
Мультиплексирование шины данных дисплея с параллельным выводом и последовательного порта Ардуино.
Статья описывает способ мультиплексного использования порта D микропроцессора ATMEL 328P (Ардуино НАНО) с целью обеспечения попеременного побайтного вывода в дисплей и обмена по последовательному каналу.
Собрал я как-то прибор для контроля уровня угарного газа (СО) из ненужных элементов – дисплей от Нокии N95, Ардуино НАНО с несправными портами (D3 и D11, пробиты в результате неудачного замыкания на +400 вольт при отладке генератора высокого напряжения), платы воспроизведения звуковых фрагментов и датчика на угарный газ MQ7. Все эти детали в той или иной степени были неисправны (кроме датчика) и никакого применения в других проектах найти не могли. Как ни странно, оказалось, что прибор очень полезен при использовании печки на даче. Лето 2019 года выдалось нежарким и печку я топил практически каждый день в течении пары недель в июле, соединяя приятное (медитирование на пламя) с полезным (утилизацией попиленных мусорных деревьев). Контролировать режимы горения оказалось очень легко, все манипуляции с заслонками сразу отражались на показаниях прибора, что позволяло управлять печкой разумно. Прибор в этой статье не описывается, в интернете таких устройств предостаточно на любой вкус. Отличительной особенностью моего прибора является функция постоянного контроля исправности датчика СО на основе сравнения запомненной эталонной кривой и получаемой в реальном масштабе времени, а также высокая скорость реакции на изменение уровня СО, достигнутая сравнением запомненных на предыдущем цикле данных с текущими.
Фокус этой статьи на увеличении скорости обмена процессора и дисплея с параллельным байтовым обменом данными.
Дисплей имеет параллельный байтовый обмен и, несмотря на использование всех известных мне способов увеличения скорости обмена, вывод на него оказался довольно медленным. Основная причина – необходимость побитного вывода байта данных на разные биты разных портов, так как Ардуино Нано не имеет ни одного полноценного порта шириной в один байт. Этот режим вывода требует грубо в 8 раз больше времени по сравнению с командой записи байта в регистр. У НАНО имеется единственный полноценный порт D, но его младшие биты используются для аппаратного последовательного порта, по которому происходит загрузка скетчей в процессор и обмен скетча с хост-машиной.
Я нашел относительно простой способ использования побайтного вывода на дисплей. Способ этот заключается в попеременном использовании порта D для вывода данных на дисплей и в обмене данными по последовательному каналу.
Предлагаемый способ позволяет значительно увеличить скорость интегрального обмена с дисплеем (около 3-х раз по моим измерениям). Под словом «интегральный» имеется в виду, что измерялись суммарные времена выполнения операций отрисовки экрана на макро-уровне. Вероятно, что измерение времен на уровне атомарных операций ввода-вывода дало бы существенно больший выигрыш (в районе одного порядка).
Измерения выполнялись на специально собранном макете (см. рисунок 1) следующим способом:


Рисунок 1. Фотографии макета для отработки мультиплексирования вывода
Программы совершенно одинаковые, переключение способа вывода осуществлялось сменой имен подпрограмм SendDat и SendCom на SendDat1 и SendCom1 соответственно.
Вывод программы на встроенный сериал монитор записывался в OneNote и анализировался.

