

Согласно отчёту Nilson о ситуации с банковскими картами и мобильными платежами, суммарный объём потерь в результате мошенничества ещё в 2016-м достиг $22,8 млрд, что на 4,4% больше, чем в 2015-м. Это только подтверждает необходимость для банков научиться распознавать мошенничество заранее, еще до того, как оно состоялось.
Это обширная и очень сложная задача. Сегодня разработано много методик, по большей части опирающихся на такое направление Data science, как обнаружение аномалий. Таким образом, в зависимости от доступного датасета большинство из этих методик можно свести к двум основным сценариям:
- Сценарий 1: датасет содержит достаточное количество образцов мошенничества.
- Сценарий 2: в датасете нет (или ничтожно мало) образцов мошенничества.
В первом случае мы можем решать задачу обнаружения мошенничества с помощью классических методик машинного обучения или статистического анализа. Можно обучить модель или вычислить вероятности для двух классов (легитимные и мошеннические транзакции), и применять модель к новым транзакциям, чтобы определить их легитимность. В этом случае работают все алгоритмы машинного обучения с учителем, предназначенные для решения задач классификации — например, случайный лес, логистическая регрессия и т. д.
Во втором случае у нас нет примеров мошеннических транзакций, поэтому нам нужно проявить изобретательность. Поскольку у нас есть лишь образцы легитимных транзакций, нужно сделать так, чтобы этого было достаточно. Есть два вариант: рассматривать мошенничество либо как отклонение, либо как аномальное значение, и использовать соответствующий подход. В первом случае можно применять изолирующий лес, а во втором случае классическим решением является автокодировщика.
Давайте на примере реального датасета посмотрим, как можно применять разные методики. Мы реализуем их на датасете для обнаружения мошенничества, созданном Kaggle. Он содержит 284 807 транзакций с банковскими картами, выполненными европейцами в сентябре 2013-го. Для каждой транзакции представлено:
- 28 главных компонент, извлечённых из исходных данных.
- Сколько времени прошло с момента первой транзакции в датасете.
- Количество денег.
У транзакций две метки: 1 для мошеннических и 0 для легитимных (нормальных). Лишь 492 (0,2 %) транзакции в датасете являются мошенническими, этого маловато, но может хватить для какого-нибудь обучения с учителем.
Обратите внимание, что ради сохранения приватности данные содержат главные компоненты вместо исходных признаков транзакций.
Сценарий 1: машинное обучение с учителем — случайный лес
Начнём с первого сценария: предположим, что у нас есть размеченный датасет для обучения классифицирующего алгоритма машинного обучения с учителем. Мы можем следовать классической схеме проекта по анализу данных: подготовка информации, обучение модели, оценка и оптимизация, развёртывание.
Подготовка информации
Обычно сюда входят:
- Восстановление пропущенных значений, если это необходимо для нашего алгоритма.
- Выбор признаков для улучшения итоговой точности.
- Дополнительные преобразования данных ради соблюдения требований регуляторов по приватности.
В нашем случае датасет уже очищен и готов к использованию, никаких приготовлений делать не нужно.
Для всех классифицирующих алгоритмов с учителем требуется обучающий и тестовый датасеты. Мы можем разделить наш массив информации на два таких датасета. Обычно их пропорции варьируются в диапазоне от 80 % — 20 % до 60 % — 40 %. Мы разделим в соотношении 70 % и 30 %: большая часть исходных данных будет использоваться для обучения, а остаток — для проверки работы получившейся модели.
Для решения стоящей перед нами задачи классификации нам нужно удостовериться, что в обоих датасетах есть образцы обоих классов — мошеннические и легитимные транзакции. Поскольку один класс встречается гораздо реже второго, рекомендуется использовать стратифицированный отбор вместо случайного. Учитывая большой дисбаланс между двумя классами, стратифицированный отбор гарантирует, что в обоих датасетах будут представлены образцы всех классов в соответствии с их изначальным распределением.
Обучение модели
Мы можем воспользоваться любым алгоритмом с учителем. Возьмём случайный лес со 100 деревьями. Каждое дерево обучено на глубину до 10 уровней, имеет не более трёх образцов на каждый узел. Алгоритм использует прирост информации (information gain ratio) для оценки критерия разделения (split criterion).
Оценка модели: принятие информированного решения
После обучения модели нужно оценить её работу на тестовом датасете. Можно использовать классические метрики оценки, такие как чувствительность и специфичность, либо каппа-коэффициент (Cohen’s Kappa). Все измерения основаны на прогнозах, сделанных моделью. В большинстве инструментов для анализа данных модели генерируют прогнозы на основе классов с наибольшей вероятностью. В задаче бинарной классификации это эквивалентно использованию по умолчанию порога в 0,5 для вероятностей одного из классов.
