS шлюзе, backend транслирует эту ошибку балансировщику. Балансировщик получая эту ошибку, и не разрывая соединение с клиентом направляет запрос на другую ноду, которая успешно отрабатывает запрос. Т.е. клиент получает ожидаемый результат, а инфраструктура подтверждает свое высокое звание “восокодоступной”. Пользователь счастлив.
И опять это не все. Балансировщик не просто получил код ответа 503. Этот код при ответе, по стандарту, желательно снабдить заголовком “Retry-After". Заголовок дает понять балансировщику, что не стоит беспокоить эту ноду по этому роуту в течении заданного времени. И следующие запросы на отправку SMS будут направляться сразу на ноду, у которой нет проблем с SMS шлюзом.
Как мы видим, надежность JSON-RPC переоценена. Действительно, легче организовать консистентность в БД. Но жертвой, в таком случае, станет надежность системы в целом.
Вывод во многом аналогичен предыдущему. Когда инфраструктура проста, очевидность JSON-RPC несомненно его плюс. Если проект предполагает высокую доступность с высокой нагруженностью, REST смотрится более верным, хотя и более сложным решением.
Порог входа в REST ниже
Я думаю, что выше проведенный анализ, развенчивающий устоявшиеся стереотипы о RPC наглядно показал, что порог входа в REST несомненно выше, чем в RPC. Связанно это с необходимостью глубокого понимания работы HTTP, а также, с необходимостью обладать достаточными знаниями о существующих инфраструктурных элементах, которые можно и нужно применять в WEB проектах.
Так почему многие думают, что REST попроще будет? Лично мое мнение заключается в том, что эта кажущаяся простота исходит из самих манифестов REST. Т.е. REST это не протокол, а концепция… у REST нет стандарта, есть некоторые рекомендации… REST не сложнее HTTP. Кажущаяся свобода и анархия манит “свободных художников”.
Несомненно, REST не сложнее HTTP. Но сам HTTP это хорошо продуманный протокол, который доказал свою состоятельность десятилетиями. Если нет глубокого понимания самого HTTP, то и о REST судить нельзя.
А вот о RPC — можно. Достаточно взять его спецификацию. Так нужен ли вам тупой JSON-RPC? Или все же хитрый REST? Решать вам.
Искренне надеюсь, что я не потратил ваше время зря.
Комментарии (108)

tuxi
19.11.2019 22:42+2
rpiontik Автор
19.11.2019 22:46+2Все верно. Статья отсылка к той. Я даже явную ссылку дал в конце статьи, а название зеркальное отражение ;) Ну и чтобы не было какого-то странного восприятия, это не попытка дезавуировать ту статью. Лишь обратная сторона одной медали.
dzsysop
19.11.2019 23:05+3Мне ваша подача более близка и понятна.
REST действительно более гибок в плане использования различных неявно задействованных, но реально существующих штуковин. (Http headers http statuses, cdns, load balancers etc). Но он таки требует от разработчика бОльшего понимания и протоколов и сети в целом и архитектуры.
В то время как RPC более строг и поэтому понятен как «вещь в себе». И разработчику незачем знать обо всем остальном. В этом тоже есть своя прелесть. И ваша статья эту разницу хорошо раскрывает.
alsii
19.11.2019 23:17+1Вот про кэши (локальный и балансера) не уловил. "Получим 32 раза артефакт пользователя". Что если между 13 и 14 "разами" данные пользователя были изменены другим процессом? Как инвалидировать локальный кэш? По времени?
rpiontik Автор
19.11.2019 23:23Для этого есть механизмы инвалидации. Если кратко, смотрите в сторону ETag. Тут не рассматривается, просто потому, что отдельная тема.

abyrvalg
20.11.2019 07:56И всё-таки, если можно, опишите в двух словах: как веб-кеш на балансировщике узнает, что данные в БД изменились?
ggo
20.11.2019 09:43Если об этом балансировщику никто не скажет, никак.
Поэтому обычно инвалидируют по времени, либо балансировщик делают чуть-чуть умным.tuxi
20.11.2019 12:07И как его сделать более умным? Наградить его связями с другими слоями системы и отправить в свободное плавание? И все это ради только использования концепции rest?
abyrvalg
20.11.2019 15:06Да понятно, про то и речь. Автор сравнивает совершенно разные вещи и делает из этого выводы. Где-то показал сферическое преимущество, где-то умолчал о нетривиальности реализации...
Ps: в целом статья очень даже хорошая.
apapacy
20.11.2019 13:49ETag конечно классно. Но он сожалению не разгружает самый ценный (с точки зрения затрат) ресурс — бэкэнд приложения. Все что он делает это говорит клиенту что запрос не изменился и можно не тратить время на его пересылку клиенту. Никто не говорит что это плохо. Особенно если ресурс массивный. Но никакой магии не произойдет. Ресурсы бэкенда исчерпываются как правило раньше чем ресурсы простого http-сервера или сети.
Поскажите, может быть я ошибаюсь. Но с тем чтобы пробить кэш и взять данные с сервера у современных реализаций http-серверов есть проблема. Например, я установил кэш для url на топ 10 новостей на 10 минут для публичных клиентов.
Параллельно у меня есть API для контент-менеджера который добавил новость. Я как бы должен ему или сделать отдельное API которое позволит GET-запросом получить данные не кэшируемые или сделать кэш чувствительным к какому-то заголовку или cookie (что фактически также заголовок) или к параметру. Проще сделать это даже в отдельном API, т.к. в случае с заголовками придется согласовывать признаки по каоторым происходит кэширование на стороне nginx с бэкэндом, который должен устанавливать какие-то cookie или с фронтендом который должен добавлять в Ajax-запросы дополнительные заголовки.
Но вот проблема. После того как я уже решил вопрос с GET-запросом для контент менеджера без кэша — простые публичные пользователи будут продолжать получать устаревшие закэшированные данные. Если бы я разрабатывал систему на том же JSON-RPC — я смог бы управлять этим параметром более гибко.rpiontik Автор
20.11.2019 14:16Писал уже ниже, но повторюсь. Управление кэшем непростая задача. Это отдельный слой web-сервиса. Иногда, когда с ним возникают проблемы, некоторые проекты идут радикальным путем — исключаю его.
Но это тупиковый путь. С ним нужно уметь работать. Если не умеешь — учиться. Задача не так проста и очевидна, чтобы ответить на вопрос — как скинуть кеш? Для начала нужно определиться со стратегией того, что вообще нужно кэшировать, как, почему, как инвалидировать кэш, на каком уровне. И далее, как сказал классик — придерживаться этой стратегии.
Дам ссылку на толковую статью по этой части. Сам, пока в полемику встревать не буду.
m.habr.com/ru/post/428127apapacy
20.11.2019 14:27Да это все мне известно. И отчасти вопрос (скорее всего) решила бы фича с purge_cache но она доступна только по коммерческой подписке