Рисунок 2. Измерение времени вывода на экран в режиме побайтного вывода
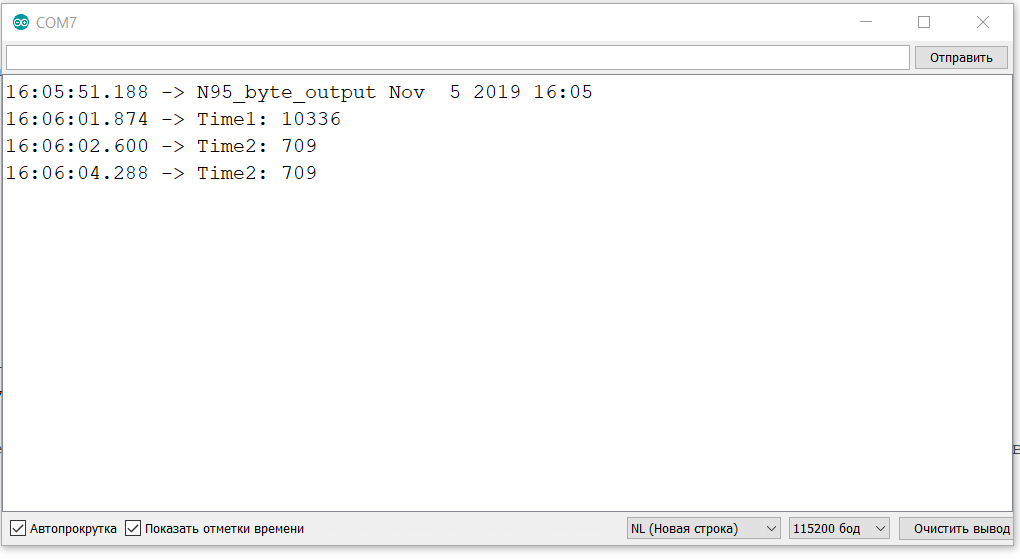
Рисунок 3. Измерение времени вывода на экран в режиме побитного вывода
Результаты измерений сведены в таблицу 1.

Таблица 1. Интегральный выигрыш в скорости обмена
Минусы предлагаемого способа заключаются в необходимости использовать дополнительные команды для переключения режимов работы с дисплеем и обмена по последовательному порту.
Также можно ожидать некоторых трудностей при приеме данных от хост-машины, прием возможен только при явном включении режима последовательного канала, что требует четкой повременной организации процессов в скетче.
Исследование мануала по процессору дало следующую информацию: включение режима последовательного порта перехватывает управление ножками D0 и D1 на аппаратном уровне. Это значит, что попытки управления ножками из скетча не дадут нужного результата.
Дальнейшее изучение вопроса показало, что, если не включать в скетче последовательный порт командой Serial.open(), то весь порт D остается в распоряжении пользователя. Можно перевести порт в режим вывода по всем ногам командой DDRD=0xFF и выводить весь байт одновременно командой PORTD=data, где переменная data содержит выводимые данные.
Перевести порт D в режим вывода достаточно один раз (в Setup). Последующие включения-выключения режима последовательного обмена не влияют на режим порта D – он так и остается в режиме параллельного вывода 8 бит. При включении режима последовательного обмена выводы D0 и D1 перейдут в режим приема и передачи соответственно. На выводе D1 появится «1» независимо от предыдущего состояния бита D1, и эта «1» будет на этом выводе все время пока включен режим последовательной передачи, кроме моментов передачи символов. При выключении режима последовательной передачи выводы D0 и D1 перейдут в состояние вывода и на них появятся сигналы из регистра вывода. Если в регистре вывода на месте D1 имеется «0», то на выводе будет сформирован отрицательный перепад, который приведет к передаче паразитного символа в последовательный канал.
Рассмотрим теперь вопрос – а не помешает ли такое использование порта D загрузке программ? При загрузке программы процессор сбрасывается импульсом, который генерируется контроллером USB порта FT232RL (либо его аналогом CH340) при выставлении сигнала DTR. Сигнал DTR переходит из 1 в 0 и отрицательный перепад через конденсатор сбрасывает процессор. После сброса процессор включает последовательный порт, запускает загрузчик и принимает код программы. Итак – нормальной загрузке скетча изменение режима работы порта D не мешает.
Если в скетче требуется вывод в сериал порт, то достаточно команды Serial.open() перед командами вывода.
Однако есть тонкость. Заключается она в том, что вход RxD микросхемы FT232RL остается присоединенным к выводу TxD и данные, идущие на дисплей, принимаются и пересылаются далее в хост-машину. Данные эти выглядят как шум, хотя на самом деле им не являются (рисунок 4).

Рисунок 4. Вид экрана в режиме побайтного вывода без блокирования
Бороться с этим ненужным сигналом можно двумя путями.
Первый путь – программный. Заключается он в том, что в скетче перед выводом используется команда Serial.println() для создания новой строки перед выводом полезной информации. Это облегчит программе в хост машине анализ входящих строк и выделение полезной информации от скетча.
Второй путь – аппаратный. Вход RxD FT232RL подсоединен к выходу TxD через резистор 1 кОм. Чтобы заблокировать передачу информации достаточно присоединить вход RxD FT232RL к «1». Сделать это проще всего одним из свободных выводов Ардуино. Я использовал вывод D8. Для выполнения этого действия я припаял к выводу 7 резистора RP1B номиналом 1 кОм проводок с разъемом на конце, проведя его через отверстия в плате с целью механической фиксации. На рисунке 5 это соединение показано красной линией, на рисунке 6 приведена фотография места пайки.
