

Не так давно перед нами стояла задача найти и извлечь печати с документов. Зачем? Например, для проверки наличия печатей в договорах с двух сторон (участников договора). У нас в закромах уже был прототип для их поиска, написанный на OpenCV, но он был сыроват. Решили откопать данный реликт, стряхнуть с него пыль и на его основе сделать рабочее решение.
Большинство приемов, описанных здесь, можно применить и вне задачи поиска печатей. Например:
- цветовая сегментация;
- поиск круглых объектов / окружностей;
- конвертация изображения в полярную систему координат;
- пересечение объектов, Intersection over Union (IoU, Коэффициент Жаккара).
В итоге, у нас было два варианта: решать с помощью нейронных сетей или же воскресить прототип на OpenCV. Почему мы решили взять OpenCV? Ответ в конце статьи.
Примеры кода будут представлены на Python и C#. Для Python потребуется пакет opencv-python и numpy, для C# — OpenCvSharp и opencv.
Надеюсь, что вы знакомы с основными алгоритмами OpenCV. Глубоко в них я погружаться не буду, так как большая часть заслуживает отдельной, подробной статьи, но оставлю ссылки с мат. частью всем жаждущим.
Забегая вперед скажу, что алгоритм работает только с цветными изображениями (так как основан на HLS-сегментации), а для поиска окружностей используется преобразование Хафа. Изначальное качество прототипа было не очень высоким из-за ложных срабатываний на шуме, оставшемся после сегментации цвета, и ложных срабатываний на рукописном тексте.
Решили фильтровать ложные срабатывания. Использовали несколько подходов – проверку на заполненность области и перевод из полярной системы координат в прямоугольную.
Что, кого и как? Начнем по порядку.
Оценка работы алгоритма
Начну с оценки качества. Когда у вас есть под рукой инструмент/скрипт для проверки, то легко отслеживать свой прогресс при разработке, поэтому всем рекомендую сначала запастись чем-то, что поможет вам понять, продвигаетесь вы или стоите на месте.
Для начала мы набрали документов, разметили, написали скрипт на python для проверки и оценки качества. Наш алгоритм возвращал описывающий прямоугольник для печати (на самом деле, можно было бы использовать и круг, но размечать прямоугольниками проще и быстрее). Далее мы сравнивали эталонные прямоугольники и найденные алгоритмом с помощью коэффициента Жаккара (или же Intersection over Union), насколько точно мы попали при поиске.
Коэффициент Жаккара не выглядит сложным и представляет собой отношение пересечения множеств над их объединением:
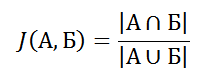
Для изображений это выглядит примерно так:
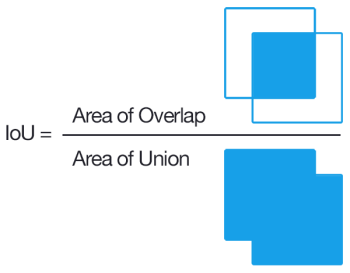
Коэффициент равен нулю, когда множества не имеют общих элементов между собой, и единице, когда множества равны, во всех остальных случаях значение будет где-то между нулем и единицей. Соответственно, чем ближе к единице, тем точнее мы попали при поиске, например:
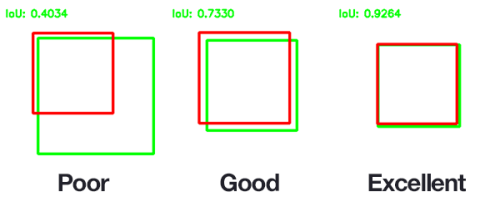
Далее подбираем приемлемый для нас порог точности (нас устроил 0.6) и считаем полноту, точность и F1-меру по найденным объектам (в нашем случае — печатям).