Однако при обнаружении мошеннических транзакций нам может понадобиться более консервативное решение. Лучше дважды проверить легитимные транзакции и рискнуть побеспокоить клиентов потенциально бесполезным звонком, чем пропустить одну мошенническую транзакцию. Поэтому мы понижаем порог приемлемости для мошеннического класса, или повышаем этот порог для легитимного. В данном случае мы решили взять для вероятности мошеннического класса порог 0,3 и сравнили результаты с порогом по умолчанию в 0,5.
На иллюстрации 1 приведены матрицы ошибок (confusion matrix), полученные при порогах в 0,5 (слева) и 0,3 (справа). Им соответствуют каппа-коэффициенты 0,89 и 0,898, полученные на субдискретизированном датасете с одинаковым количеством легитимных и мошеннических транзакций. Как видите, снижение порога для мошеннических транзакций привело к ложной классификации нескольких легитимных транзакций, однако мы корректно определили больше мошеннических.
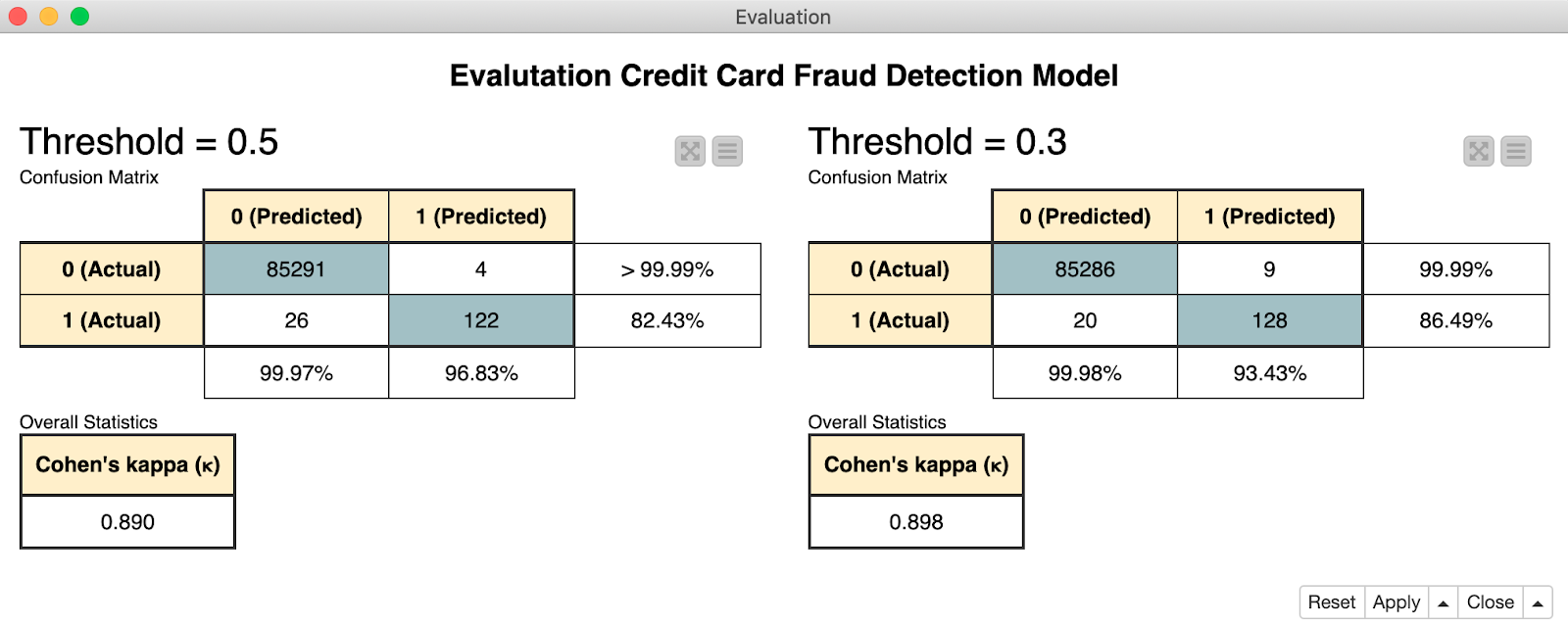
Иллюстрация 1. В матрицах ошибок class 0 соответствует легитимным транзакциям, 1 — мошенническим. При снижении порога до 0,3 мы корректно определи на 6 мошеннических транзакций больше.
Гиперпараметрическая оптимизация
Как и во всех классификационных решениях, для завершения цикла обучения можно оптимизировать параметры модели. Для случайного леса это означает поиск оптимального количества деревьев и их глубины, чтобы получить оптимальное качество классификации (D. Goldmann, "Stuck in the Nine Circles of Hell? Try Parameter Optimization and a Cup of Tea"; KNIME Blog, 2018, Hyperparameter optimization). Также можно оптимизировать порог прогнозирования.
Мы воспользовались очень простым процессом обучения всего с несколькими узлами (иллюстрация 2): считывание, разделение на обучающий и тестовый наборы, обучение случайного леса, генерирование прогноза, применение порога и оценка качества. Мы запустили процесс "Fraud Detection: Model Training" на open source платформе KNIME Analytics Platform.

