

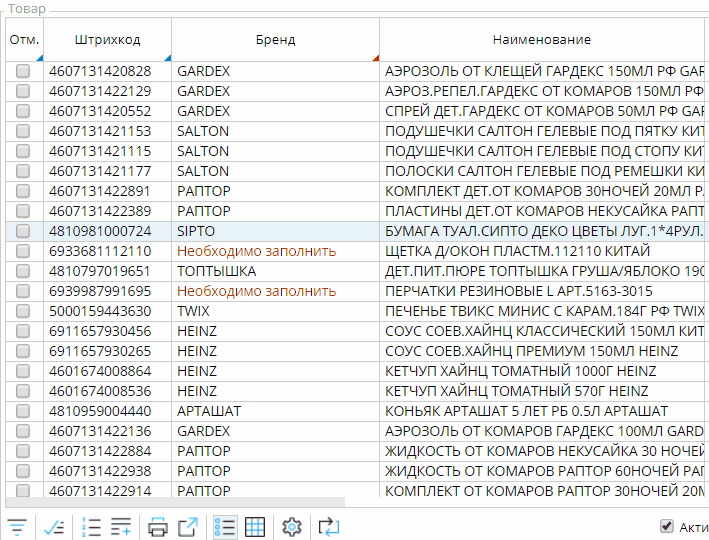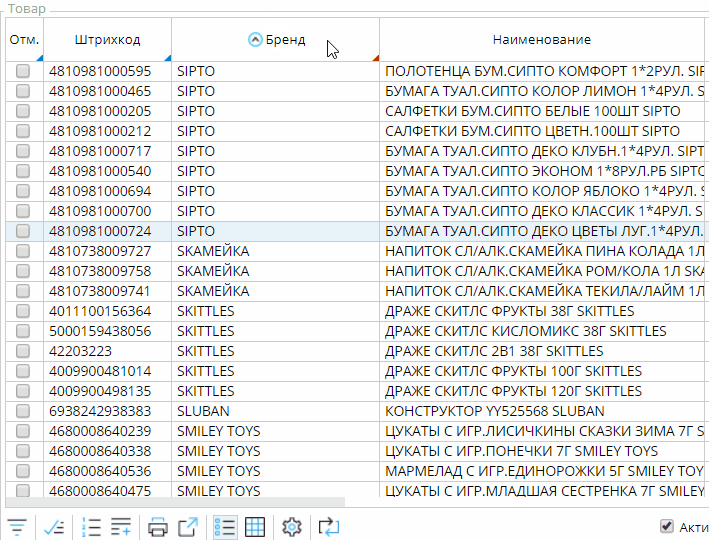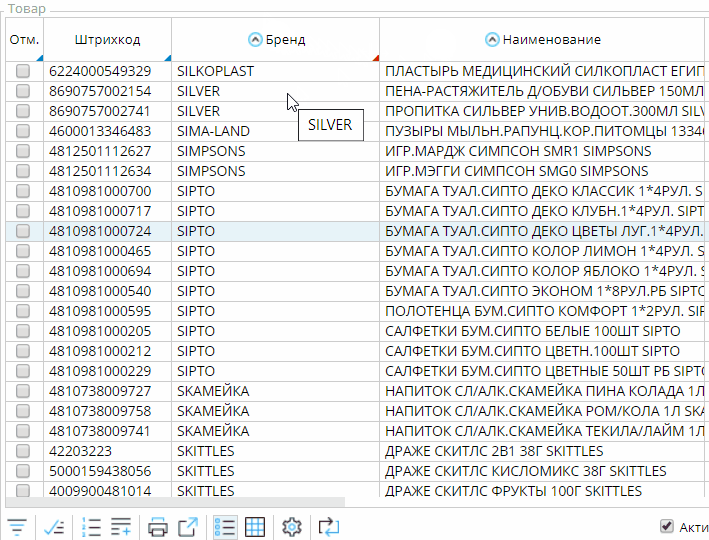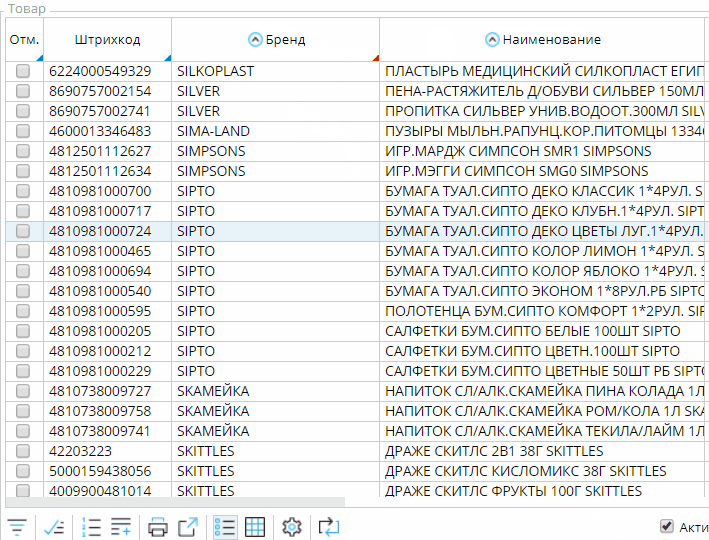
В интерфейсе каждого современного приложения в том или ином виде присутствуют списки объектов. При работе с ними у пользователя часто возникают потребности в однотипных действиях вроде сортировки, фильтраций, экспорта и так далее. Реализация этих операций часто осложняется тем, что списки могут быть “динамическими”. В этом случае данные будут по мере необходимости считываться не только с сервера на клиент, но и с сервера базы данных на сервер приложений.
В открытой и бесплатной платформе lsFusion все списки по умолчанию являются динамическими и добавляются на любую форму в несколько строк кода. В этой статье я расскажу некоторые технические подробности их реализации, а также возможности в интерфейсе, которые автоматически предоставляются пользователю при работе с любым списком на любой форме.
Создание
Списки на форму в lsFusion добавляются инструкцией OBJECTS:
OBJECTS i = Item |
OBJECTS (i = Item, s = Stock) |
Колонки в список добавляются инструкцией PROPERTIES:
PROPERTIES name(i), name(s), quantityOnHand(i, s) |
По умолчанию, в списке будут показаны все объекты, находящиеся в базе данных. Чтобы ограничить их можно использовать инструкцию FILTERS:
FILTERS quantityOnHand(i, s) > 0 |
Навигация
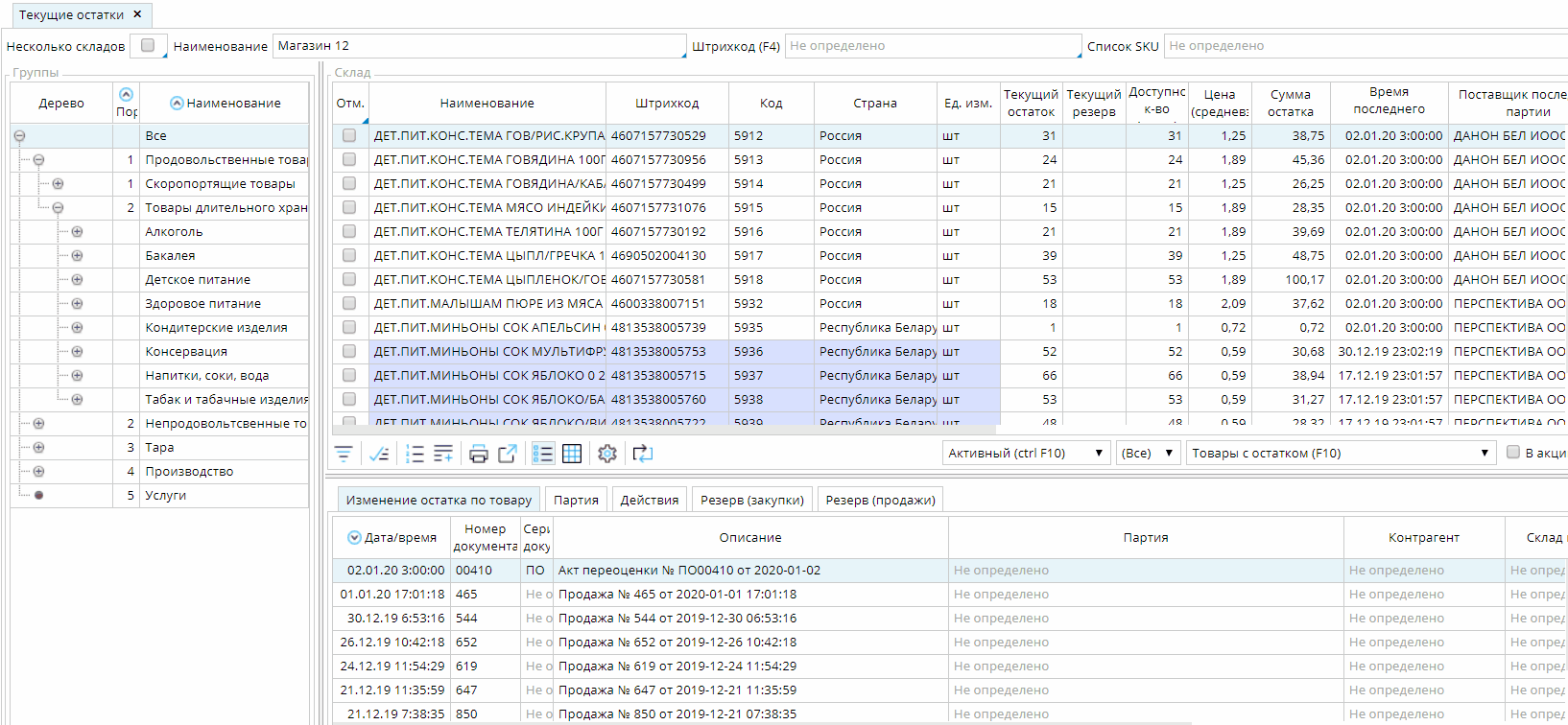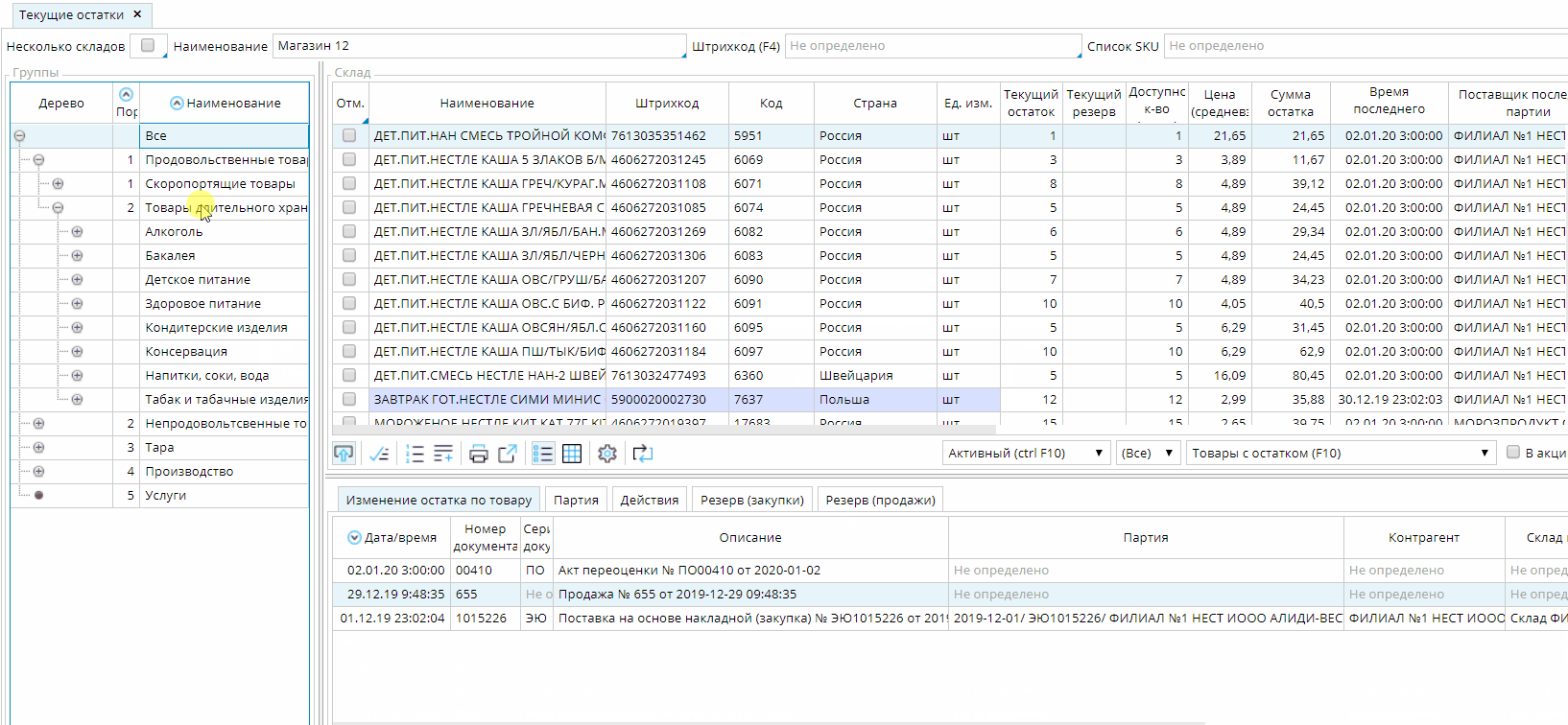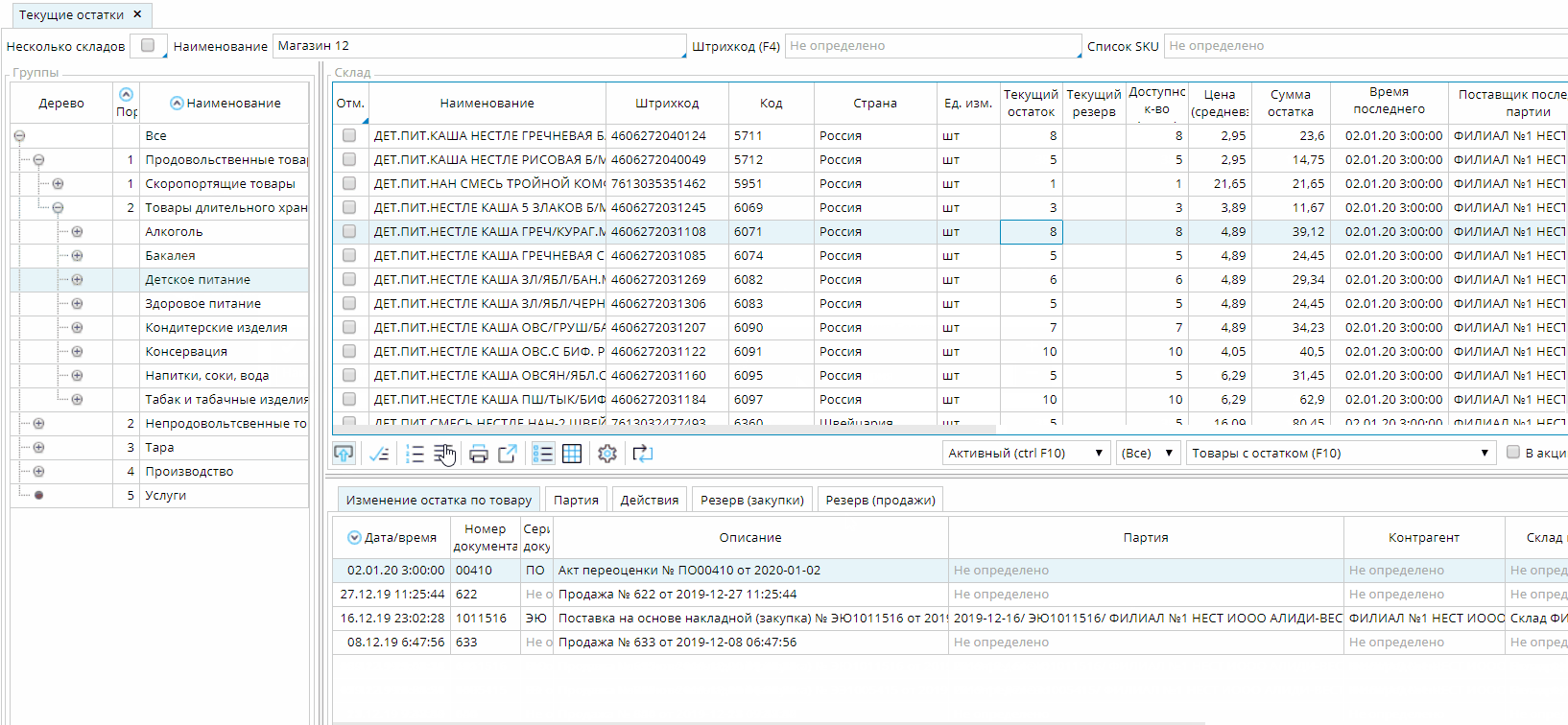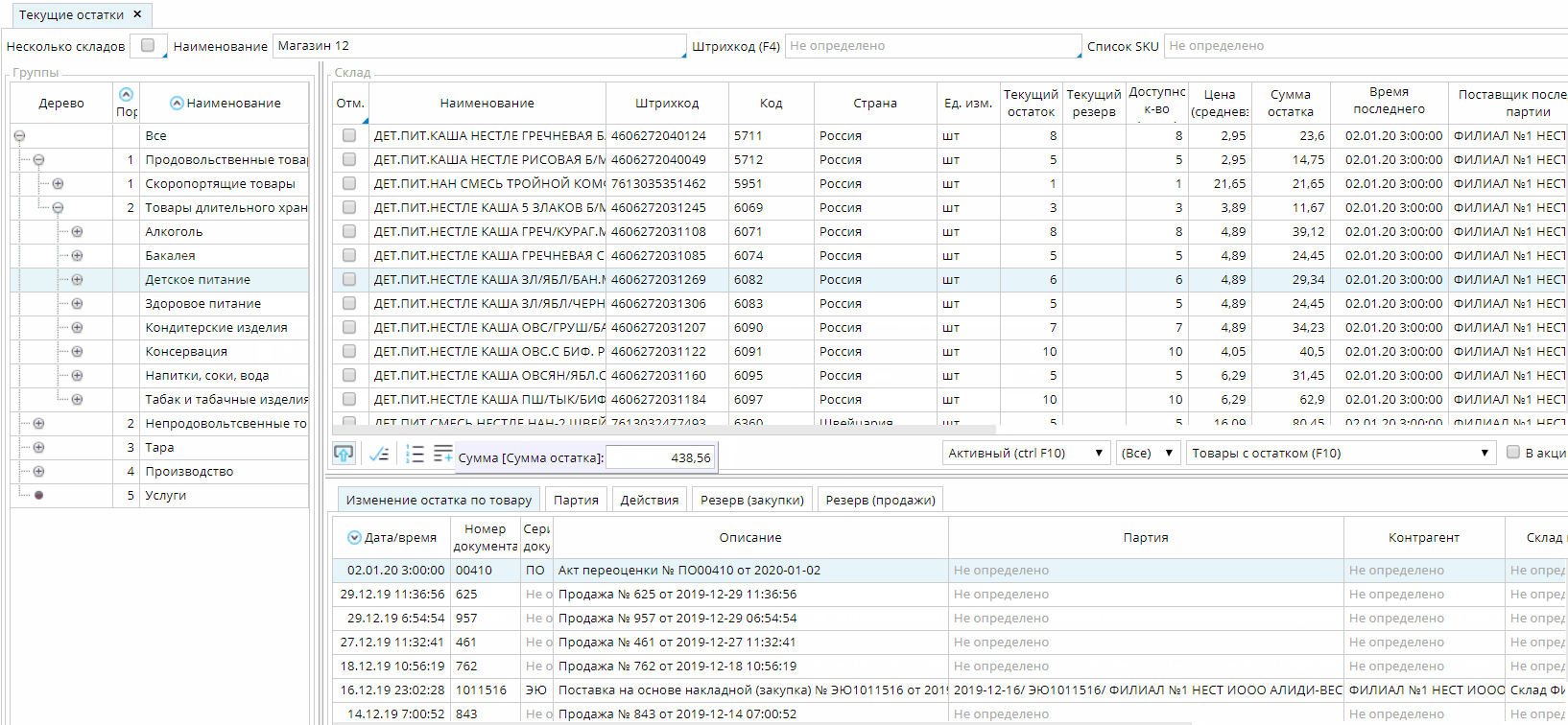
Когда пользователь открывает форму, платформа автоматически определяет количество видимых записей в зависимости от размеров таблицы. Для простоты изложения предположим, что таких записей — 50. В каждый момент времени платформа будет хранить и на клиенте, и на сервере по 150 записей. При этом текущий активный объект должен находиться в середине этого “окна”: с 50й по 99ю запись. Записей может быть меньше, если текущий объект находится либо в самом начале, либо в конце списка.