import sys
from collections import namedtuple
Metrics = namedtuple("metrics", ["tp", "fp", "fn"])
def bb_intersection_over_union(a, b):
# Координаты заданы в виде верхнего левого и правого нижнего угла прямоугольника.
# 0 - координата X для верхнего левого угла,
# 1 - координата Y для верхнего левого угла,
# 2 - координата X для правого нижнего угла,
# 3 - координата Y для правого нижнего угла.
x_a = max(a[0], b[0])
y_a = max(a[1], b[1])
x_b = min(a[2], b[2])
y_b = min(a[3], b[3])
# Площадь пересечения.
inter_area = max(0, x_b - x_a + 1) * max(0, y_b - y_a + 1)
# Площади прямоугольников.
a_area = (a[2] - a[0] + 1) * (a[3] - a[1] + 1)
b_area = (b[2] - b[0] + 1) * (b[3] - b[1] + 1)
# Intersection over Union.
iou = inter_area / float(a_area + b_area - inter_area)
return iou
def same_stamp(a, b):
"""Проверка, что печати находятся в одном и том же месте"""
iou = bb_intersection_over_union(a, b)
print(f'iou: {iou}')
return iou > 0.6
def compare_stamps(extracted, mapped):
"""
Посчитать метрики
:param extracted: Печати, извлеченные алгоритмом.
:param mapped: Размеченные (эталонные) печати.
"""
tp = []
fp = []
fn = list(mapped)
for stamp in extracted:
for check in fn:
if same_stamp(stamp, check):
tp.append(check)
fn.remove(check)
break
else:
fp.append(stamp)
return Metrics(len(tp), len(fp), len(fn))
def compare(file, sectors):
"""
Посчитать метрики для конкретного файла.
:param file: Путь до файла.
:param sectors: Размеченные печати.
"""
print(f'file: {file}')
try:
stamps = extract_stamps(file) # Это метод, который возвращает нам координаты печатей.
metrics = compare_stamps(stamps, [ss for ss in sectors if 'stamp' in ss['tags']])
return file, metrics
except:
print(sys.exc_info())
return file, Metrics(0, 0, 0)
if __name__ == '__main__':
file_metrics = {}
# dataset - словарь, который содержит путь до файлов в паре с координатами заранее размеченных (эталонных) печатей.
for file, sectors in dataset.items():
file_metrics[file] = compare(file, sectors)
# Подсчет точности, полноты и F1-меры.
total_metrics = Metrics(*(sum(x) for x in zip(*file_metrics.values())))
precision = total_metrics.tp / (total_metrics.tp + total_metrics.fp) if total_metrics.tp > 0 else 0
recall = total_metrics.tp / (total_metrics.tp + total_metrics.fn) if total_metrics.tp > 0 else 0
f1 = 2 * precision * recall / (precision + recall) if (precision + recall) > 0 else 0
print('precision\trecall\tf1')
print('{:.4f}\t{:.4f}\t{:.4f}'.format(precision * 100, recall * 100, f1 * 100).replace('.', ','))
print('tp\tfp\tfn')
print('{}\t{}\t{}'.format(total_metrics.tp, total_metrics.fp, total_metrics.fn))
print('tp\tfp\tfn')
for file in dataset.keys():
metric = file_metrics.get(file)
print(f'{metric.tp}\t{metric.fp}\t{metric.fn}')
print(f'precision: {precision}, recall: {recall}, f1: {f1}, {total_metrics}')HLS-сегментация
Цветовая сегментация позволяет извлечь (отфильтровать) определенную цветовую часть изображения для какого-либо диапазона цветового пространства. Нам это нужно, чтобы отделить текст документа от печатей. Итоговый результат выглядит примерно вот так (чувствительные данные замазаны):

Разберем же все по кусочкам.
Начнем с HLS палитры. Сама аббревиатура расшифровывается как Hue, Lightness, Saturation, что переводится как тон, светлота, насыщенность. Изобразить данное цветовое пространство можно так:
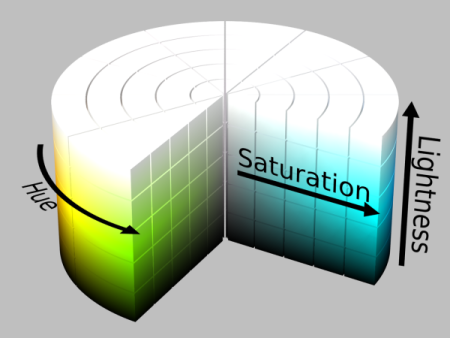
Почему же именно она нам подошла больше всего? На такой палитре очень легко отделить какой-то один цвет взяв нужный нам диапазон тона. В нашем случае это синий и его оттенки, а именно диапазон от ~180 до ~280.
