
The search for a suitable storage platform: GlusterFS vs. Ceph vs. Virtuozzo Storage
This article outlines the key features and differences of such software-defined storage (SDS) solutions as GlusterFS, Ceph, and Virtuozzo Storage. Its goal is to help you find a suitable storage platform.
Gluster
Let’s start with GlusterFS that is often used as storage for virtual environments in open-source-based hyper-converged products with SDS. It is also offered by Red Hat alongside Ceph.
GlusterFS employs a stack of translators, services that handle file distribution and other tasks. It also uses services like Brick that handle disks and Volume that handle pools of bricks. Next, the DHT (distributed hash table) service distributes files into groups based on hashes.
Note: We’ll skip the sharding service due to issues related to it, which are described in linked articles.
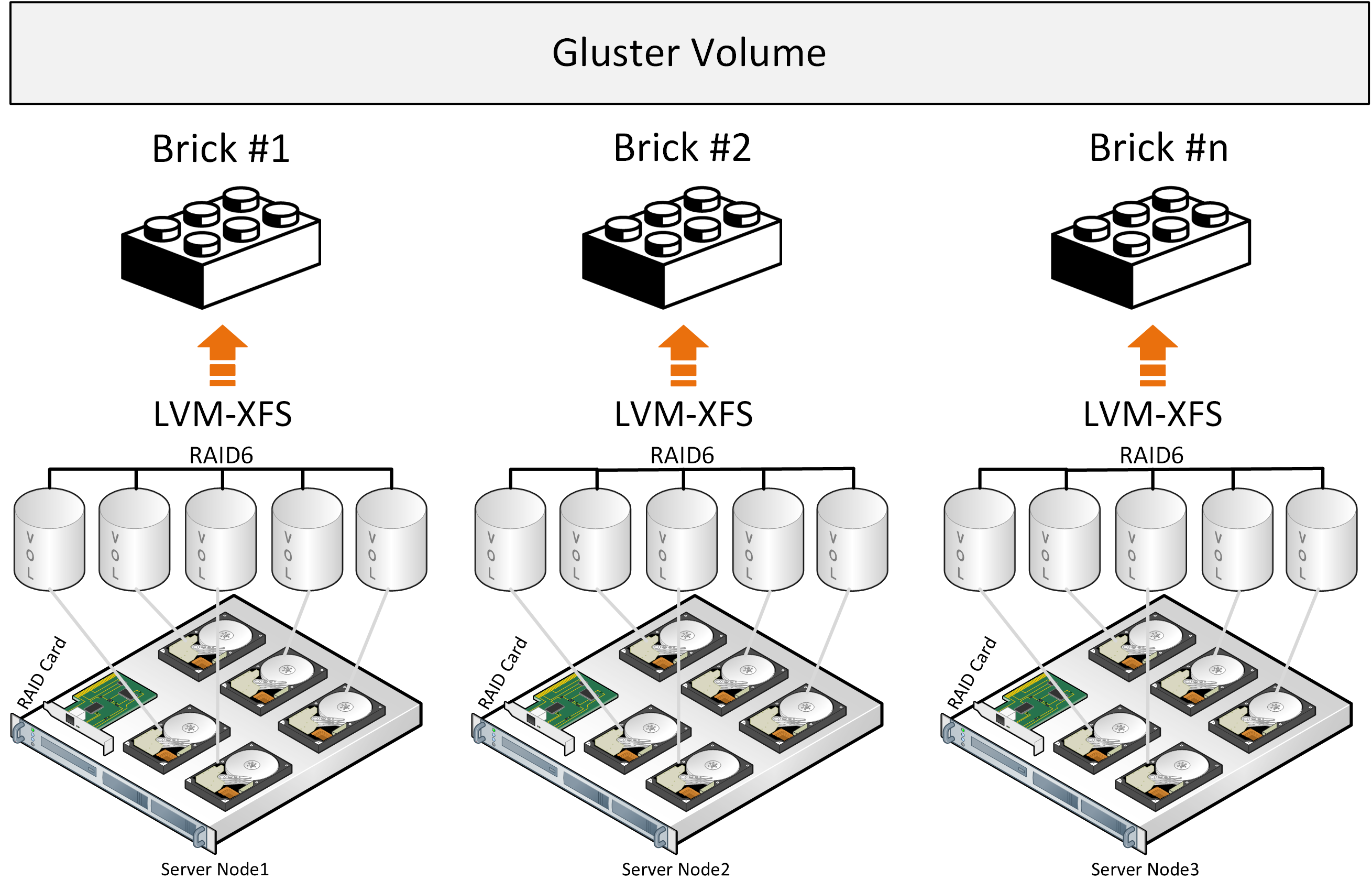
When a file is written onto GlusterFS storage, it is placed on a brick in one piece and copied to another brick on another server. The next file will be placed on two or more other bricks. This works well if the files are of about the same size and the volume consists of a single group of bricks. Otherwise the following issues may arise:
- Storage space in groups is not utilized evenly, depending on file size. If a group does not have enough space, an attempt to write a file will result in an error. The file will not be written or placed in another group.