Если при открытии формы необходимо сделать активной какую-то конкретную запись, то к серверу базы данных делается два запроса, каждый из которых считывает по 75 записей с каждой стороны от нужной записи. Затем из их результатов склеивается общий список. В случае, когда нужно инициализировать список с начала или конца, то делается один запрос на 100 записей, а активной устанавливается первая или последняя полученная запись. То же самое происходит, если пользователь нажимает в списке CTRL+HOME или CTRL+END, чтобы перейти в начало или конец списка.
Как только пользователь делает активной запись за пределами середины текущего окна (до 50й или после 99й), то платформа считывает дополнительные записи таким образом, чтобы текущая запись оказалась в самом “центре” нового окна.
Особенность такой реализации динамического списка заключается в том, что текущий объект не может быть за пределами середины окна. Поэтому при скроллировании списка происходит автоматическое перемещение текущего объекта в видимую область.
Считывание данных в списке всегда происходит в два запроса. Первым запросом считываются только ключи нужных записей во временную таблицу. Вторым запросом считываются значения всех колонок по уже считанным ключам. Так сделано по той причине, что в колонках могут быть любые выражения, которые могут быть скомпилированы в подзапросы или другие сложные SQL конструкции. В этом случае платформа сама проталкивает эти ключи в подзапросы, чтобы расчет значений этих колонок шел не по всей базе данных, а только по нужным ключам. Это создает небольшой overhead, так как делается два запроса вместо одного, но защищает от случайного “попадания” в неэффективный план сервера базы данных.
Фильтрация
Записи в списке на форме могут быть отфильтрованы на основе следующих вариантов:
- Указание в коде постоянного отбора при помощи инструкции FILTERS: Выражение может зависеть от любых других текущих выбранных объектов на форме. Например, если на форме есть таблица или дерево со складом, то в выражении для списка товаров можно обращаться к текущему складу, чтобы отфильтровать только товары, которые есть на остатках.
FILTERS <выражение>
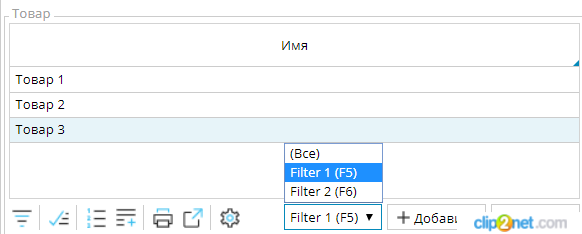
- Указание в коде отбора, который может быть применен пользователем по необходимости при помощи инструкции FILTERGROUP:
