
Предлагаю ознакомиться с расшифровкой доклада Дениса Карасик "Кафка. Описание одной борьбы"
Apache Kafka часто преподносится как серебряная пуля: стоит только начать ее использовать, как все проблемы решатся сами собой, дыхание станет свежим, а волосы мягкими и шелковистыми. Но так ли оно на самом деле? (спойлер — не совсем)
На примере Badoo я расскажу, как Kafka выросла от эксперимента в одном сервисе до полноценного managed-решения и стала основой для многих ключевых инструментов внутри компании.
Основные темы, которых коснёмся:
- область применения и типовые usecases;
- надежность vs производительность;
- управление кластерами и capacity planning;
- мониторинг и эксплуатация.
Доклад будет полезен в первую очередь тем, кто только собирается знакомиться с Kafka — он поможет составить поверхностное представление о будущем пути и потенциальных трудностях. Для более искушенных слушателей я постараюсь осветить тему масштабирования и управления нагруженными кластерами.
Доброе утро! Меня зовут Денис. И сегодня я вам расскажу, как за последние полтора года Кафка у нас в Badoo выросла из эксперимента в одном сервисе до полноценного решения и стала одним из ключевых инструментов внутри компании.
Но перед тем, как начать рассказ, пару слов обо мне. Кто я такой и стоит ли меня слушать? Я работаю в компании Badoo в отделе платформы с 2014-го года. И в нашем отделе мы решаем различные инфраструктурные задачи. Мы развиваем и поддерживаем свое облако. Занимаемся хранением системных данных и активно занимаемся инфраструктурой очередей. И как раз на очередях мы решили поэкспериментировать. Это был первый проект, где мы внедряли Kafka. Нашей целью было улучшение времени доставки. С тех пор уже много воды утекло, и сейчас у нас три кластера Kafka в двух дата-центрах, т. е. в каждом по три кластера. И более 10 ключевых сервисов работают на Kafka. И за всем этим следят два админа.
Содержание
О чем я сегодня буду рассказывать?
- Для начала мы очень быстро пробежимся по основной терминологии Kafka.
- Затем мы затронем очень важные вопросы надежности – как не потерять данные, потому что мы их теряли.
- Потом я уделю внимание структуре кластера.
- Рассмотрим, как управлять кластером и что с ним делать.
- И последний блок будет о мониторинге и диагностике проблем.
Коллеги, я принципиально не стал выстраивать доклад, как очередную success story. Я очень скептически к ним отношусь. Создается впечатление, что люди, которые их пишут, либо о чем-то умалчивают, либо я и все, с кем я работаю, это какие-то криворукие инженеры, которые регулярно натыкаются на всевозможные баги и проблемы. Мне очень важно, чтобы вы, во-первых, не повторяли наших ошибок и у вас все было нормально, и, во-вторых, чтобы вы поняли, что Кафка – это действительно мощный и надежный инструмент, но каждое ваше действие должно быть осознанным – любая ошибка может вам очень дорого стоить.
- Kafka. Начало
Коротко о Kafka. Что это такое? По сути – это распределенный лаг, с возможностью публикации подписки. Основная задача – это доставка сообщений от продюсеров, которые пишут кластер, до подписчиков.
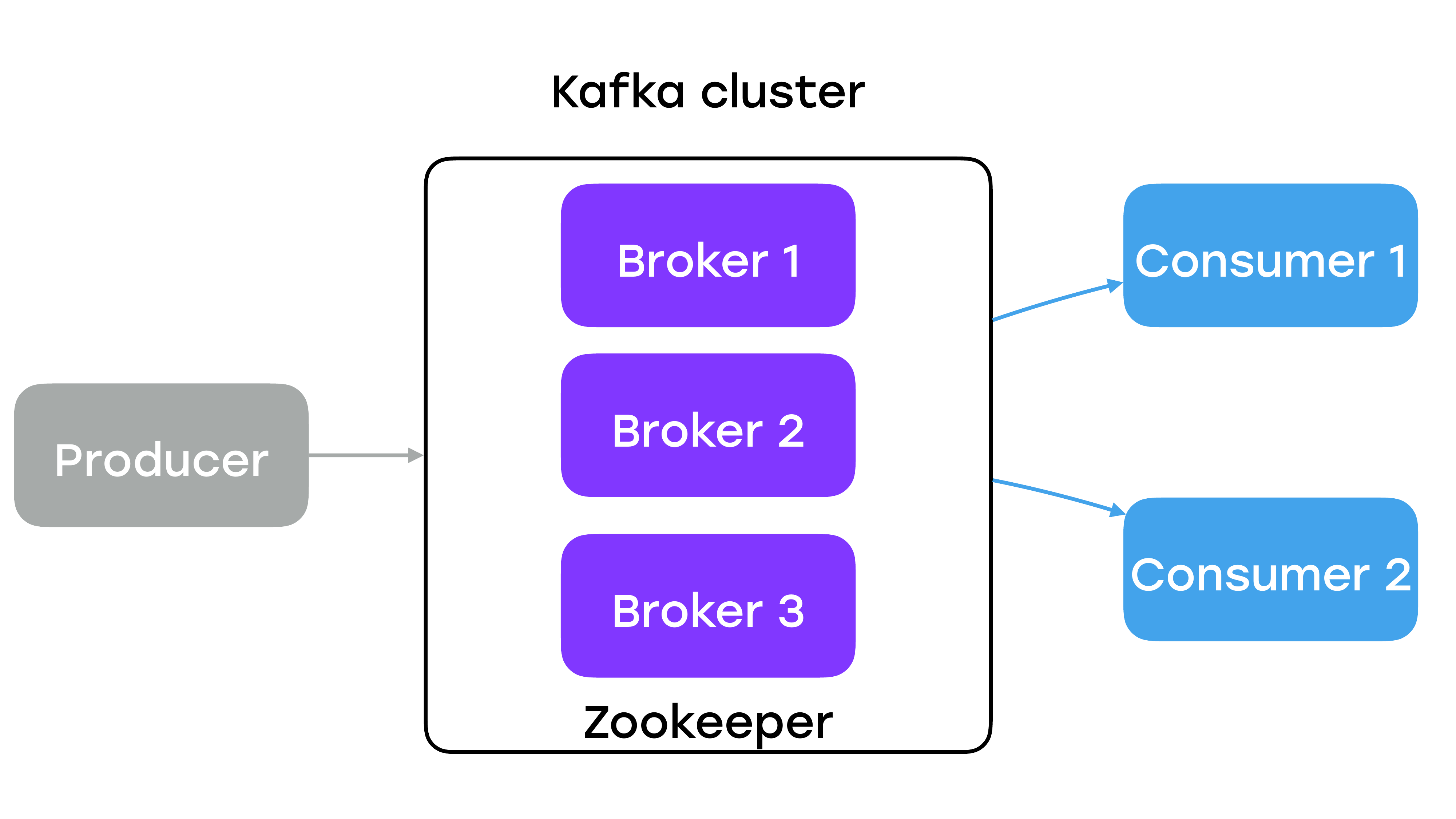
Кластер Kafka состоит почти всегда из нескольких нод, именуемых брокерами. И координация между нодами осуществляется с помощью демона ZooKeeper.
Topic
Как продюсер пишет данные и где они там хранятся?
Данные в Kafka разбиты по топикам. И каждый топик состоит из определенного числа партиций.
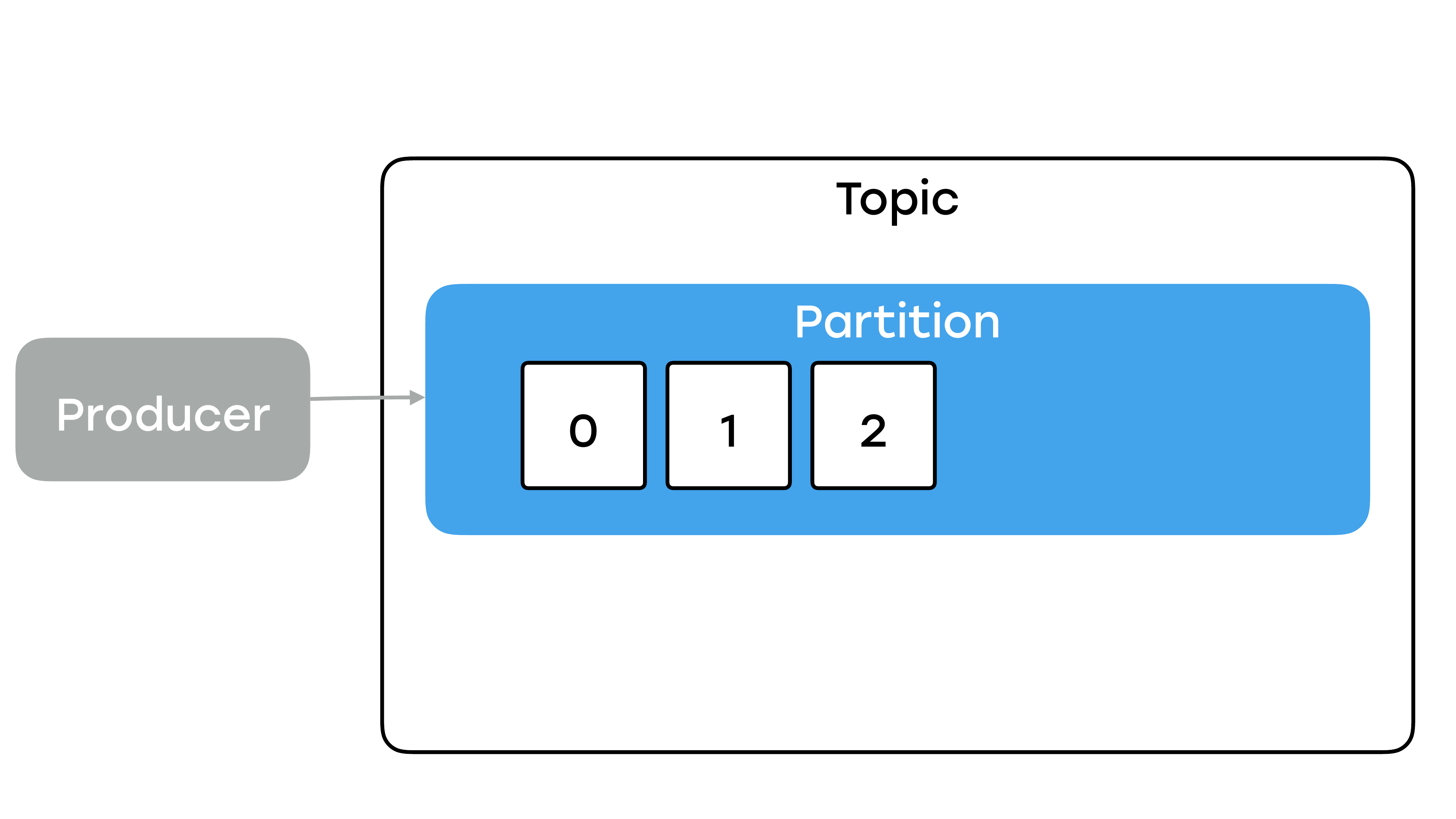
Партиции – это и есть основная единица хранения данных в Kafka. Именно в партициях хранятся данные. И если вы зайдете на брокер, на файловую систему, то вы там никаких топиков не увидите. Топик – это лишь некий логический контейнер вокруг партиции. Каждая партиция – это упорядоченный неизменяемый лог коммитов, т. е. каждый продюсер может дописывать данные только в конец и не может никак со своей стороны повлиять на уже записанные данные, т. е. не может их ни менять, ни удалять. И каждому сообщению присваивается некий уникальный порядковый номер, именуемый offset.
С записью немножко разобрались. Как из Kafka мы читаем? Есть два способа. Первый способ – мы указываем консьюмеру топик, указываем консьюмеру номер партиции и указываем offset, с которого он начинает читать.
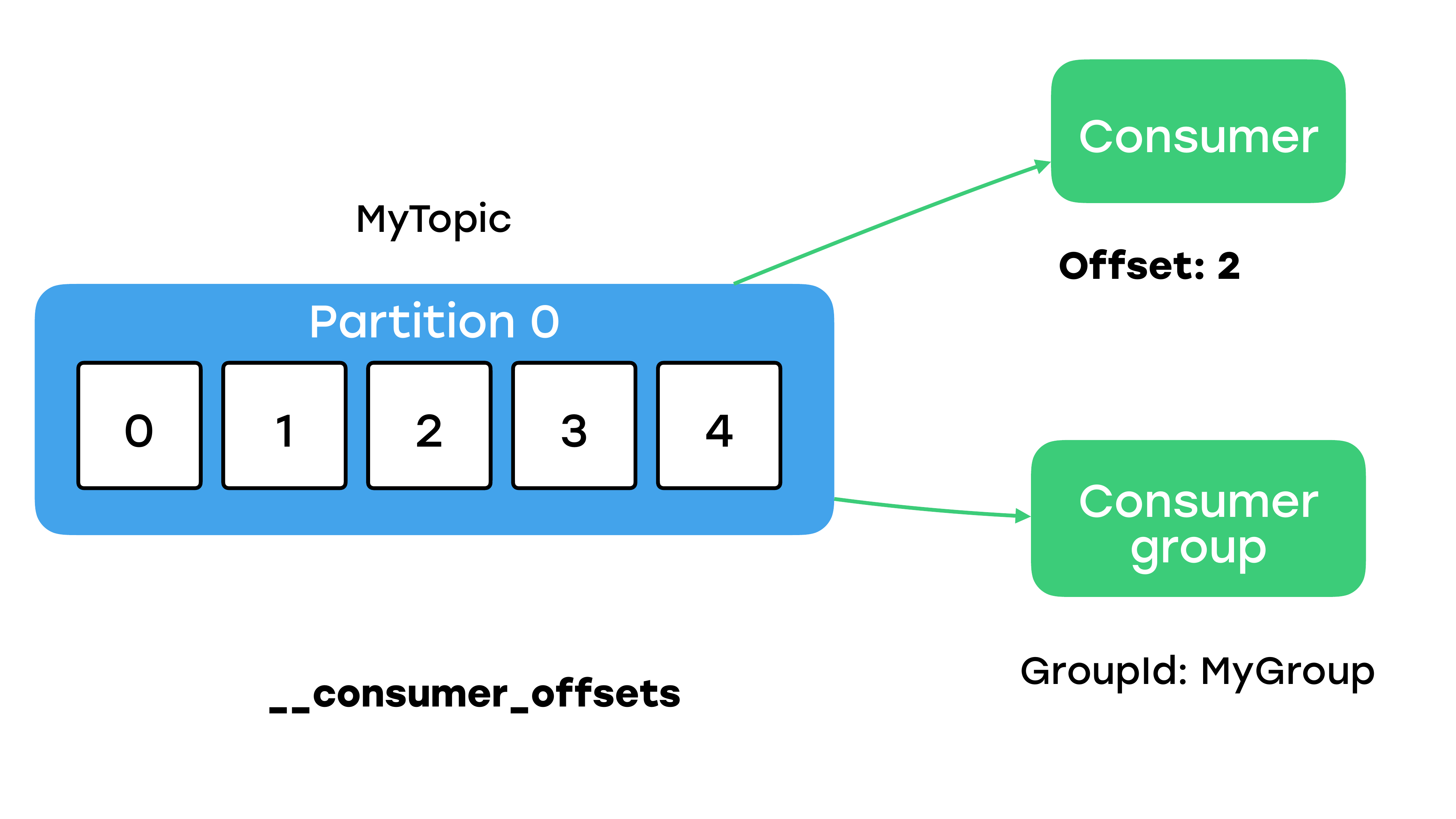
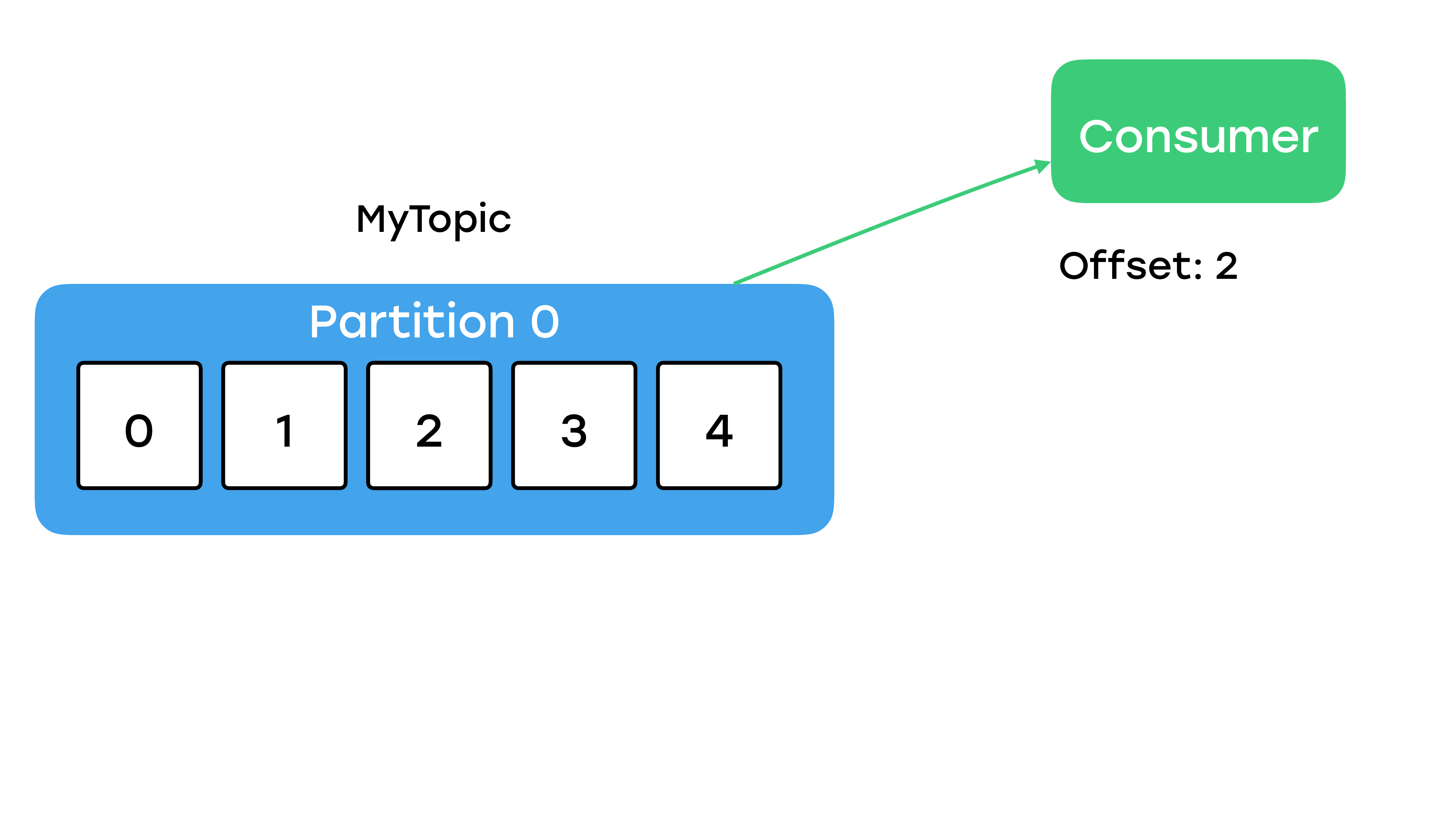 Консьюмер будет вычитывать с offset, как на примере 2, когда он дойдет до конца партиции, он будет ожидать новых сообщений, которые тоже потом будет вам возвращать. Но в таком случае вы должны вне Kafka менеджерить хранение оффсетов. Если вы не хотите так делать, то вы можете создать консьюмер-группу, т. е. указать какой-то уникальный идентификатор группы, и тогда Kafka будет распределять партиции, и сама будет запоминать ваши записанные оффсеты внутри специального топика.
Консьюмер будет вычитывать с offset, как на примере 2, когда он дойдет до конца партиции, он будет ожидать новых сообщений, которые тоже потом будет вам возвращать. Но в таком случае вы должны вне Kafka менеджерить хранение оффсетов. Если вы не хотите так делать, то вы можете создать консьюмер-группу, т. е. указать какой-то уникальный идентификатор группы, и тогда Kafka будет распределять партиции, и сама будет запоминать ваши записанные оффсеты внутри специального топика.
Это все, что я хотел сказать в вводном слове про Kafka. Да, это достаточно быстро и скомкано, но поверьте – для понимания доклада вам этого точно хватит.
- Вопросы надежности
Мы переходим к очень важному вопросу – к вопросу надежности. Почему он важен? Мы внедряли Kafka не только для того, чтобы все стало очень быстрым. Для нашей бизнес-логики очень важно не потерять сообщения. И давайте разберемся, как Kafka нам может обеспечить надежность.
Replication factor
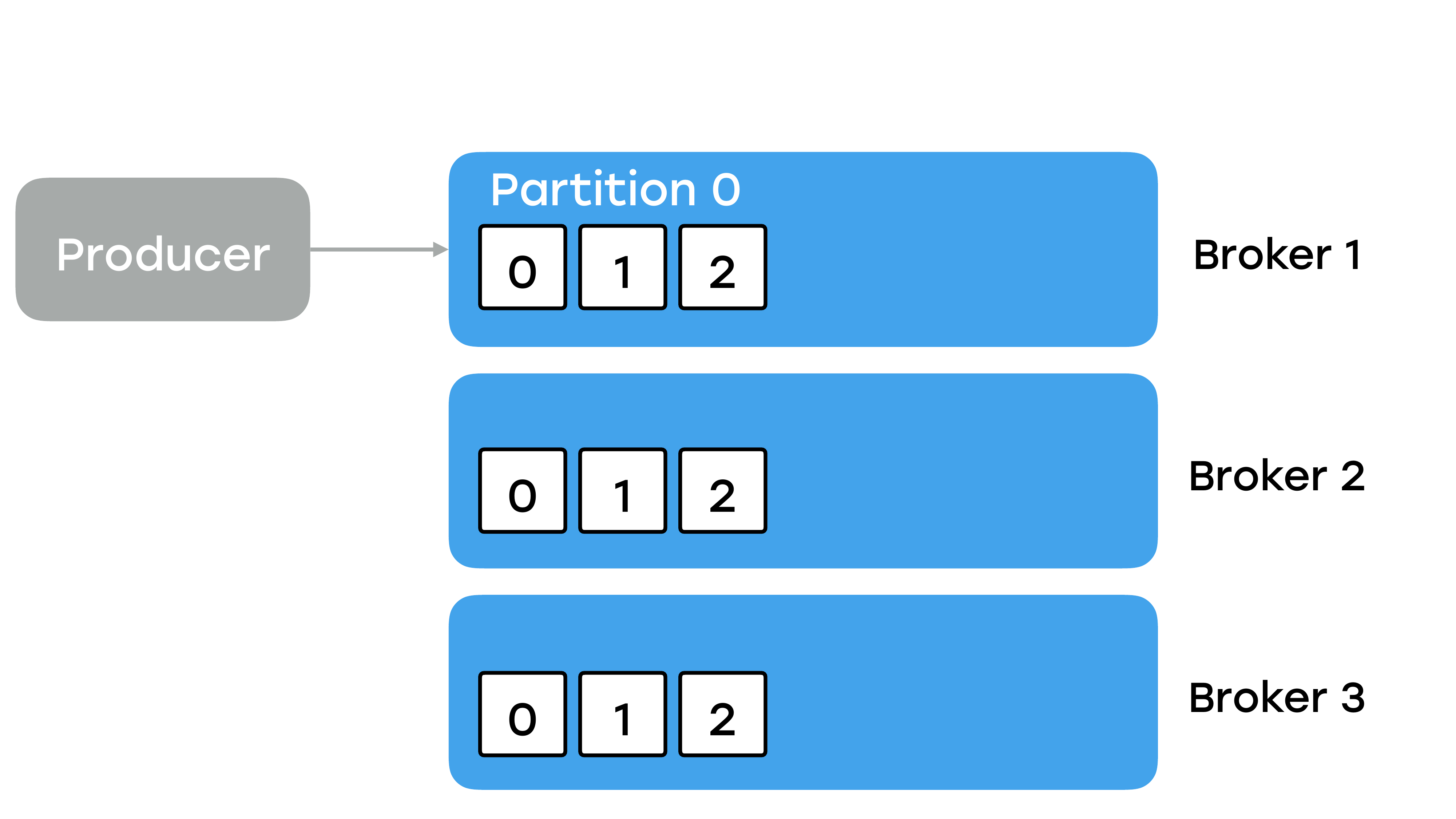
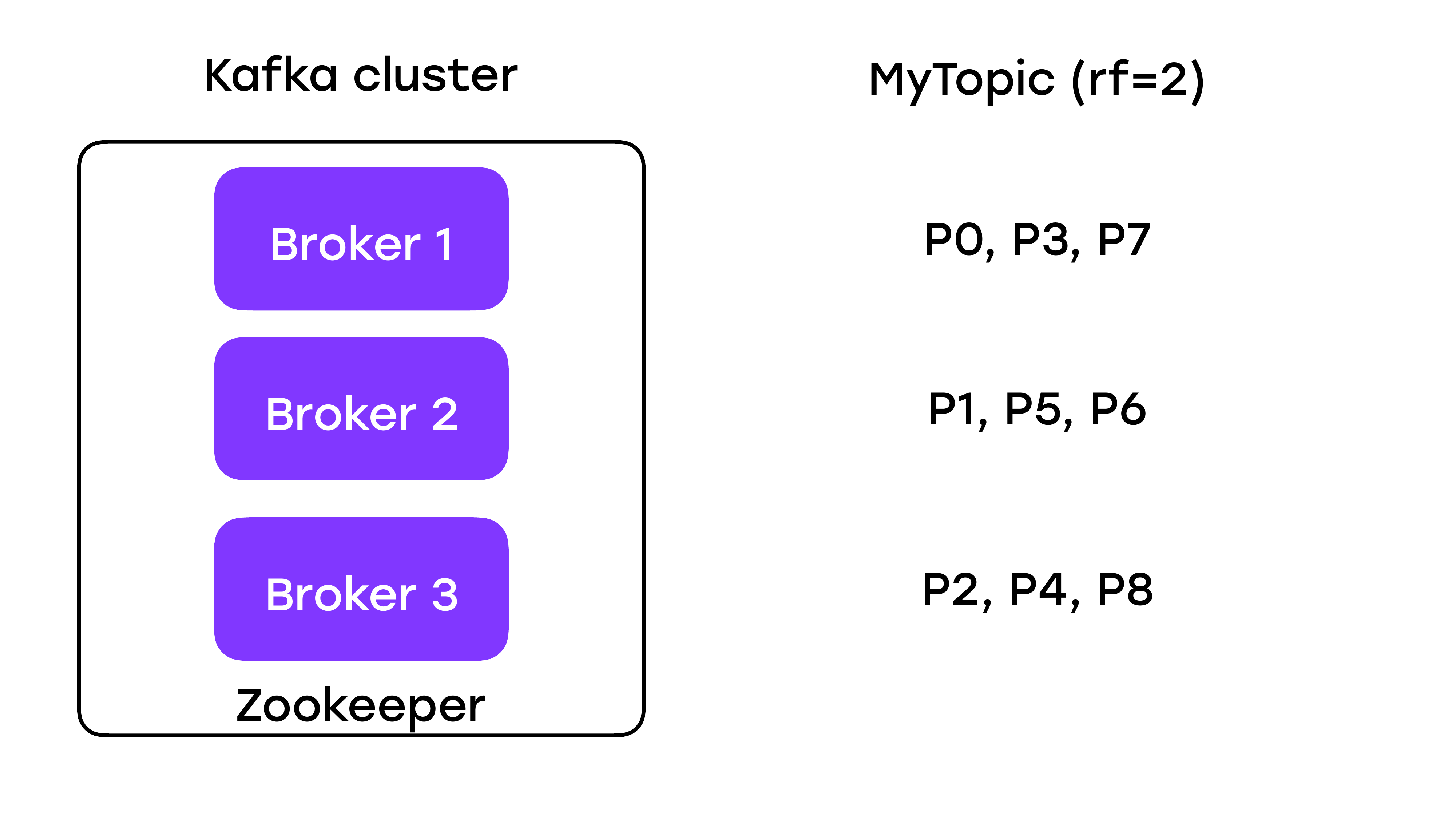
Как я уже говорил, Kafka – это распределенная система. И когда мы говорим о распределенных системах и задумываемся о надежности, то первое, что приходит на ум, это репликация. Продюсер пишет данные в какой-то топик, который живет на каком-то брокере, но мы хотим, чтобы любая партиция топика как-то реплицировалась и присутствовала на других брокерах. Указали мы replication factor, например, как в этом примере, 3.
И все у нас будет хорошо, данные никуда не пропадут, всегда останутся и все будет замечательно? Так ли это? Давайте разберемся.
Чтобы ответить на этот вопрос, нужно разобраться, как данные пишутся в Kafka и как работает внутри репликация. Продюсер всегда пишет данные в какую-то партицию и всегда общается с одним брокером, а не со всеми. Этот брокер будет называться лидером.
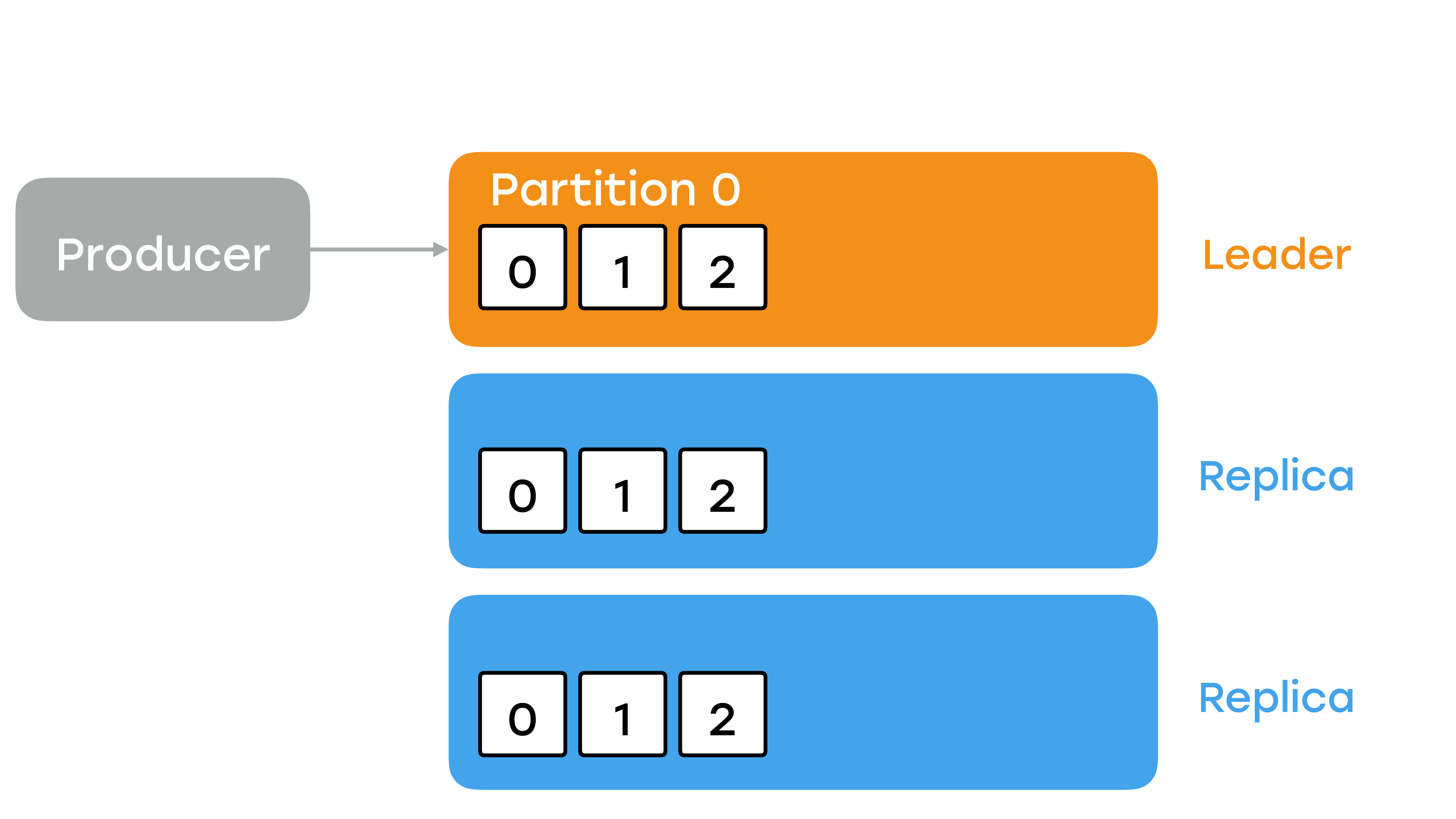
И на всех слайдах он будет рыжего цвета. Более того, консьюмеры тоже читают данные всегда с одного брокера, с этого лидера. Реплики нужны в том случае, если с лидером случится что-то плохое, они смогли бы занять его место. В них никто не пишет, никто не читает, они сами подтягивают сообщения от основного брокера, от лидера. Но нужно понимать, что брокер является для многих партиций лидером, но для других партиций он будет репликой. Т. е. это не какой-то один волшебный брокер, который лидер для всех.
Что произойдет, если мы запишем сообщение?
Как я уже сказал, продюсер запишет его в лидер, и оно появится именно там. Но в этот момент, когда оно появилось в лидере, оно не будет доступно для чтения ни одному из консьюмеров. Это важный момент.
На рисунке показана линия high watermark.
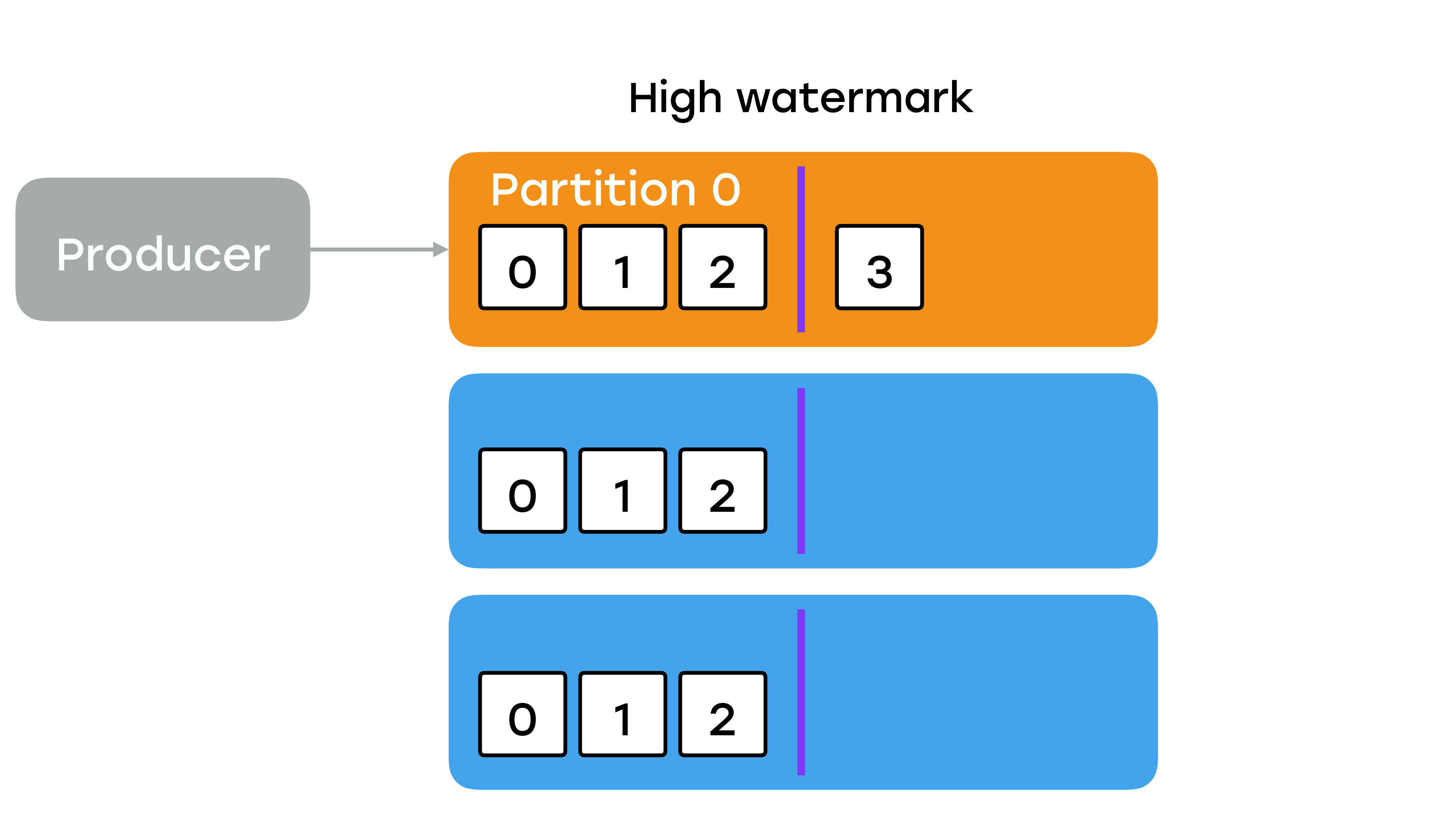
Слева от нее – это уже успешно записанные сообщения, которые доступны для чтения. Справа с offset: 3 оно еще не считается успешно записанным и никому не доступно. И чтобы оно стало доступным, все реплики должны его себе подтянуть. Т. е. сначала какая-то его одна подтягивает, потом какая-то вторая и только потом лидер узнает о том, что все реплики подтянули, сдвигает линию watermark, и сообщение становится доступным для чтения.
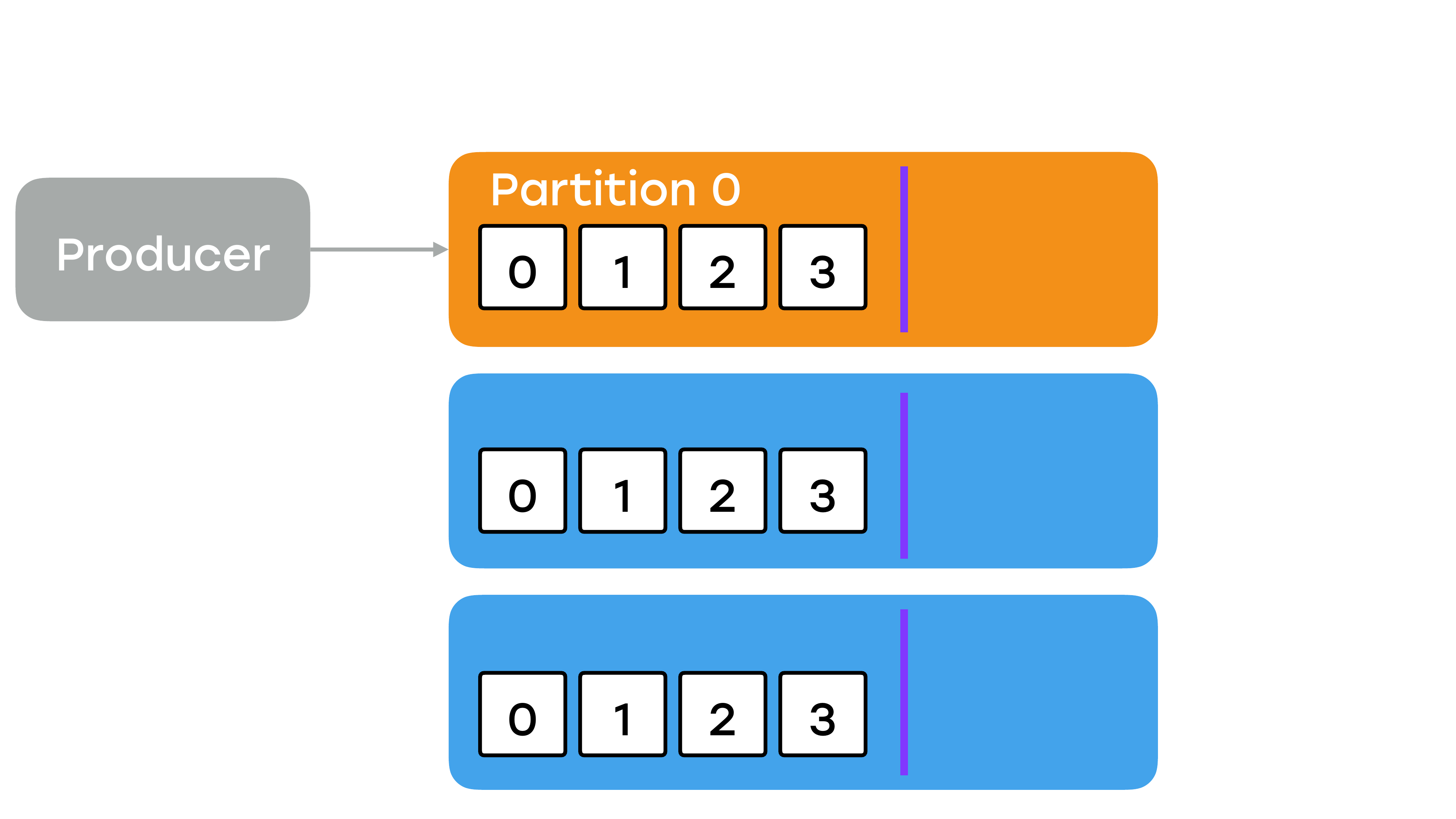
И в Kafka нет никакого кворума на запись. Вы никак не можете указать, например, пускай половину реплик подтянет и тогда оно будет доступно на чтение или пускай только у лидера оно будет, тогда его можно читать. Нет, все реплики должны его обязательно подтянуть. Т. е., по сути, мы пишем данные со скоростью самого медленного брокера — Все брокеры должны быть одинаковыми
И из этого следует, что все брокеры должны иметь одинаковую конфигурацию. Если вы не хоститесь где-то в облаках и у вас свои дата-центры, как у нас, вы не сможете собрать брокера из любого подручного железа. У вас будет потеря производительности. И по этой же причине вы не сможете разделить брокера одного кластера по разным дата-центрам. Это очень сильно будет аффектить запись.
Replica.fetch.wait.max.ms
Как можно на эту скорость повлиять? Во-первых, есть вот такой параметр, он сверху указан. Это время, как часто брокер реплики будет опрашивать лидер.
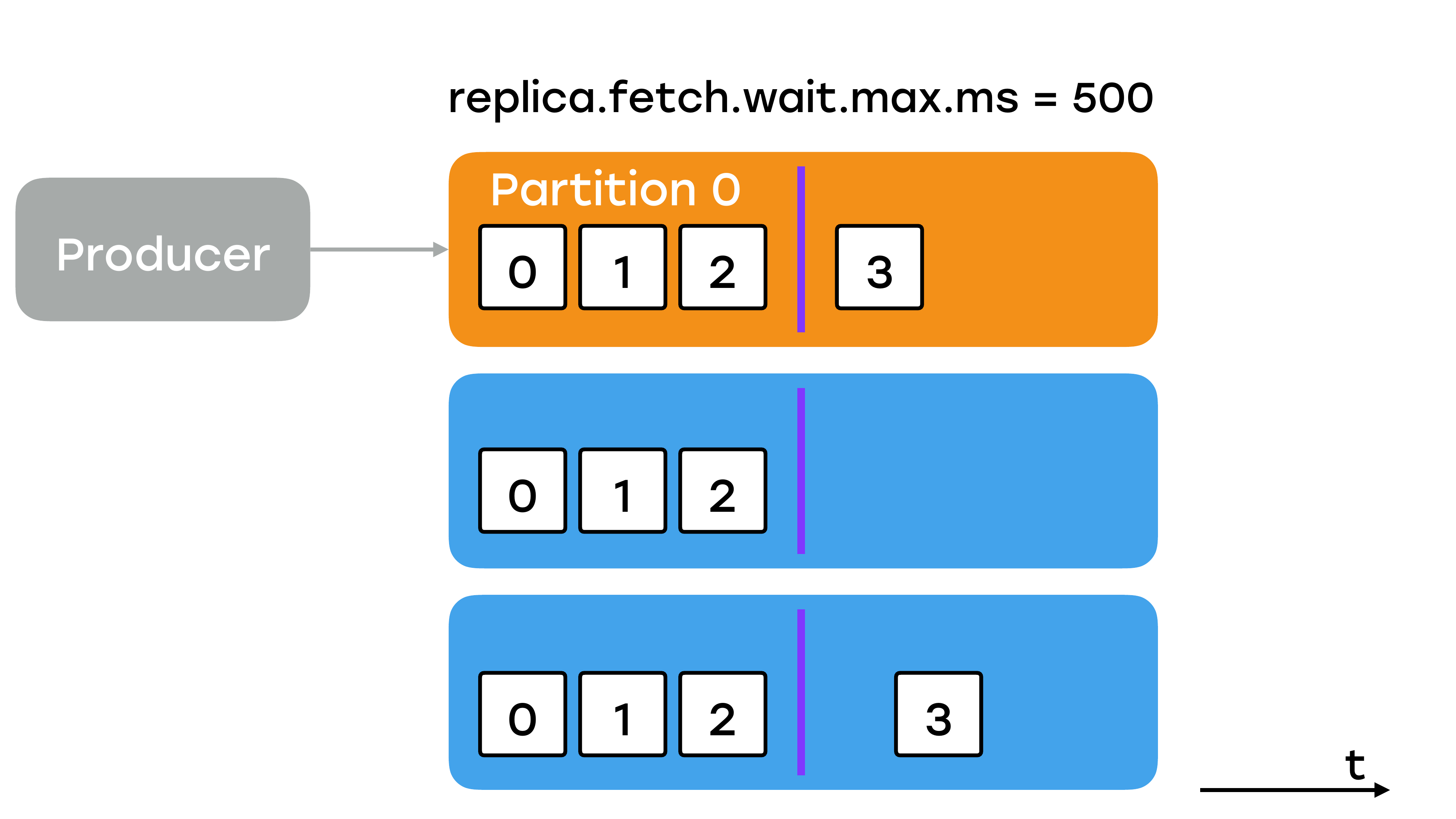
Значение по умолчанию 500 миллисекунд. Мы его выставили в 200 у себя. И тут вот первый поинт. Не рассчитывайте, что в Kafka по умолчанию будут адекватные и подходящие вам значения. Всегда для важных параметров устанавливайте их осознанно в нужные вам значения.
Конфигурация продюсера. Параметр «acks»
Хорошо, тут мы подкрутили. Как мы можем еще повлиять на запись? Есть ощущение, что мы можем что-то указать в конфигурациях продюсера. Да, там действительно есть очень важный конфигурационный параметр «acks», который, по сути, определяет тип подтверждения, который мы будем получать от лидера при записи данных.