- When a file is being written, only its group’s I/O is used, resources assigned to other groups are idle. It is impossible to utilize entire volume’s I/O to write a single file.
- The overall concept looks less efficient due to data not being split into blocks that are easier to balance and distribute evenly.
The architecture overview also shows that GlusterFS works as file storage on top of a classic hardware RAID. It also uses such open-source components as FUSE, which has limited performance. There are attempts to shard files into blocks, but they come at the cost of performance as well. This could be somewhat mitigated by means of a metadata service but GlusterFS does not have one. Higher performance is achievable by applying the Distributed Replicated configurations to six and more nodes to set up 3 reliable replicas and provide optimal load balancing.

The figure above shows distribution of load while two files are being written. The first file is copied onto three servers grouped into Volume 0. The second file is copied onto Volume 1, which also comprises three servers. Each server has a single disk.
The general conclusion is that you can use GlusterFS if you understand its performance and fault tolerance limits that will hinder certain hyper-converged setups where resources are spent on compute workloads as well.
More details on performance that you can achieve with GlusterFS, even if with limited fault tolerance, are provided at.
Ceph
Now let’s take a look at Ceph. According to research published on the Internet, Ceph works best on dedicated servers as it may require all of the available hardware resources under load.
The architecture of Ceph is more intricate than that of GlusterFS. In particular, Ceph stores data as blocks, which looks more efficient, and it also does employ metadata services. The overall stack of components is rather complicated, however, and not very flexible when it comes to using Ceph with virtualization. Due to complexity and lack of flexibility, the component hierarchy can be prone to losses and latencies under certain loads and in hardware failure events.
At the heart of Ceph is the Controlled Replication Under Scalable Hashing (CRUSH) algorithm that handles distribution of data on storage. The next key part is a placement group (PG) that groups objects to reduce resource consumption, increase performance and scalability, and make CRUSH more efficient. Addressing each object directly, without grouping them into PGs, would be quite resource-intensive. Finally, each disk is managed by its OSD service.

Overall diagram

PG and hashing function diagram
On the logical tier, a cluster can comprise one or more pools of data of different types and configurations. Pools are divided into PGs. PGs store objects that clients access. On the physical tier, each PG is assigned one primary disk and multiple replica disks, as per pool replication factor. Logically, each object is stored in a PG, while physically it’s kept on that PG’s disks, which can be located on different servers or even in different datacenters.
In this architecture, PGs look necessary to provide flexibility to Ceph, but they also seem to reduce its performance. For example, when writing data, Ceph has to place it in a PG logically and across PG’s disks physically. The hash function works when both searching and inserting objects but the side effect is that rehashing (for example, when adding or removing disks) is very resource-intensive and limited. Another issue with the hash is that it does not allow relocating the data once it has been placed. So if a disk is under a high load, Ceph cannot write data onto another disk instead. Because of this, Ceph consumes a lot of memory when PGs are self-healing or when the storage capacity is increased.
The general conclusion is that Ceph work well (albeit slowly) when it does not come to scalability, emergencies or updates. With good hardware, you can improve its performance by means of caching and cache tiering. Overall, Ceph seems to be a better choice for production than GlusterFS.
Vstorage
Now let’s turn to Virtuozzo Storage that has an even more interesting architecture. It can share a server with a hypervisor (KVM/QEMU) and can be installed rather easily on a lot of hardware. The caveat is that the entire solution needs to be configured right to achieve good performance.