На форму будет добавлен выпадающий список (или флажок, если в группе один фильтр), при помощи которого пользователь сможет выбирать один из фильтров, который необходимо применить.FILTERGROUP myFilters
FILTER 'Filter 1' <expression> 'F5' DEFAULT
FILTER 'Filter 2' <expression> 'F6'
- Произвольная фильтрация, сделанная пользователем в интерфейсе вручную:
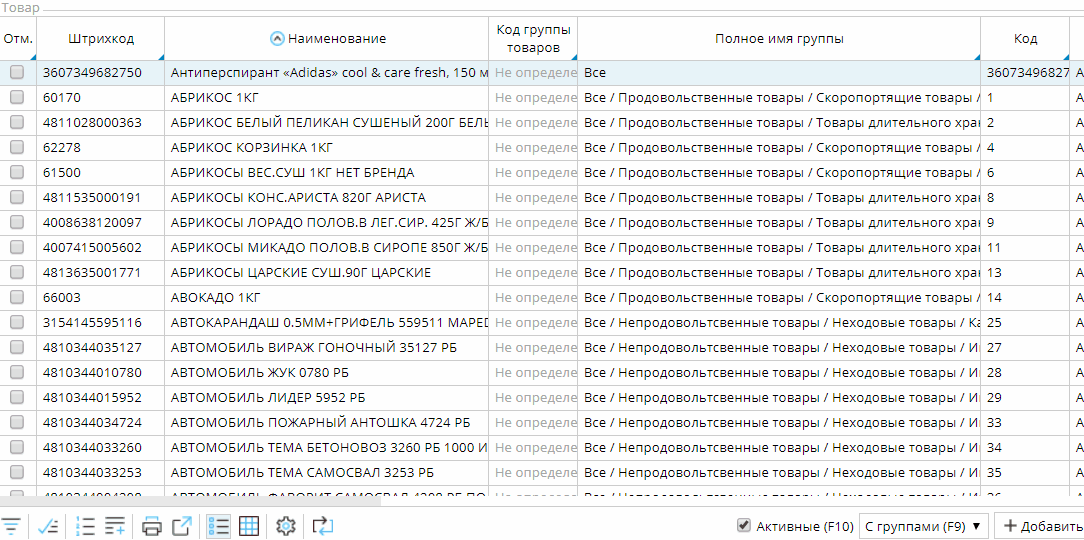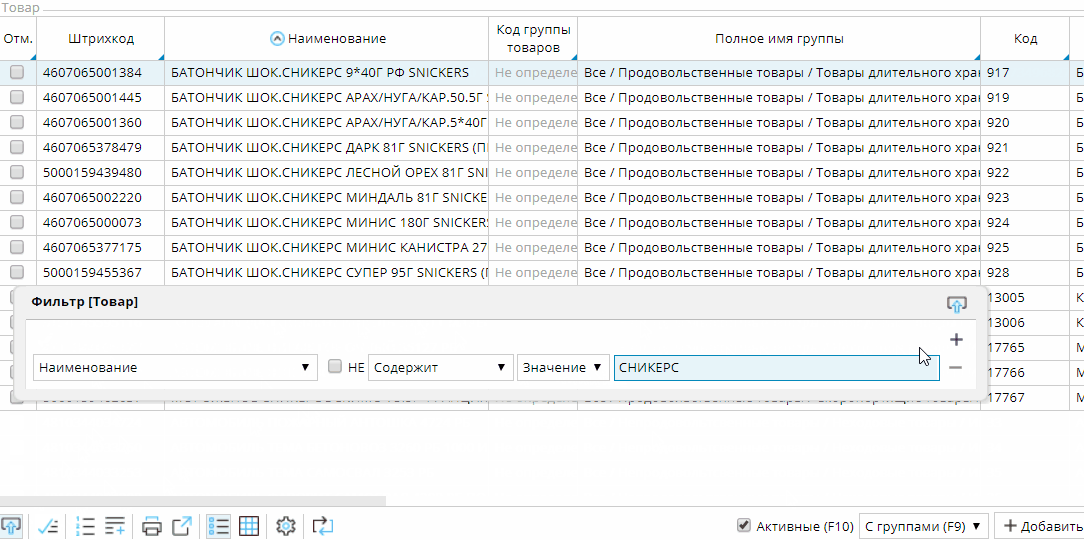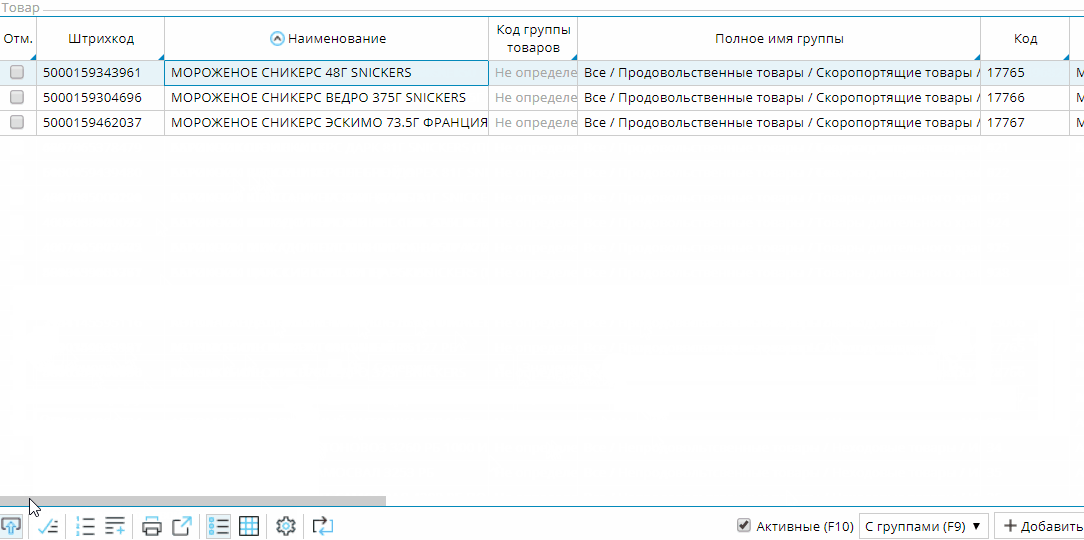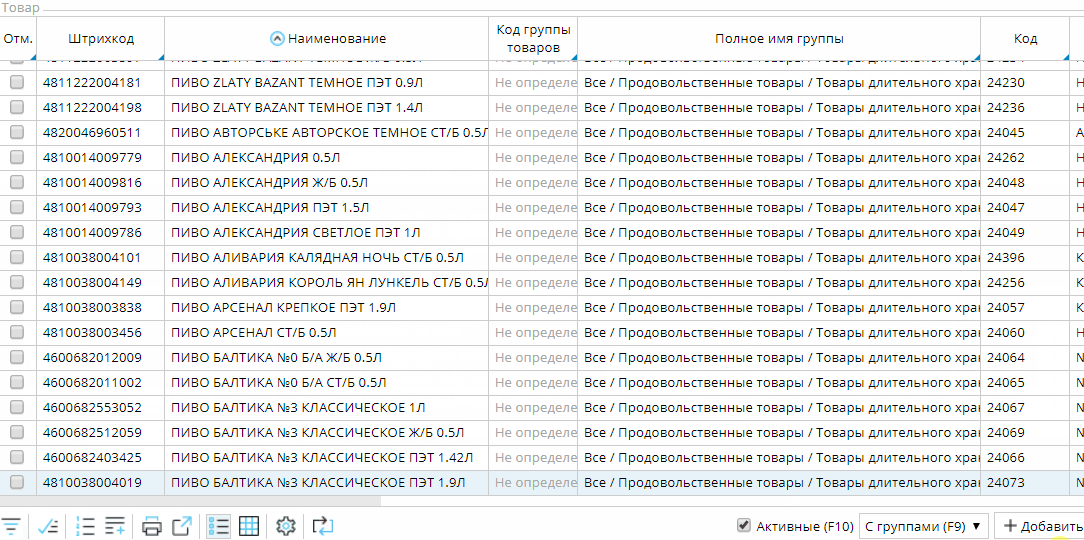
Если колонка в списке не является редактируемой, то при вводе символов будет автоматически включаться фильтр по этой колонке, который можно сбросить одиночным нажатием клавиши ESC.
Платформа сама следит за изменением любых условий, которые могут повлиять на текущий фильтр (изменение зависимых объектов, пользовательские действия и т.д.). При обнаружении таких изменений происходит автоматическое обновление списка, при этом не изменяя текущего выбранного объекта. Для этого делается два запроса по 75 записей в каждую сторону от текущей также как и при инициализации формы.
Сортировка
По умолчанию, записи в списках отсортированы по возрастанию внутренних идентификаторов объектов. Эти идентификаторы автоматически генерируются по возрастанию при создании объектов (при этом глобально уникальны в рамках всех классов), и по ним всегда построены индексы.
Сортировка в списке может быть изменена следующим образом:
- Указанием в коде колонок, по которым идет сортировка через инструкцию ORDER:
ORDER column1(o) DESC, column2(o) - Двойным нажатием мышки пользователем на заголовок колонки (при зажатом CTRL будет добавлена “вложенная” сортировка).
В зависимости от текущей сортировки при считывании ключей записей в блок ORDER BY запроса будут добавлены соответствующие выражения колонок. При этом в сортировку всегда в конец добавляется уникальный идентификатор объекта(ов), чтобы обеспечить уникальность ключей всех записей.
В условие WHERE запроса будет добавлено выражение вида: column1 > value1 OR (column1 = value1 AND column2 > value2) OR (column1 = value1 AND column2 = value2 AND key > value). Также при считывании ключей в запрос будет добавлена инструкция LIMIT с необходимым количеством считываемых записей. При считывании записей “вверх” порядок в ORDER BY и выражение в WHERE будут соответственно “перевернуты”, чтобы считывать записи в обратную сторону.
