

Источник
Привет, Хабр! Меня зовут Максим Пчелин, и я руковожу разработкой BI-DWH в MyGames (игровое подразделение Mail.ru Group). В этой статье я расскажу о том, как и зачем мы строили клиентоориентированное DataLake-хранилище.
Статья состоит из трех частей. Сперва я расскажу, почему мы решили реализовывать DataLake. Во второй части я опишу, какие технологии и решения мы используем, чтобы хранилище могло работать и наполняться данными. И в третьей части опишу, что мы делаем для улучшения качества наших сервисов.
Что привело нас к DataLake
Мы в MyGames работаем в отделе BI-DWH и делаем сервисы двух категорий: хранилище для аналитиков данных и сервисы регулярной отчетности для бизнес-пользователей (менеджеров, маркетологов, разработчиков игр и других).
Почему такое нестандартное хранилище?
Обычно BI-DWH не предполагает реализации DataLake-хранилищ, это нельзя назвать типовым решением. А как тогда строятся такие сервисы?
Обычно в компании есть проект — в нашем случае это игра. У проекта есть система логирования, которая чаще всего пишет данные в базу. Поверх этой базы создаются витрины для агрегатов, метрик и других сущностей для будущей аналитики. На основе витрин с помощью любого подходящего BI-инструмента строится регулярная отчетность, а также системы Ad-Hoc аналитики, начиная с простых SQL-запросов и Excel-таблиц, и заканчивая Jupyter Notebook для DS и ML. Всю систему поддерживает одна команда разработки.
Допустим, в компании рождается еще один проект. Завести под него еще одну команду разработки и инфраструктуру привлекательно, но дорого. Значит, проект нужно «подселять». Сделать это можно по-разному: на уровне базы данных, на уровне витрин, или хотя бы на уровне отображения — вопрос решаемый.
А если в компании появился третий проект? «Подселение» уже может плохо закончиться: могут возникнуть проблемы с распределением ресурсов или прав доступа. Например, один из проектов делает внешняя команда, которой не стоит что-либо знать про первые два проекта. Ситуация становится более рискованной.
А теперь представим, что проектов не три, а гораздо больше. И так сложилось, что это именно наш случай.
MyGames — одно из самых больших подразделений Mail.ru Group, у нас в портфолио 150 проектов. Причем все они очень разные: собственной разработки и купленные для оперирования в России. Они работают на различных платформах: PC, Xbox, Playstation, iOS и Android. Эти проекты разрабатываются в десяти офисах по всему миру, в которых работают сотни людей, принимающих решения.

Для бизнеса это замечательно, но усложняет задачу для BI-DWH команды.
В наших играх логируются множество действий игрока: когда он заходил в игру, где и как получал уровни, с кем и насколько успешно дрался, что и за какую валюту покупал. Все эти данные нам нужно собирать по каждой из игр.
Нам это необходимо для того, чтобы бизнес мог получать ответы на имеющиеся у него вопросы по проектам. Что было на прошлой неделе после запуска акции? Какие у нас прогнозы по выручке или использованию мощностей игровых серверов на следующий месяц? Что можно сделать, чтобы повлиять на эти прогнозы?
Важно, что MyGames не навязывает проектам парадигму разработки. Каждая игровая студия логирует данные так, как считает более эффективным. Какие-то проекты генерируют логи на стороне клиента, какие-то — на стороне сервера. Для их сбора одни проекты использует РСУБД, другие — совсем иные инструменты: Kafka, Elasticsearch, Hadoop, Tarantool или Redis. И мы обращаемся к этим источникам за данными, чтобы заливать их в хранилище.
Чего хотят от нашего BI-DWH?
В первую очередь, от отдела BI-DWH хотят получить данные по всем нашим играм для решения как ежедневных операционных задач, так и стратегических. Начиная от того, сколько жизней дать страшному монстру в конце уровня, и заканчивая тем, как правильно распределять ресурсы внутри компании: каким проектам дать больше разработчиков или кому выделить маркетинговый бюджет.
Также от нас ожидают надежности. Мы работаем в крупной компании и не можем жить по принципу «вчера работали, а сегодня система лежит, и поднимется только через неделю, если мы что-нибудь придумаем».
От нас хотят экономии. Мы были бы рады решать все проблемы покупкой железа или наймом людей. Но мы коммерческая организация и не можем себе такое позволить. Мы стараемся приносить компании прибыль.
Что немаловажно, от нас хотят клиентоориентированности. Клиенты в данном случае — это наши потребители, заказчики: менеджеры, аналитики и т. д. Мы должны подстраиваться под наши игры и работать так, чтобы клиентам было удобно с нами сотрудничать. Например, в некоторых случаях, когда мы приобретаем для оперирования проекты на азиатском рынке, вместе с игрой мы можем получить базы с наименованиями на китайском. И документацию по этим базам на китайском. Мы могли бы поискать ETL-разработчика со знанием китайского или отказаться загружать данные по игре, но вместо этого мы с командой запираемся в переговорке, берем часы и начинаем играть. Входить и выходить из игры, покупать, стрелять, умирать. И смотрим, что и когда появляется в той или иной таблице. Затем пишем документацию и на её основе строим ETL.
В этом деле важно чувствовать грань. Копаться в уникальном логировании игры с DAU в 50 человек, когда рядом нужно помочь проекту с DAU 500 000, — непозволительная роскошь. Так что мы, конечно, можем потратить много сил на построение кастомного решения, но только если это действительно нужно бизнесу.