Это как бы уже не проблема протокола http а проблема коробочной реализации этого протокола в различных серверах.rpiontik Автор
20.11.2019 14:32Коммерчески состоятельные проекты тратят большие средства на ФОТ. На ФОТ грамотных, талантливых специалистов. Потратить деньги на решение, которое сделано грамотными, талантливыми специалистами другой компании, которое обоснованно собственными специалистами и окупается бизнесом — вполне логичный шаг. Более того, (ИМХО) это как раз верный шаг в сравнении с воспитанием «незаменимых» специалистов с их «уникальными» решениями на бесплатном софте. Возможно это непопулярное мнение, но он мое.
Но все же, это не единственное решение. Можно реализовать хитрые «ручки», которые доступны изнутри сети на кэшироующих серверах. И микросервисы управления кэшем. Еще раз повторюсь — нет единой пилюли для всего. Это действительно непростая часть проекта и делают ее для непростых проектов. Т.е. решение сопоставимо задаче.apapacy
20.11.2019 14:58+1Делать велосипед что на REST что на JSON-RPC неперспективно. Что касается JSON-RPC то нет ничего кроме велосипедов не только по кэшированию но и вообще по теме.
Что касается задачи — то это самый распространенный случай. Есть контент кэшируемый и обновляемый. Решается обычно влоб — есть GET api/content кэшируемый и есть GET api/admin/content не кэшируемый. То что обычный клиент получит контент с допустимым лагом вобщем-то никого особенно не волнует. Если приложение конечно самое обычное — то есть 100500 сайт-визитка или интернет-магазин
rpiontik Автор
20.11.2019 15:11И да и нет. «Хитрые» роуты решают вопрос в случае, когда ты уверен, что не будет атаки на инфраструктуру с целью ее перегрузить.
Запросы за авторизацией, не часто нужно кэшировать. Просто потому, что действия пользователя чаще всего разнообразные, а возвращаемый контент уникальный. Т.е. кэш тут попросту ничего не дает. Но иногда и их нужно. Например, когда пользователь получает доступ к статическим файлам (скажем медиабиблиотеке) просто потому, что он залогинился.
alsii
20.11.2019 17:22То что обычный клиент получит контент с допустимым лагом вобщем-то никого особенно не волнует. Если приложение конечно самое обычное — то есть 100500 сайт-визитка или интернет-магазин.
Т.е. прочитает клиент предыдущую версию описания товара, оплатит, а получит потом не то, что хотел? Ну в принципе вы правы, кого это волнует… Пусть потом попробует доказать, что он читал что-то другое. Печально!
rpiontik Автор
20.11.2019 18:04Он, возможно, прочитает не то описание и увидит не ту цену. При стечении негативных обстоятельств. Но заплатить не ту сумму у него не выйдет. Т.к. транзакция оплаты будет валидироваться по актуальным данным. Тут-то все и встанет на места.
Ни один клиент при этом не пострадает ;)
А вот над оперативностью обновления можно думать, но не загоняться. Потому, что так можно предполажить, что клиент открыл страницу… смотрит на нее 2 часа и потом наживает кнопку купить. А за эти два часа товар поменял описание и цену. Результат тот же. Но кэш тут в общем-то не виноват. Точнее это уже кэш пользователя зафейлил информацию.apapacy
20.11.2019 20:48Кстати один из вариантов почему не REST — такие вещи как зависшие страницы нужно обновлять по изменению цен проталкиванием с сервера. Если делать по REST каркас приложения сильно на REST ориентируется и проталкивание это еще один каркас. Поэтому частенько разработчики махлюют и делают опросы по таймеру. Если все делать на единой технологии (типа WAMP) то не возникает сопротивления каркаса ориентированного на REST необходимости проталкивать сообщения с сервера. Все как бы работает в одном ключе.
tuxi
20.11.2019 15:13+1Как вариант, это решается отправкой одиночных реквестов с кастомным заголовком. Придется сделать некий свой «велосипед» со своими правилами, но в более менее больших проектах это оправдано, если кроме этой фичи от бесплатного nginx больше ничего не надо.
Sioln
19.11.2019 23:57+1Про СМС в RPC какой-то наивный подход.
Что мешает так же транзакционно, как и остальные команды в батче, класть СМС в очередь и отправлять из отдельных процессов?
А то у вас возможна не менее худшая ситуация, когда СМС успешно ушла, а транзакция, например, записи переменного кода из СМС в БД — откатилась.rpiontik Автор
20.11.2019 00:01Да нет. Не получается так. Т.к. сначала создается пользователь. А уж далее выполняются несвязанные действия в его контексте. Т.е. обогащение и верификация через СМС. Ну и если на одной ноде обогащение не прошло, оно уйдет на вторую, как и в случае с СМС. А уж если и там обвалится — ну это уже даунтайм.
Sioln
20.11.2019 00:19Перечитайте. Реализация, которую вы придумали в варианте RPC, кривая и будет порождать косяки. Так не делают в принципе (или делают, а потом переписывают).
Во-первых она требует сетевого io с сервисом смс и держит в это время соединение с пользователем и транзакцию.
Во-вторых, смс ушла на шлюз, но потом мы не смогли закомитить транзакцию. Приплыли, телефон получит СМС с кодом, которого нет в бд.rpiontik Автор
20.11.2019 00:27Реализация, которую я изложил относительно типовая. Сначала создается какой-то юзер. Но находится в состоянии «draft». Пока не пройдет его активация через SMS. Обогащение, как я понимаю, вопросов не вызывает? Остановимся на SMS. Алгоритм такой:
1. Я открываю транзакцию в СУБД
2. Инсертю секрет
3. Дергаю SMS шлюз
4. Если все удалось, комичу, если нет, ролбэчу и падаю с ошибкой 503.
Управление ушло на другую ноду.
Вы хотите сказать, что в боевом сервисе все будет не так работать? Ну так да. Дергать напрямую из бэка никто не будет гейт. Для этого SMS поставят в очередь в каконить RabbitMQ. И она уйдет когда будет возможность. Не забывайте, что цель статьи наглядность. Если я начну тут расписывать все тонкости реальных инфраструктур… основная мысль будет утеряна. Упрощение допустимое «зло» в этом случае.pankraty
20.11.2019 06:01+1В данном случае упрощение искажает картину. Вы постулируете, что при невозможности отправить сообщение по причине лежащего смс шлюза транзакций отказывается, и это-де плохо. Но на деле, если сообщение ушло в очередь, транзакция будет закоммичена, а дальше это уже ответственность очереди — обеспечить, что шлюз его получит. Да и в принципе, держать открытой транзакцию, пока сторонний сервис не прочихается — обычно не самая хорошая идея.