Следует отметить, что сложность выполнения этих запросов будет относительно небольшой при наличии соответствующего индекса (так как будет осуществляться пробег по индексу, начиная от текущего ключа вверх или вниз только на заданное количество записей). Поэтому для ускорения работы с динамическим списком при сортировке по колонкам column1, column2 рекомендуется построить следующий индекс:
INDEX column1(Object o), column2(o), o; |
Одной из особенностей подобной реализации является отсутствие “честного” скроллбара. При считывании записей осуществляется чтение только нужного их количества. Запрос на получение общего количества рядов в списке через COUNT(*) с нужным фильтром может привести к полному прогону по таблице или индексу, что негативно скажется на производительности. Та же самая проблема будет и при считывании записей через конструкцию OFFSET. Кроме того, следует учитывать, что при навигации по списку количество записей в нем может изменяться другими пользователями путем внесения новых изменений.
Редактирование
Удивительно, но в некоторых даже коммерческих платформах не смогли реализовать возможность редактирования в динамических списках. Основная сложность реализации такого механизма заключается в том, что на сервере и клиенте хранится только видимое окно, а изменения могут быть сделаны в рамках всего списка.
В lsFusion нет какого-то специфического механизма, который реализует непосредственно редактирование в списке. Эта функциональность реализована в рамках общего механизма сессий.
Все изменения, сделанные в текущей сессии изменений, сохраняются во временных таблицах. Когда пользователь что-то редактирует на форме (в том числе и значение в одной из записей), то новые значения записываются во временные таблицы с подходящими ключами. Затем, когда вторым запросом (после получения ключей) идет считывание значений колонок, то в запрос просто добавляется JOIN с соответствующими временными таблицами с изменениями.
При сохранении сессии изменений выполняется запрос, который в одной транзакции записывает все значения из временных таблиц в базу данных.