Иллюстрация 2. Этот процесс считывает датасет и делит его на обучающий и тестовый наборы. Затем обучает случайный лес, применяет получившуюся модель к тестовому набору и оценивает качество её работы при порогах в 0,3 и 0,5.
Развёртывание
Когда качество работы модели становится удовлетворительным, можно использовать её для работы с реальными данными.
Процесс развёртывания (иллюстрация 3) импортирует обученную модель, считывает по одной новой транзакции за раз и применяет к ней модель и выбранный порог, чтобы получить финальный прогноз. Если транзакция считается мошеннической, владельцу банковской карты отправляется письмо, чтобы он подтвердил легитимность операции.
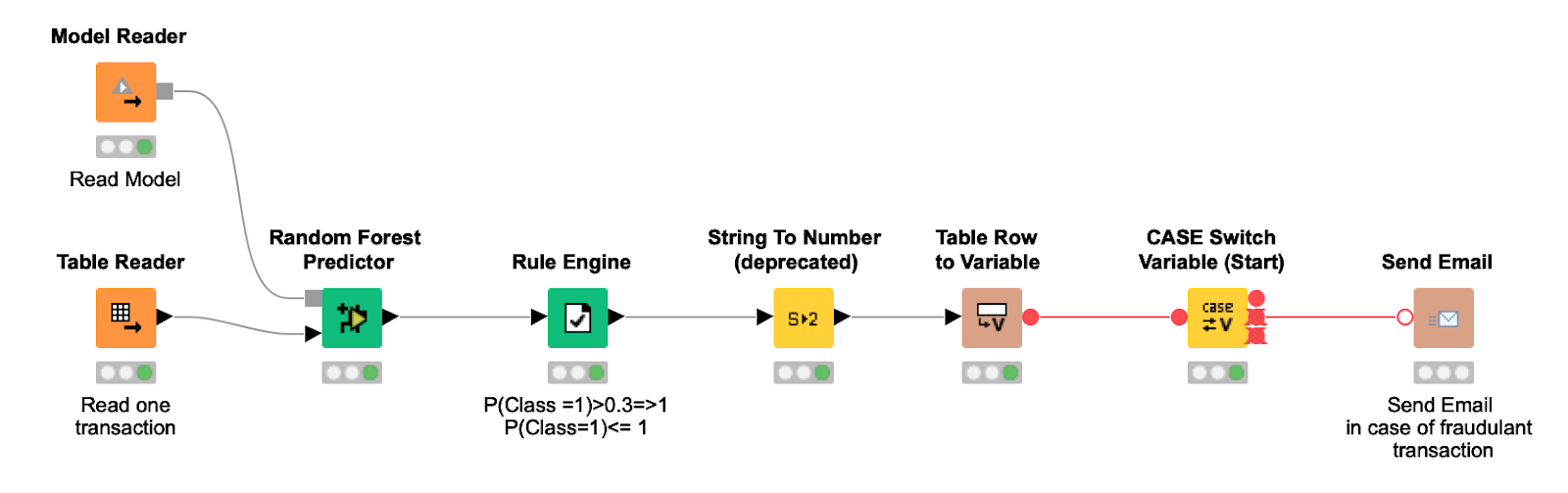
Иллюстрация 3. Процесс развёртывания считывает обученную модель и передаёт ей по одной новой транзакции, применяет порог прогнозируемых вероятностей и отправляет владельцу банковской карты письмо, если транзакция оценивается как мошенническая.
Сценарий 2: обнаружение аномалий с помощью автокодировщика
Поскольку в исходном датасете было очень мало мошеннических транзакций, мы можем их полностью убрать из фазы обучения и использовать только для тестирования.
Один из предложенных подходов основан на методиках обнаружения аномалий. Эти методики часто применяются для поиска любых приемлемых и неприемлемых событий в данных, будь то аппаратные сбои в интернете вещей, аритмичное сердцебиение при ЭКГ или мошеннические транзакции с банковских карт. Сложность обнаружения аномалий заключается в отсутствии аномальных образцов для обучения.
Часто используется такая методика, как нейронный автокодировщик: это нейронная архитектура, которую можно обучить только на одном классе событий и использовать для предупреждения о неожиданных новых событиях.
Нейронная архитектура автокодировщика
Как показано на иллюстрации 4, автокодировщик представляет собой нейросеть прямого распространения, обученную с помощью обратного распространения ошибки. Сеть содержит входной и выходной слои, каждый из которых состоит из узлов. Между ними находится один или несколько скрытых слоёв, а в середине — самый маленький слой, состоящий из узлов (). Идея в том, чтобы научить нейросеть воспроизводить входной вектор x в виде выходного вектора .