ZaEzzz
20.11.2019 07:41Упрощение автора не искажает общую картину.
Представте, что у вас кролик на той ноде слег и вы не можете отправить сообщение в очередь…pankraty
20.11.2019 07:59+1Чтобы продолжать функционировать в случае неработающей очереди, при этом сохранив гарантию отправки сообщения, существует паттерн guaranteed delivery (https://www.enterpriseintegrationpatterns.com/patterns/messaging/GuaranteedMessaging.html).
Отправляющая сторона хранит у себя сообщения до тех пор, пока очередь не примет его. Сохранение сообщения происходит в той же транзакции, что и сохранение данных, поэтому если сохранение произошло, то сообщение уже не потеряется (разве что "протухнет"). Отметка о прочтении проставится, когда очередь заработает, и теоретически может получиться, что очередь сообщение приняла и отправила сообщение, но не смогла закоммитить транзакцию с отметкой о прочтении — так что сообщение отправится более одного раза.
Суть моего возражения в том, что негоже беку возвращать 503 и откатывать всю транзакцию, если при сохранении информации о пользователе смс шлюз был недоступен, в расчете на то, что
мы вновь попытаемся выполнить через какой-то интервал времени (Какой? Решает фронт?)
ZaEzzz
20.11.2019 08:36Если не отходить далео от темы, то какая разница что там вдруг отказало? Очередь, шлюз или еще что. Суть в другом — что-то в батч операции пошло не так и это может откатить всю транзакцию.
К примеру написли так, что в этой же транзакции загружается аватар пользователя, а он не смог, потому что «нет космоса слева».pankraty
20.11.2019 08:42Так в этом и суть транзакции, чтобы откатить все сразу, если что-то отказало. Если это не требуется, то не надо исполнять логику в виде транзакции — и тогда какая разница, это один батч, некоторые части которого отказали, или несколько REST-запросов, некоторые из которых отказали?
При этом зеркальный вариант — когда транзакция все-таки необходима — несколькими REST-запросами реализовать затруднительно. И это тоже надо учитывать, выбирая между REST и RPC.ZaEzzz
20.11.2019 09:09На самом деле я противник того, чтобы уходить в одну крайность.
Надо RPC? Легко, только не нужно отказываться от фич HTTP. Нужен REST? Так же легко, только на надо упарываться с запросами на каждый чих когда можно сделать пачку.

maxim_ge
20.11.2019 10:20Сохранение сообщения происходит в той же транзакции, что и сохранение данных, поэтому если сохранение произошло, то сообщение уже не потеряется (разве что «протухнет»).
С этим могут быть проблемы, если очередь хранится в «кролике» или «кафке» а данные хранятся в postgress/cassandra/ydb/…pankraty
20.11.2019 10:27Не имеет значения, в какой СУБД хранятся данные, если она поддерживает транзакции. Вот тут вариант реализации расписан более детально (http://www.kamilgrzybek.com/design/the-outbox-pattern/). Но мы все дальше уходим в оффтопик.

defuz
20.11.2019 18:04+1Транзакции в БД придумали для того чтобы гарантировать атомарность изменений данных в БД. Ваша идея держать транзакцию открытой пока вы ходите в SMS шлюз так себе решение.
Во-первых, некоторые БД при некоторых уровнях изоляции чувствуют себя не очень хорошо при большом количестве открытых транзакций. Поход на удаленный SMS шлюз – слишком долго, чтобы все это время держать транзакцию открытой.
Во-вторых, если же у вас слабый уровень изоляции, это означает что вы успешно дернете шлюз, но не выполните корректную запись секрета в БД из-за конфликтующих строк, что на мой взгляд еще худшее зло.
В-третьих, вы все равно не можете гарантировать 100% достижение результата: даже если SMS шлюз корректно ответил, пользователь все еще может не получить SMS по ряду причин.
В-четвертых, получение пользователем SMS – идемпотентная операция, а потому ничего страшного не произойдет, если секрет в БД вы добавите, а SMS пользователь не получит, или получит дважды.
По-этому нужно коммитить секрет еще до запроса в шлюз, и только после этого отправлять SMS. Если шлюз вернул ошибку – дергать еще раз, на усмотрение бекенда. И в любом случае предусмотреть дергание шлюза еще раз по запросу пользователя, но не раньше чем через время, определенное в БД рядом с секретом и не больше чем то количество раз, которое предусмотрено конфигурацией.