Групповая корректировка
Достаточно часто у пользователя возникает необходимость изменить значение колонки сразу для всех отобранных объектов в списке. Для этого в тулбаре каждого списка есть специальная кнопка (с горячей клавишей F12). При ее нажатии включается обычный режим редактирования ячейки, но изменения применяются не для текущей записи, а для всех отобранных.
Такой механизм позволяет быстро редактировать большое количество объектов по заданным критериям:

Также, как и при обычном редактировании, изменения не сразу сохраняются в базу данных, а записываются во временные таблицы. Затем пользователю нужно будет нажать кнопку Сохранить для записи их в базу данных. Недостатком такого подхода может быть то, что пользователь случайно изменит лишние данные. Но тут, как говорится, работает принцип: “with great power comes great responsibility”.
Итоги по списку
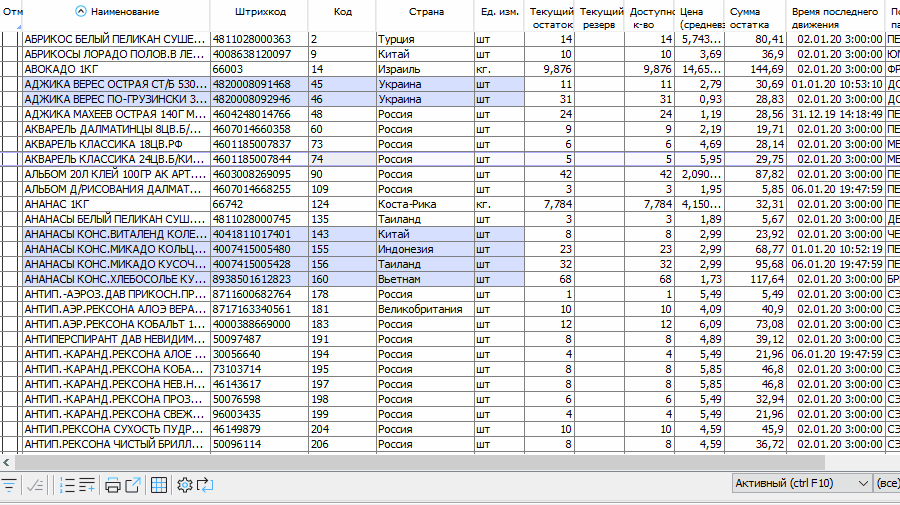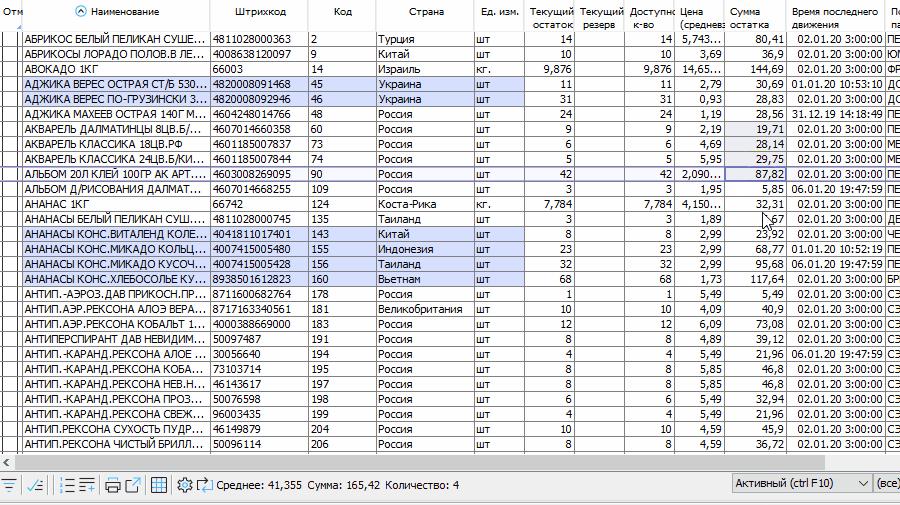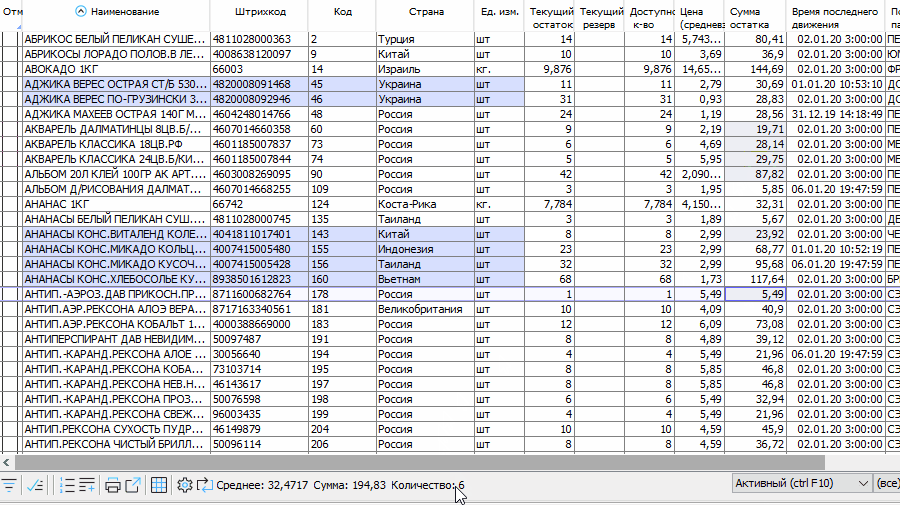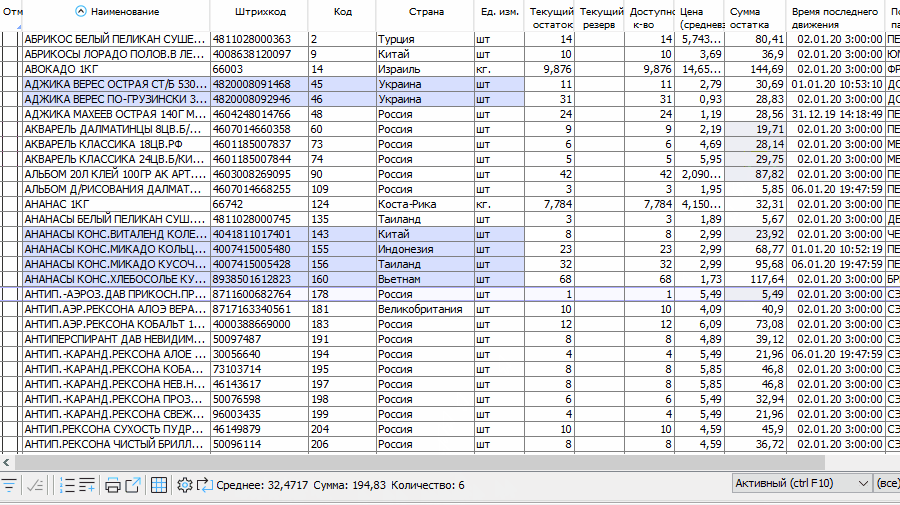
В любом списке пользователю предоставляется возможность узнать количество записей или сумму по определенной колонке в текущем отборе. Для этого пользователю нужно нажать соответствующие кнопки в тулбаре конкретного списка:
Для получения этих данных будет автоматически сформирован запрос с выражением COUNT(*) или SUM, в WHERE которого будет добавлено выражение текущего отбора. При помощи этой возможности можно быстро получать итоги по спискам, не прибегая к формированию отчетов.