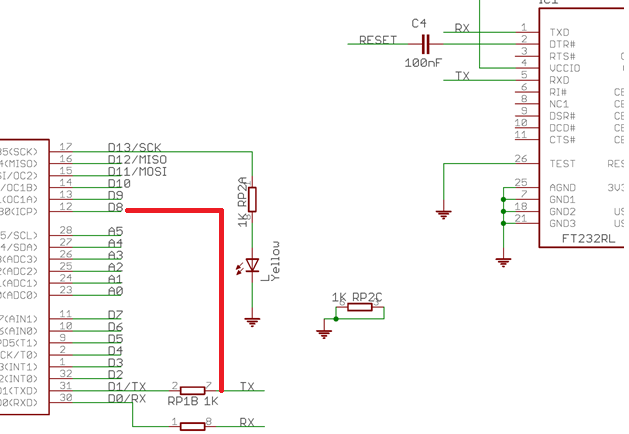
Рисунок 5. Часть схемы Ардуино нано

Рисунок 6. Место пайки дополнительного провода в Ардуино НАНО
Механизм этот работает так: после сброса ножка D8 находится в режиме высокоимпедансного входа и штатной работе механизма загрузки программ в плату Ардуино не мешает.
Когда в скетче надо начать управлять дисплеем, то вывод D8 переводится в режим активного вывода, на нем выставляется «1» (это блокирует передачу данных от вывода TxD Atmel328P на вывод RxD FT232RL) и после этого выполняется команда Serial.end();. Порядок действий важен, так как после выключения режима последовательной передачи на выводе TxD появится бит D1, который сохранился в выходном регистре порта D от предыдущей записи байта в этот порт. Если бит D1 был «0», то при выключении режима последовательной передачи ножка процессора переключится из «1» в «0» и это породит передачу паразитного символа по последовательному каналу.
В процессе отладки также оказалось, что надо дождаться окончания передачи всего буфера в хост-машину перед блокировкой последовательного канала, иначе часть передаваемых данных будет потеряна.
Когда в скетче требуется включить передачу данных по сериал порту, надо включить режим последовательной передачи и выключить блокировку прохождения сериал данных путем установки режима чтения на выводе D8.
Для выполнения этих задач в скетч добавлены две подпрограммы:
Полностью тестовую программу можно взять тут.
Статья описывает способ мультиплексного использования порта D микропроцессора ATMEL 328P (Ардуино НАНО) с целью обеспечения попеременного побайтного вывода в дисплей и обмена по последовательному каналу.
Собрал я как-то прибор для контроля уровня угарного газа (СО) из ненужных элементов – дисплей от Нокии N95, Ардуино НАНО с несправными портами (D3 и D11, пробиты в результате неудачного замыкания на +400 вольт при отладке генератора высокого напряжения), платы воспроизведения звуковых фрагментов и датчика на угарный газ MQ7. Все эти детали в той или иной степени были неисправны (кроме датчика) и никакого применения в других проектах найти не могли. Как ни странно, оказалось, что прибор очень полезен при использовании печки на даче. Лето 2019 года выдалось нежарким и печку я топил практически каждый день в течении пары недель в июле, соединяя приятное (медитирование на пламя) с полезным (утилизацией попиленных мусорных деревьев). Контролировать режимы горения оказалось очень легко, все манипуляции с заслонками сразу отражались на показаниях прибора, что позволяло управлять печкой разумно. Прибор в этой статье не описывается, в интернете таких устройств предостаточно на любой вкус. Отличительной особенностью моего прибора является функция постоянного контроля исправности датчика СО на основе сравнения запомненной эталонной кривой и получаемой в реальном масштабе времени, а также высокая скорость реакции на изменение уровня СО, достигнутая сравнением запомненных на предыдущем цикле данных с текущими.
Фокус этой статьи на увеличении скорости обмена процессора и дисплея с параллельным байтовым обменом данными.