Однако, как только разработчики, особенно новички, слышат, что придется так подстраиваться, у них возникает желание никогда так не делать. Любой разработчик хочет сделать идеальную архитектуру, никогда ее не менять и писать о ней статьи на Хабр.
Но что произойдет, если мы перестанем подстраиваться под наши игры? Допустим, начнем требовать от них слать данные в единое входное API? Результат будет один — все начнут разбегаться.
- Одни проекты начнут пилить свои BI-DWH решения, с преферансом и поэтессами. Это приведет к дублированию ресурсов и сложностям при обмене данными между системами.
- Другие проекты не потянут создание своего BI-DWH, но и под наш подстраиваться не захотят. А третьи вообще перестанут пользоваться данными, что еще хуже.
- Ну и самое главное — у руководства не будет актуальной систематизированной информации о том, что происходит в проектах.
Могли бы мы реализовать хранилище по-простому?
150 проектов — это много. Реализовывать решение сразу для всех чересчур долго. Бизнес не будет ждать год появления первых результатов. Поэтому мы взяли 3 проекта, которые приносят максимальную выручку, и реализовали первый прототип для них. Мы хотели собрать по ним ключевые данные и создать базовые дэшборды с самыми популярными метриками — DAU, MAU, Revenue, регистрации, ретеншены, а также немного экономики и прогнозов.
Мы не могли использовать для этого игровые базы самих проектов. Во-первых, это затруднило бы кросспроектный анализ из-за необходимости сведения данных из нескольких баз. Во-вторых, поверх этих баз работают сами игры, которым важно, чтобы мастера и реплики не были перегружены. Наконец, все игры в какой-то момент удаляют всю ненужную им историю данных в своих базах, что неприемлемо для аналитики.
Поэтому единственный вариант — собрать всё необходимое для анализа в едином месте. На этом этапе нам подходила любая реляционная база данных или простое текстовое хранилище. Мы прикрутили бы BI и строили бы дашборды. Вариантов комбинаций таких решений много:

Но мы же понимали, что позже нам надо будет покрыть все остальные 150 игр. Возможно, какая-нибудь кластерная реляционная БД и справится с объемами генерируемых данных. Но ведь источники не только находятся в совершенно разных системах, но еще и имеют очень разную структуру данных. У нас встречаются реляционные структуры, Data Vault и другие. Не получится всё это поместить в одну БД без сложных и трудоемких ухищрений.
Все это привело нас к пониманию, что нам нужно строить DataLake.
Реализация DataLake
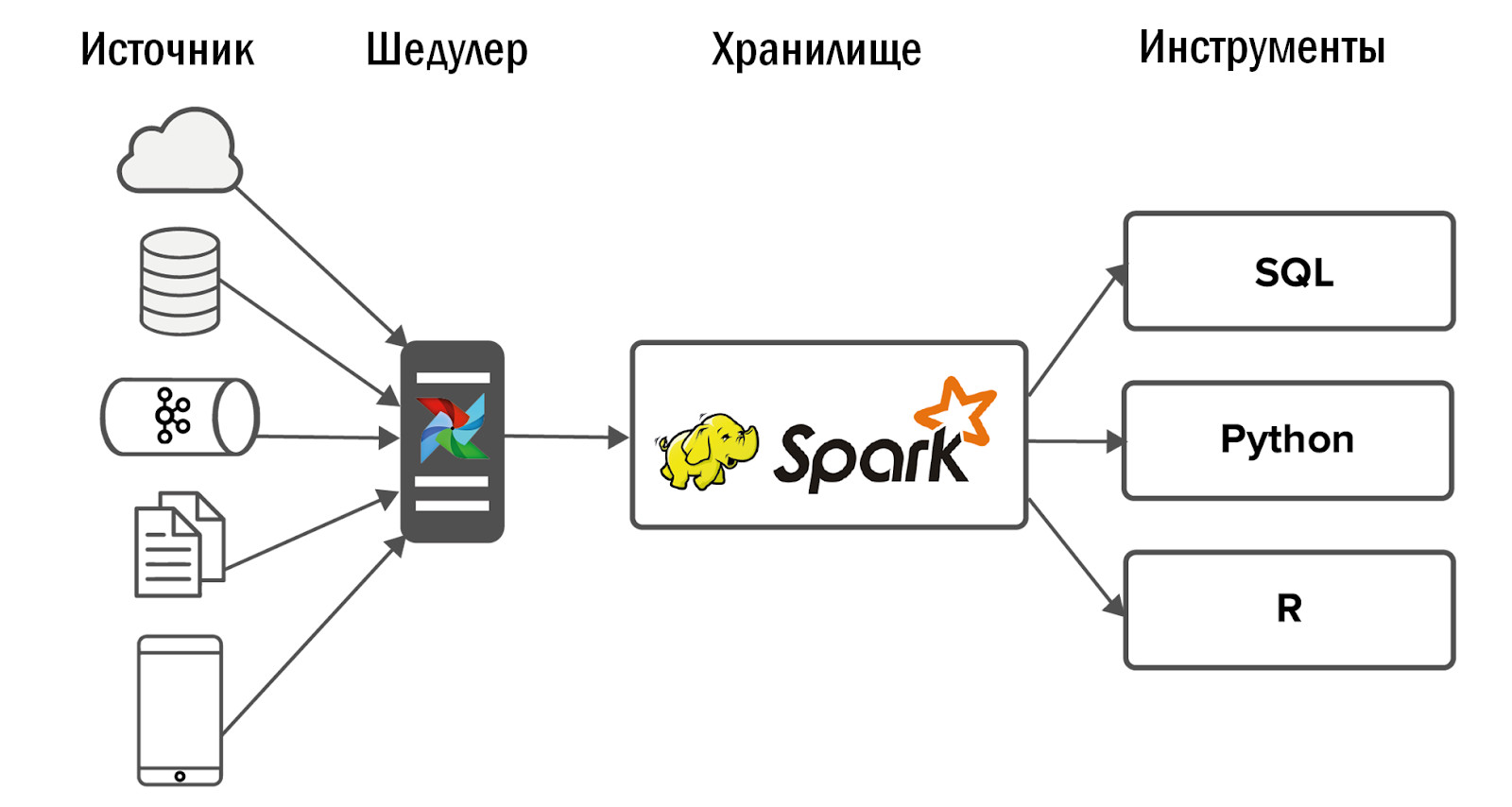
В первую очередь DataLake-хранилище подходит под наши условия, так как позволяет хранить неструктурированные данные. DataLake может стать единой точкой входа для всех разнообразных источников, начиная с таблиц из РСУБД и заканчивая JSON, которые мы грузим из Kafka или Mongo. Как следствие, DataLake может стать основой для кросспроектной аналитики, реализованной на основе интерфейсов для различных потребителей: SQL, Python, R, Spark и так далее.