В десктоп-версии клиента также есть возможность считать суммы по выделенным ячейкам по аналогии с Excel:
Copy / Paste
В десктоп-версии пользователю предоставлена возможность отметить определенные ячейки, нажать CTRL+C, и вставить значения из них в буфер обмена:
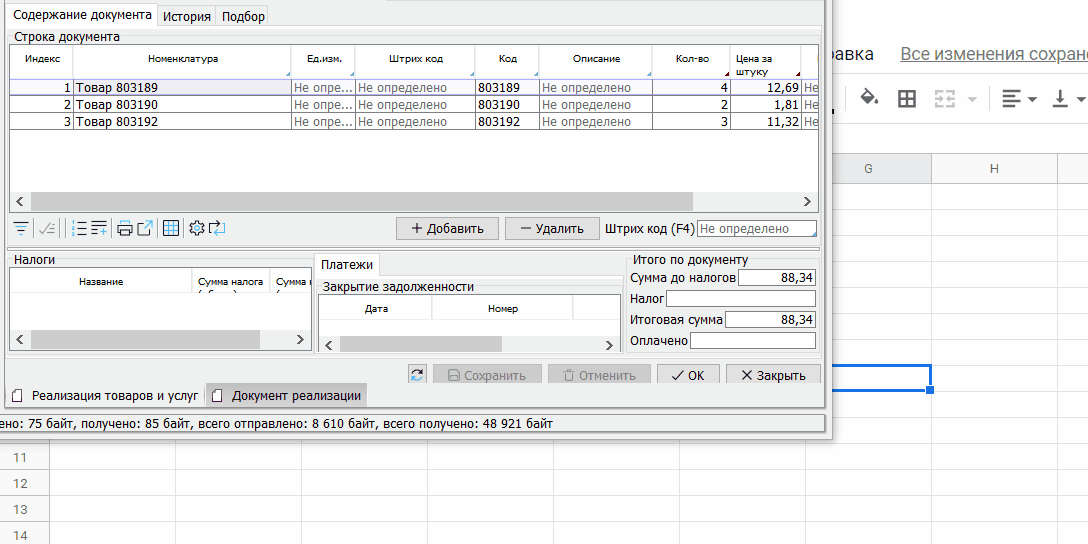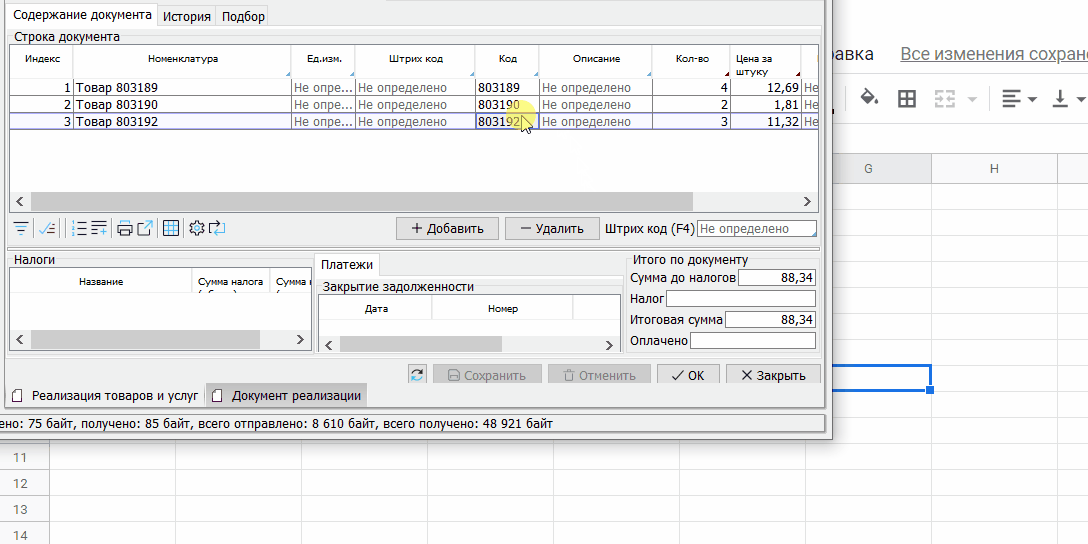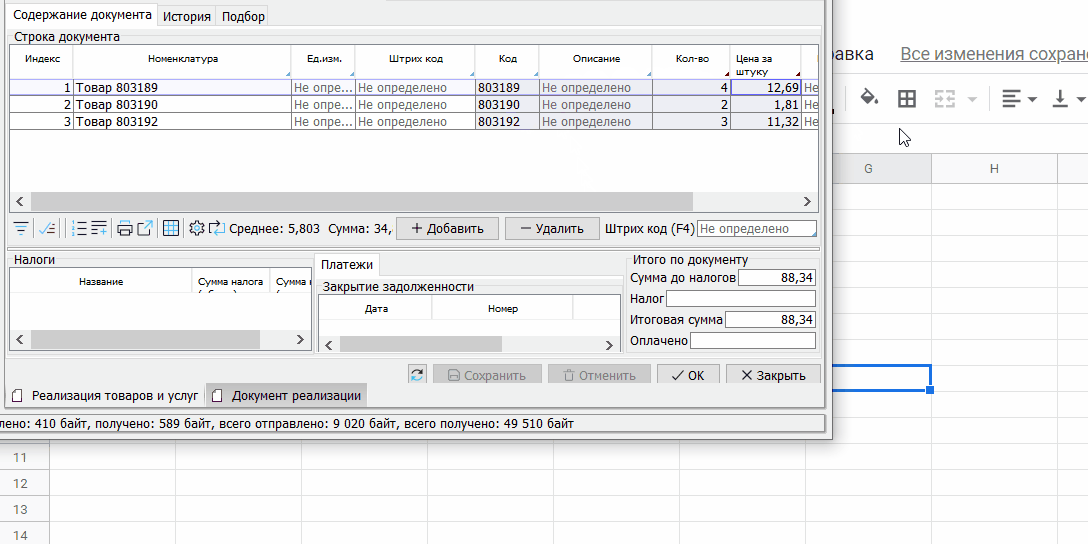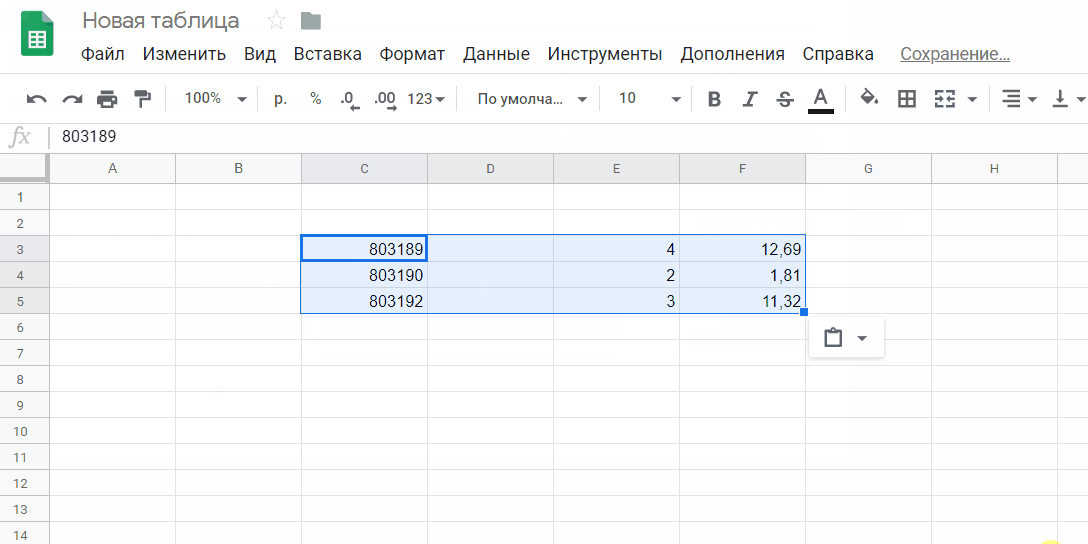
Точно так же можно из буфера обмена вставить таблицу в любой редактируемый список на любой форме:

Такая возможность часто является альтернативой разработке специализированного импорта.
Настройка таблицы
В любом списке можно изменить некоторые его параметры:
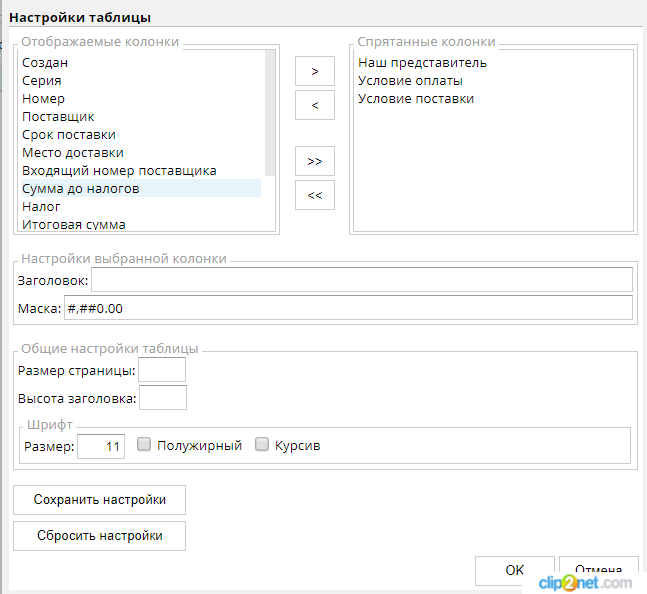
Можно изменить состав колонок, их размеры, заголовки, маски и так далее. Сохранить настройки таблицы можно как для текущего пользователя, так и для всех пользователей (если у текущего пользователя есть нужные права).
Следует отдельно отметить параметр Размер страницы. При помощи него можно изменять размер “окна”, описанного в начале статьи. Например, вместо автоматических 50 записей можно указать большее значение. Тогда на клиент и сервер будет загружаться больший объем данных, но запросы будут происходить реже. Установка значения этого параметра в 0 сделает из любого динамического списка обычный, то есть всегда будут считываться все записи списка. Величину размера окна можно также указать непосредственно в коде при помощи параметра pageSize инструкции DESIGN.