Автокодировщик обучается только на образцах одного или двух классов, в нашем случае это легитимные транзакции. После развёртывания автокодировщик будет воспроизводить входной в виде выходного , причём для мошеннических транзакций (аномалий) результат будет не оптимальным. Разницу между и можно оценить через измерение расстояния:
Финальное решение, является ли транзакция легитимной или мошеннической, применяется на основе применения порогового значения к расстоянию . Транзакция является кандидатом в мошенники в соответствии с правилом определения аномалий:
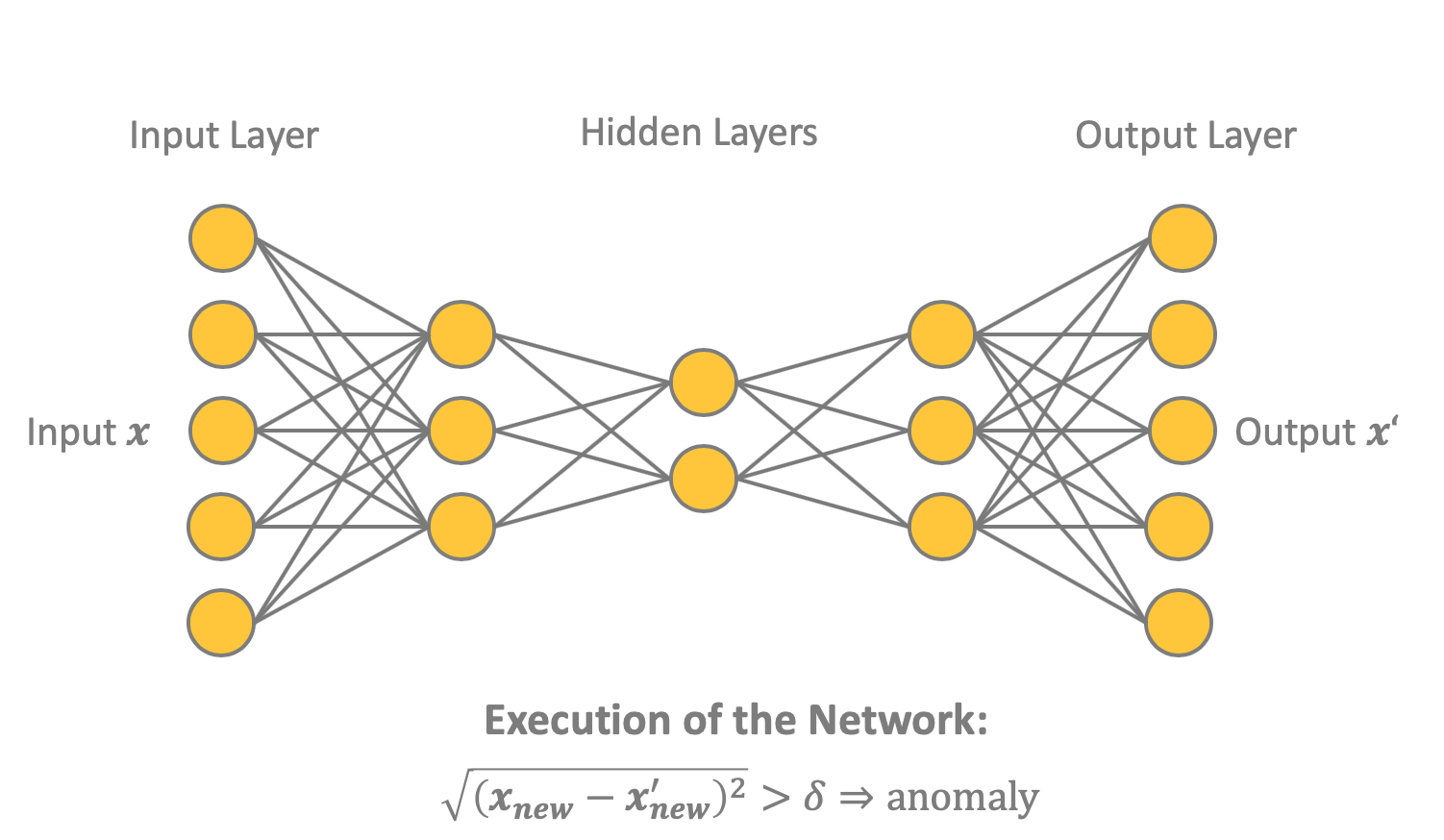
Иллюстрация 4. Здесь показана возможная сетевая структура автокодировщик. В данном случае пять входных узлов и три скрытых слоя с тремя, двумя и тремя узлами соответственно. Выходной содержит пять узлов, как и входной. Для определения аномалий — мошеннических транзакций — можно использовать расстояние между входным и выходным .
Конечно, можно задать такое пороговое значение , чтобы сигнализация срабатывала только в самых очевидных случаях мошенничества. Либо подобрать в зависимости от ваших потребностей и ситуации.
Давайте рассмотрим разные стадии процесса.