И есть ощущение, что он влияет и на целостность, надежность данных и на скорость записи.
Давайте посмотрим, как это все работает и какие он может принимать значения. Вариант первый – значение 0. Мы никакого подтверждения не ждем. Тогда у нас продюсер отправляет данные, какие-то сообщения A, B, C. Отправляет их в партицию на лидер.
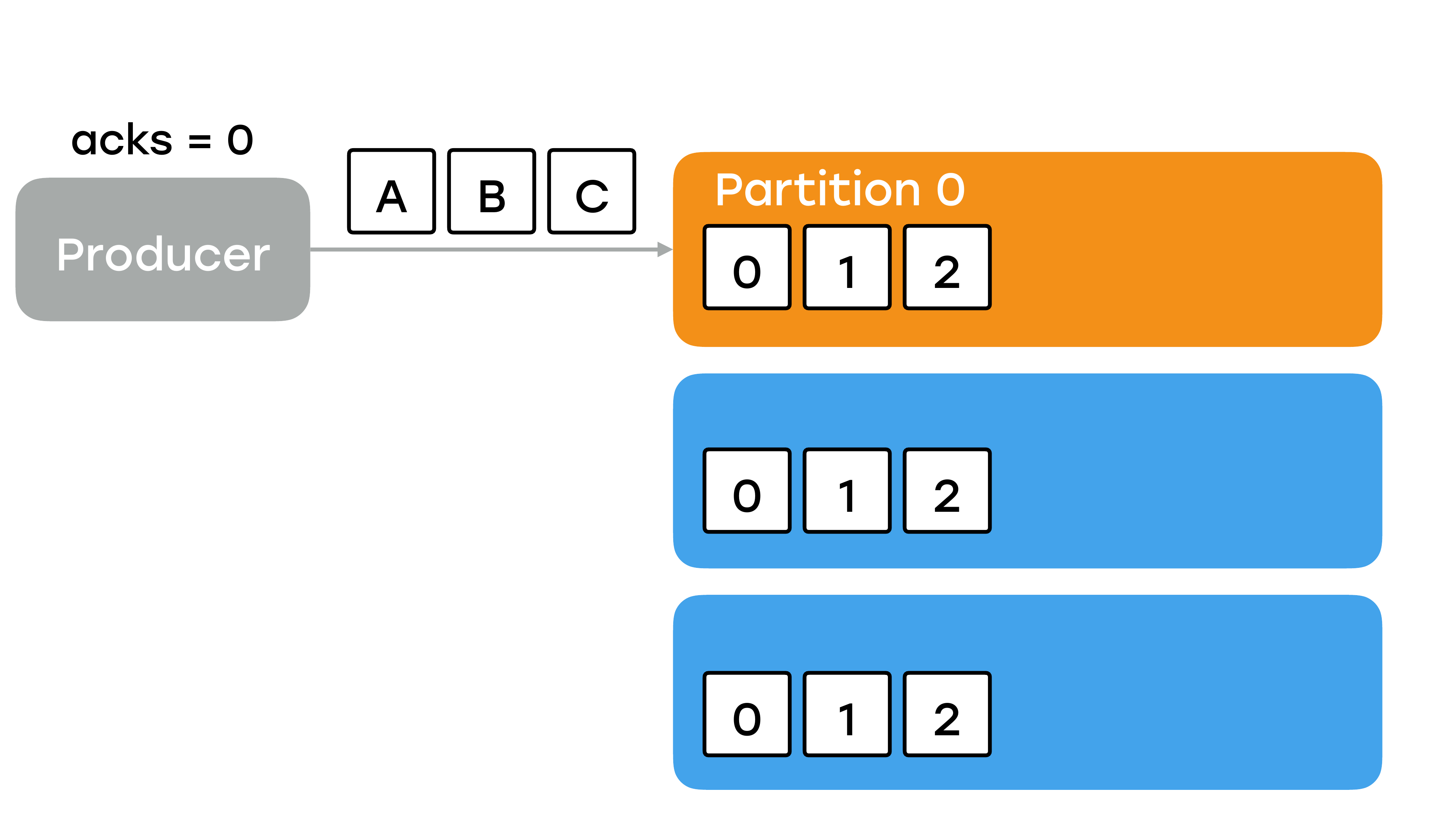
С его стороны пули вылетели, дальше его ничего не волнует. Вы уже получили какое-то подтверждение и дальше как-нибудь они запишутся. И, вероятнее всего, что какое-то сообщение не дойдет до кластера, и вы никогда об этом не узнаете. Явно, что такой вариант не подходит для важных данных. Вы почти гарантированно будете периодично что-то терять.
Второй вариант – мы ожидаем подтверждение, когда лидер записал у себя сообщение.