Экспорт в Excel
Для любого списка существует возможность выгрузки всех его записей в Excel. Для этого достаточно нажать следующую кнопку:

При этом учитываются текущие отборы, сортировки, а также только видимые колонки, указанные в настройке таблицы.
Pivoting
По умолчанию, любой список показывается в виде таблицы. Но существует возможность переключить его в специальный режим отображения, в котором пользователь может строить различные отчеты и диаграммы:
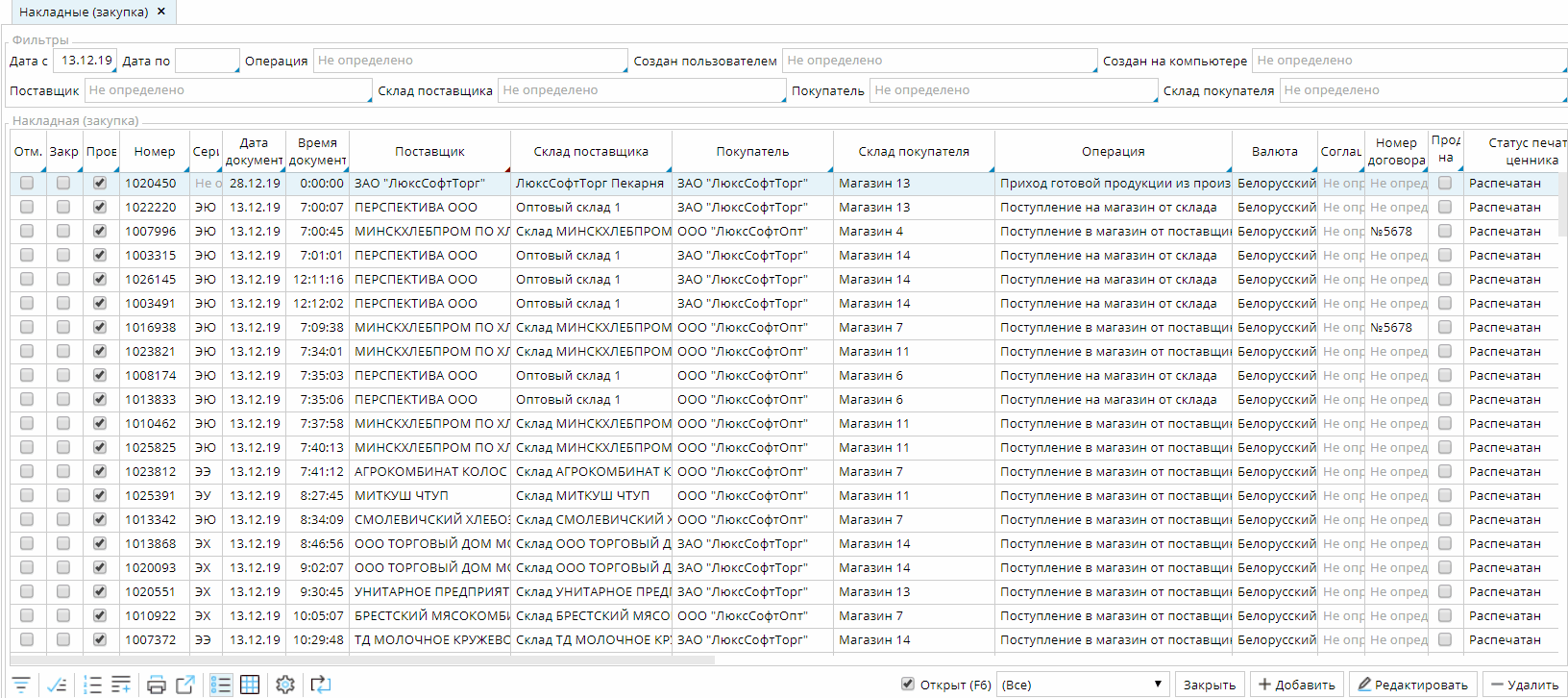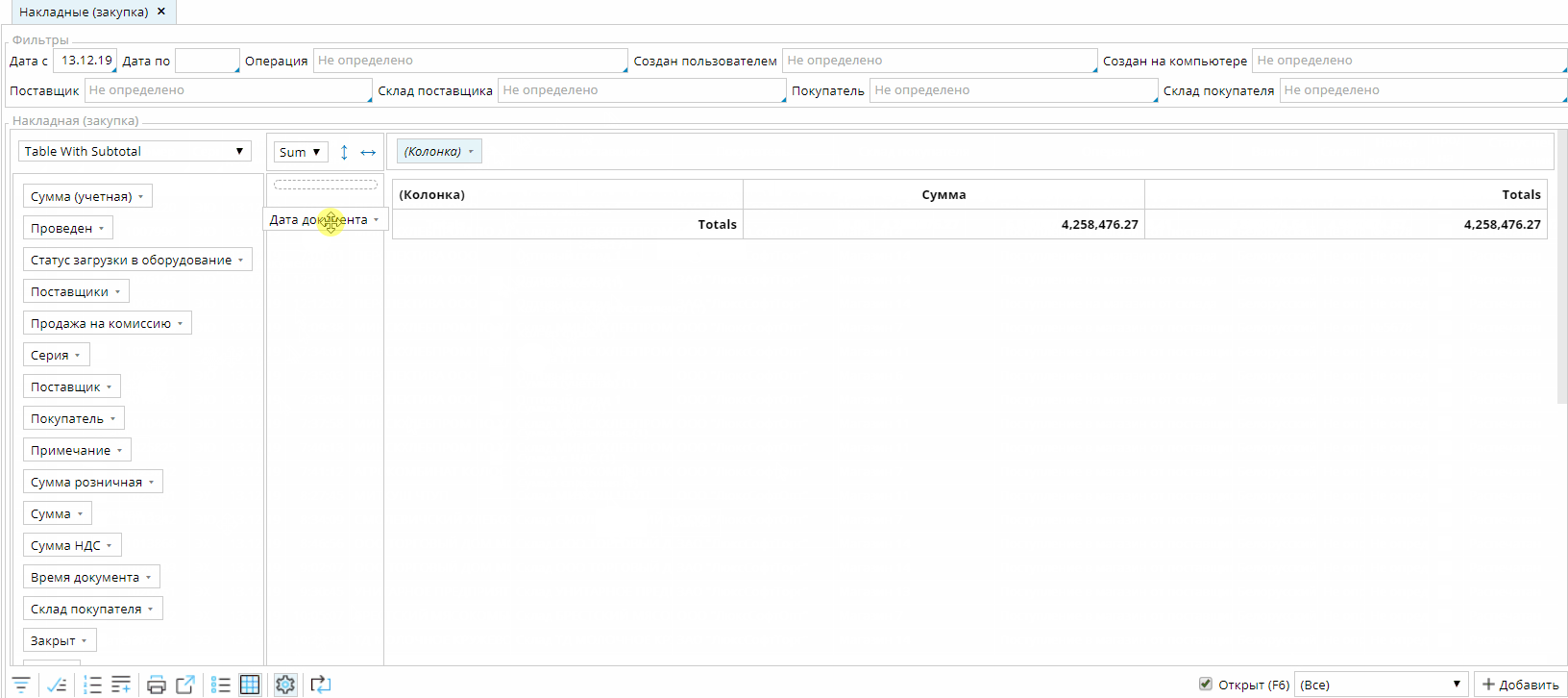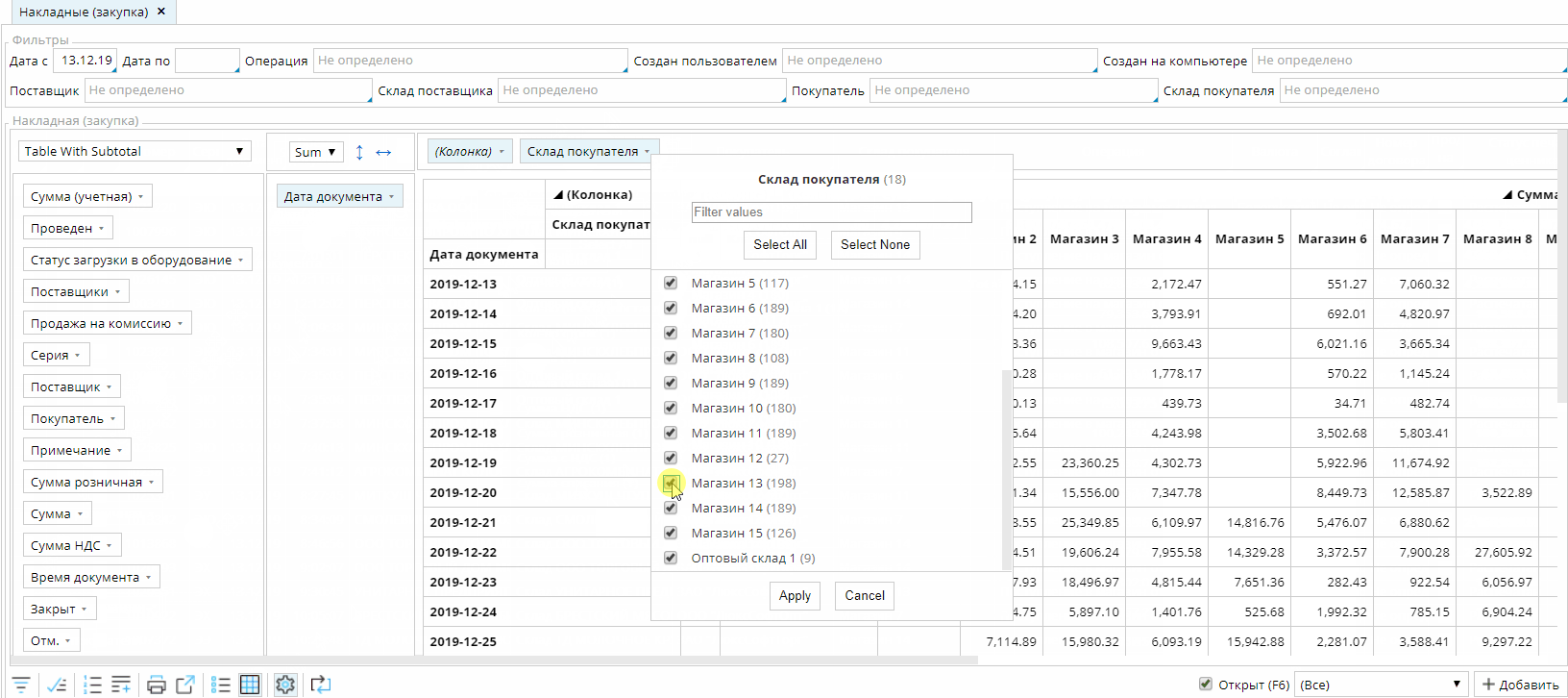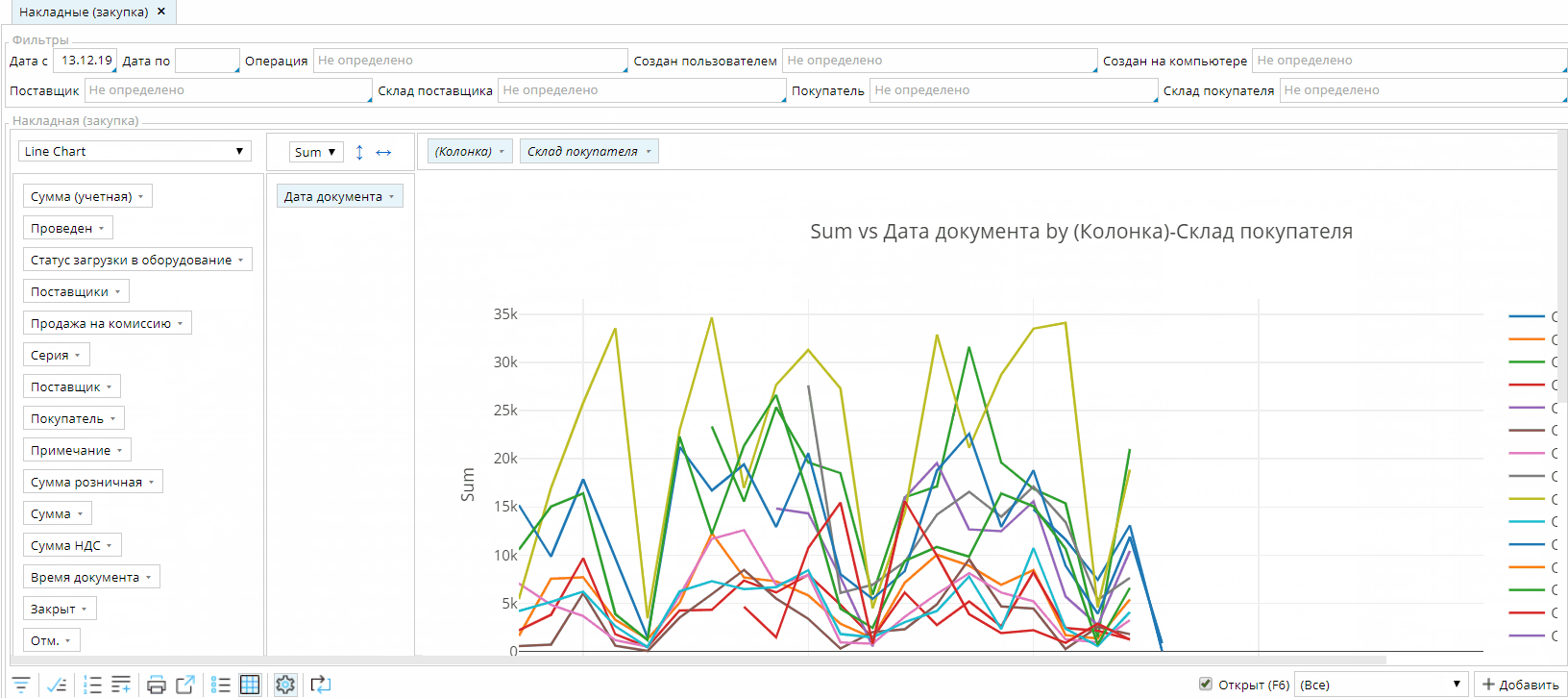
При небольшом количестве записей в списке работа с данными будет происходить непосредственно на клиенте. Как только количество данных превышает определенный порог, то для группировки данных будут использоваться автоматически сгенерированные запросы к базе данных на сервере.
Альтернатива
Возникает резонный вопрос. Каким образом решают проблему редактирования динамических списков в платформах, где такая возможность не поддерживаются. Чаще всего делают простой список, заставляя пользователь какими-то отборами ограничивать количество записей (например, указывать фильтры по категориям, поставщикам или другим связанным справочникам).
Однако этот подход имеет одну серьезную проблему. Даже при установленных отборах нет никакой гарантии, что в выборке не окажется значительное количество записей. Вычислить заранее количество получаемых значений невозможно, так как часто сложность такой операции сравнима непосредственно со сложностью получения всех данных. Соответственно, в некоторых случаях в список будет добавлено большое количество записей, что приведет к большому потреблению ресурсов на сервере или клиенте, а также значительному снижению производительности.
Заключение
Реализация динамического списка в современной разработке является не самой тривиальной задачей, поскольку в нее вовлечены как клиентская, так и серверная часть. В мире существует достаточно мало библиотек с открытым исходным кодом и открытой лицензией, позволяющих быстро и удобно реализовать эту функциональность.