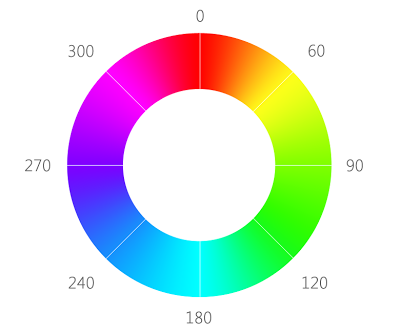
Так же выставляем нижний порог для насыщенности, так как мы не хотим извлекать или тускло-синий и серый цвет, и порог светлоты, так как мы не хотим извлекать черный и белый.
def colored_mask(img, threshold = -1):
# Размытие для удаления мелких шумов.
denoised = cv2.medianBlur(img, 3)
cv2.imwrite('denoised.bmp', denoised)
# Сохранение в ЧБ для получения маски.
gray = cv2.cvtColor(denoised, cv2.COLOR_BGR2GRAY)
cv2.imwrite('gray.bmp', gray)
# Получение цветной части изображения.
adaptiveThreshold = threshold if threshold >= 0 else cv2.mean(img)[0]
color = cv2.cvtColor(denoised, cv2.COLOR_BGR2HLS)
mask = cv2.inRange(color, (0, int(adaptiveThreshold / 6), 60), (180, adaptiveThreshold, 255))
# Создание маски цветной части изображения.
dst = cv2.bitwise_and(gray, gray, mask=mask)
cv2.imwrite('colors_mask.bmp', dst)
return dstprivate void ColoredMask(Mat src, Mat dst, double threshold = -1)
{
using (var gray = new Mat())
using (var color = new Mat())
using (var mask = new Mat())
using (var denoised = new Mat())
{
// Размытие для удаления мелких шумов.
Cv2.MedianBlur(src, denoised, 3);
denoised.Save("colors_denoised.bmp");
// Сохранение в ЧБ для получения маски.
Cv2.CvtColor(denoised, gray, ColorConversionCodes.BGR2GRAY);
gray.Save("colors_gray.bmp");
// Получение цветной части изображения.
var adaptiveThreshold = threshold < 0 ? src.Mean()[0] : threshold;
Cv2.CvtColor(denoised, color, ColorConversionCodes.BGR2HLS);
Cv2.InRange(color, new Scalar(0, adaptiveThreshold / 6, 60), new Scalar(180, adaptiveThreshold, 255), mask);
// Создание маски цветной части изображения.
Cv2.BitwiseAnd(gray, gray, dst, mask);
dst.Save("colors_mask.bmp");
}
}В результате мы получим нечто похожее на это:

Из важных аспектов хочу отметить, что тон для HLS в OpenCV задан значениями не от 0 до 360, а от 0 до 180. Причина банальна — разработчики хотели вместить доступный диапазон в uint8/uchar/byte, которые вмещают значения от 0 до 255, и поэтому поделили 360 на 2.
Поиск окружностей
Окей, мы нашли цвет, а что дальше? Нам же нужны были печати, а не всё, что подходит под “цвет настроения синий”.
Тут мы прибегнем к уже упомянутому ранее преобразованию Хафа, с помощью которого можно довольно точно находить эллипсы и окружности. Здесь, здесь и здесь (читать именно в данной последовательности) приведено очень хорошее и подробное описание преобразования Хафа, так что те, кто жаждет знаний — можете заглянуть туда. Здесь описывать не буду, так как это тема для отдельной статьи.
А мы, тем временем, применим его для поиска окружностей. Благо в OpenCV он уже реализован, нужно всего лишь вызвать его для нашей маски синего цвета, и все сразу заработает. Также стоит упомянуть, что в текущей реализации преобразования Хафа для поиска окружностей встроен детектор границ Кенни, что немного упрощает жизнь.