Подготовка данных
Сначала нужно вынести подмножество легитимных транзакций в обучающий датасет. Мы использовали 90 % легитимных транзакций для обучения автокодировщик, а оставшиеся 10 % вместе со всеми мошенническими транзакциями поместили в тестовый датасет.
Обычно данные нужно готовить в обучающем датасете. Но он уже очищен и готов к использованию. Никакой дополнительной подготовки не требуется. Необходимо лишь выполнить такой шаг: нормализовать входные векторы, чтобы они укладывались в [0,1].
Создание и обучение автокодировщик
Архитектура сети-автокодировщик определяется как 30-14-7-7-30. В ней применяются функции активации tanh и ReLU, а также регуляризатор активности L1 = 0,0001, как предложено в посте "Credit Card Fraud Detection using Autoencoders in Keras — TensorFlow for Hackers (Part VII)". Параметр L1 является ограничением разреженности (sparsity constraint), снижающим вероятность переобучения нейросети.
Алгоритм обучается до тех пор, пока финальные значения потерь не уложатся в диапазон [0.070, 0.071] в соответствии с loss-функцией в виде среднеквадратичной ошибки:
где — размер пакета, а — количество узлов во входном и выходном слое.
Зададим 50 эпох обучения, размер пакета тоже сделаем равным 50. В качестве обучающего алгоритма возьмём Adam — оптимизированную версию метода обратного распределения ошибки. После обучения сохраним нейросеть в виде Keras-файла.
Оценка модели: принятие информированного решения
Значение loss-функции не даёт нам всей полноты картины. Оно лишь говорит нам, насколько хорошо нейросеть можно воспроизводить «нормальные» входные данные в выходном слое. Чтобы получить полное представление о качестве обнаружения мошеннических транзакций, нужно применить к тестовым данным упомянутое выше правило обнаружения аномалий.
Для этого нужно определить порог для срабатывания предупреждения. Начинать можно с последнего значения loss-функции в конце фазы обучения. Мы использовали , но, как уже говорилось, этот параметр можно настроить в зависимости от ваших требований к консервативности нейросети.
На иллюстрации 5 показана оценка работы нейросети на тестовой выборке, выполненная с помощью измерения расстояний.

Иллюстрация 5. Здесь показан оценка работы автокодировщик — матрица ошибок и каппа-коэффициент. 0 обозначает легитимные транзакции, 1 — мошеннические.
В результате получился такой процесс: собираем нейронный автокодировщик, делим данные на обучающую и тестовую выборку, нормализуем данные перед подачей в нейросеть, обучаем нейросеть, прогоняем через неё тестовые данные, вычисляем расстояние , применяем пороговое значение и оцениваем результат. Скачать весь процесс можно здесь: Keras Autoencoder for Fraud Detection Training.

Иллюстрация 6. Считываем датасет и разбиваем его на две выборки: 90 % легитимных транзакций в обучающей и остальные 10 % + все мошеннические транзакции в тестовой. Нейросеть-автокодировщик определяется в левой верхней части схемы. После нормализации данных обучаем автокодировщик и оцениваем его работу.
Развёртывание
Обратите внимание, что сама нейросеть и пороговое правило были развёрнуты в REST-приложении, которое принимает входные данные из REST-запроса и генерирует прогноз в REST-ответе.
Ниже показан процесс развёртывания, скачать его можно здесь: Keras Autoencoder for Fraud Detection Deployment.

Иллюстрация 7. Исполнение этого процесса можно запустить из любого приложения, отправив новую транзакцию в REST-запросе. Процесс считывает и применяет модель к входным данным, а затем отправляет ответ с прогнозом: 0 для легитимной транзакции или 1 для мошеннической.
Обнаружение отклонений: изолирующий лес
При отсутствии образцов мошенничества может применяться ещё одна группа стратегий, основанная на методиках обнаружения отклонений. Мы выбрали изолирующий лес (M. Widmann and M. Heine, "Four Techniques for Outlier Detection," KNIME Blog, 2019).
Суть алгоритма в том, что отклонение можно изолировать с помощью меньшего количества случайных разделений по сравнению с образцом обычного класса, поскольку отклонения встречаются реже и не укладываются в статистику датасета.
Алгоритм случайным образом выбирает признак, а затем случайным образом выбирает значение из диапазона этого признака в качестве разделителя (split value). С помощью рекурсивного применения этой процедуры разделения генерируется дерево. Глубину дерева определяет количество необходимых случайных разделений (уровень изоляции) для изолирования образца. Уровень изоляции (его часто называют средней длиной (mean length)), усреднённый по лесу таких случайных деревьев, является мерой нормальности и нашей функцией принятия решений для обнаружения отклонений. Случайное партиционирование делает деревья для отклонений существенно короче, а для нормальных образцов — длиннее. Следовательно, если лес случайных деревьев для определённого образца генерирует более короткие пути, то это наверняка отклонение.