sergeyfast
20.11.2019 00:28Не знаю, откуда у вас взялись такие тезисы, но давайте разберем.
RPC запросы быстрее и эффективнее, потому, что позволяют делать batch-запросы.
Кол-во batch запросов всегда ограничивается в рамках разумного, например не больше 5.
На схеме у вас master-master репликация? Или вы будете роутить только GET запросы на реплику со всеми известными последствиями.
Использование кеша: на уровне сервера приложений (но в PHP у вас его нет по умолчанию), тут можно отдельную статью писать.
RPC запросы надежнее, потому, что могут выполнять batch-запросы в рамках одной транзакции
В документации написано, что batch запросы могут исполнятся параллельно. Поэтому с транзакциями тут вообще нет никакой связи.
The Server MAY process a batch rpc call as a set of concurrent tasks, processing them in any order and with any width of parallelism.
Весь смысл в batch-запросах: запустить их выполнение параллельно на сервере и сделать это в одном HTTP запросе, если возможно.
А смысл в RPC: это проектирование API. Даже gRPC пытаются сделать grpc-gateway, чтобы на бэкенде использовать gRPC, а фронтенд там как-нибудь сам справится.rpiontik Автор
20.11.2019 00:38Не скрою, ждал этого поста :))) Вопросы правильные.
Кол-во batch запросов всегда ограничивается в рамках разумного, например не больше 5.
Какой тогда смысл в этом? Какие-то условности. В протоколе есть ограничения?
В документации написано, что batch запросы могут исполнятся параллельно.
Я сразу указал, что пишу о стереотипах, которые слышу от коллег по «цеху». То, что в документации есть иное — очевидно. Как и то, что в документации по HTTP все написано. Но… не все читают. Тем более, что «может» и «нужно» неравнозначны. Все как всегда зависит от конкретной реализации. Но если вы предлагаете получать batch, парсить его и раскидывать внутри по нодам, а потом собирать в кучу… так по мне это дикий оверхед. Все уже придумано, это REST.
А смысл в RPC: это проектирование API.
Ну такой себе аргумент. Все же мы в проектирование API и на REST трудностей не испытываем. OpenAPI/Swagger в помощь.sergeyfast
20.11.2019 00:55Смысл в том, что когда у пользователя есть 5 различных сущностей (например, получить профиль, последние сообщения, счетчик новых откликов и т.д.), то проще упаковать это в batch, чем делать 5 HTTP запросов. А в этот момент на сервере они могут выполниться параллельно.
Вы можете мне возразить, что будет HTTP/2, одно соединение, и там дальше запросы полетят на разные ноды/инстансы приложения. Но если мы говорим о классическом PHP-FPM (не в daemon, типа roadrunner.dev), то конечный RPS будет у вас гораздо меньше из-за оверхеда на обработку каждого запроса на PHP.
Тем более, что «может» и «нужно» неравнозначны
Поэтому половину вашей статьи можно убрать, так как она не соответствует спецификации. Может — это как с проверкой на null: Если в 99% не null, но в 1% null, то вряд ли не нужно проверять на null, иначе все упадет.
получать batch парсить его и раскидывать внутри по нодам
graphql передает привет :)
мы в проектирование API и на REST трудностей не испытываем.
Рад за вас.dzsysop
20.11.2019 01:03+1если мы говорим о классическом PHP-FPM
Вообще-то PHP далеко не единственный язык на котором можно писать RESTfull API ;-)
rpiontik Автор
20.11.2019 01:05то проще упаковать это в batch, чем делать 5 HTTP запросов
Я никогда не понимал слово «проще». Проще кому? Программисту? Инфраструктуре? Логам? Мониторингу? Выберите пожалуйста из этого списка — кому проще? Может я кого-то забыл?
А в этот момент на сервере они могут выполниться параллельно
Могут выполняться. А могут нет. Это же от вашего кода зависит? От вашего умения? А в REST они могут выполняться на разных серверах, в разных регионах мира, причем сейчас одним кодом, а через секунду другим. Или даже одновременно разными. И все параллельно. И это никак не будет зависит от вашего умения параллелить batch запросы. Т.е. ценность этого скила, скажем так, становится невысока.
Поэтому половину вашей статьи можно убрать, так как она не соответствует спецификации.
Ну уж… давайте дадим и читателям сделать свое заключение. Может не все так пессимистично?
graphql передает привет
Зачем? Он передает привет? Там своих граблей мало? У каждой технологии есть свои сферы реализации. Надеюсь, вы не нашли, что я где-то говорю, что RPC это плохо? Ведь это не так. Я даже ссылку привел на статью, которая обратное говорит. Всему свое время и место.sergeyfast
20.11.2019 01:53Тут был длинный текст, но habr его съел другой кнопкой ответить, к сожалению…
GraphQL был упомянут в контексте github.com/graphql/dataloader
По поводу проще: думайте о пользователе, которому не важно, что у вас там внутри в архитектуре, а который хочет получить результат за минимальное время. Поэтому тема взаимодействия «frontend» и «backend» на схеме вообще не раскрыта, а от этого зависит все остальное обсуждение. Кто такой фронтенд — браузер в регионах ИЛИ сервис, отдающий готовый HTML? Или и то, и другое (next.js), и еще мобильные приложения?
Network latency, время обработки ответа, легкость разработки/поддержки API, его версионирование, вот это важно. А все остальное — это уже способы достижения этих целей.
Зачем обсуждать протоколы API, если нет контекста? Берите gRPC! :)rpiontik Автор
20.11.2019 02:07Я планирую статью о gRPC, и, кстати, о том почему REST хорош (удобен) для всех, включая пользователя. И про оперативность там будет.
Но смею уже сейчас утверждать, что rpc дает профиты по производительности исключительно в тех случаях, которые рассмотрены тут в статье. Во всех остальных, он доставляет скорее боль и пораждает оверхеды.
Предлагаю отложить завершение диалога на эту публикацию.
defuz
20.11.2019 18:28А в REST они могут выполняться на разных серверах, в разных регионах мира, причем сейчас одним кодом, а через секунду другим. Или даже одновременно разными. И все параллельно.
Вы так это преподносите, как будто это что-то хорошее. Пока ваш batch запрос выполнялся на 5 разных серверах в разных регионах, пользователь обновил свои данные, а скрипт удалил половину устаревшего контента. В результате пользователь получит вместо данных набор не консистентной херни.
Зато все параллельно.
Смысл горизонтального масштабирования не в том, что размазывать один batch запрос пользователя по разным регионам. Во-первых, сам пользователь находится ближе всего как раз таки к одному конкретному региону, и во-вторых на больших масштабах не будет никакого прироста производительности, если вы балансируете каждый отдельный запрос, а не пользовательские сессии.rpiontik Автор
20.11.2019 18:30-1Вы так это преподносите, как будто это что-то хорошее.
Yep.defuz
20.11.2019 18:38Нет. Система не должна быть спроектирована сложнее, чем это необходимо для выполнения требований. Возможность выполнять любой запрос на любом сервере по отдельности – сомнительное требование. Достоинства такого подхода не показаны, зато недостатки – на лицо.
Запросы должны идти в разные регионы если это нужно, а не потому что так можно. Никто не мешает сделать два RPC запроса вместо одного.rpiontik Автор
20.11.2019 18:45Система должна быть спроектирована хорошо.
Никто не мешает сделать два RPC запроса вместо одного.
Здравый смысл мешает. Это создание дополнительных требований к протоколу. И попытка получить от RPC несвойтсвенное ему поведение. Конечно, никто это запретить делать не может. Но для этого уже есть REST. Протокол JSON-RPC не ограничивает число запросов в batch. На том и стоим. Ручное ограничение это уже не JSON-RPC.defuz