И кажется, что вариант весьма приемлемый. Смотрите, что произойдет. Продюсер пишет сообщение. Оно записывается в лидер.
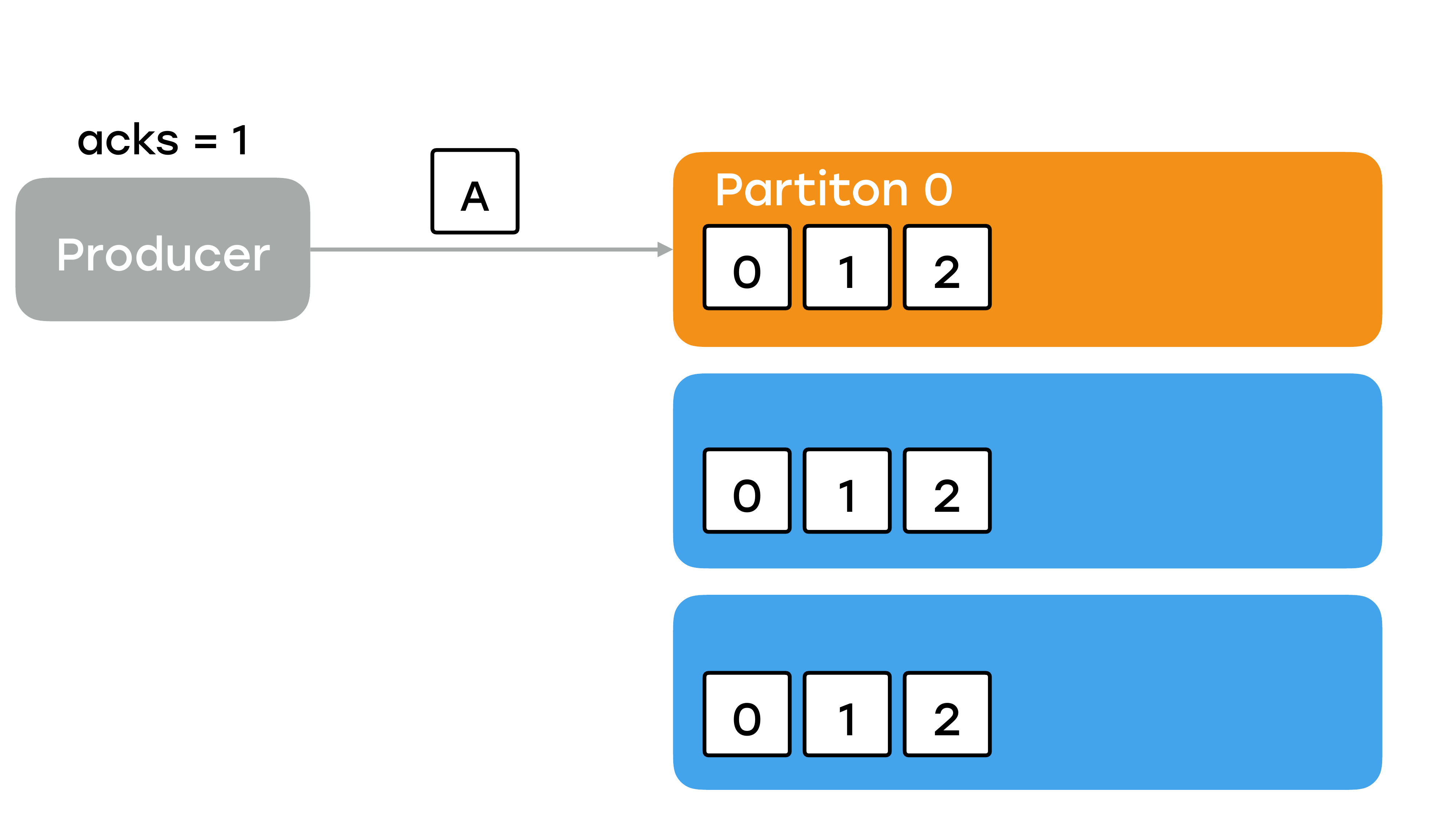
Помните, что сейчас сообщение никому не доступно, оно еще не среплицировалось никуда. В это время лидер отправляет подтверждение продюсеру и все кажется неплохо, пока у вас в этот момент лидер не уйдет в небытье. А такое вполне может случиться. Он может просто моргнуть из-за каких-то сетевых проблем. И что произойдет сейчас? Для чего мы делали реплики? Правильно – одна из реплик, скорее всего, тут же станет лидером.
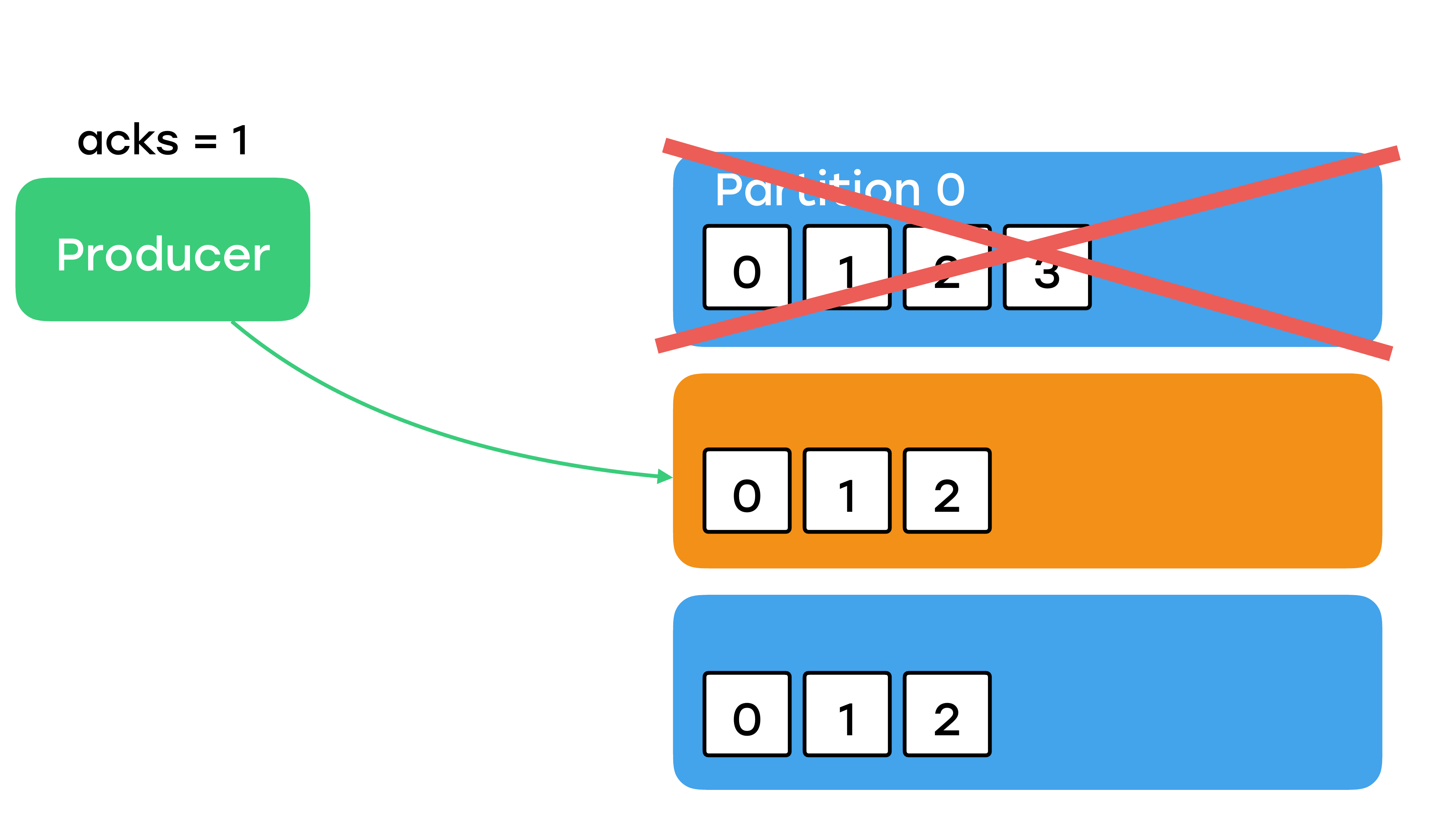
И когда наш предыдущий упавший брокер вернется, он поймет, что он уже не лидер и синхронизируется с новым лидером и сотрет у себя сообщение, которое было с offset: 3. И вы опять же можете потерять сообщение. Более того, вы точно будете их терять при каких-то сетевых проблемах. Этот вариант тоже не подходит для важных данных.
И остается последний вариант, когда мы честно будем ждать подтверждения от всех реплик.