Дисплей имеет параллельный байтовый обмен и, несмотря на использование всех известных мне способов увеличения скорости обмена, вывод на него оказался довольно медленным. Основная причина – необходимость побитного вывода байта данных на разные биты разных портов, так как Ардуино Нано не имеет ни одного полноценного порта шириной в один байт. Этот режим вывода требует грубо в 8 раз больше времени по сравнению с командой записи байта в регистр. У НАНО имеется единственный полноценный порт D, но его младшие биты используются для аппаратного последовательного порта, по которому происходит загрузка скетчей в процессор и обмен скетча с хост-машиной.
Я нашел относительно простой способ использования побайтного вывода на дисплей. Способ этот заключается в попеременном использовании порта D для вывода данных на дисплей и в обмене данными по последовательному каналу.
Предлагаемый способ позволяет значительно увеличить скорость интегрального обмена с дисплеем (около 3-х раз по моим измерениям). Под словом «интегральный» имеется в виду, что измерялись суммарные времена выполнения операций отрисовки экрана на макро-уровне. Вероятно, что измерение времен на уровне атомарных операций ввода-вывода дало бы существенно больший выигрыш (в районе одного порядка).
Измерения выполнялись на специально собранном макете (см. рисунок 1) следующим способом:
- В тестовой программе расставлялись метки времени с выводом на хост-машину.
- Дисплей присоединялся к выводам D2 — D9, загружалась тестовая программа, в которой вывод байта осуществлялся путем распределения байта по битам.
- Дисплей присоединялся к выводам D0 – D7, загружалась тестовая программа, в которой вывод байта осуществлялся командой PORTD=data.
Рисунок 1. Фотографии макета для отработки мультиплексирования вывода
Программы совершенно одинаковые, переключение способа вывода осуществлялось сменой имен подпрограмм SendDat и SendCom на SendDat1 и SendCom1 соответственно.
Вывод программы на встроенный сериал монитор записывался в OneNote и анализировался.
Рисунок 2. Измерение времени вывода на экран в режиме побайтного вывода
Рисунок 3. Измерение времени вывода на экран в режиме побитного вывода
Результаты измерений сведены в таблицу 1.
Таблица 1. Интегральный выигрыш в скорости обмена
Минусы предлагаемого способа заключаются в необходимости использовать дополнительные команды для переключения режимов работы с дисплеем и обмена по последовательному порту.
Также можно ожидать некоторых трудностей при приеме данных от хост-машины, прием возможен только при явном включении режима последовательного канала, что требует четкой повременной организации процессов в скетче.
Исследование мануала по процессору дало следующую информацию: включение режима последовательного порта перехватывает управление ножками D0 и D1 на аппаратном уровне. Это значит, что попытки управления ножками из скетча не дадут нужного результата.
Дальнейшее изучение вопроса показало, что, если не включать в скетче последовательный порт командой Serial.open(), то весь порт D остается в распоряжении пользователя. Можно перевести порт в режим вывода по всем ногам командой DDRD=0xFF и выводить весь байт одновременно командой PORTD=data, где переменная data содержит выводимые данные.
Перевести порт D в режим вывода достаточно один раз (в Setup). Последующие включения-выключения режима последовательного обмена не влияют на режим порта D – он так и остается в режиме параллельного вывода 8 бит. При включении режима последовательного обмена выводы D0 и D1 перейдут в режим приема и передачи соответственно. На выводе D1 появится «1» независимо от предыдущего состояния бита D1, и эта «1» будет на этом выводе все время пока включен режим последовательной передачи, кроме моментов передачи символов. При выключении режима последовательной передачи выводы D0 и D1 перейдут в состояние вывода и на них появятся сигналы из регистра вывода. Если в регистре вывода на месте D1 имеется «0», то на выводе будет сформирован отрицательный перепад, который приведет к передаче паразитного символа в последовательный канал.
Рассмотрим теперь вопрос – а не помешает ли такое использование порта D загрузке программ? При загрузке программы процессор сбрасывается импульсом, который генерируется контроллером USB порта FT232RL (либо его аналогом CH340) при выставлении сигнала DTR. Сигнал DTR переходит из 1 в 0 и отрицательный перепад через конденсатор сбрасывает процессор. После сброса процессор включает последовательный порт, запускает загрузчик и принимает код программы. Итак – нормальной загрузке скетча изменение режима работы порта D не мешает.
Если в скетче требуется вывод в сериал порт, то достаточно команды Serial.open() перед командами вывода.