20.11.2019 19:21«Хорошо» – это никудышняя формулировка требований к дизайну.
Здравый смысл мешает.
Чем именно вам мешает здравый смысл не пытаться батчить два запроса на разные домены?
Это создание дополнительных требований к протоколу. И попытка получить от RPC несвойтсвенное ему поведение. Конечно, никто это запретить делать не может. Но для этого уже есть REST. Протокол JSON-RPC не ограничивает число запросов в batch. На том и стоим. Ручное ограничение это уже не JSON-RPC.
Никаких дополнительных требований к протоколу как раз не возникает – есть некоторый набор атомарных запросов, каждый из которых должен вернуть консистентный результат, но не гарантировать консистентность между собой (если иное не оговорено явно).
Зато у вас могут возникнуть охренеть какие дополнительные требования к реализации, если вы постулируете что каждый отдельный запрос к данным может выполниться в любой последовательности, на любых серверах и в любое время.
Я не против ни RPC, ни REST. Но мой опыт говорит как раз о том, что необходимо объединять несколько запросов к данным в один атомарный запрос, чтобы обеспечить консистентность возвращаемого результат. Вы же постулируете как большое достоинство совершенно обратный принцип.
apapacy
20.11.2019 02:21Хорошая статья и хорошая тема. Кстати в последнее время уже не поднимает холивара.
Но некоторые моменты вызывают у меня вопросы в статье.
На приведенной схеме эта мощь реализуется через метод запроса — GET.
У HTTP методов, помимо прочего, есть стратегии кеширования. Познакомиться с ними можно в документации на HTTP. Для RPC используются POST запросы, которые не считаются идемпотентнымиЭто не так. Спецификация JSON-RPC не определяет не только метод но и даже транспортный протокол. Хотите в качестве транспорта использовать http-POST — пожалуйста, http-GET — никто не запрещает главное в количество символов URL уложиться. А еще можно на вебсокетах, или AMQP, MQTT и т.п.
Хотите реализовать правила кэширования — все же реализуемо. Можно кэшировать как на клиенте так и на любом из серверов. Выражаясь Вашими словами все в руках свободного художника.
Развитая инфраструктура включает в себя CDN. Часто он же решает вопрос противодействия DDoS и DoS атакам… Тут для RPC все становится совсем плачевно. RPC просто не в состоянии делегировать работу с нагрузкой CDN. Остается надеяться только на системы противодействия атакам.
CDN это совсем другая песня. Это же контент, статика (медиа, ассетики и т.п.) к удаленному вызову процедур вообще прямого отношения не имеют.
RPC запросы надежнее, потому, что могут выполнять batch-запросы в рамках одной транзакции (далее Вы показываете что это не так)
batch-запросы используют немного не для этого. Просто некоторые считают что при одном запросе будет легче структурировать приложение на фронтэнде. Эту же фичу предлагает graphql, но поскольку ни graphql, ни json-rpc широко не используются этот момент остается под вопросом.
Сами по себе транзакции внутри одной базы данных имеют смысл только если вся транзакция выполнятся единым обращением к базе данных (несколько операторов но обращение одно). Если действительно из нескольких батч-процедур вызывать пред началом bеgin, потом несколкьо обращений в базу данных и в заключении commit — то это так называемая https://en.wikipedia.org/wiki/Long-lived_transaction. Это плохо. Так никто не делает. Хотя к сожалению некоторые библиотеки на этом построены (например orm sequelize для node.js)
Порог входа в REST ниже
Я думаю, что выше проведенный анализ, развенчивающий устоявшиеся стереотипы о RPC наглядно показал, что порог входа в REST несомненно выше, чем в RPCСложно говорить о пороге вхожднеия в RPC поскольку в реальной практике в него малок кто входит. Также сложно говорить о стереотипах RPC, поскольку большинству разработчиков он не интересен и поэтому не известен.
Ну и накоенец, почему я пишу на REST. Потому что есть готовые специалисты и готовые средства для разработки. Повизавшись на любую другую технологию я просто рискую растерять всех сотрудников на проекте. Когда у меня появляются проекты где я делаю и фронт и бэк я пытаюсь сделать что-то что мне больше по душе. Например https://habr.com/ru/post/459978/ на веб-сокетах + socket.io
rpiontik Автор
20.11.2019 09:19-1Начну с конца.
Сложно говорить о пороге вхожднеия в RPC поскольку в реальной практике в него малок кто входит. Также сложно говорить о стереотипах RPC, поскольку большинству разработчиков он не интересен и поэтому не известен.
Вам, видимо, сильно везет. Я пишу статьи на Хабр потому, что в своей работе постоянно встречаюсь с необходимостью обсуждать с коллегами технологический стек, который мы будем использовать. Мы даже внедрили специальный документ — порядок принятие ключевых решений. Он требует проведение предварительного анализа любого элемента стека перед внедрением. Так вот… примерно в 70% случаев начинается диалог со слов — а давайте завезем RPC. Или — а давайте завезем GraphQL. Или gRPC.
Эта статья, по сути, часть такого анализа. Я решил, что писать сухой внутренний документ не единственный верный путь. Уверен, она мне еще не раз пригодится.
batch-запросы используют немного не для этого. Просто некоторые считают что при одном запросе будет легче структурировать приложение на фронтэнде. Эту же фичу предлагает graphql, но поскольку ни graphql, ни json-rpc широко не используются этот момент остается под вопросом.
Опять же вам реально «везет». У меня независимые коллеги только и делают, что хвастаются как они завезли GraphQL. Подчеркиваю, это не плохо, плохо то, что я часто на слышу аргументации этому.
CDN это совсем другая песня. Это же контент, статика (медиа, ассетики и т.п.) к удаленному вызову процедур вообще прямого отношения не имеют.
Вопрос CDN был поднят как средство кэширования. С этим прекрасно справляется, например CloudFlare. Для RPC он не имеет смысла в этом вопросе.
Это не так. Спецификация JSON-RPC не определяет не только метод но и даже транспортный протокол. Хотите в качестве транспорта использовать http-POST — пожалуйста, http-GET — никто не запрещает главное в количество символов URL уложиться. А еще можно на вебсокетах, или AMQP, MQTT и т.п.
Вынужден с вами согласиться. Более того, всячески поддержать — для RPC HTTP просто транспорт. И в целом, действительно можно использовать любой метод из предложенных. Но используется POST потому, что… в GET метод можно напихать и процедуры модификации и процедуры получения данных. При этом, такой запрос перестанет считаться идемпотентным. Высока вероятность, что очередной запрос просто не дойдет до сервера, потому, что будет закеширован.
Можно рассмотреть вариант, что вы начнете на фронте батчи паковать исходя из того, что это за процедура… но как я и раньше писал, это начинается дикий оверхед. А во-вторых, весь профит протокола с его прозрачностью резко сойдет на нет.
Я еще могу заметить, что GET метод, где параметры будут PRC уже будет сильно смахивать на URI… Т.ч. все же POST.
Что же касается синхронных транспортов (типа WEBSocket), то PRC прям хорошо ложится. Как пример, мы сейчас пилим шину на WEBSocket именно с RPC вызовами.
Хорошая статья и хорошая тема. Кстати в последнее время уже не поднимает холивара.
Спасибо! Статья не ради холивара. Этого добра хватает и без нее :)