Подготовка данных
Данные готовятся так же, как описывалось выше: восстановление пропущенных значений, выбор признаков, дополнительные преобразования данных для соблюдения требований регулятора по приватности. Поскольку этот датасет уже очищен, можно пользоваться, дополнительной подготовки не требуется. Обучающая и тестовая выборки создаются так же, как для автокодировщик.
Обучение и применение изолирующего леса
Мы обучили лес из 100 деревьев с максимальной глубиной 8 и для каждой транзакции вычислили средний уровень изоляции по всем деревьям в лесу.
Оценка модели: принятие информированного решения
Помните, что средний уровень изоляции для отклонений ниже, чем для других единиц данных. Мы приняли порог . Следовательно, транзакция считается мошеннической, если средний уровень изоляции будет ниже этого значения. Как и в двух предыдущих примерах, значение порога можно выбирать в зависимости от желаемой чувствительности модели.
Эффективность этого подхода на тестовой выборке показана на иллюстрации 8. Финальный процесс, который можно скачать отсюда, показан на иллюстрации 9.

Иллюстрация 8. Оценка эффективности изолирующего леса на том же тестовом наборе, который использовался для автокодировщика.
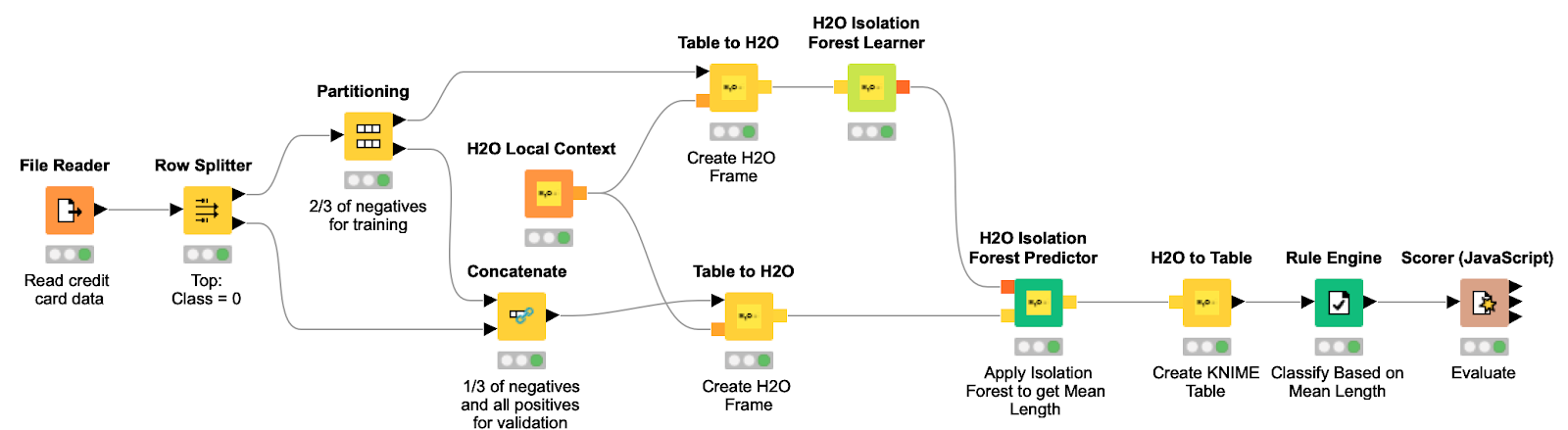
Иллюстрация 9. Этот процесс считывает датасет, создаёт обучающую и тестовую выборку и преобразует их в H2O Frame. Затем обучает изолирующий лес и применяет модель к тестовому набору, чтобы найти отклонения с помощью уровня изоляции для каждой транзакции.
Развёртывание
Процесс считывает модель изолирующего леса и применяет её к новым входным данным. На основе порогового значения, определённого при обучении и применённого к уровню изоляции, модель идентифицирует входные транзакции как легитимные или мошеннические.
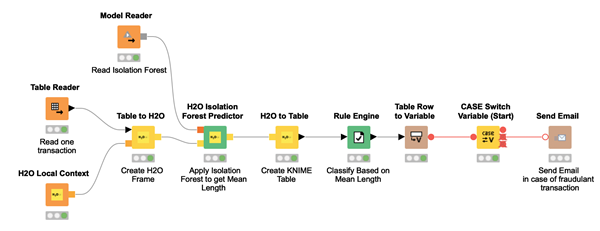
Иллюстрация 10. Процесс считывает новую транзакцию и применяет к ней обученную модель изолирующего леса. Для каждой входной транзакции вычисляется уровень изоляции и принимается решение, является ли транзакция мошеннической. Если да, то владельцу банковской карты отправляется письмо.
Резюме
Обнаружение мошенничества — это обширное направление исследований в сфере анализа данных. Мы описали два возможных сценария в зависимости от доступного датасета: либо с образцами легитимных и мошеннических транзакций, либо совсем без мошеннических (с пренебрежимо малым количеством).