# mask - маска, полученная после сегментации;
# method: метод поиска окружностей (в OpenCV реализован только Gradient);
# dp: разрешение, используемое для детектирования центров кругов (1 — одинаково с исходным изображением, 2 — половина высоты/ширины и т.д. Чем ниже это значение (т.е. выше разрешение), тем больше “голосов” нужно отдать какому-либо объекту, чтобы принять его за круг. Это повышает точность, но плохо “пропечатанные” окружности могут не найтись);
# minDist: минимальное расстояние между окружностями (мы брали % от ширины изображения);
# param1: верхнее пороговое значение, передаваемое детектору границ Кенни (нижнее пороговое значение будет в 2 раза меньше);
# param2: суммирующее пороговое значение детектированя центров;
# minRadius: минимальный радиус круга;
# maxRadius: максимальный радиус круга;
circles = cv2.HoughCircles(mask, cv2.HOUGH_GRADIENT, 1, 20, param1, param2, minRadius, maxRadius)
# Отобразим найденные окружности.
circles = np.uint16(np.around(circles))
cimg = cv2.cvtColor(img,cv2.COLOR_GRAY2BGR)
for i in circles[0,:]:
cv2.circle(cimg,(i[0],i[1]),i[2],(165,25,165),2)// mask - маска, полученная после сегментации;
// method: метод поиска окружностей (в OpenCV реализован только Gradient);
// dp: разрешение, используемое для детектирования центров кругов (1 — одинаково с исходным изображением, 2 — половина высоты/ширины и т.д. Чем ниже это значение (т.е. выше разрешение), тем больше “голосов” нужно отдать какому-либо объекту, чтобы принять его за круг. Это повышает точность, но плохо “пропечатанные” окружности могут не найтись);
// minDist: минимальное расстояние между окружностями (мы брали % от ширины изображения);
// param1: верхнее пороговое значение, передаваемое детектору границ Кенни (нижнее пороговое значение будет в 2 раза меньше);
// param2: суммирующее пороговое значение детектирования центров;
// minRadius: минимальный радиус круга;
// maxRadius: максимальный радиус круга;
var houghCircles = Cv2.HoughCircles(morphed, HoughMethods.Gradient, 1, max, cannyEdgeThreshold, houghThreshold, min, max);
// Отобразим найденные окружности.
foreach (var circle in houghCircles)
Cv2.Circle(morphed, circle.Center, (int)circle.Radius, new Scalar(165, 25, 165), 2);Пробуем и получаем вот это:

Как видно из результата, не всё так гладко, как хотелось бы. Мы нашли окружность совсем не там, где хотели, а на месте шума. Да, мы могли бы подобрать идеальные коэффициенты для данного документа, где удалился бы весь шум, но остались печати. Ко всему пространству документов такой подход не применим (где-то печати “улетают” с документов из-за слишком больших порогов при отделении цвета, где-то шум принимается за окружность).
Фильтрация
В итоге нам нужно было что-то делать с ложными срабатываниями. Поэтому мы придумали несколько подходов.
Первый заключается в том, чтобы проверить на заполненность ту область, которую мы считаем за круг. Так как шум обычно представлял из себя “небольшое” скопление пикселей, вооружились теорией, что такие ложные участки будут не сильно заполнены. В итоге — вырезаем круг, проверяем.

Как видно из картинки, где мы вырезали возможные круги, место с шумом намного меньше заполнено, чем корректные места. Но не всё так просто. Печати не всегда проставляются четко, и они могут попасть под этот фильтр. Но в качестве “наивного” способа эта фильтрация может сработать.
def equals(first, second, epsilon):
diff = cv2.subtract(first, second)
nonZero = cv2.countNonZero(diff)
area = first.size * epsilon
return nonZero <= area
for i in circles[0, :]:
empty = np.zeros((256, 256, 1), dtype="uint8")
cv2.circle(empty, (i[0], i[1]), i[2], (255, 255, 255), -1)
crop = img * (empty.astype(img.dtype))
cv2.imwrite('crop.bmp', crop)
if not equals(crop, empty, threshold):
result.append(i)foreach (var circle in circles)
{
var x = (int) circle.Center.X;
var y = (int) circle.Center.Y;
var radius = (int) Math.Floor(circle.Radius);
using (var empty = Mat.Zeros(src.Rows, src.Cols, MatType.CV_8UC1))
using (var mask = empty.ToMat())
using (var crop = new Mat())
{
// Вырезание круга (печати) для следующей проверки.