trawl
20.11.2019 08:33+1Речь идет о том, что в RPC можно в одном запросе выполнить вызов сразу нескольких процедур. Например, создать пользователя, добавить ему аватар и в том же запросе подписать его на какие-то топики. Всего один запрос, а сколько пользы!
Вообще, именно этот кейс прокрутить нельзя.
JSON-RPC сервер не обязан обрабатывать запросы в указанном порядке. Он может сам выбирать порядок их обработки. Он может даже выполнять их асинхронно, если умеет.
То есть сервер может начать добавлять аватар ещё до того, как завершится создание пользователя...rpiontik Автор
20.11.2019 08:53Можно. Для этого достаточно использовать uuid как идентефикатор пользователя. uuid сгенерируется еще на клиенте. В этом случае, порядок выполнения не имеет значения. Запрос может упасть в момент валидации на любой процедуре. И либо все откатится, либо все применится.

iago
20.11.2019 14:56Пожалуйста, только не на клиенте! Не делайте нам больно
rpiontik Автор
20.11.2019 15:16У… клиент должен страдать! :)))
Из комментом, я вынес для себя то, что есть еще одна интересная тема — управление распределенным хранилищем. Думаю, стоит ее затронуть. И клиент там будет очень важной и нагруженной частью. А uuid, ключевой штукой, которая позволит клиенту частично получать сервис даже в offline.tuxi
20.11.2019 15:40+1Кто в системе главный — тот и «папа». Если это например какая-нибудь большая учетная система, со своими тараканами, то и UUID будем делать тот, который она требует. Вплоть до того, что только она и имеет право его сгенерить и ее придется сначала спросить. Были и такие кейсы.
rpiontik Автор
20.11.2019 16:10Не… GUID делался как раз для того, чтобы любой мог его генерировать и использовать без синхронизации с другим (не спрашивая). А UUID это конкретная реализация класса GUID.
Это крайне важная составляющая распределенных хранилищ.v2kxyz
20.11.2019 16:47Не… GUID делался как раз для того, чтобы любой мог его генерировать и использовать без синхронизации с другим (не спрашивая)
Да, но обычно подразумевается, что он генерируется в доверенной среде, а клиент иногда — недоверенная и вообще враждебная.rpiontik Автор
20.11.2019 16:56В целом да. Но атака UUID такая себе штука. Вся проблема заключается в том, что самое плохое, что может возникнуть — коллизия. А этот контроль, в любом случае, осуществляется на «принимающей стороне».
Придумать «плохой» UUID так же сложно как «хороший»;)tuxi
20.11.2019 17:51А чем тогда контроль отличается от "… вплоть до того, что только она и имеет право его сгенерить и ее придется сначала спросить"?
rpiontik Автор
20.11.2019 18:07Тем, что система доверяет, но проверяет. А не не доверяет и сама все делает.
В первом случае ты волен делать что угодно, но в конце результат будет проверен. Во втором случае, ты ничего не можешь делать пока тебе не дадут то, без чего ты не можешь начать.
v2kxyz
20.11.2019 18:18Я конечно тот еще специалист по безопасности, но тут tools.ietf.org/html/rfc4122#section-6 явно указано, что не стоит предполагать, что UUID сложно угадать. Я ни в коем случае не утверждаю, что генерировать UUID на клиенте нельзя никогда, но есть случаи, когда стоит задуматься, особенно если речь идет об авторизации/аутентификации.
rpiontik Автор
20.11.2019 18:23Получить доступ по UUID (угадать) и создать объект с UUID принципиально разные действия. Думать стоит всегда. Это точно.
v2kxyz
20.11.2019 18:37Так там на верху ветки шла речь об одном запросе, который:
1) Создает пользователя
2) На что-то его подписывает
Причем запрос вызывает именно несколько разных процедур, а не одну с кучей параметров.
Отсюда можно сделать вывод, что зная UUID пользователя, который можно угадать — его можно и подписать на что-нибудь не нужное…
rpiontik Автор
20.11.2019 18:40Создать пользователя
В этом суть. Создание роисходит с уже указанным UUID, который сгенерирован на стороне клиента. Т.е. он о нем уже знает. А не угадывает существующего пользователя.
mayorovp
20.11.2019 18:30Это как раз аргумент в пользу клиентской генерации. Когда UUID генерируется сервером — злоумышленник ещё может "поймать" какую-то закономерность и что-то с этим сделать. Но когда идентификаторы генерируются кучей клиентов независимо — никакой закономерности просто нет.
v2kxyz
20.11.2019 19:24+1Почему закономерности нет? Алгоритм же есть и он на клиенте, его можно вызвать много раз для анализа входа-выхода. Мне кажется, что так даже проще. Но я никогда чем-то подобным не занимался, поэтому могу быть не прав — и мне интересно в чем.
tuxi
20.11.2019 19:38+1Один из этапов взлома — выяснение алгоритма. В случае генерации на клиенте, мы просто дарим алгоритм «бэзвазмэздно» (с) Сова из Винни-Пуха
mayorovp
20.11.2019 21:26+1Потому что у каждого клиента свой ГСЧ с независимым внутренним состоянием.
defuz
20.11.2019 18:16Для этого достаточно использовать uuid как идентефикатор пользователя. uuid сгенерируется еще на клиенте. В этом случае, порядок выполнения не имеет значения.
Отличный план.
Как гарантировать что клиент не подставил в качестве ID значение своего соседа?rpiontik Автор
20.11.2019 18:24+1Ключ в БД? И если будет коллизия, транзакция откатится. А если нет — проблемы соседа, что он не был первым.
defuz
20.11.2019 18:35Чем тогда UUID отличается от любого другого уникального пользовательского идентификатора (username, phone, email)? По-моему достоинств никаких, только добавится лишний шаг на конвертацию из логина в uuid на этапе авторизации.
Если же мы говорим о каких-либо объектах, не являющихся пользователями, тогда у нас наверняка будет необходимость авторизовывать запросы по UUID. А как их авторизовывать, если запись о самом объекте возникнуть позже, чем нужно будет произвести запись дополнительной информации по этому объекту?rpiontik Автор
20.11.2019 18:38-1Тем, что UUID формализванный стандарт придуманный умными людьми для таких целей и хранится в СУБД под отдельным типом. Что сильно помогает.
defuz
20.11.2019 19:03UUID не придумывался для того чтобы генерировать ключи на стороне пользователя.
UUID – это просто 128 битное число, и стандарт в первую очередь описывает не тривиальные способы его генерации, подходящие для разных нужд. В вашем случае вы не можете гарантировать корректность генерации, по-этому это уже не совсем UUID, а просто нечто имеющее такую же размерность.
Если вам все равно нужно гарантировать уникальность человеко-запоминаемого идентификатора, использование размерности UUID теряет смысл. Если проверки на уникальность человеко-запоминаемого идентификатора не избежать, можно вполне обойтись 64 или даже 32 битным ключем, генерируемым последовательно, что позволит сэкономить в 2 или 4 раза на размере ключа.
Единственный оправданный способ использовать UUID – их назначение пользователям на стороне серверов, если необходимо избежать синхронизации в процессе раздачи числовых идентификаторов. Но это уже совсем другая история.rpiontik Автор
20.11.2019 19:05Думаю, для этого его и делали
Основное назначение UUID — это позволить распределённым системам уникально идентифицировать информацию без центра координации. Таким образом, любой может создать UUID и использовать его для идентификации чего-либо с приемлемым уровнем уверенности, что данный идентификатор непреднамеренно никогда не будет использован для чего-то ещё.
Остальное решается простым правилом — доверяй, но проверяй. Валидация на сервере решит эту проблему при синхронизации с клиентом.
trawl
22.11.2019 19:53Окей. Клиент сгенерил уже существующий uuid. Первый запрос возвращает ошибку конфликта, последующие обновляют существующего пользователя.
rpiontik Автор
22.11.2019 21:56Ok… Забьем на авторизацию… и то, что batch выполняется в транзакции… и или все или ничего.
И какой он? Первый. Напишите тут плз его uuid.