В первом случае мы предложили классический подход на основе алгоритма машинного обучения с учителем, с выполнением всех шагов, принятых в проектах по анализу данных и описанных в процессе CRISP-DM process. Это рекомендованный подход. В частности, мы реализовали классификатор на основе случайного леса.
В некоторых ситуациях необходимо решать проблему обнаружения мошенничества, не имея на руках образцов. В таких случаях можно использовать менее точные подходы. Мы описали да из них: нейросеть-автокодировщик из методик обнаружения аномалий и изолирующий лес из методик обнаружения отклонений. Они не так точны, как случайный лес, но в некоторых случаях альтернатив просто нет.
Конечно, это не единственные возможные подходы, но они представляют три популярные группы решений для задачи обнаружения мошенничеств.
Обратите внимание, что два последних подхода применялись в ситуациях, когда нет доступа к размеченным мошенническим транзакциям. Это своего рода вынужденные подходы, которые можно использовать, если невозможно воспользоваться классическим решением для классификации. Если возможно, используйте классифицирующий алгоритм с учителем. Но если информации о мошенничества нет, помогут два последних описанных подхода. Они дают ложноположительные срабатывания, но иногда других способов просто нет.
Комментарии (30)

amarao
02.12.2019 14:01Оффтопик, но не мог пройти мимо.
Если в чём-то содержится файл
creditcard.csv, то это такой жирный флаг на фрод, что можно дальше не продолжать.
gofat
Autoencoder (даже у вас именно так написано). По-русски пишут «автоэнкодер». У вас же трансформировалось в «автокодер».
NIX_Solutions Автор
Спасибо, что указали на термин. Только «энкодер» — это не по-русски. По-русски «автокодировщик». Поправили в тексте.
roryorangepants
К сожалению, несмотря на то, что «автоэнкодер» — это не по-русски, но этот вариант популярнее. На том же хабре 75 статей с упоминанием автоэнкодеров и всего 43 с автокодировщиками.
Впрочем, конечно, оба варианта приемлемы.
NIX_Solutions Автор
Будем бороться за популярность правильного варианта :) Вики
roryorangepants
А кто определяет, что он правильный? Вряд ли википедия может являться ground truth.
GamesMRG
Вероятно, нормы русского языка, которые сложились давным-давно.
roryorangepants
Как нормы русского языка могут определять, какой из вариантов приживется? Термины могут заимствоваться из другого языка, могут переводиться.
Автоэнкодер — это заимствование (транслитерация).
Автокодировщик — это перевод (причем частичный, ведь мы не говорим самокодировщик, не говоря уж о том, что код — корень иностранного происхождения сам по себе).
Оба варианта легитимные.
GamesMRG
У слова encoder есть сложившиеся варианты перевода, и говорить о легитимности транслитерации тут не приходится. Траслитерируют по незнанию и/или лени.
gofat
А потом переводную литературу читать невозможно по теме. Зато русский язык отстояли.
P.S. Не против использования русскоязычных терминов, но именно в данной области я за заимствования, максимально приближенные к оригиналу.
System12
В серьезных документах практически всегда есть глава «Термины и определения». Транслитерация не спасает от потери смысла. Особенно по межпрофессиональным вопросам.
GamesMRG
Да чего уж, читайте сразу на английском. А то ишь, напереводили по-русски, после транслита понять невозможно.
System12
Недавно встречал данные о количестве слов, которых нет в словарях русского языка. Тысячи. Даже употребительное «бизнеспроцесс» не вошло ни в один словарь (или терминологический стандарт). а уж про такое узкоприменительное слово спорить просто смешно.
GamesMRG
Слово «кодировщик» есть в различных толковых словарях русского языка.
System12
А «автокодировщика» нет.
GamesMRG
Спор-то ведь не о приставке, а о корне. Приставка не меняет суть дела.
System12
Спор начался именно из-за приставок (автокодер — автоэнкодер). А они в русском языке могут изменить смысл до обратного. Я уже не говорю о межпрофессиональном общении, когда одно и тоже слово может иметь ну очень разные значения. Потому до официального включения термина в словарь (терминологический стандарт) все споры имеют статус «Я художник, я так вижу». :))
GamesMRG
Да при чём тут приставка? Автор первого комментария даже выделил жирным корень, перевод которого ему не понравился. Авто — это приставка. Кодировщик/энкодер — корень.
roryorangepants
You won't believe it!
А спор начался из-за того, что более «русский» вариант не обязательно является правильным. С точки зрения механизмов добавления новых слов в язык оба варианта ок, и вариант «автоэнкодер» является общепринятым.
GamesMRG
Гхм, мы же не спорили, как лучше — кодер или энкодер, верно? Так при чём тут приставка в английском слове, если речь шла о корне в словах на русском?