Однако есть тонкость. Заключается она в том, что вход RxD микросхемы FT232RL остается присоединенным к выводу TxD и данные, идущие на дисплей, принимаются и пересылаются далее в хост-машину. Данные эти выглядят как шум, хотя на самом деле им не являются (рисунок 4).
Рисунок 4. Вид экрана в режиме побайтного вывода без блокирования
Бороться с этим ненужным сигналом можно двумя путями.
Первый путь – программный. Заключается он в том, что в скетче перед выводом используется команда Serial.println() для создания новой строки перед выводом полезной информации. Это облегчит программе в хост машине анализ входящих строк и выделение полезной информации от скетча.
Второй путь – аппаратный. Вход RxD FT232RL подсоединен к выходу TxD через резистор 1 кОм. Чтобы заблокировать передачу информации достаточно присоединить вход RxD FT232RL к «1». Сделать это проще всего одним из свободных выводов Ардуино. Я использовал вывод D8. Для выполнения этого действия я припаял к выводу 7 резистора RP1B номиналом 1 кОм проводок с разъемом на конце, проведя его через отверстия в плате с целью механической фиксации. На рисунке 5 это соединение показано красной линией, на рисунке 6 приведена фотография места пайки.
Рисунок 5. Часть схемы Ардуино нано
Рисунок 6. Место пайки дополнительного провода в Ардуино НАНО
Механизм этот работает так: после сброса ножка D8 находится в режиме высокоимпедансного входа и штатной работе механизма загрузки программ в плату Ардуино не мешает.
Когда в скетче надо начать управлять дисплеем, то вывод D8 переводится в режим активного вывода, на нем выставляется «1» (это блокирует передачу данных от вывода TxD Atmel328P на вывод RxD FT232RL) и после этого выполняется команда Serial.end();. Порядок действий важен, так как после выключения режима последовательной передачи на выводе TxD появится бит D1, который сохранился в выходном регистре порта D от предыдущей записи байта в этот порт. Если бит D1 был «0», то при выключении режима последовательной передачи ножка процессора переключится из «1» в «0» и это породит передачу паразитного символа по последовательному каналу.
В процессе отладки также оказалось, что надо дождаться окончания передачи всего буфера в хост-машину перед блокировкой последовательного канала, иначе часть передаваемых данных будет потеряна.
Когда в скетче требуется включить передачу данных по сериал порту, надо включить режим последовательной передачи и выключить блокировку прохождения сериал данных путем установки режима чтения на выводе D8.
Для выполнения этих задач в скетч добавлены две подпрограммы:
void s_begin()
{
Serial.begin(115200); // Включаем управление выводом TxD от модуля USART. Нога TxD переходит в "1", нога RxD становится входом
pinMode(8, INPUT); // Отключаем подтяжку входа RxD FT232RL к "1", разрешая прохождение сериал данных на вход RxD FT232RL
}
void s_end()
{
Serial.flush(); //Ждем конца передачи
pinMode(8, OUTPUT); //Подтягиваем вход FT232RL к "1" отключая передачу данных пока идет управление дисплеем. Без этого
D8_High; //будут передаваться паразитные данные
Serial.end(); // закрываем сериал канал. В этот момент на ноги TxD и RxD начинают выводится биты D0(RxD) и D1(TxD) порта D
}
Полностью тестовую программу можно взять тут.
Alyoshka1976
Если Вы выводили в побитном режиме посредством digitalWrite, то конечно, функция весьма медленная из-за множества всяких проверок (да и с режимом обработки прерываний она вольно обращается :-)
Если точно знать, что делать, то можно вот так оформить побитный вывод, который займет считанные машинные циклы (в проекте "нанокомпьютера", откуда этот отрывок, мне была важна именна неприкосновенность прерываний):
Winnie_The_Pooh Автор
Я использовал макроподстановки типа #define D0_High PORTD |=B00000001, которые делают то же самое, что и предложенный Вами способ.
Alyoshka1976
Нет, не совсем тоже самое.
PORTD |=B00000001 эквивалентно PORTD = PORTD | B00000001, т.е. требуется дополнительная операция.
Это можно проверить, отключив через platform.txt оптимизацию кода:
запись в порт с учетом его состояния
Скетч использует 514 байт (1%) памяти устройства
прямая запись в порт
Скетч использует 506 байт (1%) памяти устройства
А sbi и cbi меняют конкретные биты порта, совсем не трогая остальные.