Переход на Hadoop
Для DataLake мы выбрали очевидное решение — Hadoop. Если конкретно, то его сборку от Cloudera. Hadoop позволяет работать с неструктурированными данными и легко масштабируется с помощью добавления дата-нод. К тому же этот продукт хорошо изучен, поэтому ответ на любой возникающий вопрос можно найти на Stackoverflow, а не тратить ресурсы на R&D.
После внедрения Hadoop у нас получилась следующая схема нашего первого единого хранилища:

Данные забирались в Hadoop из небольшого числа источников, а затем на него натравливались несколько интерфейсов: BI-инструменты и сервисы для Ad-Hoc аналитики.
Дальше события развивались неожиданно: наш Hadoop стартовал отлично, и потребители, для которых данные потекли в хранилище, забросили старые аналитические системы и начали ежедневно использовать новинку для своей работы.
Но возникла проблема: чем больше ты делаешь, тем больше от тебя хотят. Очень быстро проекты, которые уже были интегрированы в Hadoop, стали просить больше данных. А те проекты, которые еще не были добавлены, начали в него проситься. Требования к стабильности стали резко расти.
При этом, не разумно просто линейно увеличивать команду. Если два DWH-разработчика справляются с двумя проектами, то для четырёх проектов мы не можем нанять еще двух разработчиков. Поэтому, сперва мы пошли другим путем.
Налаживание процессов
В условиях ограниченности ресурсов самое дешевое решение — настраивать процессы. Более того, в крупной компании невозможно просто придумать архитектуру хранилища и ее реализовать. Придётся договариваться с огромным количеством людей.
- В первую очередь, с представителями бизнеса, которые выделяют ресурсы на аналитику. Вам придется доказывать, что реализовывать нужно только те задачи от ваших Заказчиков, которые принесут пользу бизнесу.
- Также нужно договариваться с аналитиками, чтобы они давали вам что-то взамен за те сервисы, которые вы им предоставите — системный анализ, бизнес-анализ, тестирование. Например, системный анализ наших источников данных мы отдали на откуп аналитикам. Они, конечно, не рады, но иначе это просто некому будет делать.
- Не в последнюю очередь придется договариваться с разработчиками игр: устанавливать SLA и договариваться о структуре данных. Если поля будут постоянно исчезать, появляться и переименовываться, то какого бы размера ни была команда, вам всегда будет не хватать рук.
- Вам также необходимо договариваться со своей собственной командой: искать компромисс между идеальными решениями, которые хотят создавать все разработчики, и стандартными решениями, которые не так интересны, но которые можно клепать дешево и быстро.
- Нужно будет договариваться и с админами о мониторинге инфраструктуры. Хотя, как только у вас появятся дополнительные ресурсы, лучше нанять в команду хранилища собственного DevOps-специалиста.
На этом месте я мог бы закончить статью, если бы такой вариант хранилища отвечал всем поставленным перед ним целям. Но это не так. Почему?
До появления Hadoop мы могли предоставлять данные и статистику для пяти проектов. С реализацией Hadoop и без увеличения команды мы смогли охватить 10 проектов. После налаживания процессов наша команда обслуживала уже 15 проектов. Это круто, но ведь проектов у нас 150. Нам было нужно что-то новое.
Внедрение Airflow
Изначально мы собирали данные из источников с помощью Cron. Два проекта — это нормально. 10 — больно, но ок. Однако, сейчас у нас ежедневно грузится порядка 12 тысяч процессов для загрузки в DataLake из 150 проектов. Cron уже не подходит. Для этого нам нужен мощный инструмент управления потоками загрузок данных.
Мы выбрали open source диспетчер задач Airflow. Он родился в недрах Airbnb, после чего его передали Apache. Это инструмент для code-driven ETL. То есть вы пишете скрипт на Python, а он преобразуется в DAG (directed acyclic graph). DAG прекрасно подходят для поддержания зависимостей между задачами — нельзя строить витрину по данным, которые еще не успели загрузиться.
В Airflow отличный обработчик ошибок. Если какой-то процесс упал или есть проблемы с сетью, то диспетчер перезапускает процесс указанное вами количество раз. Если сбоев достаточно много, например, таблица в источнике поменялась, то приходит письмо с уведомлением.