Cv2.Circle(mask, x, y, radius, Scalar.White, -1);
src.CopyTo(crop, mask);
crop.Save("crop.bmp");
// Проверка на заполненность пикселями.
if (!MatEquals(crop, empty, threshold))
result.Add(circle);
}
}
private bool MatEquals(Mat a, Mat b, double epsilon = 0.0)
{
var notEquals = a.NotEquals(b);
var nonZero = Cv2.CountNonZero(notEquals);
var area = a.Rows * epsilon * a.Cols;
return nonZero <= area;
}Для ложных срабатываний на шумах этого метода хватает. А вот что же делать, например, с рукописным текстом, который остается после отделения цвета из-за синей пасты и не проходит эту фильтрацию?
А что если мы возьмем все имеющиеся контуры на изображении, впишем в них эллипсы и посмотрим насколько эллипс – круг, а точнее – отношение малой (minor) оси к большой (major) (можно было бы сразу вписывать окружности, но тогда был шанс напороться на большой шум, который был бы воспринят как печать).
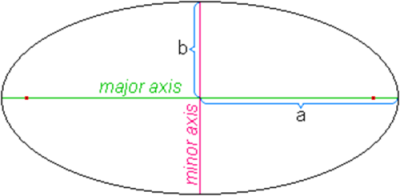
Заодно убили двух зайцев: оказалось, что преобразование Хафа не любит концентрические круги, и частенько на печатях находился внутренний круг вместо внешнего, плюс некоторые печати алгоритм просто не находил.
Нехитрым способом (трешхолдами) отсеиваем неблагородные эллипсы, объединяем вложенные друг в друга круги, и voila – выкидываем кучу ложных срабатываний.

Фиолетовые круги – преобразование Хафа, зеленый – эллипс с внутренним кругом, синий – эллипс без внутренних кругов, голубой – новый контур, который получился после объединения с эллипсом.
segments = []
contours, hierarchy = cv2.findContours(img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for contour in contours:
if contour.shape[0] < 5:
continue
ellipse = cv2.fitEllipse(contour)
width = ellipse[1][0]
height = ellipse[1][1]
minor = min(width, height)
major = max(width, height)
if minor / 2 > minorMin and major / 2 < majorMax:
r1 = math.fabs(1 - math.fabs(major - minor) / max(minor, major))
cv2.ellipse(src, ellipse, (255, 0, 0), 3)
if r1 > roundness:
segments.append((ellipse[0], major / 2))
cv2.ellipse(src, ellipse, (0, 255, 0), 3)
else: cv2.ellipse(src, ellipse, (0, 0, 255), 1)
cv2.imwrite('test_res.bmp', src)def distance(p1, p2):
return math.sqrt(math.pow(p2[0] - p1[0], 2) + math.pow(p2[1] - p1[1], 2))
def isNested(inner, outer, epsilon):
distance = distance(inner[0], outer[0])
radius = outer[1] * epsilon
return distance < radius and inner[1] < radius - distance
nested = []
for i in inner:
for o in outer:
if (isNested(i, o, 1.3)):
if (distance(i[0], i[1]) < 30 and i[1] / o[1] > 0.75):
nested.append(i)
else: nested.append(o)Cv2.FindContours(src, out var contours, hierarchy, RetrievalModes.External, ContourApproximationModes.ApproxSimple);
foreach (var contour in contours)
{
// Эллипс можно построить минимум по 5 точкам.
if (contour.Height < 5)
continue;
var ellipse = Cv2.FitEllipse(contour);
var minor = Math.Min(ellipse.Size.Width, ellipse.Size.Height);
var major = Math.Max(ellipse.Size.Width, ellipse.Size.Height);
if (minor / 2 > minorSize && major / 2 < majorSize)
{
// Отношение малой оси к большой. Чем больше значение, тем больше эллипс похож на круг.