Сообщение будет записано в лидер. Потом какая-то реплика его первая подтянет, потом подтянет вторая. И только тогда продюсер получит подтверждение.
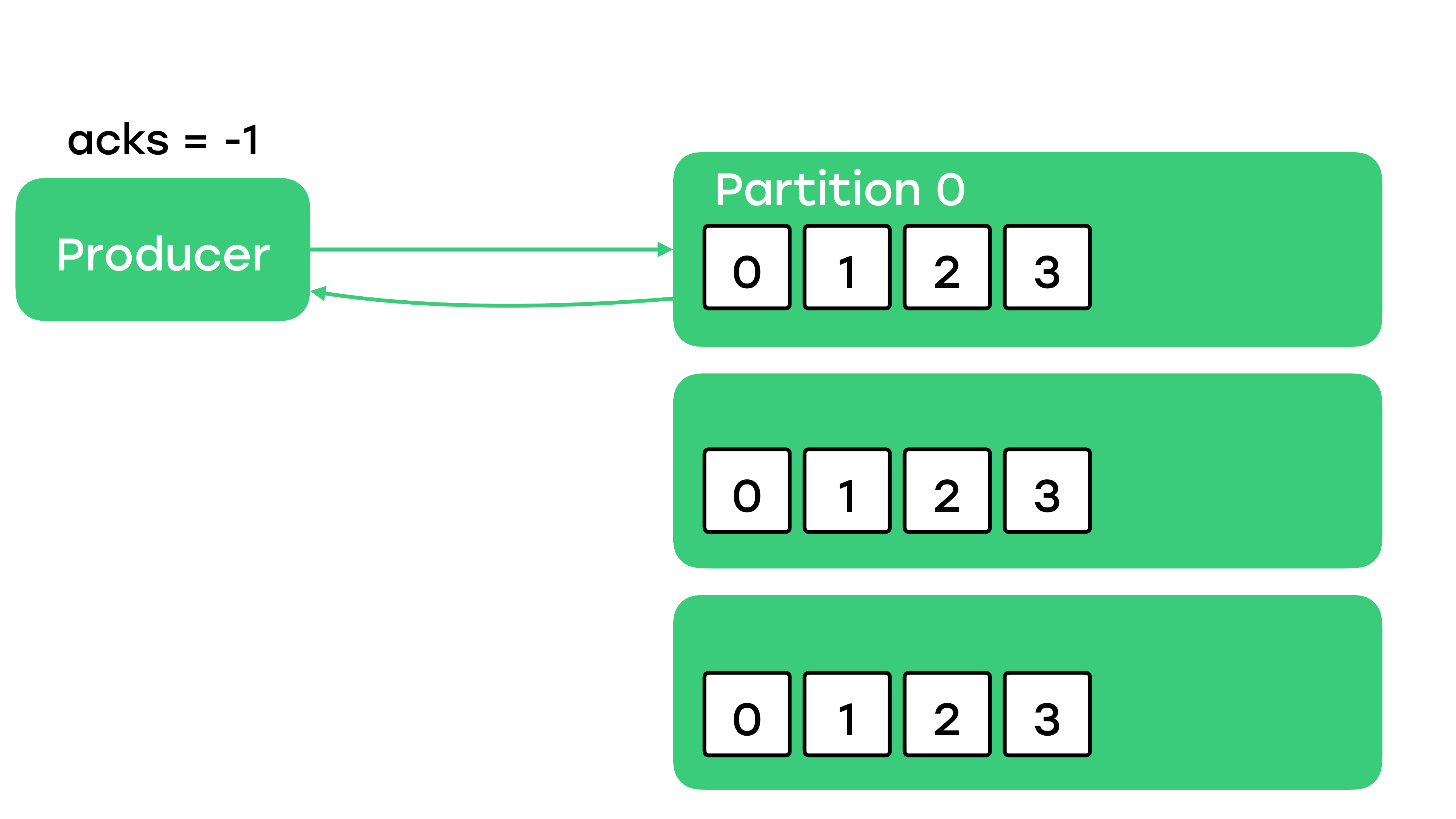
Этот вариант самый надежный и честный. Получив подтверждение от записи, мы сейчас точно знаем, что это сообщение доступно на чтении и консьюмеры могут его забирать.
Мы говорили сначала, что есть один параметр репликации и оказывается, что нужно подстроить acks.