В Airflow отличный UI: удобно отображается, какие процессы выполняются, какие завершились успешно или с ошибкой. Если задачи падали с ошибками, можно из интерфейса перезапустить их и контролировать процесс через мониторинг, не залезая в код.
Airflow кастомизируемый, он строится поверх операторов — это плагины для работы с конкретными источниками. Часть операторов поставляется из коробки, множество написало сообщество Airflow. При желании можете создать свой оператор, интерфейс для этого очень простой.
Как мы используем Airflow?
Например, нам надо загрузить таблицу из PostgreSQL в Hadoop. Задача
sql_sensor_battle_log проверяет, есть ли в источнике нужные нам данные за вчерашний день. Если есть, то задача load_stg_data_from_battle_log забирает данные из PG и складывает в Hadoop. Наконец, load_oda_data_from_battle_log выполняет первичную обработку: скажем, преобразование из Unix Time в человекочитаемое время. Такой цепочкой задач данные забираются данные из одной сущности в одном источнике:

А так — из всех нужных нам сущностей одного источника:
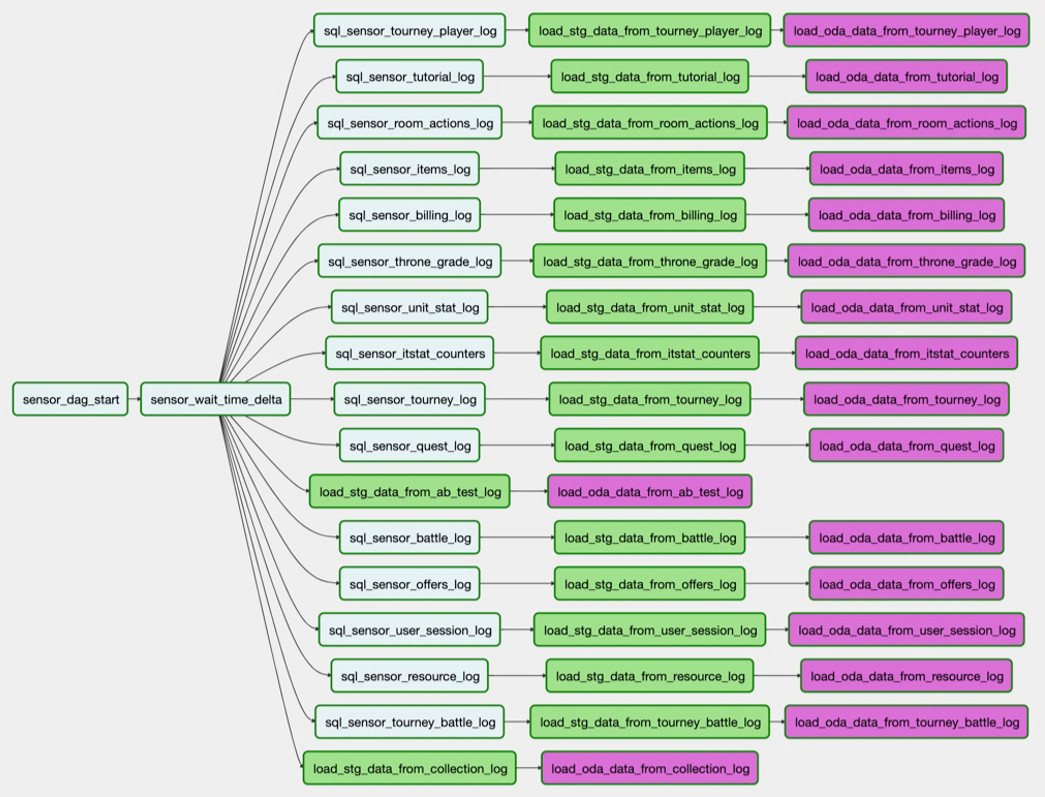
Именно этот сет загрузок и есть DAG. И на текущий момент у нас 250 таких DAG для загрузки сырых данных, их обработки, преобразования и создания по ним витрин.