Winnie_The_Pooh Автор
Не буду спорить :) в любом случае параллельный вывод 1 байта быстрее 8-ми выводов бита с логическими операциями определения какой бит надо выставить.
Serge78rus
Команда PORTD |=B00000001 и будет оттранслирована компилятором в SBI, а PORTD |= 0x58 нет, так как затрагивает более одного бита. Во всяком случае, это точно работает с компилятором GCC, но в Arduino, вроде, он и используется.
Alyoshka1976
Спасибо, интересно посмотреть, как g++ будет вести себя в этом случае в различных режимах оптимизации.
Serge78rus
Ну, если интересно, то смотрите (правда я пользовался не g++, а gcc, но думаю в данном случае без разницы). Исходный код:
Вообще без оптимизации (O0):
С любой включенной опцией оптимизации (O1, O2, O3, Os) получается одно и то же:
Alyoshka1976
))))))) Мой результат на 9 минут раньше.
Serge78rus
Так мне и лет больше. Зато у меня сравнение разных режимов оптимизации, как Вы и просили, а у Вас только O0 и Os.
Я контроллерами AVR редко пользуюсь, поэтому долго искал, где же у меня лежит среда разработки для них. А ведь еще параллельно и работать приходится.
Alyoshka1976
Alyoshka1976
P.S. Оптимизатор не всегда придерживается требуемой стратегии s
(хотя конечно gnu.org дает уклончивый ответ — "except those that often increase code size" :-)
дешевле (по размеру) было бы заменить (4 байта, 4 цикла)
а не: (6 байтов, но 3 цикла)
Serge78rus
Тут может быть гораздо более неприятный момент: две интсрукции sbi атомарны (каждая по отдельности) и не чуствительны к изменению в процессе выполнения других битов регистра из какого-нибудь прерывания. Чего нельзя сказать о конструкции in — ori — out. Именно в подобных случаях и приходится периодически контролировать код, генерируемый компилятором.
Alyoshka1976
Так и есть при включенной оптимизации (результаты моей проверки):
-O0
-Os
-O0
-Os
-O0
-Os
Winnie_The_Pooh Автор
Проверил, заменил макроподстановки на прямой ассемблерный код, время цикла изменилось незначительно: вместо 213 стало 195 мС.
swa111
Как то давно для своих проектов использовал такие макросы
Работают корректно только если номера пинов и портов — константы. GCC всегда транслирует в sbi и cbi если это возможно. При этом Изменений в программе минимум. Всего то нужно использовать digitalWriteC вместо digitalWrite.
Alyoshka1976
Забавно, что SBI/CBI таки не всегда быстрее, хотя и компактнее.
GarryC
У Константина Чижова есть восхитительный шаблонный класс в его библиотеке mcucpp, который генерит минимально возможную последовательность записи данных в произвольный набор ножек.
clawham
Вот ещё один человек скоро прозреет от ардуиновых либ и окажется что все фокусы и приемы на ардуине дают 2-3 прирост а нормальный подход сразу дал бы увеличение скорости раз так в 30 не менее :)
Иногда таки полезно знать ассемблерные команды которые в один такт делают то что адруновая либа детает за примерно полторы тысячи тактов а результат то тот же.
Вы делаете по сути программную эмуляцию готовой апаратной функции а как все знают программная эмуляция всегда впринципе медленнее апаратной а тут ещё и ардуино который и в программных эмуляциях лидер по тормозам :)
Winnie_The_Pooh Автор
Поясните свою мысль: хотите ли Вы сказать, что команда PORTD=data транслируется в полторы тысячи тактов из-за ардуиновых либ? Я пока уверен, что эта команда транслируется в одну ассемблерную :)
Polaris99
А Ваша уверенность зиждется на анализе полученного в результате программного кода или на твердой уверенности в мощи ардуины?
Winnie_The_Pooh Автор
Ну раз Вы отвечаете вопросом на вопрос — и я поступлю так же: Вы конечно же проанализировали уже, во что превращается команда PORTD=data и готовы показать обществу результат своих изысканий?
Polaris99
Я пока уверен, что эта команда транслируется в одну ассемблерную
Это вопрос был? Ну тогда ок, вопросов больше нет.