Следует сказать, что acks – это протокольный параметр, т. е. продюсер с каждым сообщением его отправляет на кластер.
Replica.max.lag.ms
Все ли это или нужно еще что-то иметь в виду? Может получиться такая ситуация, когда реплики выходят из строя.
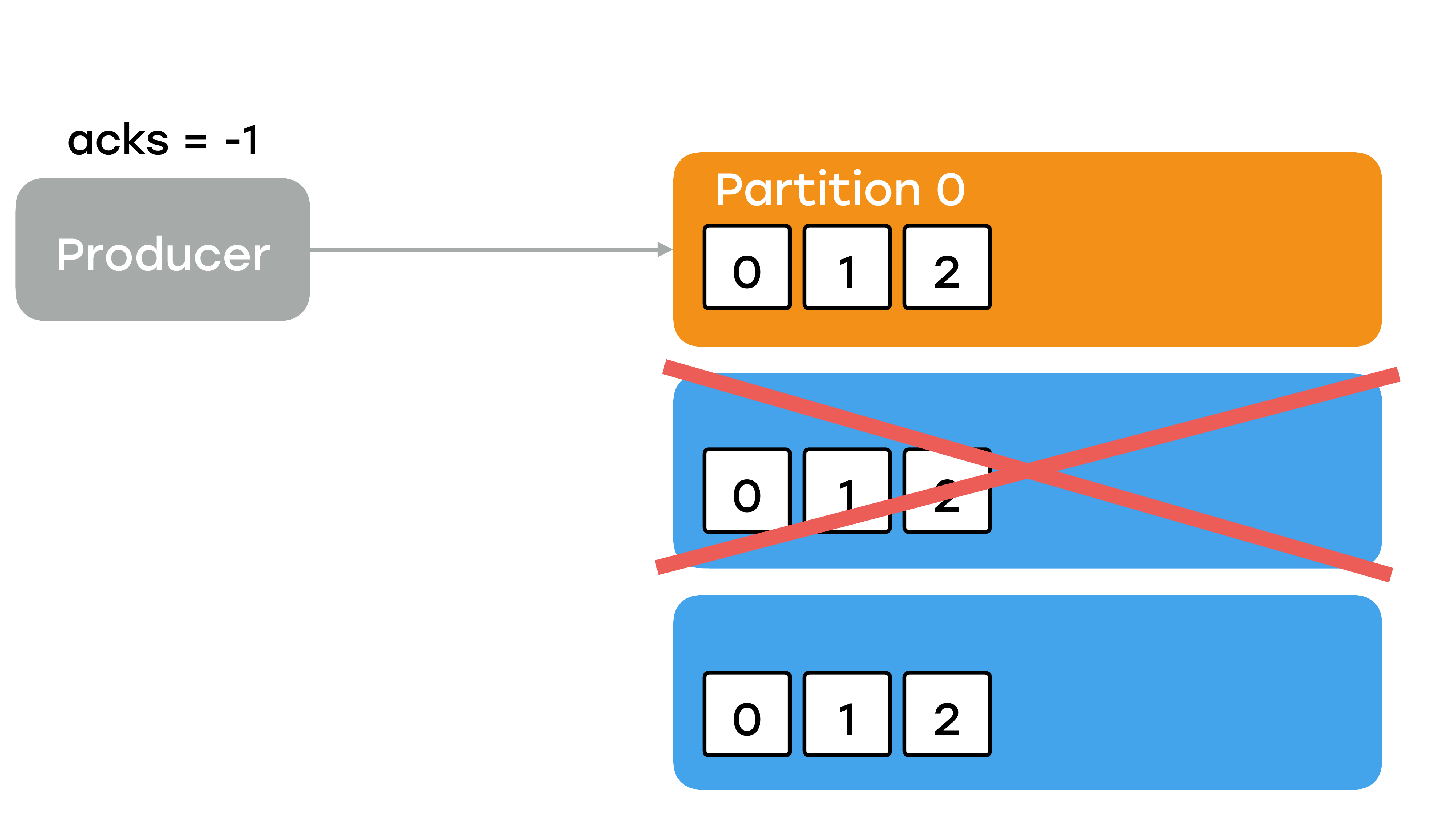
А я говорил, что для того чтобы запись была, нужно, чтобы все реплики его подтянули. На самом деле в этом утверждении есть небольшой нюанс. Не совсем все, а только те реплики, которые на данный момент находятся в статусе «in sync», т. е. они живые и они успевают затягивать последние сообщения с брокера лидера. Выражаясь по-простому, есть конфигурационный параметр у брокера «replica.max.lag.ms», который по умолчанию равен 10 секунд.
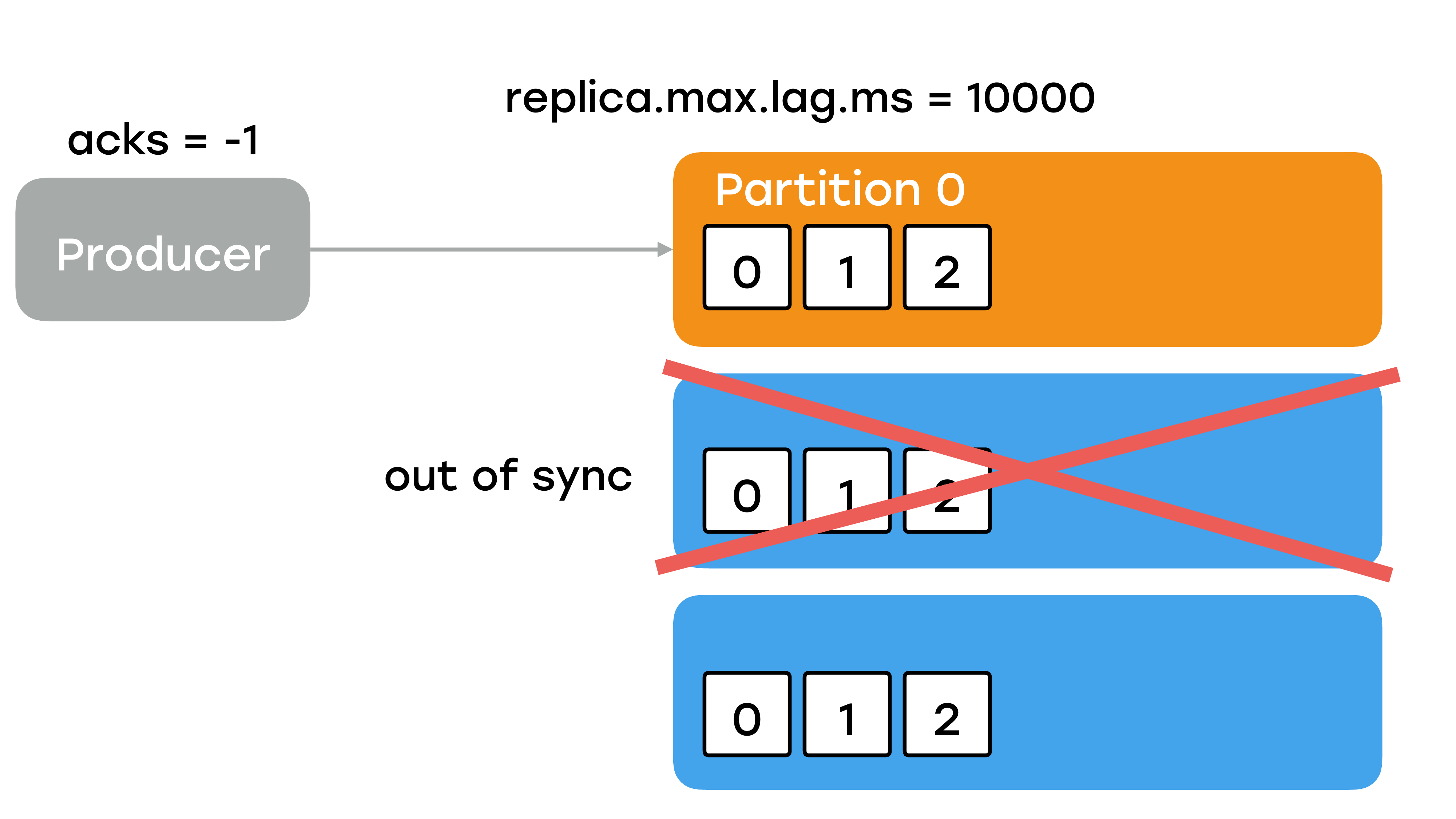
И это очень много, т. е. у каждого брокера реплики есть 10 секунд, чтобы затащить последнее, самое свежее сообщение. Если у вас реплика по каким-то причинам выпала из строя, то лидер будет ожидать ее 10 секунд в условиях нагруженной боевой системы. Это очень долго. И у себя мы выставили этот параметр в секунду.
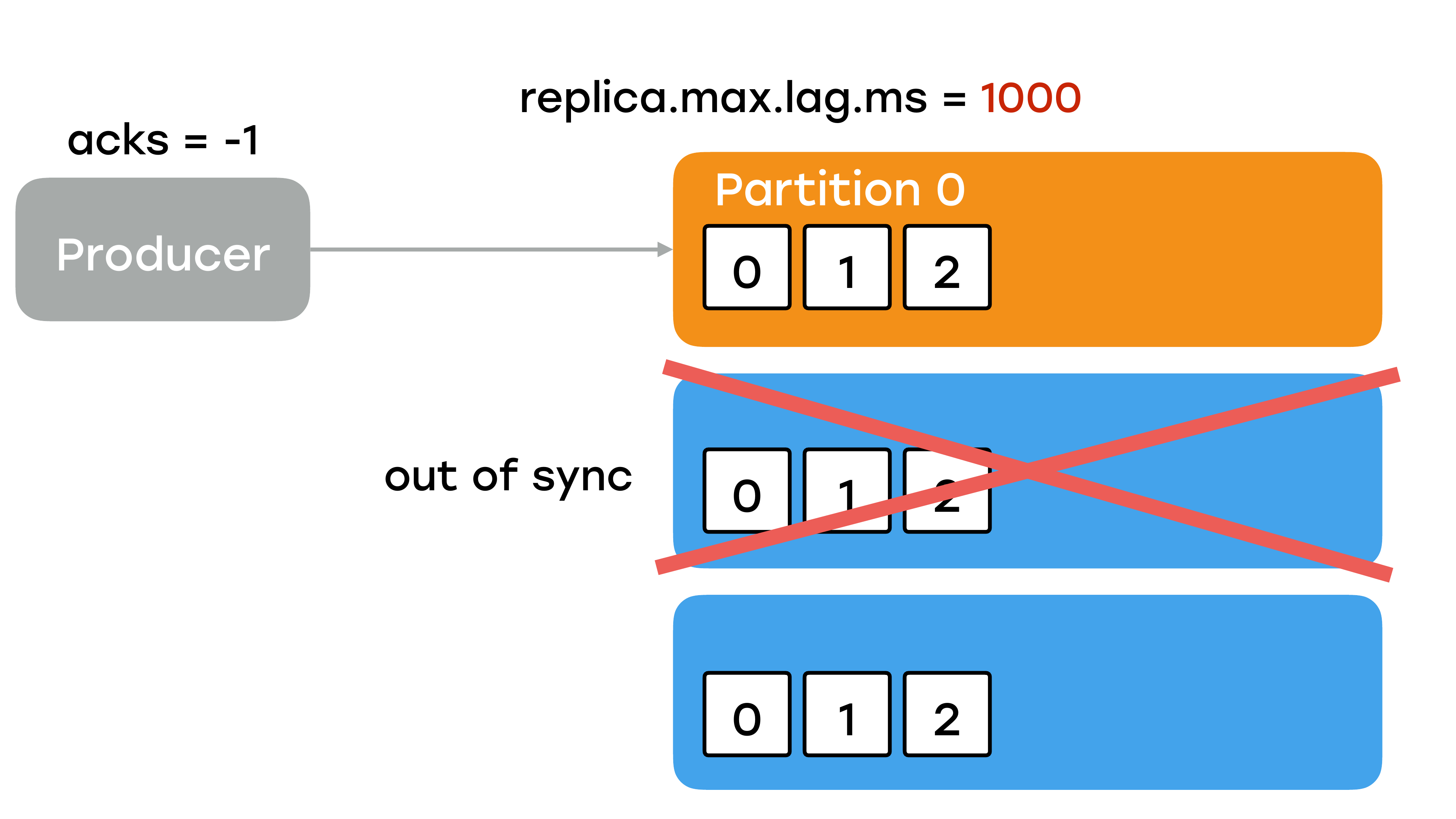
Повторюсь, не рассчитывайте, что в Kafka будут адекватные дефолтные значения.
И при такой ситуации продюсер отправляет сообщение. Оно приходит в живого лидера. Лидер всегда в статусе «in sync». Затем оно реплицируется на оставшуюся в живых реплику и потом продюсер получает подтверждение, что все хорошо, запись удалась, его можно читать.
Все бы здесь неплохо, но возможна ситуация, когда у вас две реплики выйдут из строя.
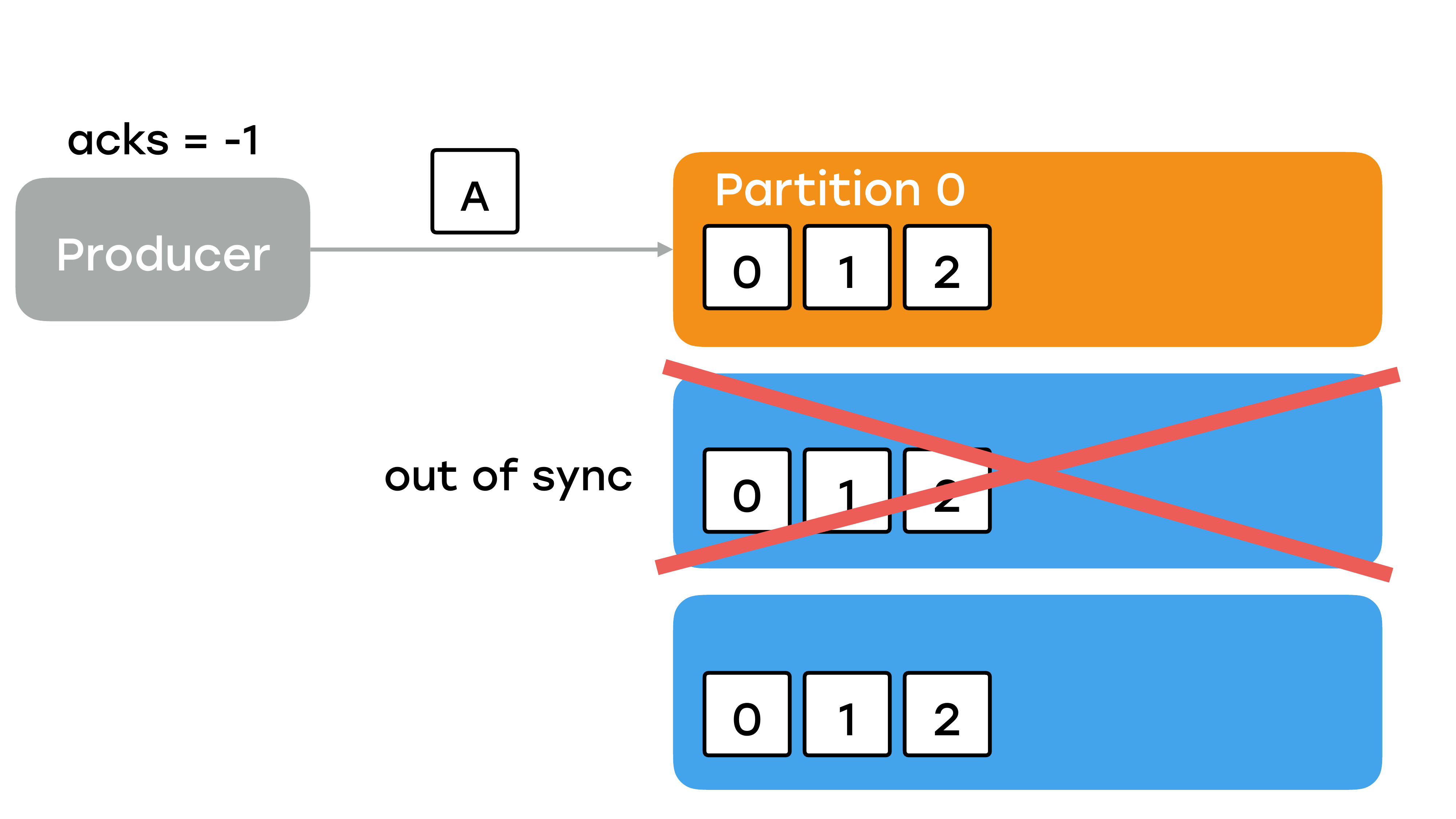
И что будет тогда? Тогда лидер останется один. Он будет один в списке живых реплик. Он будет один отправлять подтверждение продюсеру. Фактически мы вернулись в ситуацию, когда мы высылали acks =1, как будто мы ждали подтверждение только от лидера. Это очень тонкий момент. У вас две реплики упали, но запись при этом ускорится, потому что никакой репликации в этот момент не будет. Лидер будет получать сообщение, видеть, что других реплик нет и будет сразу отрапортовывать продюсеру. Но может случиться такая беда, что в этот момент у вас лидеру станет плохо, причем настолько плохо, что он потеряет данные.
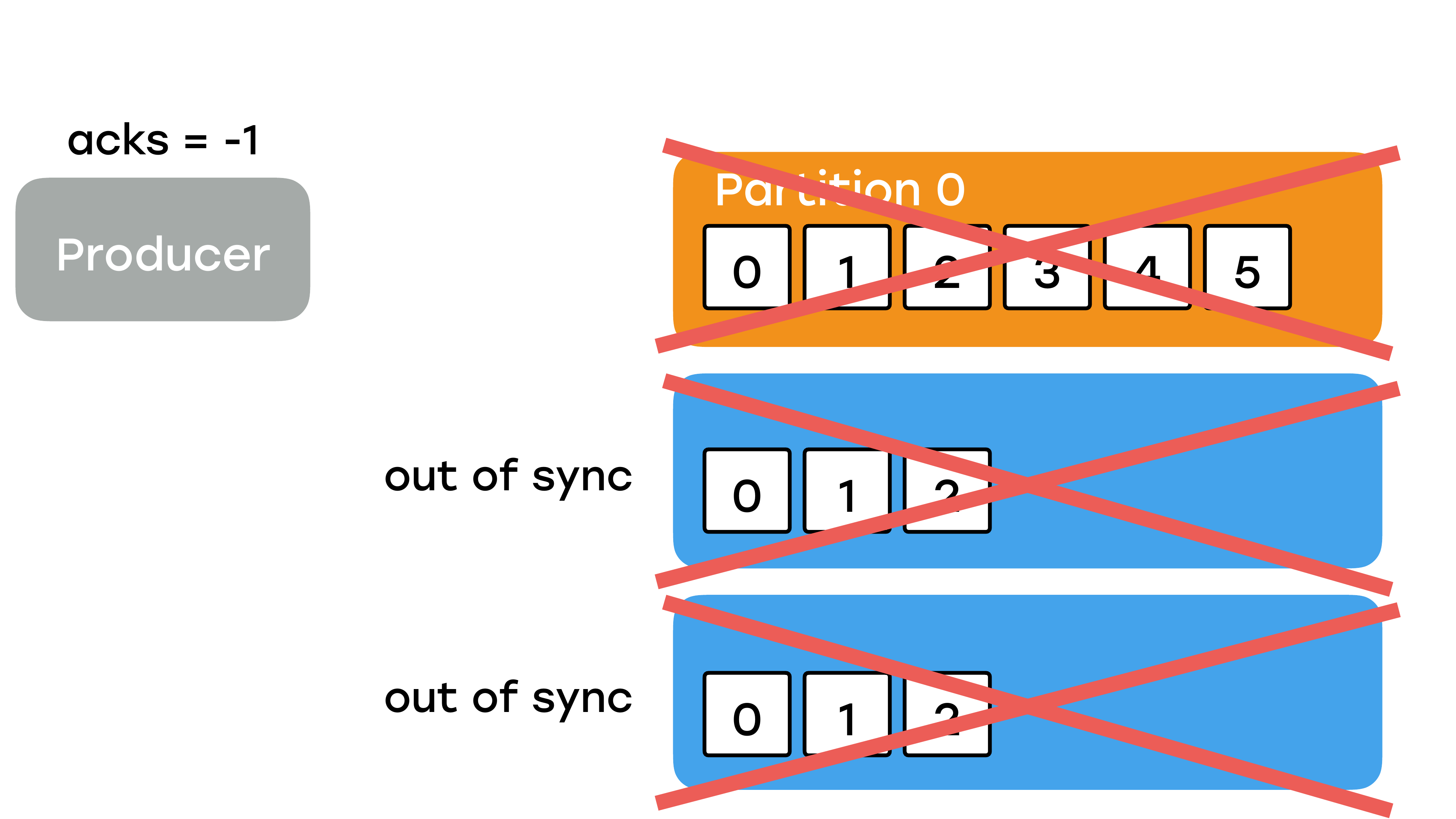
Вы, наверное, думаете, что я вам страшилки рассказываю и такое в жизни никогда не будет, что три брокера было и все три вылетели. Но именно с такой ситуацией мы столкнулись в первые полгода. У нас два брокера находились за одним свитчом в дата-центре. И этот свитч приказал долго жить, и мы потеряли две реплики. Соответственно, оставшийся в живых брокер честно решил стать лидером для части партиций, для которых он до этого был репликой и не выдержал нагрузки. Он прилег совсем, и данные там побились. Мы очень долго не могли его запустить. И это было очень большой проблемой, потому что, когда мы починили свитч, и оставшиеся реплики вернулись, то ни одна из них не смогла стать лидером, потому что они в статусе «out of sync». Они знают, что у них части данных нет, они будут ждать лидера. А лидер у нас умер раз и навсегда.
Min.insync.replicas
И как с такой ситуацией быть? Как с ней бороться? Давайте для начала решим, как ее не допустить. В конфигурации топика есть очень важный параметр, который называется «min.insync.replicas».
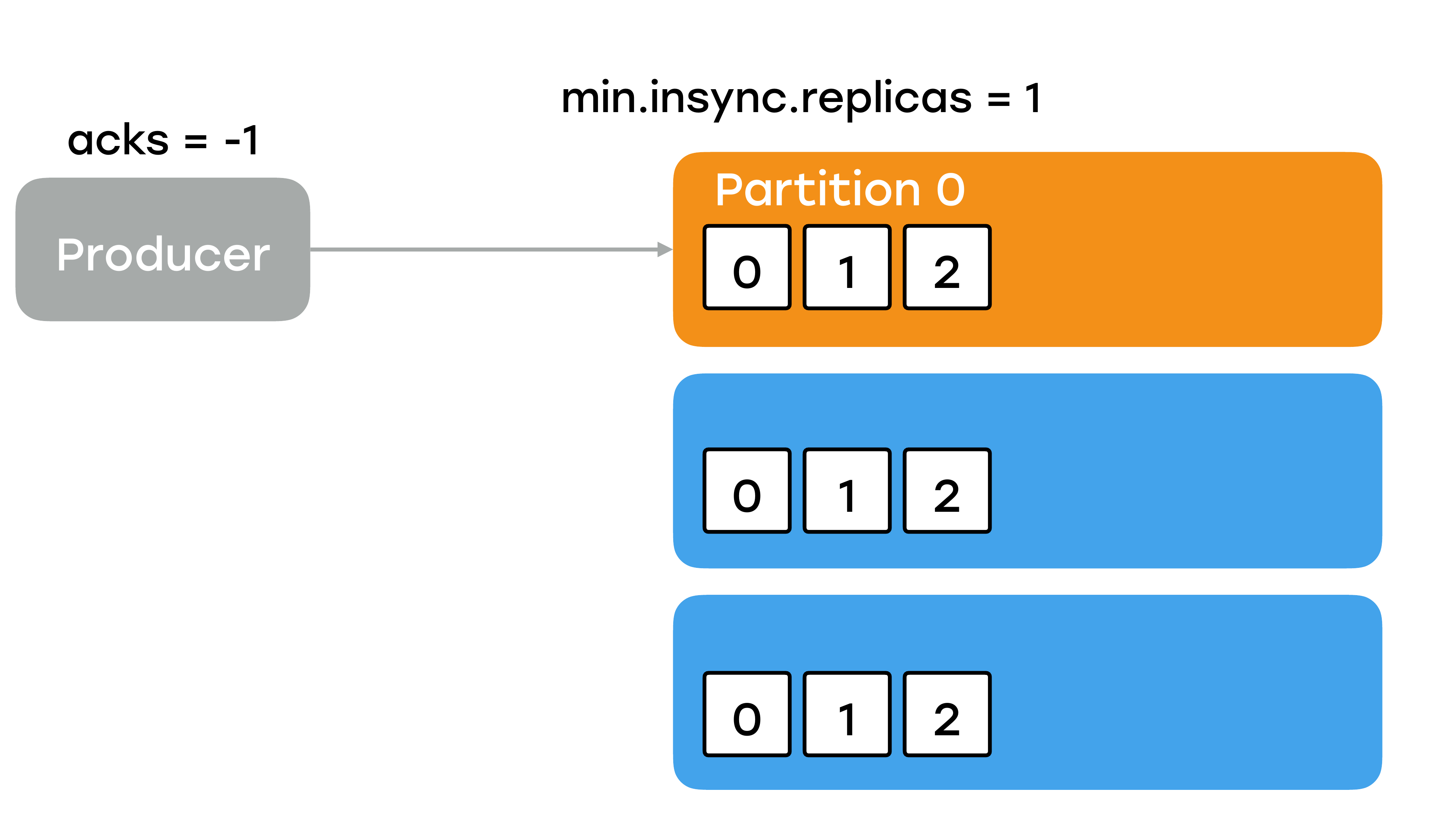
Я его буду называть min.isr для краткости. И очень жаль, что в документации он никак не выделен большими красными буквами в разноцветной рамке, потому что когда мы поняли, как он работает, в этот момент мы уже часть данных потеряли, у нас уже были аварии. Потому что фактически он определяет минимальное число реплик в статусе «in sync», включая лидера, которые необходимы для успешной записи. Грубо говоря, если в предыдущем примере мы бы выставили min.isr = 2, то при таком раскладе, когда у нас две реплики ушли, при попытке записать лидер отрапортовал ошибкой – недостаточное количество реплик живых.
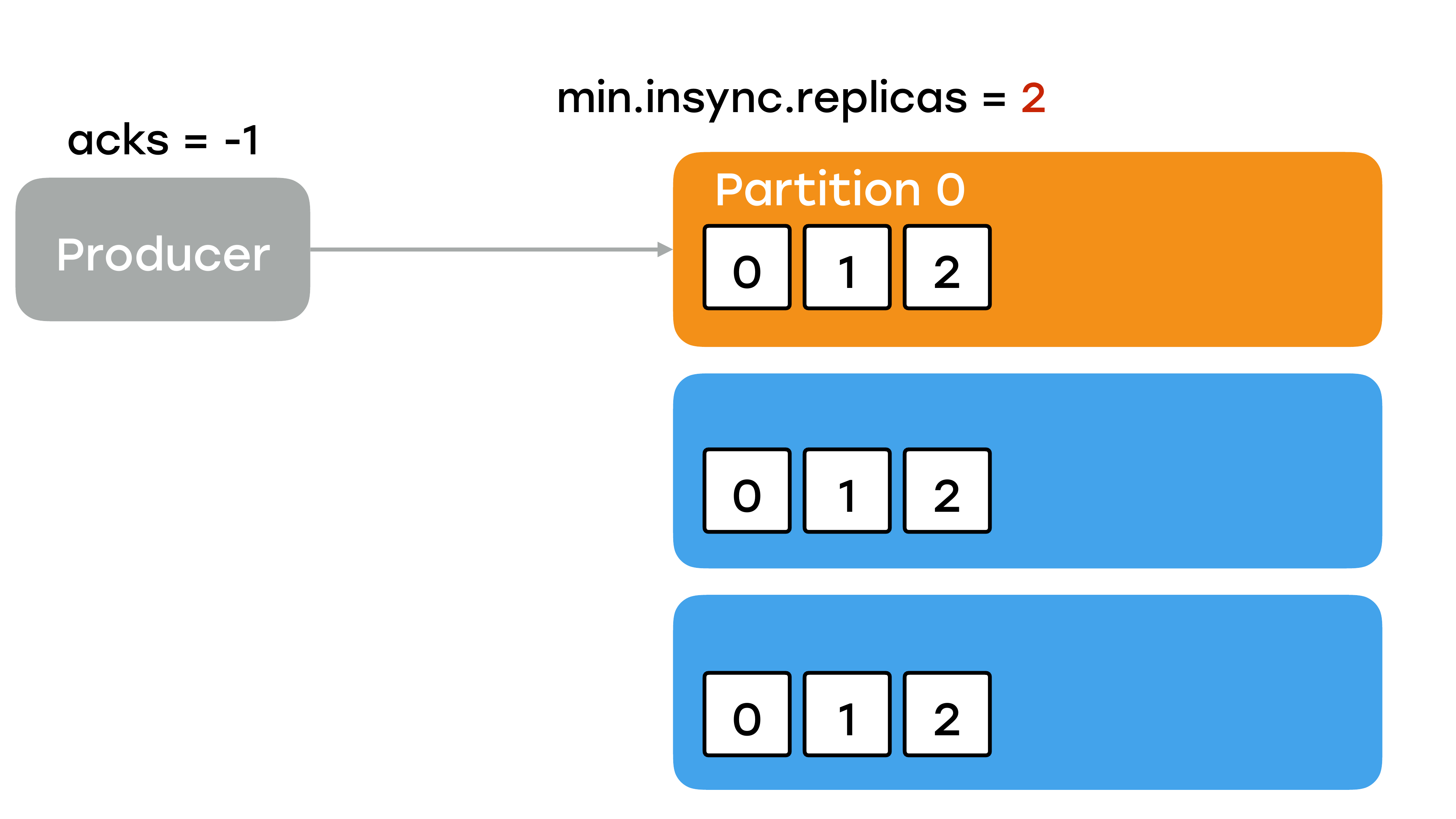
И мы бы не потеряли данные, мы бы просто ждали, когда что-то там починиться.
Очень важный момент. Параметр min.isr работает только тогда, когда вы посылаете acks = -1, т. е. вы ждете всех реплик. Если вы acks выбрали какой-то другой, например, ждете ответа только от лидера, то ничего не произойдет в таком случае. Неважно какой min.isr у вас стоит, до лидера данные дошли, вы получите подтверждение.
С min.isr мы разобрались. Это уже третий параметр, заметьте. Что делать, когда у вас все-таки возникла ситуация такая, как у нас, т. е. когда лежит лидер, мы его не можем поднять и есть две реплики в статусе «out of sync»?
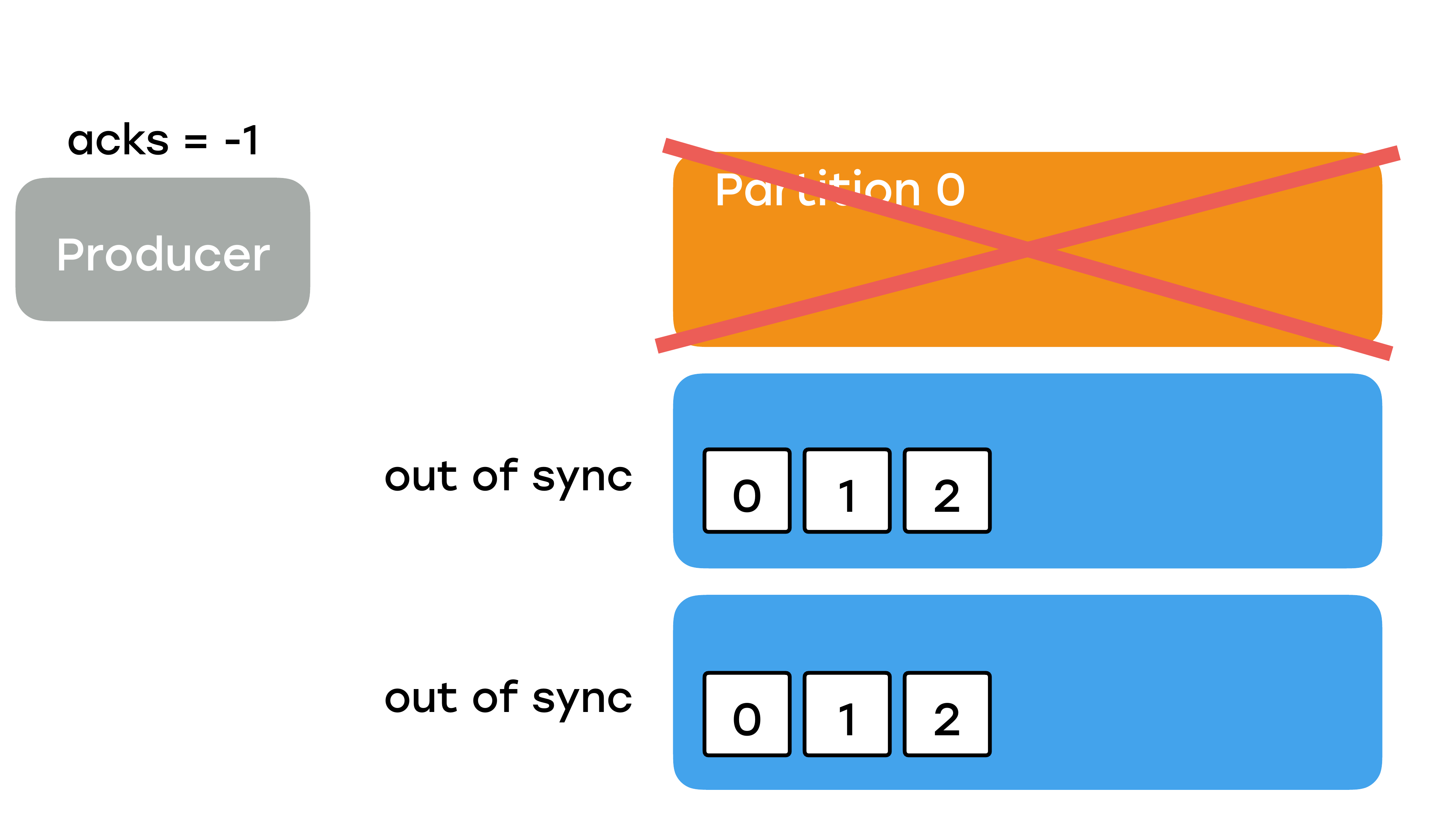
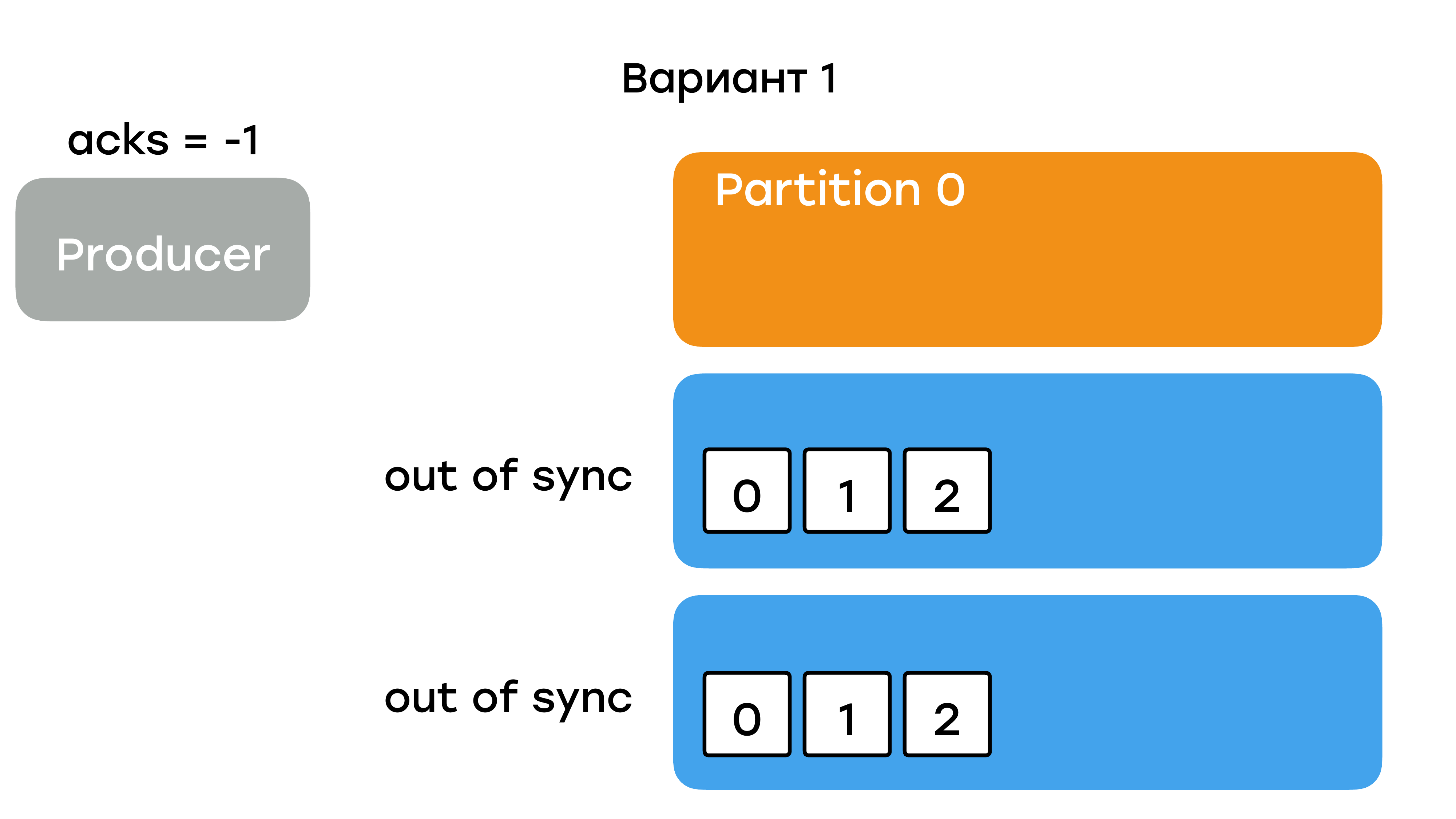
У вас есть два варианта. Первый вариант – поднять лидера с потерей данных.
И тогда чуда не произойдет. Оставшиеся реплики синхронизируются с ним, и вы потеряете все данные партиции.
К сожалению, в нашем случае так и получилось. Мы немножко поторопились и включили лидера. И он был с битыми данными, с пустыми партициями. И мы потеряли данные. Было очень неприятно.
Есть второй рекомендованный вариант.
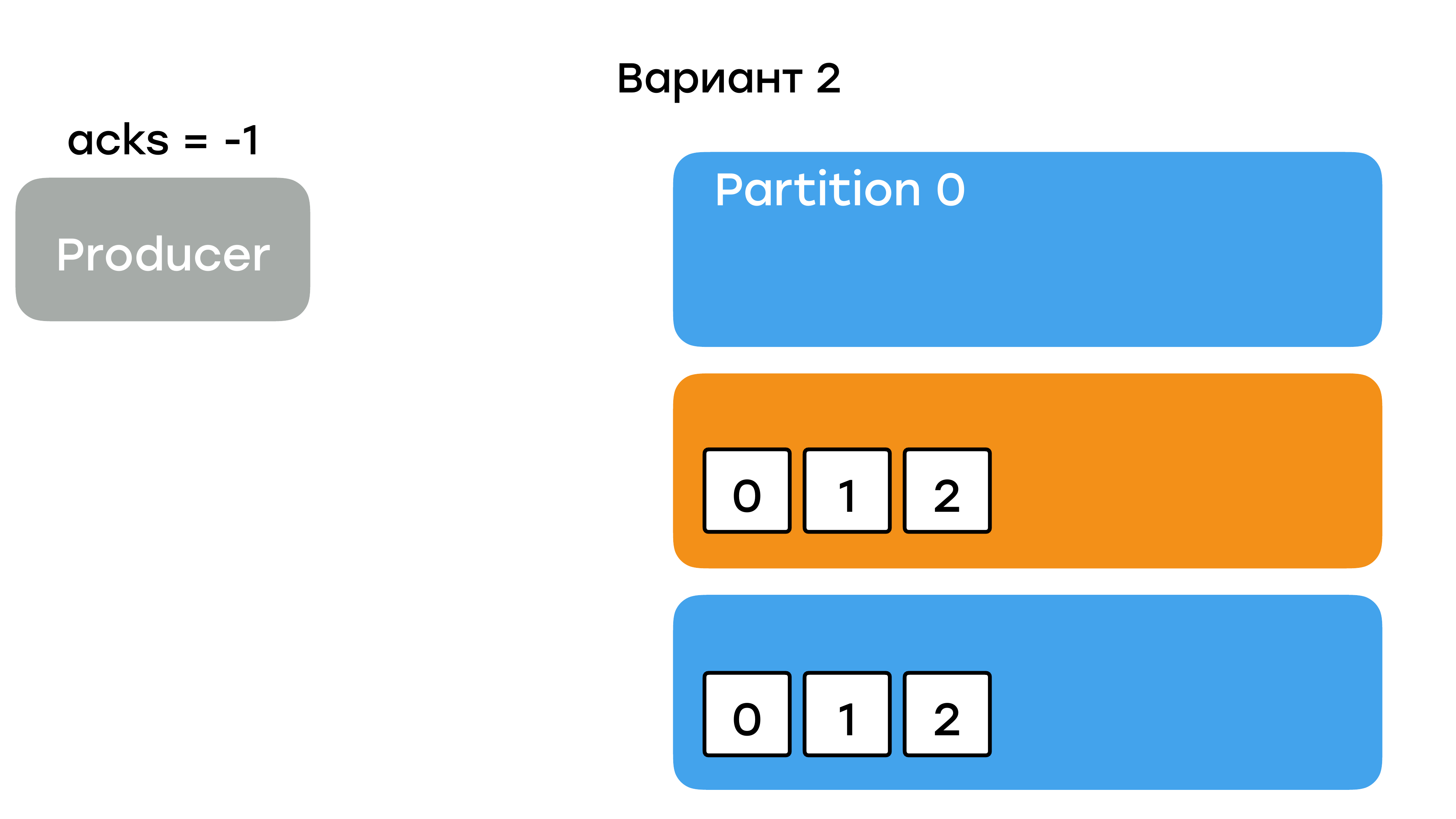
Вы можете потерять только часть данных, которые были на лидере, но их не было в репликах. Т. е. вы должны зафорсить лидерство у какой-то реплики, которая была в статусе «out of sync». Если вы это сделаете, то у вас поднимется пустой лидер. Синхронизируется с новым лидером. И вы как-то продолжите работать с частичной потерей данных.
Unclean.leader.election.enable
И чтобы выбрать в качестве лидера такую реплику с out of sync, вам нужно вставить в настройках топика параметр «unclean.leader.election.enable = true».
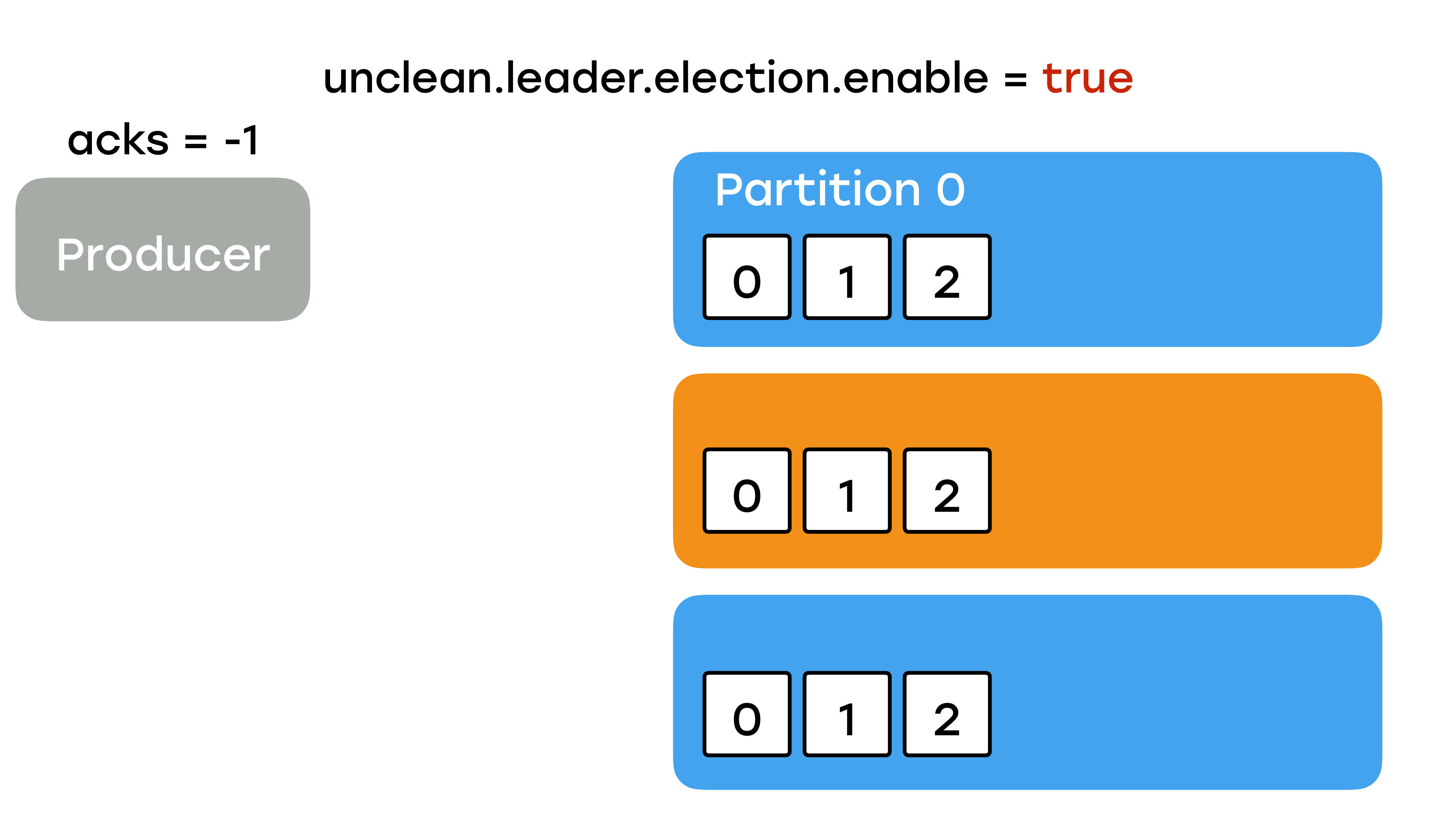
Немножко об этом параметре.