Схема обновленного единого хранилища получилась следующей:
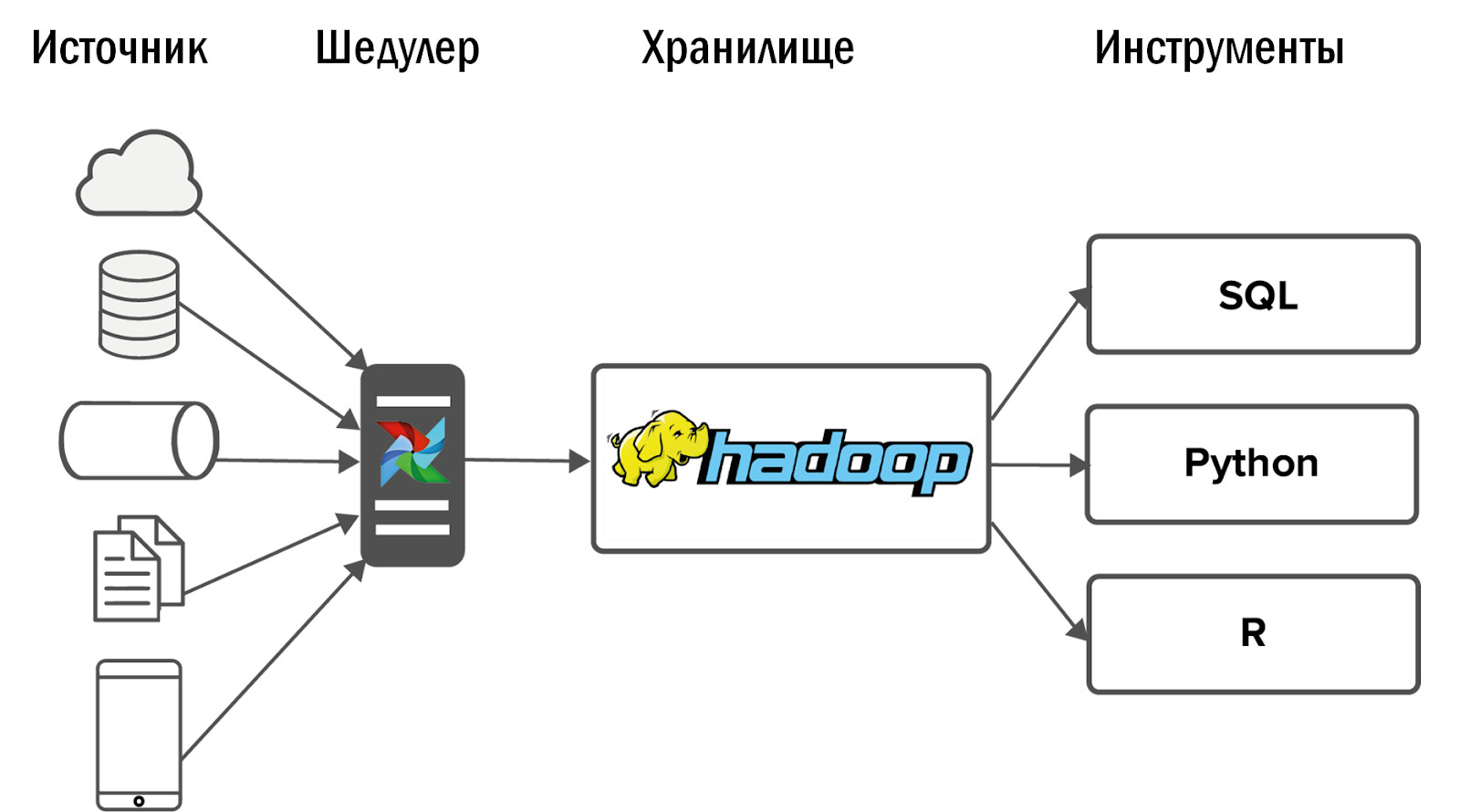
- После внедрения Airflow мы смогли позволить себе резкий рост количества источников — до 400 штук. Источники данных как внутренние (от наших игр), так и внешние: покупные системы статистики, разнородные API. Именно Airflow позволяет нам ежедневно выполнять и контролировать 12 тысяч процессов, которые обрабатывают данные из всех наших 150 игр.
- Подробнее про наш Airflow писала в своей статье Дина Сафина (https://habr.com/ru/company/mailru/blog/344398/). А также присоединяйтесь к сообществу Airflow в Telegram (https://t.me/ruairflow). Многие вопросы по Airflow можно решить с помощью документации, но иногда появляются и более кастомные запросы: как мне упаковать Airflow в докер, почему ничего не работает третий день и все в таком духе. На такое можно получить ответ в этом сообществе.
Что улучшить в DataLake
На этом этапе у разработчиков DWH появляется уверенность, что всё готово и теперь можно успокоиться. К сожалению или к счастью, еще есть что подкрутить в DataLake.
Качество данных