var r1 = Math.Abs(1 - Math.Abs(major - minor) / Math.Max(minor, major));
if (r1 > roundness)
{
var circle = new CircleSegment(ellipse.Center, major / 2);
segments.Add(circle);
}
}
contour.Dispose();
}
}private bool IsCirclesNested(CircleSegment inner, CircleSegment outer, double epsilon)
{
var distance = inner.Center.DistanceTo(outer.Center);
var secondRadius = outer.Radius * epsilon;
return distance < secondRadius && inner.Radius < secondRadius - distance;
}
var nested = new List<CircleSegment>();
foreach (var i in inner)
foreach (var o in outer)
{
if (IsCirclesNested(i, o, 1.3))
{
if (i.Center.DistanceTo(o.Center) < 30 &&
i.Radius / o.Radius > 0.75)
nested.Add(i);
else nested.Add(o);
}
}
return outer.Union(inner).Except(nested).ToList();Если вы думаете, что этого может быть достаточно, то я скажу вам, что нет. Хотя для большинства случаев этого будет более чем хватать. Но если вы хотите больше точности — устройтесь поудобней, у меня есть еще один метод.
В данном методе на помощь нам приходит щепотка “математической магии”, а именно перевод из одной системы координат в другую, конкретно в логарифмическую-полярную систему. Я могу понять удивление некоторых “чем это вообще может помочь”? С помощью этого мы “выворачиваем” печать. Но зачем? Это легко позволяет понять, является ли что-то на объекте круглым. Покажу на примере:
Думаю, всем понятно, какой в этом смысл: проверить круглый ли объект намного легче, когда он не круглый, а в виде линии. Вот обратный пример:

Теория тут очень простая — вместо привычных нам X и Y мы за основу системы координат берем логарифм расстояния от центра до точки и угол, на который нужно повернуть ось X, чтобы она пересекла нужную нам точку. Это очень походит на полярную систему координат, за исключением того, что мы берем логарифм расстояния, а не само расстояние.
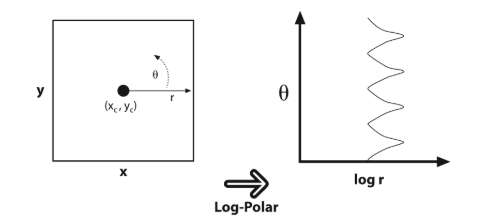
Теперь ближе к реальности — берем наше предположение, полученное после поиска кругов с помощью преобразования Хафа, вырезаем его и переводим в полярную систему координат (выворачиваем наизнанку). Дальше, используя всё то же преобразование Хафа, находим прямые линии (в статьях, которые я приводил выше также описано, что стоит за этим, рекомендую почитать).
После перевода в полярную систему координат, изображение будет не в горизонтальном положении, а в вертикальном. Мы (для себя) повернули его на 90 градусов для соответствия с оригинальной картинкой.
maxRadius = math.sqrt(math.pow(src.shape[0], 2) + math.pow(src.shape[1], 2)) / 2
magnitude = src.shape[0] / math.log(maxRadius)
center = (src.shape[0] / 2, src.shape[1] / 2)
polar = cv2.logPolar(src, center, magnitude, cv2.INTER_AREA)var maxRadius = Math.Sqrt(Math.Pow(stampImage.Width, 2) + Math.Pow(stampImage.Height, 2)) / 2;
var magnitude = stampImage.Width / Math.Log(maxRadius);
var center = new Point2f(stampImage.Width / 2, stampImage.Height / 2);
Cv2.LogPolar(stampImage, cartesianImage, center, magnitude, InterpolationFlags.Area);Для поиска контуров использовали оператор Собеля, так как он позволяет строить контуры с учетом градиента, плюс немного OpenCV’шной магии в виде морфологических операций. Также, для поиска контуров можно использовать и оператор Кенни, который, кстати, используется в преобразовании Хафа в библиотеке OpenCV. Копипастить не буду, по ссылкам сможете найти подробное объяснение.