Это очень важный параметр. И он очень полезным бывает, когда нужно что-то починить. И с версией Kafka 2.0 вы можете менять динамически, просто выставив это в настройках. Не нужно там больше ничего перезагружать, рестартовать, все сразу применится.
Но по умолчанию не рекомендуется выставлять его в «true», а оставлять его в «false», без понимания, как он работает. Иначе, если он выставлен в «true», и вы забыли его вернуть в «false», у вас спокойно могут быть ситуации, когда лидер по каким-то причинам с данными чуть-чуть моргнул и на несколько секунд выпал из кластера и у него была реплика в статусе «out of sync», т. е. без нужных данных. И она станет лидером, и вы какой-то хвост снова потеряете, причем вы об этом никогда не узнаете. Все произойдет прозрачно, об этом узнаете как-нибудь потом, когда кто-то придет и спросит: «Где мои данные?». И вы узнаете много нового о себе и о Kafka. Поэтому разработчики сделали параметр по умолчанию «false». Беда только в том, что они сделали это только, начиная с версии 0.11. До этого приоритет отдавался в пользу отказоустойчивости, а не в пользу надежности. И сделали они это не просто так, а по желанию трудящихся.
Есть замечательный проект Kafka+Improvement+Proposals.

KIP-106: https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Improvement+Proposals
Это фактически предлагаемое улучшение. Вы даже сами можете туда написать. И этот очень важный проект. Потому что, когда у вас начнутся какие-то проблемы с Kafka, а они у вас рано или поздно начнутся, вам нужно будет искать решение. И далеко не всегда Stack Overflow или Google вам помогут. Скорее всего, Google вас туда и наредиректит.
В этом проекте разобрано много пограничных кейсов, там очень много полезной информации, включая то, как это работает. Вы найдете этого в документации. Более того, там есть ссылок на Kafka JIRA, где есть тоже очень много обсуждений. И вам потребуется понимать, как Kafka работает внутри. И вам необходимо будет как-то по этому проекту ходить, и постоянно читать, что происходит. Более того, там сейчас есть новые типы, о том, что будет в следующих версиях. Это тоже очень хорошо узнавать заранее, т. е. до того, как вы что-то обновите на production.
Параметры
Суммарно я сейчас рассказал про пять параметров, которые влияют на надежность данных, а до этого мы предполагали, что нам хватит лишь одного фактора репликации. Их пять.

И только понимание, как работает репликация, как идет запись и умелое конфигурирование – вас спасет от потери данных.
Мы теряли по трем причинам. Первый – это отказ оборудования. На него очень сложно повлиять. Второй фактор – это человеческий фактор. Люди всегда ошибаются, от этого вы не застрахуетесь. И третье – это то, что были небезопасные параметры у наших топиков, у продюсеров. И на это вы повлиять можете.
Выводы
Выводы по разделу:

Внимательно относитесь ко всем параметрам Kafka. Не только к этим пяти. Явно задавайте все значения, не рассчитывайте, что по умолчанию будет стоять что-то адекватное и вам подходящее.
Никогда не используйте acks = 0 и 1 для важных данных. Вы гарантированно будете их терять и вряд ли об этом узнаете.
По умолчанию значение acks = 1, т. е. по умолчанию вы будете ждать подтверждение от лидера. И если у вас в компании, как и у нас, много разработчиков и все используют Kafka, то они все будут писать своих продюсеров, кто-то точно возьмет значение по умолчанию. Получит проблемы, и вам с этим придется разбираться. Гораздо удобнее предоставить какой-то инструмент и оградить потребителей Kafka от самостоятельного конфигурирования.
Вам нужно понимать, как работает механизм репликации, как работает запись, как все это устроено внутри.
Для этого есть проекты KIP, JIRA, Etc. Документацию тоже полезно читать, хоть там не все описано.
Обязательно проводите учения. И обязательно на production. Вы должны уметь ушатывать брокеры и потом все это поднимать назад, иначе вы получите в ночь на 1-го января такую проблему и будете не очень рады всем этим заниматься.
- Структура кластера
Мы плавно перешли к разделу о структуре кластера.
Кластер из трех брокеров
Я вам рассказал про конфигурирование всех этих параметров. И если мы возьмем кластер из трех брокеров, а первые наши кластера были именно такие, то, как мы можем конфигурировать топики?
Мы можем задавать Rf = 2, miniSR = 1 и тогда с доступностью тут все нормально.
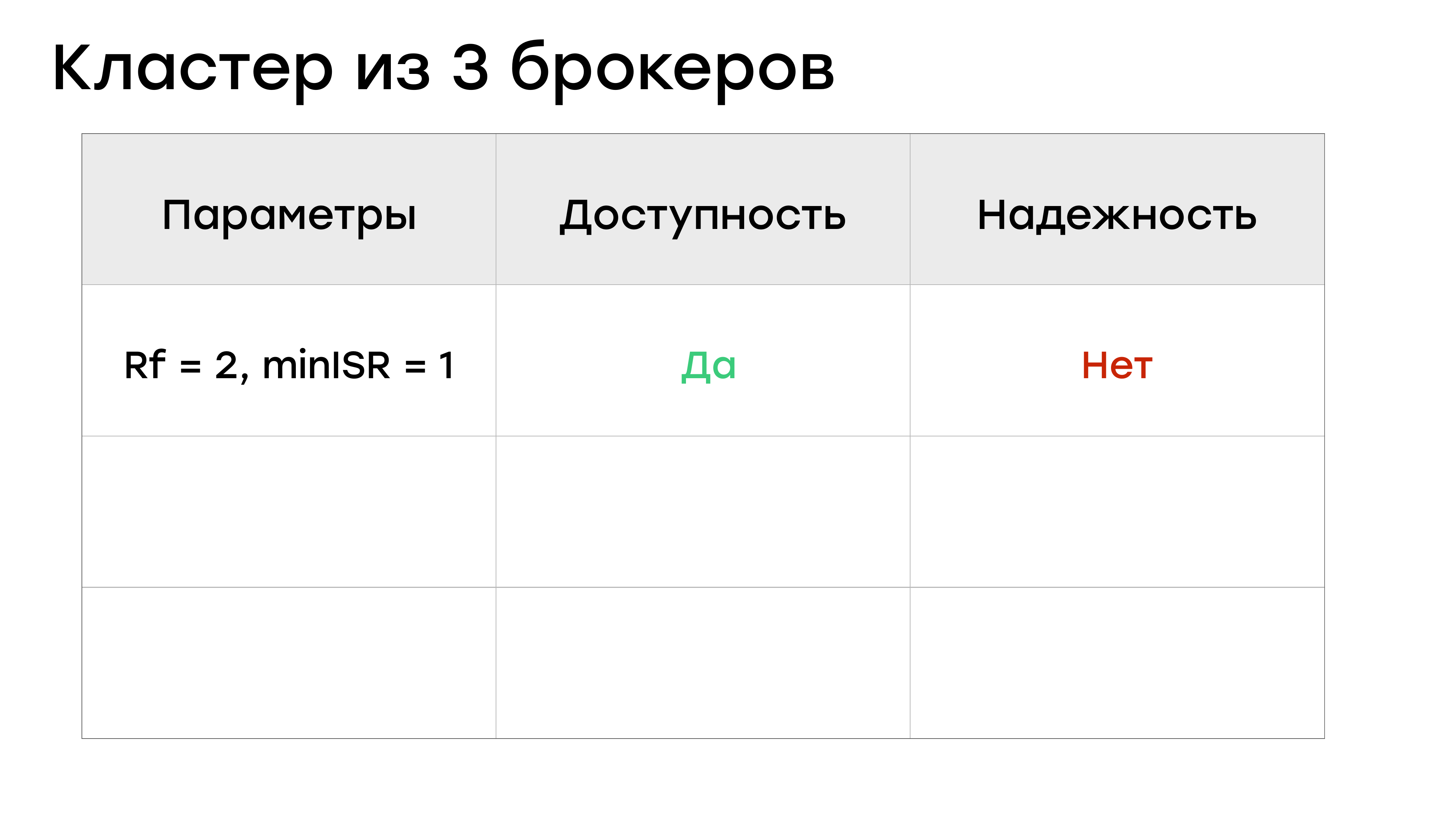
В этот момент вы любой брокер можете выключить. И запись в партицию не будет остановлена. Но как мы видели, miniSR = 1 – это не очень хорошо в плане надежности.
ОК, можно сделать Rf = 2 и miniSR = 2, тогда с надежностью будет все хорошо.
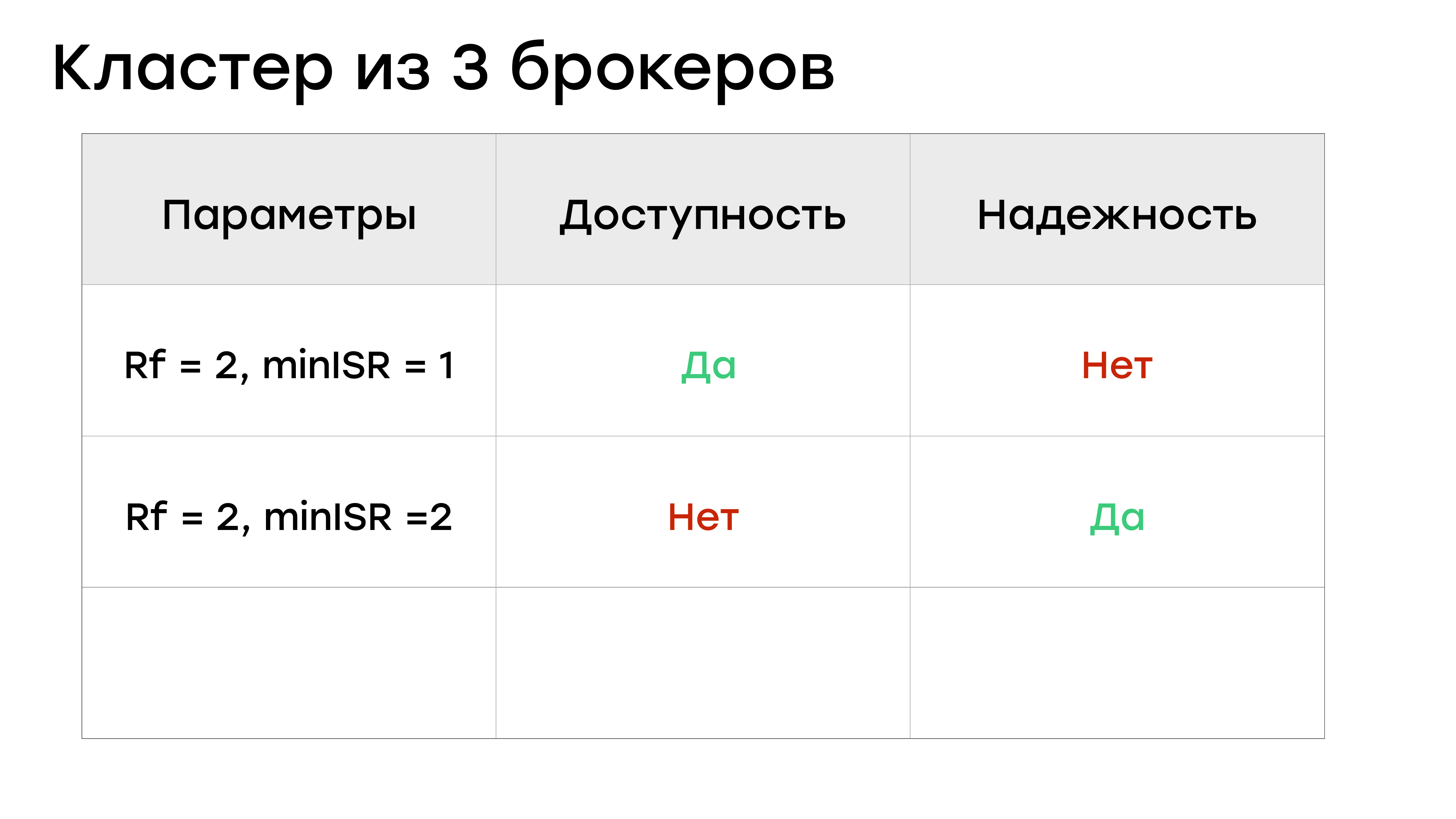
У вас будет всегда две реплики с данными, и вы их вряд ли потеряете, т. е. вы минимизируете этот риск. Но тогда у вас все плохо с доступностью. Если хоть один брокер выпадет, вы встанете и с не сможете писать в кластер. А Kafka, в которую нельзя писать, в большинстве случаев бесполезна.
И остается третий вариант, наиболее подходящий для кластера из трех брокеров – Rf = 3 и miniSR = 2.
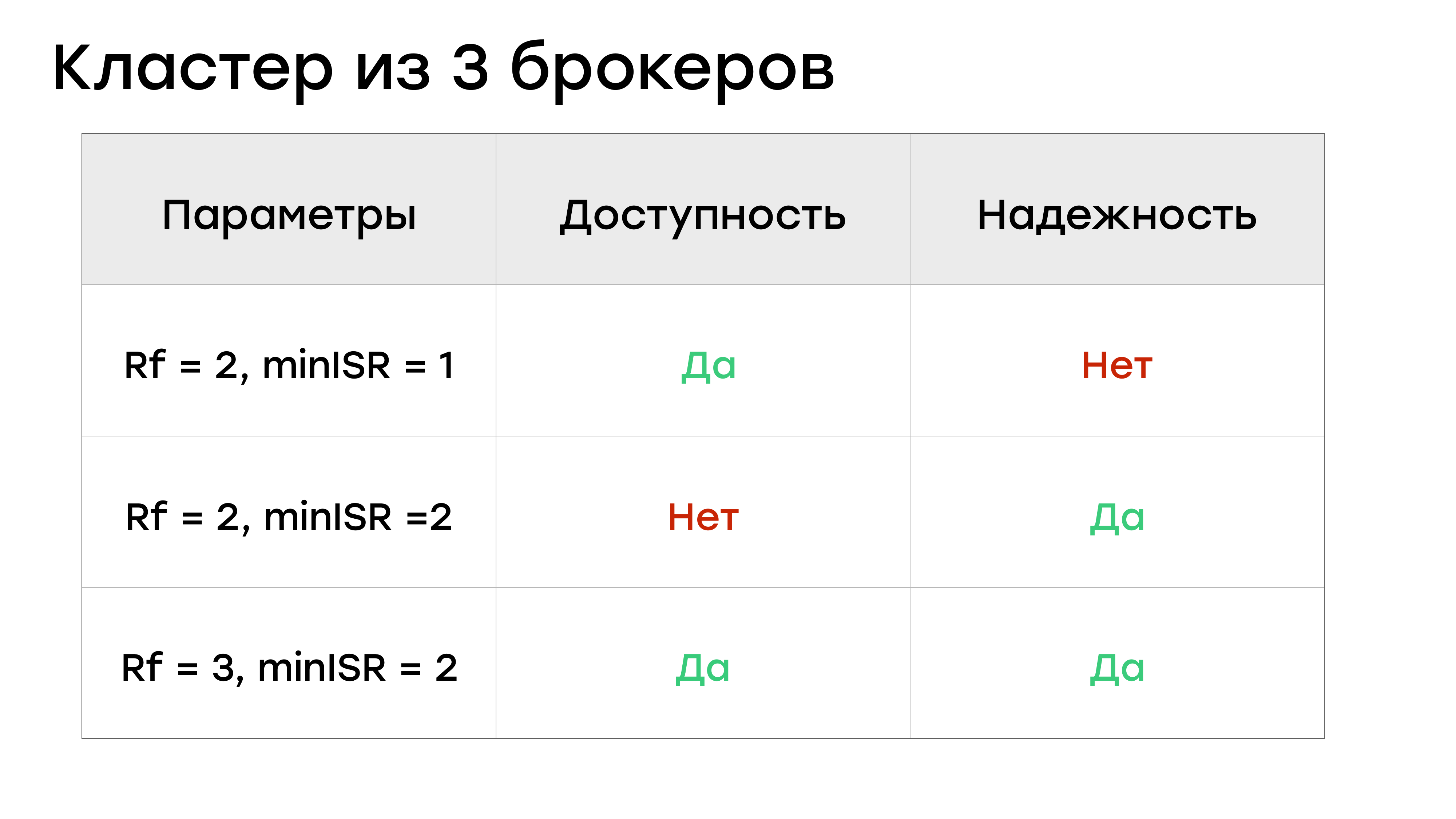
Тогда у вас и с надежностью все более-менее, и с доступностью все более-менее хорошо. Но есть ощущение, что при такой конфигурации мы не очень рационально используем ресурсы кластера. Три брокера, мы всегда выставляем Rf = 3. И если у вас есть три брокера, то каждый брокер является лидером для каких-то партиций.
И если один брокер выходит из строя, то два остальных брокера в случае, если репликация настроена, они из реплик превращаются для этих партиций в лидеров. И нагрузка на них возрастает. И это может быть очень критичным. Вы потеряете часть производительности в лучшем случае, а в худшем у вас другие брокеры могут выпасть. Поэтому мы решили, что трех брокеров нам не хватает и стали в наших кластерах добавлять брокеров. И сейчас у нас кластера из пяти брокеров.
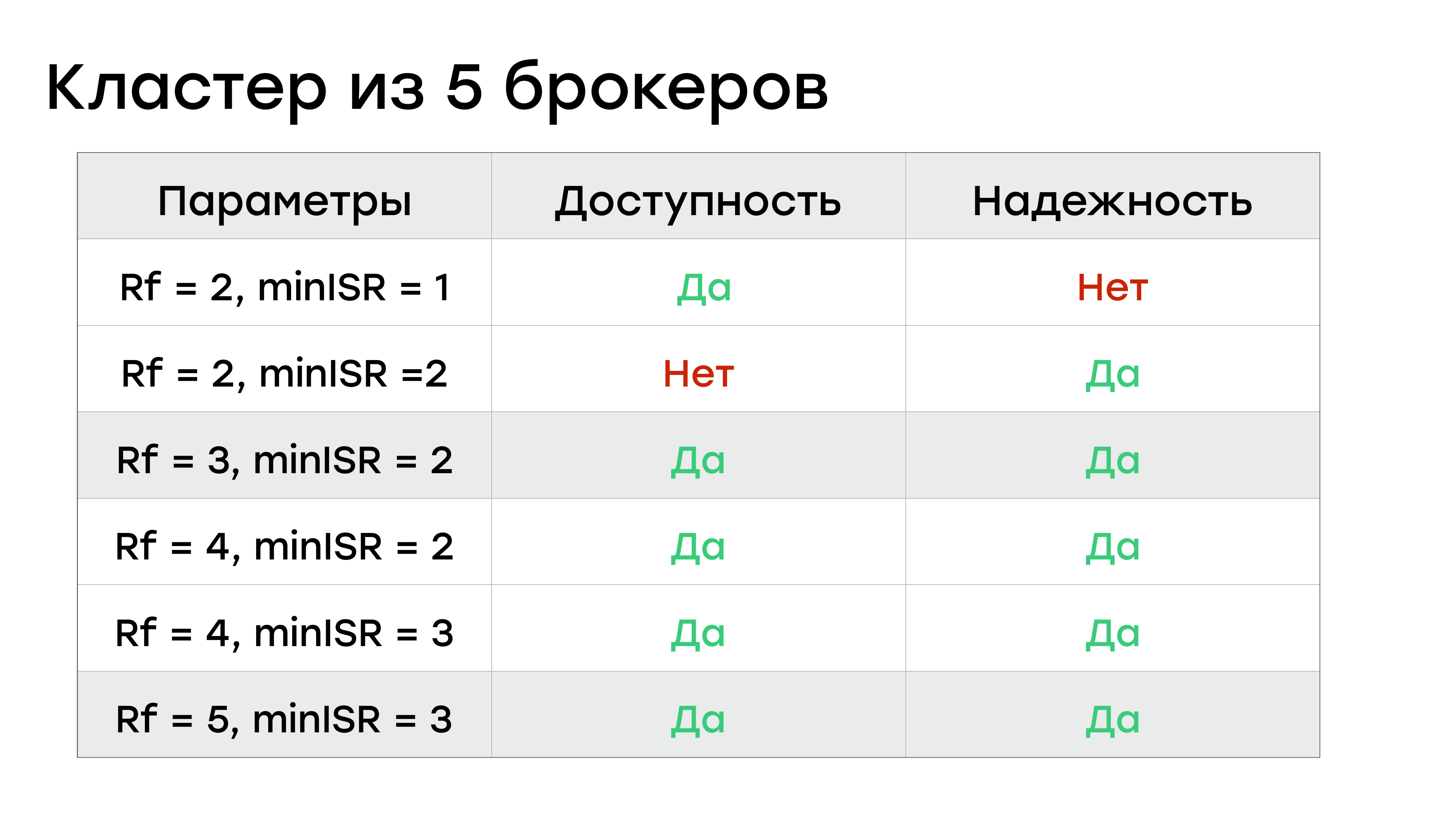
С пятью брокерами все гораздо проще. У вас гораздо больше свободы для выбора конфигурации. Вы можете сделать конфигурацию Rf = 5 и miniSR = 3. Потерять данные тут очень сложно. Или можете воспользоваться стандартной для большинства пользователей конфигурацией в Rf = 3 и miniSR = 2. При этом у вас и с доступностью нормально, и с надежностью нормально, и более-менее балансируется нагрузка по кластеру.
- Управление кластером
Хорошо, кластер у нас есть. С конфигурацией все понятно. Что нас подстерегает дальше? Во-первых, у вас всегда будут возникать рутинные задачи в управлении кластером.
Это:
- Удаление/добавление брокера. Мы, например, увеличили кластер с трех до пяти.
- Добавление/удаление топика.
- Изменение количества партиций.
- Изменение фактора репликации у топика.
- Обновление кластера. Это очень важный вопрос, т. е. обновление ПО, обновление новой версии Kafka.
Перераспределение партиций
Какие тут могут быть нюансы? Все, кроме обновления кластера, так или иначе у нас завязано на перераспределении партиций.
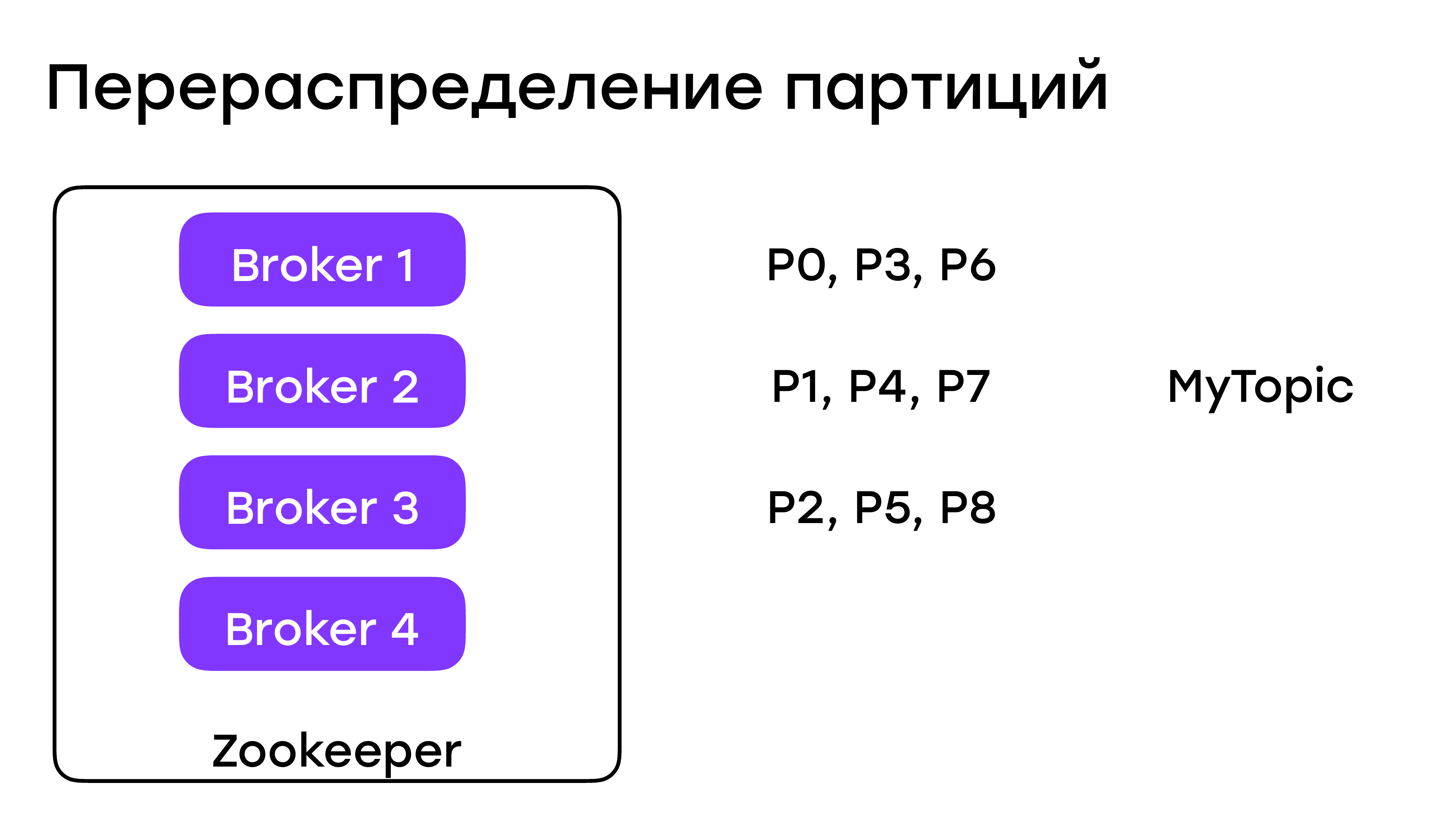
Например, был у нас кластер из трех брокеров и на нем были как-то партиции распределены. Добавили мы четвертого брокера, чуда не произойдет. У вас в существующих топиках партиции останутся на этих трех брокерах. Вам нужно сделать какие-то действия, чтобы они распределились.
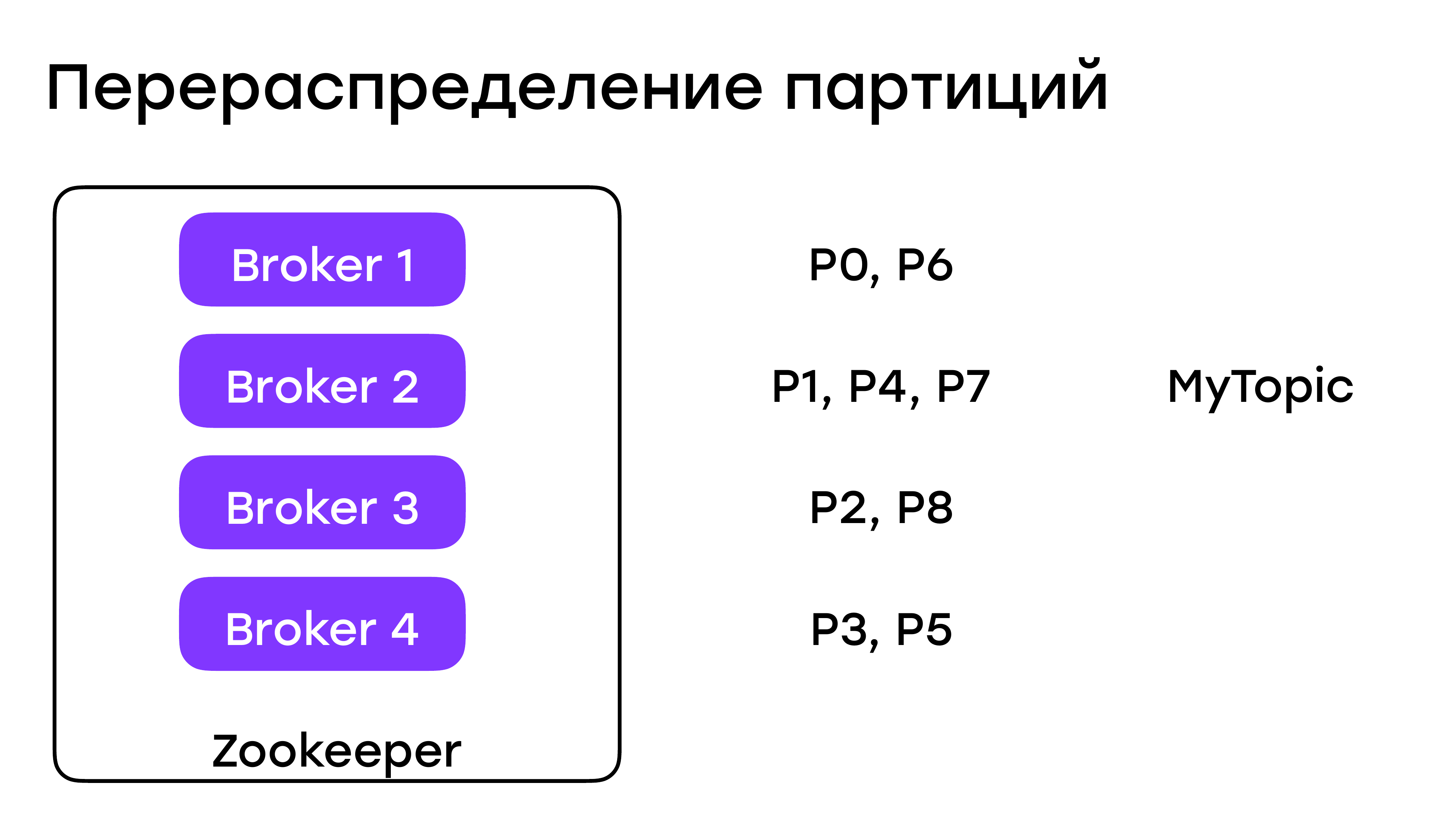
С удалением брокера из кластера такая же ситуация. Нужно руками что-то там перераспределять.
И Kafka предлагает для этого инструменты. Например, вот такую утилиту «kafka-reassign-partitions.sh».