При большом количестве таблиц в DataLake в первую очередь страдает качество данных. Для примера возьмем таблицу с платежами. В ней лежит user_id, сумма, дата и время платежа:
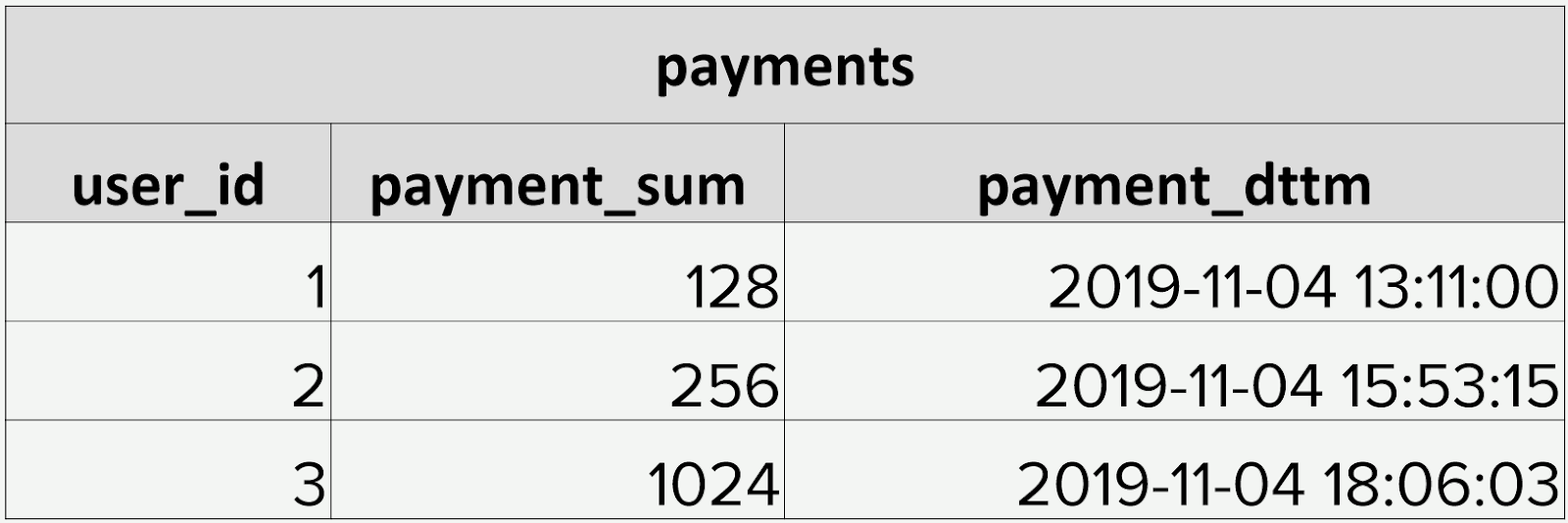
Платежей каждый день происходит примерно около 10 тысяч:

Однажды в таблицу за день пришло только 28 записей. Да еще и user_id все пустые:
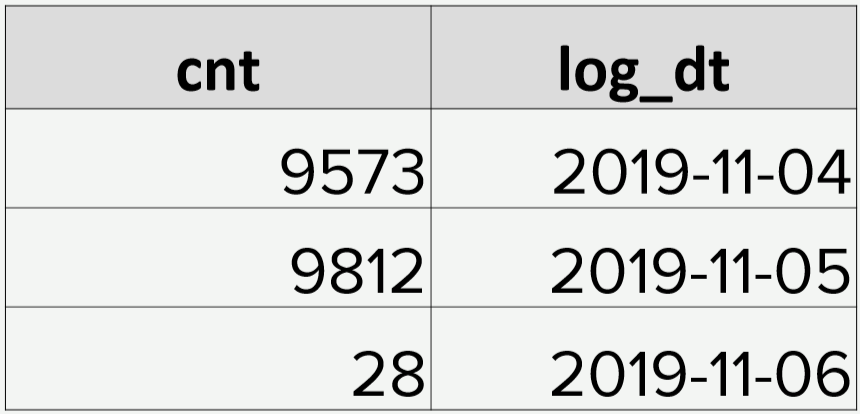
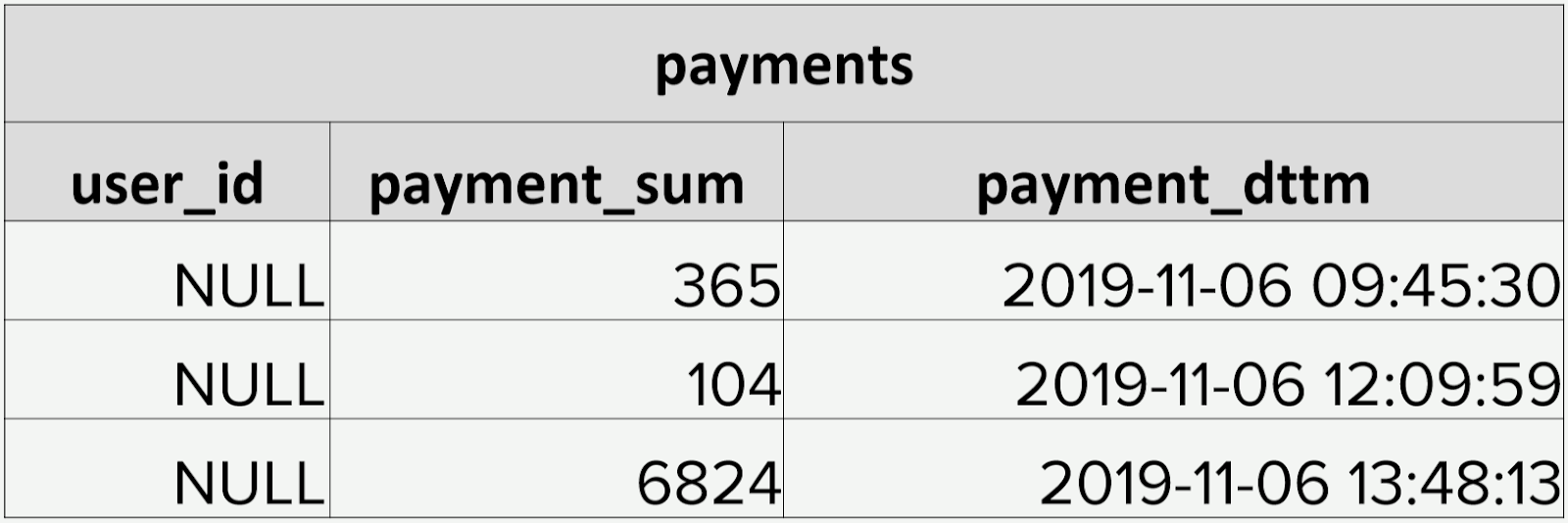
Если у нас в источнике вдруг что-нибудь ломается, то, благодаря Airflow, мы об этом узнаем сразу. А вот если формально данные есть, и даже в нужном формате, то о поломке мы узнаём не сразу и уже от потребителей данных. Руками проверять наши 5000 таблиц в хранилище не реально.
Чтобы такого не допускать мы разработали собственную систему контроля качества данных (DQ). Ежедневно она мониторит ключевые загрузки в наше хранилище: отслеживает резкие изменения в количестве строк, ищет пустые поля, проверяет на дублирование данных. Также система применяет кастомные проверки от аналитиков. На основе этого она рассылает на почту оповещения о том, что и где пошло не так. Аналитики идут в проекты и выясняют, почему, например, данных слишком мало, устраняют причины, и мы перезагружаем данные.