Значит, Вас точно не должно смущать, что формат вывода в порт у AVR выглядит так: OUT A,Rr, где Rr — регистр, а не данные. А уж во что там сконвертит GCC в итоге — это вообще дело десятое.
Alyoshka1976
Как показала проверка, фантазии компилятору не занимать :-) — в одном случае он использует доступ к портам через общее адресное пространство (смещение на 0x20), а в другом — как к порта ввода-вывода.
clawham
digitalwrite транслируется в ту самую тыщу тактов :)
а portD=data явно не то что нужно! мы же не всем портом разом рулить хотим а только одним битом так? значить сначала надо отключить прерывания(в них ведь могут дергать порты и биты портов так?) потом считать кудато состояние порта на сейчас, потом применить битовую маску разную для установки или снятия бита, потом записать полученный байт назад в порт и снова разрешить прерывания… видите как не просто даже простое изменение бита? cbi sbi делает это все за один такт. Ещё вопросы?
Winnie_The_Pooh Автор
Вы статью читали или просто по мотивам выступаете? :)
Я рулю всем байтом разом одной командой. Статья именно об этом: как на Нано использовать весь порт D одновременно.
Так понятно?
reticular
совсем не ясно Зачем вы накладываете на себя ограничения в виде полноценного порта?
ну нет порта: -возьмите полпорта В
ну будет две команды:
PORTD=dataD & maskD;
PORTB=dataB & maskB;
зато без «огорода»
Winnie_The_Pooh Автор
Я захотел сделать байтовый вывод максимально быстро — т.е. одной командой. Вывод в два полубайта — две команды и они выполняются в два раза дольше.
GarryC
Если Вы хотели сделать вывод максимально быстро, то не следует перед выводом каждого байта подтверждать состояние управляющей ноги.
Winnie_The_Pooh Автор
Я не понял Вас. ПОясните. О какой управляющей ноге Вы пишете?
GarryC
D11_High; в SendDat()
Winnie_The_Pooh Автор
Эта нога управляет режимом Data\Command при управлении дисплеем.
Обычно за байтом команды идут несколько байт данных.
Действительно, наверно можно оптимизировать и выставлять ногу один раз.
Подумаю на досуге :)
Winnie_The_Pooh Автор
Проверил, перенес манипуляции D11 в SendCom:
3.1 раза перешло в 3.6 раза.
reticular
дада дольше на 1 микросекунду
стоит ли однамиллионная секунды того огорода что вы нагородили?
стоит ли она того времени, что вы затратили на отладку мультиплексирования?
зачем усложнять? (возможно это вызов? я например для увлекательности, при решении, понижаю себе IQ, возможно без мультиплексирования не было бы этой статьи)
Winnie_The_Pooh Автор
Это просто развлечение техногика. Исследование возможностей железки. Мне это доставляет удовольствие.
Если же подходить к вопросу с точки зрения здравого смысла, то ни использованный процессор, ни дисплей не оптимальны. Сейчас использовать Ардуино Нано практического смысла нет — его прекрасно заменяет Blue Pill на STM32F103, у которого цена меньше, размер незначительно больше, процессор существенно мощнее.
iig
Даже без эксперимента понятно, что вывод байта ассемблерным кодом будет работать быстрее, чем побитовый ногодрыг на С++ :)
Winnie_The_Pooh Автор
«Практика — критерий истины» (с) В.И.Ленин ;)
Serge78rus
Вот кто-кто, а В.И.Ленин уж лучше бы ограничился теоретическими измышлениями, а не проверял их на практике.
shadrap
Спасибо, интересно, как раз думал поэкспериментировать с таким дисплеем…
А MQ-7 не используйте для таких целей, на что он реагирует и что измеряет это большой вопрос.)) Из всей этой серии как-то приспособил MQ2 под контроль утечки баллонного газа, помог найти утечку в подводных шлангах. А для таких серьезных вещей как СО\СО2 использую Winsen-овские датчики, они конечно подороже, но хоть понятно что измеряют.
Winnie_The_Pooh Автор
Про свойства MQ7 я в курсе — некогда провел достаточно подробный цикл измерений в лаборатории газов с эталонными газами. ЕГо конечно нельзя использовать в качестве измерителя концентрации конкретного газа, но как показометр общего загрязнения — вполне можно.
Для контроля СО2 использую датчики К-30 на NDIR технологии.