К счастью — или вашему неудовольствию — это пока что не общепринятый термин, и у слова encoder есть устоявшиеся переводы, добавлять ничего нового не требуется. Об этом я писал выше. Как и том, почему защищают транслит.
roryorangepants
You won't believe it!
В русском это тоже приставка «эн-». А корень что в «кодер», что в «кодировщик» общий — «код».
Мне кажется, вы слегка ошибаетесь.
Во-первых, у слова «encoder» есть два устоявшихся перевода: «кодировщик» и «энкодер». Пруф второго можете найти в той же статье на википедии, которую я упомянул выше.
Во-вторых, перевод «автоэнкодер» действительно не общепринятый, я был не прав с этой формулировкой. Тем не менее, по всем параметрам «автоэнкодер» более используемый, чем «автокодировщик»: по результатам в гугле (7к vs 4к), количеству статей на хабре (75 vs 43), поисковым запросам («автокодировщик» вообще отсутствует), упоминаниям в ODS (25 vs 148).
Так что, хотите вы этого или нет, в этом вопросе сообщество на стороне автоэнкодера.
GamesMRG
Вы с поразительным упорством упёрлись не туда. Ещё раз: спор был не про кодер/энкодер с приставкой «эн». Спор был про энкодер/кодировщик с приставкой «авто». Ну или если совсем докапываться до терминов: речь шла об основе кодер/кодировщик, с совсем сопутствующими суффиксами и окончаниями. И приставкой «авто».
Вы правда не понимаете, что «энкодер» — это не перевод, а транслит? И что переводом является именно «кодировщик»?
А тут я присоединяюсь к автору поста: буду вместе с ним топить за правильный перевод, а не за ленивую или безграмотную транслитерацию сообщества.
roryorangepants
Вы с поразительным упорством спорите с буквальным утверждением, не понимая, что это просто аналогия, чтобы показать, что ваши «авто» и «кодировщик» — тоже иностранные корни, тот самый транслит, который вы так не уважаете.
Мне кажется, это вы не понимаете, что если в русском языке присутствует заимствованное слово, то хоть оно и является транслитом с английского, оно в то же время является и переводом.
Вы же не считаете слово «код» транслитом от слова «code», правда? А ведь оно формально является.
Какое счастье, что «автоэнкодер» не является неправильным переводом.
Язык — динамическая штука. Его определяет в конечном итоге народ, который им пользуется. Ещё вчера не существовало феминитивов — сейчас они у многих в обиходе и в украинском, например, вошли в официальные правила языка с этого года.
Так же и в науке — терминология заимствуется из английского разными путями. И побеждает тот путь, который больше понравился сообществу.
GamesMRG
Эти транслиты уже настолько давно и прочно устоялись, что бороться с ними не имеет смысла.
Считаю. С чего бы мне так не считать? Только здесь такая же ситуация, как с «авто» — слово уже стало частью языка.
Совершенно верно. И пока у «энкодера» не такой катастрофический перевес с точки зрения встречаемости в статьях, я предпочту использовать более «русское» «кодировщик». Благо, что это слово в языке существует давно и не является новомодным бездумным транслитом (да, я помню про «код», но «это просто аналогия, чтобы показать»).
roryorangepants
Предпочитайте, это же абсолютно нормальный вариант. Только не навязывайте другим в комментариях свою не обоснованную позицию о том, что второй вариант некорректный.
GamesMRG
Учитывая, что в словарях есть слово «кодировщик», а «энкодер» отсутствует, да, этот транслит — не перевод — многими применяется не то что некорректно, а бездумно. С пренебрежением к собственному языку. Прикрываясь «мнением сообщества», своей ленью и равнодушием.
roryorangepants
Если вы потрудитесь заглянуть в толковый словарь, а не в орфографический, то узнаете, что слово «кодировщик» означает вовсе не архитектуру нейросети, а слова «автокодировщик» там тоже нет.
Как и 90% терминов из deep learning.
А ещё вы, видимо, невнимательно читаете мои сообщения. Я вам в явном виде выше писал, что слово «энкодер» есть в русских словарях. Другое дело, что оно там тоже значит далеко не нейросетевую архитектуру.
GamesMRG
Одно и то же слово в русском языке может иметь разные значения в зависимости от контекста. Как и в английском. Так что апеллирование к тому, что для «кодировщика» не успели добавить значение «архитектура нейросети», это лукавство. Делов-то, добавить ещё одно значение в словарь. Оригинал-то encoder остался тем же.
В общем, мне кажется, наш спор себя исчерпал. Оба остались при своём мнении.
roryorangepants
Какое лукавство? Вы говорите посмотреть слово в словаре, но другой вариант в словаре тоже есть.
И они оба имеют в словаре не тот смысл, про который мы спорим.
Вы не привели ни одного, просто ни одного аргумента, показывающего, что писать «автоэнкодер» неправильно, ведь буквально все валидные аргументы применимы к обоим вариантам одинаково.
Hait
Вики не является достоверным источником