HPro
20.11.2019 11:22Ох и на тяжёлые дебаты вы подписались)
Все подходы по своему хороши. Мне вот нравится юзать RPC в вебсокетах.
Имхо, кэширование данных (изменяемых!) на клиенте — сомнительное решение. А кэширование на редисе во многом можно заменить кэшированием на вебсервере, который прекрасно кэширует POST запросы.
rpiontik Автор
20.11.2019 11:29Дебаты обычные :) Я бы так сказал. Это не первый мой заход на тему REST. В прошлый раз разговор был о кодах ответа. Кирпичей тоже было знатно накладено. Ниче… Это всем полезно. Это развивает критическую точку зрения.
Кеширование это отдельный, очень важный и один из самых сложных слоев архитектуры системы. Который часто просто отбрасывается потому, что не удается с ним справится. Но это не повод его не использовать. Это повод изучать средства управления кэшем.
На WEBSocket мы также завозим RPC ;)
CheY
20.11.2019 12:01Речь идет о том, что в RPC можно в одном запросе выполнить вызов сразу нескольких процедур. Например, создать пользователя, добавить ему аватар и в том же запросе подписать его на какие-то топики. Всего один запрос, а сколько пользы!
Действительно, если у вас будет всего одна нода backend, это будет казаться быстрее при batch-запросе. Потому, что три REST запроса потребуют в три раза больше ресурсов от одной ноды на установку соединений.
Вот в этом тезисе, от которого строятся дальнейшие размышления (которые вообще верные), видится небольшая манипуляция. REST не для вызова процедур, но его мерят этой линейкой. Если отталкиваться от этого примера, то если в сервисе есть кейс, где нужно «создать пользователя, установить аватарку, подписать его на что-то», то нужно задуматься о возможности в момент создания пользователя сразу передать все требуемые данные. По сути это Resource Expansion работающий для создания ресурса. Как экстремальное развитие идеи Resource Expansion можно рассматривать GraphQL. Вы же не сравниваете RPC с GraphQL по линейке количества вызовов процедур?apapacy
20.11.2019 12:31Под вызовом нескольких процедур одним запросом обычно подразумевается немного другой случай. Когда на сервере реализовано api из N процедур и заранее неизвестно в каком сочетании из будет вызывать фронтенд. Например если это Хабр то при переходе на страницу со статьей возможно на фронтенде удобно будет получить список топ "что сейчас обсуждают" или "самое читаемое". Это отдается на откуп фронтенду.
Что касается REST и манипуляций это с Вами соглашусь. В процессе разных дискуссий REST понимается то в узком смысле (REST-API/RESTFull-API) то как REST в самом общем смысле как это было описано в диссертации Roy Fielding как обоснование уже давно на тот момент используемого протокола http

3draven
20.11.2019 14:58Интересная статья, подумаю в одном месте заюзать РПЦ, там как раз надо просто подергивать метод, передавая sql и параметры его. Джейсонрпц для этого в самый раз.
А рэст это не просто хттп и он "передача состояния"… это вообще не рпц.



EvgeniiR
20.11.2019 22:59Т.е. REST это не протокол, а концепция… у REST нет стандарта, есть некоторые рекомендации…
REST это архитектурный стиль описанный Роем Филдингом 20 лет назад как попытка стандартизировать тот ещё молодой WEB, где гипертекст и браузеры только развивались.
У него есть 7 конкретных ограничений из которых 6 обязательных.
Советую хотя бы посмотреть маленькое интервью с ним — youtube. В нём он как раз описал причины появления REST.
Оригинальная публикация в которой был введён термин — тут
То что вы называете REST это всё тот же RPC поверх http. http verbs, resource — это все уровень http и описано в rfc по http(rfc7231), это не про REST, и вы не найдёте этого в оригинальном описании REST. Зато найдёте такую вот строчку:Глава 5.2 диссертацииREST ignores the details of component
implementation and protocol syntax in order to focus on the roles of components, the
constraints upon their interaction with other components, and their interpretation of
significant data elements.rpiontik Автор
20.11.2019 23:21-1У меня один вопрос — вы сами то требования читали? Что из требований изложенных в REST нарушено в статье?
Советую хорошо все перепроверить перед ответом.EvgeniiR
20.11.2019 23:30Что из требований изложенных в REST нарушено в статье?
Один из важнейших принципов — Unified Interface, и HATEOAS(Hypertext as the engine of application state) в частности, как минимум. Это не про случай когда клиент с сервером структурками данных общается.
Вы просто сравниваете несравнимое. И цель REST — никак не в производительности.
Обратите внимание, что первый запрос в случае с REST должен вернуть идентификатор пользователя
Архитектурный стиль сам по себе ничего не возвращает)
А сервер в REST-архитектуре должен возвращать гипертекст, клиент не должен полагаться на конкретные струтуры данных.
И переходы состояния на клиенте контроллируются сервером через гипертекст, клиент сам не знает куда ему делать запросы.rpiontik Автор
20.11.2019 23:39-1А что из них вообще присутствует?)
А что нет?
А сервер в REST-архитектуре должен возвращать гипертекст, клиент не должен полагаться на конкретные струтуры данных.
Идентификатор пользователя в парадигме REST это URI на пользователя. По которому, затем выполняются методы обогащения.
Мне кажется, что вы все же не подумали перед ответом. Жаль.