Приоритизация загрузок
С ростом количества задач по загрузке данных в DataLake быстро возникает конфликт приоритетов. Обычная ситуация: какой-нибудь не самый важный проект ночью занял своими загрузками все ресурсы, и таблицы, которые нужны для расчета метрик для топ-менеджмента, не успевают загрузиться к началу рабочего дня. Мы боремся с этим несколькими способами.
- Мониторинг ключевых загрузок. У Airflow есть своя система SLA, которая позволяет определить, все ли из ключевого пришло вовремя. Если какие-то данные не загрузились, то мы узнаем об этом на несколько часов раньше пользователей и успеем всё починить.
- Настройка приоритетов. Для этого мы используем систему очередей и приоритетов Airflow. Она позволяет нам определять порядок загрузки DAGов и количество параллельных процессов в них. Нет смысла загружать логи, которые анализируются раз в квартал, перед загрузкой данных для метрик топ-менеджмента.
Контроль длительности ночного батча
У нас батчевое хранилище. Ночью у нас идет процесс его построения, и нам важно отслеживать, чтобы на обработку ежедневного батча хватало ночи. Иначе, в рабочее время аналитикам не будет хватать ресурсов хранилища для работы. Эта задачу мы регулярно решаем несколькими путями:
- Обратное масштабирование. Мы грузим не все данные, а только те, что нужны аналитикам. Мониторим все загружаемые таблицы, и если какая-то из них не используется полгода, то отключаем ее загрузку.
- Наращивание мощностей. Если мы понимаем, что уперлись в возможности сети, количество ядер или емкость дисков, то добавляем дата-ноды в Hadoop.
- Оптимизация воркеров Airflow. Мы делаем всё, чтобы каждая часть нашей системы максимально использовалась в каждый момент времени построения хранилища.
- Рефакторинг неоптимальных процессов. К примеру, мы считаем экономику свежей игры, и это занимает у нас 5 минут. Но через год данные разрастаются, и этот же запрос обрабатывается 2 часа. В какой-то момент мы должны перестроиться на инкрементальный пересчёт, хотя в самом начале это могло казаться излишним усложнением.
Контроль потребления ресурсов
Важно не только успевать заканчивать подготовку хранилища к началу рабочего дня, но и отслеживать доступность его ресурсов после этого. С этим со временем могут возникать трудности. В первую очередь, причина в том, что аналитики пишут неоптимальные запросы. Опять же, самих аналитиков становится всё больше и больше. Самое простое в таком случае: нарастить аппаратные мощности. Однако неоптимальный запрос всё равно займёт все доступные ресурсы. То есть рано или поздно вы начнёте тратить деньги на железо без существенной пользы. Поэтому мы применяем несколько других подходов.
- Квотирование: оставляем пользователям хотя бы чуть-чуть ресурсов. Да, запросы будут выполняться медленно, но хотя бы будут.
- Мониторинг потребляемых ресурсов: сколько ядер используют запросы пользователей, кто забыл использовать партиции в Hadoop и занял всю оперативную память и т.д… Причём эти мониторинги видны самим аналитикам, и когда у них что-то не работает, они сами находят виновного и разбираются с ним. Если бы у нас было мало проектов, мы бы сами отслеживали потребление ресурсов. Но при таком количестве нам пришлось бы нанять отдельную, постоянно разрастающуюся команду мониторинга. А в долгосрочной перспективе это неразумно.
- Добровольно-принудительное обучение пользователей. Работа аналитиков заключается не в написании качественных запросов в ваше хранилище. Их работа — отвечать на вопросы бизнеса. И кроме нас самих — команды хранилища — никого не интересует качество запросов аналитиков. Поэтому мы создаем FAQ и презентации, проводим лекции для наших аналитиков, объясняем, как можно работать с нашим DataLake, а как нельзя.
Фактически, тратить время на обеспечение доступности данных гораздо важнее, чем на их заливку. Если данные в хранилище есть, но они недоступны, то с точки зрения бизнеса их всё равно что нет, а ваши усилия на загрузку уже потрачены.
Гибкость архитектуры
Важно не забывать о гибкости построенного DataLake и не бояться менять архитектуру при смене вводных факторов: какие данные нужно заливать в хранилище, кто и как их потребляет. Мы не считаем, что наша архитектура всегда будет оставаться неизменной.
Например, запустилась у нас новая мобильная игра. Она с клиентов пишет JSON в Nginx, Nginx кидает данные в Kafka, мы разбираем их с помощью Spark и кладём в Hadoop. Всё работает, задача закрыта.
Прошла пара месяцев, и в хранилище все процессы ночного батча начали выполняться дольше. Начинаем разбираться, в чем дело: оказывается, игра «выстрелила», данных стало генерироваться в 50 раз больше и Spark не справляется с разбором JSON, утягивая за собой половину ресурсов хранилища. Изначально все данные отправлялись в один топик Kafka, а Spark разбирал их по разным сущностям. Мы попросили разработчиков игр делить данные на клиентах по разным сущностям и лить их в отдельные топики Kafka. Стало легче, но ненадолго. Тогда решили перейти с ежедневных разборов JSON на ежечасные. Однако хранилище начало строится не только ночью, а круглосуточно, что для нас было нежелательно. После таких попыток мы для решения этой задачи отказались от Spark и внедрили ClickHouse.

У него есть отличный движок для разбора JSON, который мгновенно раскладывает данные по таблицам. Информацию из Kafka мы сперва отправляем в ClickHouse, а оттуда забираем в Hadoop. Это полностью решило нашу проблему.