Все с ней будет хорошо. Она умеет генерировать план перераспределений, умеет его накатывать и умеет выдавать вам информацию о том, как сейчас происходит процесс перераспределения.
Kafka-reassign-partitions.sh – generate
План перераспределения выглядит примерно так.

Обычный json-файл, в котором есть информация, какие партиции из каких топиков, на какие реплики, на какие брокеры поедут.
Но у этой утилиты есть очень большие недостатки. Во-первых, она не очень удобно работает с фактором репликации, если вы захотите увеличивать, то вам фактически руками придется генерировать планы. Но самое важное в том, что она не умеет экономить перемещение партиций по брокерам. И это очень критично, потому что плохой план может привести к деградации кластера очень легко. У вас поедут все партиции и в этот момент вы можете наблюдать катастрофический рост latency и ваши бизнес-метрики могут зайти за линию …. Это очень нехорошо.
Альтернативные инструменты
Соответственно, какие есть альтернативные инструменты?

Во-первых, есть Kafka-manager. https://github.com/yahoo/kafka-manager. Она с визуальным интерфейсом, там можно нажимать на кнопочки. Но она тоже не очень хорошо строит планы перераспределения.
И есть отличный скрипт Kafka-reassign-tool от Димаса. https://github.com/dimas/kafka-reassign-tool. Димас, спасибо тебе большое, кто бы ты ни был. Это выбор редакции. Это отличная маленькая утилита, которая позволяет вам сгенерировать план экономично и отлично умеет работать с изменением фактора репликации.
И для тех, кто живет в Java-мире, а мы в нем не живем, есть достаточно мощные утилиты от Linkedin https://github.com/linkedin/kafka-tools. Мы их не смотрели, но по описанию они должны делать все то же самое.
Процесс перераспределения

Как пользуемся мы? Мы берем kafka-reassign-tool. Генерируем карту, генерируем план, а потом уже используем родные утилиты.
И все здесь было бы не плохо, но если не выставить значение «throttle» в какое-то адекватное значение, то, не смотря на любой экономный план, вы все равно потенциально можете все ушатать.

И остановить этот процесс будет невозможно, пока он не сломается, либо не закончится успешно. Всегда обязательно выставляйте throttle при перераспределении партиц.
Проблемы перераспределения
Какие у вас могут быть проблемы?
Неоптимальный план. Это можно контролировать.
Неверный или неуказанный throttle. Нужно указывать.
И в Kafka иногда бывают баги. Мы натолкнулись на один из них, когда в процессе reassign брокер падал до null pointer exception. В общем-то, ничего страшного. Упал и упал, перезагрузим. К чести разработчиков Кафки достаточно быстро его пофиксили и все бы хорошо, но вам нужно внимательно следить за теми версиями, которые у вас на production и что в них происходит.
Что делать, если процесс сломался?
Тут все просто.

У нас он ломался достаточно часто. Это почти рутинная процедура. Когда стартует процесс reassign, в ZooKeeper создается нода – reassign_partitions. Ее нужно удалить. Посмотреть, в каком у вас все состоянии, что и куда доехало, что и куда не доехало. И подкорректировать план, и запустить заново. Ничего особенного тут делать не нужно.
Удаление топика
Эта задача тривиальная, если у вас в настройках кластера выставлен параметр «delete.topic.enable = true».

Тогда вы можете просто все удалить любым инструментом, можно даже воспользоваться тем, что идет в комплекте.
Но зачастую этот параметр выставляют с false из соображения безопасности.

Например, чтобы какой-нибудь нерадивый админ не перепутал продуктовый кластер с тестовым и ничего там удалил.
Официально удалять ничего нельзя, но если очень хочется, то можно. Ибо даже в неиспользованном топике они все равно требуют ресурсов от кластера.
Удаление топика (Вариант 1)
То, что я вам буду сейчас показывать, это очень небезопасный процесс. Ответственность за него мы не несем, предупреждаю сразу, но тем не менее он работает.
 Ни разу этот план нас не подводил, но даже для нас он показался не очень безопасным, не говоря уже об официальных источниках.
Ни разу этот план нас не подводил, но даже для нас он показался не очень безопасным, не говоря уже об официальных источниках.
Удаление топика (Вариант 2)
Поэтому мы решили удалять примерно так:

Когда у нас все партиции лежат на одном брокере, у нас настроено так, чтобы можно было потушить один брокер без потери производительности. Мы можем его спокойно потушить, все почистить и рестартануть. Вот примерно так мы сейчас и действуем.
Создание топика
Что можно сказать про создание топика? Тут все тривиально. Создаете и работаете дальше. Но есть нюанс. Те, кто еще помнит первый раздел, с которого я начинал, то я там говорил, что конфигурация очень важна. От нее зависит надежность и то, как у вас все будет жить. Поэтому если у вас, как и у нас, несколько кластеров с кучей топиков, то вы никогда не узнаете, что там происходит и какие параметры есть. Особенно, если вы предоставляете всем своим разработчикам возможность создавать топики. Поэтому мы решили сделать единый конфигурационный файл для кластера, со всеми настройками топиков.
Конфигурация топиков
Каждый пользователь, который хочет использовать Kafka, хочет создать свой топик, он ничего в Kafka не делает, он просто заходит в этот файл, указывает основные параметры.

Затем периодически запускает php-скрипт, который подтягивает этот файл, накатывает все изменения. И все готово. Более того, он еще и проверяет, что все настройки, указанные в файле, совпадают с теми, которые реально есть на кластере.
Казалось бы, зачем все это нужно? Но мы запустили такую процедуру где-то месяцев через 8 работы с Kafka и оказалось, что у нас куча топиков в production сконфигурировано неверно. Те топики, которые должны были быть сконфигурированы одинаково, различаются. И это потенциальная потеря данных. Это очень нехорошо. Мы сразу все нашли, почистили, поправили.
Явно задаем параметры по умолчанию
Чтобы это все работало, повторюсь, явно задавайте для каждого вашего топика значения по умолчанию.

Не рассчитывайте, что в Kafka они будут какими-то адекватными. Я буду повторять это еще много раз. Более того, если вы их не зададите, то вам будет нечего сверять.
Регулярные обновления
И мы переходим к такому важному вопросу, как обновление кластера, обновление ПО. Что здесь может пойти не так и какие тут могут быть вопросы и сомнения?
Даже в нашей команде был дискусс – надо ли нам обновляться регулярно и как часто. С одной стороны, новая версия – это новые возможности, которые иногда бывают очень классные и нужные. Но с другой стороны, уже все работает на какой-то стабильной версии.
Зачем обновляться, если и так все хорошо? Новые версии почти всегда устраняют какие-то ошибки. И это классно. Но зачастую в них бывают новые ошибки, как мы убедились, когда мы выкатились до мажорной версии и получили null pointer exception при reassign.
Нет никакой гарантии, что вы удачно сможете обновиться с версии 0.11 до версии 4.5, когда она когда-нибудь выйдет. Поэтому, конечно, регулярное обновление тут лучше. Но у вас нет особых гарантий даже если вы обновились на ближайшую версию. Точнее, если вы живете в Java-мире и обновляете всю свою экосистему, то, скорее всего, у вас все будет хорошо и эти гарантии есть. Но мы не живем в Java-мире. Наши клиенты написаны на других языках, используют другие библиотеки.
И у нас был реальный кейс, когда мы поторопились – обновили версию Kafka до мажорного релиза, который устранял кучу багов. Мы этот релиз очень ждали. В этот момент у нас сломалась вся наша работа с консьюмер-группами. Это было очень печально. Очень хорошо, что наша работа с консьюмер-группами никак не аффектила пользователей продукта, т. е. на production никто ничего не заметил. Просто где-то у разработчиков не доезжали логи. И мы смогли в течение дня обновить все наши клиенты, подтащить новые библиотеки. Нам повезло, что разработчики библиотек у себя их уже обновили под новую версию и мы все быстро починили. Но потенциально мы могли положить весь кластер, всю работу на какое-то время. И откатываться было бы очень сложно.
Обновление – наш алгоритм
И после этого мы выработали такой алгоритм:

- Сначала мы выкладываем новую версию на «dummy» кластер. Т. е. там ничего нет, там только запускаем тест и проверяем – все ли наши tools работают с Kafka.
- Затем выкладываем на тестовый стенд, где уже работает весь функционал аналогичный production, т. е. он тестовый.
- Там новая версия лежит на карантине примерно 14 дней. И в это время мы активно мониторим KIP и JIRA – вдруг какие-то проблемы будут найдены.
- И если за 14 дней мы у себя ничего не увидели, ничего не появилось в KIP и в JIRA, т. е. все хорошо, тогда мы выкладываем в production.
Выводы
Выводы по разделу:
Обязательно следите за трафиком при распределении партиций. Деградация кластера может быть очень критичной.
Единая точка «правды» — это хорошо. Центральные конфиги – это замечательно, это очень вам поможет. Менеджить несколько кластеров с кучей топиков очень-очень сложно, почти невозможно все держать в голове.
Обновляться нужно регулярно, но никогда не спешите с этим, особенно с Кафкой.
- Мониторинг и диагностика проблем
И мы перешли к последнему важному разделу – это мониторинг и диагностика проблем.
Что мониторим?
- Как вы уже поняли, мы мониторим конфигурацию топиков.
- Естественно, мы мониторим отставание консьюмер-групп. И для консьюмер-групп у нас есть также единый файл конфигурации, где перечислены все консьюмер-группы, для которых мы мониторим разницу в offsets.
- Мы мониторим логи ошибок. Все знают, что логи лучше смотреть при появлении проблем.
У нас есть механизм, когда все сервисы отправляют свои логи в Elasticsearch и есть механизм с нотификациями.

Ссылка: https://habr.com/ru/company/badoo/blog/280606/
Мы можем задать какой-то фильтр и в каждом временном окне посмотреть – есть ли что-то в этих логах или нет. Например, мы всегда можем посмотреть – есть ли за последние 5 минут в логах ошибки.
Казалось бы, для чего все это нужно? Очень просто. Мы активно используем Kafka не только для стриминга, а еще как систему хранения данных. И в Kafka есть внутренний тред, который занимается схлопыванием данных. Неважно, как он сейчас работает – мы просто заложили, что он будет работать. И в какой-то момент что-то пошло не так. Этот тред отвалился, и мы об этом никак не могли узнать, все остальные графики работали, все было хорошо. Просто наши сервисы стали дико тормозить от этого. И мы нашли информацию о том, что что-то пошло не так только в логах ошибок. Только там это было. Поэтому мы решили это замониторить. И теперь если с внутренними тредами Кафки что-то случается, то об этом есть записи в логах, и мы сразу об этом узнаем.
И, конечно, мы всегда мониторим, чтобы у нас все реплики были в статусе «in sync».
И мониторим перекосы на брокерах. Что это такое? И зачем это нужно? Если вы делали reassign, если у вас какие-то брокеры выпадали и появлялись заново, то у вас возможна ситуация, когда какой-то брокер является лидером для большого числа партиций. Например, в топике было 10 партиций. И сейчас у вас какой-то брокер является лидером для 8 из них. Это большой перекос по нагрузке. Это очень плохо для производительности. В большинстве случаев нужно стараться сделать так, чтобы нагрузка распределялась по брокерам равномерно. И мы за всем этим смотрим.
Последнее – это «Функциональный» мониторинг. По факту мы мониторим Kafka как некий внешний сервис. Мы создали тестовые топики вот с такими параметрами: RF = 5, miniSR = 3; RF = 3, miniSR = 2.

И у нас есть небольшая утилита, которая постоянно пишет с параметром acks = «all» или «-1» в данный топик.

И мы смотрим всегда честное время записи в старших перцентилях. Параллельно у нас есть тред, который читает, что проверяет «лаг» чтения.
Зачем мы это все делаем? Мы внедряли Kafka не только для того, чтобы я вышел на сцену и все это вам рассказывал. Нам нужно было добиться быстрой доставки сообщений, почти мгновенной. И даже если у вас все работает, нет никаких ошибок, все брокеры живы, все в статусе «in sync», вам нужно, чтобы ваши бизнес-метрики были в нужном статусе. Вам нужно, чтобы запись всегда попадала в некий обещанный лимит. Эти все пункты влияют на «зажигание лампочек». Что-то идет не так, загорается лампочка, звонят ответственному человеку, он лезет туда разбираться, что происходит.
Метрики и capacity planning
Kafka отдает очень много метрик через Java Management eXtensions. Но повторюсь, мы не в Java-мире. Нам нужно было использовать JMX-агент Jolokia. Это мост между JMX и http. Соответственно, мы все эти метрики собираем и активно на них смотрим. Их там действительно очень много. Я на этом страшном слайде перечислил некоторые из них, на которые мы реально посматриваем.

NetworkProcessorAvgIdlePercent
Это важная метрика.

Она практически говорит, насколько у нас свободны сетевые ресурсы. Чем ее значение больше, тем лучше. И в какой-то момент мы видели, что у нас фактически сетевые треды в Kafka заканчиваются. И если мы будем давать больше нагрузки, то у нас свободных тредов не останется. Мы увеличили конфигурационный параметр в кластере, увеличили количество тредов. Тредов стало больше. Проблему мы немножко отодвинули на потом, т. е. сейчас у нас все хорошо.
Zabbix
Помимо метрик Kafka наша компания использует Zabbix для мониторинга. Там можно увидеть очень много параметров: CPU Utilization, CPU iowait, CPU Load, Disk space.
На это все желательно тоже смотреть. И не просто смотреть, а как-то реагировать.
I/O Sheduler: NOOP вместо CFQ
Kafka – это все-таки персистентное хранилище. Она работает с диском, поэтому нам очень важно, чтобы запись на диск была быстрой и хорошей. Поскольку у нас Kafka админят два человека, которые параллельно занимаются администрированием всех наших MySQL-серверов, то они по своему опыту знают, что изменения I/O Sheduler для систем хранения данных NOOP вместо дефолтного CFQ дает вот такой прирост производительности в записи.

И поскольку мы используем файловую систему Ext4, мы выставили параметр «data = writeback». Это нам сильно позволило снизить проблемы записи на диск. Но! Такая конфигурация хорошо подходит для серверов с Kafka. Если у вас на машине еще какой-то софт установлен, то очень внимательно относитесь к Sheduler и к настройке файловой системы, потому что, сделав хорошо для Кафки вы можете сделать большие проблемы для каких-то ваших других сервисов.
Итоги
Подведем некоторые итоги:

- Kafka – это не автопилотируемый аппарат. У вас не получится просто ее запустить и благополучно смотреть, как она работает. Вам всегда придется за ней следить.
- Для надежной записи вам нужно будет следить за кучей параметров. Важный – это acks. Никогда не выставляйте его в 0 и 1. И всегда следите за нужным параметром «miniSR».
- Централизованная конфигурация – это очень хорошо. Это спасет вас, если у вас море топиков. Это достаточно дешево сделать.
- Обязательно нужно мониторить все, что важно. И по возможности мониторинг должен быть автоматизированным. Плюс обязательно проводите обучение, чтобы проверять загораются ли у вас ваши лампочки или нет.
- Обновляться нужно регулярно, потому что действительно многие проблемы уходят после обновления. Главное, следить, чтобы не вылезли новые проблемы.
- И постоянно читайте KIP и JIRA, чтобы быть в курсе всего, что происходит.
И если вы все это сделаете, тогда – да, тогда Kafka – это мощный, надежный, классный инструмент и все у вас будет хорошо.
Я не рассказал еще очень много всего, что могу рассказать. Подходите к нам на стенд и там я вам все это буду рассказывать. Спасибо всем!
Вопросы
Антон Ленок, программист из Сбербанка. Денис, большое спасибо за очень интересный доклад. Я новичок в мире Kafka. Мне очень интересно в нем. И у меня родился вопрос на основе того, что вы нам рассказали. Не рассматривали ли вы такую ситуацию, когда можно было бы использовать две Кафки? Например, для каких-то важных данных, которые нам не хотелось бы потерять и можно бы выставить в настройке Acknowledge «-1». И вторую Kafka, которую нам бы хотелось ускорить и поставить в Acknowledge – подтверждение только от одного брокера. Там можно было бы ее побыстрее обновлять, можно было бы смотреть – есть баги или нет. И вообще смотреть, как себя ведет сеть.
Я понял ваш вопрос. Во-первых, Acknowledge – это параметры на продюсере, а не в кластере. Т. е. вы можете использовать спокойно один кластер для всего и как-то регулировать зависимость от вашей задачи именно в настройке на продюсере. У нас несколько кластеров в Кафке. Но, как показала практика, везде запись должна быть надежной. И данные потерять везде очень критично. Но повторюсь, настройками продюсера все это решается спокойно на одном кластере. Кафка очень хорошо масштабируется и зачастую вам одного кластера может хватить для решения многих задач и проблем.
Здравствуйте! Дмитрий, Яндекс. Вы упомянули термин «учение». Нельзя ли поподробнее? Как оно выглядит? Т. е. выводится свитч, приходит человек и свитч отключает или как?
К сожалению, не всегда можно отправить человека в дата-центр. Они у нас иногда далеко находятся. Но – да, мы по жесткому режиму тушим брокера: можно в штатном режиме тушить, можно в жестком. Лучше рассмотреть все варианты. Сначала все это обкатом на тестовом. Неприятно получить такую ситуацию, когда на production потушили и не смогли восстановиться. И когда мы все обкатали на тестовом, то мы уже теоретически умеем восстанавливаться. Если теоретически мы живем без брокера, то тогда мы обязательно проведем учение на production. Свитчи мы не тушим, потому что со свитчами много серверов. Обычно мы по жесткому тушим одного или двух брокеров. Одного обязательно. И разруливаем ситуацию. Это очень важный пункт. Если вы не умеете с этим работать, вы получите проблему.
Меня зовут Михаил, Санкт-Петербург. Во-первых, спасибо за интересный доклад. На каком железе у вас крутятся брокеры? И сколько в среднем партиций приходится на каждый брокер?
Я осознанно не делал слайды с каким железом у нас крутятся брокеры. По памяти я это сейчас не скажу. Но если интересно, можете связаться с нами, я вышлю всю конфигурацию. Это не тайна, просто я об этом не хотел упоминать, у меня доклад был очень короткий. Сколько в среднем партиций на брокере? Сложно сказать, потому что у нас несколько кластеров. Есть кластеры, где бывает по несколько сотен партиций на брокере, а есть кластеры, где их несколько десятков. Для того чтобы с нами связаться, у нас есть пиар-отдел (у Badoo), там можно задать вопрос. Или можно легко найти меня в социальной сети Facebook по моей фамилии.
Добрый день! Вячеслав Старцев, Новосибирск. Спасибо за интересный доклад! Вопрос у меня про ZooKeeper. ZooKeeper у вас в кластере, в ансамбле или как? Насколько я понимаю, если упадет у вас ZooKeeper, то никакого толку от отказоустойчивого кластера Kafkaне будет?
Да, вы абсолютно правы. ZooKeeper у нас в своем собственном кластере. У нас там несколько нод ZooKeeper. И так получилось, что за все полтора года с ZooKeeper существенных проблем у нас не было. Да, были моменты, когда одна нода выходила из строя. Но это быстро чинилось. Тут я вам ничего хитрого не подскажу. Почему-то нам повезло и с ZooKeeper у нас не было проблем. Нам хватало даже трех нод в кластере ZooKeeper, даже пять устанавливать не стали.
Т. е. у вас три, да?
Если не ошибаюсь, у нас три ноды в ZooKeeper, в отдельном кластере. ZooKeeper у нас используется только под Kafka. Мы не в Java-мире, нам для других целей ZooKeeper не нужен.
blaze79
'partition_cnt' => 64
смотрим и плачем, смотрим и плачем