arthuriantech
20.11.2019 23:50+1Все, что нужно знать о REST — он неотличим от HTTP.
Как это вообще понимать? Архитектурный стиль REST развивался параллельно с HTTP для того, чтобы выделить принципы, которые закладывались в основу HTTP. Это разные понятия.
Вдобавок, сам Филдинг пишет так:
A REST API should not contain any changes to the communication protocols aside from filling-out or fixing the details of underspecified bits of standard protocols, such as HTTP’s PATCH method or Link header field. Workarounds for broken implementations (such as those browsers stupid enough to believe that HTML defines HTTP’s method set) should be defined separately, or at least in appendices, with an expectation that the workaround will eventually be obsolete. [Failure here implies that the resource interfaces are object-specific, not generic.]
https://roy.gbiv.com/untangled/2008/rest-apis-must-be-hypertext-drivenrpiontik Автор
20.11.2019 23:54-1Я написал ровно то, что написал. Не ищите в этом больше. Отличить REST от простого HTTP запроса невозможно. Не зная, что это REST запрос. Это позволяет смотреть на REST проще, не загоняясь во все эти казуистические дебри — кто, что сказал в каком году про REST. А рассматривать мощь REST ввиду полного использования им «магии» HTTP.
arthuriantech
21.11.2019 00:01+1Рой Филдинг является автором REST и соавтором HTTP. Это не "кто-то там", а авторитетный первоисточник по этому вопросу. Главный документ по REST уже написан, вам лишь нужно правильно ссылаться на него.
rpiontik Автор
21.11.2019 00:03-1Спасибо. Теперь я знаю. Мой мир более не будет прежним.
arthuriantech
21.11.2019 00:12+1Не нужно воспринимать мои посты как личностный выпад. Просто ваша статья противопоставляет RPC с HTTP и не содержит вещей, специфичных для REST.
arthuriantech
21.11.2019 00:31Отличить REST от простого HTTP запроса невозможно. Не зная, что это REST запрос.
Потому что не существует такого понятия как REST-запрос, так же как не существует такой вещи, как RESTful URI.
Если я напишу приложение в рамках HTTP, широко используя его возможности и не нарушая его ограничений, это будет достаточным условием для того, чтобы назвать свое приложение RESTful?
arthuriantech
20.11.2019 23:38Обязательных ограничений пять, а шестое — код по требованию — является опциональным. А в остальном совершенно солидарен с вами. Занятно, что сам Филдинг в своей диссертации указывал на любовь на любовь компьютерной индустрии к баззвордам:
Design-by-buzzword is a common occurrence. At least some of this behavior within the software industry is due to a lack of understanding of why a given set of architectural constraints is useful.
EvgeniiR
21.11.2019 07:55Обязательных ограничений пять, а шестое — код по требованию — является опциональным
Да, спасибо за уточнение, вот это я выдал под вечер.

vp7
21.11.2019 10:29-1Отправка SMS с временным паролем прямо из frontend'а это прям эпично.
Раз надо отправлять sms, то это какой-то публичный сайт… у вас наружу висит API "отправить любой текст любому абоненту"? Да вас спаммеры за такой интерфейс расцелуют,… а коллекторы (после того, как вы проиграете суд с смс-провайдером, через которого под вашим аккаунтом разошлют сообщений на дофига денег) снимут последние штаны.
А ещё шлюз провайдера может уйти в запланированный даунтайм на несколько часов..
Отдельно хочу добавить пять копеек по поводу "кеширование на уровне HTTP" — всен хорошо до тех пор, пока вам не попадётся корпоративная прокси с настройкой на агрессивное кеширование. Тут-то и окажется, что периодически HTTP POST — лучшее решение для API.

rsvasilyev
21.11.2019 13:36+1Отличный пост, раскрывает все плюшки, которые может предоставить инфраструктура, завязанная на HTTP. Если ваше приложение может выиграть от использования таких плюшек — супер!
Несколько замечаний:
Запрос использует инфраструктуру только по одному плечу от балансировщика к backend. В то время, как REST все также проигрывает в первом запросе, но наверстывает упущенное используя всю инфраструктуру.
Да, batch-запрос прилетает и целиком выполняется на первом backend. Однако параллельный batch-запрос от следующего клиента может быть сбалансирован на другой backend. В сумме нагрузка между backend распределяется равномерно.
Следовательно, RPC не в состоянии эффективно использовать инфраструктурные кэши. Это приводит к тому, что приходится “завозить” софтовые кэши.
Если у вас преобладают статические ресурсы, или речь о CDN — отлично, инфраструктурные кэши подойдут. В оригинальном посте JSON-RPC рекомендовался, в первую очередь, для приложений, где фичи вроде HTTP-кеширования использовать невозможно.
RPC запросы надежнее, потому, что могут выполнять batch-запросы в рамках одной транзакции
Как уже обсудили выше, ни порядок, ни транзакционность выполнения запросов в batch-е никто никому не обещал. Batch-и, прежде всего, позволяют сэкономить трафик и latency для клиента.
В общем, здесь как всегда — каждой задаче свой инструмент.

yvm
gRPC
rpiontik Автор
Думал уже о нем. Отдельно, позже проведу анализ. Протокол заслуживает отдельного внимания.
Denisss025
Будете делать анализ, сравните его ещё с Twirp. Не просто же так в Twitch сделали это ответвление от gRPC.
bat
смысл их сравнивать с рестом, их и прочие rpc-протоколы надо сравнивать между собой