В открытой и бесплатной платформе lsFusion динамические списки создаются в несколько строк кода и предоставляют пользователю большое количество возможностей по работе с ними. В сочетании с возможностью редактирования таких списков платформа позволяет очень быстро работать с документами на сотни тысяч строк, организовывать удобную работу по подбору записей в документы, проводить групповые изменения справочников и многое другое.
Использование динамических списков позволяет значительно снизить потребление процессорного времени и памяти на сервере и клиенте за счет работы с ограниченным набором данных, а также уменьшить загрузку канала связи между сервером и клиентом. За счет такой высокой эффективности на решениях на базе платформы lsFusion в Беларуси осуществляют свою основную операционную деятельность пять из восьми крупнейших розничных сетей.
bakhirev
Хорошая статья. Хотелось бы подробнее узнать про: ролевую модель, реализацию работы с графиками и другие «фичи» интерфейса.
vandrouny Автор
Спасибо за комментарий. Про ролевую модель будет отдельная статья, куда войдет все то, что связано с поддержкой / управлением системы (то есть политика безопасности, интерпретатор, монитор процессов, планировщик, профилировщик и т.п.).
Что касается работы с графиками, это все в рамках сводных таблиц (группировок), который позволяет кроме таблиц, подключать и другие рендереры, в частности plot.ly/javascript (в гифке есть пример). Для настройки самих сводных таблиц используется: pivottable.js.org/examples, для отображения в виде таблицы: github.com/nagarajanchinnasamy/subtotal. Правда их пришлось еще допиливать, так как они умеют показывать либо все подитоги, либо вообще никаких. Но благо одно из преимуществ open-source, что у популярных небольших библиотек код как правило вполне читабельный, так что это не было такой уж проблемой.
В любом случае разработчик на lsFusion от этого всего абстрагирован (если ему не интересно). Для него все — списки просто с разными представлениями (таблица, группировки (таблица, графики), карта, календарь). Правда в 3-й версии (как и в демках на 4) там еще далеко не все подключено. Как доделаем, сразу будет статья про эту версию где все будет подробно расписано. Плюс там же будет про настройки пользователем интерфейсов (там в 4-й версии будет еще добавление новых колонок, выбор «вариантов» формы из наследуемых форм / сохраненных пользователем и т.п.)