Virtuozzo Storage utilizes just a few services organized in a compact hierarchy: the client service mounted via a custom FUSE implementation, a metadata service (MDS), and a chunk service (CS) that equals to a single disk on the physical tier. In terms of performance, the fastest fault tolerant setup is two replicas, although with caching and journals on SSD disks, you can also achieve good performance with erasure coding (EC) or RAID6 on a hybrid or, better yet, an all-flash configuration. The downside of EC is that changing even a single chunk (block of data) means that checksums need to be recalculated. To avoid losing resources on this, Ceph, for example, uses delayed writes with EC.
This may result in performance issues in case of certain requests, e.g., to read all the blocks. In turn, Virtuozzo Storage writes changed chunks using the log-structured file system approach that minimizes performance expenses on checksum calculations. An online calculator provided by Virtuozzo helps you estimate performance with and without EC and plan your configuration accordingly.
Despite the simplicity of the Virtuozzo Storage architecture, its components still need decent hardware as laid out in the requirements. So if you need a hyper-converged setup alongside a hypervisor, it is recommended to plan the server configuration beforehand.
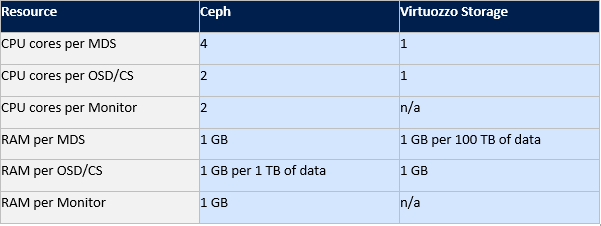
The following table compares the consumption of hardware resource by Ceph and Virtuozzo Storage:
Unlike GlusterFS and Ceph that can easily be compared based on research published on the Internet, Virtuozzo Storage is not as popular, so the documentation remains the primary source of information about its features.
For this reason, I will describe the architecture of Virtuozzo Storage in more detail, so the part dedicated to this solution will be longer.
Let’s take a look at how writes are performed in a hybrid setup where data is stored on HDDs while caches (read/write journals) are kept on SSDs.
A client, a FUSE mount point service, initiates a write to the server where the mount point is. Then MDS directs the client to a CS that manages data chunks of equal size (256 MB) on a single disk.

The chunk is replicated, almost in parallel, to multiple servers, according to the replication factor. In a setup with the replication factor of 3 and caches (read/write journals) on SSDs, the data write is committed after the journal has been written to the SSD. At that moment, however, the data is still being flushed from the caching SSD to the HDD in parallel.
Essentially, as soon as the data gets into a journal on the SSD, it’s immediately read and flushed to HDD. Given the replication factor of 3, the write will be committed after it’s been confirmed by the third server’s SSD drive. It may seem that dividing the sum of SSD write speeds by the number of SSDs produces the speed at which one replica is written.
Actually, replicas are written in parallel and since SSDs have much lower latencies than the network, the write speed essentially depends on network throughput. One can estimate the actual system IOPS by loading the entire system the right way, instead of focusing only on memory and cache. There is a dedicated test method for this that takes into account data block size, the number of threads, and other things.
The number of MDS per cluster is determined by the Paxos algorithm. Also, from the client’s point of view, the FUSE mount point is a storage directory mounted to all servers at once.
Another beneficial distinction of Virtuozzo Storage from Ceph and GlusterFS is FUSE with fast path. It significantly improves IOPS and lets you go beyond just horizontal scalability. The downside is that Virtuozzo Storage requires a paid license unlike Ceph and GlusterFS.
For every platform described in this article, it’s vital to properly plan and deploy the network infrastructure, providing enough bandwidth and proper aggregation. For the latter, it’s very important to choose the right hashing scheme and frame size.
To sum it up, Virtuozzo Storage offers the best performance and reliability, followed by Ceph and GlusterFS. Virtuozzo Storage wins for having the optimal architecture, custom FUSE with fast path, the ability to work on flexible hardware configurations, lower resource consumption, and the possibility to share the hardware with compute/virtualization. In other words, it is a part of a hyper-converged solution. Ceph is second because its block-based architecture allows it to outperform GlusterFS, as well as work on more hardware setups and in larger-scale clusters.
In my next article, I would like to compare vSAN, Space Direct Storage, Virtuozzo Storage, and Nutanix Storage. I would also like to review Virtuozzo Storage integration into third-party hardware data storage solutions.
If you have any comments or questions regarding the article, please let me know.
The translation was helped by Artem Pavlenko, many thanks to him for this.