Мы, конечно, стараемся не разводить зоопарк систем в нашем DataLake-хранилище, но под конкретные задачи стараемся подбирать максимально подходящие технологии.
Стоило ли оно того?
Стоило ли разворачивать Hadoop, систему контроля качества, разбираться с Airflow, налаживать бизнес-процессы? Конечно, стоило:
- У бизнеса появилась актуальная информация по всем проектам, которая доступна в единых сервисах.
- Пользователи нашей системы, начиная от гейм-дизайнеров и заканчивая менеджерами, перестали принимать решения только на основе интуиции и перешли к Data Driven-подходам.
- Мы дали аналитикам инструменты для того, чтобы они делали свой собственный rocket science. Теперь они отвечают на сложные запросы бизнеса, строят прогнозные модели, рекомендательные системы, улучшают игры. Собственно, ради этого мы и работаем в BI-DWH.
Комментарии (12)

famelar
13.12.2019 11:39+1Отличная статья! Спасибо! А почему выбор пал именно на Cloudera Hadoop? Насколько я знаю в бесплатной версии у них ограничено кол-во узлов в кластере. Вы ограничились этим или приобретали Enterprise версию? Почему не выбрали Hortonworks? Да она не без недостатков и нужно поработать напильником, но вроде как полностью опенсорс.

PchelinM Автор
13.12.2019 11:55Несколько лет назад, в момент выбора сборки, Cloudera нам она показалась чуть более подходящей:
- В Mail.ru уже был опыт ее использования
- В ней есть Impala, которая чуть менее стабильна чем hive, но крайне быстра и нравится нашим аналитикам
В целом, нам будем уже крайне дорого менять сборку, но если бы мы выбирали прямо сейчас, то может быть выбрали бы Hortonworks
P.S. Ограничения по хостам нет даже в community версииfamelar
16.12.2019 02:55+1По кол-ву нод немного напутал да и за новостями не следил последний год :). Оказывается Hortonworks слился с Cloudera в начале этого года.
ivsmodern
13.12.2019 12:06+1Спасибо за статью, очень познавательно.
Если будет возможность ответить было бы интересно узнать следующее… При таком количестве и разнообразии источников есть ли потребность в каталогизации данных, Какой инструментарий используете или планируете использовать? Как технически и организационно решаете вопросы с администрированием доступа? Есть ли необходимость в консолидации, гармонизации исходных данных перед передачей их аналитиками, если да, то какие архитектурные последствия для вашего data lake это имеет?
Спасибо.PchelinM Автор
13.12.2019 12:13Спасибо!
Потребность в каталогизации определённо имеется. Сейчас мы всю мета-информацию храним в json’ах — по одному на каждый источник. На основе этих json’ов и строится забор данных из Airflow. Мы обдумываем создание центра управления загрузками через мету, но писать о нем пока рано.
Доступы нас к источникам
- Почти все наши источники находятся в инфраструктуре Mail.ru и ими управляют специальные админы. Для получения доступов с нашей стороны требуется задача на них, а они уже пропиливают дырки, заводят пользователя и каталогизируют это на своей стороне
Доступы аналитиков к хранилищу
- Для управления правами к базам внутри нашего Hadoop используется самописная веб тула поверх AD. В ней мы по таскам раздаем доступы аналитикам к данным конкретных проектов
Концепция Data Lake подразумевает хранение данных из источников AS IS, так что мы приводим их к единому виду уже только на уровне витрин.ivsmodern
14.12.2019 04:12+1Спасибо за ваш ответ.
Относительно гармонизации источников здесь ваш коллега делился аналогичным опытом и описывал подход с RAW>ODD>RDS>MART архитектурой. Подобное видение также исповедует Alex Gorelik в своей работе The Enterprise Big Data Lake. С вашей точки зрения как практика и имея ввиду специфику задач стоящих перед вами это чересчур?PchelinM Автор
14.12.2019 12:29Идея Юры Емельянова из статьи нам близки. Во-первых, они имеют опыт успешной реализации. Во-вторых, Юра был первым архитектором нашего хранилища)
Однако, в нашем случае, при широком хранилище (более 5000 таблиц) и независимых потребителях данных мы не используем слой RDS (или DDS). У нас 3 уровня данных:
- RAW. Он же закрытый от потребителей STG для промежуточного хранения сырья
- ODA (Operational Data Area) для хранения данных в формате близком к AS IS. Таких данных более 95 процентов от всего объема хранилища
- DMA (Data Mart Area) для витрин
Основная причина такого подхода — наши аналитики ходят видеть в хранилище именно ту структуру данных, которая есть в источниках их проектов. Они сами независимо друг от друга выбирают эту структуру со своими разработчиками игр под свои конкретные аналитические нужды.
Единая для всех структура данных создается нами уже только для слоя DMA (витрин), который используется для BI и кросс-проектной аналитики.
somurzakov
хорошая статья, спасибо. если можно пару вопросов, в большинстве случаев по вашему опы у, вы:
somurzakov
еще пару вопросов в догонку: у вас лейк только в проде или аналитики также имебт доступ к дев/тестовой среде, где они могут отточить свои аналитияеские запросы/дешборды прежде чем пушить их в прод?
PchelinM Автор
Прямо сейчас наши аналитики могут создавать свои собственные дашборды и писать любые запросы к хранилищу, однако, не могут писать свой ETL. Его мы полностью контролируем сами. Но скорее всего мы будем менять эту часть и отдавать часть не критичного ETL на сторону аналитиков
PchelinM Автор
Привет, спасибо!