Применяем оператор Собеля и находим линии с помощью преобразования Хафа:
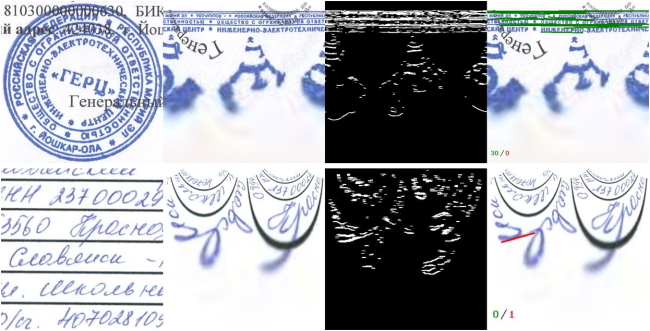
Единственное, мы допускаем, что линия не обязательно должна быть ровно под углом в 90 градусов, так как центр мог определиться не совсем точно.
# Поиск границ.
sobel = cv2.Sobel(polar, cv2.CV_16S, 1, 0)
kernel = cv2.getStructuringElement(shape=cv2.MORPH_RECT, ksize=(1, 5))
img = cv2.convertScaleAbs(sobel)
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]
img = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)
img = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)
# Поиск вертикальных линий.
def is_vertical(img_src, line):
tolerance = 10
coords = line[0]
angle = math.atan2(coords[3] - coords[1], coords[2] - coords[0]) * 180.0 / math.pi
edge = img_src.shape[0] * 0.66
out_of_bounds = coords[0] < edge and coords[2] < edge
return math.fabs(90 - math.fabs(angle)) <= tolerance and not out_of_bounds
lines = cv2.HoughLinesP(img, 1, math.pi / 180, 15, img.shape[0] / 5, 10)
vertical = [line for line in lines if is_vertical(img, line)]
correct_lines = len(vertical)// Поиск границ.
using (var sobel = new Mat())
using (var kernel = Cv2.GetStructuringElement(MorphShapes.Rect, new Size(1, 5)))
{
Cv2.Sobel(img, sobel, MatType.CV_16S, 1, 0);
Cv2.ConvertScaleAbs(sobel, img);
Cv2.Threshold(img, img, 0, 255, ThresholdTypes.Binary | ThresholdTypes.Otsu);
Cv2.MorphologyEx(img, img, MorphTypes.Open, kernel);
Cv2.MorphologyEx(img, img, MorphTypes.Close, kernel);
}
// Поиск вертикальных линий.
bool AlmostVerticalLine(LineSegmentPoint line)
{
const int tolerance = 10;
var angle = Math.Atan2(line.P2.Y - line.P1.Y, line.P2.X - line.P1.X) * 180.0 / Math.PI;
var edge = edges.Width * 0.66;
var outOfBounds = line.P1.X < edge && line.P2.X < edge;
return Math.Abs(90 - Math.Abs(angle)) <= tolerance && !outOfBounds;
}
var lines = Cv2.HoughLinesP(img, 1, Math.PI / 180, 15, img.Width / 5, 10);
var correctLinesCount = lines.Count(AlmostVerticalLine);В итоге мы снизили пороги для поиска кругов, наложили наши фильтрации и получили результат близкий к 85%. Но есть и некоторые ограничения:
- это работает только на цветных документах (хотя можно попробовать извлекать и без отделения цвета, но результаты намного хуже);
- размер печати зависит от размера документа (так что если у вас маленькая печать на ватмане — скорее всего она пролетит мимо);
- рукописка и подписи остаются на документе, бывает, срабатывает на них даже после фильтрации;
- ну и решение всё равно чувствительно к шумам, особенно к синим.
Итак, возвращаясь к вопросу из начала статьи — “почему не нейроночки?”. Потому что:
- не нужно большое количество данных;
- не нужна разметка для получения результата (только для проверки метрик);
- не нужно обучать нейронку;
- работает быстрее.
В итоге мы получаем быстрое, как в плане разработки, так в плане работы, решение. Мы выбрали OpenCV потому что извлечение печатей нужно было клиенту здесь и сейчас, да и опыта с нейронками было мало. Сейчас мы уже переписали на U-Net, так как хоть решение на OpenCV вполне рабочее, но нужно было поднимать качество.
dkurt
С обученным U-Net можно обратно в OpenCV — нейронные сети не обучаются, но запускать можно.